

MCMNET: Multi-Scale Context Modeling Network for Temporal Action Detection


Abstract
:1. Introduction
- (1)
- We propose an effective two-stream network to aggregate the multi-scale temporal context. Using this model, we are able to detect action in some scenarios where the temporal relation of the action is complex.
- (2)
- A multi-scale context modeling network is proposed for temporal action detection. MCMNET consists of two main modules: MRCA and IE. MRCA processes the input data in multiple stages with different temporal scales, which allows MCMNET to learn both fine-grained relations in the early stage and coarse relations between composite actions in the latter stage. While IE is used to aggregate long-term and short-term context effectively, which makes the video features richer.
- (3)
- The experiments prove the convincing performance of MCMNET on three popular action detection benchmarks: ActivityNet-v1.3, Charades, and TSU.
2. Related Work
2.1. Action Recognition
2.2. Action Detection with CNN
2.3. Action Detection with Transformer
3. Proposed Method
3.1. Problem Formulation
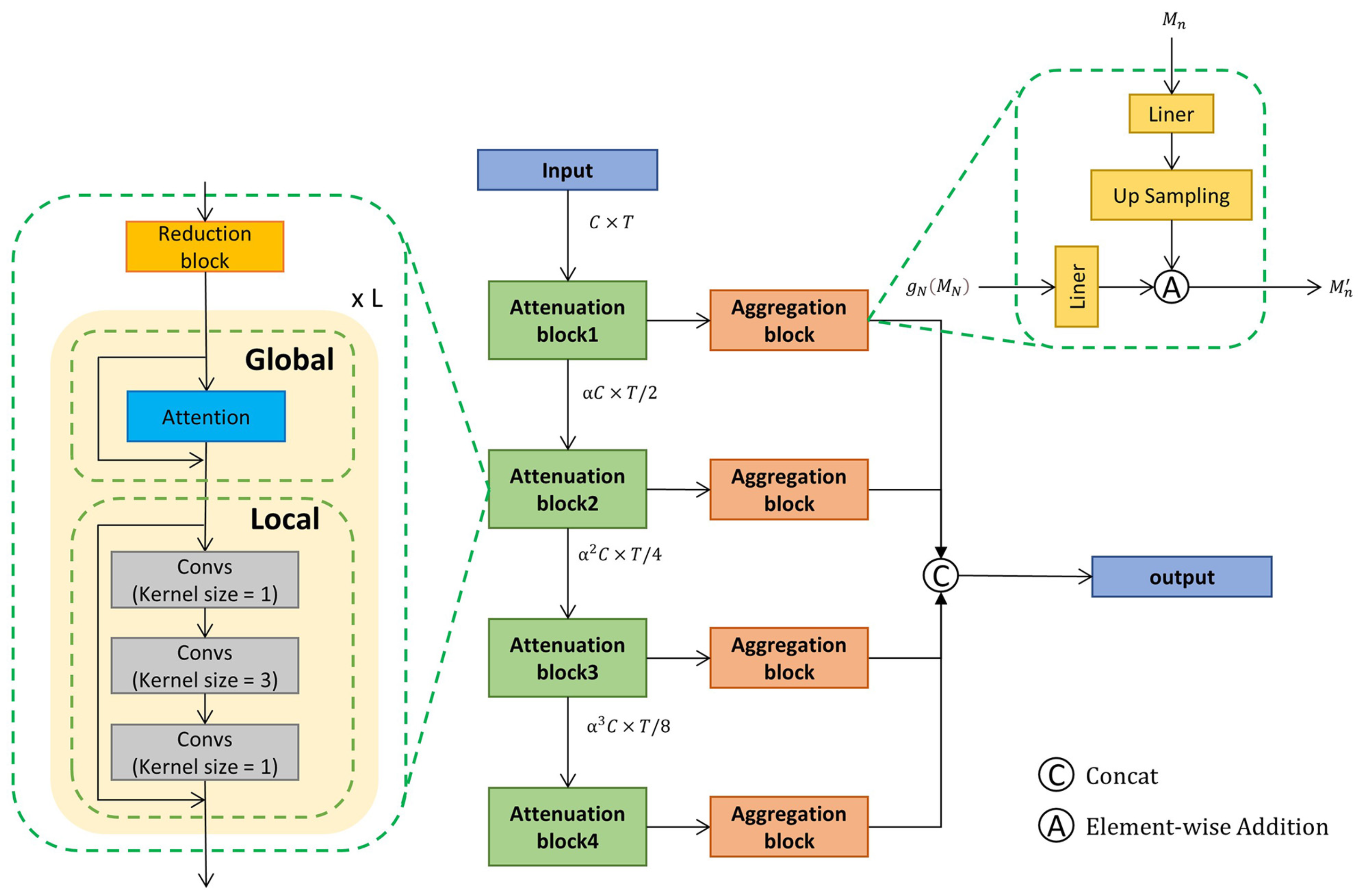
3.2. MCMNET Architecture
3.3. Multi-Resolution Context Aggregation
3.4. Information Enhancement Module
3.5. Norm and Localization
| Algorithm 1 Interpolation and Rescaling in Norm&Location. |
|
3.6. Training and Inference
4. Experiments
4.1. Datasets and Metrics
4.2. Implementation Details
4.3. Comparison with State-of-the-Arts Methods
4.4. Ablation Study
4.5. Visualization
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, Y.; Xiong, Y.; Wang, L.; Wu, Z.; Tang, X.; Lin, D. Temporal action detection with structured segment networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2914–2923. [Google Scholar]
- Shou, Z.; Wang, D.; Chang, S.F. Temporal Action Localization in Untrimmed Videos via Multi-stage CNNs. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1049–1058. [Google Scholar]
- Shou, Z.; Chan, J.; Zareian, A.; Miyazawa, K.; Chang, S.F. CDC: Convolutional-De-Convolutional Networks for Precise Temporal Action Localization in Untrimmed Videos. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1417–1426. [Google Scholar]
- Xu, H.; Das, A.; Saenko, K. R-c3d: Region convolutional 3d network for temporal activity detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5783–5792. [Google Scholar]
- Dai, X.; Singh, B.; Zhang, G.; Davis, L.S.; Chen, Y.Q. Temporal Context Network for Activity Localization in Videos. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5727–5736. [Google Scholar]
- Sun, Y.; Miao, Y.; Chen, J.; Pajarola, R. PGCNet: Patch graph convolutional network for point cloud segmentation of indoor scenes. Vis. Comput. 2020, 36, 2407–2418. [Google Scholar] [CrossRef]
- Xu, M.; Zhao, C.; Rojas, D.S.; Thabet, A.; Ghanem, B. G-tad: Sub-graph localization for temporal action detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10156–10165. [Google Scholar]
- Zeng, R.; Huang, W.; Tan, M.; Rong, Y.; Zhao, P.; Huang, J.; Gan, C. Graph convolutional networks for temporal action localization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7094–7103. [Google Scholar]
- Zeng, R.; Huang, W.; Tan, M.; Rong, Y.; Zhao, P.; Huang, J.; Gan, C. Graph Convolutional Module for Temporal Action Localization in Videos. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 6209–6223. [Google Scholar] [CrossRef] [PubMed]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Wang, L.; Yang, H.; Wu, W.; Yao, H.; Huang, H. Temporal Action Proposal Generation with Transformers. arXiv 2021, arXiv:2105.12043. [Google Scholar]
- Cheng, F.; Bertasius, G. TALLFormer: Temporal Action Localization with Long-memory Transformer. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Li, S.; Zhang, F.; Zhao, R.W.; Feng, R.; Yang, K.; Liu, L.N.; Hou, J. Pyramid Region-based Slot Attention Network for Temporal Action Proposal Generation. In Proceedings of the British Machine Vision Conference, London, UK, 21–24 November 2022. [Google Scholar]
- Qing, Z.; Su, H.; Gan, W.; Wang, D.; Wu, W.; Wang, X.; Qiao, Y.; Yan, J.; Gao, C.; Sang, N. Temporal Context Aggregation Network for Temporal Action Proposal Refinement. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 485–494. [Google Scholar]
- Weng, Y.; Pan, Z.; Han, M.; Chang, X.; Zhuang, B. An efficient spatio-temporal pyramid transformer for action detection. In Proceedings of the Computer Vision—ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part XXXIV. Springer: Berlin/Heidelberg, Germany, 2022; pp. 358–375. [Google Scholar]
- Wang, H.; Schmid, C. Action recognition with improved trajectories. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 3551–3558. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. Adv. Neural Inf. Process. Syst. 2014, 27. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y. Towards good practices for very deep two-stream convnets. arXiv 2015, arXiv:1507.02159. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional two-stream network fusion for video action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1933–1941. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? a new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Diba, A.; Fayyaz, M.; Sharma, V.; Karami, A.H.; Arzani, M.M.; Yousefzadeh, R.; Van Gool, L. Temporal 3d convnets: New architecture and transfer learning for video classification. arXiv 2017, arXiv:1711.08200. [Google Scholar]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. Slowfast networks for video recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6202–6211. [Google Scholar]
- Qiu, Z.; Yao, T.; Mei, T. Learning spatio-temporal representation with pseudo-3d residual networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5533–5541. [Google Scholar]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A closer look at spatiotemporal convolutions for action recognition. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6450–6459. [Google Scholar]
- Xie, S.; Sun, C.; Huang, J.; Tu, Z.; Murphy, K. Rethinking spatiotemporal feature learning: Speed-accuracy trade-offs in video classification. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 305–321. [Google Scholar]
- Wu, J.; Sun, P.; Chen, S.; Yang, J.; Qi, Z.; Ma, L.; Luo, P. Towards high-quality temporal action detection with sparse proposals. arXiv 2021, arXiv:2109.08847. [Google Scholar]
- He, Y.; Han, X.; Zhong, Y.; Wang, L. Non-Local Temporal Difference Network for Temporal Action Detection. Sensors 2022, 22, 8396. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.; Zhao, X.; Su, H.; Wang, C.; Yang, M. Bsn: Boundary sensitive network for temporal action proposal generation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Gao, J.; Shi, Z.; Wang, G.; Li, J.; Yuan, Y.; Ge, S.; Zhou, X. Accurate temporal action proposal generation with relation-aware pyramid network. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 10810–10817. [Google Scholar]
- Song, Y.; Kim, I. Spatio-Temporal Action Detection in Untrimmed Videos by Using Multimodal Features and Region Proposals. Sensors 2019, 19, 1085. [Google Scholar] [CrossRef] [PubMed]
- Gao, J.; Yang, Z.; Chen, K.; Sun, C.; Nevatia, R. Turn tap: Temporal unit regression network for temporal action proposals. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3628–3636. [Google Scholar]
- Buch, S.; Escorcia, V.; Shen, C.; Ghanem, B.; Carlos Niebles, J. Sst: Single-stream temporal action proposals. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2911–2920. [Google Scholar]
- Long, F.; Yao, T.; Qiu, Z.; Tian, X.; Luo, J.; Mei, T. Gaussian temporal awareness networks for action localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 344–353. [Google Scholar]
- Lin, T.; Liu, X.; Li, X.; Ding, E.; Wen, S. Bmn: Boundary-matching network for temporal action proposal generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3889–3898. [Google Scholar]
- Liu, Q.; Wang, Z. Progressive Boundary Refinement Network for Temporal Action Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Su, H.; Gan, W.; Wu, W.; Qiao, Y.; Yan, J. Bsn++: Complementary boundary regressor with scale-balanced relation modeling for temporal action proposal generation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; pp. 2602–2610. [Google Scholar]
- Chen, G.; Zheng, Y.D.; Wang, L.; Lu, T. DCAN: Improving temporal action detection via dual context aggregation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2022; pp. 248–257. [Google Scholar]
- Chao, Y.W.; Vijayanarasimhan, S.; Seybold, B.; Ross, D.A.; Deng, J.; Sukthankar, R. Rethinking the faster r-cnn architecture for temporal action localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1130–1139. [Google Scholar]
- Lin, T.; Zhao, X.; Shou, Z. Single Shot Temporal Action Detection. In Proceedings of the 25th ACM international conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017. [Google Scholar]
- Buch, S.; Escorcia, V.; Ghanem, B.; Fei-Fei, L.; Niebles, J.C. End-to-end, single-stream temporal action detection in untrimmed videos. In Proceedings of the British Machine Vision Conference 2017, London, UK, 4–7 September 2017; British Machine Vision Association: Durham, UK, 2019. [Google Scholar]
- Wang, C.; Cai, H.; Zou, Y.; Xiong, Y. Rgb stream is enough for temporal action detection. arXiv 2021, arXiv:2107.04362. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Qiu, H.; Ma, Y.; Li, Z.; Liu, S.; Sun, J. Borderdet: Border feature for dense object detection. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part I 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 549–564. [Google Scholar]
- Lin, C.; Xu, C.; Luo, D.; Wang, Y.; Tai, Y.; Wang, C.; Li, J.; Huang, F.; Fu, Y. Learning salient boundary feature for anchor-free temporal action localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 3320–3329. [Google Scholar]
- Yang, L.; Peng, H.; Zhang, D.; Fu, J.; Han, J. Revisiting anchor mechanisms for temporal action localization. IEEE Trans. Image Process. 2020, 29, 8535–8548. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Arnab, A.; Dehghani, M.; Heigold, G.; Sun, C.; Lučić, M.; Schmid, C. Vivit: A video vision transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 6836–6846. [Google Scholar]
- Bertasius, G.; Wang, H.; Torresani, L. Is space-time attention all you need for video understanding? In Proceedings of the ICML, Virtual, 18–24 July 2021; p. 4. [Google Scholar]
- Zhang, Y.; Li, X.; Liu, C.; Shuai, B.; Zhu, Y.; Brattoli, B.; Chen, H.; Marsic, I.; Tighe, J. Vidtr: Video transformer without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 13577–13587. [Google Scholar]
- Liu, Z.; Ning, J.; Cao, Y.; Wei, Y.; Zhang, Z.; Lin, S.; Hu, H. Video swin transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3202–3211. [Google Scholar]
- Liu, X.; Wang, Q.; Hu, Y.; Tang, X.; Zhang, S.; Bai, S.; Bai, X. End-to-end temporal action detection with transformer. IEEE Trans. Image Process. 2022, 31, 5427–5441. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.L.; Wu, J.; Li, Y. Actionformer: Localizing moments of actions with transformers. In Proceedings of the Computer Vision—ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part IV. Springer: Berlin/Heidelberg, Germany, 2022; pp. 492–510. [Google Scholar]
- Wang, X.; Qing, Z.; Huang, Z.; Feng, Y.; Zhang, S.; Jiang, J.; Tang, M.; Gao, C.; Sang, N. Proposal relation network for temporal action detection. arXiv 2021, arXiv:2106.11812. [Google Scholar]
- Shi, D.; Zhong, Y.; Cao, Q.; Zhang, J.; Ma, L.; Li, J.; Tao, D. ReAct: Temporal Action Detection with Relational Queries. arXiv 2022, arXiv:2207.07097v1. [Google Scholar]
- Nag, S.; Zhu, X.; Song, Y.Z.; Xiang, T. Proposal-free temporal action detection via global segmentation mask learning. In Proceedings of the Computer Vision—ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part III. Springer: Berlin/Heidelberg, Germany, 2022; pp. 645–662. [Google Scholar]
- Heilbron, F.C.; Escorcia, V.; Ghanem, B.; Niebles, J.C. Activitynet: A large-scale video benchmark for human activity understanding. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 961–970. [Google Scholar]
- Sigurdsson, G.A.; Varol, G.; Wang, X.; Farhadi, A.; Laptev, I.; Gupta, A. Hollywood in homes: Crowdsourcing data collection for activity understanding. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 510–526. [Google Scholar]
- Sigurdsson, G.A.; Divvala, S.; Farhadi, A.; Gupta, A. Asynchronous temporal fields for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 585–594. [Google Scholar]
- Yeung, S.; Russakovsky, O.; Jin, N.; Andriluka, M.; Mori, G.; Fei-Fei, L. Every moment counts: Dense detailed labeling of actions in complex videos. Int. J. Comput. Vis. 2018, 126, 375–389. [Google Scholar] [CrossRef]
- Dai, R.; Das, S.; Sharma, S.; Minciullo, L.; Garattoni, L.; Bremond, F.; Francesca, G. Toyota smarthome untrimmed: Real-world untrimmed videos for activity detection. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 2533–2550. [Google Scholar] [CrossRef] [PubMed]
- Idrees, H.; Zamir, A.R.; Jiang, Y.G.; Gorban, A.; Laptev, I.; Sukthankar, R.; Shah, M. The thumos challenge on action recognition for videos “in the wild”. Comput. Vis. Image Underst. 2017, 155, 1–23. [Google Scholar] [CrossRef]
- Zhao, H.; Torralba, A.; Torresani, L.; Yan, Z. Hacs: Human action clips and segments dataset for recognition and temporal localization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8668–8678. [Google Scholar]
- Xiong, Y.; Wang, L.; Wang, Z.; Zhang, B.; Song, H.; Li, W.; Lin, D.; Qiao, Y.; Van Gool, L.; Tang, X. Cuhk & ethz & siat submission to activitynet challenge 2016. arXiv 2016, arXiv:1608.00797. [Google Scholar]
- Heilbron, F.C.; Barrios, W.; Escorcia, V.; Ghanem, B. Scc: Semantic context cascade for efficient action detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3175–3184. [Google Scholar]
- Dai, R.; Das, S.; Minciullo, L.; Garattoni, L.; Francesca, G.; Bremond, F. Pdan: Pyramid dilated attention network for action detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2021; pp. 2970–2979. [Google Scholar]
- Liu, X.; Bai, S.; Bai, X. An empirical study of end-to-end temporal action detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 20010–20019. [Google Scholar]
- Piergiovanni, A.; Ryoo, M. Temporal gaussian mixture layer for videos. In Proceedings of the International Conference on Machine learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 5152–5161. [Google Scholar]
- Dai, R.; Das, S.; Kahatapitiya, K.; Ryoo, M.S.; Brémond, F. MS-TCT: Multi-scale temporal convtransformer for action detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 20041–20051. [Google Scholar]
- Ryoo, M.S.; Gopalakrishnan, K.; Kahatapitiya, K.; Xiao, T.; Rao, K.; Stone, A.; Lu, Y.; Ibarz, J.; Arnab, A. Token turing machines. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 19070–19081. [Google Scholar]
- Tirupattur, P.; Duarte, K.; Rawat, Y.S.; Shah, M. Modeling multi-label action dependencies for temporal action localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1460–1470. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | 0.5 | 0.75 | 0.95 | Average |
|---|---|---|---|---|
| SCC [66] | 40.00 | 17.90 | 4.70 | 21.70 |
| CDC [3] | 45.30 | 26.00 | 0.20 | 23.80 |
| BSN [29] | 46.45 | 29.96 | 8.02 | 30.03 |
| PGCN [6] | 48.26 | 33.16 | 3.27 | 31.11 |
| BMN [35] | 50.07 | 34.78 | 8.29 | 33.85 |
| TSCN [67] | 35.30 | 21.40 | 5.30 | 21.70 |
| G-TAD [7] | 50.36 | 34.60 | 9.02 | 34.09 |
| E2E-TAD [68] | 50.47 | 35.99 | 10.83 | 35.10 |
| Actionformer [54] | 53.50 | 36.20 | 8.2 | 35.6 |
| TadTR [53] | 49.12 | 32.58 | 8.63 | 32.30 |
| MCMNET (ours) | 46.70 | 34.90 | 6.38 | 32.83 |
| Method | Charades | TSU | MultiTHUMOS | GFLOPs |
|---|---|---|---|---|
| R-C3D [4] | 12.7 | 8.7 | - | - |
| PDAN [67] | 23.7 | 32.7 | 40.2 | 3.2 |
| TGM [69] | 20.6 | 26.7 | 37.2 | 1.2 |
| MS-TCT [70] | 25.4 | 33.7 | 43.1 | 6.6 |
| TTM [71] | 28.8 | - | - | 0.8 |
| MLAD [72] | 18.4 | - | 42.2 | 44.8 |
| MCMNet (ours) | 27.3 | 33.1 | 43.0 | 24.7 |
| Reduction Block | Global Block | Local Block | Aggregation Block | 0.5 | 0.75 | 0.95 | Avg. |
|---|---|---|---|---|---|---|---|
| × | × | × | × | 40.88 | 26.93 | 2.57 | 25.71 |
| ✓ | × | × | × | 41.92 | 27.35 | 2.92 | 27.96 |
| ✓ | ✓ | × | × | 42.61 | 30.78 | 4.03 | 28.06 |
| ✓ | ✓ | ✓ | × | 44.02 | 32.18 | 5.65 | 30.73 |
| ✓ | ✓ | ✓ | ✓ | 46.70 | 34.90 | 6.38 | 32.83 |
| Reduction Block | Global Block | Local Block | Aggregation Block | Charades | TSU |
|---|---|---|---|---|---|
| × | × | × | × | 25.9 | 31.4 |
| ✓ | × | × | × | 26.3 | 32.0 |
| ✓ | ✓ | × | × | 26.8 | 32.3 |
| ✓ | ✓ | ✓ | × | 27.1 | 32.9 |
| ✓ | ✓ | ✓ | ✓ | 27.3 | 33.1 |
| Expasion Block | Fixation Block | 0.5 | 0.75 | 0.95 | Avg. |
|---|---|---|---|---|---|
| × | × | 41.02 | 28.51 | 5.18 | 30.38 |
| × | ✓ | 43.97 | 29.78 | 5.69 | 31.14 |
| ✓ | × | 41.48 | 31.22 | 5.10 | 30.81 |
| ✓ | ✓ | 46.70 | 34.90 | 6.38 | 32.83 |
| Expasion Block | Fixation Block | Charades | TSU |
|---|---|---|---|
| × | × | 26.1 | 32.0 |
| × | ✓ | 26.3 | 32.7 |
| ✓ | × | 25.9 | 32.1 |
| ✓ | ✓ | 27.3 | 33.1 |
| Charades | TSU | ||
|---|---|---|---|
| 1 | 1 | 26.2 | 32.1 |
| 1 | 1.5 | 26.7 | 32.7 |
| 2 | 1 | 27.0 | 33.0 |
| 2 | 1.5 | 27.3 | 33.1 |
| 2 | 2 | 27.2 | 32.9 |
| 4 | 2 | 26.5 | 32.6 |
| Block Number N | Charades | TSU |
|---|---|---|
| 1 | 26.6 | 32.1 |
| 3 | 26.8 | 32.6 |
| 5 | 27.1 | 32.9 |
| 7 | 27.3 | 33.1 |
| 9 | 27.2 | 32.8 |
| 11 | 27.0 | 32.5 |
| MRCA | IE (Expansion Block) | IE (Fixation Block) | Tcost (s) | GFLOPs |
|---|---|---|---|---|
| ✓ | × | × | 0.133 | 10.2 |
| ✓ | ✓ | × | 0.171 | 17.5 |
| ✓ | x | ✓ | 0.290 | 17.4 |
| ✓ | ✓ | ✓ | 0.312 | 24.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Zhou, F.; Ma, C.; Wang, D.; Zhang, W. MCMNET: Multi-Scale Context Modeling Network for Temporal Action Detection. Sensors 2023, 23, 7563. https://doi.org/10.3390/s23177563
Zhang H, Zhou F, Ma C, Wang D, Zhang W. MCMNET: Multi-Scale Context Modeling Network for Temporal Action Detection. Sensors. 2023; 23(17):7563. https://doi.org/10.3390/s23177563
Chicago/Turabian StyleZhang, Haiping, Fuxing Zhou, Conghao Ma, Dongjing Wang, and Wanjun Zhang. 2023. "MCMNET: Multi-Scale Context Modeling Network for Temporal Action Detection" Sensors 23, no. 17: 7563. https://doi.org/10.3390/s23177563
APA StyleZhang, H., Zhou, F., Ma, C., Wang, D., & Zhang, W. (2023). MCMNET: Multi-Scale Context Modeling Network for Temporal Action Detection. Sensors, 23(17), 7563. https://doi.org/10.3390/s23177563