



Human Activity Recognition via Score Level Fusion of Wi-Fi CSI Signals


Abstract
:1. Introduction
2. Related Work
2.1. Vision-and-Sound-Based HAR
2.2. Mobile-Device-Based HAR
2.3. Wi-Fi-Based HAR
3. Preliminaries
3.1. Wi-Fi for Human Activity Recognition
3.2. Wi-Fi CSI Signal Features
4. Proposed System
4.1. Preprocessing
4.2. Classification Stage
4.3. Fusion Stage
5. Experiments
5.1. Database
5.2. Experimental Setup
5.3. Results and Discussion
5.3.1. Experiment I(a) Effect of Cropping Size and Pass-Band on the LSE Classifier
5.3.2. Experiment I(b) to Observe the Effect of Cropping Size and Pass-Band on the SVM-RBF Classifier
5.3.3. Experiment I(c) to Observe the Effect of Cropping Size and Pass-Band on the KNN Classifier
5.3.4. Experiment II Fusion of First-Level LSE and SVM-RBF Scores Using LSE, SVM-RBF, KNN, and ANnet
5.3.5. Experiment III Comparison of the Proposed Fusion with SOTA Methods in Table 1
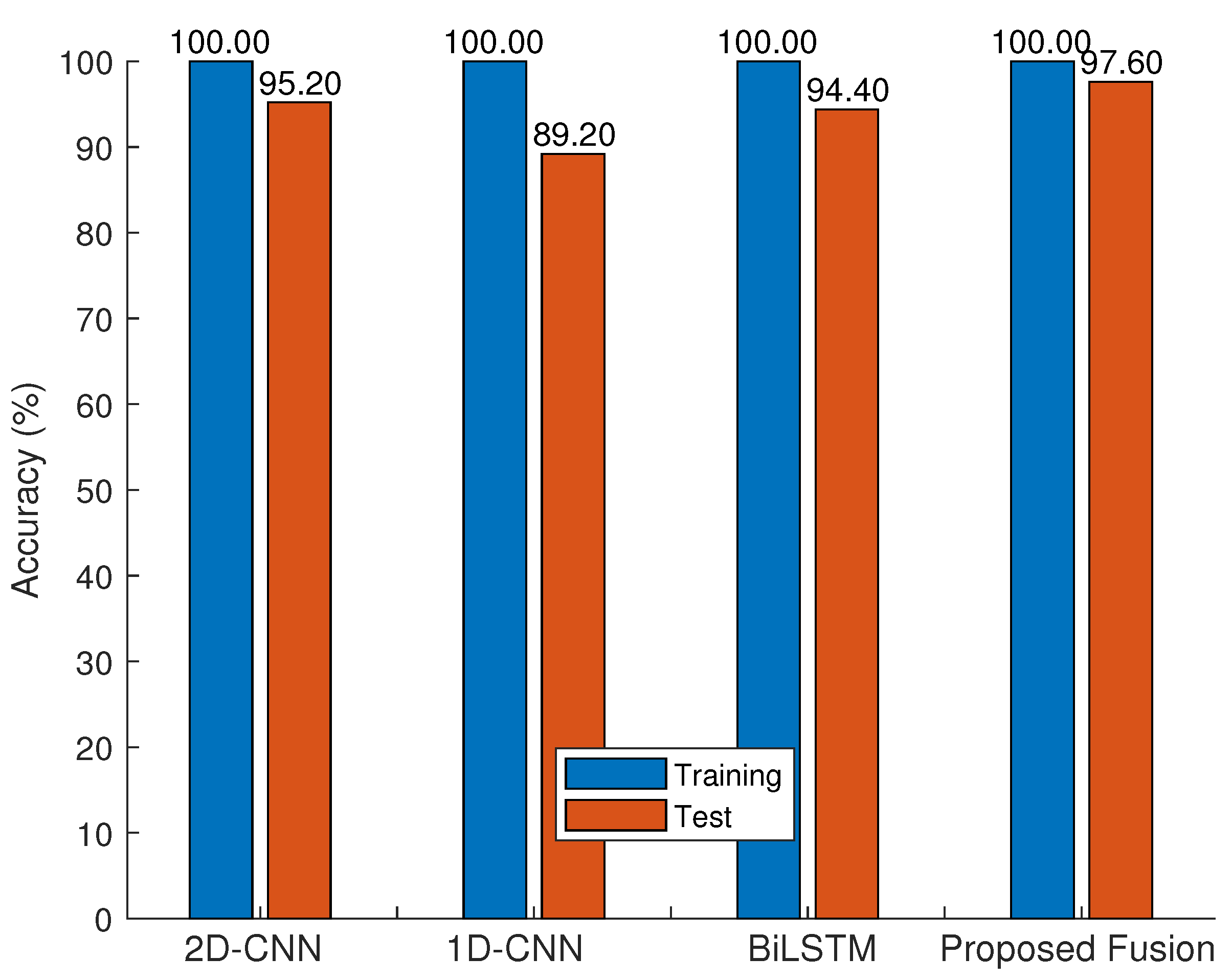
5.4. Summary of Results and Observations
- Expt I: This experiment reveals that the preprocessing steps of selecting the cropping size and the normalized pass-band have a significant impact on the recognition accuracy. In particular, each database shows its best accuracy at different combinations of settings. For example, the HAR-RP and HAR-ARIL datasets show that a small cropping size leads to a high accuracy at an intermediate range of normalized pass-bands. For the HAR-RT database, the accuracy increases as the pass-band value increases.
- Expt II: This experiment shows that fusion using SVM-RBF and ANnet outperforms the LSE and KNN in general. Moreover, many of their fused results show an improved accuracy compared with that before fusion.
- Expt III: This experiment shows that the proposed fusion has either comparable or better accuracy than that of SOTA. In particular, the SOTA methods show significant over-fitting in view of their higher model complexity than the proposed fusion method. In other words, the proposed fusion method has capitalized on the low model complexity but with sufficient mapping capability to generalize the prediction.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Aggarwal, J.K.; Ryoo, M.S. Human activity analysis: A review. Acm Comput. Surv. 2011, 43, 1–43. [Google Scholar] [CrossRef]
- Thakur, D.; Biswas, S. Smartphone based human activity monitoring and recognition using ML and DL: A comprehensive survey. J. Ambient. Intell. Humaniz. Comput. 2020, 11, 5433–5444. [Google Scholar] [CrossRef]
- Nweke, H.F.; Teh, Y.W.; Mujtaba, G.; Al-Garadi, M.A. Data fusion and multiple classifier systems for human activity detection and health monitoring: Review and open research directions. Inf. Fusion 2019, 46, 147–170. [Google Scholar] [CrossRef]
- Ariza-Colpas, P.P.; Vicario, E.; Oviedo-Carrascal, A.I.; Shariq Butt Aziz, M.A.P.M.; Quintero-Linero, A.; Patara, F. Human Activity Recognition Data Analysis: History, Evolutions, and New Trends. Sensors 2022, 22, 3401. [Google Scholar] [CrossRef]
- Jeon, J.H.; Oh, B.S.; Toh, K.A. A System for Hand Gesture Based Signature Recognition. In Proceedings of the International Conference on Control, Automation, Robotics and Vision (ICARCV 2012), Singapore, 5–7 December 2012; pp. 171–175. [Google Scholar]
- Bailador, G.; Sanchez-Avila, C.; Guerra-Casanova, J.; de Santos Sierra, A. Analysis of pattern recognition techniques for in-air signature biometrics. Pattern Recognit. 2011, 44, 2467–2478. [Google Scholar] [CrossRef]
- Wang, W.; Liu, A.X.; Shahzad, M.; Ling, K.; Lu, S. Understanding and modeling of wifi signal based human activity recognition. In Proceedings of the 21st Annual International Conference on Mobile Computing and Networking, Paris, France, 7–11 September 2015; pp. 65–76. [Google Scholar]
- Jung, J.; Moon, H.C.; Kim, J.; Kim, D.; Toh, K.A. Wi-Fi based user identification using in-air handwritten signature. IEEE Access 2021, 9, 53548–53565. [Google Scholar] [CrossRef]
- Scholz, M.; Sigg, S.; Schmidtke, H.R.; Beigl, M. Challenges for device-free radio-based activity recognition. In Proceedings of the Workshop on Context Systems, Design, Evaluation and Optimisation; 2011. [Google Scholar]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification, 2nd ed.; John Wiley & Sons, Inc.: New York, NY, USA, 2001. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Ayodele, T.O. Types of machine learning algorithms. New Adv. Mach. Learn. 2010, 3, 19–48. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Anitha, U.; Narmadha, R.; Sumanth, D.R.; Kumar, D.N. Robust human action recognition system via image processing. Procedia Comput. Sci. 2020, 167, 870–877. [Google Scholar] [CrossRef]
- Schuldt, C.; Laptev, I.; Caputo, B. Recognizing human actions: A local SVM approach. In Proceedings of the 17th International Conference on Pattern Recognition, Cambridge, UK, 23–26 August 2004; Volume 3, pp. 32–36. [Google Scholar]
- Ahmad, Z.; Illanko, K.; Khan, N.; Androutsos, D. Human action recognition using convolutional neural network and depth sensor data. In Proceedings of the 2019 International Conference on Information Technology and Computer Communications, Singapore, 16–18 August 2019; pp. 1–5. [Google Scholar]
- Fu, Z.; Culurciello, E.; Lichtsteiner, P.; Delbruck, T. Fall detection using an address-event temporal contrast vision sensor. In Proceedings of the 2008 IEEE International Symposium on Circuits and Systems (ISCAS), Washington, DC, USA, 18–21 May 2008; pp. 424–427. [Google Scholar]
- Stork, J.A.; Spinello, L.; Silva, J.; Arras, K.O. Audio-based human activity recognition using non-Markovian ensemble voting. In Proceedings of the 2012 IEEE RO-MAN: The 21st IEEE International Symposium on Robot and Human Interactive Communication, Paris, France, 9–13 September 2012; pp. 509–514. [Google Scholar]
- Ramezanpanah, Z.; Mallem, M.; Davesne, F. Human action recognition using Laban movement analysis and dynamic time warping. Procedia Comput. Sci. 2020, 176, 390–399. [Google Scholar] [CrossRef]
- Wang, K.; Wang, X.; Lin, L.; Wang, M.; Zuo, W. 3D human activity recognition with reconfigurable convolutional neural networks. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 97–106. [Google Scholar]
- Dobhal, T.; Shitole, V.; Thomas, G.; Navada, G. Human activity recognition using binary motion image and deep learning. Procedia Comput. Sci. 2015, 58, 178–185. [Google Scholar] [CrossRef]
- Mahjoub, A.B.; Atri, M. Human action recognition using RGB data. In Proceedings of the 2016 11th International Design & Test Symposium (IDT), Hammamet, Tunisia, 18–20 December 2016; pp. 83–87. [Google Scholar]
- Anjum, A.; Ilyas, M.U. Activity recognition using smartphone sensors. In Proceedings of the 2013 IEEE 10th Consumer Communications and Networking Conference (CCNC), Las Vegas, NV, USA, 11–14 January 2013; pp. 914–919. [Google Scholar]
- Nandy, A.; Saha, J.; Chowdhury, C. Novel features for intensive human activity recognition based on wearable and smartphone sensors. Microsyst. Technol. 2020, 26, 1889–1903. [Google Scholar] [CrossRef]
- Yatani, K.; Truong, K.N. Bodyscope: A wearable acoustic sensor for activity recognition. In Proceedings of the 2012 ACM Conference on Ubiquitous Computing, Pittsburgh, PA, USA, 5–8 September 2012; pp. 341–350. [Google Scholar]
- Castro, D.; Coral, W.; Rodriguez, C.; Cabra, J.; Colorado, J. Wearable-based human activity recognition using an IoT approach. J. Sens. Actuator Netw. 2017, 6, 28. [Google Scholar] [CrossRef]
- Voicu, R.A.; Dobre, C.; Bajenaru, L.; Ciobanu, R.I. Human physical activity recognition using smartphone sensors. Sensors 2019, 19, 458. [Google Scholar] [CrossRef]
- Rustam, F.; Reshi, A.A.; Ashraf, I.; Mehmood, A.; Ullah, S.; Khan, D.M.; Choi, G.S. Sensor-based human activity recognition using deep stacked multilayered perceptron model. IEEE Access 2020, 8, 218898–218910. [Google Scholar] [CrossRef]
- Chen, Y.; Xue, Y. A deep learning approach to human activity recognition based on single accelerometer. In Proceedings of the 2015 IEEE International Conference on Systems, Man, and Cybernetics, Hong Kong, 9–12 October 2015; pp. 1488–1492. [Google Scholar]
- Ghate, V. Hybrid deep learning approaches for smartphone sensor-based human activity recognition. Multimed. Tools Appl. 2021, 80, 35585–35604. [Google Scholar] [CrossRef]
- Sadowski, S.; Spachos, P. RSSI-based indoor localization with the internet of things. IEEE Access 2018, 6, 30149–30161. [Google Scholar] [CrossRef]
- Hsieh, C.F.; Chen, Y.C.; Hsieh, C.Y.; Ku, M.L. Device-free indoor human activity recognition using Wi-Fi RSSI: Machine learning approaches. In Proceedings of the 2020 IEEE International Conference on Consumer Electronics-Taiwan (ICCE-Taiwan), Taiwan, 28–30 September 2020; pp. 1–2. [Google Scholar]
- Wang, Y.; Liu, J.; Chen, Y.; Gruteser, M.; Yang, J.; Liu, H. E-eyes: Device-free location-oriented activity identification using fine-grained WiFi signatures. In Proceedings of the 20th Annual International Conference on Mobile Computing and Networking, Maui, HI, USA, 7–11 September 2014; pp. 617–628. [Google Scholar]
- Chen, Z.; Zhang, L.; Jiang, C.; Cao, Z.; Cui, W. WiFi CSI based passive human activity recognition using attention based BLSTM. IEEE Trans. Mob. Comput. 2018, 18, 2714–2724. [Google Scholar] [CrossRef]
- Wang, F.; Gong, W.; Liu, J. On spatial diversity in WiFi-based human activity recognition: A deep learning-based approach. IEEE Internet Things J. 2018, 6, 2035–2047. [Google Scholar] [CrossRef]
- Lu, X.; Li, Y.; Cui, W.; Wang, H. CeHAR: CSI-based Channel-Exchanging Human Activity Recognition. IEEE Internet Things J. 2022, 10, 5953–5961. [Google Scholar] [CrossRef]
- Islam, M.S.; Jannat, M.K.A.; Hossain, M.N.; Kim, W.S.; Lee, S.W.; Yang, S.H. STC-NLSTMNet: An Improved Human Activity Recognition Method Using Convolutional Neural Network with NLSTM from WiFi CSI. Sensors 2023, 23, 356. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Cao, R.; Zhou, M.; Xie, L. Temporal-frequency attention-based human activity recognition using commercial WiFi devices. IEEE Access 2020, 8, 137758–137769. [Google Scholar] [CrossRef]
- Moshiri, P.F.; Shahbazian, R.; Nabati, M.; Ghorashi, S.A. A CSI-based Human Activity Recognition using deep learning. Sensors 2021, 21, 7225. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, Q.; Wang, Y.; Yu, G. CSI-Based Location-Independent Human Activity Recognition Using Feature Fusion. IEEE Trans. Instrum. Meas. 2022, 71, 5503312. [Google Scholar] [CrossRef]
- Showmik, I.A.; Sanam, T.F.; Imtiaz, H. Human Activity Recognition from Wi-Fi CSI Data Using Principal Component-Based Wavelet CNN. Digit. Signal Process. 2023, 138, 104056. [Google Scholar] [CrossRef]
- Zou, H.; Yang, J.; Prasanna Das, H.; Liu, H.; Zhou, Y.; Spanos, C.J. WiFi and vision multimodal learning for accurate and robust device-free human activity recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 1–8. [Google Scholar]
- Yang, D.; Wang, T.; Sun, Y.; Wu, Y. Doppler shift measurement using complex-valued CSI of WiFi in corridors. In Proceedings of the 2018 3rd International Conference on Computer and Communication Systems (ICCCS), Nagoya, Japan, 27–30 April 2018; pp. 67–371. [Google Scholar]
- IEEE std 802.11 a-1999; Part 11: Wireless LAN Medium Access Control (MAC) and Physical Layer (PHY) Specifications: High-Speed Physical Layer in the 5 GHz Band. IEEE: New York, NY, USA, 1999.
- Halperin, D.; Hu, W.; Sheth, A.; Wetherall, D. Predictable 802.11 packet delivery from wireless channel measurements. ACM SIGCOMM Comput. Commun. Rev. 2010, 40, 159–170. [Google Scholar] [CrossRef]
- Yang, Z.; Zhou, Z.; Liu, Y. From RSSI to CSI: Indoor localization via channel response. ACM Comput. Surv. 2013, 46, 1–32. [Google Scholar] [CrossRef]
- Nee, R.V.; Prasad, R. OFDM for Wireless Multimedia Communications; Artech House, Inc.: Norwood, MA, USA, 2000. [Google Scholar]
- Toh, K.A. Kernel and Range Approach to Analytic Network Learning. Int. J. Networked Distrib. Comput. 2018, 7, 20–28. [Google Scholar] [CrossRef]
- Schäfer, J.; Barrsiwal, B.R.; Kokhkharova, M.; Adil, H.; Liebehenschel, J. Human Activity Recognition Using CSI Information with Nexmon. Appl. Sci. 2021, 11, 8860. [Google Scholar] [CrossRef]
- Wang, F.; Feng, J.; Zhao, Y.; Zhang, X.; Zhang, S.; Han, J. Joint activity recognition and indoor localization with WiFi fingerprints. IEEE Access 2019, 7, 80058–80068. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Database | Remark |
|---|---|---|
| 1D-CNN BiLSTM | HAR-RP: 3 volunteers * 7 activities * 20 samples = 420 samples (sit down, stand up, lie down, run, walk, fall and bend) [39] | The raw CSI amplitude data with 52-dimensional vector. |
| 2D-CNN | CSI signals are converted to RGB images by pseudo color map | |
| LSTM | HAR-RT: 1084 samples with 6 activities (sit, sit down, stand, stand up, walk and fall) [49] | Normalized raw CSI amplitude data with 256-dimensional vector. |
| DTW+kNN SVM-RBF | HAR-ARIL: 1394 samples with 6 activities (hand up, hand down, hand left, hand right, hand circle, and hand cross) [50] | Normalized raw CSI amplitude data with 52-dimensional vector. |
| Brief Description of the Experiments | Database |
|---|---|
| Experiment I Analysis of preprocessing parameters (cropping sizes, filtering band) (a) LSE, (b) SVM, and (c) KNN. | HAR-RP, HAR-RT HAR-ARIL |
| Experiment II Fusion of first level LSE and SVM-RBF scores using LSE, SVM-RBF, KNN, and ANnet. | HAR-RP, HAR-RT HAR-ARIL |
| Experiment III Comparison of proposed system with SOTA methods in Table 1. | HAR-RP, HAR-RT HAR-ARIL |
| Database | Size\Band | 0.02 | 0.05 | 0.1 | 0.5 |
|---|---|---|---|---|---|
| HAR-RP | 50 | 48.1 | 40.4 | 72.8 | 72.4 |
| 100 | 67.3 | 73.6 | 69.4 | 68.5 | |
| 200 | 72.5 | 71.9 | 69.3 | 64.5 | |
| 500 | 67.1 | 67.5 | 64.2 | 67.1 | |
| Database | Size\Band | 0.1 | 0.5 | 0.8 | 1.0 |
| HAR-RT | 50 | 30.4 | 45.1 | 48.8 | 71.4 |
| 100 | 39.1 | 48.8 | 50.7 | 66.4 | |
| 150 | 41.9 | 50.1 | 52.5 | 60.3 | |
| 200 | 46.5 | 51.2 | 53.5 | 55.2 | |
| Database | Size\Band | 0.1 | 0.3 | 0.5 | 0.8 |
| HAR-ARIL | 50 | 37.2 | 35.4 | 32.6 | 42.1 |
| 100 | 32.1 | 38.2 | 48.3 | 41.6 | |
| 150 | 35.1 | 48.2 | 50.1 | 51.3 | |
| 180 | 43.1 | 49.2 | 51.6 | 51.5 |
| Database | Size\Band | 0.02 | 0.05 | 0.1 | 0.5 |
|---|---|---|---|---|---|
| HAR-RP | 50 | 94.2 | 94.2 | 96.3 | 95.4 |
| 100 | 95.1 | 95.6 | 95.4 | 95.1 | |
| 200 | 94.5 | 94.8 | 94.9 | 94.5 | |
| 500 | 94.2 | 94.5 | 94.6 | 94.2 | |
| Database | Size\Band | 0.1 | 0.5 | 0.8 | 1.0 |
| HAR-RT | 50 | 69.5 | 81.1 | 81.1 | 95.4 |
| 100 | 78.8 | 81.5 | 81.4 | 92.6 | |
| 150 | 81.1 | 81.5 | 81.6 | 88.0 | |
| 200 | 81.1 | 81.5 | 81.6 | 79.2 | |
| Database | Size\Band | 0.1 | 0.3 | 0.5 | 0.8 |
| HAR-ARIL | 50 | 66.7 | 72.5 | 72.1 | 68.4 |
| 100 | 68.9 | 70.3 | 73.5 | 69.1 | |
| 150 | 69.2 | 68.2 | 68.1 | 69.1 | |
| 180 | 69.5 | 68.1 | 68.4 | 68.7 |
| Database | Prepressing | Cropping and Resizing | Normalized Passband |
|---|---|---|---|
| HAR-RP | process1 | 50 | 0.1 |
| process2 | 100 | 0.05 | |
| HAR-RT | process1 | 50 | 1.0 |
| process2 | 100 | 1.0 | |
| HAR-ARIL | process1 | 50 | 0.3 |
| process2 | 100 | 0.5 |
| Database | Size\Band | 0.02 | 0.05 | 0.1 | 0.5 |
|---|---|---|---|---|---|
| HAR-RP | 50 | 89.2 | 90.4 | 92.6 | 90.8 |
| 100 | 92.1 | 92.3 | 90.4 | 91.8 | |
| 200 | 91.6 | 89.2 | 92.0 | 90.6 | |
| 500 | 92.0 | 90.8 | 91.8 | 90.4 | |
| Database | Size\Band | 0.1 | 0.5 | 0.8 | 1.0 |
| HAR-RT | 50 | 56.7 | 63.2 | 72.4 | 82.3 |
| 100 | 54.5 | 60.4 | 68.4 | 76.7 | |
| 150 | 52.3 | 55.2 | 52.5 | 65.1 | |
| 200 | 50.3 | 54.5 | 53.5 | 60.2 | |
| Database | Size\Band | 0.1 | 0.3 | 0.5 | 0.8 |
| HAR-ARIL | 50 | 63.9 | 65.7 | 63.8 | 62.5 |
| 100 | 62.4 | 64.5 | 64.9 | 63.5 | |
| 150 | 63.5 | 64.1 | 63.5 | 63.2 | |
| 180 | 63.1 | 64.2 | 63.7 | 63.9 |
| HAR-RP | ||||||
| Method | LSE | SVM | Score Level Fusion | |||
| LSE | SVM | KNN | ANnet | |||
| W/O transform | process1 | process2 | 52.3 | 86.9 | 82.4 | 88.0 |
| 52.3 | 95.2 | |||||
| process2 | process1 | 69.0 | 91.7 | 89.1 | 90.4 | |
| 69.0 | 94.0 | |||||
| W transform | process1 | process2 | 92.8 | 97.6 | 95.4 | 97.6 |
| 92.8 | 96.4 | |||||
| process2 | process1 | 94.0 | 94.0 | 94.0 | 95.2 | |
| 90.4 | 94.0 | |||||
| HAR-RT | ||||||
| Method | SVM | SVM | Score Level Fusion | |||
| LSE | SVM | KNN | ANnet | |||
| W/O transform | process1 | process2 | 93.5 | 96.3 | 94.7 | 95.4 |
| 95.4 | 92.6 | |||||
| W transform | process1 | process2 | 94.5 | 96.4 | 95.2 | 95.4 |
| 95.4 | 92.6 | |||||
| Method | LSE | SVM | Score Level Fusion | |||
| LSE | SVM | KNN | ANnet | |||
| W/O transform | process1 | process2 | 79.2 | 93.5 | 90.3 | 92.6 |
| 71.4 | 92.6 | |||||
| process2 | process1 | 79.7 | 94.5 | 91.5 | 94.0 | |
| 66.3 | 95.4 | |||||
| W transform | process1 | process2 | 92.1 | 93.0 | 92.6 | 92.6 |
| 76.5 | 92.6 | |||||
| process2 | process1 | 88.9 | 92.1 | 89.3 | 90.8 | |
| 76.9 | 95.4 | |||||
| HAR-ARIL | ||||||
| Method | SVM | SVM | Score Level Fusion | |||
| LSE | SVM | KNN | ANnet | |||
| W/O transform | process1 | process2 | 72.5 | 78.4 | 74.2 | 75.5 |
| 72.5 | 73.5 | |||||
| W transform | process1 | process2 | 81.7 | 83.7 | 82.5 | 83.8 |
| 80.1 | 82.3 | |||||
| Method | KNN | SVM | Score Level Fusion | |||
| LSE | SVM | KNN | ANnet | |||
| W/O transform | process1 | process2 | 73.6 | 75.2 | 74.7 | 75.2 |
| 65.7 | 73.5 | |||||
| process2 | process1 | 72.5 | 74.8 | 73.1 | 72.6 | |
| 64.9 | 72.5 | |||||
| W transform | process1 | process2 | 74.3 | 82.9 | 82.4 | 82.5 |
| 70.8 | 82.3 | |||||
| process2 | process1 | 73.0 | 81.4 | 80.5 | 81.5 | |
| 69.6 | 80.1 | |||||
| HAR-RP | |
| Method | Execution Time (s) |
| ANnet-fusion | 15.7 |
| 1D-CNN | 47.2 |
| 2D-CNN | 59.8 |
| BiLSTM | 67.9 |
| HAR-RT | |
| Method | Execution Time (s) |
| ANnet-fusion | 58.3 |
| LSTM | 376.1 |
| HAR-ARIL | |
| Method | Execution Time (s) |
| ANnet-fusion | 18.6 |
| DTW+KNN | 3356 |
| SVM-RBF | 69 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lim, G.; Oh, B.; Kim, D.; Toh, K.-A. Human Activity Recognition via Score Level Fusion of Wi-Fi CSI Signals. Sensors 2023, 23, 7292. https://doi.org/10.3390/s23167292
Lim G, Oh B, Kim D, Toh K-A. Human Activity Recognition via Score Level Fusion of Wi-Fi CSI Signals. Sensors. 2023; 23(16):7292. https://doi.org/10.3390/s23167292
Chicago/Turabian StyleLim, Gunsik, Beomseok Oh, Donghyun Kim, and Kar-Ann Toh. 2023. "Human Activity Recognition via Score Level Fusion of Wi-Fi CSI Signals" Sensors 23, no. 16: 7292. https://doi.org/10.3390/s23167292
APA StyleLim, G., Oh, B., Kim, D., & Toh, K.-A. (2023). Human Activity Recognition via Score Level Fusion of Wi-Fi CSI Signals. Sensors, 23(16), 7292. https://doi.org/10.3390/s23167292