

A Smart Home Digital Twin to Support the Recognition of Activities of Daily Living

 , ,
, ,  , and
, and
Abstract
:1. Introduction
1.1. A Variable and Sparse Unevenly Sampled Time Series
- Partial observability and sparsity of the data: The input data in HAR consists of traces captured by a variety of sensors, including motion sensors, door sensors, temperature sensors, and more, integrated into the environment or objects within the house [6]. However, each sensor has a limited field of view, resulting in most of the residents’ movements going unobserved by the sensor network in a typical smart home setup. Unlike HAR in videos, where the context of human actions, such as objects of interest or the position of obstacles, can be captured in the images, the sparsity of ambient sensors in HAR does not provide information beyond their field of view. Each sensor activation alone provides limited information about the current activity. For example, the activation of a motion sensor in the kitchen could indicate activities such as “cooking”, “washing dishes”, or “housekeeping”. Therefore, the information from multiple sensors needs to be combined to infer the current activity accurately. Additionally, each sensor activation provides only a partial piece of information about the activity and the state of the environment, unlike videos where both the agent performing the activity and the environment state are visible. Consequently, the time series of sensor activity traces cannot be approximated as a Markov chain. Instead, estimating the context or current state of the environment relies on past information and the relationship with other sensors.
- Variability of the data: Activity traces between different households exhibit significant variations. The variability arises from differences in house structures, layouts, and equipment. House layouts can vary in terms of apartments, houses with gardens, houses with multiple floors, the presence of bathrooms and bedrooms, open-plan or separate kitchens, and more. The number and types of sensors can also differ significantly between homes. For instance, datasets like MIT [7] use 77–84 sensors for each apartment, while the Kasteren dataset [8] uses 14–21 sensors. The ARAS dataset [9] includes apartments with 20 sensors, while the Orange4Home dataset [10] is based on an apartment equipped with 236 sensors. All these factors, including home topography, sensor count, and their placement, can result in radical differences in activity traces. The second cause of variability stems from household composition and residents’ living habits. ADLs vary depending on the residents’ habits, hobbies, and daily routines, leading to different class balances among ADLs. For example, the typical day of a student, a healthy adult, or an elderly person with frailty will exhibit distinct patterns. Furthermore, the more residents there are, the more the sensor activation traces corresponding to each resident’s activities become intertwined, leading to complex scenarios involving composite actions, concurrent activities, and interleaved activities.
1.2. Digital Twins for Generating Similar Data
1.3. Contributions
- We propose a novel approach that paves the way for digital twins in the context of smart homes.
- We enhance the Virtual Home [16] video-based data simulator to support sensor-based data simulation for smart homes, which we refer to as VirtualSmartHome.
- We demonstrate, through an illustrative example, that we can replicate a real apartment to generate data for training an ADL classification algorithm.
- Our study validates the effectiveness of our approach in generating data that closely resembles real-life scenarios and enables the training of an ADL recognition algorithm.
- We outline a tool and methodology for creating digital twins for smart homes, encompassing a simulator for ADLs in smart homes and a replicable approach for modeling real-life apartments and scenarios.
- The proposed tool and methodology can be utilized to develop more effective ADL classification algorithms and enhance the overall performance of smart home systems.
2. Related Work
2.1. Machine Learning Algorithms for Activity Recognition Based on Smart Home IoT Data
2.2. Activities of Daily Living Datasets
2.3. Existing Home Simulators
3. Virtual Smart Home: The Simulator
3.1. Design of Virtual Smart Home
- 1.
- Interactive Objects: While Virtual Home already offers a variety of objects for inclusion in apartments, many are passive and non-interactive. To address this limitation, we added the functionality to interact with some new objects. Agents can now open trash cans, the drawers of column cabinets, and push on toilet faucets. Objects with doors are implemented by splitting them into two parts—one static and one capable of rotation around an axis to simulate interaction. Fluid objects like toilet faucets are simulated by placing the origin point of the fluid at its supposed source.
- 2.
- Simulation Time Acceleration: To generate a large volume of data quickly, we implemented the ability to accelerate simulation times. This feature utilizes the Time.timeScale function of the Unity game engine. However, the acceleration cannot surpass the rendering time of the Unity game engine, resulting in a maximum four-fold increase in simulation speed.
- 3.
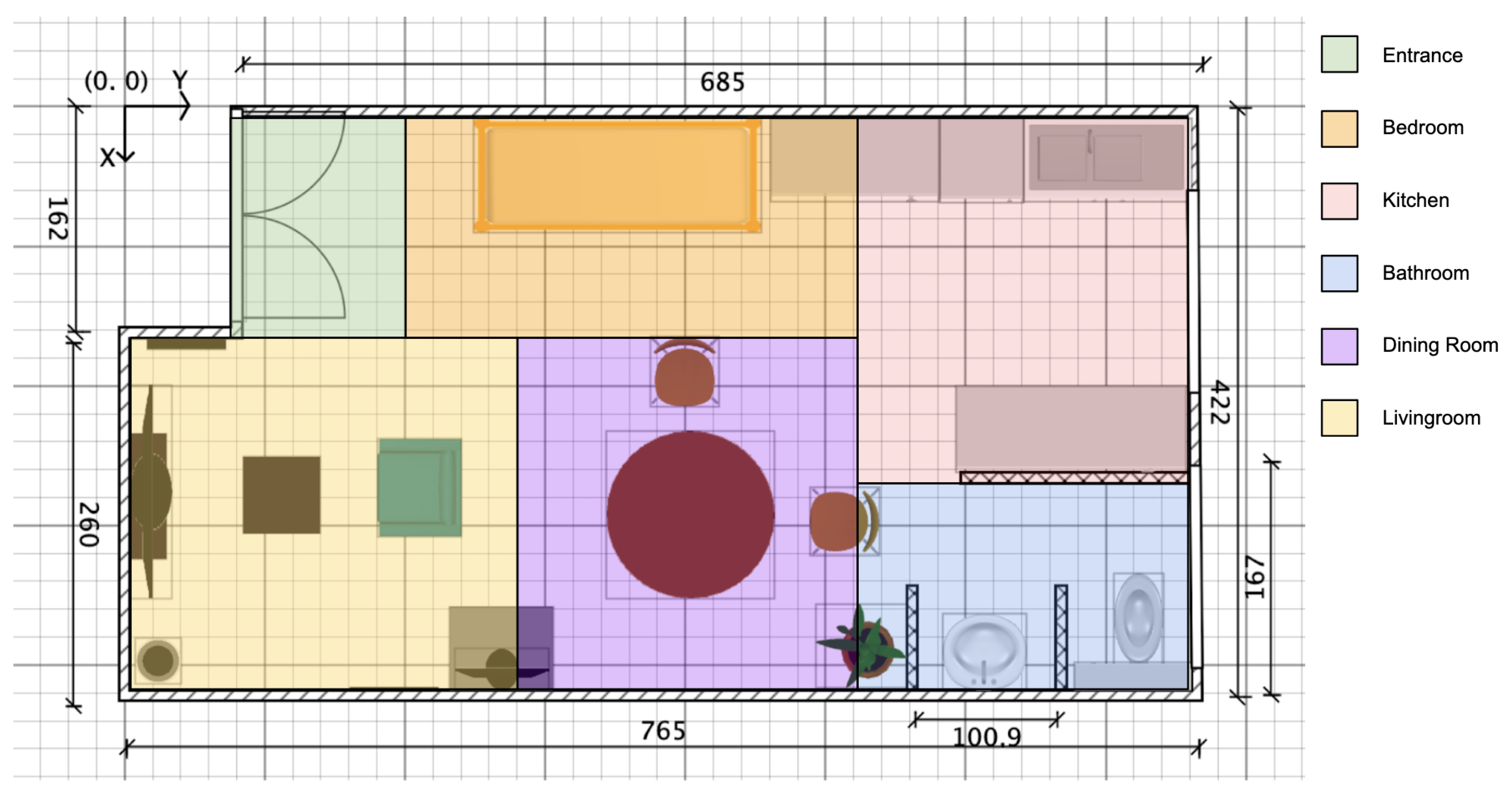
- Real-Life Apartment Replication and Room Creation: To replicate a real-life apartment, we propose a methodology that involves creating a 2D map of the flat using tools like Sweet Home 3D [52]. This map is then reproduced in Virtual Home, respecting the hierarchical object structure imposed by the simulator. Finally, the interactive objects are placed in a manner similar to their real-world counterparts. We demonstrated the effectiveness of this method by replicating a real-life intelligent apartment based on our room dimension measurements. Additionally, we have introduced the ability to create new rooms, such as outdoor and entrance areas.
- 4.
- IoT Sensors: While Virtual Home previously focused on recording activities using videos, we have implemented IoT sensors to enhance the simulation. The following sensors have been incorporated: (1) opening/closing sensors, (2) pressure sensors, (3) lights, (4) power consumption, and (5) zone occupancy sensors. Except for the zone occupancy sensors, all other sensors are simulated using the environment graph of the scene. This graph lists all objects in the scene with their corresponding states (e.g., closed/open, on/off). The zone occupancy sensor takes the form of a sensitive floor, implemented using a raycast. It originates from the center of the avatar and is directed downwards. The floor of the flat is divided into rooms, and the intersection with the floor identifies the room in which the avatar is located.
- 5.
- Simulation Interface: We have developed an interface that allows users to launch simulations by specifying the apartment, ambient sensors, scenarios, date, and time. The interface facilitates the scripting of each labeled activity for reproduction in the simulation. It provides three main functions: (1) the creation of an experiment configuration file, where the simulation flat and desired sensor data can be chosen; (2) the creation of a scenario configuration file, offering choices such as experiment date, simulation acceleration, and various activities with their durations; (3) the association of an experiment configuration file with a scenario configuration file and the subsequent launch of the simulation. This functionality enables the storage of synthetic sensor logs in a database file and provides a comprehensive record of the conducted experiment, including the experiment configuration file and the scenario configuration file.
3.2. Assessing the Simulator through Dataset Creation
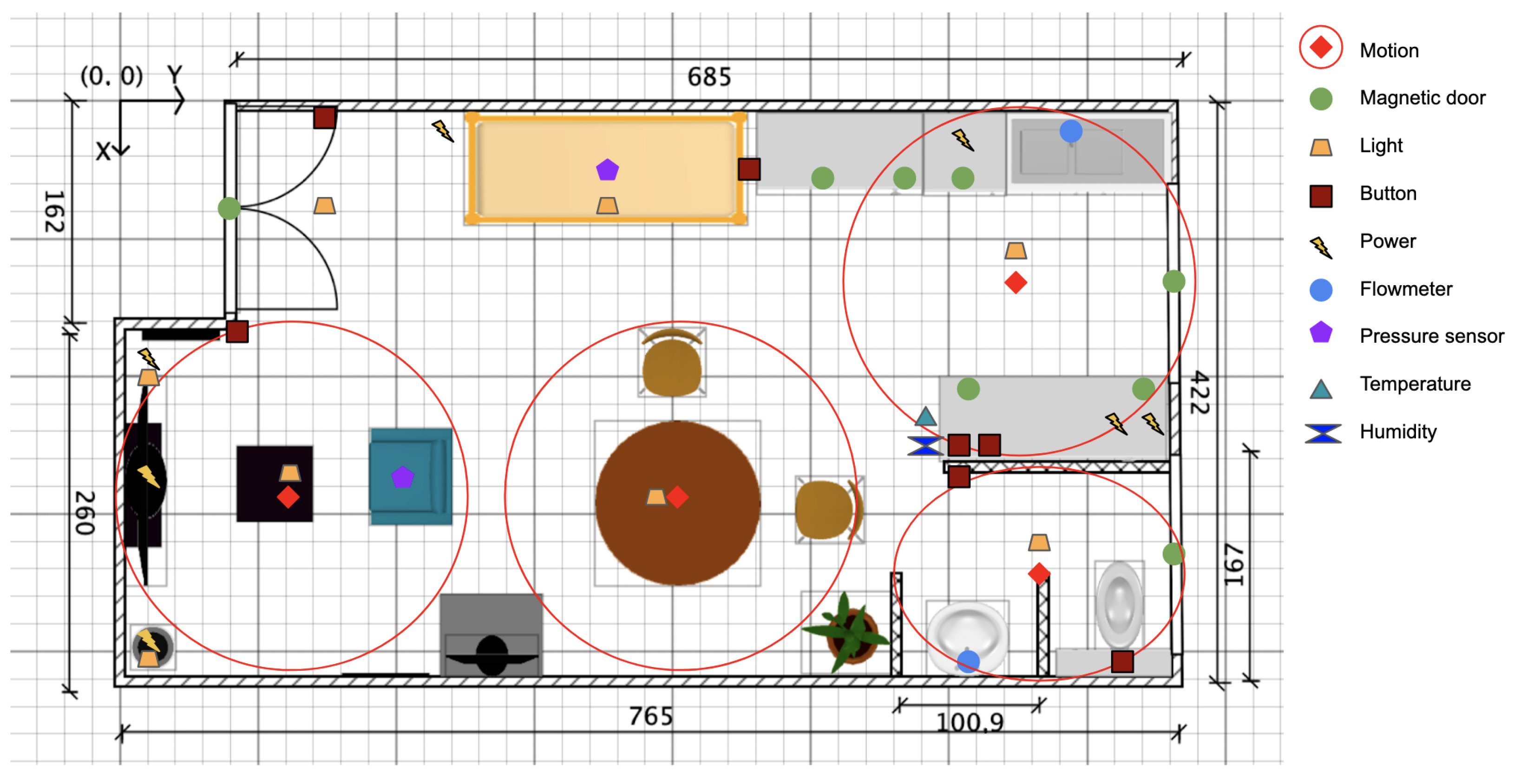
3.2.1. The Smart Apartment
- 1.
- A sensitive floor that tracks the movement or presence of a person in different areas.
- 2.
- Motion sensors placed strategically to detect motion in specific locations.
- 3.
- Magnetic open/close sensors to monitor the status of doors or windows.
- 4.
- Smart lights that can be controlled remotely or manually adjusted by switches.
- 5.
- Smart plugs to monitor the status and power consumption of various devices such as the stove, oven, kettle, outlets, and television.
- 6.
- Pressure sensors installed on the bed and sofa to detect occupancy.
3.2.2. The Ground Truth Dataset
- 1.
- Morning scenario: This scenario involved getting out of bed and going through a typical morning routine before heading to work.
- 2.
- Lunchtime scenario: In this scenario, participants returned home from work, prepared and ate lunch, and then went back to work.
- 3.
- Evening scenario: This scenario focused on participants returning home for the evening until it was time to go to bed.
3.2.3. The Synthetic Dataset
4. Comparison between Synthetic Data and Real Data
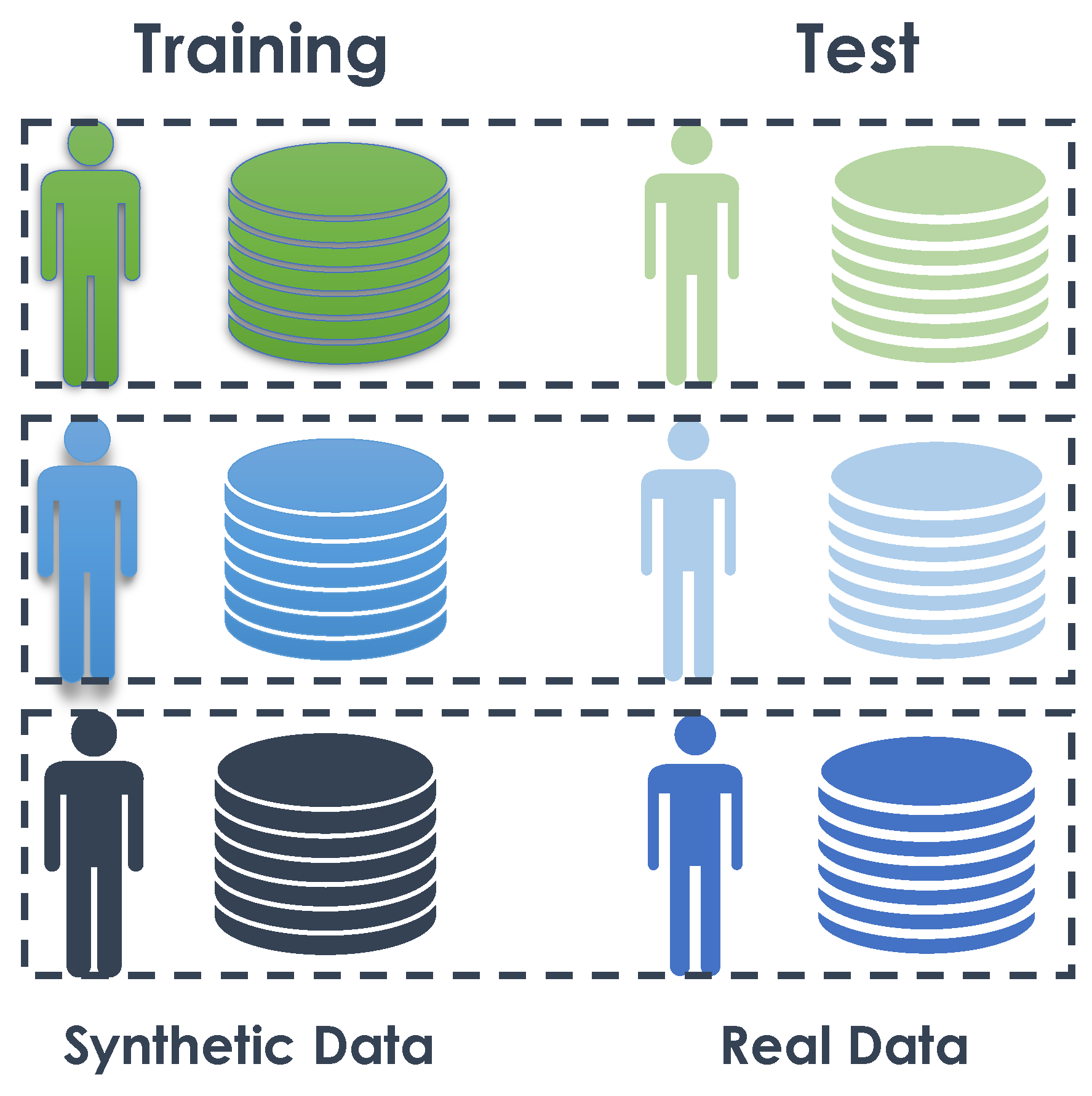
- 1.
- Training and validating on synthetic data using three subjects with leave-one-out subject validation.
- 2.
- Training and validating on real data using three subjects with leave-one-out subject validation.
- 3.
- Training the algorithm on synthetic data from one subject and validating it on the real data of the same subject.
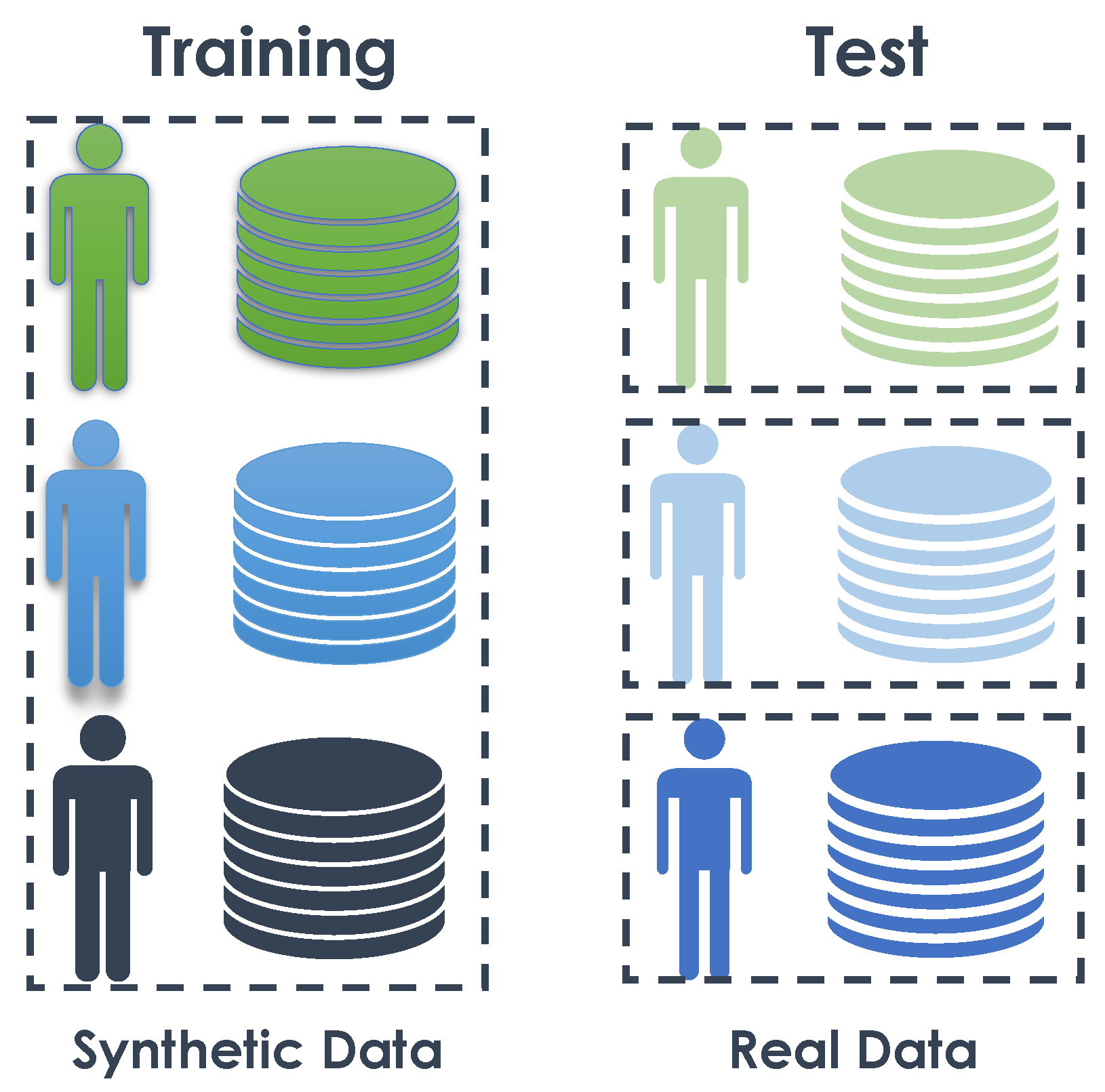
- 4.
- Training the algorithm on synthetic data from all subjects and validating it on the real data for each subject.
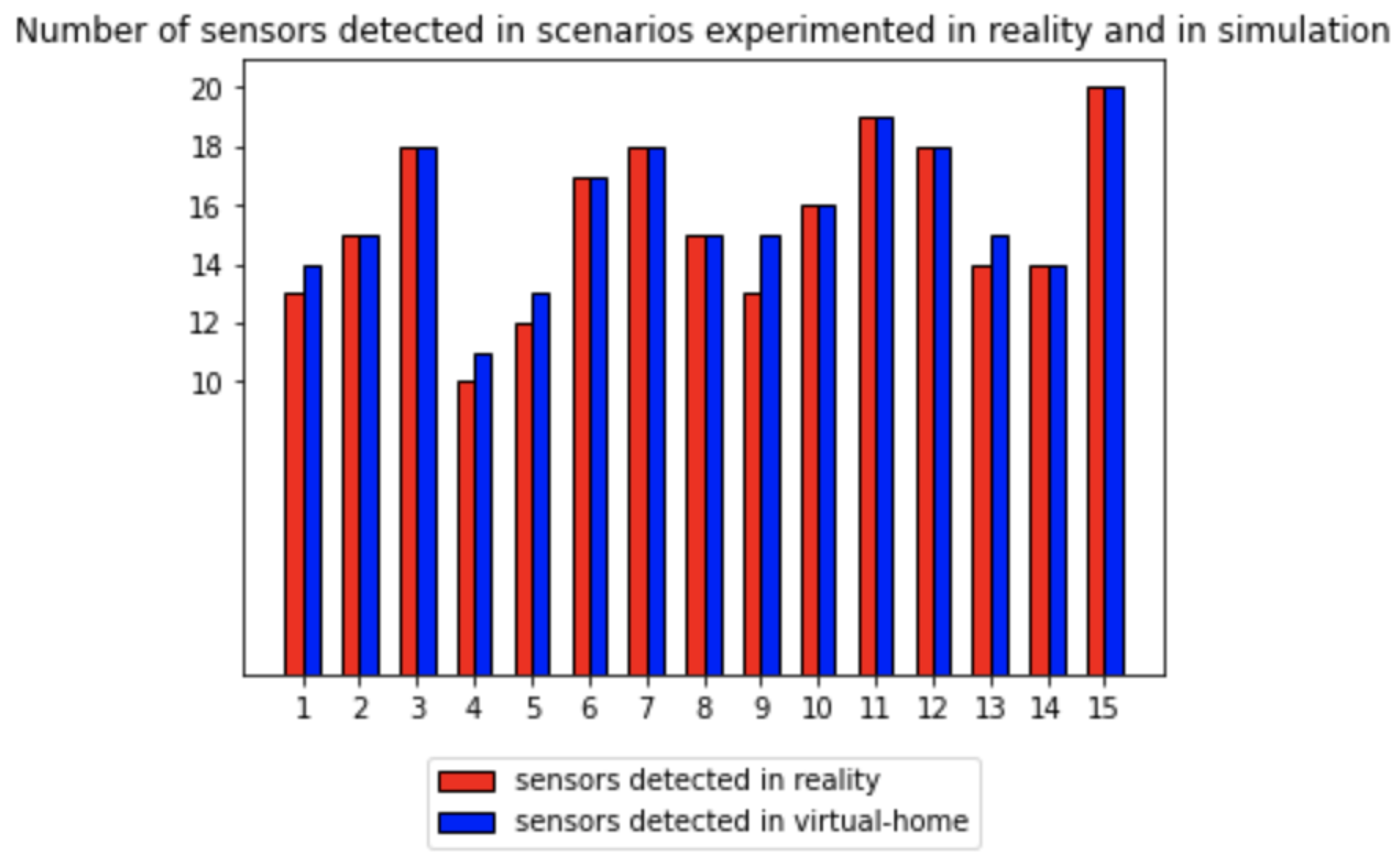
4.1. Comparison of Triggered Sensors in Real and Synthetic Logs for Similar Scenarios
4.2. Comparison with Cross-Correlation
4.3. Activity Recognition
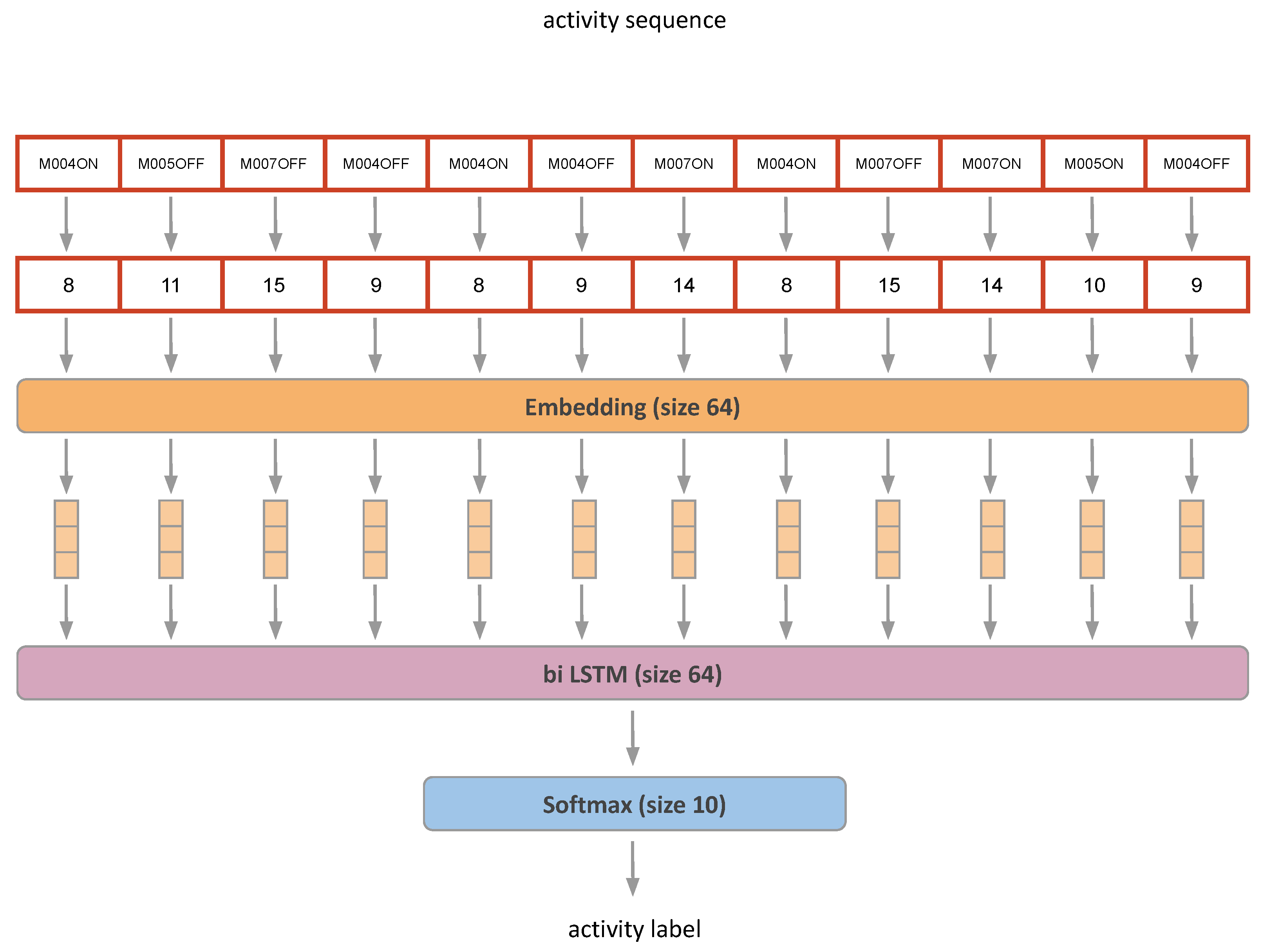
4.3.1. The Activity Recognition Algorithm
4.3.2. Preprocessing and Training Details
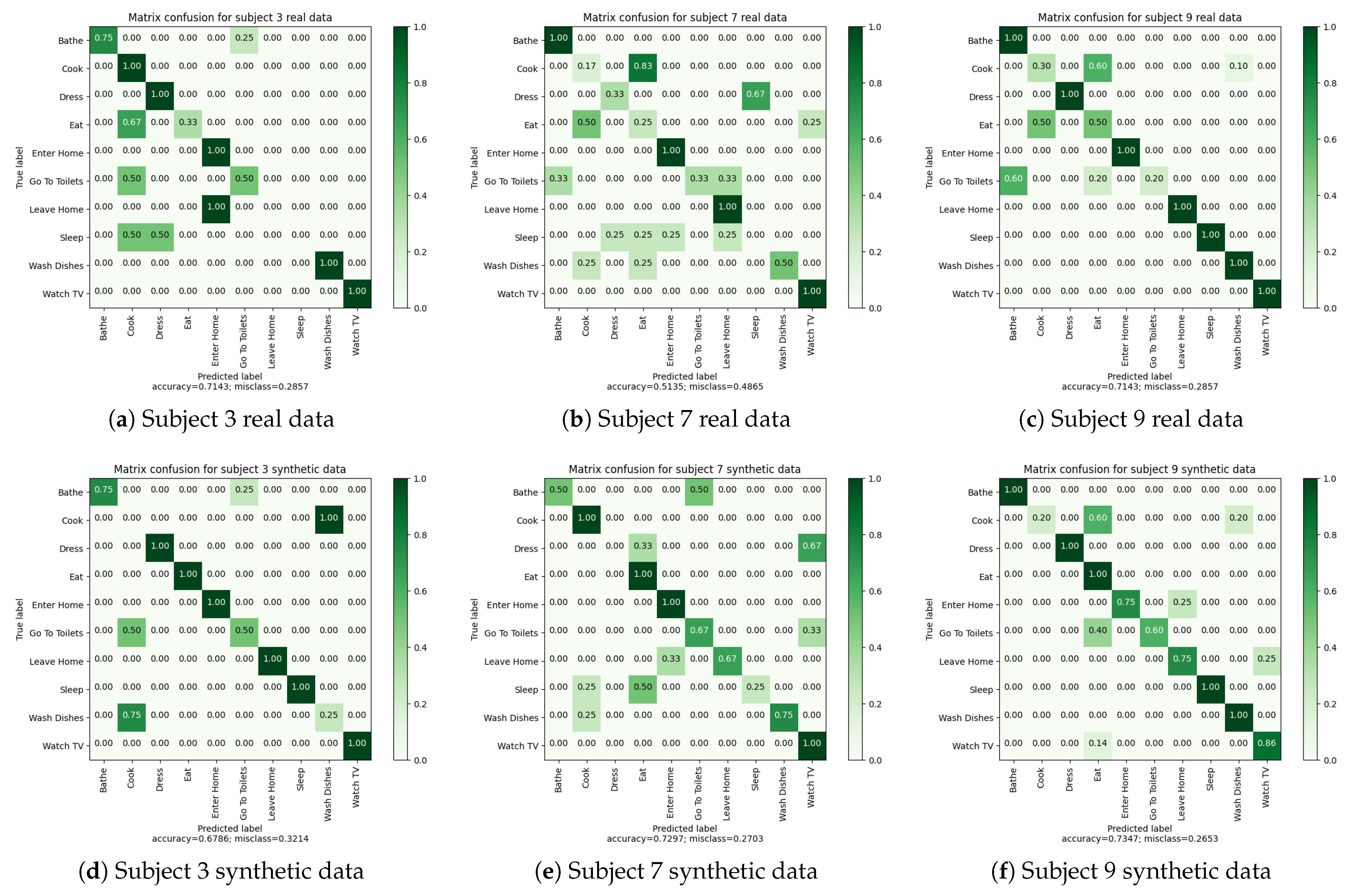
4.3.3. Experiments 1 and 2: Leave-One-Subject-Out Cross Validations
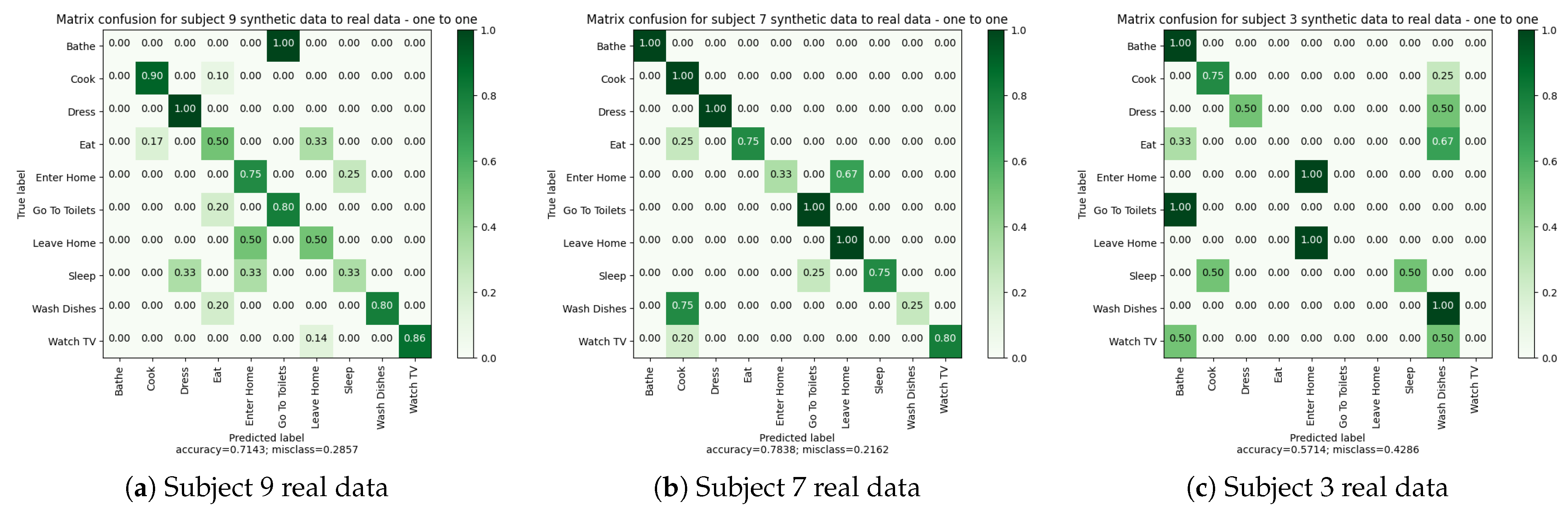
4.3.4. Experiment 3: One-to-One—Training on Synthetic Data and Testing on Real Data
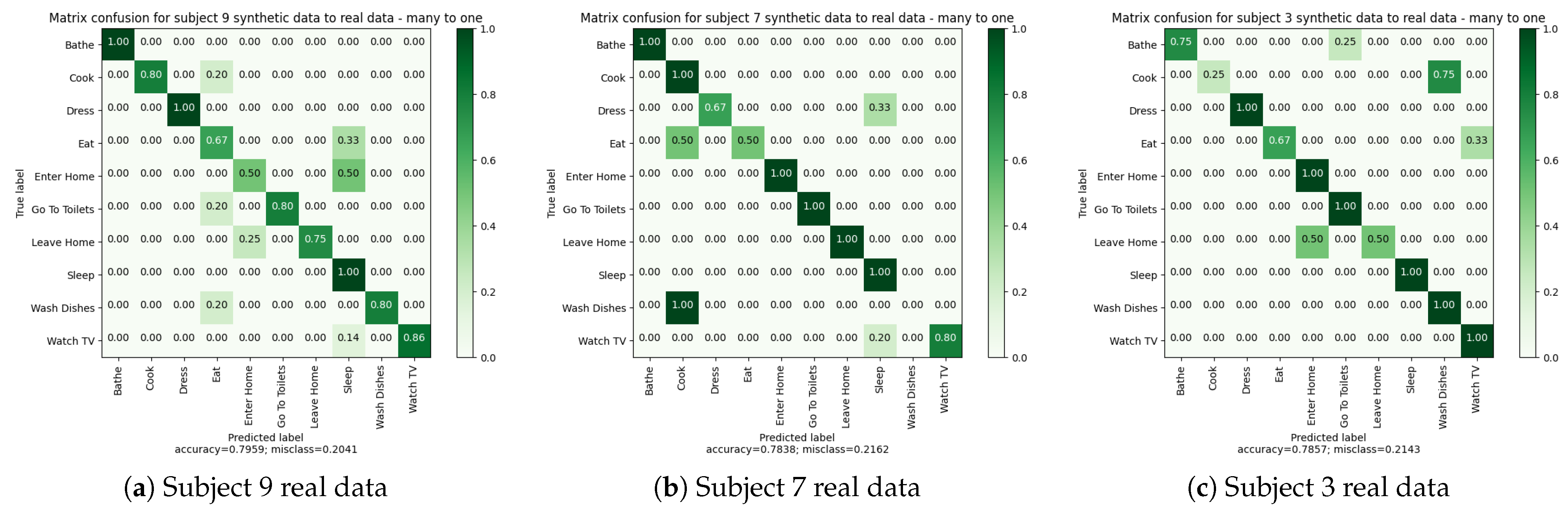
4.3.5. Experiment 4: Many-to-One—Training on Synthetic Data and Testing on Real Data
4.4. Summary
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dang, L.M.; Min, K.; Wang, H.; Piran, M.J.; Lee, C.H.; Moon, H. Sensor-based and vision-based human activity recognition: A comprehensive survey. Pattern Recognit. 2020, 108, 107561. [Google Scholar] [CrossRef]
- Bouchabou, D.; Nguyen, S.M.; Lohr, C.; LeDuc, B.; Kanellos, I. A Survey of Human Activity Recognition in Smart Homes Based on IoT Sensors Algorithms: Taxonomies, Challenges, and Opportunities with Deep Learning. Sensors 2021, 21, 6037. [Google Scholar] [CrossRef] [PubMed]
- Tan, T.H.; Gochoo, M.; Huang, S.C.; Liu, Y.H.; Liu, S.H.; Huang, Y.F. Multi-resident activity recognition in a smart home using RGB activity image and DCNN. IEEE Sens. J. 2018, 18, 9718–9727. [Google Scholar] [CrossRef]
- Bouchabou, D.; Nguyen, S.M.; Lohr, C.; Kanellos, I.; Leduc, B. Fully Convolutional Network Bootstrapped by Word Encoding and Embedding for Activity Recognition in Smart Homes. In Proceedings of the IJCAI 2020 Workshop on Deep Learning for Human Activity Recognition, Yokohama, Japan, 7–15 January 2021. [Google Scholar]
- Liciotti, D.; Bernardini, M.; Romeo, L.; Frontoni, E. A Sequential Deep Learning Application for Recognising Human Activities in Smart Homes. Neurocomputing 2019, 396, 501–513. [Google Scholar] [CrossRef]
- Hussain, Z.; Sheng, Q.; Zhang, W.E. Different Approaches for Human Activity Recognition: A Survey. arXiv 2019, arXiv:1906.05074. [Google Scholar]
- Tapia, E.M.; Intille, S.S.; Larson, K. Activity recognition in the home using simple and ubiquitous sensors. In Proceedings of the International Conference on Pervasive Computing, Vienna, Austria, 21–23 April 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 158–175. [Google Scholar]
- van Kasteren, T.L.; Englebienne, G.; Kröse, B.J. Human activity recognition from wireless sensor network data: Benchmark and software. In Activity Recognition in Pervasive Intelligent Environments; Atlantis Press: Paris, France, 2011; pp. 165–186. [Google Scholar]
- Alemdar, H.; Ertan, H.; Incel, O.D.; Ersoy, C. ARAS human activity datasets in multiple homes with multiple residents. In Proceedings of the 2013 7th International Conference on Pervasive Computing Technologies for Healthcare and Workshops, Venice, Italy, 5–8 May 2013; pp. 232–235. [Google Scholar]
- Cumin, J.; Lefebvre, G.; Ramparany, F.; Crowley, J.L. A dataset of routine daily activities in an instrumented home. In Proceedings of the International Conference on Ubiquitous Computing and Ambient Intelligence, Philadelphia, PA, USA, 7–10 November 2017; Springer: Cham, Switzerland, 2017; pp. 413–425. [Google Scholar]
- Grieves, M. Digital Twin: Manufacturing Excellence through Virtual Factory Replication; Digital Twin White Paper; Digital Twin Consortium: Boston, MA, USA, 2014; Volume 1, pp. 1–7. [Google Scholar]
- Grieves, M.; Vickers, J. Digital twin: Mitigating unpredictable, undesirable emergent behavior in complex systems. In Transdisciplinary Perspectives on Complex Systems; Springer: Cham, Switzerland, 2017; pp. 85–113. [Google Scholar]
- Barricelli, B.R.; Casiraghi, E.; Fogli, D. A survey on digital twin: Definitions, characteristics, applications, and design implications. IEEE Access 2019, 7, 167653–167671. [Google Scholar] [CrossRef]
- Ngah Nasaruddin, A.; Ito, T.; Tee, B.T. Digital Twin Approach to Building Information Management. Proc. Manuf. Syst. Div. Conf. 2018, 2018, 304. [Google Scholar] [CrossRef]
- Khajavi, S.; Hossein Motlagh, N.; Jaribion, A.; Werner, L.; Holmström, J. Digital Twin: Vision, Benefits, Boundaries, and Creation for Buildings. IEEE Access 2019, 7, 147406–147419. [Google Scholar] [CrossRef]
- Puig, X.; Ra, K.; Boben, M.; Li, J.; Wang, T.; Fidler, S.; Torralba, A. Virtualhome: Simulating Household Activities via Programs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8494–8502. [Google Scholar]
- Sedky, M.; Howard, C.; Alshammari, T.; Alshammari, N. Evaluating machine learning techniques for activity classification in smart home environments. Int. J. Inf. Syst. Comput. Sci. 2018, 12, 48–54. [Google Scholar]
- Gochoo, M.; Tan, T.H.; Liu, S.H.; Jean, F.R.; Alnajjar, F.S.; Huang, S.C. Unobtrusive activity recognition of elderly people living alone using anonymous binary sensors and DCNN. IEEE J. Biomed. Health Inform. 2018, 23, 693–702. [Google Scholar] [CrossRef]
- Singh, D.; Merdivan, E.; Hanke, S.; Kropf, J.; Geist, M.; Holzinger, A. Convolutional and recurrent neural networks for activity recognition in smart environment. In Towards Integrative Machine Learning and Knowledge Extraction, Proceedings of the BIRS Workshop, Banff, AB, Canada, 24–26 July 2015; Springer: Cham, Switzerland, 2017; pp. 194–205. [Google Scholar]
- Singh, D.; Merdivan, E.; Psychoula, I.; Kropf, J.; Hanke, S.; Geist, M.; Holzinger, A. Human activity recognition using recurrent neural networks. In Proceedings of the International Cross-Domain Conference for Machine Learning and Knowledge Extraction, Reggio, Italy, 29 August–1 September 2017; Springer: Cham, Switzerland, 2017; pp. 267–274. [Google Scholar]
- Cook, D.J.; Crandall, A.S.; Thomas, B.L.; Krishnan, N.C. CASAS: A Smart Home in a Box. Computer 2013, 46, 62–69. [Google Scholar] [CrossRef]
- De-La-Hoz-Franco, E.; Ariza-Colpas, P.; Quero, J.M.; Espinilla, M. Sensor-based datasets for human activity recognition—A systematic review of literature. IEEE Access 2018, 6, 59192–59210. [Google Scholar] [CrossRef]
- Golestan, S.; Stroulia, E.; Nikolaidis, I. Smart Indoor Space Simulation Methodologies: A Review. IEEE Sens. J. 2022, 22, 8337–8359. [Google Scholar] [CrossRef]
- Bruneau, J.; Consel, C.; OMalley, M.; Taha, W.; Hannourah, W.M. Virtual testing for smart buildings. In Proceedings of the 2012 Eighth International Conference on Intelligent Environments, Guanajuato, Mexico, 26–29 June 2012; pp. 282–289. [Google Scholar]
- Kolve, E.; Mottaghi, R.; Han, W.; VanderBilt, E.; Weihs, L.; Herrasti, A.; Gordon, D.; Zhu, Y.; Gupta, A.; Farhadi, A. AI2-THOR: An Interactive 3D Environment for Visual AI. arXiv 2019, arXiv:1712.05474. [Google Scholar]
- Xia, F.; Zamir, A.R.; He, Z.; Sax, A.; Malik, J.; Savarese, S. Gibson Env: Real-World Perception for Embodied Agents. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9068–9079. [Google Scholar] [CrossRef]
- Roitberg, A.; Schneider, D.; Djamal, A.; Seibold, C.; Reiß, S.; Stiefelhagen, R. Let’s Play for Action: Recognizing Activities of Daily Living by Learning from Life Simulation Video Games. arXiv 2021, arXiv:2107.05617. [Google Scholar]
- Savva, M.; Kadian, A.; Maksymets, O.; Zhao, Y.; Wijmans, E.; Jain, B.; Straub, J.; Liu, J.; Koltun, V.; Malik, J.; et al. Habitat: A Platform for Embodied AI Research. arXiv 2019, arXiv:1904.01201. [Google Scholar]
- Alshammari, N.; Alshammari, T.; Sedky, M.; Champion, J.; Bauer, C. OpenSHS: Open smart home simulator. Sensors 2017, 17, 1003. [Google Scholar] [CrossRef] [PubMed]
- Ho, B.; Vogts, D.; Wesson, J. A smart home simulation tool to support the recognition of activities of daily living. In Proceedings of the South African Institute of Computer Scientists and Information Technologists 2019, Skukuza, South Africa, 17–18 September 2019; pp. 1–10. [Google Scholar]
- Lee, J.W.; Cho, S.; Liu, S.; Cho, K.; Helal, S. Persim 3D: Context-Driven Simulation and Modeling of Human Activities in Smart Spaces. IEEE Trans. Autom. Sci. Eng. 2015, 12, 1243–1256. [Google Scholar] [CrossRef]
- Synnott, J.; Chen, L.; Nugent, C.; Moore, G. IE Sim—A Flexible Tool for the Simulation of Data Generated within Intelligent Environments. In Proceedings of the Ambient Intelligence, Pisa, Italy, 13–15 November 2012; Paternò, F., de Ruyter, B., Markopoulos, P., Santoro, C., van Loenen, E., Luyten, K., Eds.; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2012; pp. 373–378. [Google Scholar]
- Bouchard, K.; Ajroud, A.; Bouchard, B.; Bouzouane, A. SIMACT: A 3D Open Source Smart Home Simulator for Activity Recognition with Open Database and Visual Editor. Int. J. Hybrid Inf. Technol. 2012, 5, 13–32. [Google Scholar]
- Park, B.; Min, H.; Bang, G.; Ko, I. The User Activity Reasoning Model in a Virtual Living Space Simulator. Int. J. Softw. Eng. Its Appl. 2015, 9, 53–62. [Google Scholar] [CrossRef]
- Francillette, Y.; Boucher, E.; Bouzouane, A.; Gaboury, S. The Virtual Environment for Rapid Prototyping of the Intelligent Environment. Sensors 2017, 17, 2562. [Google Scholar] [CrossRef] [PubMed]
- Buchmayr, M.; Kurschl, W.; Küng, J. A simulator for generating and visualizing sensor data for ambient intelligence environments. Procedia Comput. Sci. 2011, 5, 90–97. [Google Scholar] [CrossRef]
- Armac, I.; Retkowitz, D. Simulation of smart environments. In Proceedings of the IEEE International Conference on Pervasive Services, Istanbul, Turkey, 15–20 July 2007; pp. 257–266. [Google Scholar]
- VirtualHome. Available online: http://www.virtual-home.org/ (accessed on 21 January 2021).
- Savva, M.; Chang, A.X.; Dosovitskiy, A.; Funkhouser, T.; Koltun, V. MINOS: Multimodal indoor simulator for navigation in complex environments. arXiv 2017, arXiv:1712.03931. [Google Scholar]
- Roberts, M.; Ramapuram, J.; Ranjan, A.; Kumar, A.; Bautista, M.A.; Paczan, N.; Webb, R.; Susskind, J.M. Hypersim: A Photorealistic Synthetic Dataset for Holistic Indoor Scene Understanding. arXiv 2021, arXiv:2011.02523. [Google Scholar]
- Srivastava, S.; Li, C.; Lingelbach, M.; Martín-Martín, R.; Xia, F.; Vainio, K.; Lian, Z.; Gokmen, C.; Buch, S.; Liu, C.K.; et al. BEHAVIOR: Benchmark for Everyday Household Activities in Virtual, Interactive, and Ecological Environments. arXiv 2021, arXiv:2108.03332. [Google Scholar]
- Shridhar, M.; Thomason, J.; Gordon, D.; Bisk, Y.; Han, W.; Mottaghi, R.; Zettlemoyer, L.; Fox, D. Alfred: A benchmark for interpreting grounded instructions for everyday tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10740–10749. [Google Scholar]
- Puig, X.; Shu, T.; Li, S.; Wang, Z.; Liao, Y.H.; Tenenbaum, J.B.; Fidler, S.; Torralba, A. Watch-And-Help: A Challenge for Social Perception and Human-AI Collaboration. In Proceedings of the International Conference on Learning Representations, Online, 3–7 May 2021. [Google Scholar]
- Cao, Z.; Gao, H.; Mangalam, K.; Cai, Q.; Vo, M.; Malik, J. Long-term human motion prediction with scene context. In Proceedings of the ECCV, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Varol, G.; Romero, J.; Martin, X.; Mahmood, N.; Black, M.J.; Laptev, I.; Schmid, C. Learning from Synthetic Humans. In Proceedings of the CVPR, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Synnott, J.; Nugent, C.; Jeffers, P. Simulation of smart home activity datasets. Sensors 2015, 15, 14162–14179. [Google Scholar] [CrossRef]
- Kamara-Esteban, O.; Azkune, G.; Pijoan, A.; Borges, C.E.; Alonso-Vicario, A.; López-de Ipiña, D. MASSHA: An agent-based approach for human activity simulation in intelligent environments. Pervasive Mob. Comput. 2017, 40, 279–300. [Google Scholar] [CrossRef]
- Helal, S.; Mann, W.; El-Zabadani, H.; King, J.; Kaddoura, Y.; Jansen, E. The gator tech smart house: A programmable pervasive space. Computer 2005, 38, 50–60. [Google Scholar] [CrossRef]
- Puig, X. VirtualHome Source Code. Available online: https://github.com/xavierpuigf/virtualhome_unity (accessed on 25 January 2021).
- Liao, Y.; Puig, X.; Boben, M.; Torralba, A.; Fidler, S. Synthesizing Environment-Aware Activities via Activity Sketches. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 6284–6292. [Google Scholar] [CrossRef]
- VirtualHome Source Code and API. Available online: https://github.com/xavierpuigf/virtualhome (accessed on 25 January 2021).
- Sweet Home 3D-Draw Floor Plans and Arrange Furniture Freely. Available online: https://www.sweethome3d.com/ (accessed on 10 September 2022).
- Experiment’Haal, le Living Lab Santé Autonomie (LLSA). Available online: http://www.imt-atlantique.fr/fr/recherche-et-innovation/plateformes-de-recherche/experiment-haal (accessed on 21 January 2021).
- Lohr, C.; Kerdreux, J. Improvements of the xAAL home automation system. Future Internet 2020, 12, 104. [Google Scholar] [CrossRef]
- Future-Shape. SensFloor—The Floor Becomes a Touch Screen. Available online: https://future-shape.com/en/system/ (accessed on 6 December 2021).
- Katz, S. Assessing self-maintenance: Activities of daily living, mobility, and instrumental activities of daily living. J. Am. Geriatr. Soc. 1983, 31, 721–727. [Google Scholar] [CrossRef]
- Cross-Correlation. Available online: https://en.wikipedia.org/w/index.php?title=Cross-correlation&oldid=1031522391 (accessed on 17 August 2021).
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Sammut, C.; Webb, G.I. (Eds.) Leave-One-Out Cross-Validation. In Encyclopedia of Machine Learning; Springer: Boston, MA, USA, 2010; pp. 600–601. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Components | Server | Light and Motion Sensors | Door Sensors | Relay | Temperature Sensors | Total Cost |
|---|---|---|---|---|---|---|
| Unit Price | USD 350 | USD 85 | USD 75 | USD 75 | USD 75 | |
| Quantity | 1 | 24 | 1 | 2 | 2 | |
| Total Price | USD 350 | USD 2040 | USD 75 | USD 150 | USD 150 | USD 2765 |
| Simulators | Open | Approach | Multi | Environment | API | Apartment | Objects | Scripts | IoT Sensors | Designer/Editor | Visual | Application | Output |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AI2Thor [25] | Yes | Model | Yes | Unity | Python | 17 | 609 | No | No | Yes | 3D | Robot Interaction | Videos |
| iGibson [26] | Yes | Model | Yes | Bullet Python | No | 15 | 570 | No | 1 | Yes | None | Robot Interaction | Videos |
| Sims4Action [27] | No | Model | Yes | Sims 4 | No | None | NA | No | No | Game Interface | 3D | Human Activity | Videos |
| Ai Habitat [28] | Yes | Model | Yes | C++ | Python | None | NA | No | No | Yes | None | Human Activity | Sens. Log |
| Open SHS [29] | Yes | Hybrid | No | Blender | Python | None | NA | No | 29 (B) | With Blender | 3D | Human Activity | Sens. Log |
| SESim [30] | Yes | Model | No | Unity | NA | NA | Yes | Yes | 5 | Yes | 3D | Human Activity | Sens. Log |
| Persim 3D [31] | No | Model | No | Unity | C# | Gator Tech | Yes | No | Yes (B) | Yes | 3D | Human Activity | Sens. Log |
| IE Sim [32] | No | Hybrid | No | NA | NA | NA | Yes | No | Yes (B) | Yes | 2D | Human Activity | Sens. Log |
| SIMACT [33] | Yes | Model | No | JME | Java | 3D kitchen | Yes | Yes | Yes (B) | With Sketchup | 3D | Human Activity | Sens. Log |
| Park et al. [34] | No | Interactive | No | Unity | NA | 1 | Yes | No | NA | With Unity | 3D | Human Activity | Sens. Log |
| Francillette et al. [35] | Yes | Hybrid | Yes | Unity | NA | NA | Yes | Yes | 8 (B and A) | With Unity | 3D | Human Activity | Sens. Log |
| Buchmayr et al. [36] | No | Interactive | No | NA | NA | NA | Yes | No | Yes (B) | NA | 3D | Human Activity | Sens. Log |
| Armac et al. [37] | No | Interactive | Yes | NA | NA | None | Yes | No | Yes (B) | Yes | 2D | Human Activity | Sens. Log |
| VirtualHome [38] | Yes | Hybrid | Yes | Unity | Python | 7 | 308 | Yes | No | Yes | 3D | Human Activity | Videos |
| Activity | Subject 1 | Subject 2 | Subject 3 | Subject 5 | Subject 6 | Subject 7 | Subject 8 | Subject 9 | Total/Activity |
|---|---|---|---|---|---|---|---|---|---|
| Bathe | 5 | 3 | 3 | 3 | 1 | 1 | 0 | 0 | 16 |
| Cook | 5 | 4 | 4 | 7 | 2 | 2 | 0 | 2 | 26 |
| Dress | 6 | 4 | 4 | 1 | 1 | 1 | 0 | 2 | 19 |
| Eat | 5 | 4 | 3 | 3 | 1 | 2 | 0 | 1 | 19 |
| Enter Home | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| Go To Toilets | 5 | 4 | 3 | 1 | 1 | 1 | 0 | 1 | 16 |
| Leave Home | 5 | 4 | 2 | 2 | 1 | 2 | 0 | 1 | 17 |
| Read | 0 | 0 | 2 | 2 | 0 | 0 | 0 | 0 | 4 |
| Sleep | 5 | 4 | 4 | 0 | 1 | 2 | 0 | 1 | 17 |
| Sleep in Bed | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 2 |
| Wash Dishes | 5 | 4 | 3 | 0 | 1 | 2 | 0 | 1 | 16 |
| Watch TV | 0 | 0 | 0 | 3 | 1 | 0 | 0 | 2 | 6 |
| Total/Subject | 41 | 31 | 28 | 25 | 10 | 13 | 0 | 11 | 159 |
| Activity | Subject 1 | Subject 2 | Subject 3 | Subject 5 | Subject 6 | Subject 7 | Subject 8 | Subject 9 | Total/Activity |
|---|---|---|---|---|---|---|---|---|---|
| Bathe | 5 | 0 | 1 | 3 | 0 | 0 | 0 | 0 | 9 |
| Cook | 7 | 6 | 1 | 3 | 1 | 4 | 2 | 5 | 29 |
| Dress | 7 | 2 | 0 | 1 | 0 | 0 | 0 | 1 | 11 |
| Eat | 5 | 2 | 1 | 3 | 0 | 2 | 1 | 2 | 16 |
| Enter Home | 5 | 2 | 1 | 2 | 1 | 2 | 1 | 2 | 16 |
| Go To Toilets | 8 | 4 | 1 | 4 | 1 | 0 | 0 | 2 | 20 |
| Leave Home | 5 | 1 | 1 | 2 | 1 | 2 | 1 | 2 | 15 |
| Read | 1 | 3 | 1 | 2 | 0 | 0 | 0 | 0 | 7 |
| Sleep | 2 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 3 |
| Sleep in Bed | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 4 |
| Wash Dishes | 6 | 2 | 1 | 2 | 1 | 2 | 1 | 2 | 17 |
| Watch TV | 0 | 2 | 0 | 0 | 1 | 4 | 1 | 0 | 8 |
| Total/Subject | 55 | 24 | 8 | 23 | 6 | 16 | 7 | 16 | 155 |
| Activity | Subject 1 | Subject 2 | Subject 3 | Subject 5 | Subject 6 | Subject 7 | Subject 8 | Subject 9 | Total/Activity |
|---|---|---|---|---|---|---|---|---|---|
| Bathe | 6 | 2 | 3 | 5 | 0 | 1 | 0 | 2 | 19 |
| Cook | 6 | 5 | 2 | 5 | 0 | 3 | 0 | 3 | 24 |
| Dress | 8 | 2 | 1 | 4 | 1 | 2 | 1 | 0 | 19 |
| Eat | 4 | 2 | 2 | 4 | 0 | 1 | 0 | 2 | 15 |
| Enter Home | 5 | 2 | 2 | 3 | 1 | 2 | 1 | 2 | 18 |
| Go To Toilets | 10 | 3 | 1 | 4 | 0 | 2 | 0 | 2 | 22 |
| Leave Home | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Read | 5 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 7 |
| Sleep | 4 | 2 | 1 | 3 | 1 | 2 | 1 | 2 | 16 |
| Sleep in Bed | 5 | 2 | 3 | 3 | 1 | 2 | 1 | 2 | 19 |
| Wash Dishes | 6 | 2 | 2 | 2 | 0 | 1 | 0 | 2 | 15 |
| Watch TV | 4 | 3 | 2 | 7 | 1 | 3 | 1 | 5 | 26 |
| Total/Subject | 63 | 26 | 19 | 40 | 5 | 20 | 5 | 22 | 200 |
| Activity | Subject 1 | Subject 2 | Subject 3 | Subject 5 | Subject 6 | Subject 7 | Subject 8 | Subject 9 | Total/Activity |
|---|---|---|---|---|---|---|---|---|---|
| Bathe | 16 | 5 | 7 | 11 | 1 | 2 | 0 | 2 | 44 |
| Cook | 18 | 15 | 7 | 15 | 3 | 9 | 2 | 10 | 79 |
| Dress | 21 | 8 | 5 | 6 | 2 | 3 | 1 | 3 | 49 |
| Eat | 14 | 8 | 6 | 10 | 1 | 5 | 1 | 6 | 50 |
| Enter Home | 10 | 4 | 3 | 6 | 2 | 4 | 2 | 4 | 35 |
| Go To Toilets | 23 | 11 | 5 | 9 | 2 | 3 | 0 | 5 | 58 |
| Leave Home | 10 | 5 | 3 | 4 | 2 | 4 | 1 | 4 | 32 |
| Read | 6 | 4 | 3 | 4 | 0 | 1 | 0 | 0 | 18 |
| Sleep | 11 | 6 | 5 | 4 | 2 | 4 | 1 | 2 | 36 |
| Sleep in Bed | 9 | 2 | 3 | 5 | 1 | 2 | 1 | 1 | 25 |
| Wash Dishes | 17 | 8 | 6 | 4 | 2 | 5 | 1 | 5 | 48 |
| Watch TV | 4 | 5 | 2 | 10 | 3 | 7 | 2 | 7 | 40 |
| Total/Subject | 159 | 81 | 55 | 88 | 21 | 49 | 12 | 49 | 514 |
| Activity | Bathe | Cook | Dress | Eat | Enter Home | Go To Toilet | Leave Home | Sleep | Wash Dishes | Watch TV | Total/Subject |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Subject 3 | 4 | 4 | 2 | 3 | 3 | 2 | 2 | 2 | 4 | 2 | 28 |
| Subject 7 | 2 | 6 | 3 | 4 | 3 | 3 | 3 | 4 | 4 | 5 | 37 |
| Subject 9 | 2 | 10 | 3 | 6 | 4 | 5 | 4 | 3 | 5 | 7 | 49 |
| Total/Activity | 8 | 20 | 8 | 13 | 10 | 10 | 9 | 9 | 13 | 14 | 114 |
| Scenario Number | Real | Synthetic | Excess Sensors Detected | Index in Figure 5 |
|---|---|---|---|---|
| s3_1_bis | 13 | 14 | floor_bedroom | 1 |
| s3_2_bis | 15 | 15 | 2 | |
| s3_3_bis | 18 | 18 | 3 | |
| s3_4_bis | 10 | 11 | floor_dining_room | 4 |
| s7_1 | 12 | 13 | floor_bathroom | 5 |
| s7_2 | 17 | 17 | 6 | |
| s7_4 | 18 | 18 | 7 | |
| s7_5 | 15 | 15 | 8 | |
| s7_6 | 13 | 15 | floor_bathroom, floor_bedroom | 9 |
| s9_1 | 16 | 16 | 10 | |
| s9_2 | 19 | 19 | 11 | |
| s9_3 | 18 | 18 | 12 | |
| s9_4 | 14 | 15 | floor_bathroom | 13 |
| s9_5 | 14 | 14 | 14 | |
| s9_6 | 20 | 20 | 15 |
| Subject | S9 | S7 | S3 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Scenario Index | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| Similarity (%) | 75.73% | 97.40% | 75.42% | 75.30% | 69.61% | 74.42% | 81.24% | 93.18% | 85.22% | 84.73% | 88.28% | 79.93% | 77.53% | 54.73% | 82.78% |
| Average Similarity (%) | 77.98% | 86.53% | 73.74% | ||||||||||||
| # Train Samples | # Validation Samples | # Test Samples | |
|---|---|---|---|
| Subject 3 | 68 | 18 | 28 |
| Subject 7 | 61 | 16 | 37 |
| Subject 9 | 52 | 13 | 49 |
| Subject 9 | Subject 7 | Subject 3 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Support | Precision | Recall | F1-Score | Support | Precision | Recall | F1-Score | Support | |
| Bathe | 40.00% | 100.00% | 57.14% | 2 | 66.67% | 100.00% | 80.00% | 2 | 100.00% | 75.00% | 85.71% | 4 |
| Cook | 50.00% | 30.00% | 37.50% | 10 | 25.00% | 16.67% | 20.00% | 6 | 50.00% | 100.00% | 66.67% | 4 |
| Dress | 100.00% | 100.00% | 100.00% | 3 | 50.00% | 33.33% | 40.00% | 3 | 66.67% | 100.00% | 80.00% | 2 |
| Eat | 30.00% | 50.00% | 37.50% | 6 | 12.50% | 25.00% | 16.67% | 4 | 100.00% | 33.33% | 50.00% | 3 |
| Enter Home | 100.00% | 100.00% | 100.00% | 4 | 75.00% | 100.00% | 85.71% | 3 | 60.00% | 100.00% | 75.00% | 3 |
| Go To Toilets | 100.00% | 20.00% | 33.33% | 5 | 100.00% | 33.33% | 50.00% | 3 | 50.00% | 50.00% | 50.00% | 2 |
| Leave Home | 100.00% | 100.00% | 100.00% | 4 | 60.00% | 100.00% | 75.00% | 3 | 0.00% | 0.00% | 0.00% | 2 |
| Sleep | 100.00% | 100.00% | 100.00% | 3 | 0.00% | 0.00% | 0.00% | 4 | 0.00% | 0.00% | 0.00% | 2 |
| Wash Dishes | 83.33% | 100.00% | 90.91% | 5 | 100.00% | 50.00% | 66.67% | 4 | 100.00% | 100.00% | 100.00% | 4 |
| Watch TV | 100.00% | 100.00% | 100.00% | 7 | 83.33% | 100.00% | 90.91% | 5 | 100.00% | 100.00% | 100.00% | 2 |
| Accuracy | 71.43% | 51.35% | 71.43% | |||||||||
| Balanced Accuracy | 80.00% | 55.83% | 65.83% | |||||||||
| Macro Avg | 80.33% | 80.00% | 75.64% | 49 | 57.25% | 55.83% | 52.50% | 37 | 62.67% | 65.83% | 60.74% | 28 |
| Weighted Avg | 77.07% | 71.43% | 70.11% | 49 | 54.19% | 51.35% | 49.19% | 37 | 68.33% | 71.43% | 65.88% | 28 |
| Subject 9 | Subject 7 | Subject 3 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Support | Precision | Recall | F1-Score | Support | Precision | Recall | F1-Score | Support | |
| Bathe | 100.00% | 100.00% | 100.00% | 2 | 100.00% | 50.00% | 66.67% | 2 | 100.00% | 75.00% | 85.71% | 4 |
| Cook | 100.00% | 20.00% | 33.33% | 10 | 75.00% | 100.00% | 85.71% | 6 | 0.00% | 0.00% | 0.00% | 4 |
| Dress | 100.00% | 100.00% | 100.00% | 3 | 0.00% | 0.00% | 0.00% | 3 | 100.00% | 100.00% | 100.00% | 2 |
| Eat | 40.00% | 100.00% | 57.14% | 6 | 57.14% | 100.00% | 72.73% | 4 | 100.00% | 100.00% | 100.00% | 3 |
| Enter Home | 100.00% | 75.00% | 85.71% | 4 | 75.00% | 100.00% | 85.71% | 3 | 100.00% | 100.00% | 100.00% | 3 |
| Go To Toilets | 100.00% | 60.00% | 75.00% | 5 | 66.67% | 66.67% | 66.67% | 3 | 50.00% | 50.00% | 50.00% | 2 |
| Leave Home | 75.00% | 75.00% | 75.00% | 4 | 100.00% | 66.67% | 80.00% | 3 | 100.00% | 100.00% | 100.00% | 2 |
| Sleep | 100.00% | 100.00% | 100.00% | 3 | 100.00% | 25.00% | 40.00% | 4 | 100.00% | 100.00% | 100.00% | 2 |
| Wash Dishes | 71.43% | 100.00% | 83.33% | 5 | 100.00% | 75.00% | 85.71% | 4 | 20.00% | 25.00% | 22.22% | 4 |
| Watch TV | 85.71% | 85.71% | 85.71% | 7 | 62.50% | 100.00% | 76.92% | 5 | 100.00% | 100.00% | 100.00% | 2 |
| Accuracy | 73.47% | 72.97% | 67.86% | |||||||||
| Balanced Accuracy | 81.57% | 68.33% | 75.00% | |||||||||
| Macro Avg | 87.21% | 81.57% | 79.52% | 49 | 73.63% | 68.33% | 66.01% | 37 | 77.00% | 75.00% | 75.79% | 28 |
| Weighted Avg | 85.66% | 73.47% | 71.65% | 49 | 73.41% | 72.97% | 68.19% | 37 | 70.71% | 67.86% | 68.99% | 28 |
| # Train Samples from Synthetic Data | # Validation Samples from Synthetic Data | # Test Samples from Real Data | |
|---|---|---|---|
| Subject 3 | 18 | 10 | 28 |
| Subject 7 | 27 | 10 | 37 |
| Subject 9 | 39 | 10 | 49 |
| S9 | S7 | S3 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Support | Precision | Recall | F1-Score | Support | Precision | Recall | F1-Score | Support | |
| Bathe | 0.00% | 0.00% | 0.00% | 2 | 100.00% | 100.00% | 100.00% | 2 | 50.00% | 100.00% | 66.67% | 4 |
| Cook | 90.00% | 90.00% | 90.00% | 10 | 54.55% | 100.00% | 70.59% | 6 | 75.00% | 75.00% | 75.00% | 4 |
| Dress | 75.00% | 100.00% | 85.71% | 3 | 100.00% | 100.00% | 100.00% | 3 | 100.00% | 50.00% | 66.67% | 2 |
| Eat | 50.00% | 50.00% | 50.00% | 6 | 100.00% | 75.00% | 85.71% | 4 | 0.00% | 0.00% | 0.00% | 3 |
| Enter Home | 50.00% | 75.00% | 60.00% | 4 | 100.00% | 33.33% | 50.00% | 3 | 60.00% | 100.00% | 75.00% | 3 |
| Go To Toilets | 66.67% | 80.00% | 72.73% | 5 | 75.00% | 100.00% | 85.71% | 3 | 0.00% | 0.00% | 0.00% | 2 |
| Leave Home | 40.00% | 50.00% | 44.44% | 4 | 60.00% | 100.00% | 75.00% | 3 | 0.00% | 0.00% | 0.00% | 2 |
| Sleep | 50.00% | 33.33% | 40.00% | 3 | 100.00% | 75.00% | 85.71% | 4 | 100.00% | 50.00% | 66.67% | 2 |
| Wash Dishes | 100.00% | 80.00% | 88.89% | 5 | 100.00% | 25.00% | 40.00% | 4 | 44.44% | 100.00% | 61.54% | 4 |
| Watch TV | 100.00% | 85.71% | 92.31% | 7 | 100.00% | 80.00% | 88.89% | 5 | 0.00% | 0.00% | 0.00% | 2 |
| Accuracy | 71.43% | 78.38% | 57.14% | |||||||||
| Balanced Accuracy | 64.40% | 78.83% | 47.50% | |||||||||
| Macro Avg | 62.17% | 64.40% | 62.41% | 49 | 88.95% | 78.83% | 78.16% | 37 | 42.94% | 47.50% | 41.15% | 28 |
| Weighted Avg | 70.78% | 71.43% | 70.39% | 49 | 87.36% | 78.38% | 76.91% | 37 | 44.92% | 57.14% | 46.59% | 28 |
| S9 | S7 | S3 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Support | Precision | Recall | F1-Score | Support | Precision | Recall | F1-Score | Support | |
| Bathe | 100.00% | 100.00% | 100.00% | 2 | 100.00% | 100.00% | 100.00% | 2 | 100.00% | 75.00% | 85.71% | 4 |
| Cook | 100.00% | 80.00% | 88.89% | 10 | 50.00% | 100.00% | 66.67% | 6 | 100.00% | 25.00% | 40.00% | 4 |
| Dress | 100.00% | 100.00% | 100.00% | 3 | 100.00% | 66.67% | 80.00% | 3 | 100.00% | 100.00% | 100.00% | 2 |
| Eat | 50.00% | 66.67% | 57.14% | 6 | 100.00% | 50.00% | 66.67% | 4 | 100.00% | 66.67% | 80.00% | 3 |
| Enter Home | 66.67% | 50.00% | 57.14% | 4 | 100.00% | 100.00% | 100.00% | 3 | 75.00% | 100.00% | 85.71% | 3 |
| Go To Toilets | 100.00% | 80.00% | 88.89% | 5 | 100.00% | 100.00% | 100.00% | 3 | 66.67% | 100.00% | 80.00% | 2 |
| Leave Home | 100.00% | 75.00% | 85.71% | 4 | 100.00% | 100.00% | 100.00% | 3 | 100.00% | 50.00% | 66.67% | 2 |
| Sleep | 37.50% | 100.00% | 54.55% | 3 | 66.67% | 100.00% | 80.00% | 4 | 100.00% | 100.00% | 100.00% | 2 |
| Wash Dishes | 100.00% | 80.00% | 88.89% | 5 | 0.00% | 0.00% | 0.00% | 4 | 57.14% | 100.00% | 72.73% | 4 |
| Watch TV | 100.00% | 85.71% | 92.31% | 7 | 100.00% | 80.00% | 88.89% | 5 | 66.67% | 100.00% | 80.00% | 2 |
| Accuracy | 79.59% | 78.38% | 78.57% | |||||||||
| Balanced Accuracy | 81.74% | 79.67% | 81.67% | |||||||||
| Macro Avg | 85.42% | 81.74% | 81.35% | 49 | 81.67% | 79.67% | 78.22% | 37 | 86.55% | 81.67% | 79.08% | 28 |
| Weighted Avg | 87.33% | 79.59% | 81.67% | 49 | 77.48% | 78.38% | 74.89% | 37 | 86.44% | 78.57% | 76.58% | 28 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bouchabou, D.; Grosset, J.; Nguyen, S.M.; Lohr, C.; Puig, X. A Smart Home Digital Twin to Support the Recognition of Activities of Daily Living. Sensors 2023, 23, 7586. https://doi.org/10.3390/s23177586
Bouchabou D, Grosset J, Nguyen SM, Lohr C, Puig X. A Smart Home Digital Twin to Support the Recognition of Activities of Daily Living. Sensors. 2023; 23(17):7586. https://doi.org/10.3390/s23177586
Chicago/Turabian StyleBouchabou, Damien, Juliette Grosset, Sao Mai Nguyen, Christophe Lohr, and Xavier Puig. 2023. "A Smart Home Digital Twin to Support the Recognition of Activities of Daily Living" Sensors 23, no. 17: 7586. https://doi.org/10.3390/s23177586
APA StyleBouchabou, D., Grosset, J., Nguyen, S. M., Lohr, C., & Puig, X. (2023). A Smart Home Digital Twin to Support the Recognition of Activities of Daily Living. Sensors, 23(17), 7586. https://doi.org/10.3390/s23177586