
PCB Defect Detection via Local Detail and Global Dependency Information

Abstract
:1. Introduction
2. Related Works
2.1. PCB Defeat Detection
2.2. Visual Transformer
3. Methodology
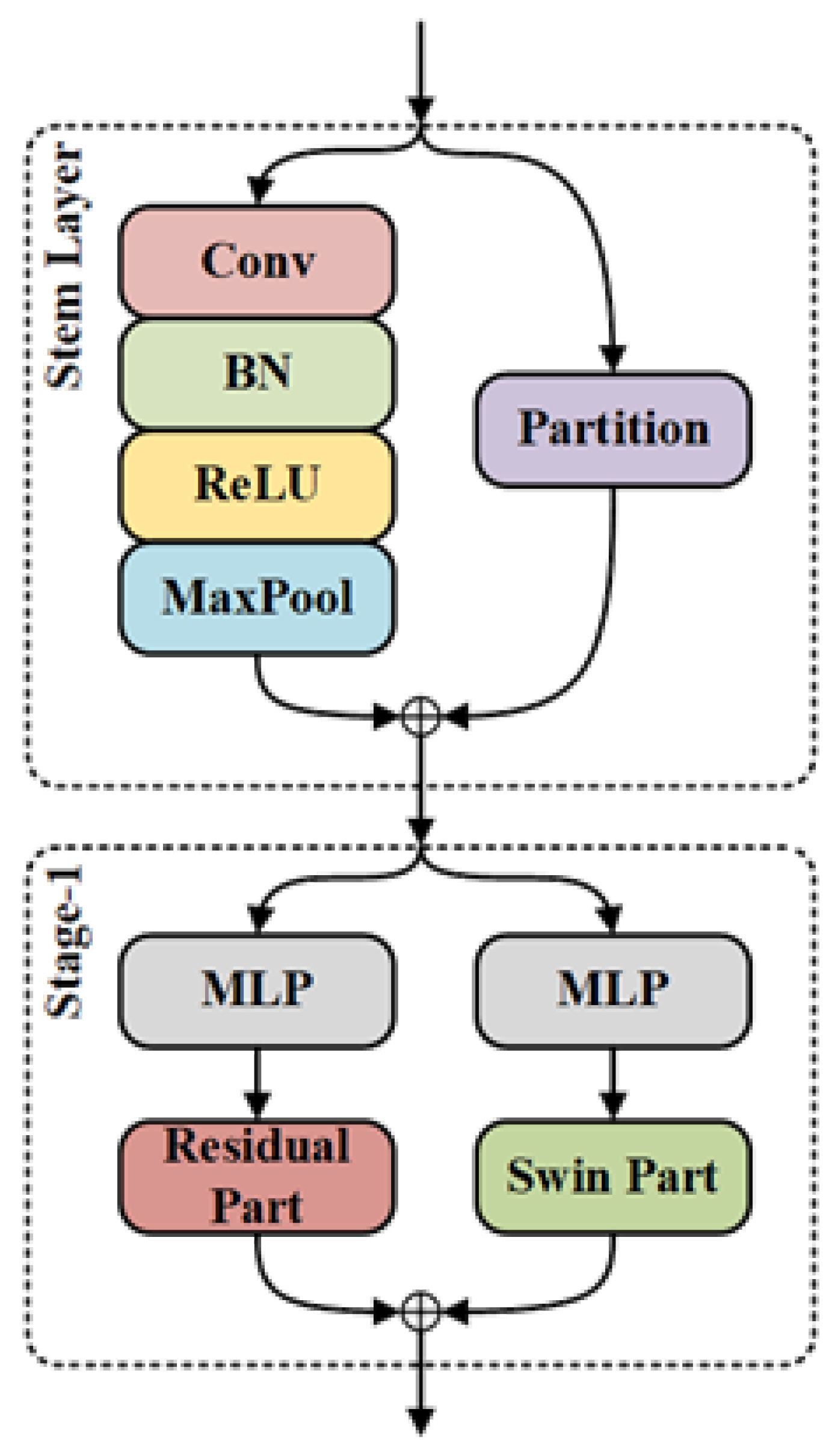
3.1. Overall Architecture
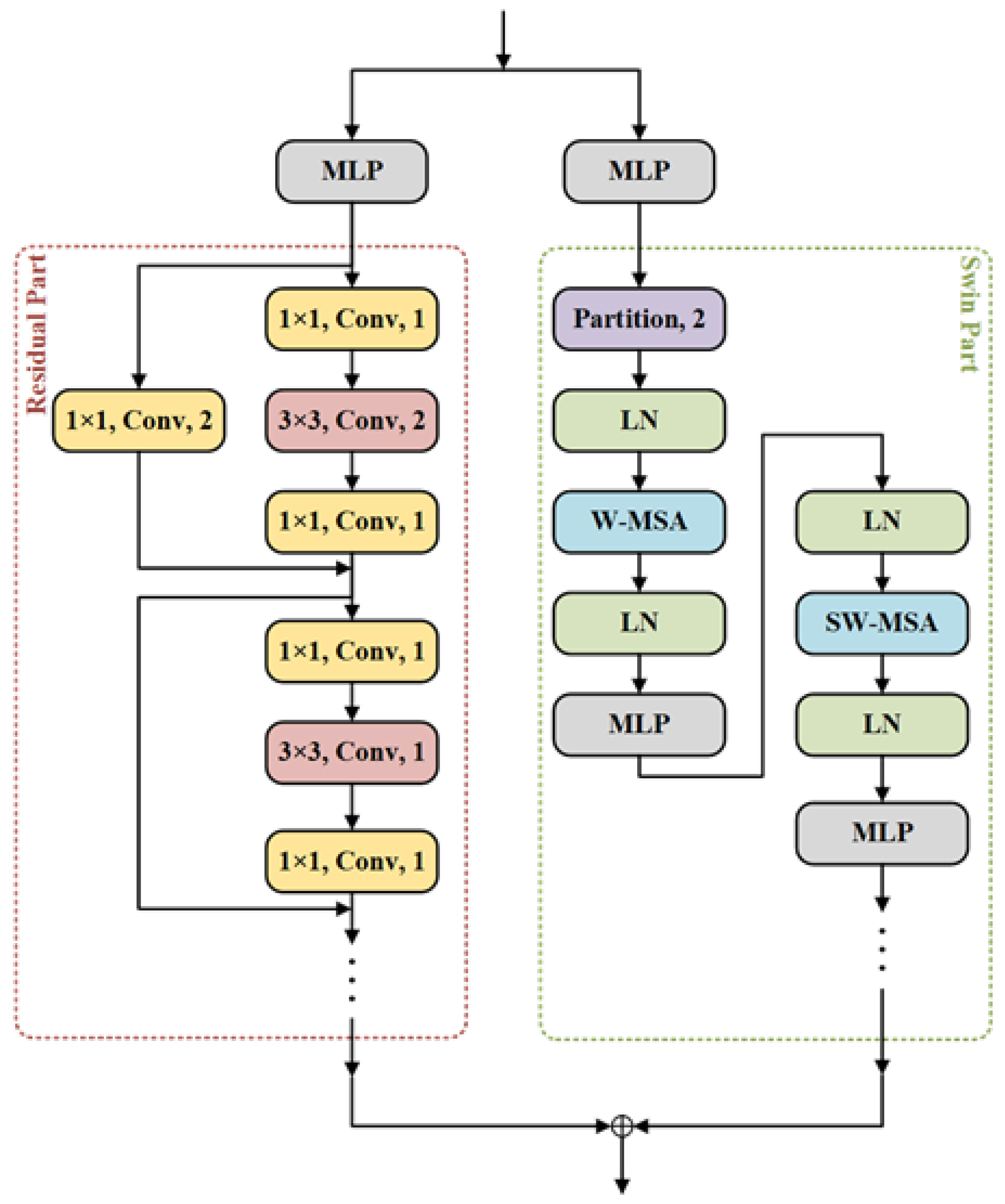
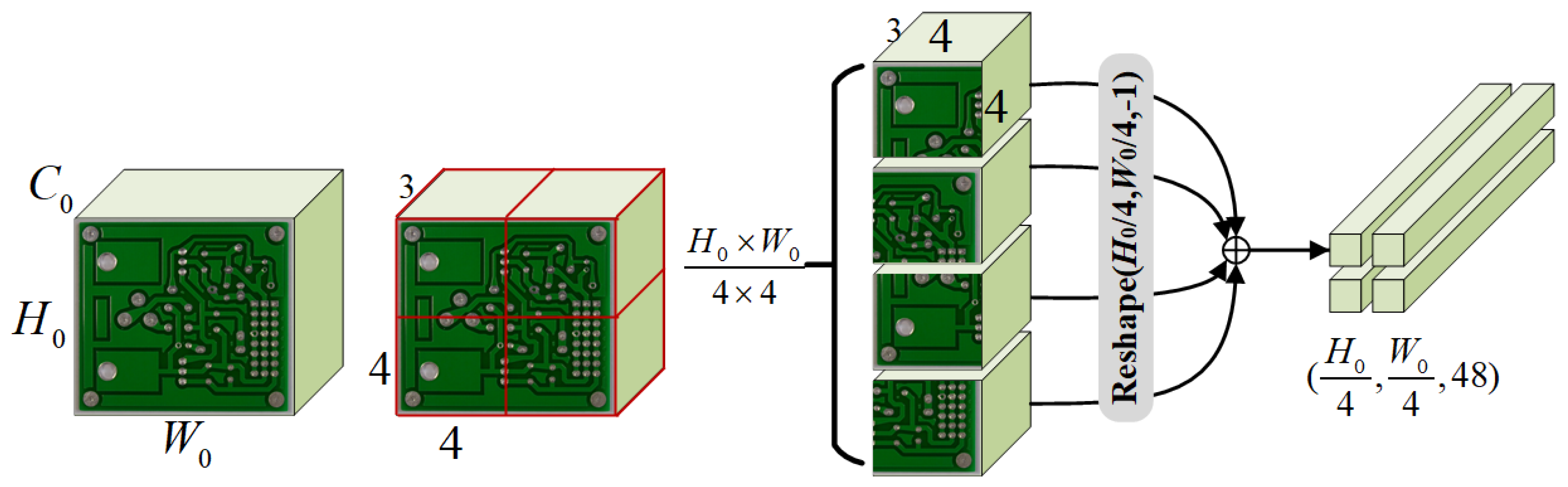
3.2. Residual Swin Transformer (ResSwinT)
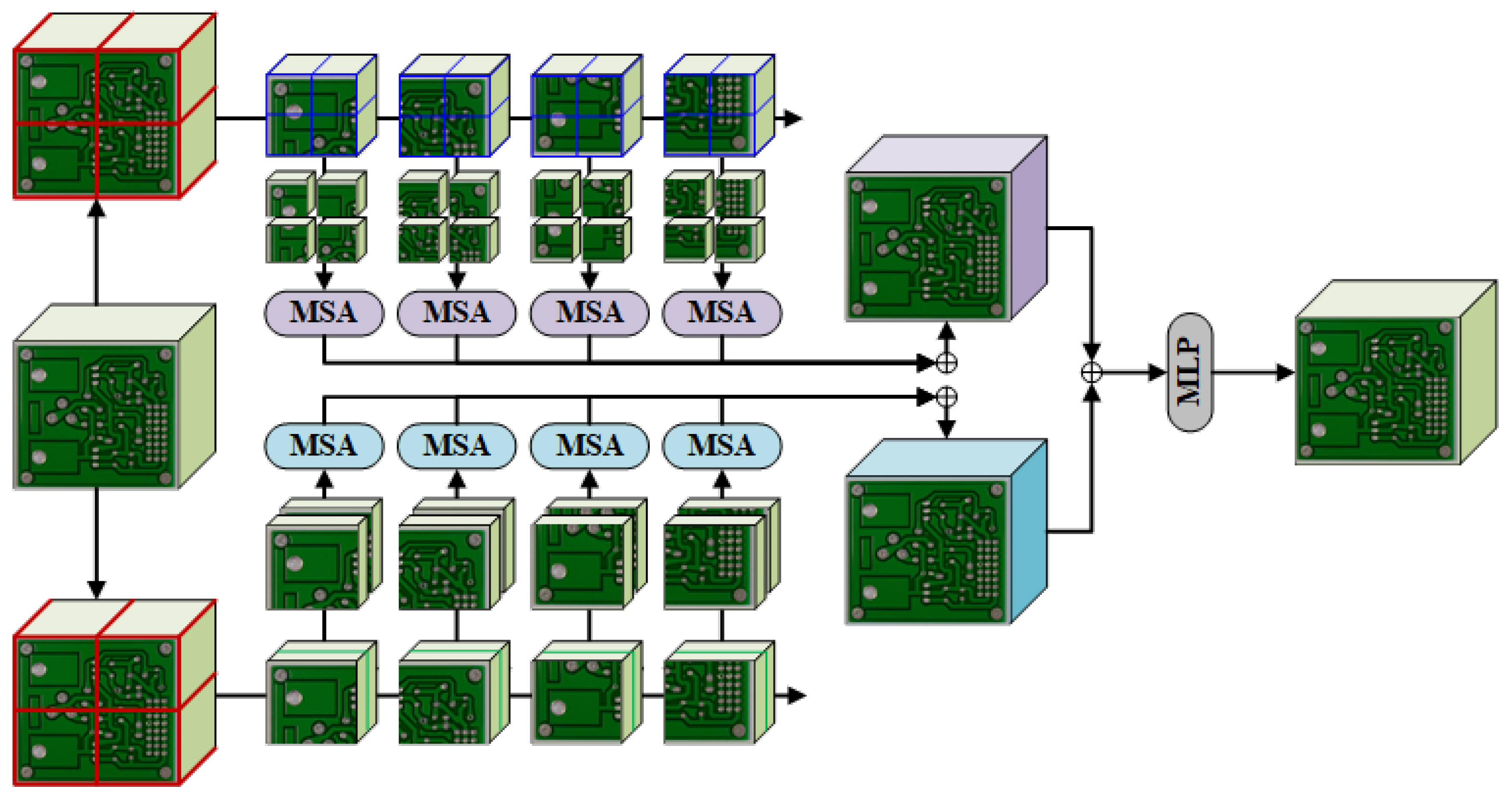
3.3. Multi-Head Spatial and Channel Self-Attention
3.3.1. SSA
3.3.2. CSA
4. Experiment Results
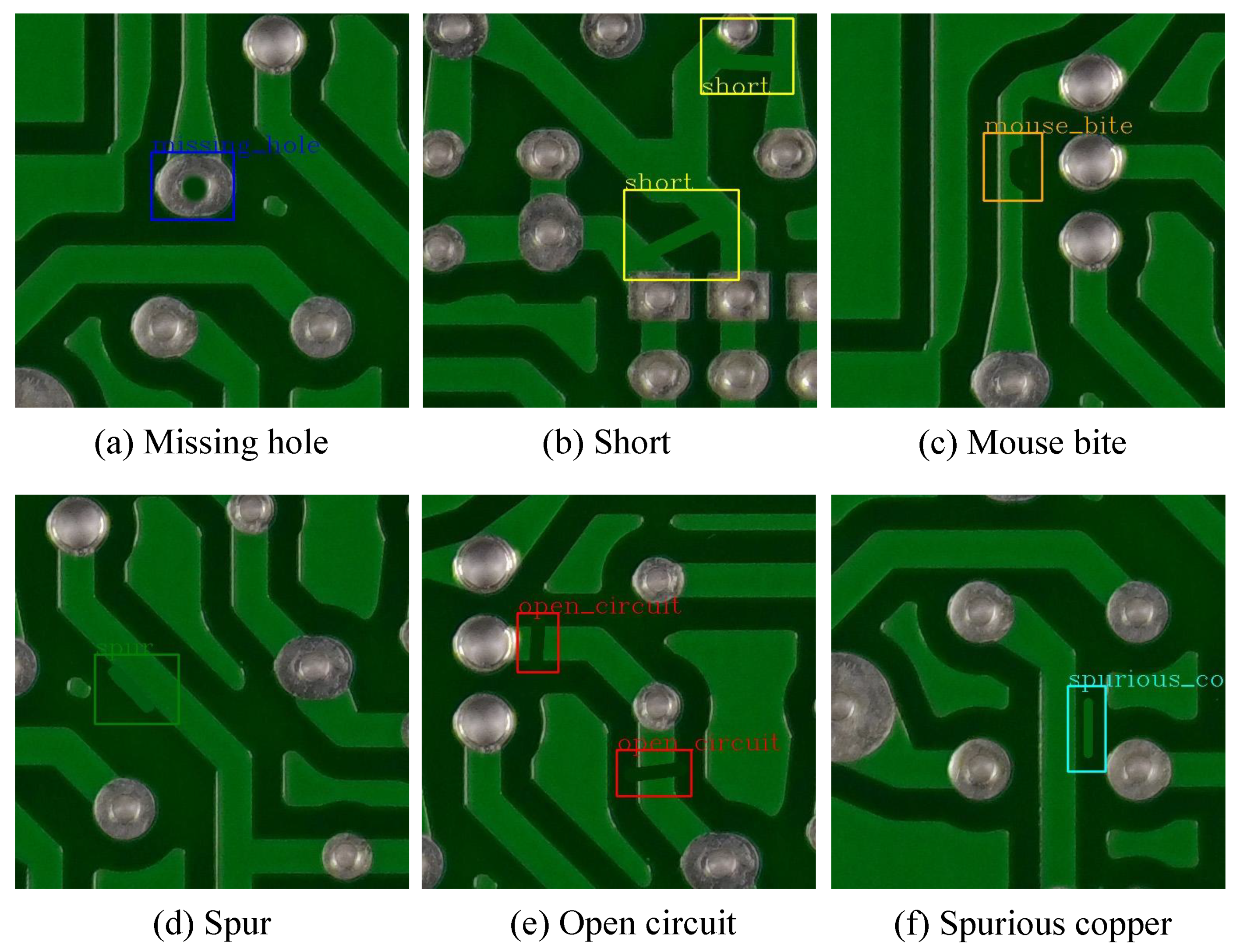
4.1. Datasets
4.1.1. PKU-Market-PCB Dataset
4.1.2. DeepPCB Dataset
4.2. Evaluation Metrics
4.3. Implemental Details
4.4. Experimental Results
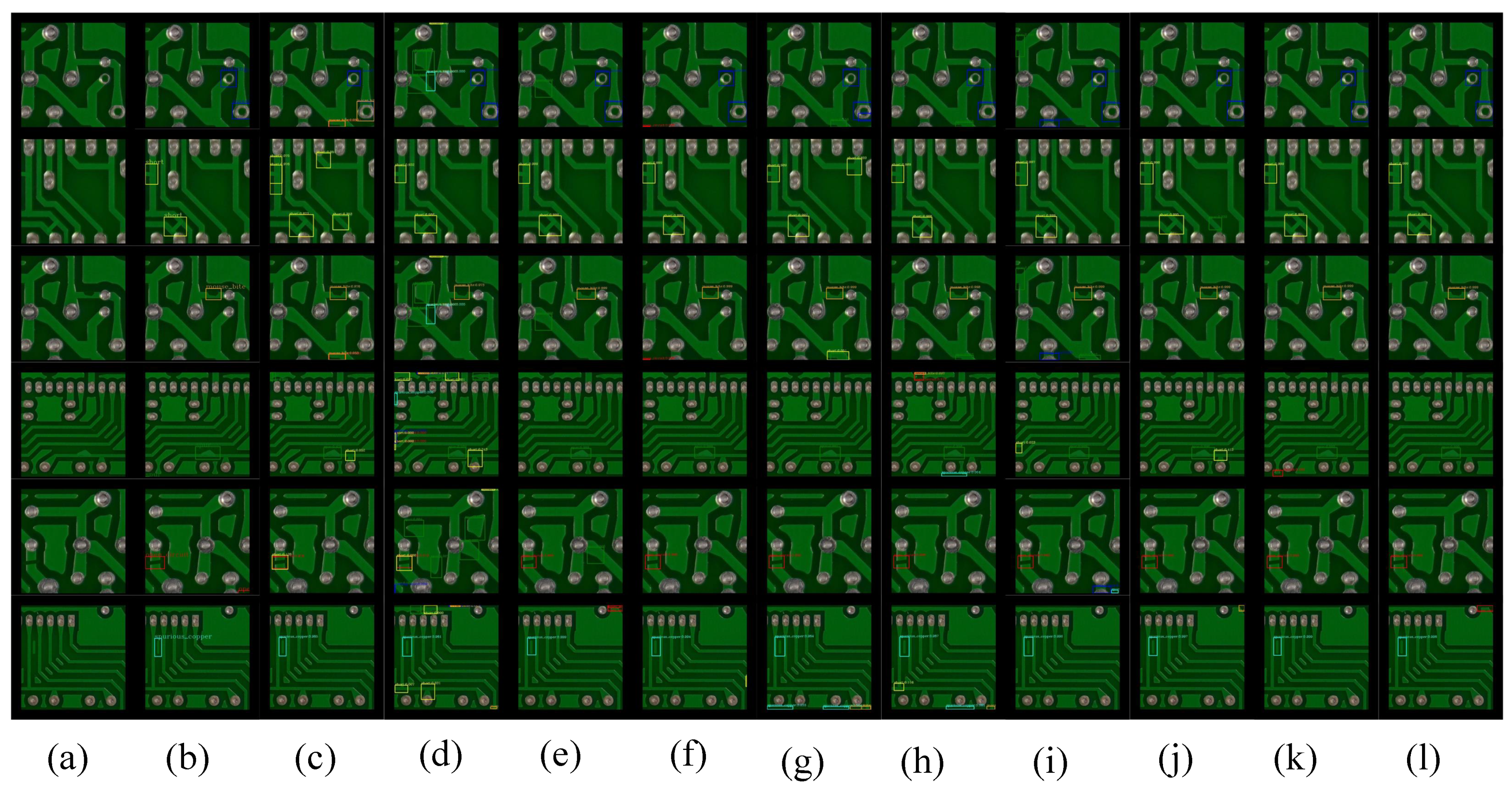
4.4.1. Experimental Results of PKU-Market-PCB
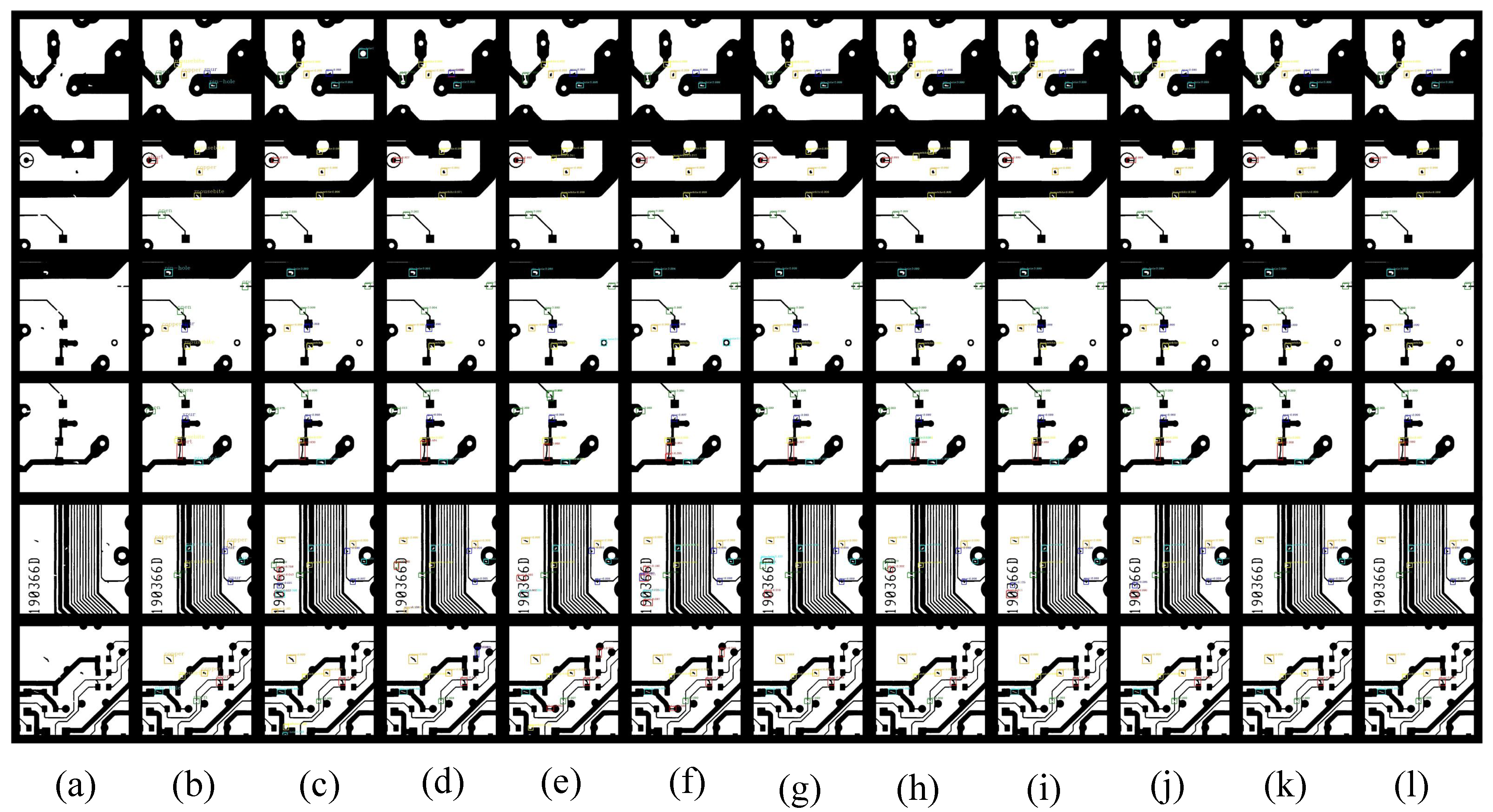
4.4.2. Experimental Results of DeepPCB
4.5. Ablation Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, S.-H.; Perng, D.-B. Automatic optical inspection system for IC molding surface. J. Intell. Manuf. 2016, 27, 915–926. [Google Scholar] [CrossRef]
- Gaidhane, V.H.; Hote, Y.V.; Singh, V. An efficient similarity measure approach for pcb surface defect detection. Pattern Anal. Appl. 2017, 21, 277–289. [Google Scholar] [CrossRef]
- Kaur, B.; Kaur, G.; Kaur, A. Detection and classification of printed circuit board defects using image subtraction method. In Proceedings of the Recent Advances in Engineering and Computational Sciences (RAECS), Chandigarh, India, 6–8 March 2014; pp. 1–5. [Google Scholar]
- Malge, P.S.; Nadaf, R.S. PCB defect detection, classification and localization using mathematical morphology and image processing tools. Int. J. Comput. Appl. 2014, 87, 40–45. [Google Scholar]
- Girshick, B.R. Fast R-CNN. arXiv 2015, arXiv:1504.08083. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2980–2988. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2015, arXiv:1506.02640. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In European Conference on Computer Vision; Springer International Publishing: Cham, Switzerland, 2020. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual Conference, 11–17 October 2021. [Google Scholar]
- Tang, S.; He, F.; Huang, X.; Yang, J. Online PCB Defect Detector On A New PCB Defect Dataset. arXiv 2019, arXiv:1902.06197. [Google Scholar]
- Ding, R.; Dai, L.; Li, G.; Liu, H. TDD-net: A tiny defect detection network for printed circuit boards. CAAI Trans. Intell. Technol. 2019, 4, 110–116. [Google Scholar] [CrossRef]
- Kim, J.; Ko, J.; Choi, H.; Kim, H. Printed Circuit Board Defect Detection Using Deep Learning via A Skip-Connected Convolutional Autoencoder. Sensors 2021, 21, 4968. [Google Scholar] [CrossRef]
- Liao, X.; Lv, S.; Li, D.; Luo, Y.; Zhu, Z.; Jiang, C. YOLOv4-MN3 for PCB Surface Defect Detection. Appl. Sci. 2021, 11, 11701. [Google Scholar] [CrossRef]
- Li, M.; Yao, N.; Liu, S.; Li, S.; Zhao, Y.; Kong, S.G. Multisensor Image Fusion for Automated Detection of Defects”, in Printed Circuit Boards. IEEE Sensors J. 2021, 21, 23390–23399. [Google Scholar] [CrossRef]
- Ahmed, I.; Muhammad, S. BTS-ST: Swin transformer network for segmentation and classification of multimodality breast cancer images. Knowl.-Based Syst. 2023, 267, 110393. [Google Scholar]
- Wang, Z.; Zhang, W.; Zhang, M.L. Transformer-based Multi-Instance Learning for Weakly Supervised Object Detection. arXiv 2023, arXiv:2303.14999. [Google Scholar]
- Lin, F.; Ma, Y.; Tian, S.W. Exploring vision transformer layer choosing for semantic segmentation. In Proceedings of the ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–9 June 2023; pp. 1–5. [Google Scholar]
- Ru, L.; Zheng, H.; Zhan, Y.; Du, B. Token Contrast for Weakly-Supervised Semantic Segmentation. arXiv 2023, arXiv:2303.01267. [Google Scholar]
- Xu, Y.; Zhang, J.; Zhang, Q.; Tao, D. ViTPose+: Vision Transformer Foundation Model for Generic Body Pose Estimation. arXiv 2022, arXiv:2212.04246. [Google Scholar]
- Chang, Z.; Feng, Z.; Yang, S.; Gao, Q. AFT: Adaptive Fusion Transformer for Visible and Infrared Images. IEEE Trans. Image Process. 2023, 32, 2077–2092. [Google Scholar] [CrossRef]
- Chang, Z.; Yang, S.; Feng, Z.; Gao, Q.; Wang, S.; Cui, Y. Semantic-Relation Transformer for Visible and Infrared Fused Image Quality Assessment. Inf. Fusion 2023, 95, 454–470. [Google Scholar] [CrossRef]
- Regmi, S.; Subedi, A.; Bagci, U.; Jha, D. Vision Transformer for Efficient Chest X-ray and Gastrointestinal Image Classification. arXiv 2023, arXiv:2304.11529. [Google Scholar]
- Zhu, L.; Li, Y.; Fang, J.; Liu, Y.; Xin, H.; Liu, W.; Wang, X. WeakTr: Exploring Plain Vision Transformer for Weakly-supervised Semantic Segmentation. arXiv 2023, arXiv:2304.01184. [Google Scholar]
- Lu, C.; Zhu, H.; Koniusz, P. From Saliency to DINO: Saliency-guided Vision Transformer for Few-shot Keypoint Detection. arXiv 2023, arXiv:2304.03140. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into High Quality Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. J. Mach. Learn. Res. 2011, 15, 315–323. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer Normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Huang, W.; Wei, P. A PCB Dataset for Defects Detection and Classification. arXiv 2019, arXiv:1901.08204. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer, Science; Springer: Cham, Switzerland, 2016; Volume 9905, pp. 21–37. [Google Scholar] [CrossRef]
- Hao, K.; Chen, G.; Zhao, L.; Li, Z.; Liu, Y. An insulator defect detection model in aerial images based on multiscale feature pyramid network. IEEE Trans. Instrum. Meas. 2022, 71, 1–12. [Google Scholar] [CrossRef]
- Liu, J.; Li, H.; Zuo, F.; Zhao, Z.; Lu, S. KD-LightNet: A Lightweight Network Based on Knowledge Distillation for Industrial Defect Detection. IEEE Trans. Instrum. Meas. 2023, 72, 3525713. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Before Cropping | After Cropping | |||
|---|---|---|---|---|
| Train | Test | Train | Test | |
| Missing hole | 362 | 126 | 1637 | 608 |
| Short | 351 | 131 | 1478 | 551 |
| Mouse bite | 365 | 126 | 1661 | 547 |
| Spur | 370 | 127 | 1641 | 587 |
| Open circuits | 366 | 126 | 1655 | 587 |
| Spurious copper | 371 | 132 | 1719 | 561 |
| Train | Test | |
|---|---|---|
| Open | 1283 | 659 |
| Short | 1028 | 478 |
| Mouse bite | 1379 | 586 |
| Spur | 1142 | 483 |
| Copper | 1010 | 464 |
| Pin hole | 1031 | 470 |
| Layer Name | Output Size | ResSwinT-T | ResSwinT-S | ||
|---|---|---|---|---|---|
| Residual Part | Swin Part | Residual Part | Swin Part | ||
| Stem layer | 160 × 160 | Conv, 64, 7 × 7, stride 2 Maxpool, 3 × 3, stride 2 | Partition, 4 × 4 | Conv, 64, 7 × 7, stride 2 Maxpool, 3 × 3, stride 2 | Partition, 4 × 4 |
| Concatenation, 112 | Concatenation, 112 | ||||
| Stage 1 | 160 × 160 | MLP, 112, 64 | MLP, 112, 48 MLP, 48, 96 | MLP, 112, 64 | MLP, 112, 48 MLP, 48, 96 |
| Concatenation, 352 | Concatenation, 352 | ||||
| Stage 2 | 80 × 80 | MLP, 352, 256 | MLP, 352, 96 Partition, 2×2 MLP, 384, 192 | MLP, 352, 256 | MLP, 352, 96 Partition, 2 × 2 MLP, 384, 192 |
| Concatenation, 704 | Concatenation, 704 | ||||
| Stage 3 | 40 × 40 | MLP, 704, 512 | MLP, 704, 192 Partition, 2 × 2 MLP, 768, 384 | MLP, 704, 512 | MLP, 352, 96 Partition, 2 × 2 MLP, 384, 192 |
| Concatenation, 1408 | Concatenation, 1408 | ||||
| Stage 4 | 20 × 20 | MLP, 1408, 1024 | MLP, 1408, 384 Partition, 2 × 2 MLP, 1536, 768 | MLP, 1408, 1024 | MLP, 1408, 384 Partition, 2 × 2 MLP, 1536, 768 |
| Concatenation, 2816 | Concatenation, 2816 | ||||
| Multi-scale outputs | [352 × 160 × 160, 704 × 80 × 80, 1408 × 40 × 40, 2816 × 20 × 20] | ||||
| Metric | Missing-Hole | Short | Mouse-Bite | Spur | Open-Circuits | Spurious-Copper | Average | |
|---|---|---|---|---|---|---|---|---|
| YOLOv3 | AP | 0.2303 | 0.3575 | 0.2828 | 0.3362 | 0.2764 | 0.3942 | 0.3129 |
| AR | 0.3512 | 0.4111 | 0.4002 | 0.4157 | 0.3596 | 0.4569 | 0.3991 | |
| F1-score | 0.2781 | 0.3824 | 0.3314 | 0.3718 | 0.3126 | 0.4232 | 0.3508 | |
| SSD | AP | 0.2716 | 0.3622 | 0.3045 | 0.3143 | 0.3191 | 0.3415 | 0.3189 |
| AR | 0.3735 | 0.4307 | 0.4066 | 0.3811 | 0.4061 | 0.4414 | 0.4066 | |
| F1-score | 0.3145 | 0.3935 | 0.3482 | 0.3445 | 0.3574 | 0.3851 | 0.3574 | |
| Faster R-CNN (ResNet50) | AP | 0.3028 | 0.3521 | 0.3119 | 0.2914 | 0.3331 | 0.3752 | 0.3278 |
| AR | 0.3837 | 0.4285 | 0.3969 | 0.3666 | 0.4155 | 0.4704 | 0.4103 | |
| F1-score | 0.3385 | 0.3866 | 0.3493 | 0.3247 | 0.3698 | 0.4175 | 0.3644 | |
| Faster R-CNN (ResNet101) | AP | 0.2958 | 0.3488 | 0.3113 | 0.3166 | 0.3499 | 0.3581 | 0.3301 |
| AR | 0.3840 | 0.4292 | 0.4110 | 0.3789 | 0.4256 | 0.4620 | 0.4151 | |
| F1-score | 0.3342 | 0.3849 | 0.3542 | 0.3449 | 0.3841 | 0.4035 | 0.3678 | |
| Cascade R-CNN (ResNet50) | AP | 0.2873 | 0.3452 | 0.3475 | 0.3153 | 0.3457 | 0.3844 | 0.3375 |
| AR | 0.3908 | 0.4200 | 0.4099 | 0.3779 | 0.4210 | 0.4677 | 0.4145 | |
| F1-score | 0.3311 | 0.3789 | 0.3761 | 0.3437 | 0.3796 | 0.4220 | 0.3721 | |
| Cascade R-CNN (ResNet101) | AP | 0.3152 | 0.3642 | 0.3522 | 0.3074 | 0.3472 | 0.3810 | 0.3445 |
| AR | 0.4061 | 0.4425 | 0.4152 | 0.3889 | 0.4341 | 0.4740 | 0.4268 | |
| F1-score | 0.3549 | 0.3995 | 0.3811 | 0.3434 | 0.3858 | 0.4224 | 0.3813 | |
| Cascade R-CNN (SwinT-T) | AP | 0.3089 | 0.3605 | 0.3614 | 0.3172 | 0.3431 | 0.3803 | 0.3452 |
| AR | 0.3998 | 0.4358 | 0.4247 | 0.3956 | 0.4218 | 0.4756 | 0.4255 | |
| F1-score | 0.3486 | 0.3946 | 0.3905 | 0.3521 | 0.3784 | 0.4226 | 0.3812 | |
| Cascade R-CNN (SwinT-S) | AP | 0.3094 | 0.3738 | 0.3195 | 0.2988 | 0.3814 | 0.4079 | 0.3485 |
| AR | 0.4095 | 0.4401 | 0.4026 | 0.3833 | 0.4521 | 0.4879 | 0.4293 | |
| F1-score | 0.3525 | 0.4042 | 0.3562 | 0.3358 | 0.4138 | 0.4443 | 0.3847 | |
| ID-YOLO | AP | 0.2783 | 0.3035 | 0.2960 | 0.2570 | 0.3289 | 0.3504 | 0.3024 |
| AR | 0.3124 | 0.3821 | 0.3501 | 0.3094 | 0.3972 | 0.3975 | 0.3581 | |
| F1-score | 0.2944 | 0.3383 | 0.3208 | 0.2808 | 0.3598 | 0.3725 | 0.3279 | |
| LightNet | AP | 0.2984 | 0.3417 | 0.3155 | 0.3141 | 0.3390 | 0.3788 | 0.3312 |
| AR | 0.3731 | 0.4409 | 0.4136 | 0.3805 | 0.4145 | 0.4813 | 0.4173 | |
| F1-score | 0.3316 | 0.3850 | 0.3579 | 0.3441 | 0.3729 | 0.4239 | 0.3693 | |
| DDTR (ours) (ResSwinT-T) | AP | 0.3252 | 0.3742 | 0.3622 | 0.3174 | 0.3572 | 0.3910 | 0.3545 |
| AR | 0.4161 | 0.4525 | 0.4252 | 0.3989 | 0.4441 | 0.4840 | 0.4368 | |
| F1-score | 0.3651 | 0.4096 | 0.3912 | 0.3535 | 0.3959 | 0.4325 | 0.3914 | |
| DDTR (ours) (ResSwinT-S) | AP | 0.3294 | 0.3938 | 0.3395 | 0.3188 | 0.4014 | 0.4279 | 0.3685 |
| AR | 0.4295 | 0.4601 | 0.4226 | 0.4033 | 0.4721 | 0.5079 | 0.4493 | |
| F1-score | 0.3729 | 0.4244 | 0.3765 | 0.3561 | 0.4339 | 0.4645 | 0.4049 |
| Metric | Missing-Hole | Short | Mouse-Bite | Spur | Open-Circuits | Spurious-Copper | Average | |
|---|---|---|---|---|---|---|---|---|
| YOLOv3 | AP | 0.6512 | 0.6099 | 0.7158 | 0.6948 | 0.8391 | 0.7319 | 0.7071 |
| AR | 0.7290 | 0.6872 | 0.7802 | 0.7580 | 0.8987 | 0.8628 | 0.7860 | |
| F1-score | 0.6879 | 0.6462 | 0.7466 | 0.7250 | 0.8679 | 0.7920 | 0.7445 | |
| SSD | AP | 0.6403 | 0.5598 | 0.7299 | 0.7036 | 0.8737 | 0.8435 | 0.7251 |
| AR | 0.7032 | 0.6385 | 0.7780 | 0.7534 | 0.9017 | 0.8870 | 0.7770 | |
| F1-score | 0.6703 | 0.5966 | 0.7532 | 0.7276 | 0.8875 | 0.8647 | 0.7502 | |
| Faster R-CNN (ResNet50) | AP | 0.6426 | 0.5947 | 0.7393 | 0.7011 | 0.8539 | 0.8156 | 0.7245 |
| AR | 0.7109 | 0.6776 | 0.7932 | 0.7594 | 0.8894 | 0.8621 | 0.7821 | |
| F1-score | 0.6751 | 0.6335 | 0.7653 | 0.7291 | 0.8713 | 0.8382 | 0.7522 | |
| Faster R-CNN (ResNet101) | AP | 0.6421 | 0.5764 | 0.7286 | 0.6952 | 0.8768 | 0.8512 | 0.7284 |
| AR | 0.7036 | 0.6475 | 0.7749 | 0.7468 | 0.9069 | 0.8938 | 0.7789 | |
| F1-score | 0.6715 | 0.6099 | 0.7510 | 0.7200 | 0.8916 | 0.8720 | 0.7528 | |
| Cascade R-CNN (ResNet50) | AP | 0.6652 | 0.6056 | 0.7561 | 0.7272 | 0.9218 | 0.8779 | 0.7590 |
| AR | 0.7252 | 0.6810 | 0.8038 | 0.7822 | 0.9455 | 0.9355 | 0.8122 | |
| F1-score | 0.6939 | 0.6411 | 0.7792 | 0.7537 | 0.9335 | 0.9058 | 0.7847 | |
| Cascade R-CNN (ResNet101) | AP | 0.6729 | 0.6135 | 0.7537 | 0.7356 | 0.9265 | 0.8810 | 0.7639 |
| AR | 0.7326 | 0.6845 | 0.8048 | 0.7855 | 0.9517 | 0.9326 | 0.8153 | |
| F1-score | 0.7015 | 0.6471 | 0.7784 | 0.7597 | 0.9390 | 0.9060 | 0.7887 | |
| Cascade R-CNN (SwinT-T) | AP | 0.6880 | 0.6306 | 0.7658 | 0.7403 | 0.9284 | 0.8811 | 0.7724 |
| AR | 0.7451 | 0.6967 | 0.8169 | 0.7977 | 0.9582 | 0.9500 | 0.8274 | |
| F1-score | 0.7154 | 0.6620 | 0.7905 | 0.7679 | 0.9431 | 0.9143 | 0.7989 | |
| Cascade R-CNN (SwinT-S) | AP | 0.6791 | 0.6365 | 0.7770 | 0.7462 | 0.9355 | 0.8703 | 0.7741 |
| AR | 0.7480 | 0.7079 | 0.8253 | 0.8004 | 0.9621 | 0.9534 | 0.8328 | |
| F1-score | 0.7118 | 0.6703 | 0.8004 | 0.7724 | 0.9486 | 0.9100 | 0.8024 | |
| ID-YOLO | AP | 0.6138 | 0.5730 | 0.7016 | 0.6862 | 0.8703 | 0.8438 | 0.7148 |
| AR | 0.7078 | 0.6850 | 0.7328 | 0.7477 | 0.9246 | 0.8591 | 0.7762 | |
| F1-score | 0.6574 | 0.6240 | 0.7168 | 0.7156 | 0.8966 | 0.8514 | 0.7442 | |
| LightNet | AP | 0.6742 | 0.6184 | 0.7323 | 0.7313 | 0.9321 | 0.8851 | 0.7622 |
| AR | 0.7304 | 0.6879 | 0.7988 | 0.7993 | 0.9314 | 0.9127 | 0.8101 | |
| F1-score | 0.7012 | 0.6513 | 0.7641 | 0.7638 | 0.9317 | 0.8987 | 0.7854 | |
| DDTR (ours) (ResSwinT-T) | AP | 0.6823 | 0.6459 | 0.7776 | 0.7577 | 0.9491 | 0.9120 | 0.7875 |
| AR | 0.7473 | 0.7061 | 0.8247 | 0.8101 | 0.9670 | 0.9564 | 0.8353 | |
| F1-score | 0.7134 | 0.6746 | 0.8005 | 0.7831 | 0.9580 | 0.9337 | 0.8107 | |
| DDTR (ours) (ResSwinT-S) | AP | 0.6860 | 0.6475 | 0.7825 | 0.7579 | 0.9524 | 0.8911 | 0.7862 |
| AR | 0.7490 | 0.7157 | 0.8343 | 0.8104 | 0.9698 | 0.9551 | 0.8390 | |
| F1-score | 0.7161 | 0.6799 | 0.8076 | 0.7833 | 0.9610 | 0.9220 | 0.8118 |
| Cascade R-CNN | AP | AR | F1-Score |
|---|---|---|---|
| ResNet101 (baseline) | 0.3445 | 0.4268 | 0.3813 (±0.00%) |
| SwinT-S | 0.3485 | 0.4293 | 0.3847 (+0.89%) |
| ResSwinT-S | 0.3573 | 0.4343 | 0.3921 (+2.82%) |
| ResSwinT-S/SSA | 0.3615 | 0.4433 | 0.3982 (+4.44%) |
| ResSwinT-S/CSA | 0.3616 | 0.4455 | 0.3992 (+4.69%) |
| ResSwinT-S/SSA + CSA | 0.3668 | 0.4500 | 0.4041 (+5.99%) |
| ResSwinT-S/SSA⊕CSA | 0.3685 | 0.4493 | 0.4049 (+6.19%) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, B.; Cai, J. PCB Defect Detection via Local Detail and Global Dependency Information. Sensors 2023, 23, 7755. https://doi.org/10.3390/s23187755
Feng B, Cai J. PCB Defect Detection via Local Detail and Global Dependency Information. Sensors. 2023; 23(18):7755. https://doi.org/10.3390/s23187755
Chicago/Turabian StyleFeng, Bixian, and Jueping Cai. 2023. "PCB Defect Detection via Local Detail and Global Dependency Information" Sensors 23, no. 18: 7755. https://doi.org/10.3390/s23187755
APA StyleFeng, B., & Cai, J. (2023). PCB Defect Detection via Local Detail and Global Dependency Information. Sensors, 23(18), 7755. https://doi.org/10.3390/s23187755