
Multi-Patch Hierarchical Transmission Channel Image Dehazing Network Based on Dual Attention Level Feature Fusion

Abstract
:1. Introduction
1.1. Related Work
1.1.1. Model-Based Parameter Estimation Method
1.1.2. Model-Free Image Enhancement Method
1.1.3. Transmission Channel Image Dehazing Method
1.2. Motivation and Contribution
- It is suggested to use a Dual Attention Level Feature Fusion Multi-Patch Hierarchical Network (DAMPHN) that combines an encoder-decoder module with a Dual Attention Level Feature Fusion (DA) module. The experimental results show that the network has low color distortion and a good defogging effect.
- DA module is proposed. DA makes use of channel attention, pixel attention, and residual connection to enhance the multi-patch layered network’s cross-level feature function strategy. The DA module has strong feature fusion capabilities, as demonstrated by numerous ablation tests.
- By calculating picture depth information and inserting 3D Berlin noise of various frequencies, 2225 pairs of non-homogeneous haze/clear images datasets are constructed based on the actual situation. The dataset can, as closely as possible, mimic the characteristics of haze dispersal in mountainous regions. Later, it is employed to support DAMPHN training and testing, which can enhance the ability of UAV inspection photos of transmission lines in mountainous locations to remove fog.
2. Materials and Methods
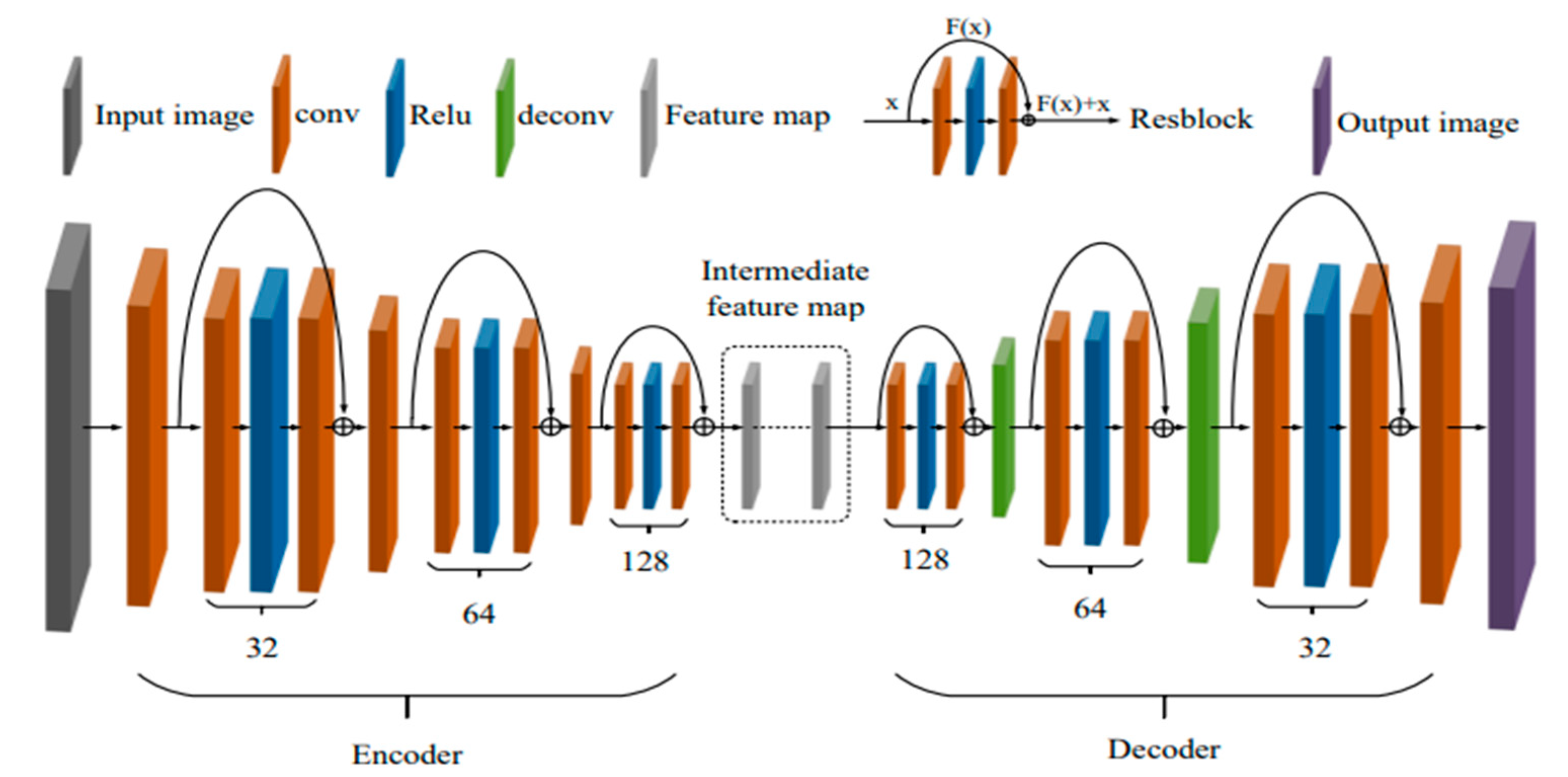
2.1. DAMPHN
2.1.1. Encoder-Decoder
2.1.2. DA Module
2.2. Loss of DAMPHN
- Reconstruction loss ;
- Perception loss ;
- Total variation loss .
3. Experiment Setup
3.1. Dataset
3.1.1. Ablation Experimental Dataset
3.1.2. Self-Built Transmission Channel Inspection Dataset (UAV-HAZE)
3.2. Implementation Details
4. Experiment Results
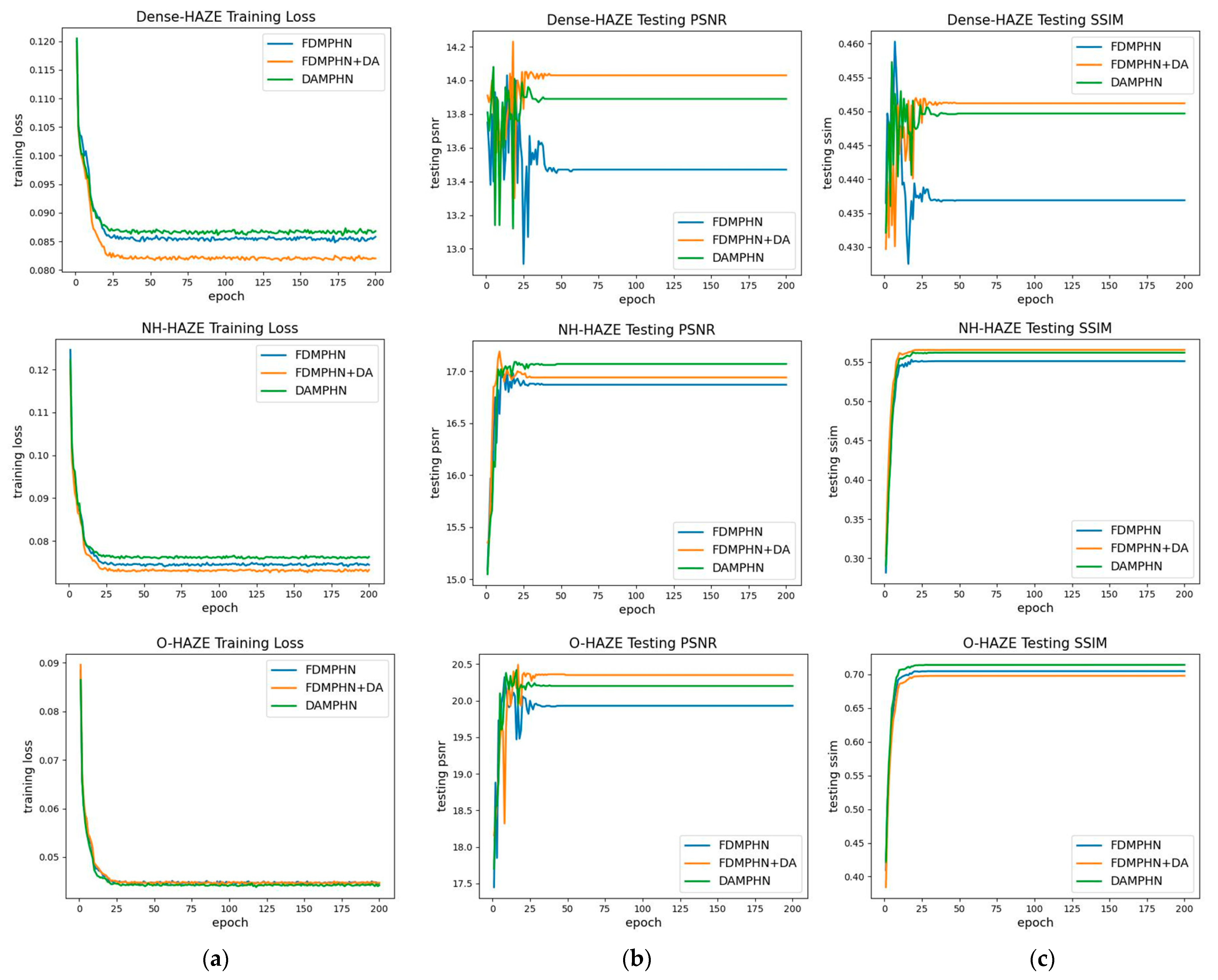
4.1. Ablation Experiment
4.1.1. DA Module
- (I)
- The network encoder-decoder has six residual modules (Resblock × 6) using only FDMPHN.
- (II)
- The approach suggested in this work builds on (I) by adding a DA module (FDMPHN + DA). A DA module plus six residual modules (Resblock × 6) make up the network encoder-decoder.
- (III)
- To optimize (II) and DAMPHN, the solution presented in this research uses just three residual modules (Resblock × 3).
- Quantitative evaluation
- Convergence analysis
4.1.2. DAMPHN Network
- Quantitative evaluation
- Qualitative assessment
- Convergence analysis
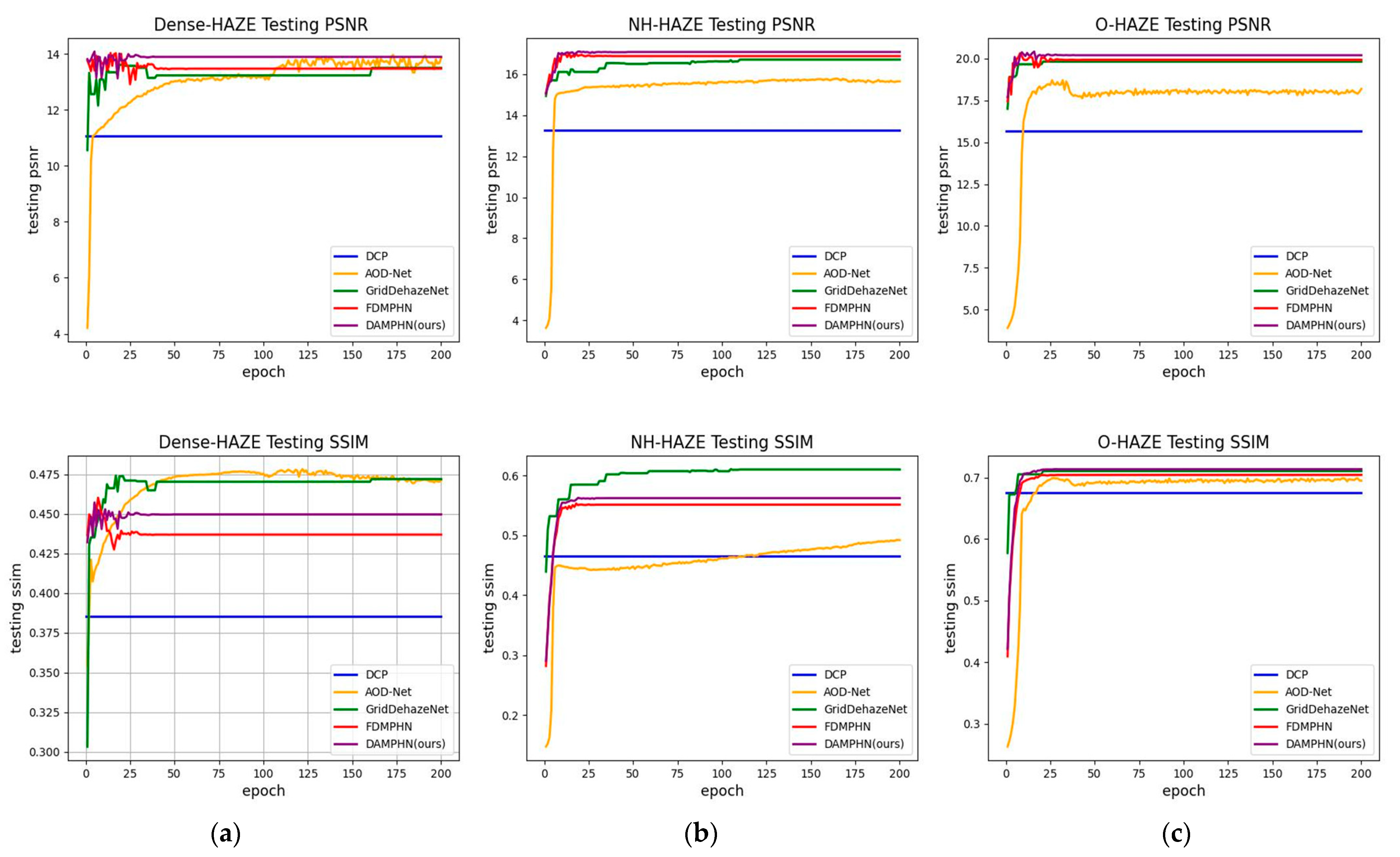
4.2. Transmission Channel Image
4.2.1. Synthetic Dataset UAV-HAZE
- Quantitative evaluation
- Qualitative assessment
4.2.2. Real Image
- Quantitative evaluation
- Qualitative assessment
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| UAV | Unmanned Aerial Vehicle |
| FDMPHN | Fast Deep Multi-Patch Hierarchical Network |
| DAMPHN | Dual Attention Level Feature Fusion Multi-Patch Hierarchical Network |
| PSNR | Peak Signal-to-Noise Ratio |
| SSIM | Structural Similarity Index Measure |
| APT | Average Processing Time |
| DCP | Dark Channel Prior |
| CAP | Color Decay Prior |
| CNN | Convolutional neural networks |
| AOD-Net | All-in-One Dehazing Network |
| DCPDN | Densely Connected Pyramid Dehazing Network |
| FDMSHN | Fast Deep Multi-Scale Hierarchical Network |
| DA | Dual Attention Level Feature Fusion |
| Ca_layer | Channel attention layer |
| Pa_layer | Pixel attention layer |
| PIQE | Perception-based Image Quality Evaluation |
References
- Li, X.; Li, Z.; Wang, H.; Li, W. Unmanned aerial vehicle for transmission line inspection: Status, standardization, and perspectives. Front. Energy Res. 2021, 9, 713634. [Google Scholar] [CrossRef]
- Zhang, T.; Tang, Q.; Li, B.; Zhu, X. Genesis and dissipation mechanisms of radiation-advection fogs in Chengdu based on multiple detection data. Meteorol. Sci. Technol. 2019, 47, 70–78. [Google Scholar]
- Zhao, L.; Zuo, X.; Zhang, S.; Lu, Y. On restoration of mountain haze image based on non-local prior algorithm. Electron. Opt. Control 2022, 29, 55–58. [Google Scholar]
- Imran, A.; Zhu, Q.; Sulaman, M.; Bukhtiar, A.; Xu, M. Electric-Dipole Gated Two Terminal Phototransistor for Charge-Coupled Device. Adv. Opt. Mater. 2023, 2300910. [Google Scholar] [CrossRef]
- Swinehart, D.-F. The beer-lambert law. J. Chem. Educ. 1962, 39, 333–335. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar]
- Zhu, Q.; Mai, J.; Shao, L. A fast single image haze removal algorithm using color attenuation prior. IEEE Trans. Image Process. 2015, 24, 3522–3533. [Google Scholar]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. DehazeNet: An end-to-end system for single image haze removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef] [Green Version]
- Li, B.; Peng, X.; Wang, Z.; Xu, J.; Feng, D. AOD-Net: All-in-one dehazing network. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4770–4778. [Google Scholar]
- Zhang, H.; Patel, V.-M. Densely connected pyramid dehazing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3194–3203. [Google Scholar]
- Li, Y.; Miao, Q.; Quyang, W.; Ma, Z.; Fang, H.; Dong, C.; Quan, Y. LAP-Net: Level-aware progressive network for image dehazing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3276–3285. [Google Scholar]
- Li, R.; Pan, J.; He, M.; Li, Z.; Tang, J. Task-oriented network for image dehazing. IEEE Trans. Image Process. 2020, 29, 6523–6534. [Google Scholar] [CrossRef]
- Bai, H.; Pan, J.; Xiang, X.; Tang, J. Self-guided image dehazing using progressive feature fusion. IEEE Trans. Image Process. 2022, 31, 1217–1229. [Google Scholar] [CrossRef]
- Das, S.-D.; Dutta, S. Fast deep multi-patch hierarchical network for nonhomogeneous image dehazing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 482–483. [Google Scholar]
- Zhang, H.; Dai, Y.; Li, H.; Koniusz, P. Deep stacked hierarchical multi-patch network for image deblurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 5978–5986. [Google Scholar]
- Wang, K.; Yang, Y.; Li, B.; Cui, L. Uneven image dehazing by heterogeneous twin network. IEEE Access 2020, 8, 118485–118496. [Google Scholar] [CrossRef]
- Liu, X.; Ma, Y.; Shi, Z.; Chen, J. Griddehazenet: Attention-based multi-scale network for image dehazing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7314–7323. [Google Scholar]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, X.; Jia, H. FFA-Net: Feature fusion attention network for single image dehazing. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11908–11915. [Google Scholar]
- Wang, C.; Shen, H.-Z.; Fan, F.; Shao, M.-W.; Yang, C.-S.; Luo, J.-C.; Deng, L.-J. EAA-Net: A novel edge assisted attention network for single image dehazing. Knowl.-Based Syst. 2021, 228, 107279. [Google Scholar] [CrossRef]
- Yang, K.; Zhang, J.; Fang, Z. Multi-patch and multi-scale hierarchical aggregation network for fast nonhomogeneous image dehazing. Comput. Sci. 2021, 48, 250–257. [Google Scholar]
- Wang, K.; Duan, Y.; Yang, Y.; Fei, S. Uneven hazy image dehazing based on transmitted attention mechanism. Pattern Recognit. Artif. Intell. 2022, 35, 575–588. [Google Scholar]
- Zhao, D.; Mo, B.; Zhu, X.; Zhao, J.; Zhang, H.; Tao, Y.; Zhao, C. Dynamic Multi-Attention Dehazing Network with Adaptive Feature Fusion. Electronics 2023, 12, 529. [Google Scholar] [CrossRef]
- Guo, Y.; Gao, Y.; Liu, W.; Lu, Y.; Qu, J.; He, S.; Ren, W. SCANet: Self-Paced Semi-Curricular Attention Network for Non-Homogeneous Image Dehazing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 1884–1893. [Google Scholar]
- Liu, J.; Jia, R.; Li, W.; Ma, F.; Wang, X. Image dehazing method of transmission line for unmanned aerial vehicle inspection based on densely connection pyramid network. Wirel. Commun. Mob. Comput. 2020, 2020, 1–9. [Google Scholar]
- Zhang, M.; Song, Z.; Yang, J.; Gao, M.; Hu, Y.; Yuan, C.; Jiang, Z.; Cheng, W. Study on the enhancement method of online monitoring image of dense fog environment with power lines in smart city. Front. Neurorobotics 2022, 16, 299. [Google Scholar] [CrossRef]
- Zhai, Y.; Jiang, L.; Long, Y.; Zhao, Z. Dark channel prior dehazing method for transmission channel image based on sky region segmentation. J. North China Electr. Power Univ. 2021, 48, 89–97. [Google Scholar]
- Xin, R.; Chen, X.; Wu, J.; Yang, K.; Wang, X.; Zhai, Y. Insulator Umbrella Disc Shedding Detection in Foggy Weather. Sensors 2023, 22, 4871. [Google Scholar] [CrossRef]
- Gao, Y.; Yang, J.; Zhang, K.; Peng, H.; Wang, Y.; Xia, N.; Yao, G. A New Method of Conductor Galloping Monitoring Using the Target Detection of Infrared Source. Electronics 2022, 11, 1207. [Google Scholar] [CrossRef]
- Yan, L.; Zai, W.; Wang, J.; Yang, D. Image Defogging Method for Transmission Channel Inspection by UAV Based on Deep Multi-patch Layered Network. In Proceedings of the Panda Forum on Power and Energy (PandaFPE), Chengdu, China, 27–30 April 2023; pp. 855–860. [Google Scholar]
- Wang, K.; Yang, Y.; Fei, S. Review of hazy image sharpening methods. CAAI Trans. Telligent Syst. 2023, 18, 217–230. [Google Scholar]
- Ancuti, C.-O.; Ancuti, C.; Sbert, D.; Timofte, R. Dense-haze: A benchmark for image dehazing with dense-haze and haze-free images. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1014–1018. [Google Scholar]
- Ancuti, C.-O.; Ancuti, C.; Timofte, R.; De, C. O-haze: A dehazing benchmark with real hazy and haze-free outdoor images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 754–762. [Google Scholar]
- Ancuti, C.-O.; Ancuti, C.; Timofte, R. NH-HAZE: An image dehazing benchmark with non-homogeneous hazy and haze-free images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 444–485. [Google Scholar]
- Zhang, N.; Zhang, L.; Cheng, Z. Towards simulating foggy and hazy images and evaluating their authenticity. In Proceedings of the Neural Information Processing: 24th International Conference, Guangzhou, China, 14–18 November 2017; pp. 405–415. [Google Scholar]
- Harsányi, K.; Kiss, K.; Majdik, A.; Sziranyi, T. A hybrid CNN approach for single image depth estimation: A case study. In Proceedings of the International Conference on Multimedia and Network Information System, Hong Kong, China, 1 June 2019; pp. 372–381. [Google Scholar]
- Wang, Z.; Bovik, A.-C. Mean squared error: Love it or leave it? A new look at signal fidelity measures. IEEE Signal Process. Mag. 2009, 26, 98–117. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.-C.; Sheikh, H.-R.; Simoncelli, E.-P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar]
- Venkatanath, N.; Praneeth, D.; Bh, M.-C.; Channappayya, S.; Medasani, S. Blind image quality evaluation using perception based features. In Proceedings of the 2015 Twenty First National Conference on Communications (NCC), Munbai, India, 27 February–1 March 2015; pp. 1–6. [Google Scholar]
- Amyar, A.; Modzelewski, R.; Vera, P.; Morard, V.; Ruan, S. Multi-task multi-scale learning for outcome prediction in 3D PET images. Comput. Biol. Med. 2022, 151, 106208. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Dense-HAZE | O-HAZE | NH-HAZE | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | APT | PSNR | SSIM | APT | PSNR | SSIM | APT | ||
| (I) | FDMPHN | 13.47 | 0.4369 | 0.031 | 19.93 | 0.7045 | 0.030 | 16.87 | 0.5512 | 0.030 |
| (II) | FDMPHN + DA | 14.03 | 0.4512 | 0.036 | 20.35 | 0.6976 | 0.035 | 16.94 | 0.5656 | 0.037 |
| (III) | DAMPHN | 13.89 | 0.4497 | 0.027 | 20.20 | 0.7138 | 0.027 | 17.07 | 0.5621 | 0.027 |
| Method | Dense-HAZE | O-HAZE | NH-HAZE | ||||||
|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | APT | PSNR | SSIM | APT | PSNR | SSIM | APT | |
| DCP [6] | 11.60 | 0.3854 | 0.406 | 15.66 | 0.6753 | 0.440 | 13.28 | 0.4650 | 0.416 |
| AOD-Net [9] | 13.85 | 0.4714 | 0.023 | 18.19 | 0.6950 | 0.010 | 15.64 | 0.4918 | 0.009 |
| GridDehazeNet [17] | 13.50 | 0.4721 | 0.026 | 19.82 | 0.7108 | 0.026 | 16.70 | 0.6101 | 0.026 |
| FDMPHN [14] | 13.47 | 0.4369 | 0.031 | 19.93 | 0.7045 | 0.030 | 16.87 | 0.5512 | 0.030 |
| DAMPHN (ours) | 13.89 | 0.4497 | 0.027 | 20.20 | 0.7138 | 0.027 | 17.07 | 0.5621 | 0.027 |
| Method | PSNR | SSIM | APT |
|---|---|---|---|
| DCP [6] | 19.97 | 0.8851 | 0.352 |
| AOD-Net [9] | 17.92 | 0.7382 | 0.001 |
| GridDehazeNet [17] | 26.98 | 0.9476 | 0.015 |
| FDMPHN [14] | 27.20 | 0.9439 | 0.234 |
| DAMPHN (ours) | 27.24 | 0.9439 | 0.014 |
| Method | Information Entropy | Standard Deviation | Clarity | PIQE | APT |
|---|---|---|---|---|---|
| DCP [6] | 17.78 | 32.19 | 459.86 | 27.51 | 0.342 |
| AOD-Net [9] | 16.10 | 45.93 | 452.79 | 28.87 | 0.005 |
| GridDehazeNet [17] | 18.28 | 41.61 | 470.18 | 24.90 | 0.021 |
| FDMPHN [14] | 18.10 | 42.38 | 465.21 | 24.48 | 0.270 |
| DAMPHN (ours) | 17.93 | 41.92 | 536.11 | 23.98 | 0.020 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zai, W.; Yan, L. Multi-Patch Hierarchical Transmission Channel Image Dehazing Network Based on Dual Attention Level Feature Fusion. Sensors 2023, 23, 7026. https://doi.org/10.3390/s23167026
Zai W, Yan L. Multi-Patch Hierarchical Transmission Channel Image Dehazing Network Based on Dual Attention Level Feature Fusion. Sensors. 2023; 23(16):7026. https://doi.org/10.3390/s23167026
Chicago/Turabian StyleZai, Wenjiao, and Lisha Yan. 2023. "Multi-Patch Hierarchical Transmission Channel Image Dehazing Network Based on Dual Attention Level Feature Fusion" Sensors 23, no. 16: 7026. https://doi.org/10.3390/s23167026