
An Efficient Image Deblurring Network with a Hybrid Architecture

Abstract
:1. Introduction
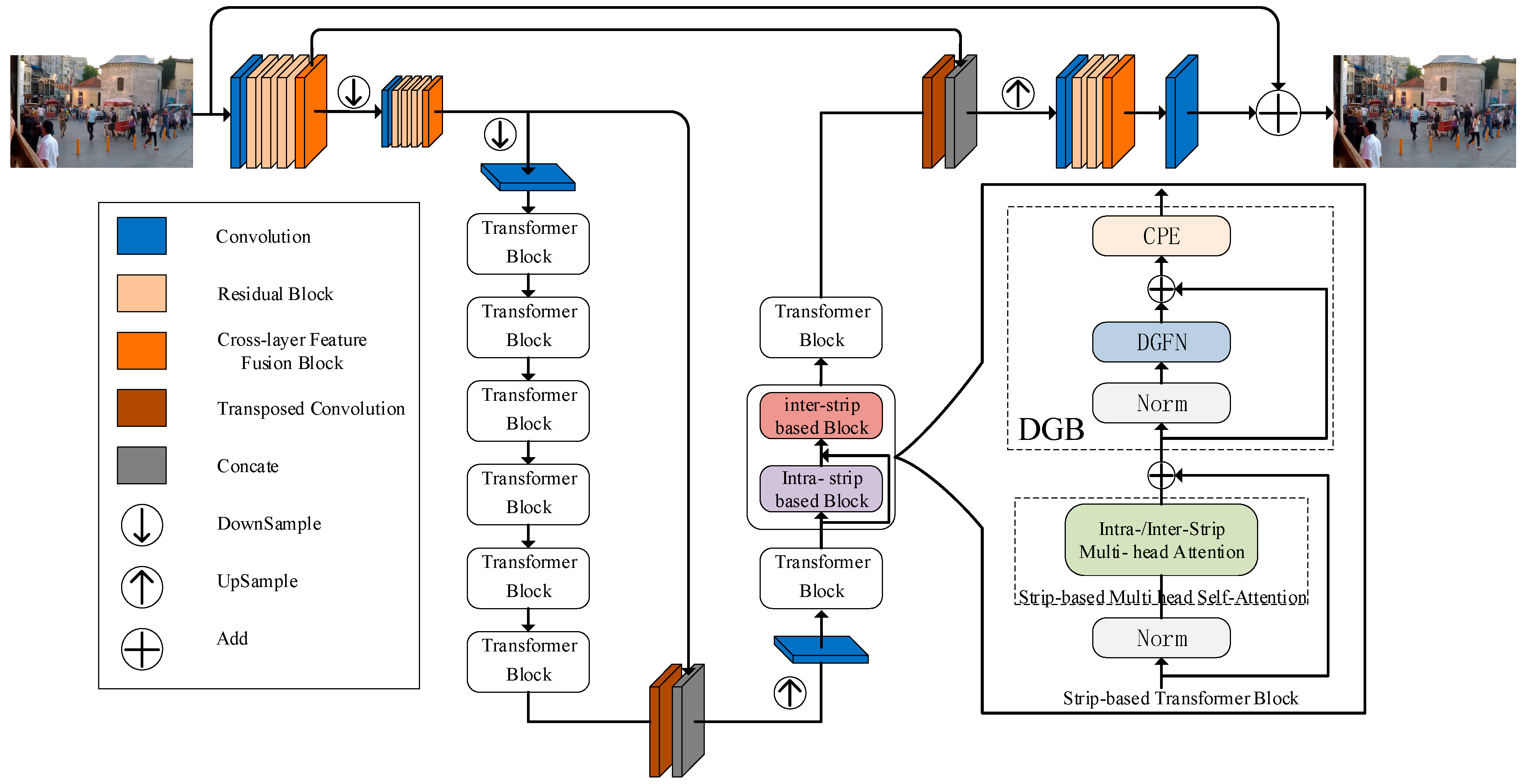
- We propose the ESIDformer network, a hybrid residual encoder–decoder architecture consisting of CNN and a transformer, for a multiscale local and global training framework for image deblurring. Based on the structure of a standard transformer, a strip-based transformer block (STB) is constructed, which can construct intra- and inter-strip tokens and stack them interleaved so as to more closely aggregate local and global pixels, and effectively handle blurred-clear image pairs.
- A dual gating feedforward network (DGFN) is designed, which fuses useful information in both paths of the element, thus achieving the effect of enriching the larger end of the information and suppressing the smaller end of the information.
- A cross-layer feature fusion block (CFFB) is designed, which adaptively fuses layered features with learnable correlations between different layers.
- We demonstrate the validity of our method by demonstrating it on the benchmark datasets GoPro, HIDE, and the real dataset RealBlur. In addition, we provide quantitative results, qualitative results, and results of ablation experiments.
2. Related Work
2.1. CNN-Based Image Deblurring Architecture
2.2. Visual Attention Mechanism
2.3. Vision Transformer
3. Approach
3.1. Network Architecture
3.2. Shallow Feature Embedding Block
3.3. Stripe-Based Transformer Block
3.3.1. Intra-SA Block
3.3.2. Inter-SA Block
3.4. Dual Gating Feedforward Network
3.5. Loss Function
4. Experiments
4.1. Datasets
4.2. Experimental Environment and Implementation Details
4.3. Experimental Results
4.3.1. Quantitative Analysis
4.3.2. Qualitative Analysis
4.4. Ablation Studies
4.4.1. Stripe-Based Multi-Head Self-Attention
4.4.2. Dual-Gating Feed-Forward Network
4.4.3. Cross-Layer Feature Fusion Block
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fergus, R.; Singh, B.; Hertzmann, A.; Roweis, S.T.; Freeman, W.T. Removing camera shake from a single photograph. ACM Trans. Graph. 2006, 25, 787–794. [Google Scholar] [CrossRef]
- Kenig, T.; Kam, Z.; Feuer, A. Blind image deconvolution using machine learning for three-dimensional microscopy. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 2191–2204. [Google Scholar] [CrossRef] [PubMed]
- Levin, A.; Weiss, Y.; Durand, F.; Freeman, W.T. Efficient marginal likelihood optimization in blind deconvolution. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 2657–2664. [Google Scholar] [CrossRef]
- Xu, L.; Zheng, S.; Jia, J. Unnatural l0 sparse representation for natural image deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1107–1114. [Google Scholar] [CrossRef]
- Michaeli, T.; Irani, M. Blind deblurring using internal patch recurrence. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part III 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 783–798. [Google Scholar] [CrossRef]
- Cai, J.F.; Ji, H.; Liu, C.; Shen, Z. Blind motion deblurring from a single image using sparse approximation. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Miami, FL, USA, 20–25 June 2013. [Google Scholar] [CrossRef]
- Zhang, X.; Burger, M.; Bresson, X.; Osher, S. Bregmanized Nonlocal Regularization for Deconvolution and Sparse Reconstruction. SIAM J. Imaging Sci. 2010, 3, 253–276. [Google Scholar] [CrossRef]
- Zhang, H.; Yang, J.; Zhang, Y.; Huang, T.S. Sparse representation based blind image deblurring. In Proceedings of the IEEE International Conference on Multimedia & Expo, Barcelona, Spain, 11–15 July 2011. [Google Scholar] [CrossRef]
- Rostami, M.; Michailovich, O.; Wang, Z. Image Deblurring Using Derivative Compressed Sensing for Optical Imaging Application. IEEE Trans. Image Process. 2012, 21, 3139. [Google Scholar] [CrossRef] [PubMed]
- Yin, M.; Gao, J.; Tien, D.; Cai, S. Blind image deblurring via coupled sparse representation. J. Vis. Commun. Image Represent. 2014, 25, 814–821. [Google Scholar] [CrossRef]
- Gao, H.; Tao, X.; Shen, X.; Jia, J. Dynamic scene deblurring with parameter selective sharing and nested skip connections. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3848–3856. [Google Scholar] [CrossRef]
- Nah, S.; Hyun Kim, T.; Mu Lee, K. Deep multi-scale convolutional neural network for dynamic scene deblurring. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3883–3891. [Google Scholar] [CrossRef]
- Suin, M.; Purohit, K.; Rajagopalan, A. Spatially-attentive patch-hierarchical network for adaptive motion deblurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3606–3615. [Google Scholar] [CrossRef]
- Zhang, H.; Dai, Y.; Li, H.; Koniusz, P. Deep stacked hierarchical multi-patch network for image deblurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5978–5986. [Google Scholar] [CrossRef]
- Park, D.; Kang, D.U.; Kim, J.; Chun, S.Y. Multi-temporal recurrent neural networks for progressive non-uniform single image deblurring with incremental temporal training. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part VI 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 327–343. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar] [CrossRef]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A. Language models are few-shot learners. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; Volume 33, pp. 1877–1901. [Google Scholar] [CrossRef]
- Fedus, W.; Zoph, B.; Shazeer, N. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. J. Mach. Learn. Res. 2022, 23, 5232–5270. [Google Scholar] [CrossRef]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 10347–10357. [Google Scholar] [CrossRef]
- Wang, W.; Xie, E.; Li, X.; Fan, D.-P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 568–578. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part I 16, 2020. Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar] [CrossRef]
- Sun, J.; Cao, W.; Xu, Z.; Ponce, J. Learning a convolutional neural network for non-uniform motion blur removal. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 769–777. [Google Scholar] [CrossRef]
- Tsai, F.-J.; Peng, Y.-T.; Lin, Y.-Y.; Tsai, C.-C.; Lin, C.-W. Stripformer: Strip transformer for fast image deblurring. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part XIX. Springer: Berlin/Heidelberg, Germany, 2022; pp. 146–162. [Google Scholar]
- Wang, T.; Zhang, K.; Shen, T.; Luo, W.; Stenger, B.; Lu, T. Ultra-High-Definition Low-Light Image Enhancement: A Benchmark and Transformer-Based Method. arXiv 2022, arXiv:2212.11548. [Google Scholar] [CrossRef]
- Tao, X.; Gao, H.; Shen, X.; Wang, J.; Jia, J. Scale-recurrent network for deep image deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8174–8182. [Google Scholar] [CrossRef]
- Zhang, J.; Pan, J.; Ren, J.; Song, Y.; Bao, L.; Lau, R.W.; Yang, M.-H. Dynamic scene deblurring using spatially variant recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2521–2529. [Google Scholar]
- Aljadaany, R.; Pal, D.K.; Savvides, M. Douglas-rachford networks: Learning both the image prior and data fidelity terms for blind image deconvolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10235–10244. [Google Scholar] [CrossRef]
- Yuan, Y.; Su, W.; Ma, D. Efficient dynamic scene deblurring using spatially variant deconvolution network with optical flow guided training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3555–3564. [Google Scholar]
- Kupyn, O.; Budzan, V.; Mykhailych, M.; Mishkin, D.; Matas, J. Deblurgan: Blind motion deblurring using conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8183–8192. [Google Scholar] [CrossRef]
- Kupyn, O.; Martyniuk, T.; Wu, J.; Wang, Z. Deblurgan-v2: Deblurring (orders-of-magnitude) faster and better. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8878–8887. [Google Scholar] [CrossRef]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.-H.; Shao, L. Multi-stage progressive image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14821–14831. [Google Scholar] [CrossRef]
- Cho, S.-J.; Ji, S.-W.; Hong, J.-P.; Jung, S.-W.; Ko, S.-J. Rethinking coarse-to-fine approach in single image deblurring. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 4641–4650. [Google Scholar]
- Chen, L.; Sun, Q.; Wang, F. Attention-adaptive and deformable convolutional modules for dynamic scene deblurring. Inf. Sci. 2021, 546, 368–377. [Google Scholar] [CrossRef]
- Suganuma, M.; Liu, X.; Okatani, T. Attention-based adaptive selection of operations for image restoration in the presence of unknown combined distortions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9039–9048. [Google Scholar] [CrossRef]
- Zhang, X.; Dong, H.; Hu, Z.; Lai, W.-S.; Wang, F.; Yang, M.-H. Gated fusion network for joint image deblurring and super-resolution. arXiv 2018, arXiv:1807.10806. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Parmar, N.; Vaswani, A.; Uszkoreit, J.; Kaiser, U.; Shazeer, N.; Ku, A.; Tran, D. Image Transformer. arXiv 2018, arXiv:1802.05751. [Google Scholar]
- Jiang, Y.; Chang, S.; Wang, Z. Transgan: Two pure transformers can make one strong gan, and that can scale up. In Proceedings of the 35th Conference on Neural Information Processing Systems (NeurIPS 2021), Online Conference, 6–14 December 2021; Volume 34, pp. 14745–14758. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1833–1844. [Google Scholar]
- Lu, Z.; Liu, H.; Li, J.; Zhang, L. Efficient transformer for single image super-resolution. arXiv 2021, arXiv:2108.11084. [Google Scholar] [CrossRef]
- Chen, H.; Wang, Y.; Guo, T.; Xu, C.; Deng, Y.; Liu, Z.; Ma, S.; Xu, C.; Xu, C.; Gao, W. Pre-trained image processing transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12299–12310. [Google Scholar]
- Wang, Z.; Cun, X.; Bao, J.; Zhou, W.; Liu, J.; Li, H. Uformer: A general u-shaped transformer for image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17683–17693. [Google Scholar] [CrossRef]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 603–612. [Google Scholar] [CrossRef]
- Chu, X.; Tian, Z.; Zhang, B.; Wang, X.; Wei, X.; Xia, H.; Shen, C. Conditional positional encodings for vision transformers. arXiv 2021, arXiv:2102.10882. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.-H. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5728–5739. [Google Scholar] [CrossRef]
- Wu, H.; Qu, Y.; Lin, S.; Zhou, J.; Qiao, R.; Zhang, Z.; Xie, Y.; Ma, L. Contrastive learning for compact single image dehazing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10551–10560. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, Virtual Event, 13–18 July 2020; pp. 1597–1607. [Google Scholar] [CrossRef]
- Shen, Z.; Wang, W.; Lu, X.; Shen, J.; Ling, H.; Xu, T.; Shao, L. Human-aware motion deblurring. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5572–5581. [Google Scholar] [CrossRef]
- Rim, J.; Lee, H.; Won, J.; Cho, S. Real-world blur dataset for learning and benchmarking deblurring algorithms. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 184–201. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | PSNR (MPSRN) ↑ | SSIM (MSSIM) ↑ | Params (M) ↓ | σPSRN/σSSIM |
|---|---|---|---|---|
| DeblurGAN-v2 | 29.08 | 0.918 | 68 | - |
| SRN | 30.24 | 0.934 | 7 | - |
| DSD | 30.96 | 0.942 | 3 | - |
| MTRNN | 31.12 | 0.944 | 3 | - |
| DMPHN | 31.39 | 0.947 | 22 | - |
| RADN † | 31.85 | 0.953 | - | - |
| SAPHN † | 32.02 | 0.953 | - | - |
| MIMO | 32.45 | 0.957 | 16 | - |
| MPRNet | 32.65 | 0.958 | 20 | - |
| IPT † | 32.52 | - | 114 | - |
| Ours | 33.11 (33.1182) | 0.963 (0.9632) | 32 | 0.0040/0.0023 |
| Method | PSNR (MPSRN) ↑ | SSIM (MSSIM) ↑ | Params(M) ↓ | σPSRN/σSSIM |
|---|---|---|---|---|
| DeblurGAN-v2 | 27.51 | 0.884 | 68 | - |
| SRN | 28.36 | 0.903 | 7 | - |
| DSD | 29.01 | 0.913 | 3 | - |
| DMPHN | 29.11 | 0.917 | 22 | - |
| MTRNN | 29.15 | 0.917 | 22 | - |
| MIMO | 30.00 | 0.930 | 16 | - |
| MPRNet | 30.96 | 0.939 | 20 | - |
| Ours | 31.10 (31.09176) | 0.948 (0.9482) | 32 | 0.1456/0.0010 |
| Model | RealBlur-J | RealBlur | σPSRN/σSSIM | |
|---|---|---|---|---|
| PSNR (MPSRN) ↑ | SSIM (MSSIM) ↑ | Params(M) ↓ | ||
| DeblurGANv2 | 29.69 | 0.870 | 68 | - |
| SRN | 31.38 | 0.909 | 7 | - |
| MPRNet | 31.76 | 0.922 | 20 | - |
| SPAIR † | 31.82 | 0.922 | - | - |
| MIMO | 31.92 | 0.919 | 16 | - |
| Ours | 32.50 (32.5216) | 0.931 (0.9309) | 32 | 0.2845/0.0012 |
| S-MSA | DGFN (w/o A) | DGFN (w/o B) | CFFB | PSNR |
|---|---|---|---|---|
| √ | 32.89 | |||
| √ | √ | 32.94 | ||
| √ | √ | 33.07 | ||
| √ | √ | √ | √ | 33.11 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, M.; Yi, S.; Lan, Z.; Duan, Z. An Efficient Image Deblurring Network with a Hybrid Architecture. Sensors 2023, 23, 7260. https://doi.org/10.3390/s23167260
Chen M, Yi S, Lan Z, Duan Z. An Efficient Image Deblurring Network with a Hybrid Architecture. Sensors. 2023; 23(16):7260. https://doi.org/10.3390/s23167260
Chicago/Turabian StyleChen, Mingju, Sihang Yi, Zhongxiao Lan, and Zhengxu Duan. 2023. "An Efficient Image Deblurring Network with a Hybrid Architecture" Sensors 23, no. 16: 7260. https://doi.org/10.3390/s23167260
APA StyleChen, M., Yi, S., Lan, Z., & Duan, Z. (2023). An Efficient Image Deblurring Network with a Hybrid Architecture. Sensors, 23(16), 7260. https://doi.org/10.3390/s23167260