
CNN-ViT Supported Weakly-Supervised Video Segment Level Anomaly Detection



Abstract
:1. Introduction
- We propose five deep models for WVAED problems by designing a MIL-based generalized framework CNN-ViT-TSAN. The information fusion between CNN and ViT is a unique contribution;
- We propose a TSAN that helps to provide anomaly scores for video snippets in WVAED problems;
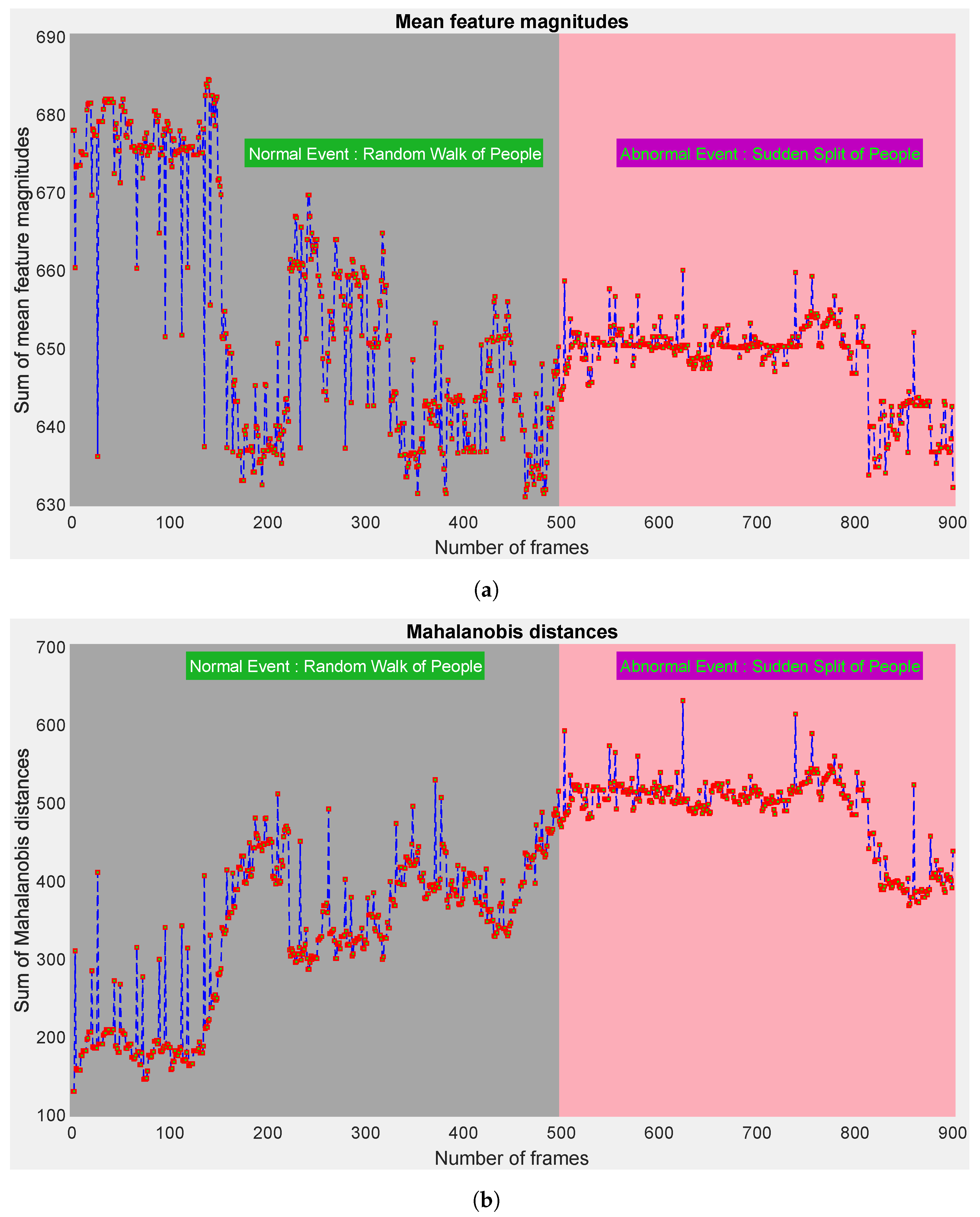
- We uniquely introduce the usage of the Mahalanobis metric for calculating probability scores in the TSAN;
- Experiments on several benchmark datasets demonstrated the superiority of our models compared with the state-of-the-art approaches.
2. Related Work
2.1. CNN-Based WVAED Methods
2.2. ViT-Based WVAED Methods
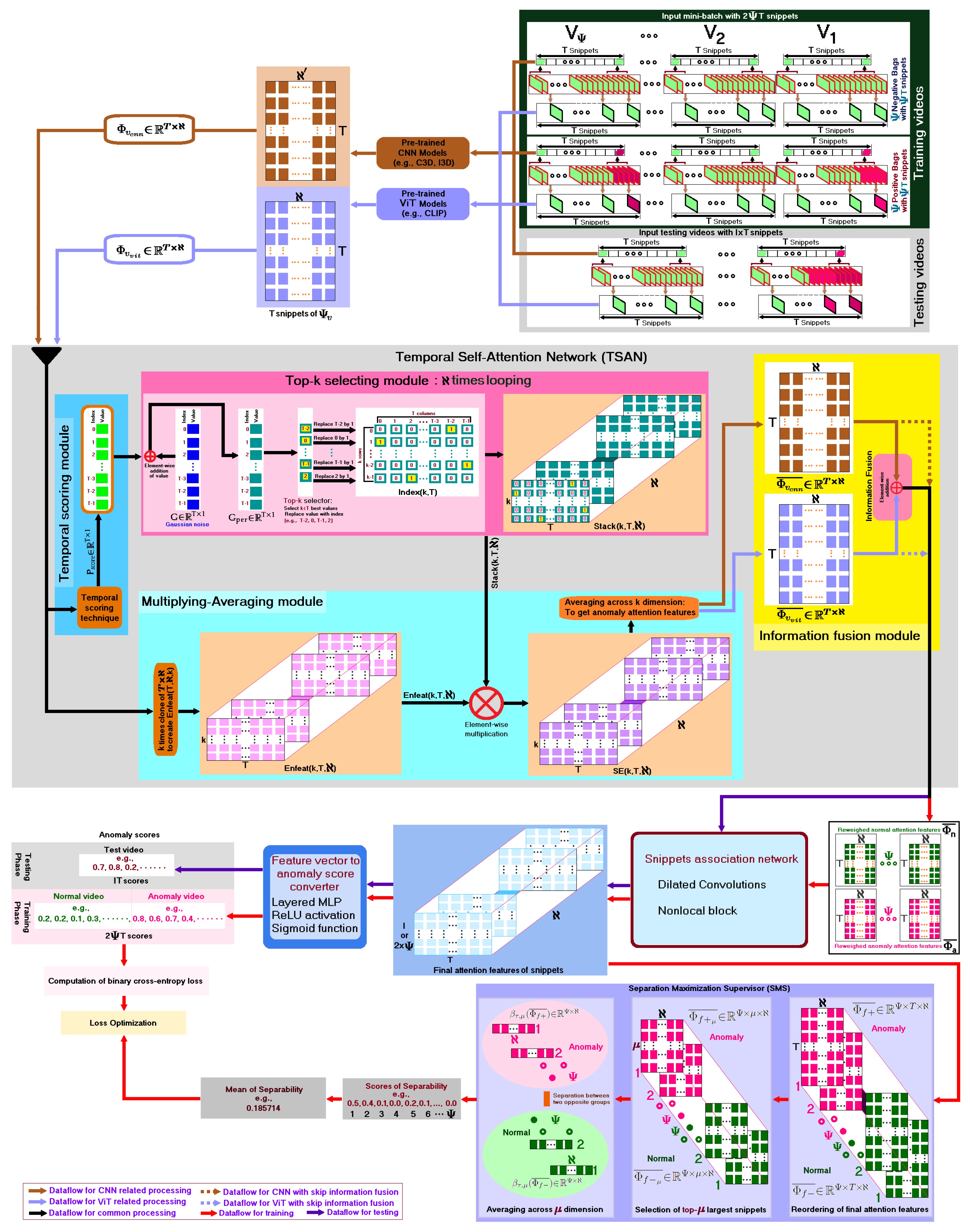
3. Proposed Generalized Framework
3.1. Feature Extraction
3.1.1. Feature Extraction Using a Pretrained CNN
3.1.2. Feature Extraction Using a Pretrained ViT
3.2. Temporal Self-Attention Network (TSAN)
3.2.1. Temporal Scoring Module
| Algorithm 1: Calculation of the probability scores considering Mahalanobis distances |
 |
| Algorithm 2: Processing of the probability scores in the TSAN |
 |
3.2.2. Top-k Selecting Module
3.2.3. Multiplying-Averaging Module
3.2.4. Information Fusion Module
3.3. Training Phase
3.4. Separation Maximization Supervisor (SMS) Learning
3.5. Loss Optimization
3.6. Testing Phase
4. Experimental Setup and Results
4.1. Used Datasets
4.1.1. UMN Dataset
4.1.2. UCSD-Peds Dataset
4.1.3. ShanghaiTech Dataset
4.1.4. UCF-Crime Dataset
4.2. Implementation Details
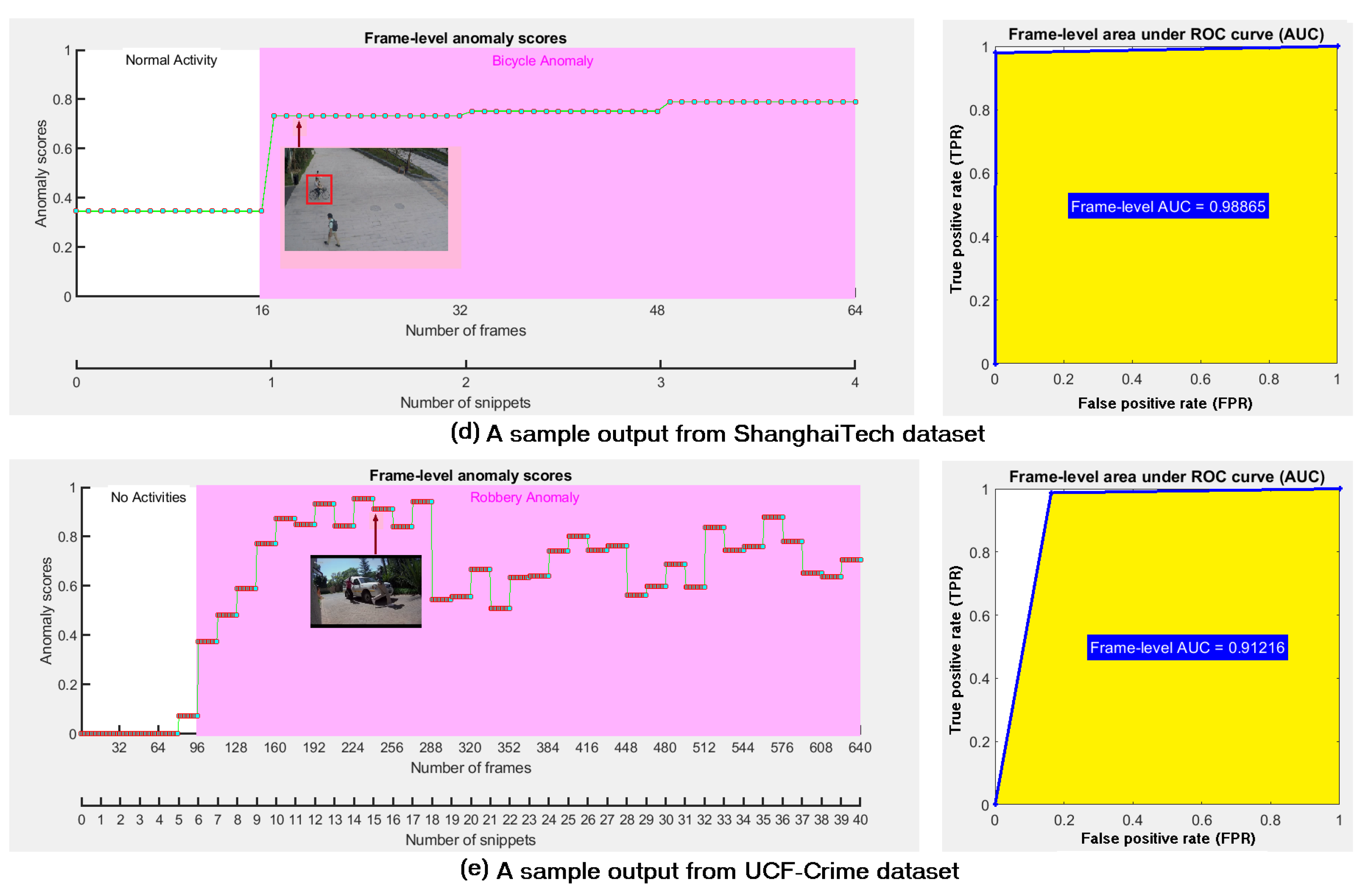
4.3. Results on Various Datasets
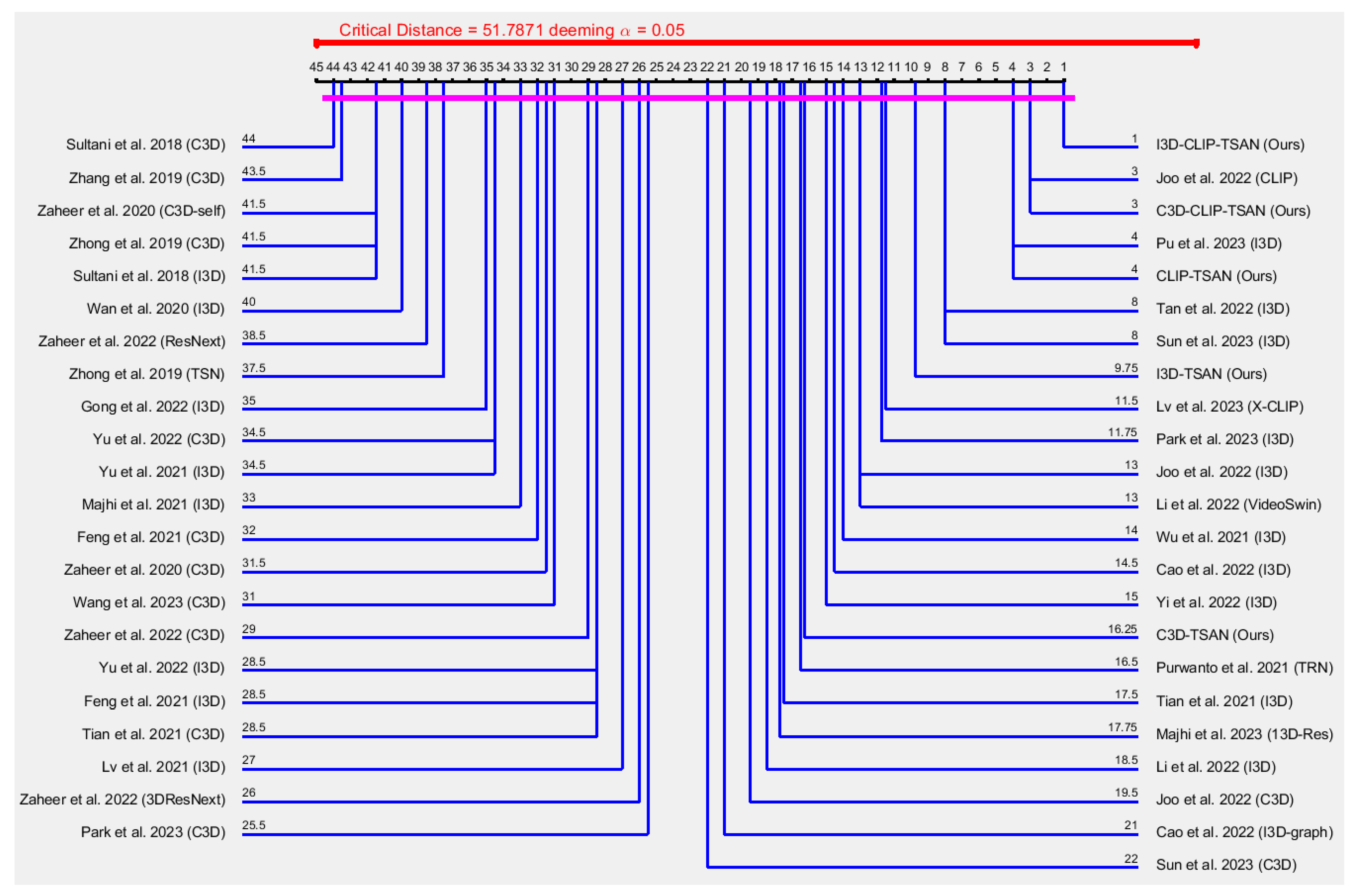
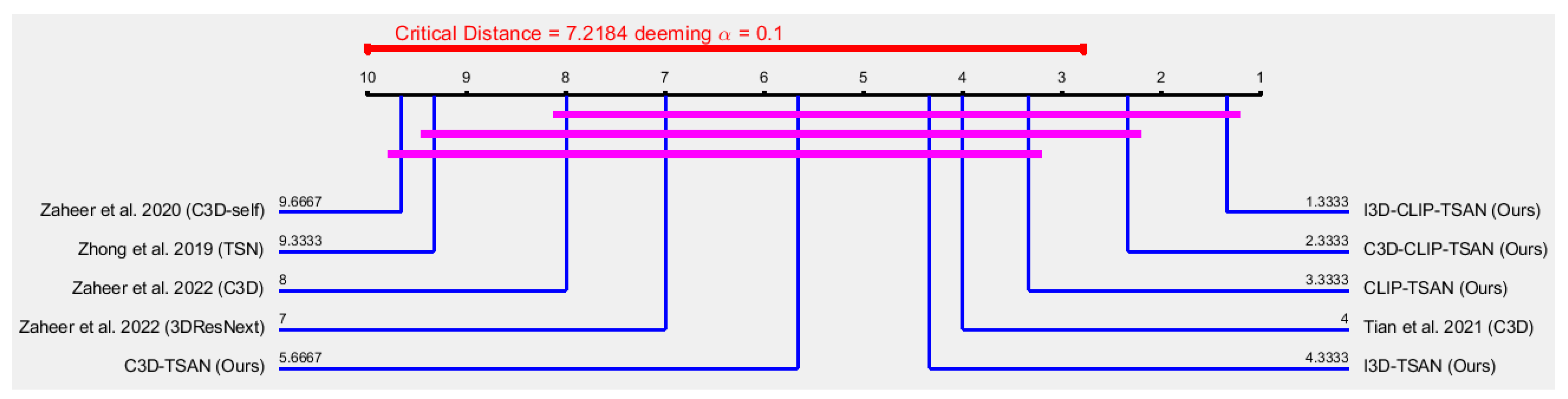
4.4. Performance Comparison
4.5. Reasons for Superiority
4.5.1. Advantage of Information Fusion
4.5.2. Better Information Gains with the Mahalanobis Metric
4.6. Analysis of the Best Network
4.7. Ablation Study
4.8. Limitation of Our Model
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, K.; Ma, H. Exploring Background-bias for Anomaly Detection in Surveillance Videos. In Proceedings of the International Conference on Multimedia (MM), Nice, France, 21–25 October 2019; pp. 1490–1499. [Google Scholar]
- Gong, D.; Liu, L.; Le, V.; Saha, B.; Mansour, M.R.; Venkatesh, S.; van den Hengel, A. Memorizing Normality to Detect Anomaly: Memory-Augmented Deep Autoencoder for Unsupervised Anomaly Detection. In Proceedings of the International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1705–1714. [Google Scholar]
- Zaheer, M.Z.; Mahmood, A.; Khan, M.H.; Segu, M.; Yu, F.; Lee, S.I. Generative Cooperative Learning for Unsupervised Video Anomaly Detection. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 14724–14734. [Google Scholar]
- Sharif, M.; Jiao, L.; Omlin, C. Deep Crowd Anomaly Detection by Fusing Reconstruction and Prediction Networks. Electronics 2023, 12, 1517. [Google Scholar]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. 2009, 41, 15. [Google Scholar]
- Zhong, J.X.; Li, N.; Kong, W.; Liu, S.; Li, T.H.; Li, G. Graph Convolutional Label Noise Cleaner: Train a Plug-And-Play Action Classifier for Anomaly Detection. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 1237–1246. [Google Scholar]
- Zaheer, M.Z.; Mahmood, A.; Astrid, M.; Lee, S. CLAWS: Clustering Assisted Weakly Supervised Learning with Normalcy Suppression for Anomalous Event Detection. In Proceedings of the European Conference Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; Volume 12367, pp. 358–376. [Google Scholar]
- Sultani, W.; Chen, C.; Shah, M. Real-World Anomaly Detection in Surveillance Videos. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6479–6488. [Google Scholar]
- Zhang, J.; Qing, L.; Miao, J. Temporal Convolutional Network with Complementary Inner Bag Loss for Weakly Supervised Anomaly Detection. In Proceedings of the International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 4030–4034. [Google Scholar]
- Wu, P.; Liu, J.; Shi, Y.; Sun, Y.; Shao, F.; Wu, Z.; Yang, Z. Not only Look, But Also Listen: Learning Multimodal Violence Detection Under Weak Supervision. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; Volume 12375, pp. 322–339. [Google Scholar]
- Zhu, Y.; Newsam, S.D. Motion-Aware Feature for Improved Video Anomaly Detection. In Proceedings of the British Machine Vision Conference (BMVC), Cardiff, UK, 9–12 September 2019; p. 270. [Google Scholar]
- Lv, H.; Zhou, C.; Cui, Z.; Xu, C.; Li, Y.; Yang, J. Localizing Anomalies From Weakly-Labeled Videos. IEEE Trans. Image Process. 2021, 30, 4505–4515. [Google Scholar] [CrossRef]
- Purwanto, D.; Chen, Y.T.; Fang, W.H. Dance with Self-Attention: A New Look of Conditional Random Fields on Anomaly Detection in Videos. In Proceedings of the International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 173–183. [Google Scholar]
- Thakare, K.V.; Sharma, N.; Dogra, D.P.; Choi, H.; Kim, I.J. A multi-stream deep neural network with late fuzzy fusion for real-world anomaly detection. Expert Syst. Appl. 2022, 201, 117030. [Google Scholar]
- Sapkota, H.; Yu, Q. Bayesian Nonparametric Submodular Video Partition for Robust Anomaly Detection. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 3202–3211. [Google Scholar]
- Liu, Y.; Liu, J.; Ni, W.; Song, L. Abnormal Event Detection with Self-guiding Multi-instance Ranking Framework. In Proceedings of the International Joint Conference on Neural Networks, IJCNN 2022, Padua, Italy, 18–23 July 2022; pp. 1–7. [Google Scholar]
- Carbonneau, M.A.; Cheplygina, V.; Granger, E.; Gagnon, G. Multiple instance learning: A survey of problem characteristics and applications. Pattern Recognit. 2018, 77, 329–353. [Google Scholar]
- Liu, Y.; Yang, D.; Wang, Y.; Liu, J.; Song, L. Generalized Video Anomaly Event Detection: Systematic Taxonomy and Comparison of Deep Models. arXiv 2023, arXiv:2302.05087. [Google Scholar]
- Tian, Y.; Pang, G.; Chen, Y.; Singh, R.; Verjans, J.W.; Carneiro, G. Weakly-supervised Video Anomaly Detection with Robust Temporal Feature Magnitude Learning. In Proceedings of the International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 4955–4966. [Google Scholar]
- Joo, H.K.; Vo, K.; Yamazaki, K.; Le, N. CLIP-TSA: CLIP-Assisted Temporal Self-Attention for Weakly-Supervised Video Anomaly Detection. arXiv 2022, arXiv:2212.05136. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D Convolutional Neural Networks for Human Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4724–4733. [Google Scholar]
- Patashnik, O.; Wu, Z.; Shechtman, E.; Cohen-Or, D.; Lischinski, D. StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery. In Proceedings of the International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 2065–2074. [Google Scholar]
- Ho, V.K.V.; Truong, S.; Yamazaki, K.; Raj, B.; Tran, M.T.; Le, N. AOE-Net: Entities Interactions Modeling with Adaptive Attention Mechanism for Temporal Action Proposals Generation. Int. J. Comput. Vis. 2023, 131, 302–323. [Google Scholar]
- Yamazaki, K.; Vo, K.; Truong, S.; Raj, B.; Le, N. VLTinT: Visual-Linguistic Transformer-in-Transformer for Coherent Video Paragraph Captioning. arXiv 2022, arXiv:2211.15103. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision. In Proceedings of the International Conference on Machine Learning (ICML), Virtual, 18–24 July 2021; Volume 139, pp. 8748–8763. [Google Scholar]
- Tran, D.; Bourdev, L.D.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Gool, L.V. Temporal Segment Networks for Action Recognition in Videos. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 2740–2755. [Google Scholar] [PubMed]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.E.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Li, L.H.; Yatskar, M.; Yin, D.; Hsieh, C.; Chang, K. VisualBERT: A Simple and Performant Baseline for Vision and Language. arXiv 2019, arXiv:1908.03557. [Google Scholar]
- Lu, J.; Batra, D.; Parikh, D.; Lee, S. ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 13–23. [Google Scholar]
- Li, Y.; Liang, F.; Zhao, L.; Cui, Y.; Ouyang, W.; Shao, J.; Yu, F.; Yan, J. Supervision Exists Everywhere: A Data Efficient Contrastive Language-Image Pre-training Paradigm. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual, 25–29 April 2022. [Google Scholar]
- Li, S.; Liu, F.; Jiao, L. Self-Training Multi-Sequence Learning with Transformer for Weakly Supervised Video Anomaly Detection. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), Conference on Innovative Applications of Artificial Intelligence (IAAI), Symposium on Educational Advances in Artificial Intelligence (EAAI), Virtual, 22 February–1 March 2022; pp. 1395–1403. [Google Scholar]
- Lv, H.; Yue, Z.; Sun, Q.; Luo, B.; Cui, Z.; Zhang, H. Unbiased Multiple Instance Learning for Weakly Supervised Video Anomaly Detection. arXiv 2023, arXiv:2303.12369. [Google Scholar]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. In Proceedings of the International Conference on Learning Representations (ICLR), Puerto Rico, PR, USA, 2–4 May 2016. [Google Scholar]
- Wang, X.; Girshick, R.B.; Gupta, A.; He, K. Non-Local Neural Networks. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- University, M. Detection of Unusual Crowd Activities in Both Indoor and Outdoor Scenes. 2021. Available online: http://mha.cs.umn.edu/proj_events.shtml#crowd (accessed on 28 March 2023).
- He, C.; Shao, J.; Sun, J. An anomaly-introduced learning method for abnormal event detection. Multim. Tools Appl. 2018, 77, 29573–29588. [Google Scholar]
- Liu, W.; Luo, W.; Lian, D.; Gao, S. Future Frame Prediction for Anomaly Detection - A New Baseline. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 6536–6545. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019; pp. 8024–8035. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Sharif, M.H. An Eigenvalue Approach to Detect Flows and Events in Crowd Videos. J. Circuits Syst. Comput. 2017, 26, 1750110. [Google Scholar] [CrossRef]
- Sharif, M.H.; Jiao, L.; Omlin, C.W. Deep Crowd Anomaly Detection: State-of-the-Art, Challenges, and Future Research Directions. arXiv 2022, arXiv:2210.13927. [Google Scholar]
- Rahman, Q.I.; Schmeisser, G. Characterization of the speed of convergence of the trapezoidal rule. Numer. Math. 1990, 57, 123–138. [Google Scholar] [CrossRef]
- Zaheer, M.Z.; Mahmood, A.; Shin, H.; Lee, S.I. A Self-Reasoning Framework for Anomaly Detection Using Video-Level Labels. IEEE Signal Process. Lett. 2020, 27, 1705–1709. [Google Scholar] [CrossRef]
- Wan, B.; Fang, Y.; Xia, X.; Mei, J. Weakly Supervised Video Anomaly Detection via Center-Guided Discriminative Learning. In Proceedings of the International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Majhi, S.; Das, S.; Brémond, F. DAM: Dissimilarity Attention Module for Weakly-supervised Video Anomaly Detection. In Proceedings of the International Conference on Advanced Video and Signal Based Surveillance (AVSS), Washington, DC, USA, 16–19 November 2021; pp. 1–8. [Google Scholar]
- Wu, P.; Liu, J. Learning Causal Temporal Relation and Feature Discrimination for Anomaly Detection. IEEE Trans. Image Process. 2021, 30, 3513–3527. [Google Scholar] [CrossRef]
- Yu, S.; Wang, C.; Ma, Q.; Li, Y.; Wu, J. Cross-Epoch Learning for Weakly Supervised Anomaly Detection in Surveillance Videos. IEEE Signal Process. Lett. 2021, 28, 2137–2141. [Google Scholar] [CrossRef]
- Feng, J.C.; Hong, F.T.; Zheng, W.S. MIST: Multiple Instance Self-Training Framework for Video Anomaly Detection. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 14009–14018. [Google Scholar]
- Zaheer, M.Z.; Mahmood, A.; Astrid, M.; Lee, S. Clustering Aided Weakly Supervised Training to Detect Anomalous Events in Surveillance Videos. arXiv 2022, arXiv:2203.13704. [Google Scholar] [CrossRef]
- Cao, C.; Zhang, X.; Zhang, S.; Wang, P.; Zhang, Y. Weakly Supervised Video Anomaly Detection Based on Cross-Batch Clustering Guidance. arXiv 2022, arXiv:2212.08506. [Google Scholar]
- Cao, C.; Zhang, X.; Zhang, S.; Wang, P.; Zhang, Y. Adaptive graph convolutional networks for weakly supervised anomaly detection in videos. arXiv 2022, arXiv:2202.06503. [Google Scholar] [CrossRef]
- Tan, W.; Yao, Q.; Liu, J. Overlooked Video Classification in Weakly Supervised Video Anomaly Detection. arXiv 2022, arXiv:2210.06688. [Google Scholar]
- Yi, S.; Fan, Z.; Wu, D. Batch feature standardization network with triplet loss for weakly-supervised video anomaly detection. Image Vis. Comput. 2022, 120, 104397. [Google Scholar] [CrossRef]
- Yu, S.; Wang, C.; Xiang, L.; Wu, J. TCA-VAD: Temporal Context Alignment Network for Weakly Supervised Video Anomly Detection. In Proceedings of the International Conference on Multimedia and Expo (ICME), Taipei, Taiwan, 18–22 July 2022; pp. 1–6. [Google Scholar]
- Gong, Y.; Wang, C.; Dai, X.; Yu, S.; Xiang, L.; Wu, J. Multi-Scale Continuity-Aware Refinement Network for Weakly Supervised Video Anomaly Detection. In Proceedings of the International Conference on Multimedia and Expo (ICME), Taipei, Taiwan, 18–22 July 2022; pp. 1–6. [Google Scholar]
- Majhi, S.; Dai, R.; Kong, Q.; Garattoni, L.; Francesca, G.; Bremond, F. Human-Scene Network: A Novel Baseline with Self-rectifying Loss for Weakly supervised Video Anomaly Detection. arXiv 2023, arXiv:2301.07923. [Google Scholar]
- Park, S.; Kim, H.; Kim, M.; Kim, D.; Sohn, K. Normality Guided Multiple Instance Learning for Weakly Supervised Video Anomaly Detection. In Proceedings of the Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 2–7 January 2023; pp. 2664–2673. [Google Scholar]
- Pu, Y.; Wu, X.; Wang, S. Learning Prompt-Enhanced Context Features for Weakly-Supervised Video Anomaly Detection. arXiv 2023, arXiv:2306.14451. [Google Scholar]
- Sun, S.; Gong, X. Long-Short Temporal Co-Teaching for Weakly Supervised Video Anomaly Detection. arXiv 2023, arXiv:2303.18044. [Google Scholar]
- Wang, L.; Wang, X.; Liu, F.; Li, M.; Hao, X.; Zhao, N. Attention-guided MIL weakly supervised visual anomaly detection. Measurement 2023, 209, 112500. [Google Scholar] [CrossRef]
- Nemenyi, P. Distribution-Free Multiple Comparisons. Ph.D. Thesis, Princeton University, Princeton, NJ, USA, 1963. [Google Scholar]
- Kullback, S.; Leibler, R. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Bousmina, A.; Selmi, M.; Ben Rhaiem, M.A.; Farah, I.R. A Hybrid Approach Based on GAN and CNN-LSTM for Aerial Activity Recognition. Remote Sens. 2023, 15, 3626. [Google Scholar] [CrossRef]
- Aksan, F.; Li, Y.; Suresh, V.; Janik, P. CNN-LSTM vs. LSTM-CNN to Predict Power Flow Direction: A Case Study of the High-Voltage Subnet of Northeast Germany. Sensors 2023, 23, 901. [Google Scholar] [CrossRef] [PubMed]
- Trinh, T.H.; Dai, A.M.; Luong, T.; Le, Q.V. Learning Longer-term Dependencies in RNNs with Auxiliary Losses. In Proceedings of the International Conference on Machine Learning (ICML), Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 4972–4981. [Google Scholar]
- Suzgun, M.; Belinkov, Y.; Shieber, S.M. On Evaluating the Generalization of LSTM Models in Formal Languages. In Proceedings of the Society for Computation in Linguistics (SCiL), New York, NY, USA, 3–6 January 2019; pp. 277–286. [Google Scholar]
- Nguyen, N.G.; Phan, D.; Lumbanraja, F.R.; Faisal, M.R.; Abapihi, B.; Purnama, B.; Delimayanti, M.K.; Mahmudah, K.R.; Kubo, M.; Satou, K. Applying Deep Learning Models to Mouse Behavior Recognition. J. Biomed. Sci. Eng. 2019, 12, 183–196. [Google Scholar] [CrossRef]
- Wang, X.; Miao, Z.; Zhang, R.; Hao, S. I3D-LSTM: A New Model for Human Action Recognition. In Proceedings of the International Conference on Advanced Materials, Intelligent Manufacturing and Automation (AMIMA), Zhuhai, China, 17–19 May 2019; pp. 1–6. [Google Scholar]
- Liu, G.; Zhang, C.; Xu, Q.; Cheng, R.; Song, Y.; Yuan, X.; Sun, J. I3D-Shufflenet Based Human Action Recognition. Algorithms 2020, 13, 301. [Google Scholar] [CrossRef]
- Obregon, D.F.; Navarro, J.L.; Santana, O.J.; Sosa, D.H.; Santana, M.C. Towards cumulative race time regression in sports: I3D ConvNet transfer learning in ultra-distance running events. In Proceedings of the International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; pp. 805–811. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Weakly Supervised Model | Feature | Frame-Level Performance Scores from Different Datasets | |||||
|---|---|---|---|---|---|---|---|---|
| UCSD-Ped2 | ShanghaiTech | UCF-Crime | ||||||
| 2018 | Sultani et al. [8] | C3D | — | — | 0.8317 | 0.1683 | 0.7541 | 0.2459 |
| Sultani et al. [8] | I3D | — | — | 0.8533 | 0.1467 | 0.7792 | 0.2208 | |
| 2019 | Zhong et al. [6] | C3D | — | — | 0.7644 | 0.2356 | 0.8108 | 0.1892 |
| Zhong et al. [6] | TSN | 0.9320 | 0.0680 | 0.8444 | 0.1556 | 0.8212 | 0.1788 | |
| Zhang et al. [9] | C3D | — | — | 0.8250 | 0.1750 | 0.7870 | 0.2130 | |
| 2020 | Zaheer et al. [46] | C3D-self | 0.9447 | 0.0553 | 0.8416 | 0.1584 | 0.7954 | 0.2046 |
| Zaheer et al. [7] | C3D | — | — | 0.8967 | 0.1033 | 0.8303 | 0.1697 | |
| Wan et al. [47] | I3D | — | — | 0.8538 | 0.1462 | 0.7896 | 0.2104 | |
| 2021 | Purwanto et al. [13] | TRN | — | — | 0.9685 | 0.0315 | 0.8500 | 0.1500 |
| Tian et al. [19] | C3D | — | — | 0.9151 | 0.0849 | 0.8328 | 0.1672 | |
| Majhi et al. [48] | I3D | — | — | 0.8822 | 0.1178 | 0.8267 | 0.1733 | |
| Tian et al. [19] | I3D | 0.9860 | 0.0140 | 0.9721 | 0.0279 | 0.8430 | 0.1570 | |
| Wu et al. [49] | I3D | — | — | 0.9748 | 0.0252 | 0.8489 | 0.1511 | |
| Yu et al. [50] | I3D | — | — | 0.8783 | 0.1217 | 0.8215 | 0.1785 | |
| Lv et al. [12] | I3D | — | — | 0.8530 | 0.1470 | 0.8538 | 0.1462 | |
| Feng et al. [51] | C3D | — | — | 0.9313 | 0.0687 | 0.8140 | 0.1860 | |
| Feng et al. [51] | I3D | — | — | 0.9483 | 0.0517 | 0.8230 | 0.1770 | |
| 2022 | Zaheer et al. [3] | ResNext | — | — | 0.8621 | 0.1379 | 0.7984 | 0.7984 |
| Zaheer et al. [52] | C3D | 0.9491 | 0.0509 | 0.9012 | 0.0988 | 0.8337 | 0.1663 | |
| Zaheer et al. [52] | 3DResNext | 0.9579 | 0.0421 | 0.9146 | 0.0854 | 0.8416 | 0.1584 | |
| Joo et al. [20] | C3D | — | — | 0.9719 | 0.0281 | 0.8394 | 0.1606 | |
| Joo et al. [20] | I3D | — | — | 0.9798 | 0.0202 | 0.8466 | 0.1534 | |
| Joo et al. [20] | CLIP | — | — | 0.9832 | 0.0168 | 0.8758 | 0.1242 | |
| Cao et al. [53] | I3D | — | — | 0.9645 | 0.0355 | 0.8587 | 0.1413 | |
| Li et al. [34] | I3D | — | — | 0.9608 | 0.0392 | 0.8530 | 0.1470 | |
| Cao et al. [54] | I3D-graph | — | — | 0.9605 | 0.0395 | 0.8467 | 0.1533 | |
| Tan et al. [55] | I3D | — | — | 0.9754 | 0.0246 | 0.8671 | 0.1329 | |
| Li et al. [34] | VideoSwin | — | — | 0.9732 | 0.0268 | 0.8562 | 0.1438 | |
| Yi et al. [56] | I3D | — | — | 0.9765 | 0.0235 | 0.8429 | 0.1571 | |
| Yu et al. [57] | C3D | — | — | 0.8835 | 0.1165 | 0.8208 | 0.1792 | |
| Yu et al. [57] | I3D | — | — | 0.8991 | 0.1009 | 0.8375 | 0.1625 | |
| Gong et al. [58] | I3D | — | — | 0.9010 | 0.0990 | 0.8100 | 0.1900 | |
| 2023 | Majhi et al. [59] | 13D-Res | — | — | 0.9622 | 0.0378 | 0.8530 | 0.1470 |
| Park et al. [60] | C3D | — | — | 0.9602 | 0.0398 | 0.8343 | 0.1657 | |
| Park et al. [60] | I3D | — | — | 0.9743 | 0.0257 | 0.8563 | 0.1437 | |
| Pu et al. [61] | I3D | — | — | 0.9814 | 0.0186 | 0.8676 | 0.1324 | |
| Lv et al. [35] | X-CLIP | — | — | 0.9678 | 0.0322 | 0.8675 | 0.1325 | |
| Sun et al. [62] | C3D | — | — | 0.9656 | 0.0344 | 0.8347 | 0.1653 | |
| Sun et al. [62] | I3D | — | — | 0.9792 | 0.0208 | 0.8588 | 0.1412 | |
| Wang et al. [63] | C3D | — | — | 0.9401 | 0.0599 | 0.8148 | 0.1852 | |
| C3D-TSAN (Ours) | C3D | 0.9675 | 0.0325 | 0.9608 | 0.0392 | 0.8578 | 0.1422 | |
| I3D-TSAN (Ours) | I3D | 0.9758 | 0.0242 | 0.9743 | 0.0257 | 0.8650 | 0.1350 | |
| CLIP-TSAN (Ours) | CLIP | 0.9811 | 0.0189 | 0.9806 | 0.0194 | 0.8763 | 0.1237 | |
| C3D-CLIP-TSAN (Ours) | C3D+CLIP | 0.9824 | 0.0176 | 0.9813 | 0.0187 | 0.8802 | 0.1198 | |
| I3D-CLIP-TSAN (Ours) | I3D+CLIP | 0.9839 | 0.0161 | 0.9866 | 0.0134 | 0.8897 | 0.1103 | |
| Feature | Mahalanobis Metric Included? | Frame-Level Performance Scores from Different Datasets | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| UMN | UCSD-Ped1 | UCSD-Ped2 | ShanghaiTech | UCF-Crime | |||||||
| Gain | Gain | Gain | Gain | Gain | |||||||
| C3D | No | 0.9136 | 1.00 | 0.8553 | 1.00 | 0.9214 | 1.00 | 0.9129 | 1.00 | 0.8262 | 1.00 |
| Yes | 0.9517 | 4.17% | 0.8996 | 5.18% | 0.9675 | 4.99% | 0.9608 | 5.25% | 0.8578 | 3.82% | |
| I3D | No | 0.9362 | 1.00 | 0.8903 | 1.00 | 0.9489 | 1.00 | 0.9359 | 1.00 | 0.8401 | 1.00 |
| Yes | 0.9644 | 3.01% | 0.9085 | 2.04% | 0.9758 | 2.83% | 0.9743 | 4.09% | 0.8650 | 2.96% | |
| CLIP | No | 0.9417 | 1.00 | 0.9063 | 1.00 | 0.9597 | 1.00 | 0.9391 | 1.00 | 0.8346 | 1.00 |
| Yes | 0.9731 | 3.33% | 0.9274 | 2.33% | 0.9811 | 2.23% | 0.9806 | 4.42% | 0.8763 | 4.99% | |
| C3D+CLIP | No | 0.9405 | 1.00 | 0.8871 | 1.00 | 0.9396 | 1.00 | 0.9422 | 1.00 | 0.8348 | 1.00 |
| Yes | 0.9876 | 5.01% | 0.9315 | 5.01% | 0.9824 | 4.56% | 0.9813 | 4.15% | 0.8812 | 5.56% | |
| I3D+CLIP | No | 0.9461 | 1.00 | 0.8943 | 1.00 | 0.9448 | 1.00 | 0.9400 | 1.00 | 0.8462 | 1.00 |
| Yes | 0.9903 | 4.67% | 0.9402 | 5.13% | 0.9839 | 4.14% | 0.9866 | 4.96% | 0.8897 | 5.14% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sharif, M.H.; Jiao, L.; Omlin, C.W. CNN-ViT Supported Weakly-Supervised Video Segment Level Anomaly Detection. Sensors 2023, 23, 7734. https://doi.org/10.3390/s23187734
Sharif MH, Jiao L, Omlin CW. CNN-ViT Supported Weakly-Supervised Video Segment Level Anomaly Detection. Sensors. 2023; 23(18):7734. https://doi.org/10.3390/s23187734
Chicago/Turabian StyleSharif, Md. Haidar, Lei Jiao, and Christian W. Omlin. 2023. "CNN-ViT Supported Weakly-Supervised Video Segment Level Anomaly Detection" Sensors 23, no. 18: 7734. https://doi.org/10.3390/s23187734
APA StyleSharif, M. H., Jiao, L., & Omlin, C. W. (2023). CNN-ViT Supported Weakly-Supervised Video Segment Level Anomaly Detection. Sensors, 23(18), 7734. https://doi.org/10.3390/s23187734