




Visual Intelligence in Precision Agriculture: Exploring Plant Disease Detection via Efficient Vision Transformers

 ,
,  , , and
, , and
Abstract
1. Introduction
- Plant disease detection is now significantly improved using CNN-based models, based on the latest research findings. However, the particular models exhibit limitations such as translation invariance, locality sensitivity and a lack of global image comprehension. To address these shortcomings inherent in CNN-based approaches, this study introduces a new approach utilizing a Vision Transformer-based model for improved and effective plant disease classification.
- Drawing inspiration from the Vision Transformer (ViT) proposed by Alexey Dosovitskiy et al. [26], we conducted training and fine-tuning of the ViT model, specifically for fire detection, resulting in notable advancements surpassing the SOTA CNN models. By improving the architecture of the ViT model, it has been possible to reduce the number of learning parameters from 85 million to 21.65 million as a result of the fine-tuning process, which has resulted in an increase in the accuracy of the model at the same time.
- The proposed GreenViT model exhibits exceptional accuracy and effectively reduced the occurrence of false alarms. Consequently, the developed system proves to be highly suitable for accurate plant disease detection, ultimately mitigating the risks associated with food scarcity and security.
2. Material and Methods
2.1. Datasets
2.1.1. Plant Village
2.1.2. Data Repository of Leaf Images
2.1.3. Plant Composite
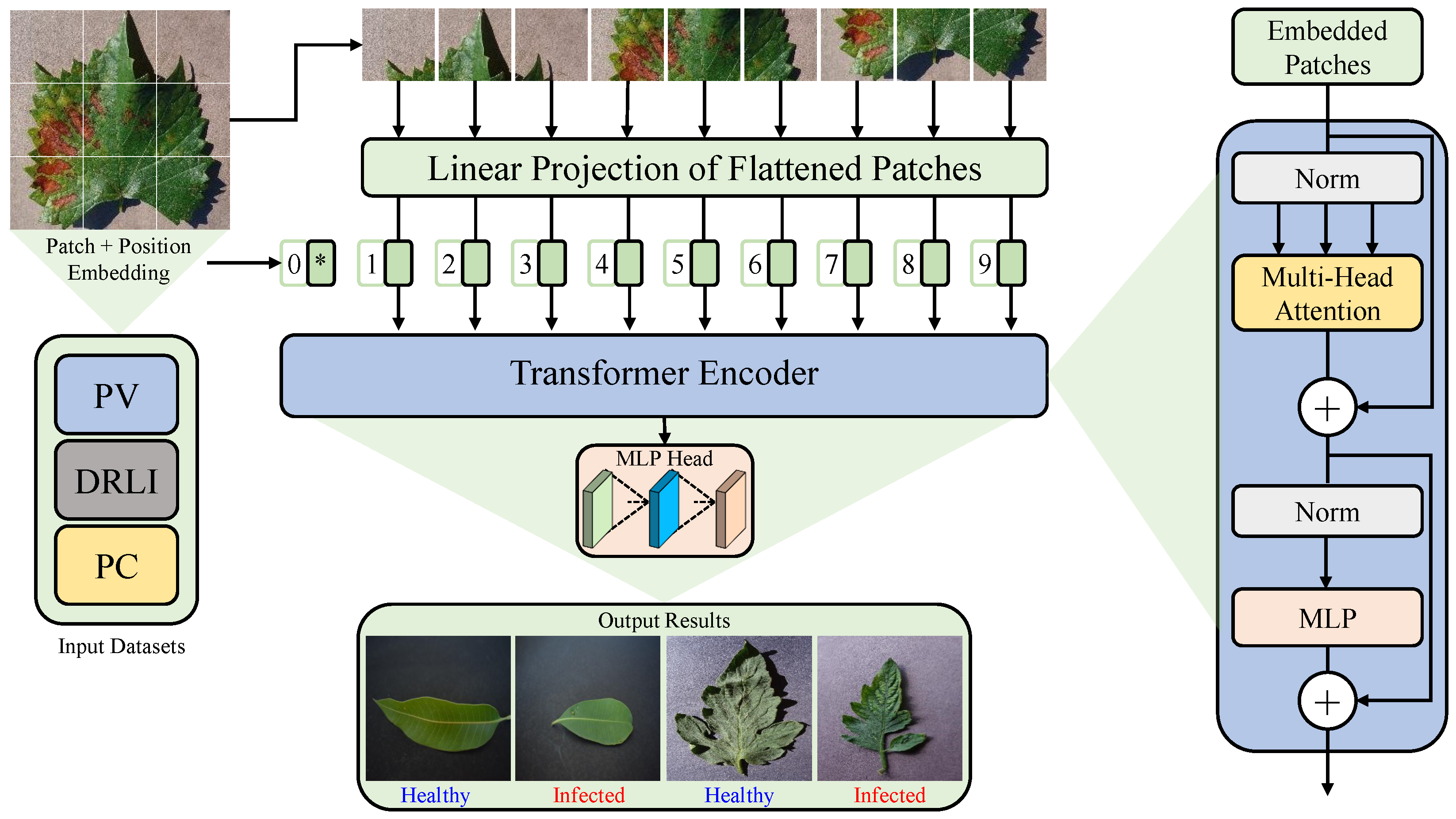
2.2. The Proposed GreenViT Plant Disease Detection Method
2.2.1. Embedding Layer
2.2.2. Encoding Layer
2.2.3. Classification Layer
3. Experimental Results
3.1. Evaluation Metrics
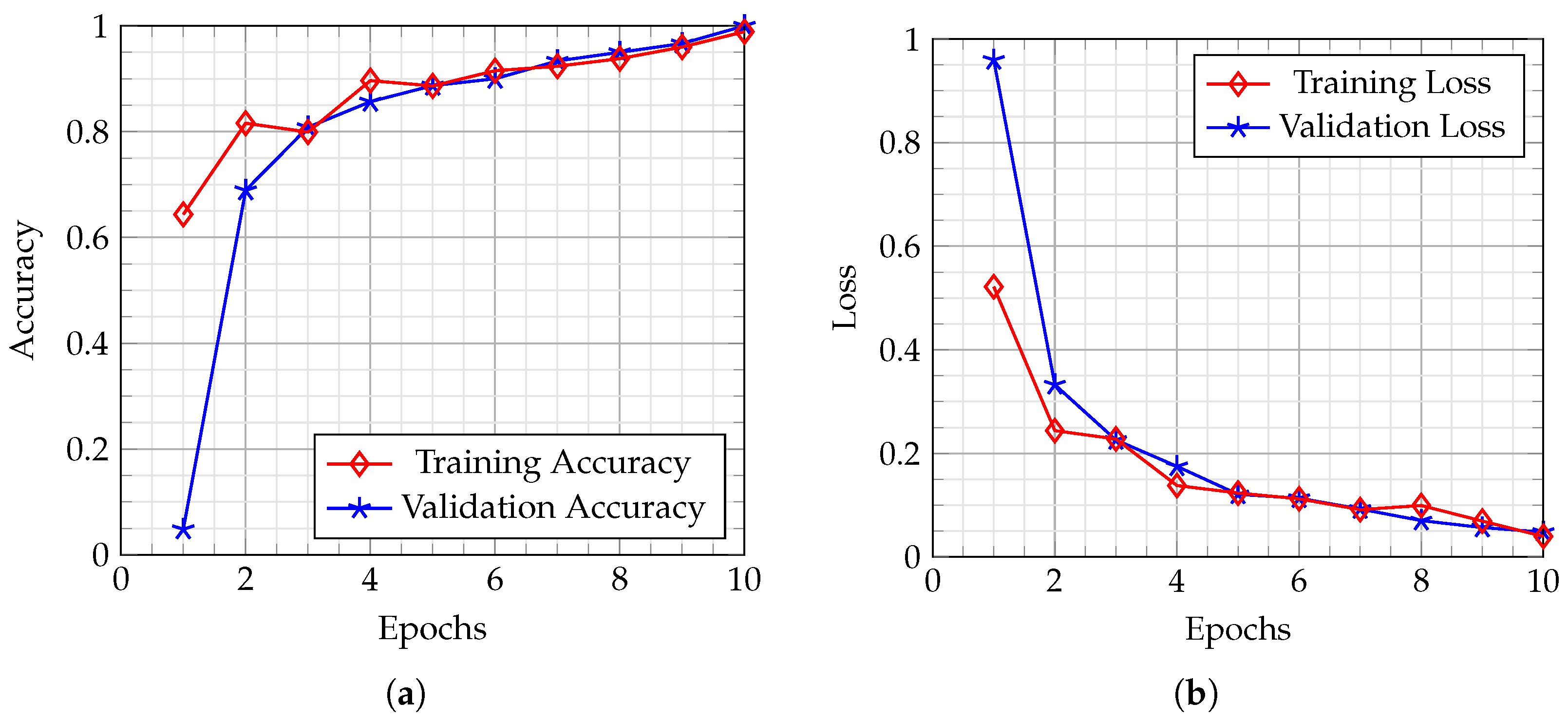
3.2. Quantitative Results
3.3. Qualitative Results
3.4. Time Complexity
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- World Bank. World Bank Survey. 2021. Available online: https://data.worldbank.org/indicator/SL.AGR.EMPL.ZS (accessed on 5 June 2023).
- World Food Clock. 2014. Available online: http://worldfoodclock.com/ (accessed on 5 June 2023).
- Thilagavathi, M.; Abirami, S. Application of image processing in diagnosing guava leaf diseases. Int. J. Sci. Res. Manag. 2017, 5, 5927–5933. [Google Scholar]
- Gavhale, K.R.; Gawande, U.; Hajari, K.O. Unhealthy region of citrus leaf detection using image processing techniques. In Proceedings of the International Conference for Convergence for Technology-2014, Pune, India, 6–8 April 2014; pp. 1–6. [Google Scholar]
- Padol, P.B.; Yadav, A.A. SVM classifier based grape leaf disease detection. In Proceedings of the 2016 Conference on Advances in Signal Processing (CASP), Pune, India, 9–11 June 2016; pp. 175–179. [Google Scholar]
- Masazhar, A.N.I.; Kamal, M.M. Digital image processing technique for palm oil leaf disease detection using multiclass SVM classifier. In Proceedings of the 2017 IEEE 4th International Conference on Smart Instrumentation, Measurement and Application (ICSIMA), Putrajaya, Malaysia, 28–30 November 2017; pp. 1–6. [Google Scholar]
- Islam, M.; Dinh, A.; Wahid, K.; Bhowmik, P. Detection of potato diseases using image segmentation and multiclass support vector machine. In Proceedings of the 2017 IEEE 30th Canadian Conference on Electrical and Computer Engineering (CCECE), Windsor, ON, Canada, 30 April–3 May 2017; pp. 1–4. [Google Scholar]
- Agrawal, N.; Singhai, J.; Agarwal, D.K. Grape leaf disease detection and classification using multi-class support vector machine. In Proceedings of the 2017 International Conference on Recent Innovations in Signal Processing and Embedded SYSTEMS (RISE), Bhopal, India, 27–29 October 2017; pp. 238–244. [Google Scholar]
- Parikh, A.; Raval, M.S.; Parmar, C.; Chaudhary, S. Disease detection and severity estimation in cotton plant from unconstrained images. In Proceedings of the 2016 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Montreal, QC, Canada, 17–19 October 2016; pp. 594–601. [Google Scholar]
- Suresha, M.; Shreekanth, K.; Thirumalesh, B. Recognition of diseases in paddy leaves using knn classifier. In Proceedings of the 2017 2nd International Conference for Convergence in Technology (I2CT), Mumbai, India, 7–9 April 2017; pp. 663–666. [Google Scholar]
- Vaishnnave, M.; Devi, K.S.; Srinivasan, P.; Jothi, G.A.P. Detection and classification of groundnut leaf diseases using KNN classifier. In Proceedings of the 2019 IEEE International Conference on System, Computation, Automation and Networking (ICSCAN), Pondicherry, India, 29–30 March 2019; pp. 1–5. [Google Scholar]
- Liu, H.; Lang, B. Machine learning and deep learning methods for intrusion detection systems: A survey. Appl. Sci. 2019, 9, 4396. [Google Scholar] [CrossRef]
- Mohanty, S.P.; Hughes, D.P.; Salathé, M. Using deep learning for image-based plant disease detection. Front. Plant Sci. 2016, 7, 1419. [Google Scholar] [CrossRef]
- Chouhan, S.S.; Singh, U.P.; Kaul, A.; Jain, S. A data repository of leaf images: Practice towards plant conservation with plant pathology. In Proceedings of the 2019 4th International Conference on Information Systems and Computer Networks (ISCON), Mathura, India, 21–22 November 2019; pp. 700–707. [Google Scholar]
- Dhaka, V.S.; Meena, S.V.; Rani, G.; Sinwar, D.; Ijaz, M.F.; Woźniak, M. A survey of deep convolutional neural networks applied for prediction of plant leaf diseases. Sensors 2021, 21, 4749. [Google Scholar] [CrossRef]
- Qiu, R.; Yang, C.; Moghimi, A.; Zhang, M.; Steffenson, B.J.; Hirsch, C.D. Detection of fusarium head blight in wheat using a deep neural network and color imaging. Remote Sens. 2019, 11, 2658. [Google Scholar] [CrossRef]
- Bi, C.; Wang, J.; Duan, Y.; Fu, B.; Kang, J.R.; Shi, Y. MobileNet based apple leaf diseases identification. Mob. Netw. Appl. 2022, 27, 172–180. [Google Scholar] [CrossRef]
- Lee, S.H.; Goëau, H.; Bonnet, P.; Joly, A. New perspectives on plant disease characterization based on deep learning. Comput. Electron. Agric. 2020, 170, 105220. [Google Scholar] [CrossRef]
- Kundu, N.; Rani, G.; Dhaka, V.S.; Gupta, K.; Nayak, S.C.; Verma, S.; Ijaz, M.F.; Woźniak, M. IoT and interpretable machine learning based framework for disease prediction in pearl millet. Sensors 2021, 21, 5386. [Google Scholar] [CrossRef] [PubMed]
- Rangarajan, A.K.; Purushothaman, R.; Ramesh, A. Tomato crop disease classification using pre-trained deep learning algorithm. Procedia Comput. Sci. 2018, 133, 1040–1047. [Google Scholar] [CrossRef]
- Amara, J.; Bouaziz, B.; Algergawy, A. A deep learning-based approach for banana leaf diseases classification. In Datenbanksysteme für Business, Technologie und Web (BTW 2017)-Workshopband, Proceedings of the Workshop Big (and Small) Data in Science and Humanities (BigDS17), Stuttgart, Germany, 6–10 March 2017; Gesellschaft für Informatik e.V.: Bonn, Germany, 2017. [Google Scholar]
- Barbedo, J.G.A. A review on the use of unmanned aerial vehicles and imaging sensors for monitoring and assessing plant stresses. Drones 2019, 3, 40. [Google Scholar] [CrossRef]
- Thai, H.T.; Tran-Van, N.Y.; Le, K.H. Artificial cognition for early leaf disease detection using vision transformers. In Proceedings of the 2021 International Conference on Advanced Technologies for Communications (ATC), Ho Chi Minh City, Vietnam, 14–16 October 2021; pp. 33–38. [Google Scholar]
- Hasan, M.; Tanawala, B.; Patel, K.J. Deep learning precision farming: Tomato leaf disease detection by transfer learning. In Proceedings of the 2nd International Conference on Advanced Computing and Software Engineering (ICACSE), Sultanpur, India, 8–9 February 2019. [Google Scholar]
- Latif, G.; Alghazo, J.; Maheswar, R.; Vijayakumar, V.; Butt, M. Deep learning based intelligence cognitive vision drone for automatic plant diseases identification and spraying. J. Intell. Fuzzy Syst. 2020, 39, 8103–8114. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Gong, C.; Wang, D.; Li, M.; Chandra, V.; Liu, Q. Vision transformers with patch diversification. arXiv 2021, arXiv:2104.12753. [Google Scholar]
- Lu, X.; Yang, R.; Zhou, J.; Jiao, J.; Liu, F.; Liu, Y.; Su, B.; Gu, P. A hybrid model of ghost-convolution enlightened transformer for effective diagnosis of grape leaf disease and pest. J. King Saud Univ.—Comput. Inf. Sci. 2022, 34, 1755–1767. [Google Scholar] [CrossRef]
- Thakur, P.S.; Khanna, P.; Sheorey, T.; Ojha, A. Explainable vision transformer enabled convolutional neural network for plant disease identification: PlantXViT. arXiv 2022, arXiv:2207.07919. [Google Scholar]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. Cvt: Introducing convolutions to vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Online, 11–17 October 2021; pp. 22–31. [Google Scholar]
- Yuan, K.; Guo, S.; Liu, Z.; Zhou, A.; Yu, F.; Wu, W. Incorporating convolution designs into visual transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Online, 11–17 October 2021; pp. 579–588. [Google Scholar]
- Li, Y.; Zhang, K.; Cao, J.; Timofte, R.; Van Gool, L. Localvit: Bringing locality to vision transformers. arXiv 2021, arXiv:2104.05707. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Online, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Wang, P.; Wang, X.; Wang, F.; Lin, M.; Chang, S.; Li, H.; Jin, R. Kvt: K-nn attention for boosting vision transformers. In Computer Vision—ECCV 2022, Proceedings of the 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Part XXIV; Springer: Cham, Switzerland, 2022; pp. 285–302. [Google Scholar]
- Child, R.; Gray, S.; Radford, A.; Sutskever, I. Generating long sequences with sparse transformers. arXiv 2019, arXiv:1904.10509. [Google Scholar]
- Ali, A.; Touvron, H.; Caron, M.; Bojanowski, P.; Douze, M.; Joulin, A.; Laptev, I.; Neverova, N.; Synnaeve, G.; Verbeek, J.; et al. Xcit: Cross-covariance image transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 20014–20027. [Google Scholar]
- Chu, X.; Tian, Z.; Wang, Y.; Zhang, B.; Ren, H.; Wei, X.; Xia, H.; Shen, C. Twins: Revisiting the design of spatial attention in vision transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 9355–9366. [Google Scholar]
- Dilshad, N.; Ullah, A.; Kim, J.; Seo, J. LocateUAV: Unmanned Aerial Vehicle Location Estimation via Contextual Analysis in an IoT Environment. IEEE Internet Things J. 2023, 10, 4021–4033. [Google Scholar] [CrossRef]
- Parez, S.; Dilshad, N.; Alanazi, T.M.; Lee, J.-W. Towards Sustainable Agricultural Systems: A Lightweight Deep Learning Model for Plant Disease Detection. Comput. Syst. Sci. Eng. 2023, 47, 515–536. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 6105–6114. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Dilshad, N.; Khan, T.; Song, J. Efficient Deep Learning Framework for Fire Detection in Complex Surveillance Environment. Comput. Syst. Sci. Eng. 2023, 46, 749–764. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S. No. | Dataset | Training | Testing | Validation | Total Images |
|---|---|---|---|---|---|
| 1 | PlantVillage [13] | 39,100 | 10,861 | 4344 | 54,305 |
| 2 | Data Repository of Leaf Images [14] | 3241 | 901 | 360 | 4502 |
| 3 | Plant Composite [39] | 42,341 | 11,762 | 4704 | 58,807 |
| Model | No. of Layers | Hidden Size (D) | Heads | Parameters (M) |
|---|---|---|---|---|
| ViT Base | 12 | 768 | 12 | 86 |
| ViT Large | 24 | 1024 | 16 | 307 |
| ViT Huge | 32 | 1280 | 16 | 632 |
| GreenViT | 8 | 768 | 4 | 21.65 |
| Model | Class | PV | DRLI | PC | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | ACC ↑ | P | R | F1 | ACC ↑ | P | R | F1 | ACC ↑ | ||
| VGG19 [41] | Healthy | 1.00 | 0.95 | 0.98 | 0.99 | 0.96 | 0.97 | 0.97 | 0.97 | 0.99 | 0.96 | 0.97 | 0.98 |
| Infected | 0.98 | 1.00 | 0.99 | 0.97 | 0.96 | 0.96 | 0.98 | 1.00 | 0.99 | ||||
| VGG16 [41] | Healthy | 0.99 | 0.99 | 0.99 | 1.00 | 0.98 | 0.94 | 0.96 | 0.96 | 0.99 | 0.99 | 0.99 | 0.99 |
| Infected | 1.00 | 1.00 | 1.00 | 0.93 | 0.98 | 0.96 | 0.98 | 1.00 | 1.00 | ||||
| EfficientNetB0 [42] | Healthy | 1.00 | 1.00 | 1.00 | 1.00 | 0.99 | 0.83 | 0.90 | 0.89 | 1.00 | 0.97 | 0.98 | 0.99 |
| Infected | 1.00 | 1.00 | 1.00 | 0.78 | 0.98 | 0.87 | 0.99 | 1.00 | 0.99 | ||||
| MobileNetV1 [43] | Healthy | 1.00 | 0.99 | 0.99 | 1.00 | 0.97 | 0.96 | 0.97 | 0.97 | 0.99 | 0.99 | 0.99 | 0.99 |
| Infected | 1.00 | 1.00 | 1.00 | 0.96 | 0.97 | 0.96 | 1.00 | 1.00 | 1.00 | ||||
| MobileNetV3Small [44] | Healthy | 1.00 | 1.00 | 1.00 | 1.00 | 0.93 | 0.99 | 0.96 | 0.96 | 1.00 | 0.99 | 0.99 | 0.99 |
| Infected | 1.00 | 1.00 | 1.00 | 0.99 | 0.93 | 0.95 | 0.99 | 1.00 | 1.00 | ||||
| ViT Base [26] | Healthy | 0.92 | 0.98 | 0.95 | 0.95 | 0.81 | 0.62 | 0.70 | 0.75 | 0.87 | 0.95 | 0.91 | 0.94 |
| Infected | 0.98 | 0.92 | 0.95 | 0.71 | 0.86 | 0.78 | 0.98 | 0.94 | 0.96 | ||||
| GreenViT | Healthy | 1.00 | 1.00 | 0.99 | 1.00 | 0.97 | 0.95 | 0.96 | 0.98 | 0.98 | 1.00 | 0.99 | 0.99 |
| Infected | 0.99 | 1.00 | 1.00 | 0.98 | 0.99 | 0.98 | 0.99 | 0.98 | 0.99 | ||||
| Fold | Dataset | ||
|---|---|---|---|
| PV | DRLI | PC | |
| 1 | 0.9836 | 0.9314 | 0.9540 |
| 2 | 0.9749 | 0.9425 | 0.9377 |
| 3 | 0.9723 | 0.9425 | 0.9471 |
| 4 | 0.9611 | 0.9623 | 0.9632 |
| 5 | 0.9839 | 0.9447 | 0.9680 |
| Average Test Accuracy | 0.9752 | 0.9446 | 0.9540 |
| Fold | Dataset | ||
|---|---|---|---|
| PV | DRLI | PC | |
| 1 | 0.9837 | 0.9647 | 0.9665 |
| 2 | 0.9543 | 0.9736 | 0.9603 |
| 3 | 0.9795 | 0.9713 | 0.9401 |
| 4 | 0.9681 | 0.9802 | 0.9540 |
| 5 | 0.9696 | 0.8450 | 0.9552 |
| 6 | 0.9812 | 0.9669 | 0.9620 |
| 7 | 0.9791 | 0.9425 | 0.9590 |
| 8 | 0.9828 | 0.9669 | 0.9580 |
| 9 | 0.9716 | 0.9337 | 0.9666 |
| 10 | 0.9698 | 0.9004 | 0.9574 |
| Average Test Accuracy | 0.9740 | 0.9445 | 0.9579 |
| Model | Parameters (M) ↓ | Size (MB) ↓ | FPS ↑ | |
|---|---|---|---|---|
| RPi 4B+ | CPU | |||
| VGG19 | 200.25 | 229.0 | 0.47 | 9.49 |
| VGG16 | 147.15 | 168.0 | 0.62 | 11.09 |
| EfficientNetB0 | 4.05 | 46.9 | 2.69 | 19.74 |
| MobileNetV1 | 3.23 | 37.1 | 8.23 | 22.96 |
| MobileNetV3Small | 1.53 | 18.0 | 7.43 | 27.94 |
| Vit Base | 86.00 | 345.0 | 0.21 | 19.83 |
| GreenViT | 21.65 | 247.0 | 0.34 | 22.19 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Parez, S.; Dilshad, N.; Alghamdi, N.S.; Alanazi, T.M.; Lee, J.W. Visual Intelligence in Precision Agriculture: Exploring Plant Disease Detection via Efficient Vision Transformers. Sensors 2023, 23, 6949. https://doi.org/10.3390/s23156949
Parez S, Dilshad N, Alghamdi NS, Alanazi TM, Lee JW. Visual Intelligence in Precision Agriculture: Exploring Plant Disease Detection via Efficient Vision Transformers. Sensors. 2023; 23(15):6949. https://doi.org/10.3390/s23156949
Chicago/Turabian StyleParez, Sana, Naqqash Dilshad, Norah Saleh Alghamdi, Turki M. Alanazi, and Jong Weon Lee. 2023. "Visual Intelligence in Precision Agriculture: Exploring Plant Disease Detection via Efficient Vision Transformers" Sensors 23, no. 15: 6949. https://doi.org/10.3390/s23156949
APA StyleParez, S., Dilshad, N., Alghamdi, N. S., Alanazi, T. M., & Lee, J. W. (2023). Visual Intelligence in Precision Agriculture: Exploring Plant Disease Detection via Efficient Vision Transformers. Sensors, 23(15), 6949. https://doi.org/10.3390/s23156949