
Video Global Motion Compensation Based on Affine Inverse Transform Model

Abstract
:1. Introduction
2. Problem Description
3. Global Motion Compensation Algorithm Based on Affine Inverse Transform Model
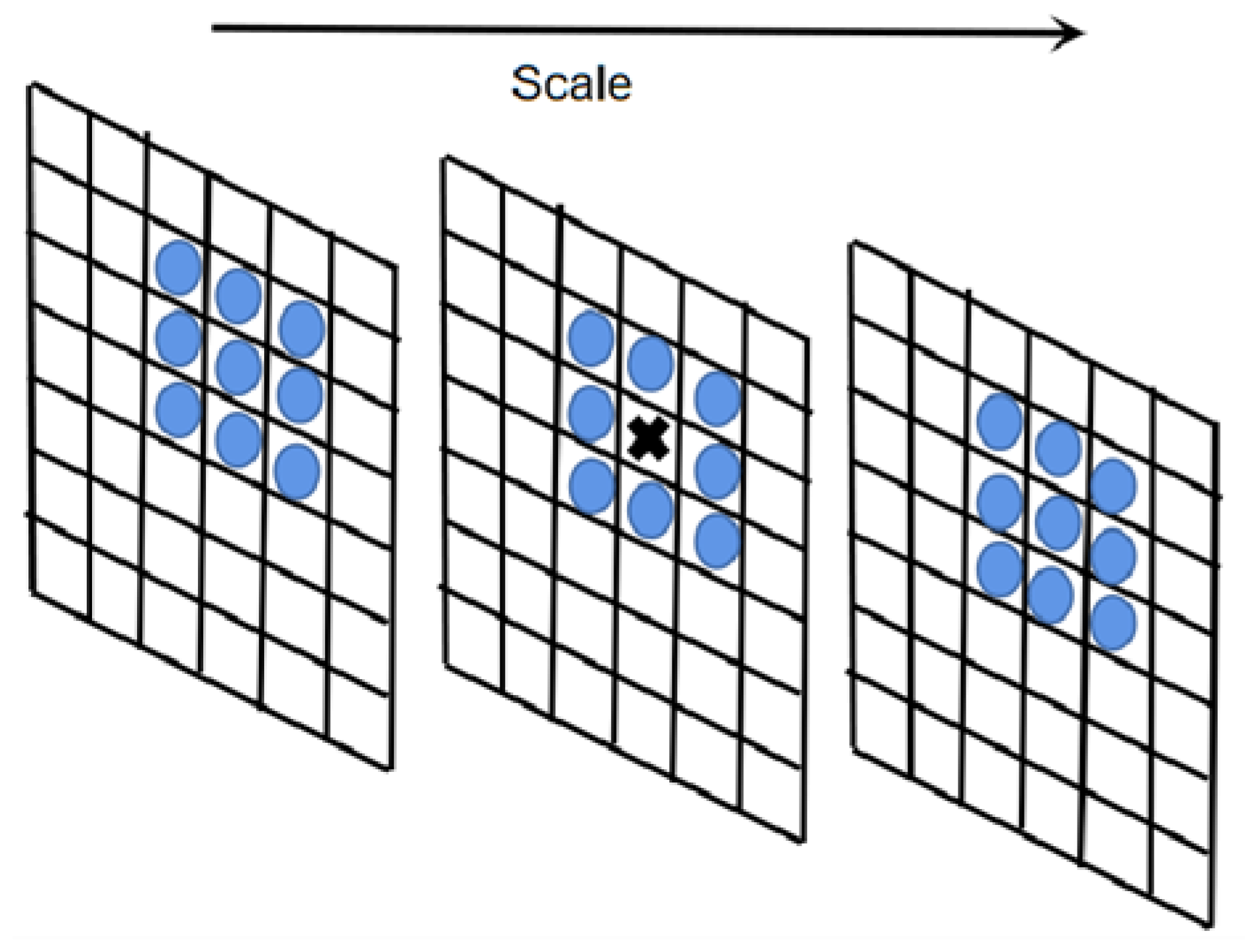
3.1. Feature Point Matching
3.2. Global Motion Estimation
3.3. Global Motion Compensation
3.4. Computational Complexity
4. Experiment
4.1. Obtaining Valid Feature Point Matches
4.2. Motion Estimation on Video Sequences
4.3. Global Motion Compensation and Object Detection
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shao, J.; Du, B.; Wu, C.; Gong, M.; Liu, T. Hrsiam: High-resolution siamese network, towards space-borne satellite video tracking. IEEE Trans. Image Process. 2021, 30, 3056–3068. [Google Scholar] [CrossRef] [PubMed]
- Schmid, J.F.; Simon, S.F.; Mester, R. Features for Ground Texture Based Localization—A Survey. arXiv 2020, arXiv:2002.11948. [Google Scholar]
- Uzair, M.; Brinkworth, R.S.; Finn, A. Bio-inspired video enhancement for small moving target detection. IEEE Trans. Image Process. 2020, 30, 1232–1244. [Google Scholar] [CrossRef] [PubMed]
- Jiang, Z.; Huynh, D.Q. Multiple pedestrian tracking from monocular videos in an interacting multiple model framework. IEEE Trans. Image Process. 2017, 27, 1361–1375. [Google Scholar] [CrossRef] [PubMed]
- Jardim, E.; Thomaz, L.A.; da Silva, E.A.; Netto, S.L. Domain-transformable sparse representation for anomaly detection in moving-camera videos. IEEE Trans. Image Process. 2019, 29, 1329–1343. [Google Scholar] [CrossRef] [PubMed]
- Feng, Z.; Zhu, X.; Xu, L.; Liu, Y. Research on human target detection and tracking based on artificial intelligence vision. In Proceedings of the 2021 IEEE Asia-Pacific Conference on Image Processing, Electronics and Computers (IPEC), Dalian, China, 14–16 April 2021; pp. 1051–1054. [Google Scholar]
- Qin, L.; Liu, Z. Body Motion Detection Technology in Video. In Proceedings of the 2021 3rd International Conference on Robotics and Computer Vision (ICRCV), Beijing, China, 6–8 August 2021; pp. 7–11. [Google Scholar]
- Kong, K.; Shin, S.; Lee, J.; Song, W.J. How to estimate global motion non-Iteratively from a coarsely sampled motion vector field. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 3729–3742. [Google Scholar] [CrossRef]
- Mohan, M.M.; Nithin, G.; Rajagopalan, A. Deep dynamic scene deblurring for unconstrained dual-lens cameras. IEEE Trans. Image Process. 2021, 30, 4479–4491. [Google Scholar] [CrossRef]
- Zhuo, T.; Cheng, Z.; Zhang, P.; Wong, Y.; Kankanhalli, M. Unsupervised online video object segmentation with motion property understanding. IEEE Trans. Image Process. 2019, 29, 237–249. [Google Scholar] [CrossRef]
- Luo, X.; Jia, K.; Liu, P.; Xiong, D.; Tian, X. Improved Three-Frame-Difference Algorithm for Infrared Moving Target. In Proceedings of the 2020 IEEE 5th International Conference on Image, Vision and Computing (ICIVC), Beijing, China, 10–12 July 2020; pp. 108–112. [Google Scholar]
- Zhao, C.; Basu, A. Dynamic deep pixel distribution learning for background subtraction. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 4192–4206. [Google Scholar] [CrossRef]
- Zhang, H.; Liu, Z. Moving target shadow detection based on deep learning in video SAR. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 4155–4158. [Google Scholar]
- Zhao, Y.; Zhao, J.; Li, J.; Chen, X. RGB-D salient object detection with ubiquitous target awareness. IEEE Trans. Image Process. 2021, 30, 7717–7731. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, S.; Zhang, X.; Wang, S.; Ma, S. Three-zone segmentation-based motion compensation for video compression. IEEE Trans. Image Process. 2019, 28, 5091–5104. [Google Scholar] [CrossRef] [PubMed]
- Xu, K.; Jiang, X.; Sun, T. Anomaly detection based on stacked sparse coding with intraframe classification strategy. IEEE Trans. Multimed. 2018, 20, 1062–1074. [Google Scholar] [CrossRef]
- Liu, H.; Hua, G.; Huang, W. Motion Rectification Network for Unsupervised Learning of Monocular Depth and Camera Motion. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 2805–2809. [Google Scholar]
- Matsushita, Y.; Yamaguchi, T.; Harada, H. Object tracking using virtual particles driven by optical flow and Kalman filter. In Proceedings of the 2019 19th International Conference on Control, Automation and Systems (ICCAS), Jeju, Republic of Korea, 15–18 October 2019; pp. 1064–1069. [Google Scholar]
- Meng, Z.; Kong, X.; Meng, L.; Tomiyama, H. Lucas-Kanade Optical Flow Based Camera Motion Estimation Approach. In Proceedings of the 2019 International SoC Design Conference (ISOCC), Jeju, Republic of Korea, 6–9 October 2019; pp. 77–78. [Google Scholar]
- Golestani, H.B.; Sauer, J.; Rohlfmg, C.; Ohm, J.R. 3D Geometry-Based Global Motion Compensation For VVC. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 2054–2058. [Google Scholar]
- Talukdar, A.K.; Bhuyan, M. A Novel Global Motion Estimation and Compensation Framework in Compressed Domain for Sign Language Videos. In Proceedings of the 2020 International Conference on Wireless Communications Signal Processing and Networking (WiSPNET), Chennai, India, 4–6 August 2020; pp. 20–24. [Google Scholar]
- Hong-Phuoc, T.; Guan, L. A novel key-point detector based on sparse coding. IEEE Trans. Image Process. 2019, 29, 747–756. [Google Scholar] [CrossRef] [PubMed]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Rodríguez, M.; Facciolo, G.; von Gioi, R.G.; Musé, P.; Morel, J.M.; Delon, J. Sift-aid: Boosting sift with an affine invariant descriptor based on convolutional neural networks. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 4225–4229. [Google Scholar]
- Medley, D.O.; Santiago, C.; Nascimento, J.C. Deep active shape model for robust object fitting. IEEE Trans. Image Process. 2019, 29, 2380–2394. [Google Scholar] [CrossRef]
- Rosten, E.; Porter, R.; Drummond, T. Faster and better: A machine learning approach to corner detection. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 32, 105–119. [Google Scholar] [CrossRef]
- Calonder, M.; Lepetit, V.; Strecha, C.; Fua, P. Brief: Binary robust independent elementary features. In Proceedings of the Computer Vision—ECCV 2010: 11th European Conference on Computer Vision, Crete, Greece, 5–11 September 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 778–792. [Google Scholar]
- Harris, C.; Stephens, M. A combined corner and edge detector. In Proceedings of the Alvey Vision Conference, Manchester, UK, 31 August–2 September 1988; Citeseer: Princeton, NJ, USA, 1988; Volume 15, pp. 147–152. [Google Scholar]
- Lv, H.; Zhang, H.; Zhao, C.; Liu, C.; Qi, F.; Zhang, Z. An Improved SURF in Image Mosaic Based on Deep Learning. In Proceedings of the 2019 IEEE 4th International Conference on Image, Vision and Computing (ICIVC), Xiamen, China, 5–7 July 2019; pp. 223–226. [Google Scholar] [CrossRef]
- Torr, P.H.; Murray, D.W. The development and comparison of robust methods for estimating the fundamental matrix. Int. J. Comput. Vis. 1997, 24, 271–300. [Google Scholar] [CrossRef]
- Yang, J.; Lu, Z.; Tang, Y.Y.; Yuan, Z.; Chen, Y. Quasi Fourier-Mellin transform for affine invariant features. IEEE Trans. Image Process. 2020, 29, 4114–4129. [Google Scholar] [CrossRef]
- Ho, M.M.; Zhou, J.; He, G.; Li, M.; Li, L. SR-CL-DMC: P-frame coding with super-resolution, color learning, and deep motion compensation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 124–125. [Google Scholar]
- Zhao, L.; Wang, S.; Zhang, X.; Wang, S.; Ma, S.; Gao, W. Enhanced motion-compensated video coding with deep virtual reference frame generation. IEEE Trans. Image Process. 2019, 28, 4832–4844. [Google Scholar] [CrossRef]
- Li, B.; Han, J.; Xu, Y.; Rose, K. Optical flow based co-located reference frame for video compression. IEEE Trans. Image Process. 2020, 29, 8303–8315. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Lu, M.; Ma, Z.; Wang, F.; Xie, Z.; Cao, X.; Wang, Y. Neural video coding using multiscale motion compensation and spatiotemporal context model. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 3182–3196. [Google Scholar] [CrossRef]
- Liu, X.; Kong, L.; Zhou, Y.; Zhao, J.; Chen, J. End-to-end trainable video super-resolution based on a new mechanism for implicit motion estimation and compensation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 March 2020; pp. 2416–2425. [Google Scholar]
- Son, H.; Lee, J.; Cho, S.; Lee, S. Real-Time Video Deblurring via Lightweight Motion Compensation. Comput. Graph. Forum 2022, 41, 177–188. [Google Scholar] [CrossRef]
- Zuo, F.; de With, P.H. Fast facial feature extraction using a deformable shape model with haar-wavelet based local texture attributes. In Proceedings of the 2004 International Conference on Image Processing, ICIP’04, Singapore, 24–27 October 2004; Volume 3, pp. 1425–1428. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | ||||||
|---|---|---|---|---|---|---|
| 0.9953 | 0.9870 | −0.0220 | 0.0023 | −0.6703 | 54.1088 | |
| 0.9615 | 0.9935 | 0.0416 | −0.0728 | −63.5515 | −61.2953 |
| Model | HRSiam | RVDMC | Ours |
|---|---|---|---|
| CPU Runtime | 0.48 | 2.3 | 0.35 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, N.; Liu, W.; Xia, X. Video Global Motion Compensation Based on Affine Inverse Transform Model. Sensors 2023, 23, 7750. https://doi.org/10.3390/s23187750
Zhang N, Liu W, Xia X. Video Global Motion Compensation Based on Affine Inverse Transform Model. Sensors. 2023; 23(18):7750. https://doi.org/10.3390/s23187750
Chicago/Turabian StyleZhang, Nan, Weifeng Liu, and Xingyu Xia. 2023. "Video Global Motion Compensation Based on Affine Inverse Transform Model" Sensors 23, no. 18: 7750. https://doi.org/10.3390/s23187750
APA StyleZhang, N., Liu, W., & Xia, X. (2023). Video Global Motion Compensation Based on Affine Inverse Transform Model. Sensors, 23(18), 7750. https://doi.org/10.3390/s23187750