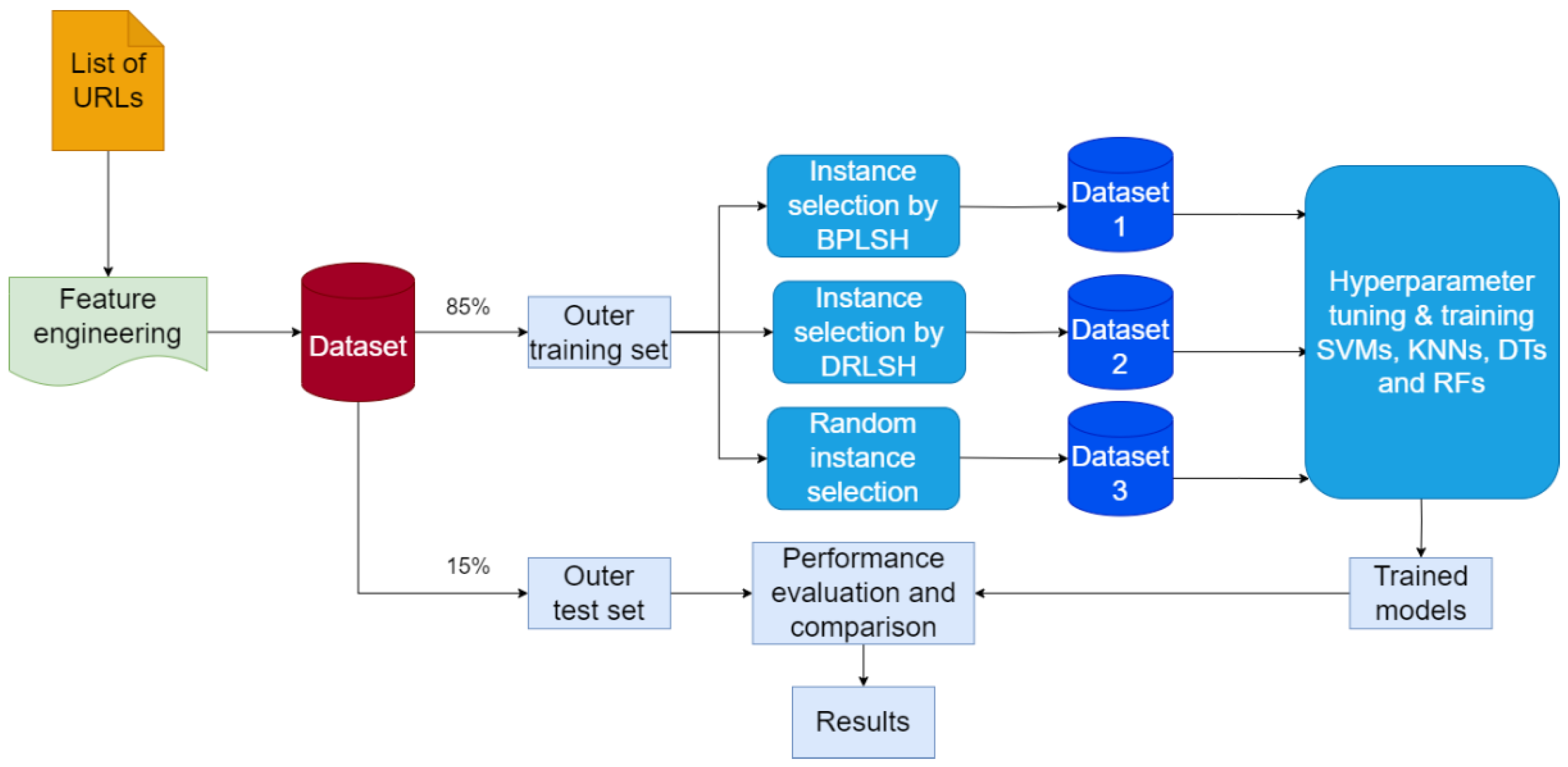
The initial step entailed data collection and preparation. This step involved gathering a multitude of URLs and their corresponding labels and indicating their malicious or benign status. Moreover, null values in the dataset were eliminated to maintain data integrity. Next, features (attributes) instrumental for identifying malicious URLs were extracted. The result was a dataset wherein each row represented a unique URL delineated by its extracted features and an associated output label indicating its classification. The second phase focused on developing models using SVMs, KNNs, DTs, and RFs to accurately distinguish malicious URLs. The prepared dataset was divided into an outer training set and an outer test set. The outer training set played a pivotal role in refining the hyperparameters of each model and in the subsequent training process, using the optimized hyperparameters. Various instance selection techniques were also employed to understand their influence on the model’s performance. These techniques helped generate smaller, representative subsets of the dataset, accelerating the training process. In the final phase, the performance of the generated models was compared and evaluated on the outer test set. All the steps of the workflow were implemented in MATLAB 2022. In what follows, each step is elaborated in more detail.
3.1. Data Collection and Preparation
A list of 650,000 URLs, along with their respective categories—phishing, defacement, malware, and benign—was collected from the Kaggle repository (
www.kaggle.com, accessed on 26 February 2023). A URL is a unique address identifying a resource, such as an HTML page. A URL consists of several parts, as shown in
Figure 2. First, it is planned to specify the protocol that is used to retrieve the object, with HTTPS (encrypted connection) and HTTP (unencrypted) being the most-used protocols. Second, the IP address indicates the web server being requested, and the port indicates the gateway that should be used to access the content. The third part of a URL is the path to the object. The fourth part is a list of parameters that can be used to specify keys and values that allow other actions to be performed. Finally, an anchor allows for jumping to a specific section of the web page. Parameters and anchors may sometimes be excluded from a URL.
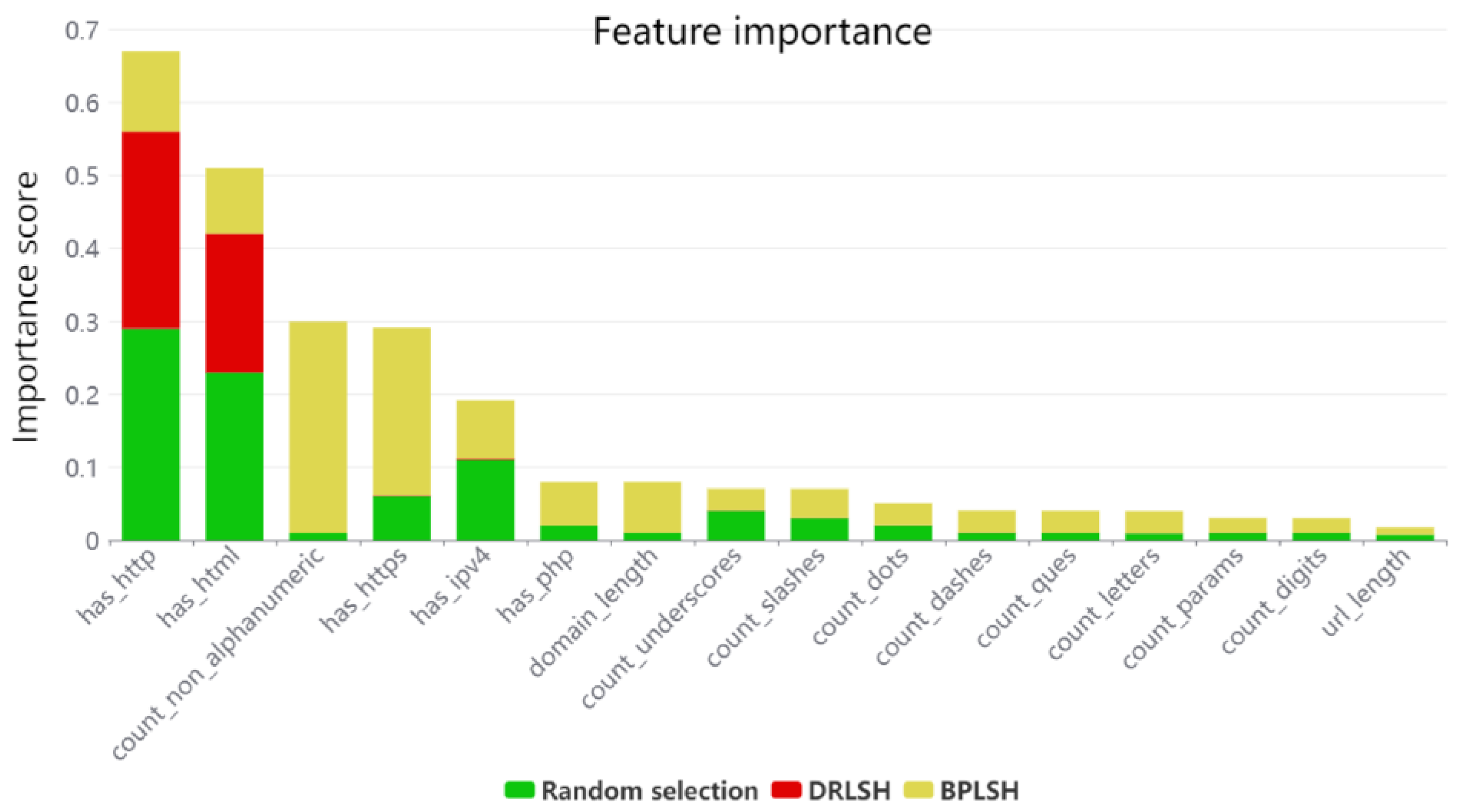
Raw URL data alone are insufficient for the identification of malignant URLs, as they fail to offer insightful details about the characteristics of the URLs that could aid in their classification. To bridge this gap, feature extraction becomes necessary, transforming raw URL data into quantifiable indicators that machine learning algorithms can effectively process. Hence, a total of 16 distinct input features were selected to train and develop machine learning models. These features captured crucial information needed for the classification task. The extracted input features were as follows:
URL_length: The length of a given URL.
Domain_length: The length of the domain name.
Has_ipv4: Verifying the presence of an IPv4 address in each URL and subsequently returning either 1 or 0.
Has_http: Verifying the presence of the HTTP protocol in each URL and subsequently returning either 1 or 0.
Has_https: Verifying the presence of the HTTPS protocol in each URL and subsequently returning either 1 or 0.
Count_dots: The number of dots.
Count_dashes: The number of dashes.
Count_underscores: The number of underscores.
Count_slashes: The number of slashes.
Count_ques: The number of question marks.
Count_non_alphanumeric: The number of non-alphanumeric characters.
Count_digits: The number of digits.
Count_letters: The number of letters.
Count_params: The number of parameters.
Has_php: Verifying the presence of the word “php” in each URL and subsequently returning either 1 or 0.
Has_html: Verifying the presence of the word “html” in each URL and subsequently returning either 1 or 0.
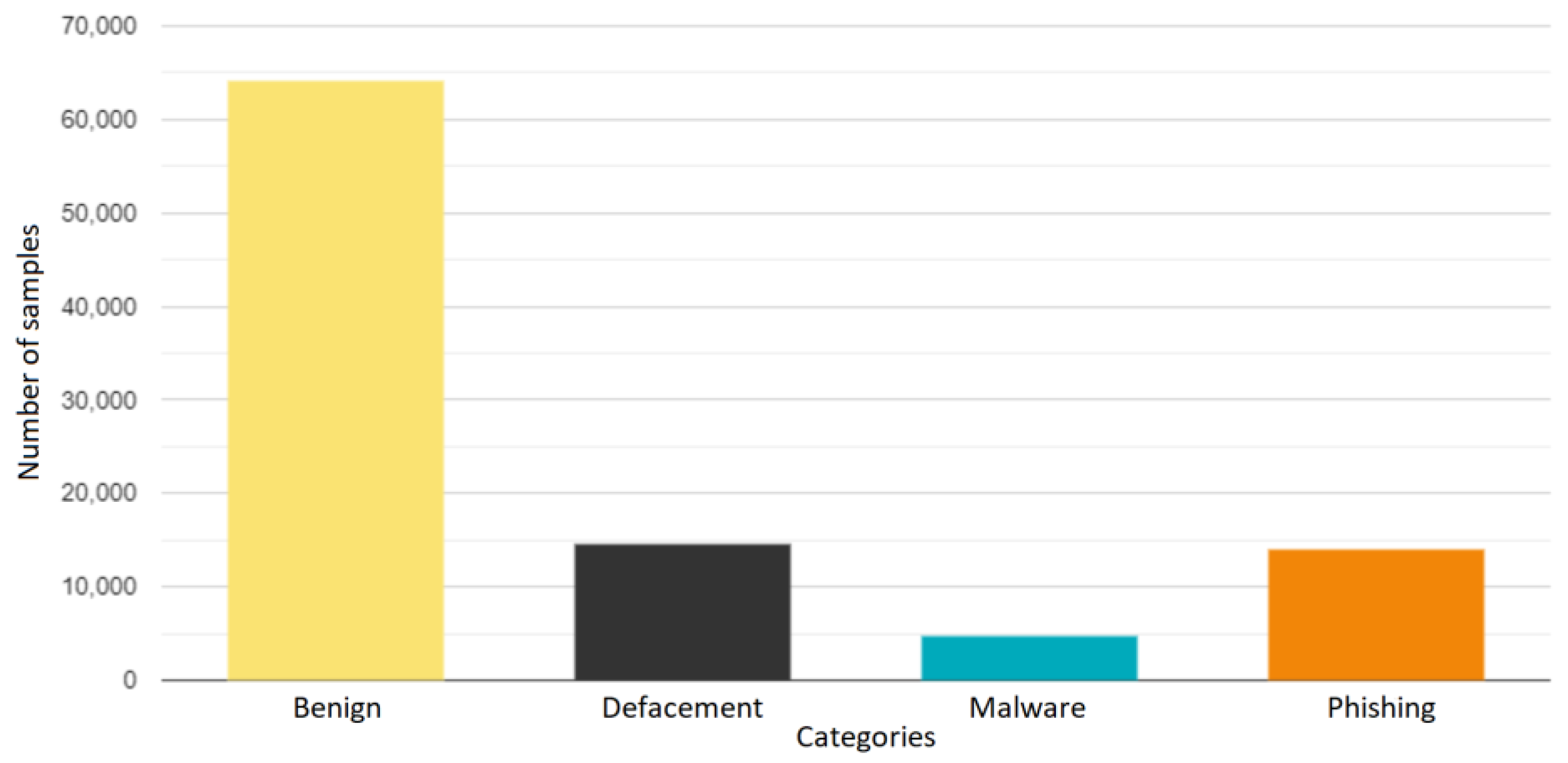
The category of each URL—phishing, defacement, malware, or benign—was used as the output feature. Hence, the resulting dataset comprised 650,000 instances, with each characterized by 16 input features and a corresponding output feature. To construct and evaluate the machine learning models, a strategic division of the dataset was implemented. Specifically, 85% of the dataset (552,500 instances) was dedicated to training the models, and the remaining 15% (97,500 instances) was reserved for testing purposes, allowing for an accurate assessment of the models’ ability to classify URLs.
3.2. Developing Machine Learning Models
While the prepared large training dataset (552,500 instances) provided a rich foundation for analysis, it could lead to the issue of computational inefficiency. To address this issue and ensure that the machine learning methods effectively and efficiently learn, instance selection was utilized. Instance selection methods enhance the efficiency of computations by selecting a small subset of instances representative of the original set. Many instance selection methods have been proposed, owing to the increasing number of records in datasets. In this study, we used BPLSH [
9], DRLSH [
8], and random selection to reduce the number of samples in the dataset.
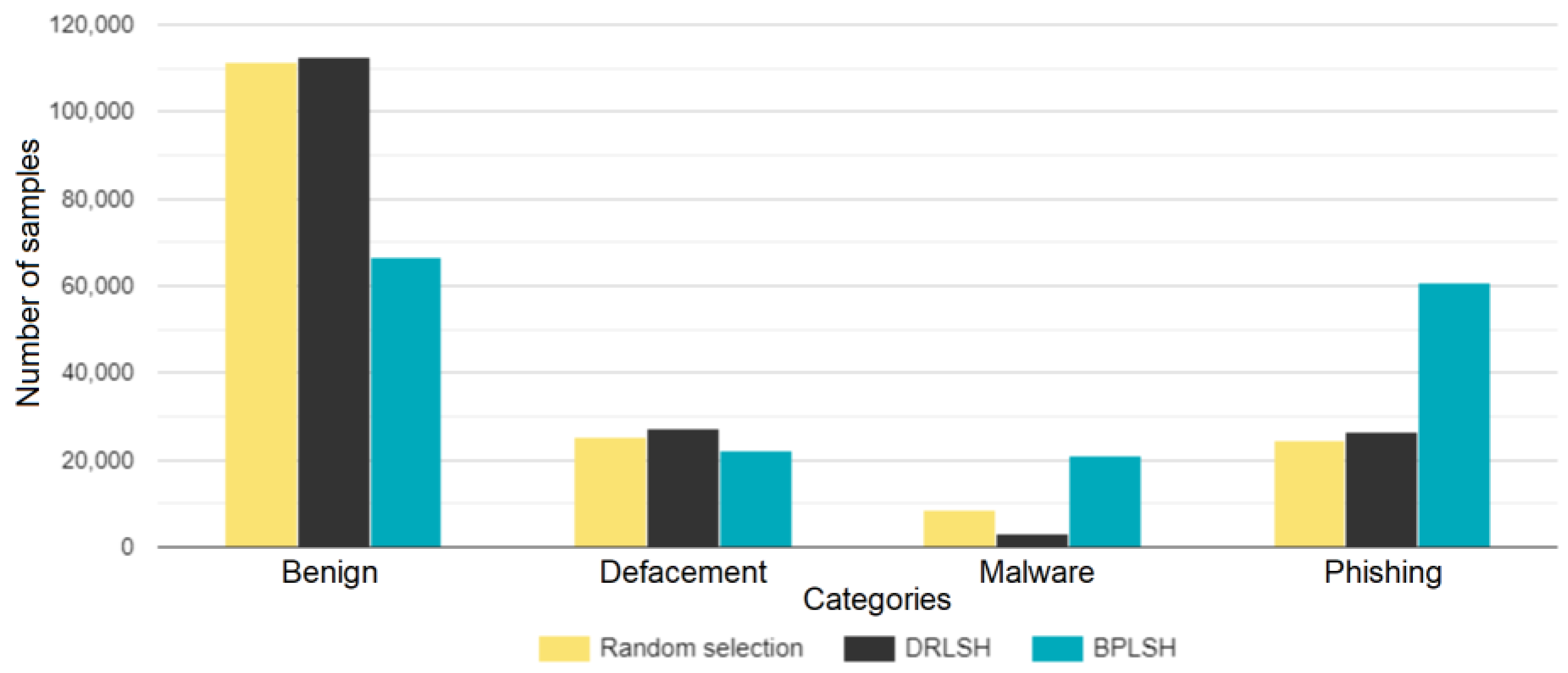
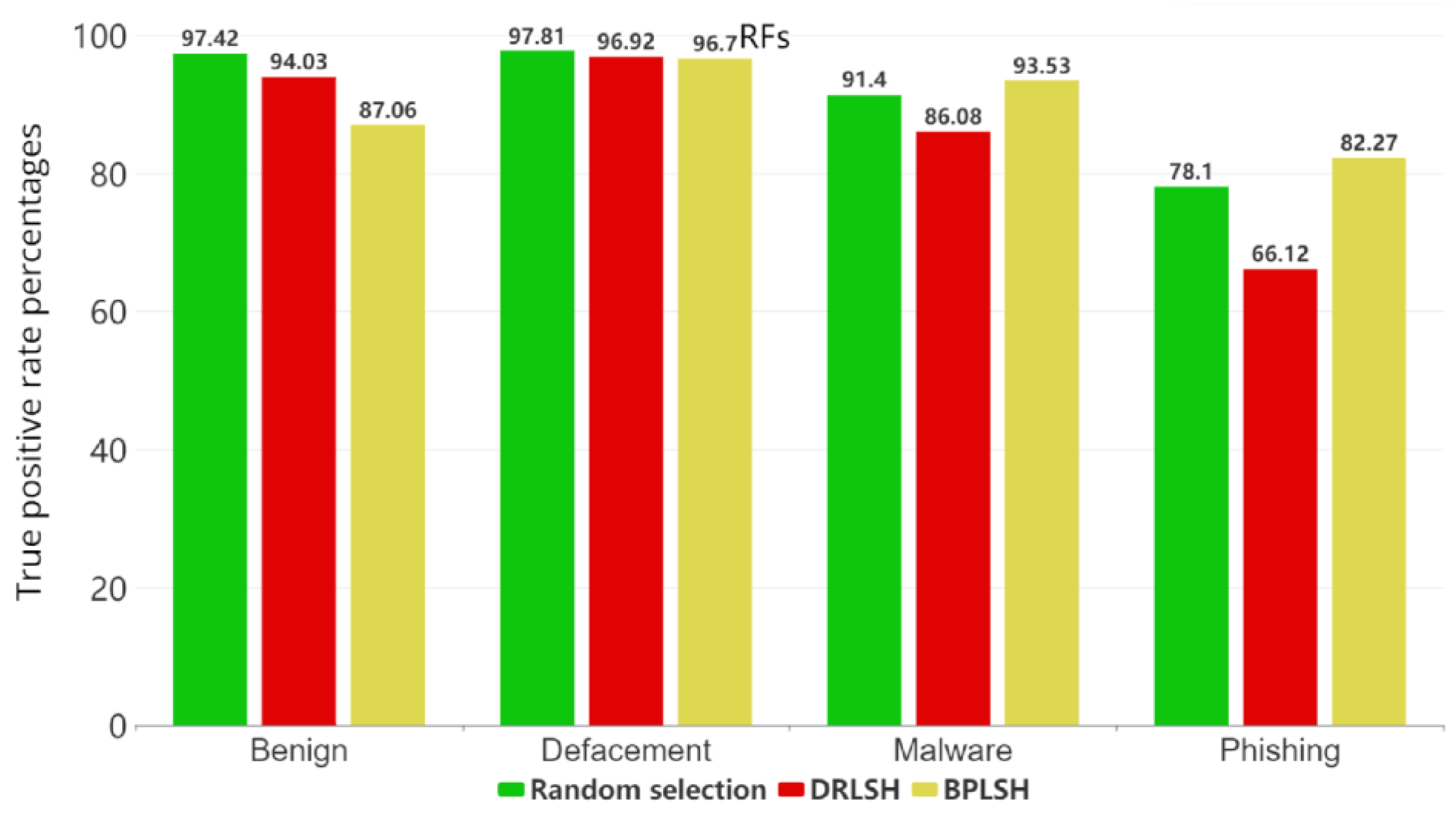
Both DRLSH and BPLSH are based on locality-sensitive hashing. They pinpoint critical samples by scrutinizing the similarity in data points and their respective labels. While DRLSH’s main objective is to detect similar instances within each class, BPLSH expands this objective to include both similar and border instances. In DRLSH, sample reduction is achieved by independently removing nearly identical data points within each class. BPLSH, however, takes a more comprehensive approach, collectively evaluating samples from all classes. It discards similar samples only when they are distanced from the decision boundaries. The time complexity of DRLSH is less than that of BPLSH. In random selection, a small subset of instances in a random manner is selected to form a reduced training dataset. Simplicity and low computational complexity are the biggest advantages of such a method, making it feasible for many different types of datasets. By applying the instance selection methods, three datasets were derived.
In the study’s dataset, comprising four categories, benign, defacement, phishing, and malware, the BPLSH method focused on analyzing the boundaries that separate these categories. In contrast, DRLSH concentrated on the examination of similar samples within the dataset. Meanwhile, random selection reduced the dataset’s size by using the randperm function.
The use of these instance selection methods, BPLSH, DRLSH, and random selection, differed from other techniques due to their varying selection criteria, objectives, and handling of decision boundaries. These distinctions made each method suitable for particular contexts and dataset characteristics.
In this study, we employed machine learning models for the detection of malicious URLs. Symbolic AI can also be used as an alternative approach to detect malicious URLs by defining a set of rules or patterns that characterize such URLs. Symbolic AI is well-suited for well-defined, rule-based tasks like identifying known patterns of malicious URLs. However, it encounters challenges when it comes to adapting to new and evolving threats.
In contrast, machine learning models, especially when complemented with instance selection methods such as BPLSH, DRLSH, and random selection, offer greater flexibility, scalability, and adaptability to address the dynamic nature of evolving threats. These models can autonomously learn and adapt to new patterns and variations in malicious URLs, making them a preferred choice for modern URL threat detection systems.
In this study, the pressing challenge was prolonged machine learning model training times. To address this, we implemented instance selection methods. These techniques, by reducing dataset size, expedited training, facilitated efficient pattern discovery in the data, and enhanced research efficiency.
After instance selection, four machine learning models, namely, DT, RF, KNNs, and SVM, were developed to identify malicious URLs. These models were selected due to their widespread popularity and extensive applications in classification. Moreover, the performance of these models was further enhanced by employing Bayesian optimization for hyperparameter tuning, a process that allows for fine-tuning the model configurations to achieve the best possible results.
3.2.1. DTs
A DT is a machine learning algorithm that makes decisions based on a tree-like model of decisions. It starts with a single node, representing the entire dataset, which is then partitioned based on specific conditions. This process continues recursively, creating a structure that resembles a tree with branches and leaves. Each internal node of the tree corresponds to a feature, each branch represents a decision rule, and each leaf node represents an outcome, i.e., the predicted class. DTs are favored for their interpretability and simplicity, as they mirror human decision-making processes and do not require complex computations. This approach makes it easier to identify the most important decision factors and how they affect the outcome [
15].
The performance of DTs is influenced by their hyperparameters, which are essentially adjustable parameters that must be fine-tuned before the model is trained. The crucial hyperparameters of DTs are the maximum number of decision splits (branch nodes) and the splitting criterion. The maximum number of decision splits refers to the maximum number of splitting points the decision tree can create from the root to the furthest leaf. It regulates the complexity of the model, preventing overfitting by restricting the number of possible decision splits. The splitting criterion refers to the function used to measure the quality of a split. This function essentially provides a means of deciding the most effective way to separate the instances at each decision node based on their feature values. The most commonly used criteria are Gini impurity and entropy. Gini impurity is a measure that quantifies the probability of incorrect classification; a Gini impurity of 0 represents perfect purity, while a score of 1 suggests a high likelihood of misclassification. In contrast, entropy measures the level of disorder within an input set, with maximum entropy signifying that all classes are equally represented (hence, high disorder) and a score of 0 indicating total order.
3.2.2. RFs
An RF is a machine learning algorithm that belongs to the ensemble learning method class. It combines multiple decision trees to create a more powerful and robust predictive model. Each tree in the forest is grown using a randomly selected subset of features and data points, preventing overfitting and enhancing the model’s generalization ability. An RF makes a final forecast by combining the predictions of individual trees, typically through a majority voting system. Unlike a single decision tree that may suffer from overfitting, the aggregation of many decision trees in an RF significantly reduces this risk [
16].
In constructing and optimizing RFs, several critical hyperparameters come into play, including the number of trees, the maximum number of decision splits, the number of predictors to sample, and the splitting criterion. The number of trees determines the total number of decision trees grown in the forest. A higher number of trees generally improves the robustness and accuracy of the model, but it also increases the computational demands. The maximum number of decision splits limits the number of levels each decision tree can have. Increasing the number of decision splits enables the model to better capture complex relationships in the data but makes the model more prone to overfitting. The number of predictors to sample refers to the number of randomly selected features considered at each split in the decision tree, offering control over the model’s randomness and bias–variance balance. Lastly, the splitting criterion plays a role similar to its function in DTs, aiding in the selection of the optimal decision rule at each node.
3.2.3. SVMs
An SVM classifier works by determining the hyperplane that best separates the classes of data points. This is achieved by maximizing the margin, which is the distance between the separating hyperplane and the nearest data points from both classes. The hyperplane is chosen to have the maximum margin, ensuring that it is as far away as possible from the data points of both classes. This feature ensures a greater separation between classes, thereby enhancing model accuracy. Concurrently, SVMs work toward minimizing classification errors, achieving a balance between margin maximization and error minimization for the optimal decision boundary [
17].
The key hyperparameters of SVMs include the choice of the kernel function, box constraint, kernel-specific parameters, and multiclass method. The kernel is a function that transforms the data into a higher dimensional space, making it possible to find a separating hyperplane when the data are not linearly separable in their original space. The most common kernels include linear, polynomial, and Gaussian. The box constraint, a regularization parameter, controls the trade-off between the model’s complexity and its capacity to tolerate errors. Indeed, it is a controlling factor in determining the model’s sensitivity to misclassification errors during training. Lower values for this parameter make the model less sensitive to misclassified training samples, leading to a simple model but increasing the risk of underfitting. Conversely, higher parameter values push the model to reduce classification errors for the training samples, even at the expense of a narrow decision margin, increasing the risk of overfitting. The kernel-specific parameters depend on the type of kernel chosen. For instance, the Gaussian kernel has a parameter called the kernel scale that adjusts the shape of the decision boundary. Higher kernel scale values may create rigid boundaries, risking underfitting, while lower values allow for flexible boundaries that can capture complex data patterns but may cause overfitting. The multiclass method specifies the strategy used to handle multiple classes. Common approaches include one-vs-one and one-vs-rest strategies. In the one-vs-one strategy, a separate SVM model is trained for each pair of classes, while in the one-vs-rest strategy, an individual SVM model is trained for each class against all other classes.
3.2.4. KNNs
KNNs are a supervised learning algorithm that is valued for its simplicity and broad applicability. KNNs first identify the
k training instances closest to a given test instance. Then, the test instance is subsequently categorized into the most prevalent class among these
k neighbors [
18]. The principal hyperparameter for KNNs is
k, representing the number of neighbors to consider during classification. Smaller
k values make the model sensitive to noise, whereas larger
k values increase computational demand. The choice of
k is, thus, a trade-off between model stability and computational efficiency.
3.2.5. Hyperparameter Tunning Using Bayesian Optimization
Optimizing hyperparameters is crucial for achieving the highest level of performance in machine learning models. While there are numerous proposed methods for automatically tuning hyperparameters [
19,
20], tackling the non-convex nature of hyperparameter optimization problems necessitates the usage of global optimization algorithms. In line with this, we employed Bayesian optimization in this study [
21]. Bayesian optimization provides an effective and sophisticated approach to hyperparameter tuning. The effectiveness of Bayesian optimization lies in its strategic design for the global optimization of computationally expensive functions. It constructs a probability model of the objective function by using past evaluations and employing Bayesian inference and Gaussian processes. This allows the algorithm to smartly explore and exploit the hyperparameter space, thereby pinpointing the hyperparameters most likely to yield superior performance.
To evaluate the performance of different hyperparameter settings in a robust manner, we utilized k-fold cross-validation. This involves partitioning the training dataset into k equally sized subsets or folds. Each subset serves as a validation set exactly once, while the model is trained on the remaining k − 1 subsets. The objective function that guides Bayesian optimization toward optimal hyperparameters is the average classification accuracy obtained from these validation sets. In this way, k-fold cross-validation complements the Bayesian optimization procedure, providing a more reliable assessment of each hyperparameter setting’s performance.
Standard 5-fold cross-validation was used, as it strikes a balance between accurately estimating model performance and managing computational costs. Each model had specific hyperparameters configured: DTs involved maximum splits and split criterion; KNNs used 10 neighbors and squared inverse distance weight; RFs employed ensemble method, number of learners, maximum splits, and predictors to sample; SVMs featured one-vs-one multiclass method, box constraint level, kernel scale, Gaussian kernel, and standardized data. These hyperparameter settings were determined to optimize each model’s performance.
3.2.6. Evaluation Metrics
The performance of the machine learning models in classifying malicious URLs was evaluated using three assessment metrics: precision, recall, and F1 score. Precision, calculated using Equation (1), is a measure that encapsulates the proportion of true positive instances within all the instances that the model classified as positive. For a specific class, e.g., malware, precision is equal to the ratio of URLs accurately identified as malware over the total URLs predicted as malware. Recall is a metric that computes the proportion of true positive instances that the model correctly identified (Equation (2)). For the malware category, as an example, recall is the ratio of URLs that are correctly classified as malware to the overall actual malware URLs. The F1 score combines precision and recall, providing a balanced measure of the two metrics in a model’s performance (Equation (3)). In Equations (1)–(3), true positives are the instances correctly predicted as positive—e.g., malware URLs correctly identified as malware. False positives are the instances that are incorrectly predicted as positive—e.g., non-malware URLs wrongly flagged as malware. False negatives are the instances incorrectly predicted as negative—e.g., malware URLs incorrectly labeled as non-malware.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}