SUGAN: A Stable U-Net Based Generative Adversarial Network



Abstract
:1. Introduction
2. Related Work
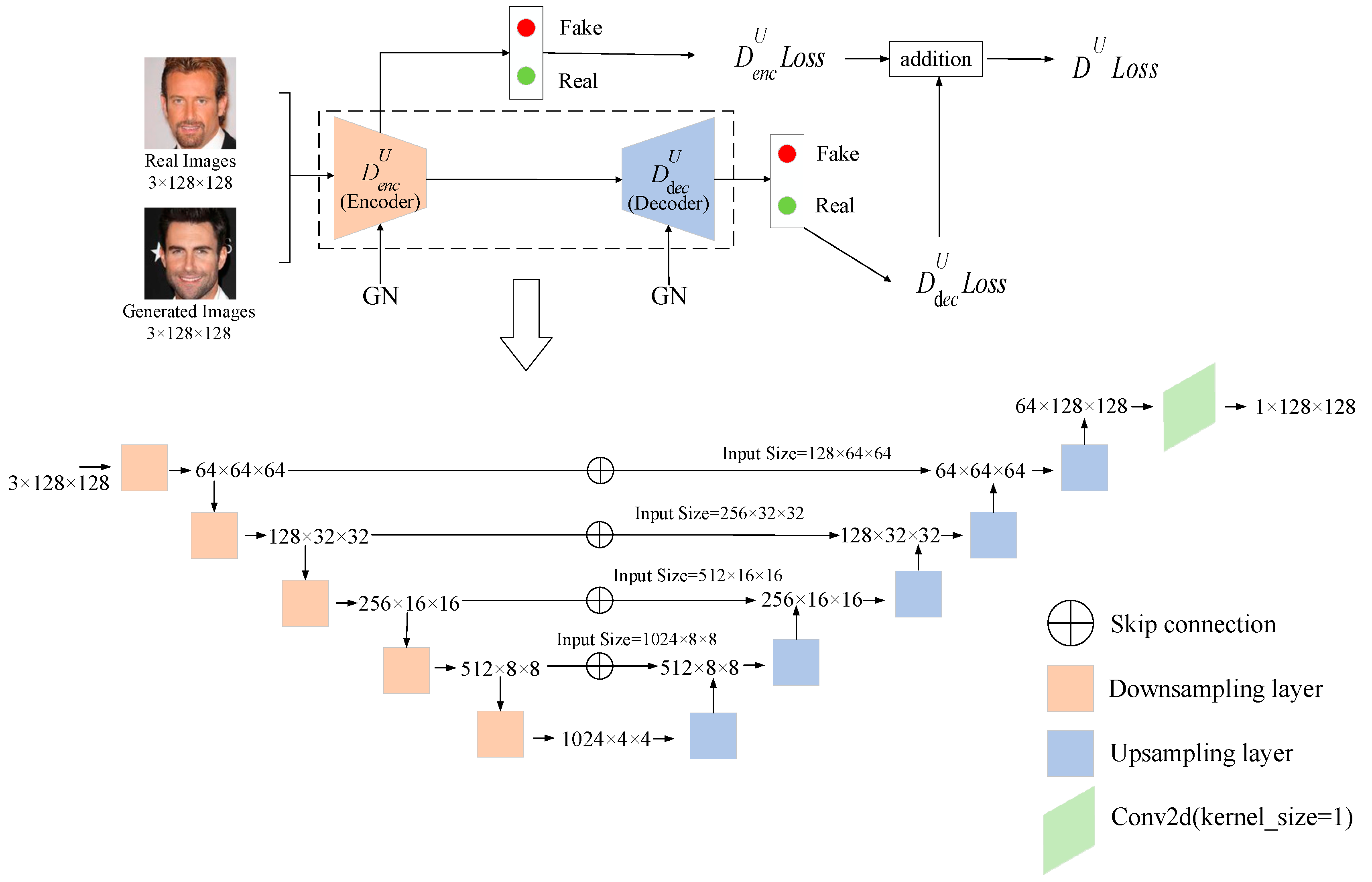
2.1. U-Net GAN
2.2. Normalization in GANs
- Model-wise or module-wise constraints. Model-wise constraints depend on full model while the module-wise constraints depend on the sum of internal modules.
- Sampling-based or non-sampling-based constraints. If a constraint approach requires sampling from a fixed pool of data, it is called a sampling-based constraint, otherwise it is called a non-sampling-based constraint.
- Hard or soft constraints. When constraining the gradient norms of any function in the discriminator, if none of these values is greater than a fixed value, the constraint is called a hard constraint, otherwise it is called a soft constraint.
3. Methods
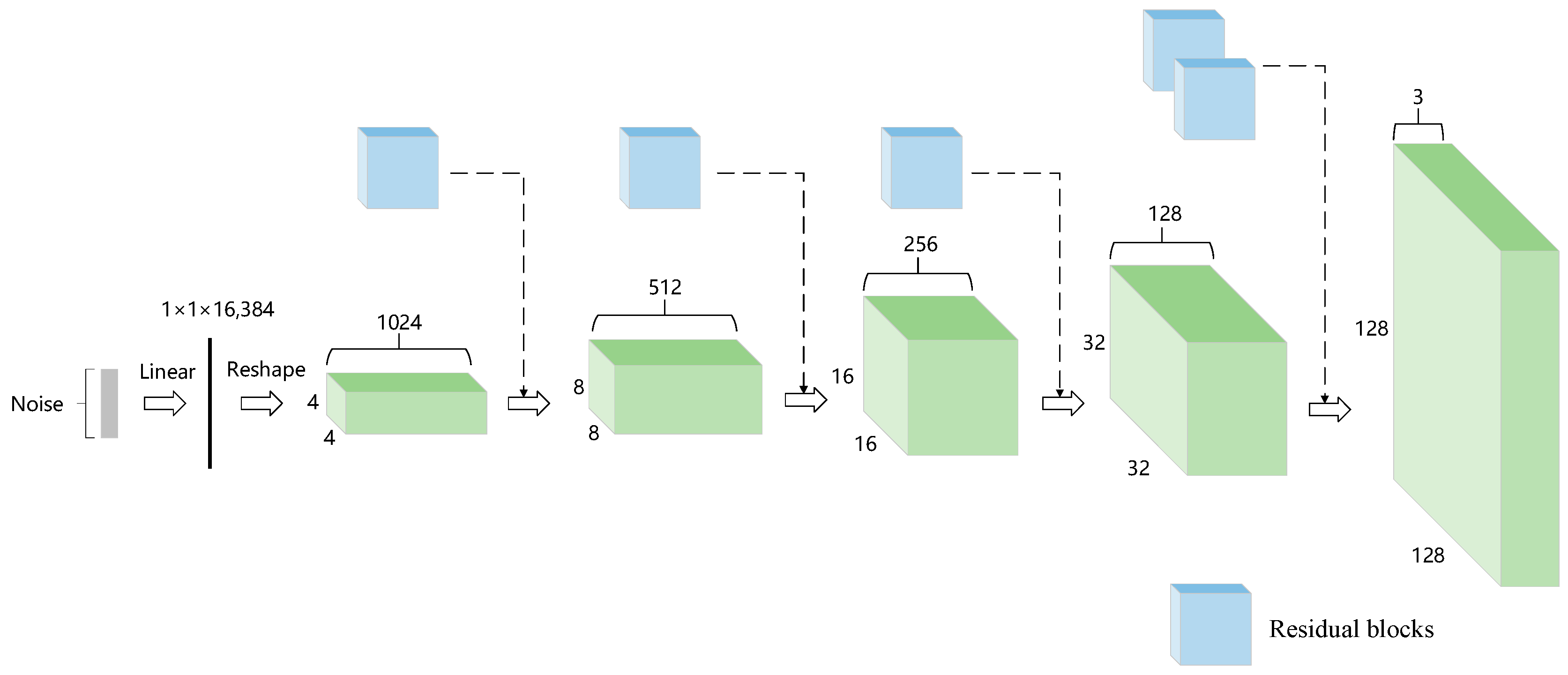
3.1. Generator Architecture
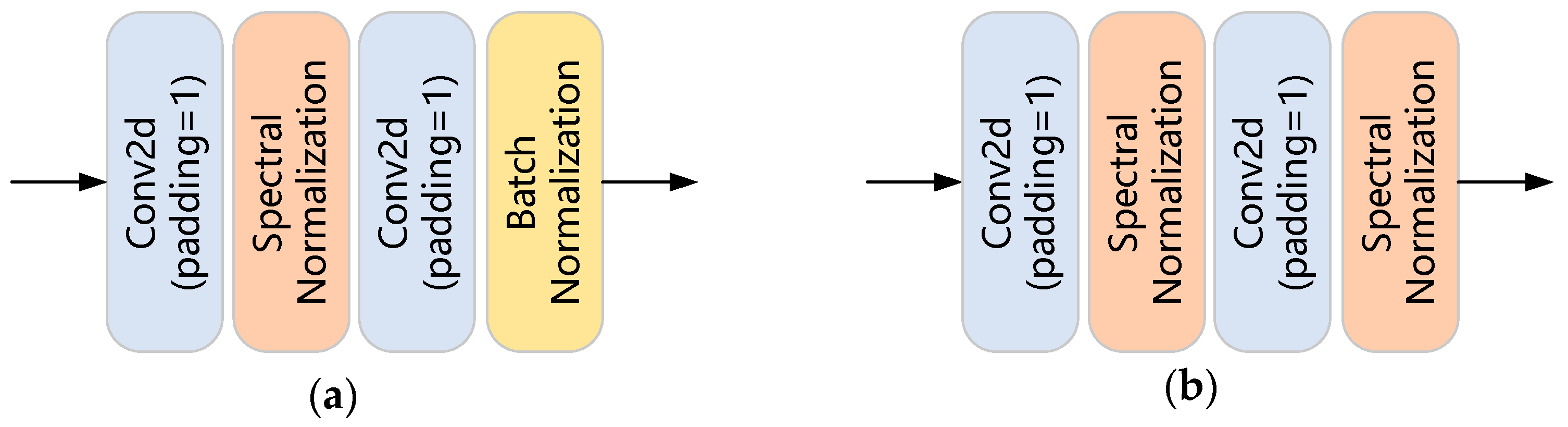
3.2. Discriminator Architecture
3.3. Loss Function
4. Experiments
4.1. Datasets
4.2. Evaluation Metrics
4.3. Results
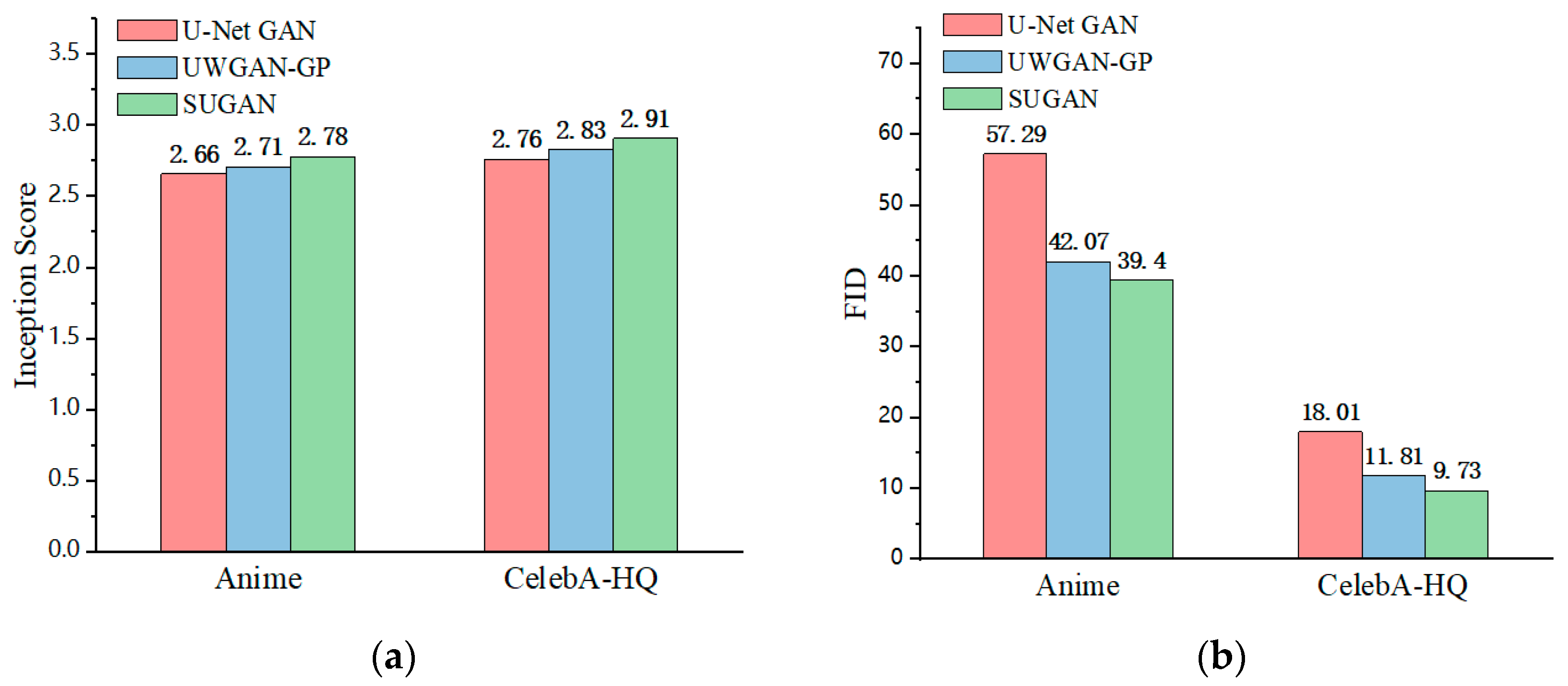
4.3.1. Unconditional Image Synthesis
4.3.2. Conditional Image Synthesis
4.3.3. Comparisons with an Alternative Improved Model
4.4. Hyperparameter Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020. [Google Scholar]
- Song, J.; Meng, C.; Ermon, S. Denoising diffusion implicit models. In Proceedings of the International Conference on Learning Representations, Virtual, 3–7 May 2021. [Google Scholar]
- Dhariwal, P.; Nichol, A. Diffusion models beat gans on image synthesis. In Proceedings of the 35th International Conference on Neural Information Processing Systems, Virtual, 6–14 December 2021. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 23–27 November 2014. [Google Scholar]
- Karras, T.; Aittala, M.; Laine, S.; Härkönen, E.; Hellsten, J.; Lehtinen, J.; Aila, T. Alias-free generative adversarial networks. In Proceedings of the 35th International Conference on Neural Information Processing Systems, Virtual, 6–14 December 2021. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Dai, M.; Hang, H.; Guo, X. Adaptive Feature Interpolation for Low-Shot Image Generation. In Proceedings of the Computer Vision-ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Kim, J.; Choi, Y.; Uh, Y. Feature statistics mixing regularization for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- He, J.; Shi, W.; Chen, K.; Fu, L.; Dong, C. Gcfsr: A generative and controllable face super resolution method without facial and gan priors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Liang, J.; Zeng, H.; Zhang, L. Details or artifacts: A locally discriminative learning approach to realistic image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Chen, Y.-I.; Chang, Y.-j.; Sun, Y.; Liao, S.-C.; Santacruz, S.R.; Yeh, H.-C. Generative adversarial network improves the resolution of pulsed STED microscopy. In Proceedings of the 2022 56th Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 31 October–2 November 2022. [Google Scholar]
- Qiao, T.; Zhang, J.; Xu, D.; Tao, D. Mirrorgan: Learning text-to-image generation by redescription. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhang, Y.; Li, M.; Li, R.; Jia, K.; Zhang, L. Exact feature distribution matching for arbitrary style transfer and domain generalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Tao, T.; Zhan, X.; Chen, Z.; van de Panne, M. Style-ERD: Responsive and coherent online motion style transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Yang, S.; Jiang, L.; Liu, Z.; Loy, C.C. Pastiche Master: Exemplar-Based High-Resolution Portrait Style Transfer. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Dalva, Y.; Altındiş, S.F.; Dundar, A. Vecgan: Image-to-image translation with interpretable latent directions. In Proceedings of the Computer Vision-ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Liu, S.; Ye, J.; Ren, S.; Wang, X. Dynast: Dynamic sparse transformer for exemplar-guided image generation. In Proceedings of the Computer Vision-ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Couairon, G.; Grechka, A.; Verbeek, J.; Schwenk, H.; Cord, M. Flexit: Towards flexible semantic image translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.-W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Kim, H.; Jhoo, H.Y.; Park, E.; Yoo, S. Tag2pix: Line art colorization using text tag with secat and changing loss. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Kim, J.; Kim, M.; Kang, H.; Lee, K. U-gat-it: Unsupervised generative attentional networks with adaptive layer-instance normalization for image-to-image translation. In Proceedings of the International Conference on Learning Representations, Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Babu, E.S.; Barthwal, A.; Kaluri, R. Sec-edge: Trusted blockchain system for enabling the identification and authentication of edge based 5G networks. Comput. Commun. 2023, 199, 10–29. [Google Scholar] [CrossRef]
- Deng, Y.; Lv, J.; Huang, D.; Du, S. Combining the theoretical bound and deep adversarial network for machinery openset diagnosis transfer. Neurocomputing 2023, 548, 126391. [Google Scholar] [CrossRef]
- Kang, M.; Zhu, J.; Zhang, R.; Park, J.; Shechtman, E.; Paris, S.; Park, T. Scaling up gans for text-to-image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]
- Zhang, J.; Peng, S.; Gao, Y.; Zhang, Z.; Hong, Q. APMSA: Adversarial perturbation against model stealing attacks. IEEE Trans. Inf. Forensics Secur. 2023, 18, 1667–1679. [Google Scholar] [CrossRef]
- Gao, J.; Zhang, J.; Liu, X.; Darrell, T.; Shelhamer, E.; Wang, D. Back to the source: Diffusion-driven test-time adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]
- Nguyen, T.H.; Van Le, T.; Tran, A. Efficient Scale-Invariant Generator with Column-Row Entangled Pixel Synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]
- Lee, D.; Lee, J.Y.; Kim, D.; Choi, J.; Kim, J. Fix the Noise: Disentangling Source Feature for Transfer Learning of StyleGAN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Liu, H.; Zhang, W.; Li, B.; Wu, H.; He, N.; Huang, Y.; Li, Y.; Ghanem, B.; Zheng, Y. Improving GAN Training via Feature Space Shrinkage. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]
- Wang, T.; Zhang, Y.; Fan, Y.; Wang, J.; Chen, Q. High-fidelity gan inversion for image attribute editing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Huang, S.; Wang, K.; Liu, H.; Chen, J.; Li, Y. Contrastive semi-supervised learning for underwater image restoration via re-liable bank. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]
- Xu, Y.; Yin, Y.; Jiang, L.; Wu, Q.; Zheng, C.; Loy, C.C.; Dai, B.; Wu, W. TransEditor: Transformer-based dual-space GAN for highly controllable facial editing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Chen, Y.; Yang, X.-H.; Wei, Z.; Heidari, A.A.; Zheng, N.; Li, Z.; Chen, H.; Hu, H.; Zhou, Q.; Guan, Q. Generative adversarial networks in medical image augmentation: A review. Comput. Biol. Med. 2022, 144, 105382. [Google Scholar] [CrossRef] [PubMed]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Paul Smolley, S. Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Brock, A.; Donahue, J.; Simonyan, K. Large scale GAN training for high fidelity natural image synthesis. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Chang, T.-Y.; Lu, C.-J. Tinygan: Distilling biggan for conditional image generation. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of gans for improved quality, stability, and variation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-attention generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Gui, J.; Sun, Z.; Wen, Y.; Tao, D.; Ye, J. A Review on Generative Adversarial Networks: Algorithms, Theory, and Applications. IEEE Trans. Knowl. Data Eng. 2023, 35, 3313–3332. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention-CMICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Schonfeld, E.; Schiele, B.; Khoreva, A. A u-net based discriminator for generative adversarial networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Miyato, T.; Kataoka, T.; Koyama, M.; Yoshida, Y. Spectral normalization for generative adversarial networks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Wu, Y.; Shuai, H.; Tam, Z.; Chiu, H. Gradient normalization for generative adversarial networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Arjovsky, M.; Bottou, L. Towards principled methods for training generative adversarial networks. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Kurach, K.; Lucic, M.; Zhai, X.; Michalski, M.; Gelly, S. A large-scale study on regularization and normalization in GANs. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Thanh-Tung, H.; Tran, T.; Venkatesh, S. Improving generalization and stability of generative adversarial networks. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Terjék, D. Adversarial lipschitz regularization. In Proceedings of the International Conference on Learning Representations, Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein gans. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Wei, X.; Gong, B.; Liu, Z.; Lu, W.; Wang, L. Improving the improved training of wasserstein GANs. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Wu, J.; Huang, Z.; Thoma, J.; Acharya, D.; Van Gool, L. Wasserstein divergence for gans. In Proceedings of the Computer Vision–ECCV 2018: 15th European Conference, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Liu, K.; Tang, W.; Zhou, F.; Qiu, G. Spectral regularization for combating mode collapse in gans. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Jiang, H.; Chen, Z.; Chen, M.; Liu, F.; Wang, D.; Zhao, T. On computation and generalization of generative adversarial networks under spectrum control. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Coates, A.; Ng, A.; Lee, H. An analysis of single-layer networks in unsupervised feature learning. In Proceedings of the Proceedings of the 14th International Conference on Artificial Intelligence and Statistics, Lauderdale, FL, USA, 11–13 April 2011. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of gans for improved quality, stability, and variation. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Park, M.; Lee, M.; Yu, S. HRGAN: A Generative Adversarial Network Producing Higher-Resolution Images than Training Sets. Sensors 2022, 22, 1435. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Normalization | Model-Wise | Non-Sampling-Based | Hard |
|---|---|---|---|
| GP | √ | ||
| SN | √ | √ | |
| GN | √ | √ | √ |
| Dataset | Number of Samples | Resolution |
|---|---|---|
| CelebA-HQ | 30,000 | 128 × 128 |
| Anime | 40,000 | 128 × 128 |
| CIFAR-10 | 60,000 | 32 × 32 |
| Model | Anime | CelebA-HQ | ||
|---|---|---|---|---|
| IS | FID | IS | FID | |
| DCGAN | 1.40 0.64 | 223.66 0.37 | 1.85 0.02 | 139.96 0.40 |
| LSGAN | 1.34 0.09 | 272.05 0.19 | 1.74 0.33 | 192.15 0.19 |
| WGAN | 2.21 0.38 | 120.26 0.81 | 2.31 0.79 | 101.34 0.26 |
| WGAN-GP | 2.29 0.11 | 85.61 0.85 | 2.36 0.12 | 54.87 0.83 |
| SNGAN | 2.37 0.21 | 73.32 0.81 | 2.48 0.79 | 43.23 0.31 |
| GNGAN | 2.48 0.66 | 66.58 0.50 | 2.52 0.46 | 24.37 0.79 |
| U-Net GAN | 2.66 0.64 | 57.29 0.81 | 2.76 0.68 | 18.01 0.20 |
| HRGAN | 2.70 0.05 | 43.15 0.42 | 2.81 0.51 | 12.44 0.16 |
| SUGAN (ours) | 2.78 0.13 | 39.40 0.71 | 2.91 0.77 | 9.73 0.94 |
| Model | CIFAR-10 | |
|---|---|---|
| IS | FID | |
| DCGAN | 6.46 0.30 | 38.73 0.61 |
| LSGAN | 5.89 0.62 | 43.08 0.30 |
| WGAN | 6.93 0.61 | 34.60 0.15 |
| WGAN-GP | 7.86 0.12 | 26.01 0.12 |
| SNGAN | 8.22 0.05 | 15.37 0.32 |
| GNGAN | 8.49 0.45 | 11.13 0.83 |
| U-Net GAN | 8.55 0.31 | 10.92 0.75 |
| HRGAN | 8.69 0.11 | 10.11 0.04 |
| SUGAN (ours) | 8.75 0.29 | 9.62 0.18 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, S.; Wang, L.; Zhang, M.; Zeng, C.; Meng, Y. SUGAN: A Stable U-Net Based Generative Adversarial Network. Sensors 2023, 23, 7338. https://doi.org/10.3390/s23177338
Cheng S, Wang L, Zhang M, Zeng C, Meng Y. SUGAN: A Stable U-Net Based Generative Adversarial Network. Sensors. 2023; 23(17):7338. https://doi.org/10.3390/s23177338
Chicago/Turabian StyleCheng, Shijie, Lingfeng Wang, Min Zhang, Cheng Zeng, and Yan Meng. 2023. "SUGAN: A Stable U-Net Based Generative Adversarial Network" Sensors 23, no. 17: 7338. https://doi.org/10.3390/s23177338
APA StyleCheng, S., Wang, L., Zhang, M., Zeng, C., & Meng, Y. (2023). SUGAN: A Stable U-Net Based Generative Adversarial Network. Sensors, 23(17), 7338. https://doi.org/10.3390/s23177338