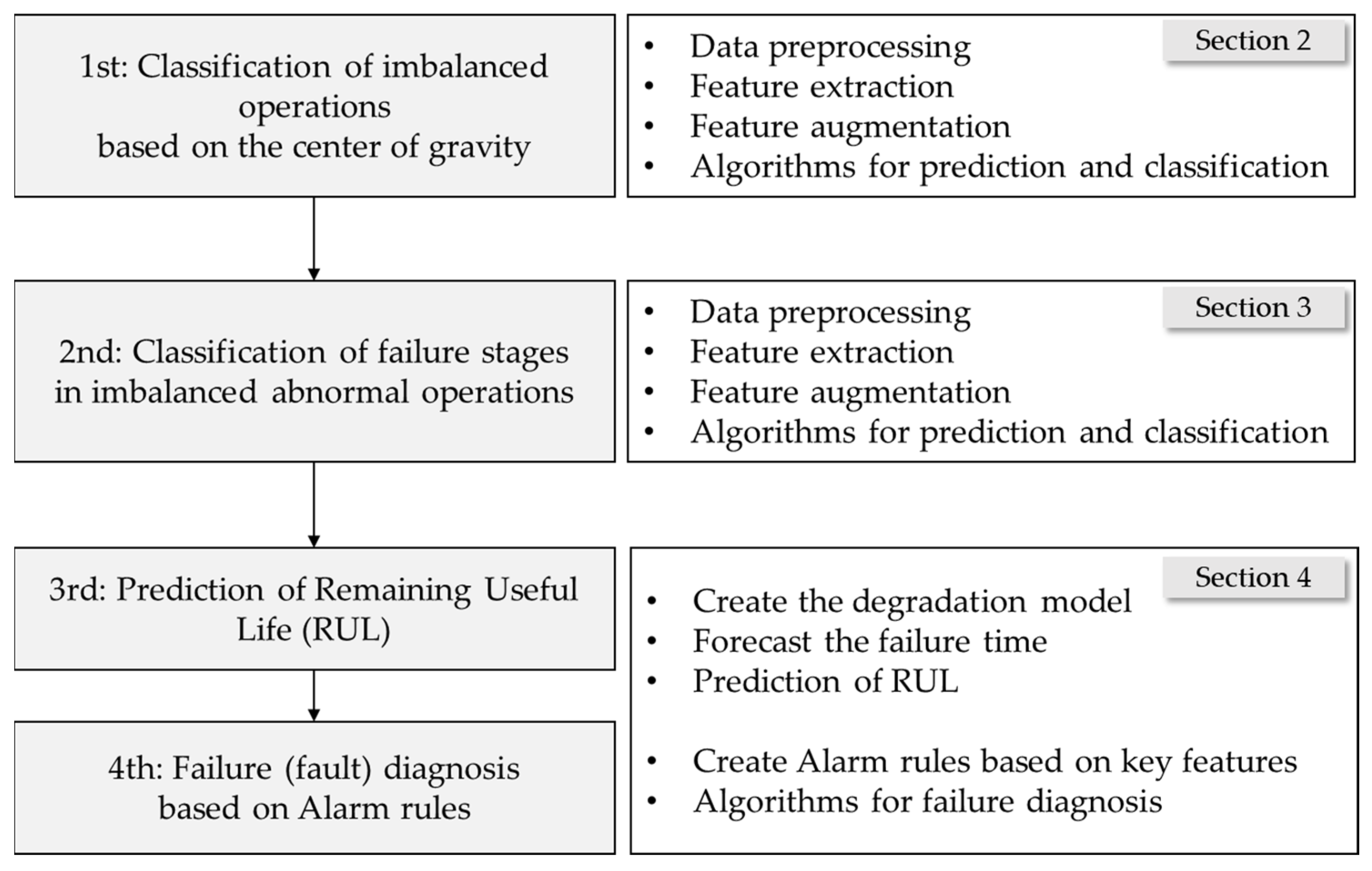
2.1. Experimental Data Acquisition and Feature Engineering
Vibration (acceleration) data were acquired from the forklift’s front-end structure and presented a process to diagnose and classify the weight center of heavy objects carried by forklifts. The front-end structure of the forklift consists of a mast, backrest, carriage, and forks, as shown in
Figure 3, and the acceleration signals were measured from the outer beam of the mast.
In the measurement experiment for data acquisition, the weight center of heavy objects carried by the forklift was measured in three configurations: center, left, and right. The condition segments of the dataset were classified and organized into center, left, and right according to each center of gravity condition. Two embedded devices (one on the left and one on the right) were attached to the front-end structure of the forklift truck to measure the vibration acceleration in three axes (x, y, z) (sampling rate 500 Hz), as shown in
Figure 4. Considering the load conditions under which the forklift operates, the operating environments of the two datasets (datasets 1 and 2) were simulated in the experiments while maintaining a state that included ground noise. In dataset 1 (only driving mode), the vehicle was loaded with 3200 kg of weight and traveled 80 m at maximum speed, as shown on the left in
Figure 5. All measurements were taken for approximately 20 min for center, left, and right condition segments to eliminate data imbalances within condition segments. In dataset 2 (complex mode), the forklift made a round trip of 80 m, as shown on the right in
Figure 5, and added lifting, lowering, and back-and-forth tilting tasks at the end of the trip. In dataset 2, approximately 32 min of data were acquired, which is 12 min longer than in dataset 1. Similarly, approximately 32 min of data were acquired for the center, left, and right condition segments to eliminate the data imbalance.
Six acceleration signals (2 sensors × (x, y, z accelerations)) were included in Data sets 1 and 2. In Dataset 2, for one acceleration signal, 960,000 feature vectors were collected at 500 (Hz) × 32 (min) × 60 (s/min). Given the large data size, which could lead to inefficient analysis, this study referred to previous studies [
27,
28] to handle the data. Eight features were extracted from each window at one-second intervals: min, max, peak to peak, mean (abs), rms (root mean square), variance, kurtosis, and skewness. In addition, four features were added by combining the max, rms, and mean (abs) features: crest factor, shape factor, impulse factor, and margin factor, as listed in
Table 1.
Through the above process, 12 features were extracted, and the measured data were compressed for efficient analysis. The data compression process transformed the dimensionality of the data from 960,000 × 6 × 1 to 1920 × 6 × 12. In this way, the number of feature vectors in the data was reduced, but the number of features was increased twelvefold, resulting in 72 features. The aim was to enable effective data processing and facilitate the diagnosis of the weight center of heavy objects at a one-second interval. Furthermore, the data range of the feature vectors was scaled from 0 to 1 using min–max normalization. Furthermore, an exponentially weighted moving average (EWMA) with a window size of 2 to 3 s was used to smooth the noise signals of the generated features. This approach helped to minimize the noise and outliers in the feature data. Moving averages average out the effects of past data, and exponentially weighted moving averages have the advantage of exponentially attenuating these effects. Therefore, they are used for tasks such as time series forecasting and noise reduction [
29,
30]. The exponentially weighted moving average is used in a way that adjusts the value of alpha (α) based on the window size, as shown in Equation (1). As described in Equation (3), this method smooths out noise in the feature vector to minimize outliers while also reducing the influence of past vectors.
The parameters employed within Equations (1) through (3) are listed below:
: the weight coefficient of exponentially moving average.
: the number of data points used by EWMA.
: the exponentially weighted moving average value at the current time t.
: the input data value at the current time t.
: the input data values at past time points.
: the weights of past time points.
: the sum of weights.
The exponentially weighted moving average was applied to take advantage of its ability to minimize outliers in the feature vector.
Figure 6 shows the ‘min’ feature extracted from the x-acceleration signal using the EWMA technique.
Table 2 and
Table 3 contrast features extracted from the dataset before and after the application of EWMA. They showcase the initial data state alongside the effects of EWMA, including smoothing and value adjustments.
Through the previous feature engineering process, as shown in
Table 4, 3699 feature vectors were generated from dataset 1 (only driving) in approximately 20 min, and 5755 feature vectors were derived from dataset 2 (complex mode), measured for approximately 32 min. In total, 9454 datasets were obtained, which were further divided into training and test datasets at a 7:3 ratio. The training and test datasets comprised 6617 and 2837 samples, respectively, with each feature vector containing 72 features. An attempt was made to use the training dataset to develop machine learning classifier models and check the performance of the machine learning models on the test dataset.
The number of feature vectors in the dataset was also augmented to minimize overfitting during the training process. Data augmentation was performed using additive white Gaussian noise (AWGN) and long short-term memory autoencoder (LSTM AE), which expanded the training dataset to a maximum of 19,851 samples (
Table 5).
AWGN was applied by referring to prior studies [
31], and the target signal-to-noise ratio (SNR) was set to 20 dB. An additional dataset could be generated by mixing noise with the original data, as shown in
Figure 7. AWGN is a method of adding noise with a Gaussian distribution to the input or output signal of a system. SNR serves as a scale that quantifies the ratio between the signal’s strength and the noise level. A higher SNR value corresponds to a more robust signal, reducing the relative impact of noise. AWGN based on SNR can be expressed as follows [
31]:
: the noise of the signal.
: the magnitude of the input or output signal.
: the standard deviation σ of the noise, calculated from the SNR value.
: the white noise, which follows a Gaussian distribution with a mean of 0 and a variance of 1.
Figure 7.
Results of noise mixed augmentation using AWGN.
Figure 7.
Results of noise mixed augmentation using AWGN.
The autoencoder is a neural network that can use unlabeled training data to learn a code that efficiently represents the input data. This type of coding is useful for dimensionality reduction because it typically has much lower dimensionality than the input. In particular, it works as a powerful feature extractor that can be used for the unsupervised pre-training of deep neural networks. An autoencoder consists of an encoder that converts the input to an internal representation and a decoder that converts the internal representation back to output [
32]. The output result is called reconstruction because the autoencoder reconstructs the input. This study used the mean square error (MSE) as the reconstruction loss in training. LSTM, an artificial recurrent neural network, was designed to address the vanishing gradients in traditional recurrent neural networks (RNNs) [
33]. As the number of hidden layers in a neural network and the number of nodes in each layer increase, the last layer is trained while the initial layer is not trained.
This long-term dependency problem arises from the vanishing gradient problem, where the gradients tend to converge to zero during the gradient propagation process, particularly when the data length increases during the training phase of RNNs [
34,
35]. On the other hand, unlike traditional RNNs, LSTM can effectively overcome the vanishing gradient problem by incorporating long- and short-term state values in the learning process, enabling successful learning even with long training durations [
36,
37]. In this study, an LSTM autoencoder consisting of two LSTM layers was implemented because time series data were used, as shown in
Figure 8. Each layer is used as an encoder and decoder [
38]. Furthermore, the repeat vector was used in the decoder part to restore the compressed representation to the original input sequence. The repeat vector function repeats the compressed latent space representation to produce a representation that matches the sequence length. This allows the decoder to use the compressed representation multiple times to reconstruct the original input sequence. Using the LSTM autoencoder, the original feature vectors were trained as input data, and the output vectors were used as the augmentation dataset. The output dataset was generated and replicated to minimize the MSE, resulting in a dataset with similar characteristics and patterns to the input dataset, as shown in
Figure 9. The equations and parameter descriptions for the LSTM autoencoder are as follows [
32,
33].
: the input time series data.
: the output (latent variable) of the encoder.
: the output (reconstructed time series data) of the decoder.
and : the hidden states of the LSTM.
, , , and : the learnable parameters (weights and biases) of the model.
: the activation function, typically sigmoid or tanh function.
MSE: the mean squared error, loss function.
: the ith element of the input data.
: the ith element of the model’s prediction (reconstructed data).
: the number of elements in the input data.
Figure 8.
Structure of the LSTM autoencoder layers.
Figure 8.
Structure of the LSTM autoencoder layers.
Figure 9.
Result of feature augmentation using the LSTM autoencoder.
Figure 9.
Result of feature augmentation using the LSTM autoencoder.
2.2. Result of Classification
To compare the accuracy of failure prediction, the selected classification algorithms were random forest [
39] and LightGBM [
40]. To enhance their performance, the ‘Bayesian optimization’ method was employed for hyperparameter tuning. Random forest, an ensemble technique, is rooted in decision trees and serves as a classifier. Decision trees build tree-like models based on input variables, efficiently growing the tree by identifying optimal splitting rules at each branch. However, the vulnerability of a single decision tree to overfitting can hinder its ability to generalize well. To address this concern, the random forest algorithm is applied to alleviate overfitting concerns. A decision tree, by itself, operates as a tree algorithm for data classification or prediction. It navigates the classification or prediction process by creating a tree structure grounded in the data, partitioning it into multiple child nodes through evaluations of specific conditions at each node. The criteria of these conditions are typically determined by metrics such as information gain (
or the Gini index (
. These metrics measure the impurity of class distribution at each node, selecting a splitting criterion that minimizes the difference in impurity before and after the split [
39,
40].
: the data of the parent node.
: the data of the th child node.
: the splitting criterion variable.
: the number of child nodes generated after splitting.
: the number of data points in the parent node.
: the number of data points in the th child node.
the number of classes.
: the ratio of the th class.
Random forest stands out as a notable ensemble learning technique, leveraging the power of decision trees. The methodology of random forest is structured around the collaborative efforts of multiple decision trees, which are subsequently aggregated to yield prediction results. The workflow of random forest unfolds as follows:
Bootstrap sample creation: The process starts by randomly selecting a subset of the input data to create what is known as a bootstrap sample. This sample comprises a distinct dataset consisting of data instances randomly extracted from the original input dataset.
Multiple decision tree generation: Next, numerous decision trees are generated, each stemming from a bootstrap sample. These decision trees come into existence with a random element, ensuring their diversity and independence.
Data prediction by decision trees: Each of the generated decision trees is then utilized to predict the input data. This prediction process is carried out individually for all the decision trees in the ensemble.
Aggregation of predictions: The prediction results obtained from the individual decision trees are aggregated. This aggregation can take the form of averaging the predictions or adopting a majority voting approach, depending on the task. The aggregated outcome serves as the foundation for the final predictions made by the random forest model.
By following these steps, random forest harnesses the collective insights of multiple decision trees, effectively enhancing prediction accuracy and generalization capabilities. Random forest addresses overfitting by generating multiple models from different data subsets. This diversification improves robustness against noise and uncertainties. The adjustment of the optimal number of decision trees and the splitting criteria can be performed through hyperparameter tuning. Typically, hyperparameters such as the splitting criteria of decision trees and the tree depth are set. The prediction function of random forest is as follow, where
is the number of generated decision trees and
represents the prediction function of the
th decision tree.
LightGBM is a machine learning model based on the gradient boosting decision tree (GBDT) algorithm. Gradient boosting works by improving the prediction model as new models compensate for the errors of the previous model. Therefore, multiple decision trees can be combined to develop a more robust model that minimizes overfitting. The working mechanism of lightGBM is similar to the conventional GBDT algorithm, but it utilizes the leaf-wise approach during the splitting process (
Figure 10). This approach allows lightGBM to produce more unbalanced trees than the traditional level-wise approach, resulting in improved predictive performance. Furthermore, lightGBM includes the feature to perform splitting using only a subset of the data, ensuring faster processing speed for large-scale datasets. However, lightGBM may result in deeper trees, depending on their leaf-wise characteristics and hyperparameter settings, which may lead to deeper trees [
41]. While this can improve the prediction accuracy of the training data, it may result in lower accuracy when predicting new data because of the overfitting problem. In the case of lightGBM, the aim was to minimize the overfitting problem through the feature augmentation conducted previously. The objective function and parameter descriptions for LightGBM are as follows [
42]:
: the loss functions used in the objective function.
: the actual value for the th data.
: the prediction from the previous time step (t − 1).
: the prediction of the th tree for the th data point .
: a term used to regulate the complexity of the tree.
: the number of leaf nodes in the tree.
: the cost parameter associated with the number of leaf nodes.
: a coefficient that regulates the weight of leaf nodes.
: the weights assigned to the tree nodes.
Figure 10.
Two kinds of tree growth: (a) level-wise growth, (b) leaf-wise growth.
Figure 10.
Two kinds of tree growth: (a) level-wise growth, (b) leaf-wise growth.
Bayesian optimization is a method for finding the optimal solution that maximizes an arbitrary objective function. This optimization technique can be applied to any function for which observations can be obtained and is particularly useful for optimizing black-box functions with high cost and unknown shapes [
43]. Therefore, Bayesian optimization is used mainly as a hyperparameter optimization method for machine learning models, taking advantage of the characteristics of such optimization techniques [
44]. The optimized hyperparameters were derived through Bayesian optimization, as shown in
Table 6. In Bayesian optimization, the aim is to identify the hyperparameter combination
that minimizes or maximizes the objective function
. The objective function typically takes a form similar to Equation (15).
represents the actual value of the objective function for the hyperparameter combination
.
is defined as the sum of the actual objective function value
and the noise
. Bayesian optimization involves experimentation with various hyperparameter combinations while modeling both the genuine objective function value
and the accompanying noise
. Through iterative processes, the next hyperparameter combination to explore is forecast, advancing the optimization process.
Because forklifts move continuously, vibration data has the characteristics of time series data. The time series data and the state changes in the condition segment (center of heavy objects carried by forklift) do not depend on the state at a single point in time but on the past values. Therefore, the probability of classifying the conditioning segment was the EWMA to diagnose the conditioning segment contextually using the moving average instead of diagnosing the conditioning segment only by the probability at that time, as shown in
Table 7. Contextual diagnosis in machine learning is a technique to diagnose by considering the context of the given data [
45]. This provides a more profound understanding than simply analyzing and predicting data patterns. It simply considers the context of the data before and after, rather than individual data points, to help make an accurate diagnosis. In addition, it is used effectively for outlier detection in time series [
46] and partial data [
47]. This study attempted to minimize the effect of noise, such as outliers, using the exponentially weighted moving average for contextual diagnosis. In applying contextual diagnosis, this study examined the effects of the window size on the moving average.
Figure 11 presents the learning and prediction process flow.
As a result of contextual diagnosis through the exponentially weighted moving average, the classification probability of each condition segment predicted by machine learning changes, as listed in
Table 7. Forklifts carry and transport unbalanced heavy objects during continuous movement or operation, and the centers of heavy objects do not fluctuate on a one-second basis. Therefore, a two to three-second window was used to calculate the moving average probability. As a result, when the condition segment was diagnosed as “center”, applying a moving average to the probabilities in certain outlier segments diagnosed as “left” or “right” would result in lower values influenced by past data.
Figure 12 and
Figure 13 present these probabilities as graphs as a function of time. From the observed results, the centers of heavy objects carried by the forklift were diagnosed more accurately by the generated classifier.
Because the data imbalance was minimized, the performance was compared using the accuracy score of 24 classifiers, including random forest and lightGBM (
Table 8). First, the accuracy increased in all cases as the window size of the exponentially weighted moving average for smoothing the feature vector time series data increased and the alpha value decreased. The classification probabilities of the condition segment predicted by machine learning were subjected to the moving average to achieve a contextual diagnosis. In all cases, the classification accuracy of the condition segment increased gradually as the size of the moving average window increased, and the alpha decreased. On the other hand, although the data augmentation minimized the overfitting of the model, it resulted in the same or slightly lower accuracy.
Applying moving average to the probabilities of the lightGBM model resulted in an overall increase in the scores (cases 13–24). This trend can be seen in the probability graphs diagnosing each condition segment in
Figure 12 and
Figure 13. However, lightGBM, with its leaf-wise growth strategy, tended to overfit with increasing tree depth and often has probabilities highly skewed towards 0 or 1. Therefore, it was difficult to observe performance improvement in the combination of the augmented dataset and contextual diagnosis for the model (cases 13, 16, 19, and 22).
Compared to lightGBM, random forest exhibited relatively less overfitting and showed gradual fluctuations in probabilities corresponding to changes in the time series. This trend can be observed in
Figure 13. The diagnosis of the condition segments was not sigmoidal but rather smooth and gradual because the probability was calculated by averaging the voting values of multiple randomly generated decision trees. These characteristics were expressed in classifiers utilizing the augmented dataset with AWGN and LSTM autoencoders. When applying AWGN and LSTM autoencoders to the dataset and contextual diagnosis in cases 10–12, the application of the probability moving average resulted in a higher score of 0.0331 (3.31%) compared to cases 1–3. On the other hand, the random forest score was lower than lightGBM in all cases when the moving average was not applied (without a contextual diagnosis).
By applying machine learning and contextual diagnosis, the diagnosis of the centers of heavy objects carried by forklifts was performed by the condition segment during the process of lifting, tilting, and moving heavy objects on uneven ground using a forklift. As a result, the random forest model (case 12) achieved a maximum accuracy of 0.9563, while the lightGBM model (case 24) achieved a maximum accuracy of 0.9566.



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}