1. Introduction
As one of the most important components of intelligent manufacturing equipment, the health status of rotating machinery may affect the overall operation status of the equipment. For instance, the faults of bearings are prone to reducing the processing quality of the workpiece, and even result in considerable economic losses and potential safety hazards. Each fault of rotating machinery will eventually be embodied in the external excitation caused by mechanical structure defects, which produces mechanical vibration signals which differ from the healthy state. Due to the exceptional performance in solving the nonlinear feature extraction for machine vibration data, deep learning has witnessed remarkable success in the field of rotating machinery fault diagnosis [
1]. In practical engineering, however, the lack of labeled data and the variable working conditions will restrict the profound study of prognostic and health management for rotating machinery [
2].
Recent advances in supervised learning methods have been widely employed to overcome the challenge of variable working conditions. Xing et al. [
3] proposed a distribution-invariant deep belief network (DBN) to learn distribution-invariant features by a locally connected structure. Zhao et al. [
4] converted the one-dimensional signal to a three-dimensional image and applied a multiscale inverted residual convolution neural network (CNN) to learn different representations of variable load bearings. The gate units of a long short-term memory (LSTM) network were also utilized to store and transfer the classification information [
5], and thus the working condition information could be ignored while the health condition was emphasized. The attention mechanism [
6,
7] combined with transfer learning enabled the model to retain invariant fault representation related to the faults during the training process. Although the aforementioned methods show superiority and outstanding stability in dealing with the inconsistent distributions within data under variable working conditions, these implementations have limitations in practical industrial scenarios. Ordinarily, the training of a decision-making model is based on the assumption of abundant labeled data, but it is unrealistic to label massive data in industrial applications.
Researchers have mainly made great efforts to alleviate the problem of insufficient labeled data from these three aspects: the feature learning-based strategy, the algorithm structure-based strategy and the data augmentation-based strategy [
8]. From the perspective of the feature learning-based strategy, feature transfer based on transfer learning attained satisfactory diagnostic results. He et al. [
9] designed a deep multi-wavelet autoencoder to select high-quality auxiliary samples for parameter knowledge transfer. Li et al. [
10] constructed a multi-layer CNN to extract transferable features from the limited labeled data of the source domain and reduced the discrepancy of the marginal and the conditional probability distribution for limited labeled tasks. From the perspective of data resources, feature transfer based on transfer learning cannot encompass the entire fault dataset and mine useful information of unlabeled data, which causes a certain waste of the available information resources.
Taking the considerable fault information of unlabeled data into account, which is the most inexpensive data available in industrial scenarios, designing a semi-supervised algorithm structure appears to be a viable solution to address the issue above. The graph-based semi-supervised learning method [
11,
12,
13] constructed a graph structure by regarding samples as vertices and regarding the similarity between points as edges, and thus the attribution of labeled samples could be propagated to unlabeled samples due to the hierarchy structure. To fully use the more abundant unlabeled data, Wu et al. [
14] designed a hybrid classification autoencoder as a one-input two-output configuration consisting of the reconstruction of the input and the prediction of the health condition. Analogously, encoder–decoder network architectures based on CNNs [
15] and LSTM [
16] are established to distinguish the abnormal regime from the normal operating regimes by the magnitude of the reconstruction loss. As is common practice, a skipped connection was introduced in the encoder–decoder architectures, which was known as a vanilla ladder network (LAN) [
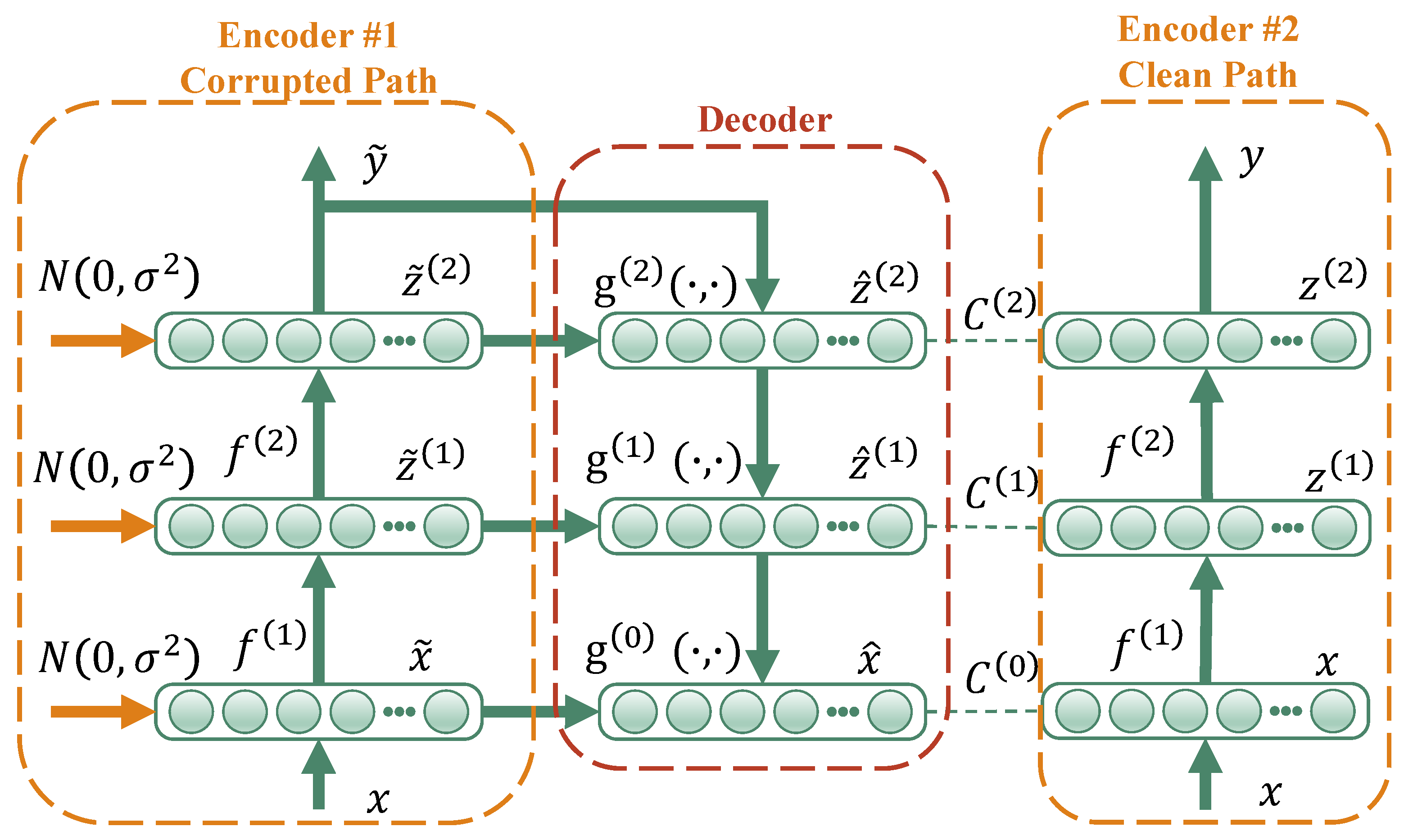
17]. The vanilla LAN constantly varied in the backbone based on a typical deep learning algorithm to obtain higher training efficiency [
15,
18]. Zhang et al. [
19] established two independent variational autoencoder (VAE)-based deep generative models to obtain the low-dimension latent features for labeled and unlabeled data, respectively. Accordingly, the multi-channel structure enabled the semi-supervised network to learn the fault representation of both labeled and unlabeled data.
Regarding aspects of the data augmentation-based strategy, some researchers attempt to extract more sensitive fault features based on signal processing. Zhang et al. [
20] input the time-frequency wavelet coefficients into a multiple association layers network combining LAN and a variational autoencoder with less-labeled samples. Roozbeh et al. [
21] fused the information of the raw sensory measurements in three different domains, and Yu et al. [
22] employed seven data augmentation strategies. However, the tremendous data preprocessing procedure ignores the end-to-end feature extraction ability of deep learning. Furthermore, to alleviate the limited labeled problem, generating data with the same distribution of labeled data is regarded as an intuitive solution [
8]. Ding et al. [
23] utilized the probabilistic mixture model and the Markov Chain Monte Carlo algorithm to expand the fault dataset, which could provide large amounts of fake data. Tao et al. [
24] generated pseudo-cluster labels for labeled and unlabeled data by adopting density peak clustering strategies. In addition, deep generative models were often utilized to generate new samples for labeled minority fault samples, such as GAN [
25,
26,
27,
28] and VAE [
29,
30]. Difficulties arise, however, when the quality of generated samples should be ensured to implement the data augmentation-based strategies.
Taken together, the research described above has the following shortcomings when facing the lack of labeled data and the variable working conditions:
These two challenges are usually overcome individually, and few works in the literature have studied these two issues simultaneously.
Closer attention is paid to expanding labeled data for supervised learning, while considerable fault information contained in unlabeled data is ignored and wasted.
More than ten labeled training samples are chiefly required; however, the available labeled samples are fewer in real industrial scenarios.
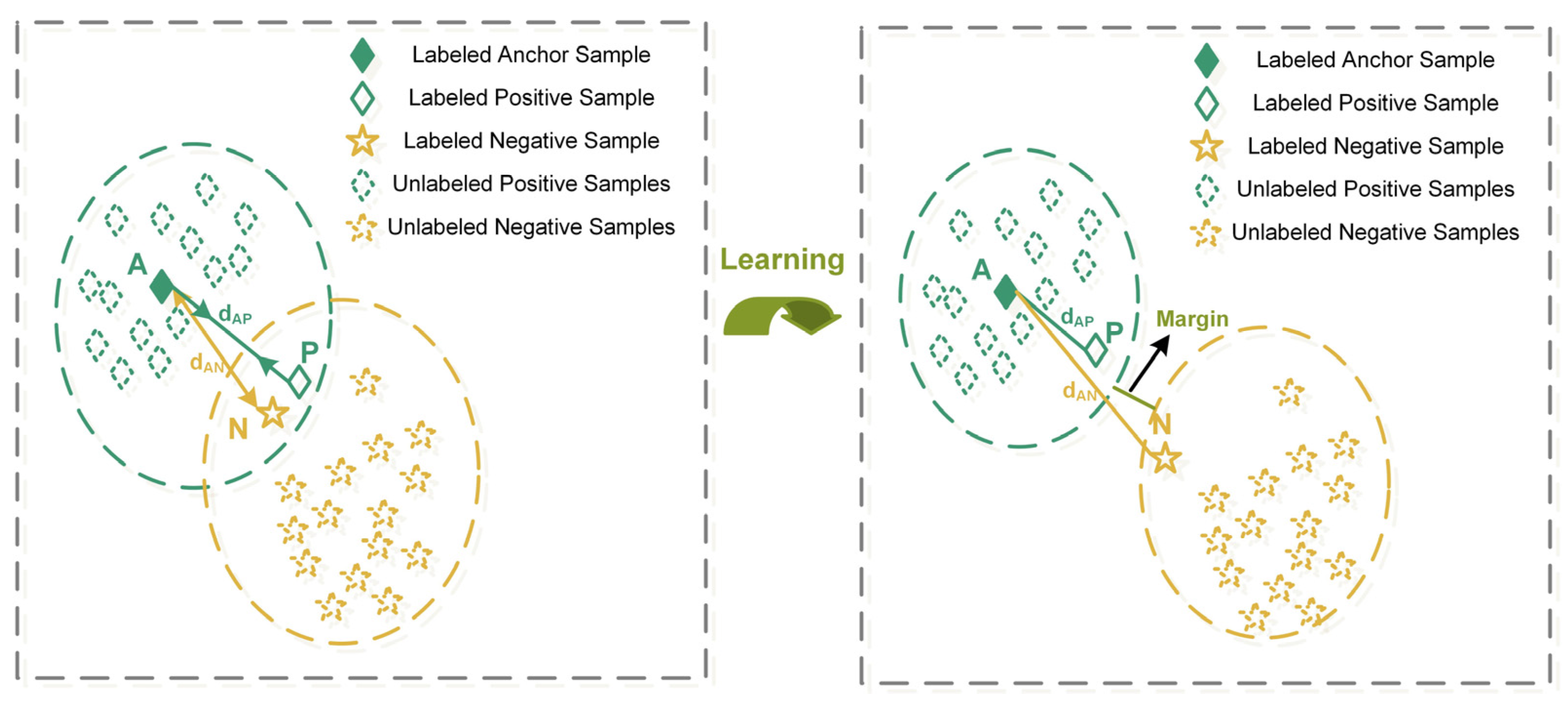
Recent advances in face recognition are attributed to the rise of metric learning. Unlike generative networks, which need to pay attention to each detail of the labeled data distribution, metric learning shows its promising potential to learn discriminative embeddings that can distinguish from other samples. Typically, contrastive loss [
31] and triplet loss [
32] could group intra-class samples closely while pushing inter-class samples distantly in the embedding space of pairwise samples. The contrastive loss could be introduced as a regularization [
33,
34,
35] to learn working condition-independent features. Rombach et al. [
36] considered triplets of training samples and learned invariance representation in the context of changing operations. Customarily, the hard example mining strategy [
37,
38] is often integrated with triplet loss to enhance the representation learning ability for the later network training stage. As a result, it provides the possibility of mining limited labeled data, which lays emphasis on the similarity among pairwise samples in the embedding space, and is able to learn fault-related rather than working condition-related representation.
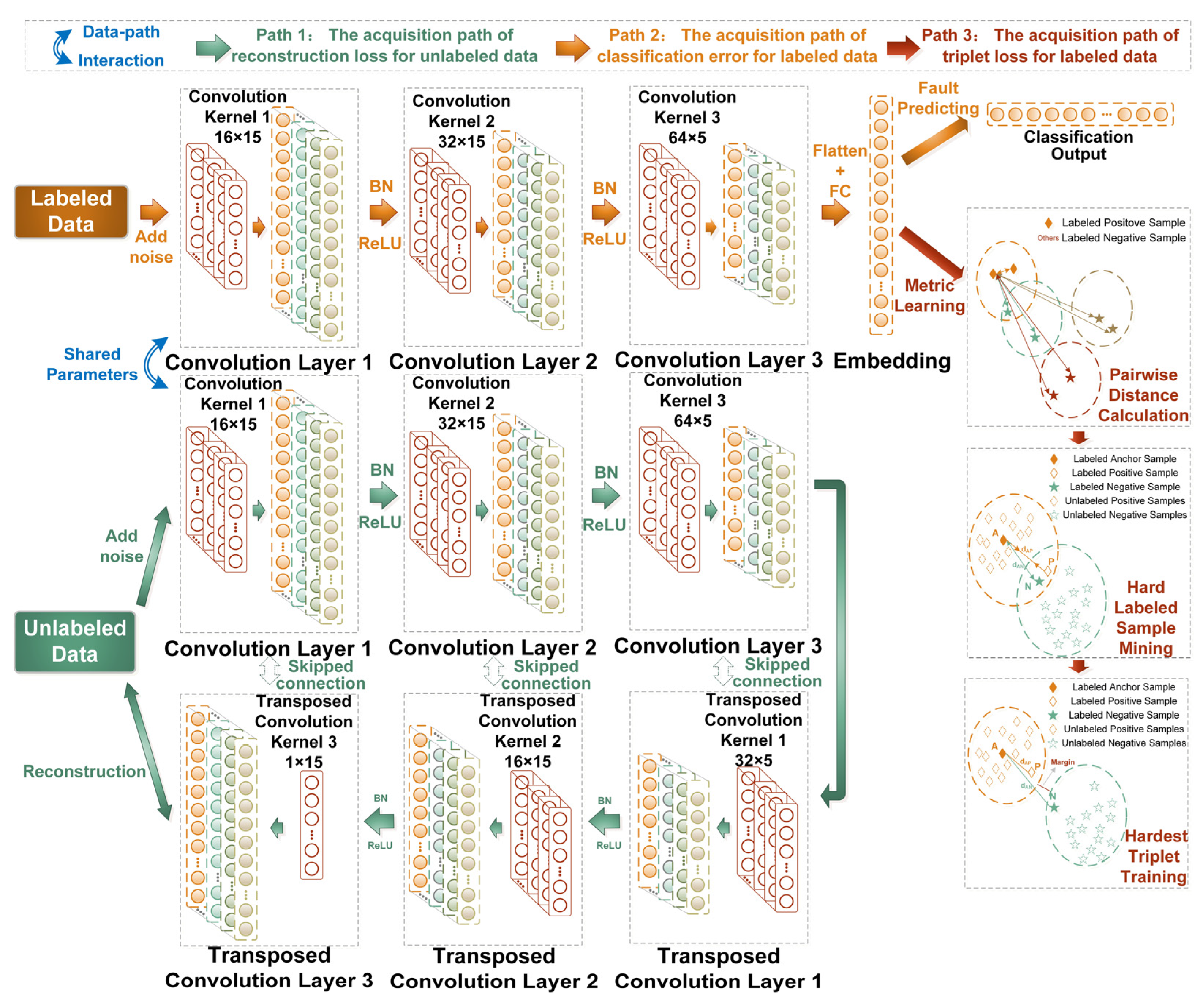
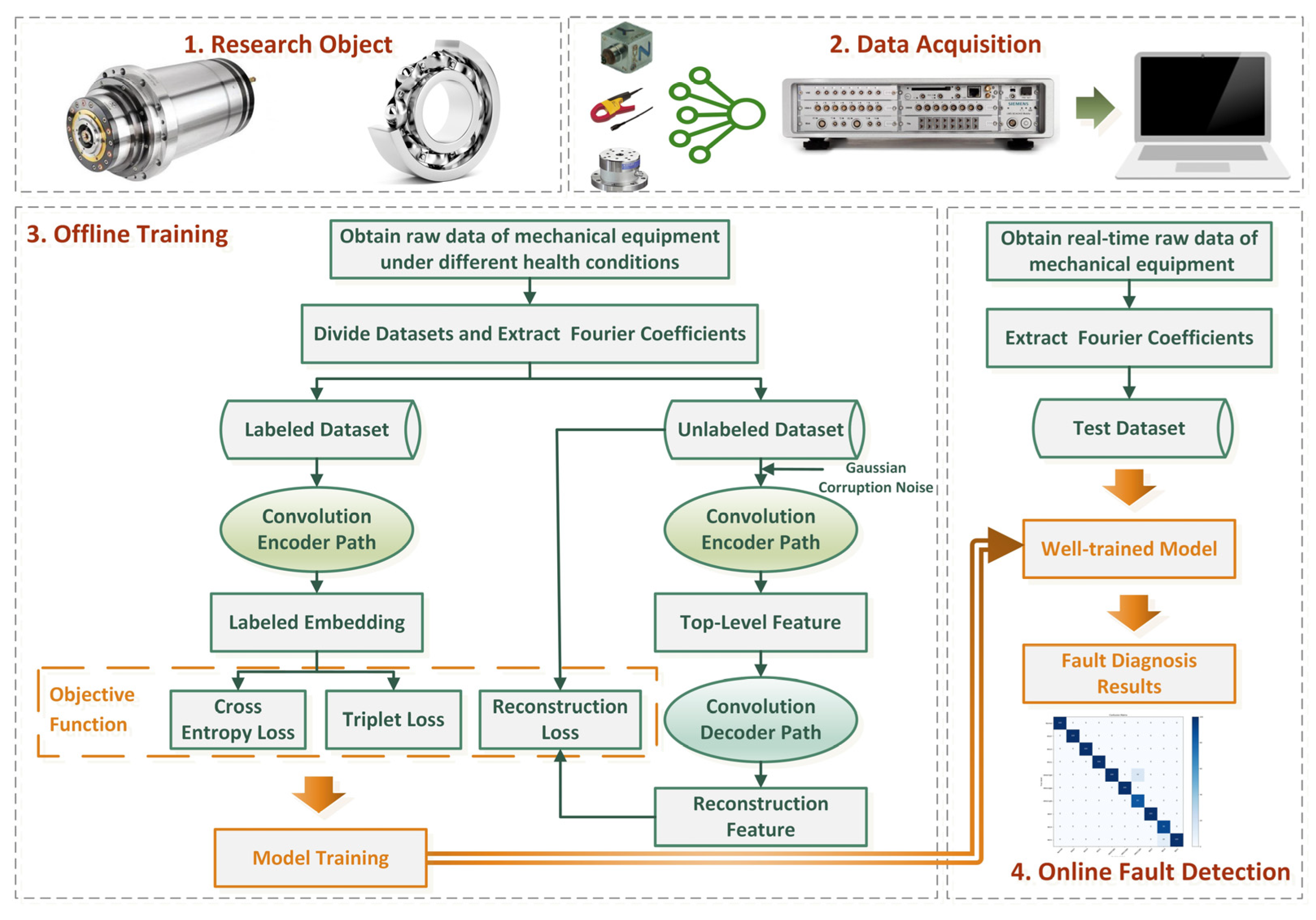
Given the shortcomings of the above methods and enlightened by metric learning, both algorithm structure-level and feature-level aspects are considered in this paper. In terms of the algorithm’s structure-level, a CNN-based ladder network (CLAN) with path interaction is established to extract features from the most readily available unlabeled data and the limited labeled data. From the aspects of the feature-level, the similarity among anchor, positive and negative samples are calculated in the embedding space based on metric learning, in which extremely limited labeled samples can be regarded as hard samples to mine fault-related information and eliminate the working condition shifting effect. Therefore, the acquired classification error, reconstruction error and triplet loss are jointly defined as the objective function for the proposed method. The main contributions of this study, as well as the acquisition of the objective function, are listed as follows:
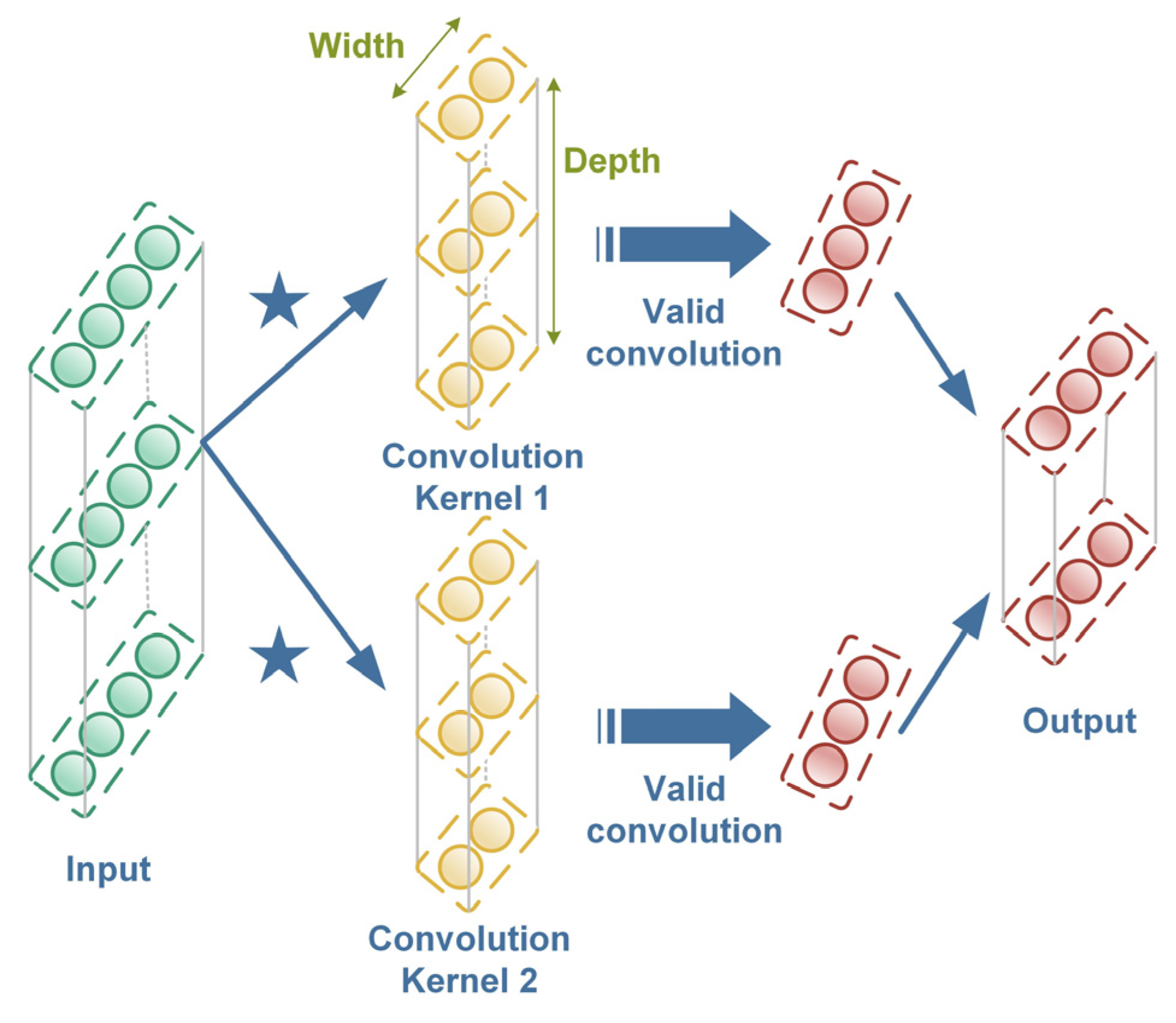
CLAN, a novel CNN-based ladder network, replaces the vanilla ladder network (LAN) backbone with a CNN and integrates the structure of the vanilla ladder network. Thus, the classification error of labeled samples and the reconstruction error of unlabeled samples can be obtained, and the parameters of the training process can be reduced by a simplified combination activation function and a path-interaction strategy.
To further alleviate the feature distribution shifting problem under variable working conditions, the triplet loss with the hard sample mining strategy is utilized to enlarge the margin among the embeddings of the limited labeled samples under different working conditions, which enables the proposed method to emphasize the fault-related features.
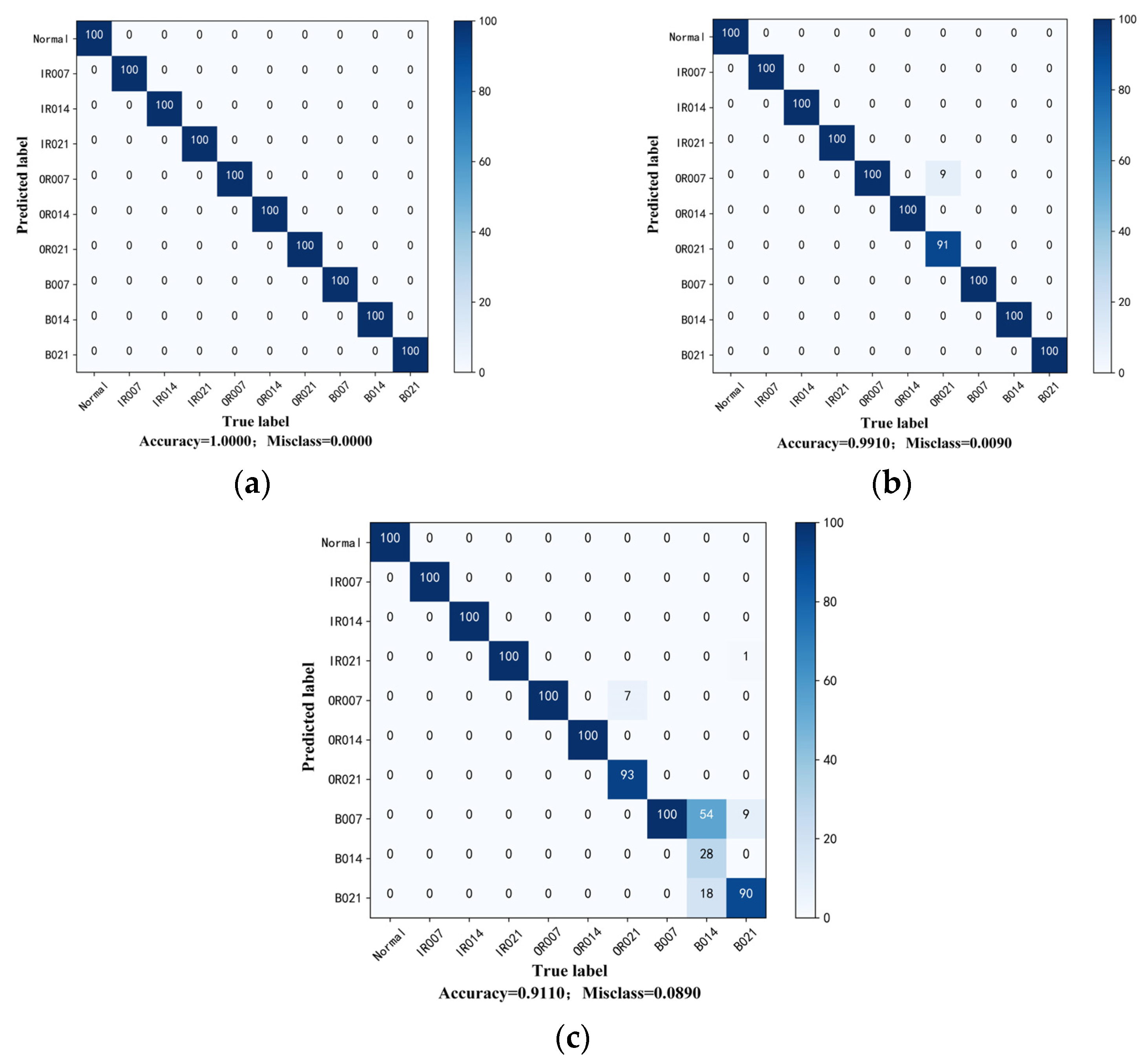
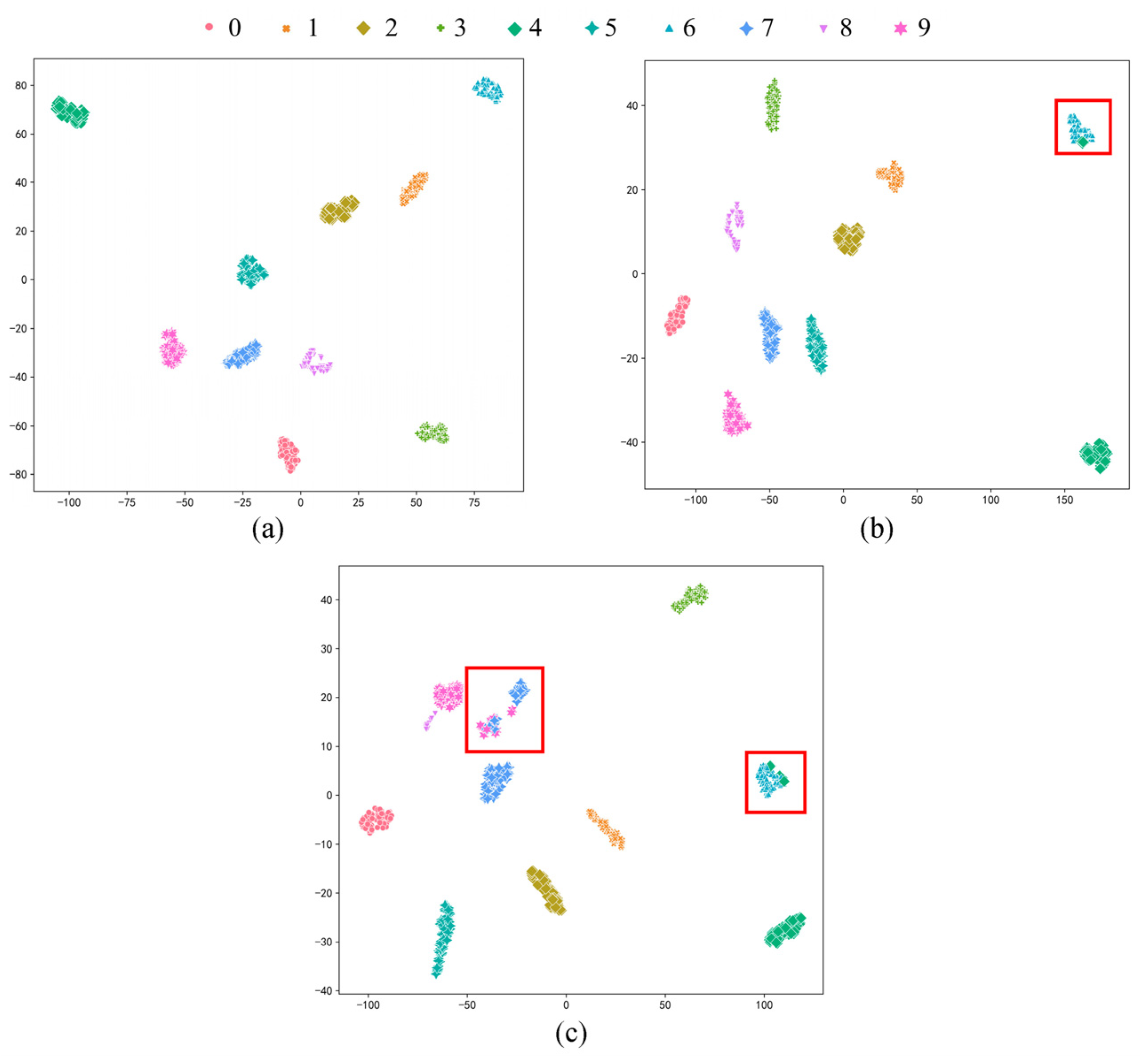
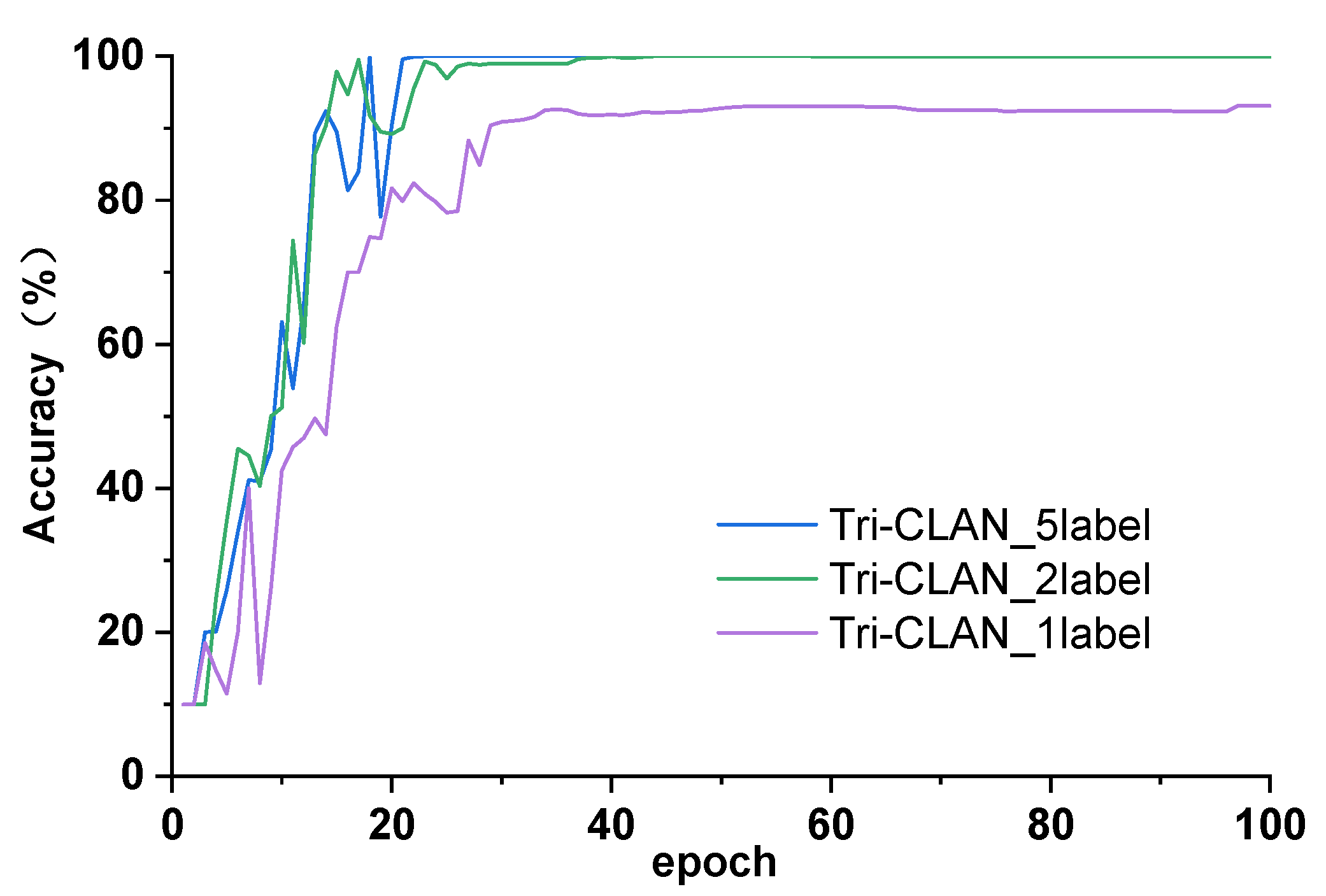
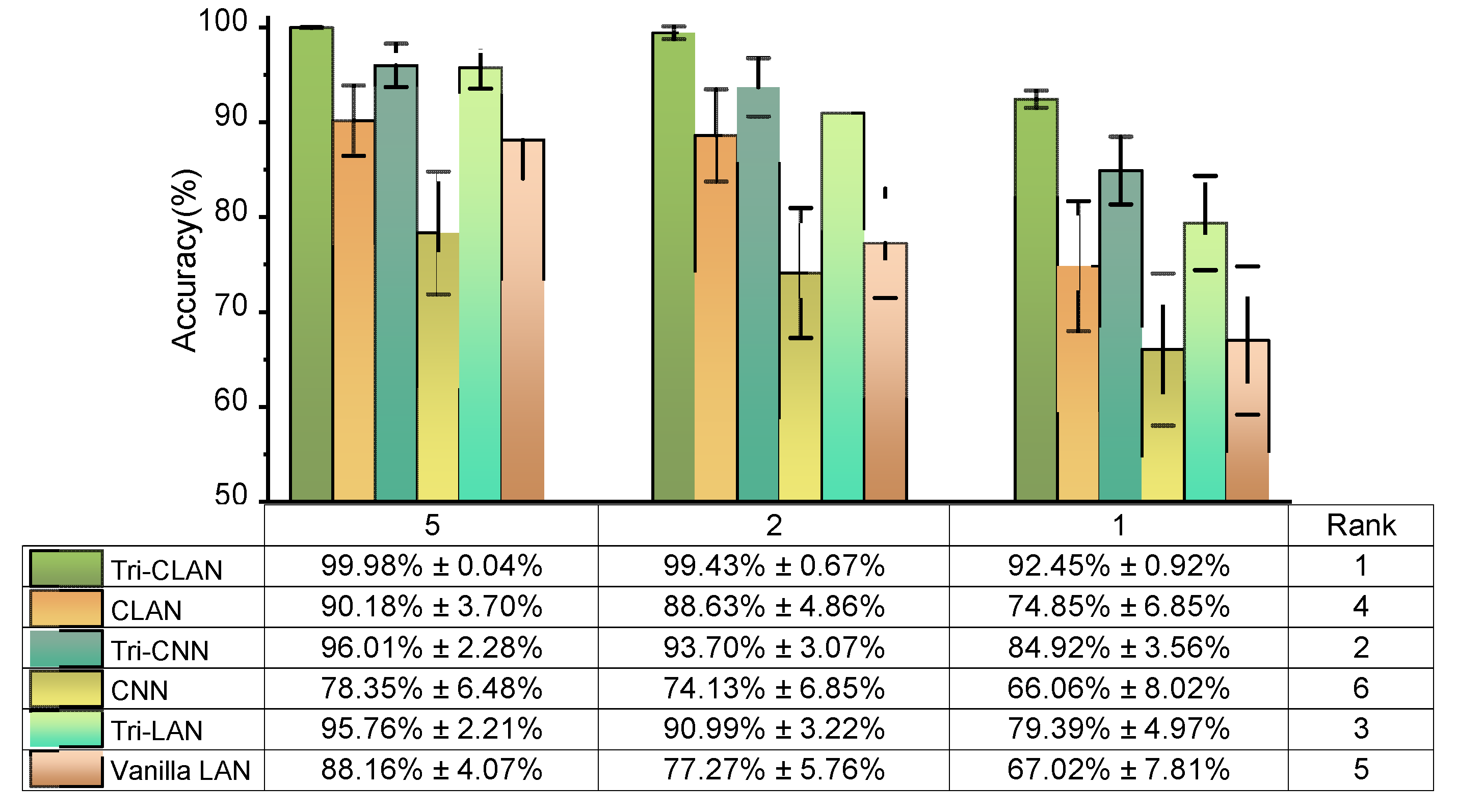
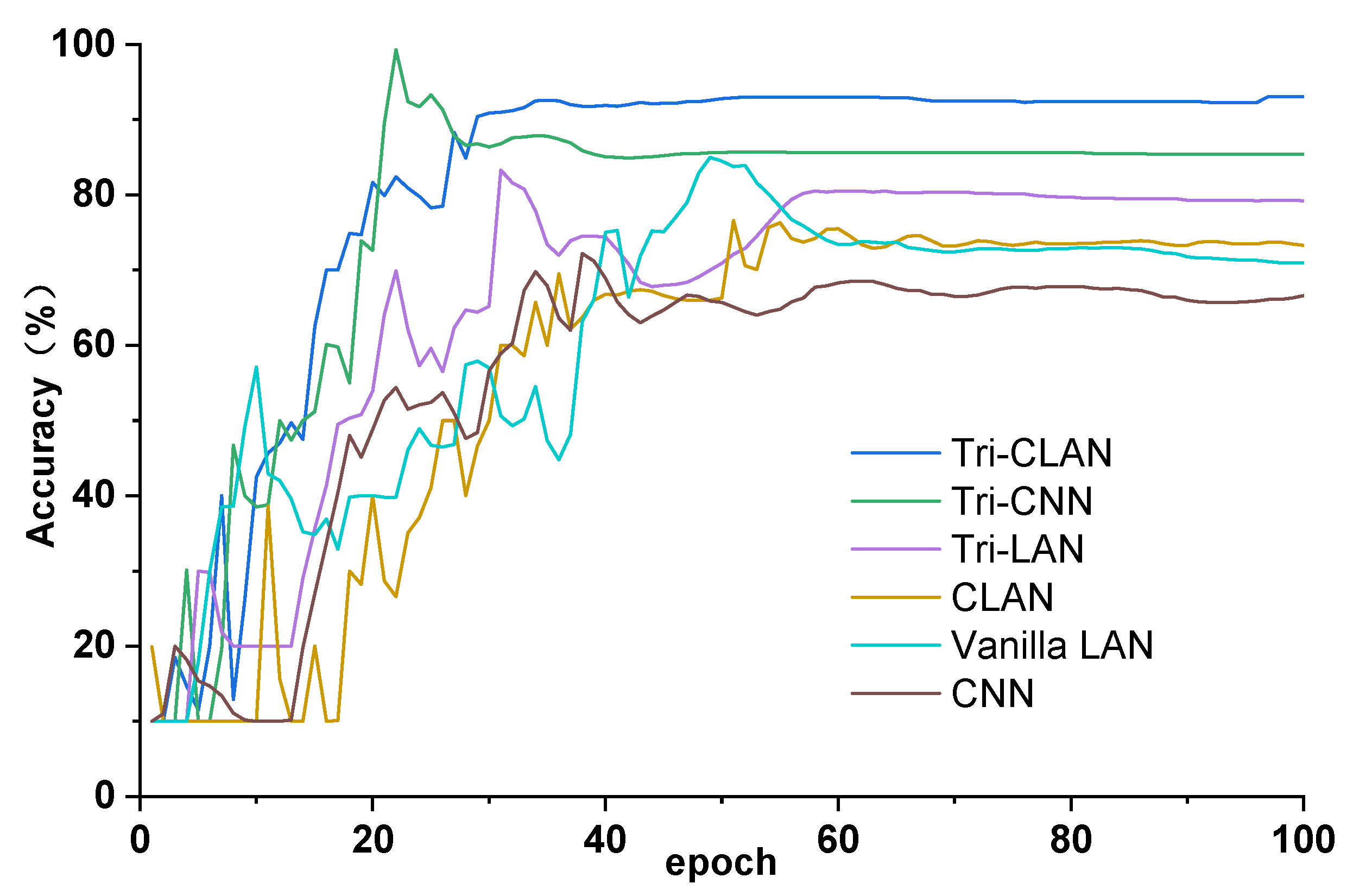
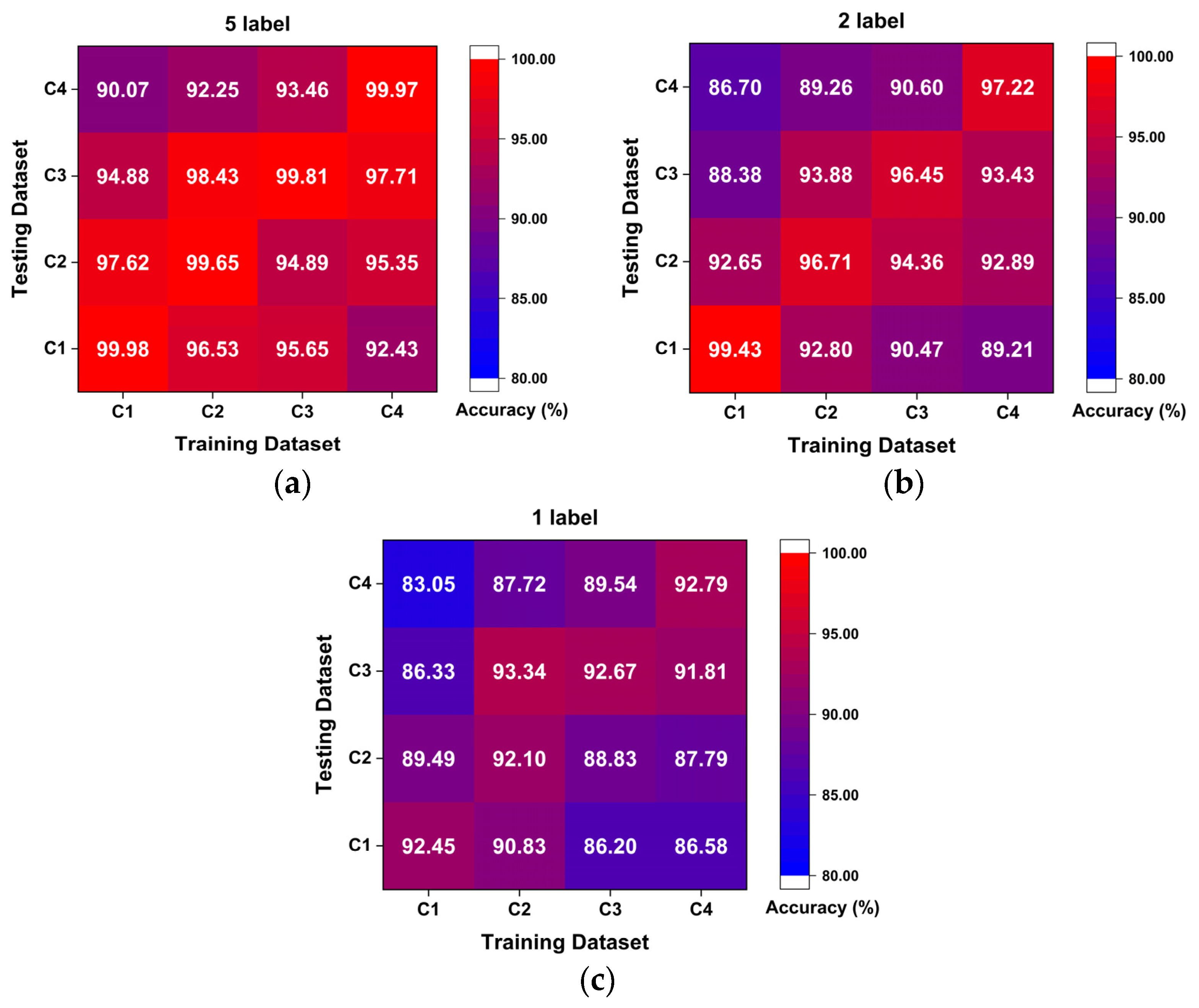
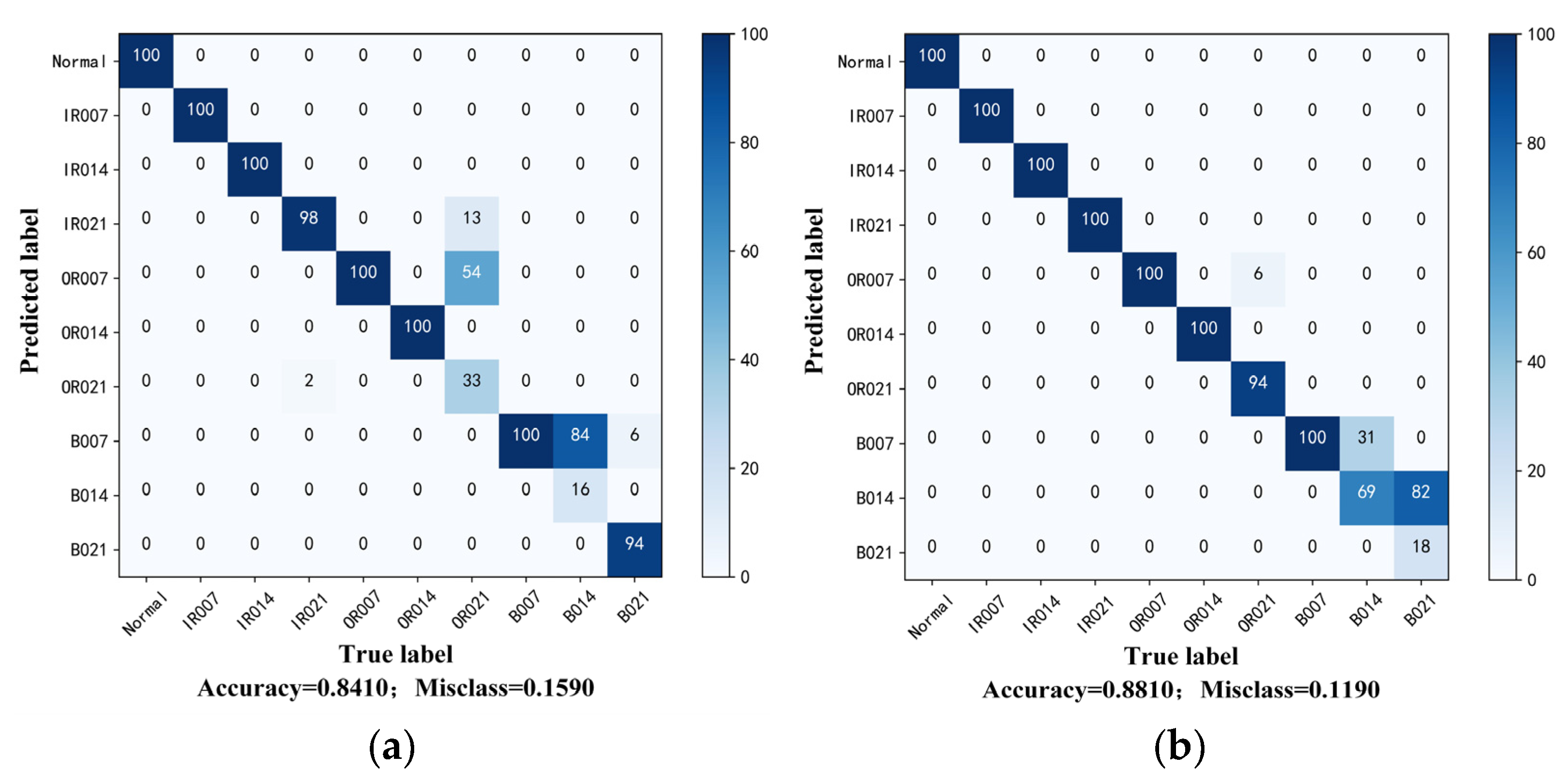
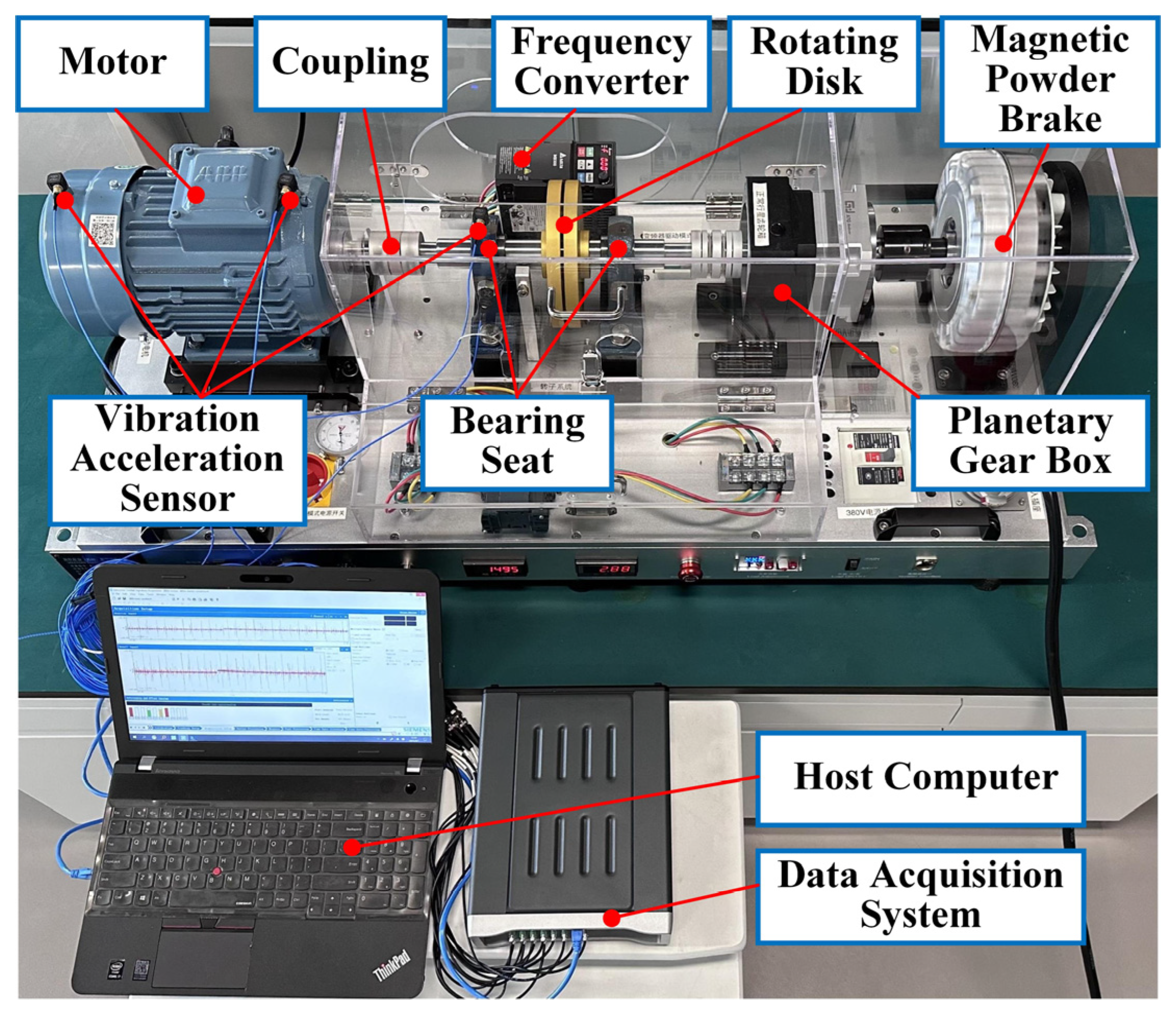
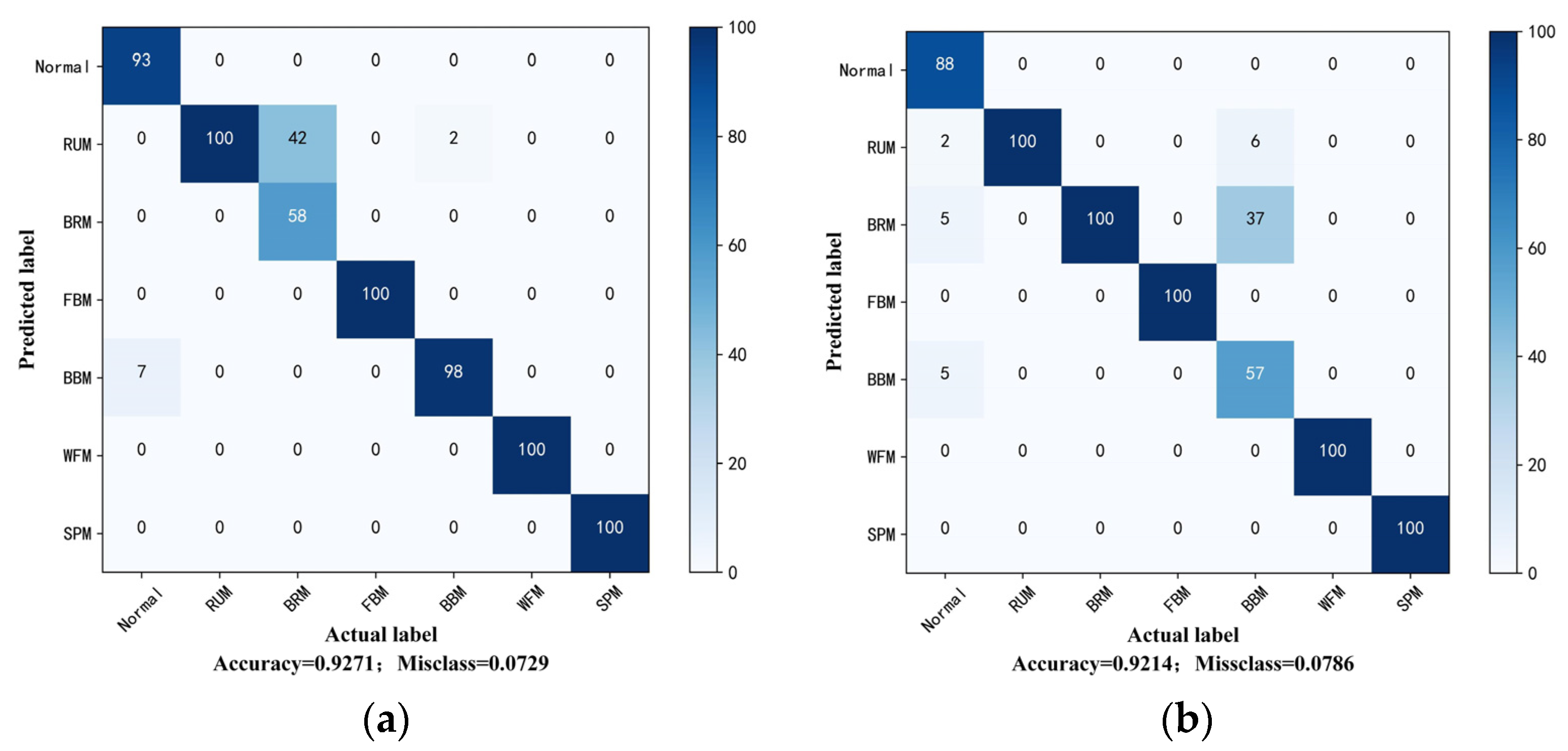
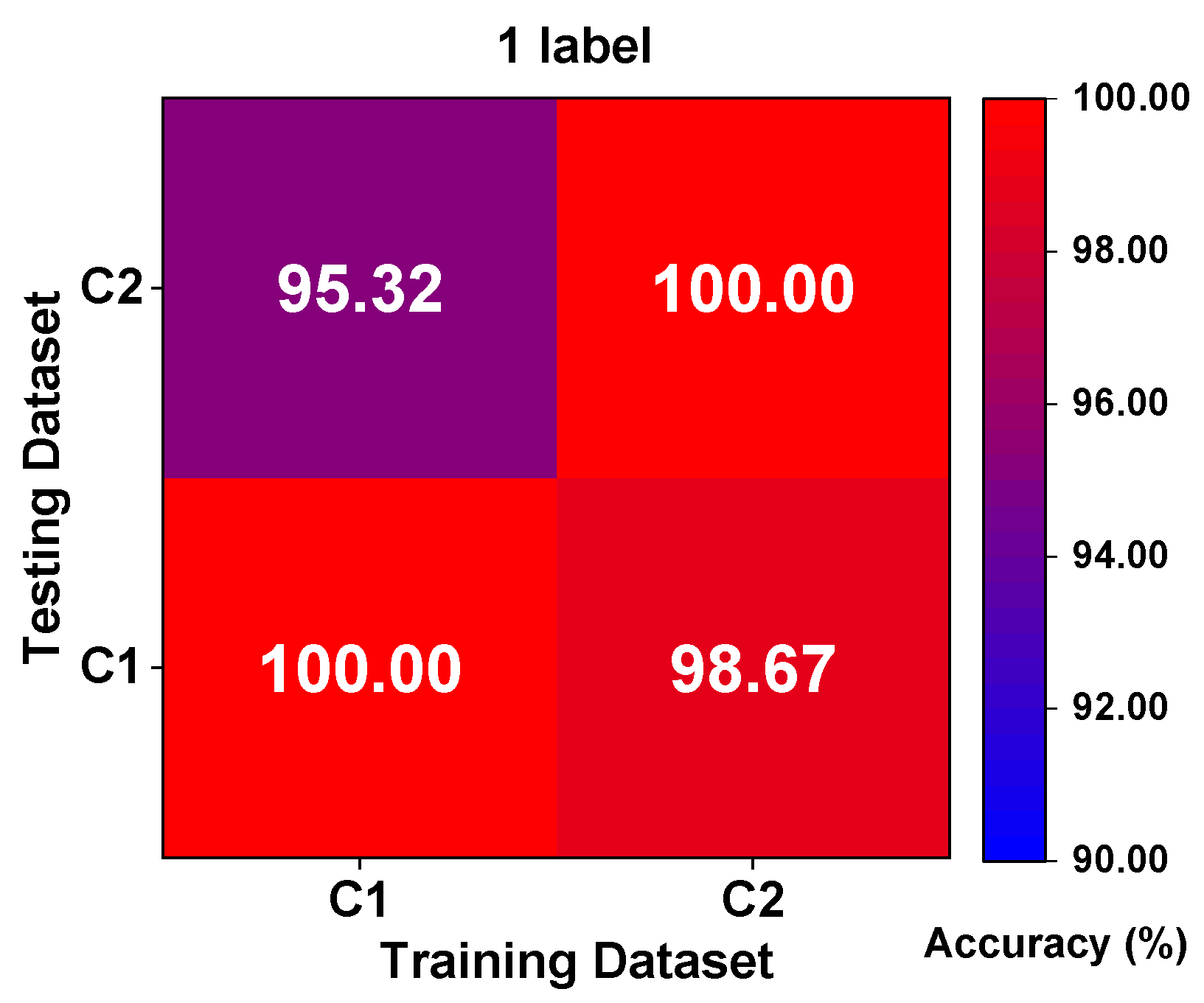
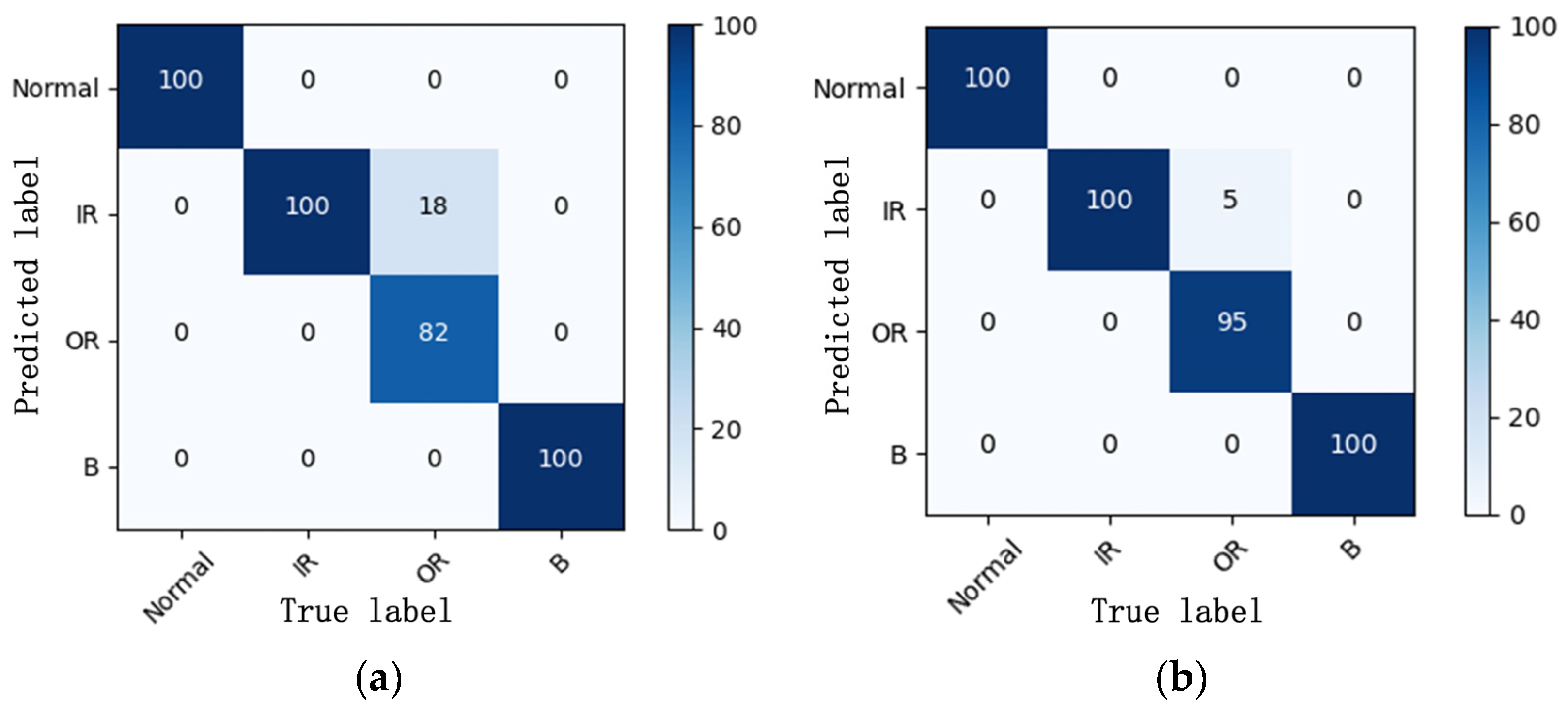
The proposed method is evaluated on two datasets: the first is the public bearing dataset from Case Western Reserve University (CWRU) for comparison with other state-of-the-art algorithms and the second is the experimental bearing dataset from our laboratory test rig of the motorized spindle to illustrate its extensive applicability. A few labeled data are selected randomly to verify the effectiveness of the proposed method. Moreover, variable working conditions are able to prove the ability of the learning distribution-invariant features.
The remaining part of the paper is organized as follows. In
Section 2, the theoretical background is expounded.
Section 3 concentrates on introducing the details of the proposed method. In
Section 4, three case studies are given to illustrate the accuracy and robustness of the proposed method for extremely limited labeled samples under variable working conditions. Finally,
Section 5 concludes this work and gives direction for future work.




























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}