Abstract
When patients perform musculoskeletal rehabilitation exercises, it is of great importance to observe the correctness of their performance. The aim of this study is to increase the accuracy of recognizing human movements during exercise. The process of monitoring and evaluating musculoskeletal rehabilitation exercises was modeled using various tracking systems, and the necessary algorithms for processing information for each of the tracking systems were formalized. An approach to classifying exercises using machine learning methods is presented. Experimental studies were conducted to identify the most accurate tracking systems (virtual reality trackers, motion capture, and computer vision). A comparison of machine learning models is carried out to solve the problem of classifying musculoskeletal rehabilitation exercises, and 96% accuracy is obtained when using multilayer dense neural networks. With the use of computer vision technologies and the processing of a full set of body points, the accuracy of classification achieved is 100%. The hypotheses on the ranking of tracking systems based on the accuracy of positioning of human target points, the presence of restrictions on application in the field of musculoskeletal rehabilitation, and the potential to classify exercises are fully confirmed.
1. Introduction
Diseases of the musculoskeletal system are widespread among different age groups and population categories. Trauma or illness can affect both the physical function and the cognitive and emotional state of a person. Studies show that people in need of rehabilitation often experience helplessness, frustration, and social isolation, which are associated with increased depression and a decreased ability to perform their daily activities [1,2,3]. The incomplete list of possible deficiencies includes muscle weakness, poor endurance, a lack of muscle control, spatial neglect, and even paralysis. Delayed or insufficient motor rehabilitation leads to the worsening of the patient’s condition. Thus, a person becomes dependent on the regular assistance of others.
Exercise-based therapy in combination with other methods of musculoskeletal rehabilitation is a logical approach to restoring and strengthening motor abilities in patients at risk of progressive musculoskeletal dysfunction. It is proven that with the systematic execution of time-consuming and complex therapeutic exercises, as a rule, there is a better functional recovery [4,5,6]. Therefore, hospital rehabilitation of the patient is an integral stage of treatment. The term “rehabilitation” refers to the complete or partial compensation of physical abilities through physical exercises for the recovery of a person in social, domestic, and professional environments.
The advantage of hospital rehabilitation compared to ambulatory rehabilitation is a question to be discussed. There are studies that confirm the fact that rehabilitation under the supervision of a specialist does not exceed rehabilitation at home [7,8,9,10] and vice versa [11,12,13,14].
As part of this study, it is assumed that the patient should receive primary controlled rehabilitation and then continue to follow the doctor’s prescriptions independently. This is necessary because not all patients can afford a permanent residence in a medical institution for the following reasons: insufficient hospital beds, high healthcare costs, a shortage of medical personnel, and the prevention of intra-hospital infections. Ambulatory rehabilitation relieves the healthcare burden and allows patients to continue their social, household, and professional activities throughout the recovery period.
Studies show that modern information technologies can improve the level of information provided to patients and their relatives about the progress of ambulatory rehabilitation [15] and that personalized medicine can lead to improved life quality for patients. In addition, mobile apps can increase the availability of rehabilitation in both rural and urban environments, reduce travel time and costs, increase involvement in therapeutic activities, and ensure decision making with the doctor regarding the treatment process. Smart wearable devices, combined with software that supports advanced analytics, can provide the user with the ability to track the dynamics of the rehabilitation process at home without constant medical supervision.
Thus, the contribution of this study is as follows:
- Analysis of existing systems for tracking human movements and their applicability in musculoskeletal rehabilitation;
- Modeling the process of monitoring and evaluating musculoskeletal rehabilitation exercises using various tracking systems, which can be used in the development of rehabilitation systems of various kinds;
- Development and testing of information-processing algorithms for various systems of movement tracking to obtain objective data on the quality of the exercise performance;
- Implementation of algorithms for the classification of human actions to automatically determine the exercise performed.
The content of this article includes an introduction that analyzes existing systems for tracking movements, approaches to data analysis on the process of performing musculoskeletal rehabilitation exercises, and methods of classification using machine learning. The following is a model of the process of monitoring and evaluating musculoskeletal rehabilitation exercises, as well as the necessary algorithms of data processing and analysis used to obtain objective indicators of exercise performance quality and recognition of actions. Section 3 provides details of the experimental studies that include comparing the accuracy of different human movement tracking systems, choosing the optimal solution for the subject area of musculoskeletal rehabilitation, and comparing machine learning algorithms for automatic classification of exercises. This article ends with a discussion of the results and conclusions.
1.1. Monitoring of User Movements
One of the components of the rehabilitation dynamics evaluation process is the analysis of the person’s motor activity, for which it is necessary to obtain not only a qualitative assessment from a specialist but also objective quantitative data. Next, the main directions and systems that allow tracking of user movements are considered.
1.1.1. Inertial Navigation Systems
Inertial navigation systems (INS) contain linear acceleration sensors (accelerometers) measuring non-gravitational acceleration on three axes (x, y, and z) and angular speed (gyroscopes or pairs of accelerometers measuring radial acceleration), determining deviation and angles of orientation.
The use of accelerometers in collecting the data on movement provides quantitative measurements and allows for specific changes in behavior when rehabilitating people. Moreover, these devices are used to objectively quantify the level of ambulatory activity of patients [16]. When evaluating human movements, an important component is the orientation in space, which cannot be determined only by using accelerometers because they do not contain information about rotation around the vertical axis. The combination of accelerometers with gyroscopes allows for a more comprehensive analysis of motion [17,18].
Combinations of accelerometers and gyroscopes are actively used to assess human motor activity during the rehabilitation period [19]. It should be noted that current research in this direction is based on the use of specialized accelerometers and gyroscopes presented as separate devices, which limits the application of these developments to a broad audience. This is due to the fact that the data provided by mobile accelerometers are not always of high accuracy and quality. This may require the development of new approaches to information processing to address the high error rate of mobile devices.
1.1.2. Steam VR Lighthouse
A number of virtual reality systems include support for wireless sensors implemented in the form of controllers, trackers, or other manipulators running on Steam VR Lighthouse technology (e.g., HTC Vive) [20]. For these systems, open-source software libraries (OpenVR) were implemented, which allowed the systems to obtain sensor location data with high frequency and accuracy without additional calculations. Alternative solutions from Oculus, Valve, and HTC, built on computer vision and a set of cameras for monitoring controllers, do not allow monitoring of all target body points except hands and fingers, which makes such solutions inapplicable for this study.
There is a positive experience with using this kind of tracking system in the field of rehabilitation [21]; however, to improve tracking accuracy, the authors combined virtual reality equipment with computer vision technologies.
The disadvantage of Steam VR Lighthouse is the need to organize a tracking area with the installation and configuration of base stations. The tracker coordinates depend on the initial calibration of the virtual reality headset, and the sensors must be located in the visibility zone of the base stations, which often leads to data loss in the event of their cover with the user’s body or clothes.
The experience of using such sensors also shows that the Steam VR Lighthouse-based tracking system does not accommodate a large number of trackers due to their size, and the scan area of base stations is limited.
1.1.3. Motion Capture Suit
Motion capture suits are implemented on the basis of a system of special markers, sensors, or trackers located on the torso, hands, and legs, combined into a single system [22,23]. Such systems allow accurate recording of the entire body’s movements, including wirelessly. The disadvantages of the approach are the need for calibration as well as the low interference resistance, which makes it difficult to use such equipment near sources of electromagnetic interference.
Another peculiarity of the suits is that the recording of data is carried out in relation to some basic supporting point, usually fixed on the back. The sensor installed at this point records the shifts and twists on three axes, while the other sensors installed on the target positions of the human body record the change in the angles of twist relative to the previous position.
Since the lengths of segments between the sensors are fixed, the recorded and digitized model of human movement does not reflect the user’s height or the length of their limbs. This requires additional data processing taking into account the height of the current user to determine the actual location of the points of the digital model. Therefore, when using motion capture suits in various three-dimensional application development environments (Unity, Unreal Engine, and others), body sizes are set by the developer manually. This feature can be used when evaluating the quality of the performance of musculoskeletal rehabilitation exercises, when the length of the limbs and height are determined for each user, after which these values are transferred to a digital model. Then, the resulting model and the characteristics of its movement correspond to the real processes of movement.
1.1.4. Computer Vision Systems
Tracking systems, based on the use of cameras or some of their sets with the subsequent application of computer vision and machine learning technologies, allow the capture of movements of the human body, including hands and face. Such technologies, for example, are implemented in libraries like MediaPipe [24], MoveNet [25], and OpenPose [26,27]. These libraries allow developers to cover a sufficient area of the image and track several people simultaneously with a large number of points (up to 500 points, including fingers and faces).
Practical tests show that with sharp movements or large distance from the camera, the accuracy of segment recognition significantly decreases, and erroneous movements of the recognized skeleton nodes appear. This approach also demonstrates low performance due to the use of algorithms with high computation complexity based on neural networks. A significant limitation is also that the use of a single camera does not allow the correct determination of the third coordinate of the points (by the Z axis), that is, the distance from the camera to the object. In a number of musculoskeletal rehabilitation exercises where it is necessary to make simple movements on one or two axes, the impact of these shortcomings is reduced. On the other hand, the use of a set of cameras that analyze the object from different sides, specialized cameras with a depth sensor, or stereo cameras also allows one to obtain the necessary data on the human body segments’ position.
1.2. Overview of Approaches to the Analysis and Classification of User Movements in the Process of Musculoskeletal Rehabilitation
In the process of musculoskeletal rehabilitation, a person performs a sufficiently large number of various exercises aimed at working out different muscle groups. Automatic recognition of the exercise performed allows one more accurately to determine the quality of its performance, since certain limit conditions can be set for each exercise to which a person should strive in the process of rehabilitation.
An important tool for the automatic analysis and classification of user movements is the use of machine learning algorithms. We consider the specifics and experience of their application in this subject area.
The study [28] examined the use of LSTM networks trained on the wave conversion of EMG data in the rehabilitation process to assess the normality of the EMG response to rehabilitation actions. The authors achieved an average accuracy of more than 94%. A review of the application of different types of neural networks in the data classification for musculoskeletal medicine shows that these technologies can provide recognition accuracy of 70 to 95% [29].
The effectiveness of various machine learning algorithms (decision tree, k-nearest neighbor, support vector method, and random forests) in the classification of exercise for shoulder joint rehabilitation is also confirmed in the study [30], where the authors obtained accuracy of up to 97%. Classification models showed high efficiency in differentiating a patient’s physical activity and determining a specific type of exercise using inertial sensor data. Similar to the abovementioned study, the article [31] presented the results of machine learning algorithms (k-nearest neighbors, reference vector method) in managing the rehabilitation planning of elderly patients at home. The main purpose of using these algorithms is to identify the best method for predicting rehabilitation potential. Subjective user assessments of functional improvements in their state were used as input data. As a result, it was discovered that machine learning algorithms could be useful in developing improved clinical protocols.
The methodology developed by the authors of article [32] for modeling and evaluating human movements in the process of physical rehabilitation therapy is based on a combination of a sensory movement recording system and a trajectory extraction algorithm. After analyzing the trajectory and comparing it with the reference, a recommendation is issued for a further course of rehabilitation. The functioning of this algorithm is based on the use of a recurrent neural network that analyzes the spatial–temporal dependencies of the user’s movements to form a final assessment of the exercise performance.
A comprehensive overview of modern research in the field of human movement recognition is presented in the paper [33], which examines various tracking technologies (such as devices, smartphones, radar, and vision devices) together with different architectures of convolutional neural networks (with the addition of recurrent and generative models and layers of attention). There is a great prospect of combining machine learning technologies with tracking systems to solve various tasks in the healthcare, video surveillance, entertainment, and sports industries.
In particular, an overview of scientific papers exploring the assessment of human movement through vision devices is also presented in the article [34]. Modern researchers in the field of optical motion capture are briefly described in relation to a number of parameters, as well as sets of open-source software tools, such as PoseNet [35] and OpenPose [36], mainly based on algorithms of convolutional neural networks [37,38,39].
In recognizing human movements, researchers use various machine learning architectures, including increasingly popular attention-based models (Transformers). In the study [40], accuracy in recognizing human actions reached 99.2%.
Thus, in the course of studying existing research in the field of the machine learning algorithms application for movement classification, the following machine learning algorithms were selected due to their effectiveness for solving similar tasks:
- Solution Trees: A simple-to-implement and easily interpreted machine learning algorithm that identifies the characteristics by which the classification was completed; the greater depth of the tree, the more branches by different characteristics are performed for classification;
- K-nearest neighbors: The classification is performed on the basis of comparing the current object characteristics with the parameters of the nearest objects and choosing a similar class to them;
- Random forest: an ensemble method of classification combining several assessors (trees of solutions with a given depth of branching) to increase the accuracy;
- Multilayered dense neural networks: simple to implement; universal approximators;
- Recurrent neural networks such as LSTM: common and effective models in time series analysis;
- Multilayered convolutional neural networks: generalize the signs of time sequences and rows, which is justified for most types of data coming from tracking systems;
- Multilayered convolutional neural networks with the addition of layers of multiheaded attention (Transformer architecture): an efficient and modern type of neuronal network that includes, in addition to convolutional neural networks, layers of multiheaded attention, allowing one to identify specific features in incoming datasets.
As a result of the analysis, the applicability of machine learning algorithms in solving tasks of analysis and classification of movements in the process of rehabilitation exercises is confirmed. As part of this study, these techniques are applied to classify selected types of exercises.
1.3. Analysis of Approaches to Assessing User Tracking Quality
In the process of performing musculoskeletal rehabilitation exercises, an important component of monitoring and evaluating this process is the precise determination of the position of the human body target points. We consider the main approaches and metrics that can be used in the process of evaluating user tracking quality.
Dynamic time warping (DTW) is one of the most commonly used algorithms for finding similarities between time series. Its purpose is to find the optimal global alignment between two time series using time distortions.
According to the study [41], if two time series (T1 and T2) are set with the number of measurements at coordinates and , the DTW algorithm builds a matrix of distances between the corresponding elements of two trajectories of the size of . Further, in this matrix, a certain path of transformation by length is determined, establishing a correspondence between the two trajectories. Then, if is the distance of some elements of two trajectories entering the path of transformation, then the DTW distance (path value) between them is calculated on the basis of the optimal path of transformation using the formula
DTW works well when finding similarities between two trajectories if they are similar, but the main disadvantage of this algorithm is that it is noise sensitive, i.e., it gives meaningless results when comparing two trajectories containing many dissimilar sections. This can make it difficult to use this algorithm in the analysis of motor activity.
When analyzing the value of the detachment of the human body target point from some benchmark, the following common metrics can be used: the mean square error (MSE) and the Euclidean distance (D) between the points. On the basis of the last metrics for the trajectory of body movement, four different estimates can be given: the average, maximum, and total Euclidean distances between the current and reference trajectories of target point motion. For the calculation of the listed metrics, the following formulas are used when comparing the points of the current and the reference trajectory of human movement [42]:
MSE:
mean Euclidean distance:
maximum Euclidean distance:
total Euclidean distance:
where is the number of trajectory points analyzed;
: the target point of the current trajectory;
: reference trajectory point.
MSE and metrics based on the Euclidian distance can be used both to determine the accuracy of tracking the target body points and to assess the performance of the exercise.
For example, instead of comparing all points of trajectories, it is possible to calculate the Euclidean distance only between the most important points determining the quality of the exercise (maximum position, distance passed by the point, etc.).
1.4. Purpose of the Research
The purpose of the research is to increase the accuracy of recognizing human movements in the process of performing musculoskeletal rehabilitation exercises. To achieve this, the following tasks need to be completed:
- Simulate the processes of monitoring and evaluating musculoskeletal rehabilitation exercises, which include the formalization of procedures for determining positions, amplitudes, and speeds of body parts of the user, as well as determining the current exercise and its performance quality.
- Develop the necessary information processing algorithms from various movement tracking systems to obtain the final result in the form of a set of target points needed to evaluate the exercises.
- Implement an algorithm for monitoring musculoskeletal rehabilitation exercises to analyze and classify user movements.
- Implement various user tracking systems, taking into account the characteristics of the subject area and the limitations arising in the process of musculoskeletal rehabilitation.
- Compare intelligent information processing algorithms, including machine learning methods, to automate the process of classifying musculoskeletal rehabilitation exercises with the chosen movement tracking method.
During the investigation, the following hypotheses should also be checked:
Hypothesis 1.
The tracking systems considered can be ranked by accuracy. Accuracy refers to the deviation of the obtained metrics of the exercise (the minimum and maximum positions of the target point relative to the reference).
Hypothesis 2.
A number of tracking systems, without consideration of their accuracy, have restrictions on application in the field of musculoskeletal rehabilitation due to the complexity of their use in ambulatory conditions.
Hypothesis 3.
The performance of the exercises by the participants of the control group can be classified using machine learning algorithms, taking into account the choice of a tracking system that provides the necessary accuracy.
2. Materials and Methods
2.1. Modeling the Process of Monitoring and Assessing Musculoskeletal Rehabilitation Exercises
The process of monitoring and evaluating exercise during musculoskeletal rehabilitation can be formalized and described, regardless of the movement tracking system used. This allows the model to be used further in other studies as a basis for creating monitoring and evaluation systems for exercises. To model the process of monitoring and evaluating musculoskeletal rehabilitation exercises, we use the set theory. In the future, during the practical implementation of the model in the form of software, the set theory will allow it to be used without additional transformations, moving from sets and operations to classes and methods implemented in the selected programming language.
The basis of the process being considered is the formation of a set of target points necessary to assess the quality of the exercises performed. In the first phase, the main components (characteristics) of the exercises were analyzed. Let be a multitude of exercises, and be a few exercises from this multitude. Let us denote the trajectory of target point movement that determines the characteristics of exercise as . This trajectory has corresponding unique parameters, including initial and final positions, and movement speed.
The target point is defined as the set of values of coordinates on three axes:
where , , and are the coordinates of the target point on the axes X, Y, and Z, respectively. Then, the multitude reflects the dynamics of the target point coordinates’ change in the process of exercise . The sequence of points in the set is ordered as they are received from the tracking system, starting from the first and ending with the last, which completes the exercise.
Each exercise can be matched by a certain tuple of its parameters:
where is the point of the human body on three axes, calculated on the basis of polynomials or splines, algorithms of linear regression, or other approaches that provide minimal deviation from the initial target points:
: time interval of the exercise in seconds;
: the number of measurements of the target point;
: the interval in seconds between measurements;
: the boundary values of spatial and space–time characteristics of the movement of the target point of the exercise:
where is the minimum value of the target point position on the X axis, similar to and for the Y and Z axes, respectively;
is the maximum value of the target point position on the X axis, similar to and for the Y and Z axes, respectively;
are the average values of the target point speed along the X, Y, and Z axes.
Each exercise can be matched by its category , reflecting the specific actions and movements necessary for the qualitative performance of this exercise:
After determining the main objects of the subject area and their properties, the task of assessing the exercise quality is considered.
Let a subset of exercises be given with reference to trajectories and characteristics of movements (received, for example, under the supervision of the doctor). If a new exercise of category , has entered the database, it is compared with the reference exercise of the same category by the following formulas:
where is the average standard deviation of the reference trajectory from the estimated;
: the arithmetic mean of time intervals between measurements of data, in seconds;
: estimate the performance time of the exercise relative to the reference;
: the correctional coefficient of the exercise performance time, allowing one to estimate the excess of the reference time as a satisfactory result, is selected experimentally depending on the exercise ();
: estimate of the Euclidean distance between the minimum and maximum values of the target point in the current and reference exercises;
: the assessment of the difference between the space–time characteristics (mean speed of movement) of the evaluated exercise and the reference exercise [43].
The maximum quality of the evaluated exercise is achieved when the following conditions are met:
Thus, the evaluation of the exercise is calculated on the basis of the deviation from the values of the recorded reference exercise, or, in its absence, the threshold values are used for all metrics: the ideal trajectory for which the maximum and minimum positions of the target point are set, the recommended average speed, and the time of execution.
An important component of the process of monitoring and evaluating the exercises performed is the automatic determination of the exercise type (category). Two options are possible in the practical implementation of such systems: manual selection of exercises or automatic recognition. The approach described below can be used to automatically determine the category of exercise.
It is necessary to approximate the relationship between the trajectories of the target point and the exercise category using a machine learning method:
Thus, displays multiple trajectories of target point movement in multiple categories of exercises. In addition to neural networks, other methods discussed in Section 1.2 may be used. Their effectiveness is evaluated further below.
For the presented model, a modification can be made in the case when not only one target point is tracked as part of the exercise but several. The set of exercises in the tracking of target points take the following form:
That is, subsets are formed that store the trajectories of each of the points. In Formula (6) and in the formulas below, it is necessary to make separate calculations for each of the target points, which can be averaged. Also, in Formula (16), not one trajectory is analyzed but a set of trajectories from all target points.
2.2. Data Processing Algorithms from Various Movement Tracking Systems for Exercise Monitoring
The model presented above in a generalized form formalizes the processes of monitoring and evaluating musculoskeletal rehabilitation exercises. For the successful application of this model, it is necessary to prepare the source data obtained from the movement tracking system and make them uniform so that the model can process them. We consider the appropriate algorithms for each tracking system.
2.2.1. Processing Data from Inertial Navigation Systems
A distinctive feature of the INS, based on the calculation of indications from the accelerometer and the gyroscope, is the need to integrate accelerations on three axes, taking into account angles of turning and the impact of the geomagnetic field. All this leads to a huge error in determining the speed and trajectory of the target point movement. The following is a description of the necessary data conversions.
INS form the output data in the acceleration tuple of the target point on three axes:
where , , and are accelerations along the X, Y, and Z axes, respectively, and , , and are the sets of acceleration values along the corresponding axes. Note that when forming the tuple it is necessary to record data from the device’s gyroscope to take into account the angle of inclination of the device in space.
Each -th data measurement is carried out after a period of time . At the next step, the speed of movement of the device is determined:
where , , and are the velocities along the X, Y, and Z axes, respectively, and the sets , and are the sets of velocity values along the corresponding axes.
The next step is to obtain increments of the target point trajectories along the three axes. Initially, the variables , , and have zero values (when ). , , and are the sets of values of the points of the target point trajectory along the corresponding axes. At each step with a time interval , the obtained metrics are
Thus, the tuple uniquely determines the position of the target point at time from the start of the record. The set of target points can then be used in the calculations of the model in Section 2.1 since its form and content correspond to the format given in (6). Therefore, all calculation formulas in Section 2.1 are applicable.
Due to the high measurement error, after integrating the initial data and accumulating the error, it may be necessary to apply filtering or data processing algorithms. That is, it is necessary to carry out a certain set of transformations of the of the initial data of the inertial navigation system in such a way that the average Euclidean distance of the deviation of the processed trajectory of the target point from the real trajectory is minimal:
where , , and are the positions of the point along the X, Y, and Z axes, respectively, calculated on the basis of the inertial navigation system data using filtering and signal processing algorithms. , , , and are the values of the corresponding real coordinates of the target point.
The linear Kalman filter [44] implemented in the FilterPy library [45] is used as the main filter in this study. Using this filter, it is possible to carry out a relatively accurate calculation of the speed and trajectory [46,47] in accordance with Formulas (19) and (20), as well as to remove noise.
2.2.2. Processing Data from Virtual Reality Systems
Virtual reality trackers and controllers powered by Steam VR Lighthouse technology provide coordinates from all sensors and angles of inclination with high frequency and precision. Thus, a data processing algorithm is not required for this class of systems, as the target point is originally formed in Formula (6). Velocity and acceleration can be obtained by differentiation.
When working with trackers or sensors of virtual reality systems, it is necessary to carry out initial calibration to obtain coordinates normalized relative to the initial position. This process does not cause difficulties, since it consists of saving the coordinate values of target points obtained during calibration and subtracting these values from the current ones, which can be integrated into the data acquisition system.
2.2.3. Processing Data from Motion Capture Suit
As a result of the motion capture suit use, a set of one base point and a multitude of segments (bones) located in relation to it is formed, the position of which is indicated by angles of inclination on three axes. If necessary, the system allows one to record, in addition to changes in the sensor angle, its movement relative to the previous measurement [23].
Mark the base point on the back of the user as , the tuple contains coordinates on three axes and angles of turns. At a certain point in time is given a number of segments (bones) , the total number of . For each segment three values are given:
where are the characteristics of the turn of the -th sensor on three axes, relative to the previous measurement.
A multitude of segments is set for each measurement, thus forming a sequence of , containing information about all the movements of the human body model. This sequence is transmitted to a development environment capable of processing recorded animations from motion capture suits.
The next stage of data processing is the selection of target points on the digital model of the human body [42]. To achieve this, it is necessary to set the size of the human body model (height and length of the limbs), after which a number of target points is set. Each target point is attached to the nearest segment of the digital model (and the segment is higher in the skeletal model hierarchy than the target point):
where is the position of the starting point of the segment in the metric coordinates of the virtual scene, the scales of which are close to the real world;
is the distance between the start point of the segment and the selected target point.
Then, when the segment is shifted, taking into account the fixed distances , changing the position of leads to obtain the current position of the target point. Thus, Formula (24) corresponds in form to (6) and can be used to assess the quality of the exercise.
2.2.4. Processing Data in Computer Vision Systems
The data processing algorithm for tracking the human body by computer vision systems has certain similarities with the algorithm presented in Section 2.2.3 but has the following features:
- There is no reference point;
- All points of the human body model have their own coordinates;
- The coordinates of body model points are given in relative values (from 0 to 1), in accordance with the position on the frame received from the camera.
These features lead to the need to perform the following conversions on the source data. The first phase of the algorithm involves extracting from the frame , obtained at time , a set of points :
where are the coordinates of point in frame along three axes. Most neural network models position points in two coordinates (X and Y) due to the complexity of depth estimation when using a camera. A number of algorithms (for example, MediaPipe) simulate the determination of the coordinate relative to some reference point, but this value is inaccurate.
Therefore, to accurately determine the position of a person in space along all three axes using several (at least two) cameras, the following is calculated:
where and are the position of point on the first and second cameras, respectively, along the X axis;
and are the position of point on the first and second cameras, respectively, along the Y axis;
and are the maximum pixel values along the X and Y axes, respectively;
and are coefficients for converting pixels into meters, determined by taking into account the length of the limbs and correlating them with the length of the corresponding recognized segment on the frame.
As a result of the transformation, the target point is formed as follows (27):
The resulting target point format corresponds to Formula (6).
Another approach is to use triangulation, the process of determining a point in three-dimensional space given its projections onto two or more images. To calculate the coordinates of a point in three-dimensional space, it is necessary to know the coordinates of its projections on images and the projective matrices of cameras [48]. The projective matrix of a certain camera can be represented as a combination of the matrices (containing the internal parameters of the camera) and (rotation), as well as the displacement vector of the , which describe the change in coordinates from the world coordinate system to the coordinate system relative to the camera:
where : the coordinates of the camera central point;
: focal length in pixels.
At the base of the three-dimensional reconstruction of the object points by the values of point projection positions on the images from all cameras is the epipolar geometry. It provides a condition for searching for pairs of corresponding points on two images: if it is known that the point on the plane of the first image corresponds to the point on the plane of the other image, then its projection must lie on the corresponding epipolar line. According to this condition, for all corresponding pairs of points , the following relation is true:
where is a fundamental matrix of size and rank equal to two.
For some point , given in three-dimensional space, the following projection formula is valid, expressed in homogeneous coordinates:
where are the homogeneous coordinates of some point on the plane of the -th image (obtained from the -th camera during the second stage), including the position on the image of (along the X axis) and (along the Y axis);
: the scaling factor;
: the projection matrix of the -th camera obtained earlier.
To simplify calculations, the projection matrix of a camera is often represented in the following form:
where is the -th row of the matrix .
Therefore, Equation (31) can be represented as follows:
The following system of equations is obtained by considering as a scaling factor:
Since is a homogeneous representation of coordinates in three-dimensional space, to calculate them, it is necessary to obtain and for at least two cameras. To solve the system of Equation (34), there are a large number of implemented triangulation algorithms, for example, L2, direct linear transform, or other approaches implemented in the OpenCV computer vision library [49]. As a result of their work, a vector of three-dimensional coordinates similar to (28) is also formed.
If, during the exercise, it is necessary to track the movement of the target point only along two coordinates, then it is possible to use Formula (27), without taking into account the second camera and the need to calculate values along the third coordinate axis. An important point of this simplification is that it is necessary to correlate the normalized length of a body segment, obtained from the recognition algorithm (for example, MediaPipe) and expressed in pixels, with the real size of this segment, defined in meters. Using this ratio allows the calculation of all body segments in metric values.
2.3. Application of Machine Learning Algorithms for Analysis and Classification of Musculoskeletal Rehabilitation Exercises
Theoretical studies described in Section 2.1 and Section 2.2 on modeling the processes of monitoring and evaluating musculoskeletal rehabilitation exercises and algorithms for processing information from various sources make it possible to collect, analyze, and evaluate user actions in the rehabilitation process. However, problem (16) remains open; that is, it is necessary to determine a machine learning algorithm that allows classifying of user actions or movements as a kind of exercise. The importance of this task lies in the fact that, without an automated determination of the current exercise, it is impossible to correctly assess the quality of its performance since each exercise has its own trajectory of movements and spatio-temporal characteristics.
In Section 1.2, the main approaches and existing research in the field of the machine learning application in the rehabilitation and tracking of human movements are reviewed. Based on the presented model and algorithms, the procedure for applying machine learning technologies for the analysis and classification of musculoskeletal rehabilitation exercises is described.
For each exercise , a trajectory of the target points movement is specified, including tuples of three-dimensional coordinates of one or more points, the number of which is specified by the variable . Thus, the total dimension of the exercise initial data has the following form:
where is the number of recorded sets of target points, corresponding to the size of the set , taking into account the supposition that, within , the lengths of the trajectories of all target points are equal.
To approximate (16), it is necessary to analyze the dynamics of changes in the position of the target points, and the use of measurement at one point in time does not allow one to determine the exercise since a person can occupy similar positions while performing various exercises. On the other hand, using the entire dataset leads to the problem of a lack of a single dimension for all exercises due to their different durations ().
To solve this problem, the classical approach is to determine the size of some window , which selects a fixed-length fragment from the input data sequence. Such fragments of the same size are processed by machine learning algorithms with some shift (step) until the window extracts the last fragment. This allows one to process time sequences of any length and create a forecast for each of them (in the framework of this study, an exercise category for each fragment). For the original time sequence, the resulting output is obtained:
where is the number of fragments determined on the basis of the following calculation; is the number of elements that are used to form complete fragments. Division by shows how many such complete fragments can exist. The unit in expression (36) determines the possibility of adding the last incomplete fragment, which can be shorter than if is not exactly divisible by (in this case, the last fragment consists of the last values).
Using expression (36), the entire initial time sequence is processed. Then, the machine learning algorithm required to approximate the expression (16) takes as input a multidimensional vector of the format and at the output returns a vector belonging to a certain category of exercise with size . The mapping is specified on the entire set of fragments of target point trajectories; even if the fragment initially does not have an exercise category , it can be assigned a new category , to which all unrecognized fragments are assigned [50].
Next, it is necessary to determine the optimal machine learning algorithm for solving the classification problem. Since multidimensional time sequences are processed, the following algorithms and architectures are chosen as possible solutions:
- DecisionTreeClassifier: decision trees for multiclass classification; the input of the algorithm must be an array of the format (the number of examples, the number of features), which requires transformation:
- KNeighborsClassifier: k-nearest neighbor classifier; the input data format is identical to decision trees and requires transformation (37);
- RandomForestClassifier: a meta estimator that trains a set of decision trees; input data format needs to be converted (37);
- NN: multilayer neural networks including dense layers;
- LSTM: multilayer recurrent neural networks, including layers of long-term memory;
- CNN: convolutional neural networks using 1D convolutional layers (Conv1D) to identify and generalize features in a time sequence;
- CNN + Transformer: a combined neural network that first identifies the main features of the data using convolutional layers, then uses the MultiHeadAttention layers to extract from the set all the most important features for the current class. As a basis for the architecture of this network, it is proposed to use MobileViT [51], which requires a transformation of the input data to the following form:
The presented five architectures of machine learning algorithms make it possible both to identify the best solution in the process of selecting the hyperparameters of each of the architectures (tree depth for the first two algorithms, the number of layers and neurons for the rest), and to determine their applicability for analyzing data on the process of human movement.
3. Results
3.1. Experimental Research Design
Experimental studies had the structure described below. A small control group was formed which performed the following exercises:
Task 1: raise the arm to a level parallel to the floor, then lower it (10 repetitions). The target point is the wrist of the hand performing the exercise by the trajectory , where each trajectory point corresponds to coordinates according to Formula (6).
where are the initial coordinates of the target point (hand) at the beginning of the exercise; is the final position of the subject’s hand in a state parallel to the floor. Thus, the hand must pass the distances and along the corresponding axes.
Task 2: lifting the leg to the level of the step, which is imitated by stepping onto the box and then returning to the starting position (10 repetitions). The target point is the foot of the leg performing the exercise by the trajectory .
where are the initial coordinates of the leg at the beginning of the exercise; is the final position of the subject’s leg while on the box (the same for all participants).
Task 3: standing up from a chair and then returning to the starting position. (10 repetitions). Target points are lumbar region and neck, along which the corresponding trajectories and are tracked in exercise .
where is the initial position of the lumbar region; is the initial position of the neck; is the position of the subject’s lumbar region in a standing position.
The experiment was carried out as follows: the subject with the tracking system hardware connected to him/her was in the starting position, and the required lengths of his body parts (arms, legs, and torso) were measured, which was used later when working with systems based on normalized coordinates. Next, the exercise was performed for 10 repetitions. The values of the target points were fixed in their extreme positions, and the trajectories of their movements were also recorded. Further, the collected data were used to evaluate the accuracy of tracking the target points and to classify the exercises performed.
During the experiment, data were collected from five motion tracking systems:
S1: Android mobile phone with built-in inertial navigation system and 100 Hz recording frequency.
S2: Wireless inertial navigation system based on the MPU-9250 MotionTracking device, recording frequency: 500 Hz.
S3: HTC Vive Tracker sensor set, recording frequency: 60–100 Hz.
S4: Motion capture suit Perception Neuron with 32 sensors, animation frequency: 60 Hz.
S5: MediaPipe Pose computer vision system and 1080 p 30 Hz cameras.
Each one of the listed tracking systems was fixed to the human body at the target point, after which data were collected when performing the exercise in the required number of repetitions. The total weight of the tracking systems does not exceed 1.5 kg, distributed mostly evenly, since the largest contribution is made by the Perception Neuron suit (1.1 kg). The collected data were digitized in accordance with the algorithms in Section 2.2. Since each participant’s height and limb length were known, it was possible to determine the optimal position of the target point, relative to which the MSE and metrics based on the Euclidean distance were calculated. A comparison of systems by metrics was carried out using statistical analysis according to the Kruskal–Wallis method to determine if there was a statistically significant difference between the medians of three or more independent groups. The Kruskal–Wallis test did not assume normality of the data and was much less sensitive to outliers than a one-way ANOVA.
Part of the experiment is shown in Figure 1.

Figure 1.
Fragments of experimental studies.
As part of the experiment, the quality of the exercise was not evaluated in terms of position, speed, or trajectory since these parameters were set individually by the attending physician. However, these metrics were used to compare tracking systems. For each exercise and repetition, the minimum and maximum positions of the target point along the three axes were analyzed, after which the distance traveled by the point was calculated. Additionally, the deviation of the target point from the initial and final positions was estimated.
The selected control group of eight people for the correct comparison of tracking systems does not have diseases of the musculoskeletal system. All participants were informed about the conditions of the experiment and agreed to participate in it.
As a result, the most accurate tracking system was selected, taking into account the requirements for the comfort of its use in conditions of musculoskeletal rehabilitation. Further, this tracking system was used in the second experiment when comparing different machine learning algorithms in order to solve the problem of classifying musculoskeletal rehabilitation exercises. To ensure the correct operation of machine learning algorithms on all tracking systems, the recording frequency was aligned to a common value of 30 Hz.
3.2. Comparison of Motion Tracking Systems in Musculoskeletal Rehabilitation Exercises
At the first stage of the experimental studies, each of the participants in the control group performed the three exercises discussed above (10 repetitions each). Each measurement was processed according to the algorithms in Section 2.2. The experiment was conducted in a closed room with a free space of 2.5 × 1.8 m with the same equipment for each participant (Figure 1). At the beginning of each experiment, the sensors were calibrated to reduce the influence of electromagnetic interference. In the experimental area, all equipment not used directly in the study was turned off. The duration of one repetition of the exercises was as follows: for Task 1—7.1 ± 1.7 s, for Task 2—6.3 ± 1.9 s, for Task 3—6.1 ± 1.3 s.
The collected and processed data were filtered to eliminate errors caused by electromagnetic interference, loss of sensors, or the accumulation of a too-large error in INS. The recording considered a result an error if the distance traveled by the target point exceeded 3 m. As a result, 1335 exercise records were collected. Table 1 shows the amount of data collected for each exercise and tracking system. It was assumed that the target points of exercise 3 were considered separately; for the upper point, we denoted this as Task 3 (TP), and for the lower point, Task 3 (BP). The last line of the table reflects the percentage of correct entries from the maximum possible number, which leads us to conclude that the recording and tracking systems are stable.

Table 1.
The amount of data collected from each tracking system.
Table 2 shows the maximum values in each of the axes for the target point (, , and ). After that, the distances traveled by the target points along the corresponding axes (, , and ) were calculated, as were two metrics, MSE and between the positions of the target point and its reference position, calculated on the basis of the overall body characteristics for each participant, as well as given constants (box and chair sizes). The metrics were calculated both for the final position and for the distance traveled (since some systems saved point values in normalized coordinates, the starting point did not always have zero values on all axes, or the direction of movement after calibration was not always in the positive direction). The lowest metric values for each exercise are shown in bold. The last column is the -value of the Kruskal test for assessing the statistical significance of the sample equality among themselves. If the -value < 0.05, then the hypothesis about the equality of the samples is refuted and there is a statistical difference between them. The obtained -value indicates that the samples are completely distinct from one another.
Table 2.
Comparison of tracking systems for accuracy.
In the course of the obtained experimental data analysis, it can be concluded that target point tracking is the most accurate when using virtual reality trackers (S3). Next in accuracy are the motion capture suit (S4) and computer vision (S5). The systems based on accelerometers (S1 and S2) provide the least accuracy. It should be noted that in a number of scenarios, the S4 and S5 systems show the best results. By evaluating the average results for all exercises, it can be concluded that the S5 system is superior to S4.
The results in Table 2 are consistent with existing studies. INS, especially those based on mobile sensors, tend to accumulate errors, which can lead to an absolute positioning error of 0.15 to 0.8 m [52,53]. In [54], phone sensors were used; when comparing different approaches, the error was up to 5% when moving over long distances (hundreds of meters), but with small movements, as in our study, it can be higher. High accuracy (up to 0.07 m) when using an IMU can be achieved by combining several devices connected to a single network [55], but such a design could approach motion capture systems in terms of implementation complexity, yielding to them in universality.
In [56], when using six virtual reality trackers, an average deviation of 0.02 m was obtained. Motion capture systems, similarly to inertial systems, are susceptible to error accumulation and, depending on the movements performed, can show different accuracy. The values obtained in the experiment are comparable with existing results of 0.2 m and an average deviation of up to 0.41 m [57].
Computer vision systems are often evaluated by angle deviations; however, a number of studies give an error estimate from 0.02 to 0.16 m [58], and a global comparative study [59] gives an error estimate from several to tens of centimeters (depending on the task and method). The results obtained in Table 2 are fully consistent with the current limitations of computer vision technology.
3.3. Assessment of the Classification Accuracy of Musculoskeletal Rehabilitation Exercises
The next stage of research is to analyze the possibility of classifying musculoskeletal rehabilitation exercises performed by a person using various machine learning algorithms. The list of compared models is presented in Section 2.3. The final parameters of the models that provide the best classification performance are presented in Table 3.
Table 3.
Parameters of selected machine learning algorithms.
Table 3.
Parameters of selected machine learning algorithms.
| Model | Description |
|---|---|
| DecisionTreeClassifier (DT) | Standard decision tree regressor with max_depth = 10 |
| KNeighborsClassifier (KNN) | Standard classifier based on k-nearest neighbors |
| RandomForestClassifier (RF) | Standard random forest with n_estimators = 20, max_depth = 10 |
| Simple neural network (NN) | Multilayer neural network with 4 hidden Dense layers of 200 neurons with ReLU activation function, 1 Dropout layer (20% dropout rate) |
| Long short-term memory neural network (LSTM) | Multilayer neural network with two LSTM layers (20 and 50 neurons), 2 hidden Dense layers of 100 neurons, 1 Dropout layer (20% dropout rate) |
| Multiple neural network (CNN) | Multilayer Neural Network with 4 Blocks from the Conv1D Convolutional Layer (number of filters from 32 to 256, convolutional kernel = 3) combined with BatchNormalization, followed by GlobalAvgPool1D and 1 Dense layer of 100 neurons |
| CNN + Transformer (Transformer) | A model based on the MobileViT architecture shown in Figure 2 |

Figure 2.
Upgraded MobileViT architecture of the Transformer model.
Figure 2.
Upgraded MobileViT architecture of the Transformer model.
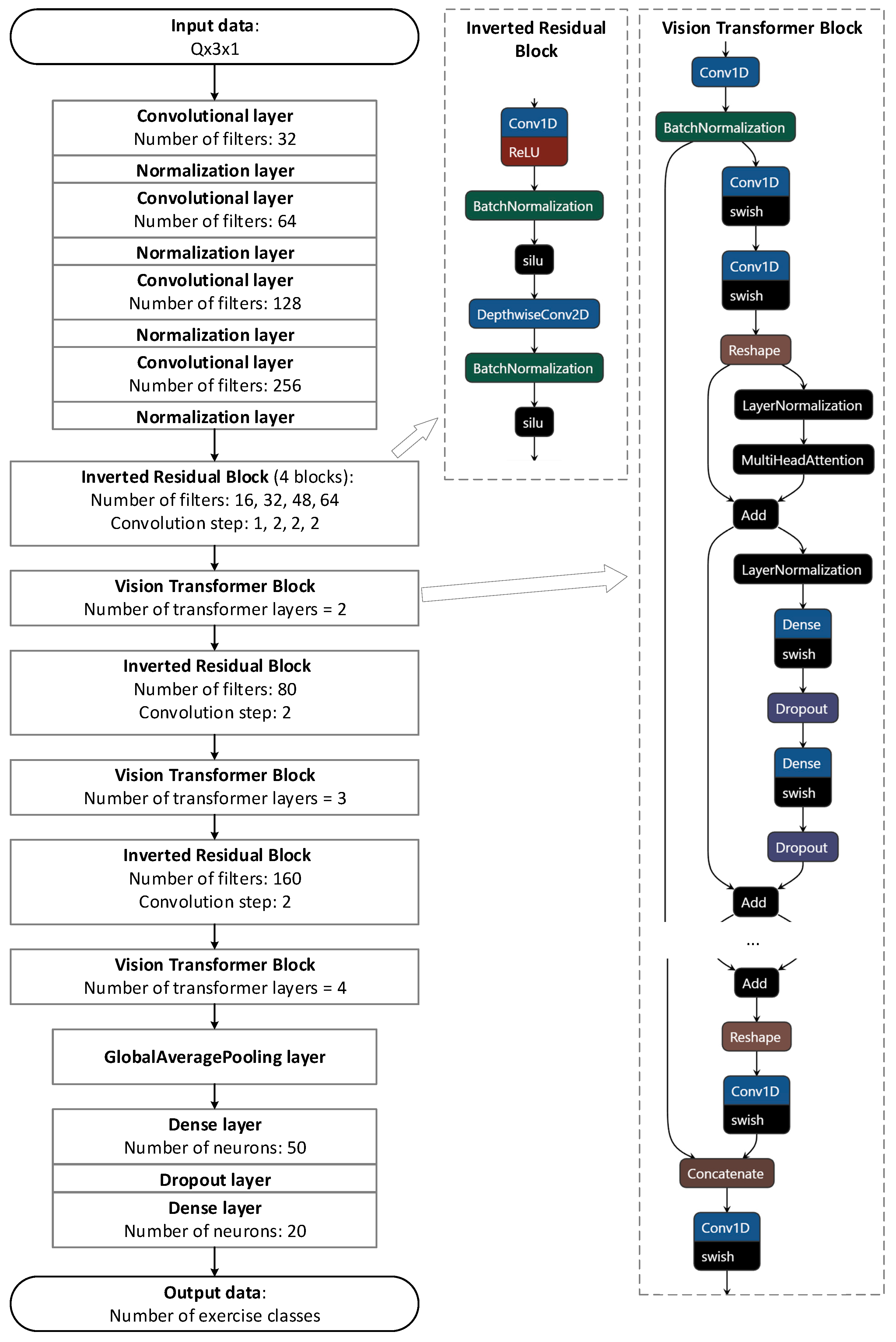
It should be noted that various tracking systems allow the extraction of information not only around the target point but also around other points of the human body (for example, systems S4 and S5) in the standard mode of operation, while other systems require the addition of more sensors, which briefly complicates the process of collecting and processing data.
At the next stage of research, experiments were carried out to determine the optimal size of the analyzed fragment . For this, data from all tracking systems were used, after which all selected models were trained for 10 epochs on the generated datasets at = 10, 25, 50, 100, 200. The results of this comparison are presented in Table 4. The best results for each model are highlighted in bold font. The table also shows the dimensions of the dataset obtained for each .
Table 4.
Comparison of selected machine learning models for different Q.
When choosing the size of , an important aspect must be taken into account: a too-long window does not allow the analysis of short exercises and increases the delay in real-time analysis. On the other hand, it is obvious that too-short fragments do not allow one to reveal the characteristic features of the exercises. In addition, for very large , if the original record has a length less than , it is not included in the dataset. Based on the data in Table 4, this happens for . At a value of , the accuracy of the trained models is low. Given the above, the optimal value of is 100, since this allows one to take all the data into account and ensure good accuracy.
Thus, the collected data were processed with a step S = 50 and a window size , which made it possible to form a dataset of 1966 values. In total, 80% of the data was used for training and 20% for testing. The data were also divided into samples related to each type of tracking system. Also, in the course of the previous experiment, the undertraining of the models was clearly visible; therefore, further training of neural networks was carried out for 50 epochs. Table 5 presents the results of comparing models for each of the tracking systems (by accuracy metric), as well as for the S3–S5 dataset (last column). Figure 3 shows the error matrices for all models trained on the S3–S5 dataset. The grouping of data S3–S5 was chosen because of its greater accuracy relative to systems S1 and S2.
Table 5.
Comparison of machine learning algorithms.

Figure 3.
Classification error matrices of different models (dataset of systems S3–S5).
When training neural networks, it was assumed that the upper and lower target points in exercise 3 were considered separately since the difference in the number of points at the input of the models would automatically reveal exercise 3 relative to the others. On the other hand, such a division is of interest in terms of the ability of models to determine the exercise even for one target point out of two.
An analysis of the results obtained suggests that the NN model shows the highest accuracy on the dataset used, followed by RF and KNN. They are stable both on individual datasets and on a complete set that combines information from various sources. It should be noted the simplicity of these models and the speed of their learning, which clearly indicate their applicability to real problems. The Transformer model also performs well on data from S3–S5 systems but has high complexity and a long training time, like LSTM.
Due to the low accuracy of tracking target points on systems S1 and S2, there is a low accuracy of the models on the data from these systems. The training of S3–S5 systems demonstrates very high accuracy results, which allows us to consider their applicability.
An experiment was also conducted to use all 33 points of the S5 computer vision system to classify exercises. Since all points of the human body were analyzed, it is possible to classify exercise 3 in the same way as the rest without the need to separate into upper and lower target points. The results are presented in Table 6. The best result was shown by the NN, RF, KNN, and Transformer models, which is consistent with previous experiments. The table also presents the values of the F1-measure metric for each of the classes.
Table 6.
Comparison of machine learning algorithms at all points of the S5 system.
The results presented in Table 6 indicate that the use of all points of the body affects the solution of the problem of the classification of musculoskeletal rehabilitation exercises. It should be noted that a number of models handle the increased volume of input data rather poorly. Other models (for example, Transformer), on the other hand, carry out classification at a high level.
Next, it is important to provide a summary of the findings from the investigations.
4. Discussion
The conducted experimental studies made it possible not only to quantitatively compare different tracking systems in terms of the accuracy of positioning human target points but also to draw conclusions about the qualitative differences between them when solving problems of musculoskeletal rehabilitation. We consider these features of motion tracking systems in the process of confirming or refuting the hypotheses put forward earlier.
To confirm the first hypothesis, the issue of ranking tracking systems by accuracy was considered. Indeed, when performing different types of exercises and recording the positions of the target points using capture systems, significantly different results were obtained. The empirical investigations reveal that the S3 system utilizes virtual reality trackers, which have design features that ensure the highest level of accuracy. The disadvantage of the S3 system is that there are problems when the sensor is covered by clothing or the body, which leads to incorrect values. It is also necessary to take into account the need to install base stations and the high cost of this system, as it should include a VR headset that is not directly involved in the process. For those systems where virtual reality is integrated into the rehabilitation procedure, this disadvantage is less important.
Next in precision are systems based on motion capture suits (S4) and the use of cameras with computer vision (S5). In a number of scenarios, comparable results were shown by these systems, but based on the results, the superiority of the S5 system can be discussed. Its advantages include the absence of additional sensors and ease of operation since it is only required to place a person in the tracking zone and periodically calibrate the cameras for the operation of triangulation algorithms. In addition, it is possible to build an S5 system based on a single camera (when tracking target points in two-dimensional space), which is discussed in Section 2.2.4. One of the important disadvantages of the S4 system is that data recording is not always correct due to external interference or the accumulation of sensor errors (about 10% of the records were eliminated after preprocessing; see Table 1).
Systems S1 and S2, based on inertial sensors (gyroscope, accelerometer), allow one to determine the movement of the target point autonomously. S1 is also extremely accessible to the general population. On the other hand, the positioning accuracy due to the accumulation of errors, noise, and sensor errors is quite high. It should be noted that from 36 to 32% of the records were unsuitable for processing due to high discrepancies with real data and the impossibility of restoring the correct movement trajectory from the initial acceleration values. This does not allow one to consider the effective use of such systems in the organization of the musculoskeletal rehabilitation process.
Hypothesis 1 is completely confirmed. In the process of its confirmation, it was found that systems S3, S5, and S4 have the best accuracy. S1 and S2 are not recommended for use.
Given the specifics of the subject area—performing musculoskeletal rehabilitation exercises—accuracy is not the only criterion for choosing a tracking system. Therefore, in the process of testing hypothesis 2 about the limitations of using the considered tracking systems and monitoring the progress of the exercises (Figure 1), the following conclusions were drawn:
- The use of a motion capture suit for people with diseases of the musculoskeletal system is impossible, as it requires attaching too many sensors and equipment to them;
- Systems S1 and S2 require fixing the corresponding devices on the human body, which is not possible or convenient for all points, especially in the case of S2. In addition, these systems, even within the framework of the experiments performed, are extremely inconvenient when collecting more than one target point (since this requires a synchronization system for launching and processing data);
- During the operation of the S3 system, there are similar disadvantages, to which is added the need to install base stations indoors, in the area where the VR helmet should also be located; this greatly limits the use of these systems in both outpatient and inpatient environments;
- The S5 system does not contact the user directly, which does not impose any restrictions on him/her; cameras can be fixed at an arbitrary distance and track all points of the human body at the same time; the disadvantages include possible system failures if other people appear in the visibility zone, but this aspect can be eliminated by additional software that takes into account the appearance of the current user.
Thus, hypothesis 2 is also confirmed. In addition to differences in tracking accuracy, the considered systems have a number of limitations that make it difficult to use them in outpatient and inpatient environments. Among all systems, therefore, preference should be given to the S5 system because it does not affect the user and is quite accurate. In addition, the use of all points of the human body allows one to classify exercises with the highest accuracy (Table 6).
To confirm hypothesis 3, the corresponding studies were carried out, as presented in Section 3.3. A comparison was made of various machine learning algorithms on each of the tracking systems under consideration, and a search was conducted for a universal model that can process and classify data from any source. In the course of these experiments, the optimal window size for analyzing movement data was determined, and models (NN, RF, and KNN) were selected that provide an accuracy of exercise classification up to 96%. The use of all points of the human body in combination with the computer vision system (S5) allows one to obtain a classification accuracy of 100% on NN, RF, KNN, and Transformer models.
Thus, the third hypothesis is also confirmed: the machine learning models trained on the collected dataset make it possible to determine the performed musculoskeletal rehabilitation exercise with high accuracy.
5. Conclusions
This study considers the task of tracking a person in the process of musculoskeletal rehabilitation using various motion capture systems in order to ensure the highest positioning accuracy. In the course of this study, the following tasks were successfully solved.
An analysis of the subject area was carried out, on the basis of which the modeling of the processes of monitoring and evaluating musculoskeletal rehabilitation exercises was performed, including a description of the procedures for determining the position of the user’s body parts, the amplitude and speed of their movement, the current exercise, and the quality of its implementation. Algorithms for processing data from various motion tracking systems have been developed.
In the course of experimental studies, based on the developed models and algorithms, data were collected from various user tracking systems. They were compared and ranked in terms of accuracy: the best results were shown by a system based on virtual reality trackers, followed by a computer vision system and a motion capture suit; the worst results were obtained using INS. In the course of the experiments, limitations were identified for the use of motion tracking systems when performing musculoskeletal rehabilitation exercises.
Various machine learning models were developed and trained to solve the problem of classification of musculoskeletal rehabilitation exercises, and their comparison was carried out. It is found that fairly simple models show the best results: a multilayer dense neural network model, a random forest, and a classifier based on k-nearest neighbors. An experiment was also conducted in the classification of exercises with the processing of all points of the body received from the computer vision system. The NN, KNN, RF, and Transformer models showed good results, which further confirms the applicability of this tracking system.
The hypotheses put forward at the beginning of this study about the ranking of tracking systems according to the positioning accuracy of human target points, about the presence of restrictions on their use in the field of musculoskeletal rehabilitation, and about the possibility of classifying musculoskeletal rehabilitation exercises are fully confirmed.
Thus, the main contribution of this study lies in the following aspects:
- -
- A comparative analysis of human movement tracking systems adapted for musculoskeletal rehabilitation, which revealed that systems based on computer vision are most preferable in this area;
- -
- Modeling the process of monitoring and evaluating specific exercises for an adapted tracking system, taking into account restrictions on low mobility of users (use in outpatient and inpatient environment, lack of sensors directly on the human body);
- -
- Development and testing of data processing algorithms for selected human tracking systems, which allows for each of them to determine the qualitative aspects of musculoskeletal rehabilitation exercises, and monitor and evaluate them;
- -
- Implementation of exercise classification algorithms with the ability to automatically determine exercises based on developed and trained machine learning models, which can also be used to identify human movement patterns and recognize types of activity for the subsequent implementation of automatic systems for monitoring and tracking human activities.
The aim of further research is to test and deepen the results obtained: expanding the range of classified exercises using the selected tracking system based on computer vision; integration of trained machine learning models for the development of software for monitoring and evaluating musculoskeletal rehabilitation exercises, operating on the basis of computer vision technologies. It is also planned to use the developed algorithms and tools in assessing changes in a person’s condition during the use of musculoskeletal rehabilitation systems.
Author Contributions
Conceptualization, A.O. and A.P.; Data curation, D.T.; Formal analysis, A.V.; Funding acquisition, A.O. and A.P.; Investigation, A.P. and D.T.; Methodology, A.O. and A.V.; Project administration, A.O.; Resources, E.S. and I.F.; Software, D.T., E.S. and I.F.; Supervision, A.O., A.V. and A.N.; Validation, A.O. and A.V.; Visualization, D.T.; Writing—original draft, A.O. and A.N.; Writing—review and editing, A.O. and A.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Ministry of Science and Higher Education of the Russian Federation within the framework of the project “Development of medical VR simulator systems for training, diagnosis and rehabilitation” (No. 122012100103-9).
Institutional Review Board Statement
This study was conducted in accordance with the Declaration of Helsinki, and approved by the Scientific and Technical Board of Tambov State Technical University (protocol 3 of 13 December 2022, project 122012100103-9).
Informed Consent Statement
Informed consent was obtained from all subjects involved in this study.
Data Availability Statement
Datasets available on request form corresponding author only as the data are sensitive and participants may be potentially identifiable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Collado-Mateo, D.; Lavib-Perez, A.M.; Penacoba, C.; Del Coso, J.; Leyton-Roman, M.; Luque-Casado, A.; Gasque, P.; Fernandez-del-Olmo, M.A.; Amado-Alonso, D. Key factors associated with adherence to physical exercise in patients with chronic diseases and older adults: An umbrella review. Int. J. Environ. Res. Public Health 2021, 18, 2023. [Google Scholar] [CrossRef] [PubMed]
- Razuvaeva, T.; Gut, Y.; Lokteva, A.; Pchelkina, E. The problem of psychological rehabilitation of persons with disorders of the musculoskeletal system acquired in adulthood. Behav. Sci. 2019, 9, 133. [Google Scholar] [CrossRef] [PubMed]
- Gatchel, R.J.; Dougall, A.L. Psychosocial and Psychiatric Sequelae of Chronic Musculoskeletal Pain and Disability Disorders. In Handbook of Musculoskeletal Pain and Disability Disorders in the Workplace; Springer Science & Business Media: New York, NY, USA, 2014; pp. 219–233. [Google Scholar]
- Negrini, S.; Antonini, G.; Carabalona, R.; Minozzi, S. Physical exercises as a treatment for adolescent idiopathic scoliosis. A systematic review. Pediatr. Rehabil. 2003, 6, 227–235. [Google Scholar] [CrossRef] [PubMed]
- Marzolini, S.; Oh, P.; McIlroy, W.; Brooks, D. The effects of an aerobic and resistance exercise training program on cognition following stroke. Neurorehabilit. Neural Repair 2013, 27, 392–402. [Google Scholar] [CrossRef] [PubMed]
- Ye, G.; Grabke, E.P.; Pakosh, M.; Furlan, J.C.; Masani, K. Clinical benefits and system design of FES-rowing exercise for rehabilitation of individuals with spinal cord injury: A systematic review. Arch. Phys. Med. Rehabil. 2021, 102, 1595–1605. [Google Scholar] [CrossRef] [PubMed]
- Gamble, A.R.; Pappas, E.; O’Keeffe, M.; Ferreira, G.; Maher, C.G.; Zadro, J.R. Intensive supervised rehabilitation versus less supervised rehabilitation following anterior cruciate ligament reconstruction? A systematic review and me-ta-analysis. J. Sci. Med. Sport 2021, 24, 862–870. [Google Scholar] [CrossRef]
- Hohmann, E.; Tetsworth, K.; Bryant, A. Physiotherapy-guided versus home-based, unsupervised rehabilitation in isolated anterior cruciate injuries following surgical reconstruction. Knee Surg. Sports Traumatol. Arthrosc. 2011, 19, 1158–1167. [Google Scholar] [CrossRef]
- Longo, U.G.; Berton, A.; Risi Ambrogioni, L.; Lo Presti, D.; Carnevale, A.; Candela, V.; Denaro, V. Cost-effectiveness of supervised versus unsupervised rehabilitation for rotator-cuff repair: Systematic review and meta-analysis. Int. J. Environ. Res. Public Health 2020, 17, 2852. [Google Scholar] [CrossRef]
- Coulter, C.; Perriman, D.M.; Neeman, T.M.; Smith, P.N.; Scarvell, J.M. Supervised or unsupervised rehabilitation after total hip replacement provides similar improvements for patients: A randomized controlled trial. Arch. Phys. Med. Rehabil. 2017, 98, 2253–2264. [Google Scholar] [CrossRef] [PubMed]
- Rhim, H.C.; Lee, J.H.; Lee, S.J.; Jeon, J.S.; Kim, G.; Lee, K.Y.; Jang, K.M. Supervised rehabilitation may lead to better outcome than home-based rehabilitation up to 1 year after anterior cruciate ligament reconstruction. Medicina 2020, 57, 19. [Google Scholar] [CrossRef]
- Ryrsø, C.K.; Godtfredsen, N.S.; Kofod, L.M.; Lavesen, M.; Mogensen, L.; Tobberup, R.; Iepsen, U.W. Lower mortality after early supervised pulmonary rehabilitation following COPD-exacerbations: A systematic review and meta-analysis. BMC Pulm. Med. 2018, 18, 154. [Google Scholar] [CrossRef]
- Nalini, M.; Moradi, B.; Esmaeilzadeh, M.; Maleki, M. Does the effect of supervised cardiac rehabilitation programs on body fat distribution remained long time? J. Cardiovasc. Thorac. Res. 2013, 5, 133. [Google Scholar] [PubMed]
- Lacroix, A.; Hortobagyi, T.; Beurskens, R.; Granacher, U. Effects of supervised vs. unsupervised training programs on balance and muscle strength in older adults: A systematic review and meta-analysis. Sports Med. 2017, 47, 2341–2361. [Google Scholar] [CrossRef] [PubMed]
- Brouns, B.; Meesters, J.J.; Wentink, M.M.; de Kloet, A.J.; Arwert, H.J.; Vliet Vlieland, T.P.M.; van Bodegom-Vos, L. Why the uptake of eRehabilitation programs in stroke care is so difficult—A focus group study in the Netherlands. Implement. Sci. 2018, 13, 133. [Google Scholar] [CrossRef] [PubMed]
- Qiu, S.; Liu, L.; Wang, Z.; Li, S.; Zhao, H.; Wang, J.; Tang, K. Body sensor network-based gait quality assessment for clinical decision-support via multi-sensor fusion. IEEE Access 2019, 7, 59884–59894. [Google Scholar] [CrossRef]
- Yen, C.T.; Liao, J.X.; Huang, Y.K. Human daily activity recognition performed using wearable inertial sensors combined with deep learning algorithms. IEEE Access 2020, 8, 174105–174114. [Google Scholar] [CrossRef]
- Tahir, S.B.U.D.; Jalal, A.; Kim, K. Wearable inertial sensors for daily activity analysis based on adam optimization and the maximum entropy Markov model. Entropy 2020, 22, 579. [Google Scholar] [CrossRef]
- Šlajpah, S.; Čebašek, E.; Munih, M.; Mihelj, M. Time-Based and Path-Based Analysis of Upper-Limb Movements during Activities of Daily Living. Sensors 2023, 23, 1289. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Weng, D.; Li, D.; Xun, H. An improved method of pose estimation for lighthouse base station extension. Sensors 2017, 17, 2411. [Google Scholar] [CrossRef] [PubMed]
- Maskeliūnas, R.; Damaševičius, R.; Blažauskas, T.; Canbulut, C.; Adomavičienė, A.; Griškevičius, J. BiomacVR: A virtual reality-based system for precise human posture and motion analysis in rehabilitation exercises using depth sensors. Electronics 2023, 12, 339. [Google Scholar] [CrossRef]
- Wu, Y.; Tao, K.; Chen, Q.; Tian, Y.; Sun, L. A Comprehensive Analysis of the Validity and Reliability of the Perception Neuron Studio for Upper-Body Motion Capture. Sensors 2022, 22, 6954. [Google Scholar] [CrossRef]
- Choo, C.Z.Y.; Chow, J.Y.; Komar, J. Validation of the Perception Neuron system for full-body motion capture. PLoS ONE 2022, 17, e0262730. [Google Scholar] [CrossRef]
- Lugaresi, C.; Tang, J.; Nash, H.; McClanahan, C.; Uboweja, E.; Hays, M.; Grundmann, M. Mediapipe: A Framework for Building Perception Pipelines. arXiv 2019, arXiv:1906.08172. Available online: https://arxiv.org/pdf/1906.08172 (accessed on 18 July 2023).
- Movenet: Ultra Fast and Accurate Pose Detection Model. Available online: https://www.tensorflow.org/hub/tutorials/movenet (accessed on 18 July 2023).
- Viswakumar, A.; Rajagopalan, V.; Ray, T.; Parimi, C. Human gait analysis using OpenPose. In Proceedings of the 2019 Fifth International Conference on Image Information Processing (ICIIP 2019), Shimla, India, 15–17 November 2019; pp. 310–314. [Google Scholar]
- D’Antonio, E.; Taborri, J.; Mileti, I.; Rossi, S.; Patané, F. Validation of a 3D markerless system for gait analysis based on OpenPose and two RGB webcams. IEEE Sens. J. 2021, 21, 17064–17075. [Google Scholar] [CrossRef]
- Dai, Y.; Wu, J.; Fan, Y.; Wang, J.; Niu, J.; Gu, F.; Shen, S. MSEva: A musculoskeletal rehabilitation evaluation system based on EMG signals. ACM Trans. Sens. Netw. 2022, 19, 1–23. [Google Scholar] [CrossRef]
- Tack, C. Artificial intelligence and machine learning|applications in musculoskeletal physiotherapy. Musculoskelet. Sci. Pract. 2019, 39, 164–169. [Google Scholar] [CrossRef] [PubMed]
- Bavan, L.; Surmacz, K.; Beard, D.; Mellon, S.; Rees, J. Adherence monitoring of rehabilitation exercise with inertial sensors: A clinical validation study. Gait Posture 2019, 70, 211–217. [Google Scholar] [CrossRef] [PubMed]
- Zhu, M.; Zhang, Z.; Hirdes, J.P.; Stolee, P. Using machine learning algorithms to guide rehabilitation planning for home care clients. BMC Med. Inform. Decis. Mak. 2007, 7, 41. [Google Scholar] [CrossRef]
- Vakanski, A.; Ferguson, J.M.; Lee, S. Mathematical modeling and evaluation of human motions in physical therapy using mixture density neural networks. J. Physiother. Phys. Rehabil. 2016, 1, 4. [Google Scholar]
- Islam, M.M.; Nooruddin, S.; Karray, F.; Muhammad, G. Human activity recognition using tools of convolutional neural net-works: A state of the art review, data sets, challenges, and future prospects. Comput. Biol. Med. 2022, 149, 106060. [Google Scholar] [CrossRef]
- Mangal, N.K.; Tiwari, A.K. A review of the evolution of scientific literature on technology-assisted approaches using RGB-D sensors for musculoskeletal health monitoring. Comput. Biol. Med. 2021, 132, 104316. [Google Scholar] [CrossRef] [PubMed]
- Kendall, A.; Grimes, M.; Cipolla, R. Posenet: A convolutional network for real-time 6-dof camera relocalization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV 2015), Washington, DC, USA, 7–13 December 2015; pp. 2938–2946. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q.; Van Der Maaten, K.Q. Weinberger, Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2018), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet, Rethinking Model Scaling for Convolutional Neural Net-works. In Proceedings of the International Conference on Machine Learning (ICML 2019), Long Beach, CA, USA, 10–15 June 2019; pp. 6105–6114. [Google Scholar]
- Dirgová Luptáková, I.; Kubovčík, M.; Pospíchal, J. Wearable sensor-based human activity recognition with transformer model. Sensors 2022, 22, 1911. [Google Scholar] [CrossRef] [PubMed]
- Vaughan, N.; Gabrys, B. Comparing and combining time series trajectories using dynamic time warping. Procedia Comput. Sci. 2016, 96, 465–474. [Google Scholar] [CrossRef]
- Obukhov, A.; Dedov, D.; Volkov, A.; Teselkin, D. Modeling of Nonlinear Dynamic Processes of Human Movement in Virtual Reality Based on Digital Shadows. Computation 2023, 11, 85. [Google Scholar] [CrossRef]
- Fasel, B.; Favre, J.; Chardonnens, J.; Gremion, G.; Aminian, K. An inertial sensor-based system for spatio-temporal analysis in classic cross-country skiing diagonal technique. J. Biomech. 2015, 48, 3199–3205. [Google Scholar] [CrossRef] [PubMed]
- Alfian, R.I.; Ma’arif, A.; Sunardi, S. Noise reduction in the accelerometer and gyroscope sensor with the Kalman filter algorithm. J. Robot. Control (JRC) 2021, 2, 180–189. [Google Scholar] [CrossRef]
- Labbe, R. Kalman and bayesian filters in python. Chap 2014, 7, 4. [Google Scholar]
- Yan, W.; Zhang, Q.; Wang, L.; Mao, Y.; Wang, A.; Zhao, C. A modified kalman filter for integrating the different rate data of gyros and accelerometers retrieved from android smartphones in the GNSS/IMU coupled navigation. Sensors 2020, 20, 5208. [Google Scholar] [CrossRef]
- Alatise, M.B.; Hancke, G.P. Pose estimation of a mobile robot based on fusion of IMU data and vision data using an extended Kalman filter. Sensors 2017, 17, 2164. [Google Scholar] [CrossRef]
- Pagnon, D.; Domalain, M.; Reveret, L. Pose2Sim: An end-to-end workflow for 3D markerless sports kinematics—Part 1: Robustness. Sensors 2021, 21, 6530. [Google Scholar] [CrossRef]
- Chen, M.; Duan, Z.; Lan, Z.; Yi, S. Scene reconstruction algorithm for unstructured weak-texture regions based on stereo vision. Appl. Sci. 2023, 13, 6407. [Google Scholar] [CrossRef]
- Obukhov, A.D.; Krasnyanskiy, M.N. Neural network method for automatic data generation in adaptive information systems. Neural Comput. Appl. 2021, 33, 15457–15479. [Google Scholar] [CrossRef]
- Mehta, S.; Rastegari, M. Mobilevit: Light-weight, general-purpose, and mobile-friendly vision transformer. arXiv 2021, arXiv:2110.02178. Available online: https://arxiv.org/pdf/2110.02178 (accessed on 16 July 2023).
- Liu, J.; Pu, J.; Sun, L.; He, Z. An approach to robust INS/UWB integrated positioning for autonomous indoor mobile robots. Sensors 2019, 19, 950. [Google Scholar] [CrossRef] [PubMed]
- Filippeschi, A.; Schmitz, N.; Miezal, M.; Bleser, G.; Ruffaldi, E.; Stricker, D. Survey of motion tracking methods based on inertial sensors: A focus on upper limb human motion. Sensors 2017, 17, 1257. [Google Scholar] [CrossRef] [PubMed]
- Tian, Q.; Salcic, Z.; Wang, K.I.K.; Pan, Y. A hybrid indoor localization and navigation system with map matching for pedestrians using smartphones. Sensors 2015, 15, 30759–30783. [Google Scholar] [CrossRef] [PubMed]
- Tsilomitrou, O.; Gkountas, K.; Evangeliou, N.; Dermatas, E. Wireless motion capture system for upper limb rehabilitation. Appl. Syst. Innov. 2021, 4, 14. [Google Scholar] [CrossRef]
- Zeng, Q.; Zheng, G.; Liu, Q. PE-DLS: A novel method for performing real-time full-body motion reconstruction in VR based on Vive trackers. Virtual Real. 2022, 26, 1391–1407. [Google Scholar] [CrossRef]
- Delamare, M.; Duval, F.; Boutteau, R. A new dataset of people flow in an industrial site with uwb and motion capture systems. Sensors 2020, 20, 4511. [Google Scholar] [CrossRef]
- Rapczyński, M.; Werner, P.; Handrich, S.; Al-Hamadi, A. A baseline for cross-database 3d human pose estimation. Sensors 2021, 21, 3769. [Google Scholar] [CrossRef] [PubMed]
- Morar, A.; Moldoveanu, A.; Mocanu, I.; Moldoveanu, F.; Radoi, I.E.; Asavei, V.; Butean, A. A comprehensive survey of indoor localization methods based on computer vision. Sensors 2020, 20, 2641. [Google Scholar] [CrossRef] [PubMed]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).