MLAM: Multi-Layer Attention Module for Radar Extrapolation Based on Spatiotemporal Sequence Neural Network


 and
and
Abstract
:1. Introduction
- We propose an improved cascaded dual attention module (CDAM) based on a self-attention module (SAM). CDAM can automatically adjust the feature weights of different positions in radar echo images and enhance the causal relationship between different features. Compared with other attention mechanisms, CDAM has a stronger ability to extract and abstract features. Therefore, it can enhance important details and slow down the blurring of extrapolated images.
- We combine the 3D convolutional block attention mechanism (3D-CBAM) and CDAM to propose a versatile MLAM. It strengthens the processing of key echo regions from a global perspective and grasps the trend of echoes.
- We design a new architecture so that the MLAM can be applied to ConvRNNs. Contrast experiments were conducted between ConvRNNs and ConvRNNs embedded with MLAMs. ConvRNNs with MLAMs achieve better results than standard ConvRNNs on radar echo datasets provided by the Hunan Meteorological Bureau and Hong Kong Observatory.
2. Background and Data
2.1. Background
2.1.1. ConvRNNs
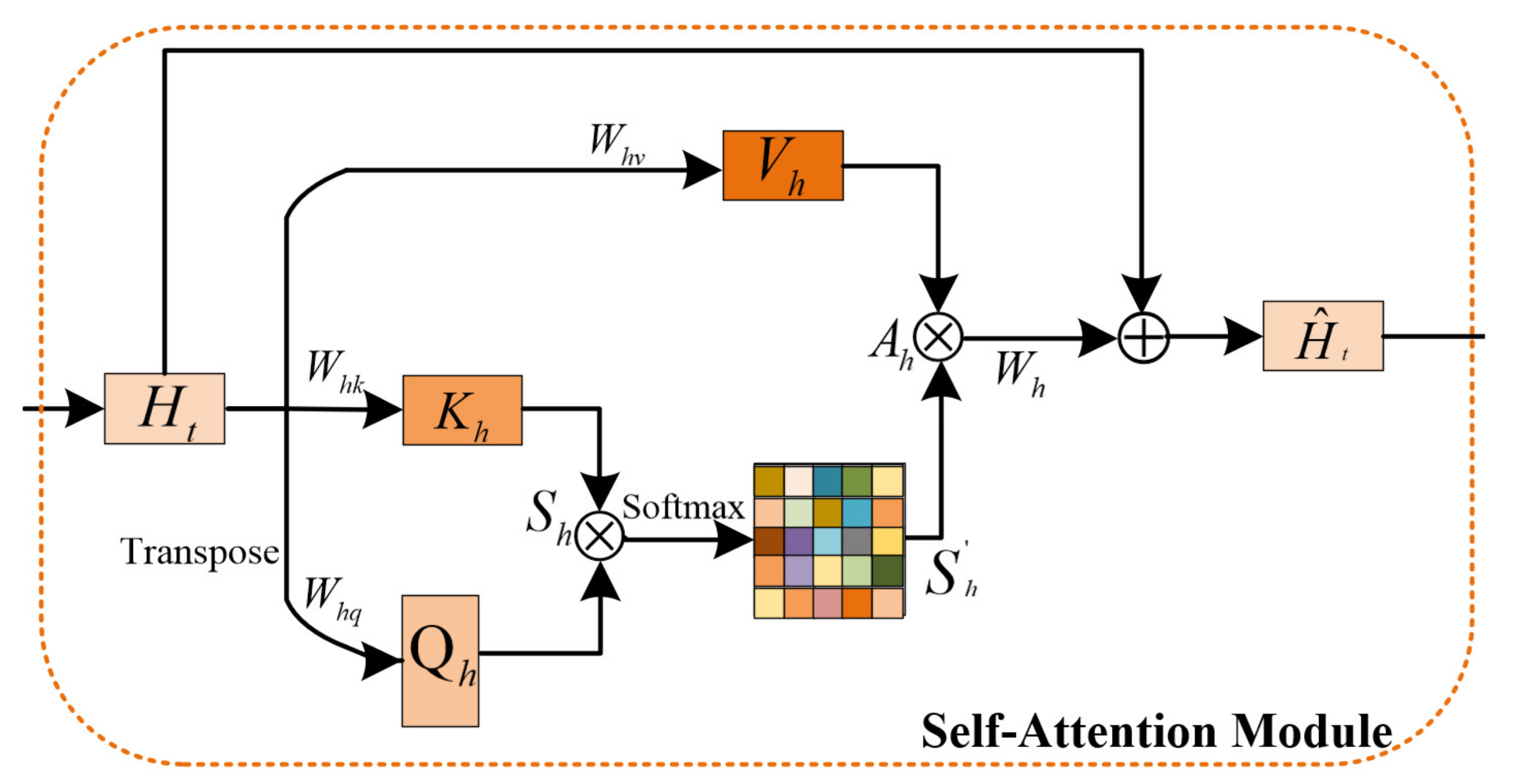
2.1.2. Self-Attention Module
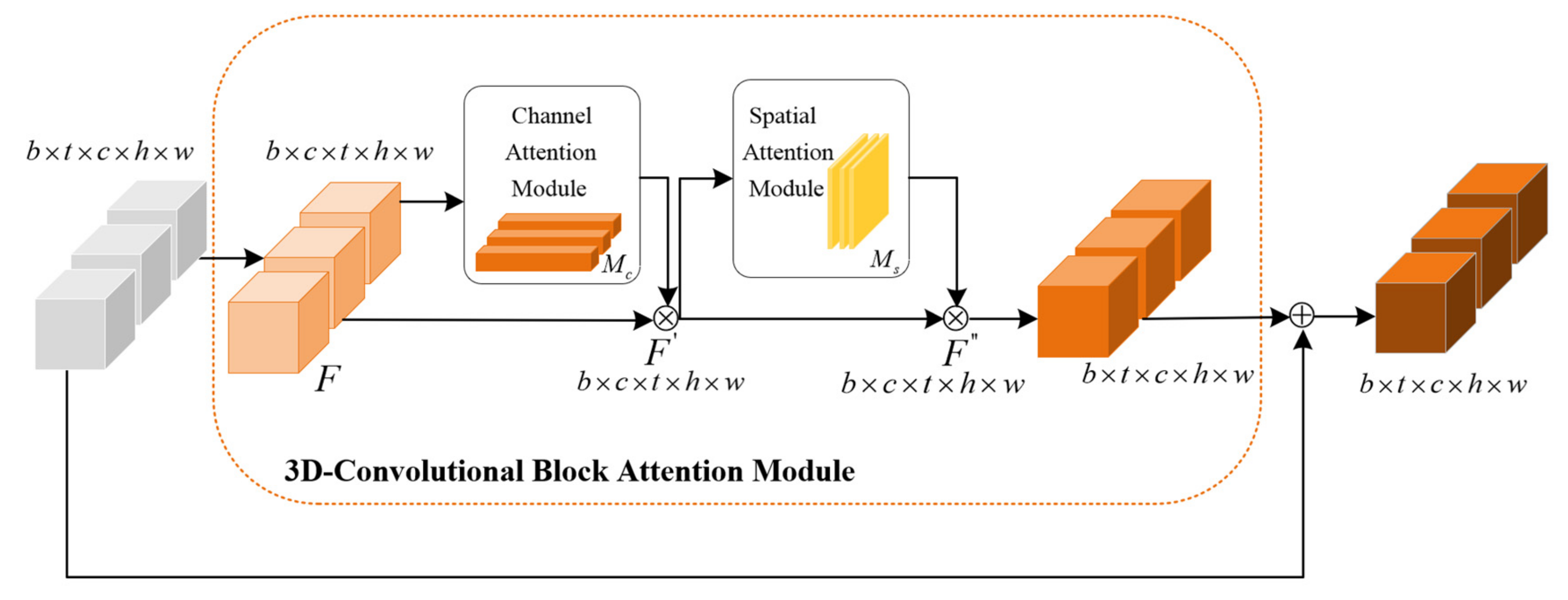
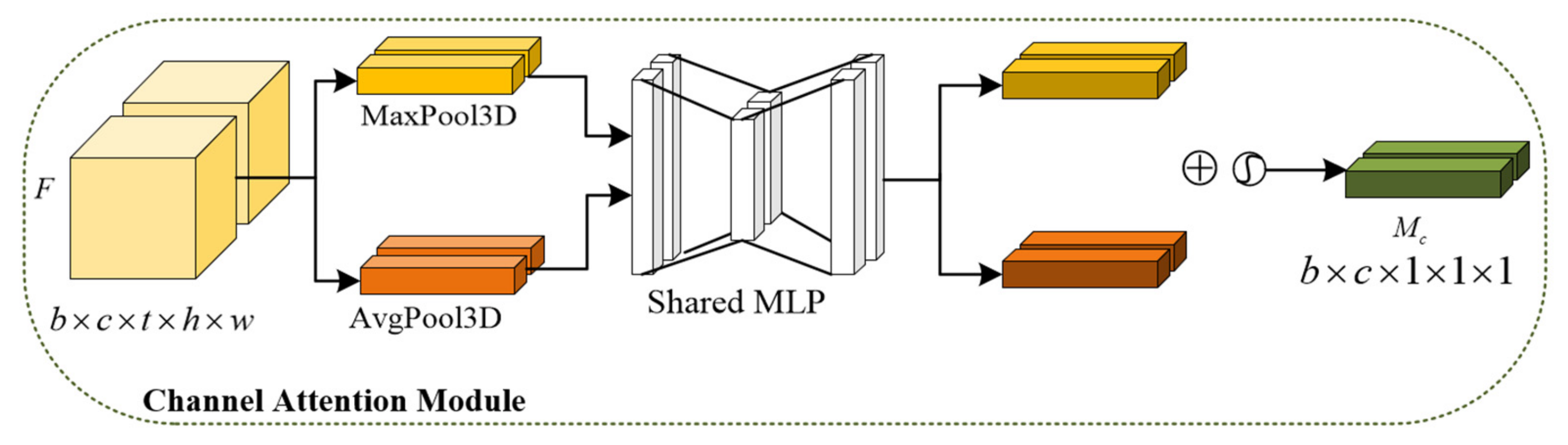
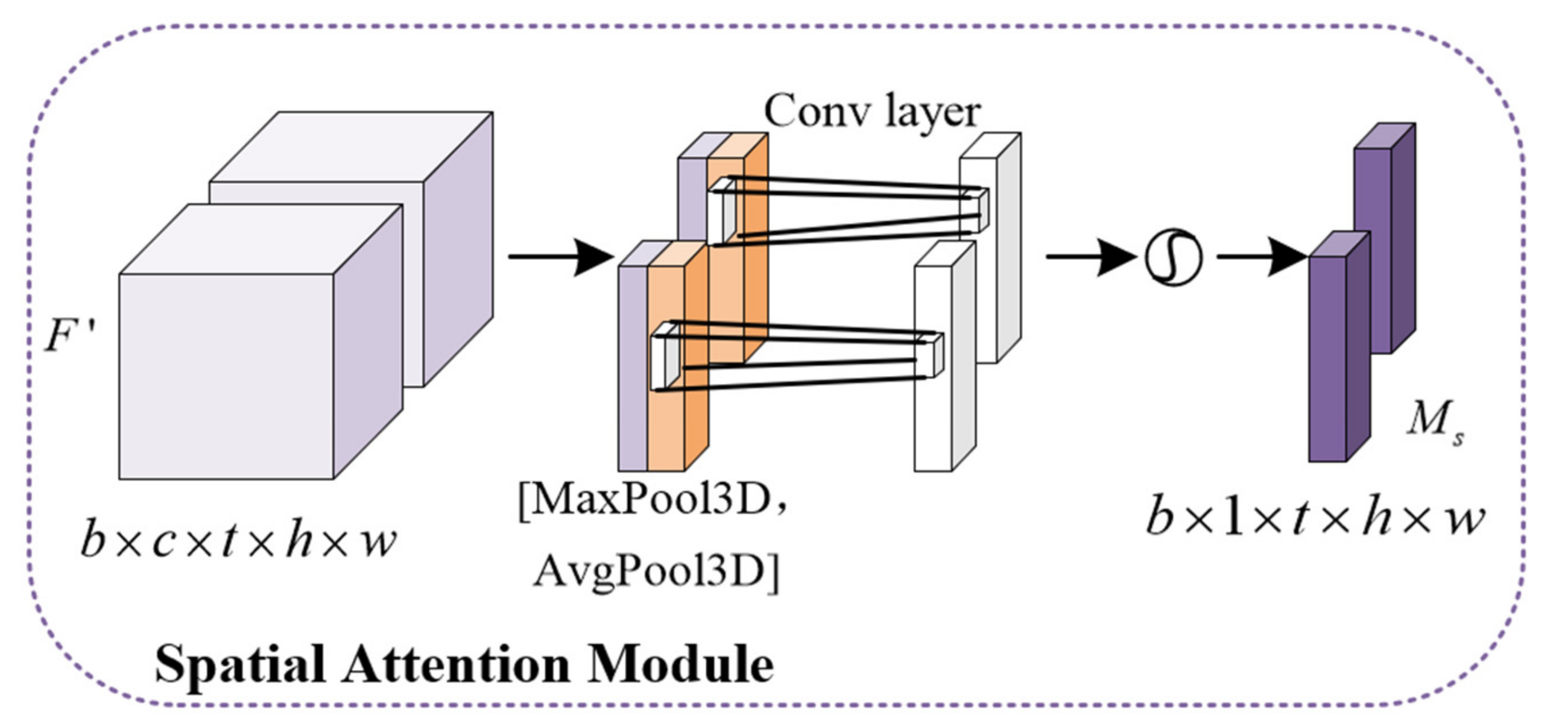
2.1.3. The 3D-Convolutional Block Attention Module
2.2. Data
2.2.1. Data Sources
2.2.2. Data Preparation
3. Proposed Method
3.1. Cascaded Dual Attention Module
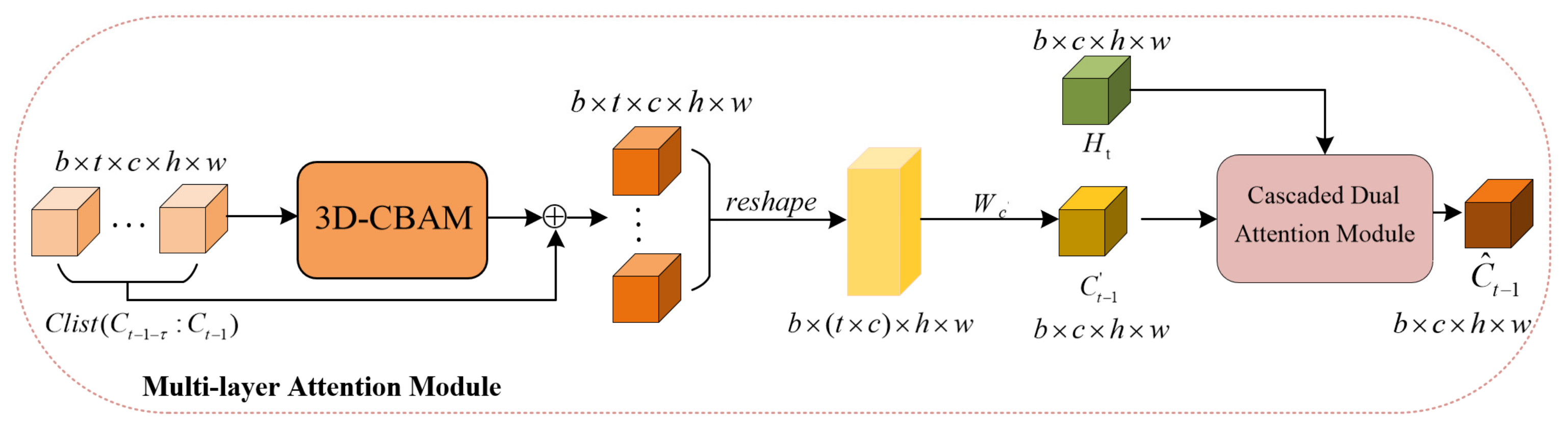
3.2. Multi-Layer Attention Module
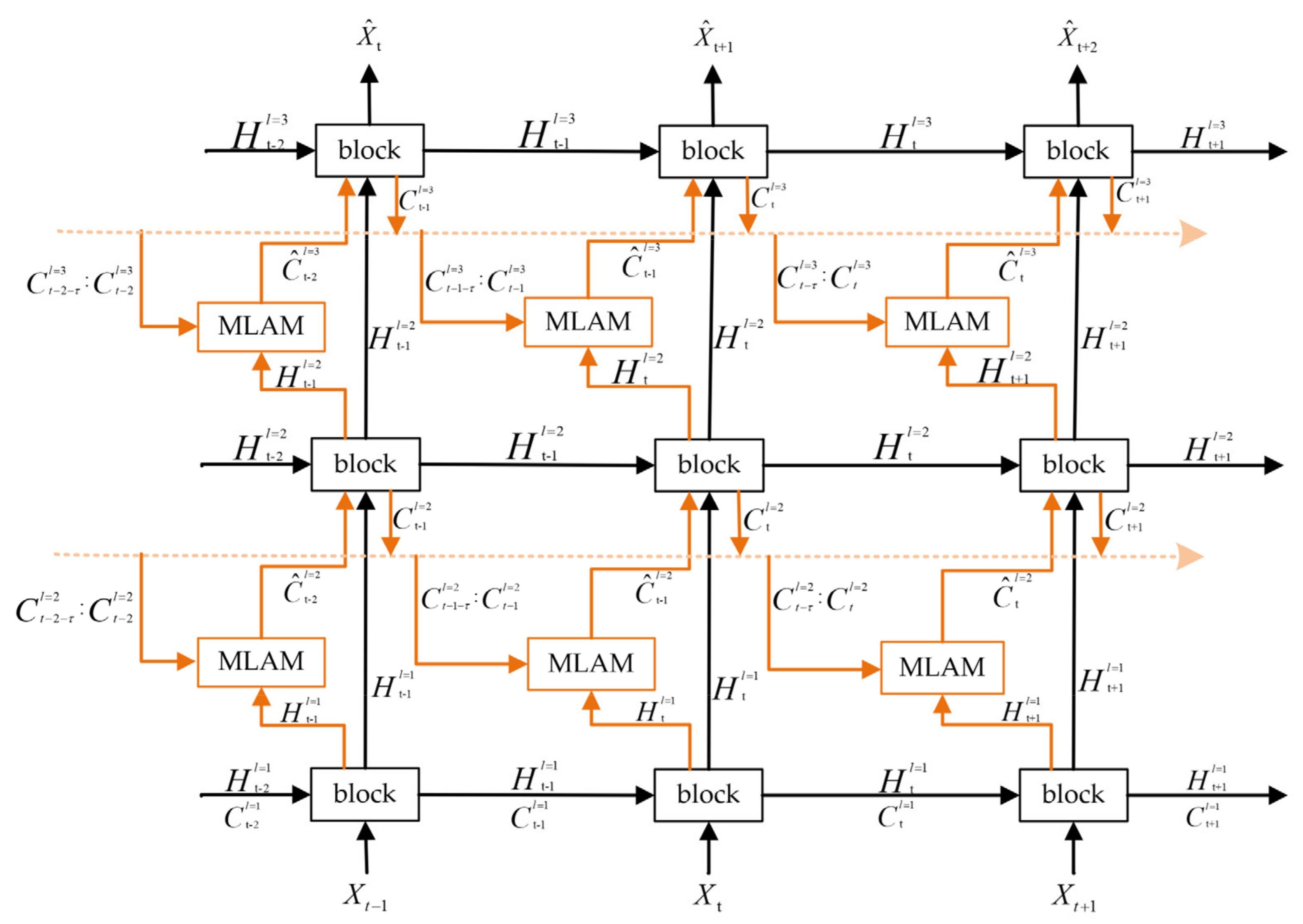
3.3. ConvRNNs with MLAM
4. Experiment
4.1. Experimental Settings
4.2. Evaluation Indicators
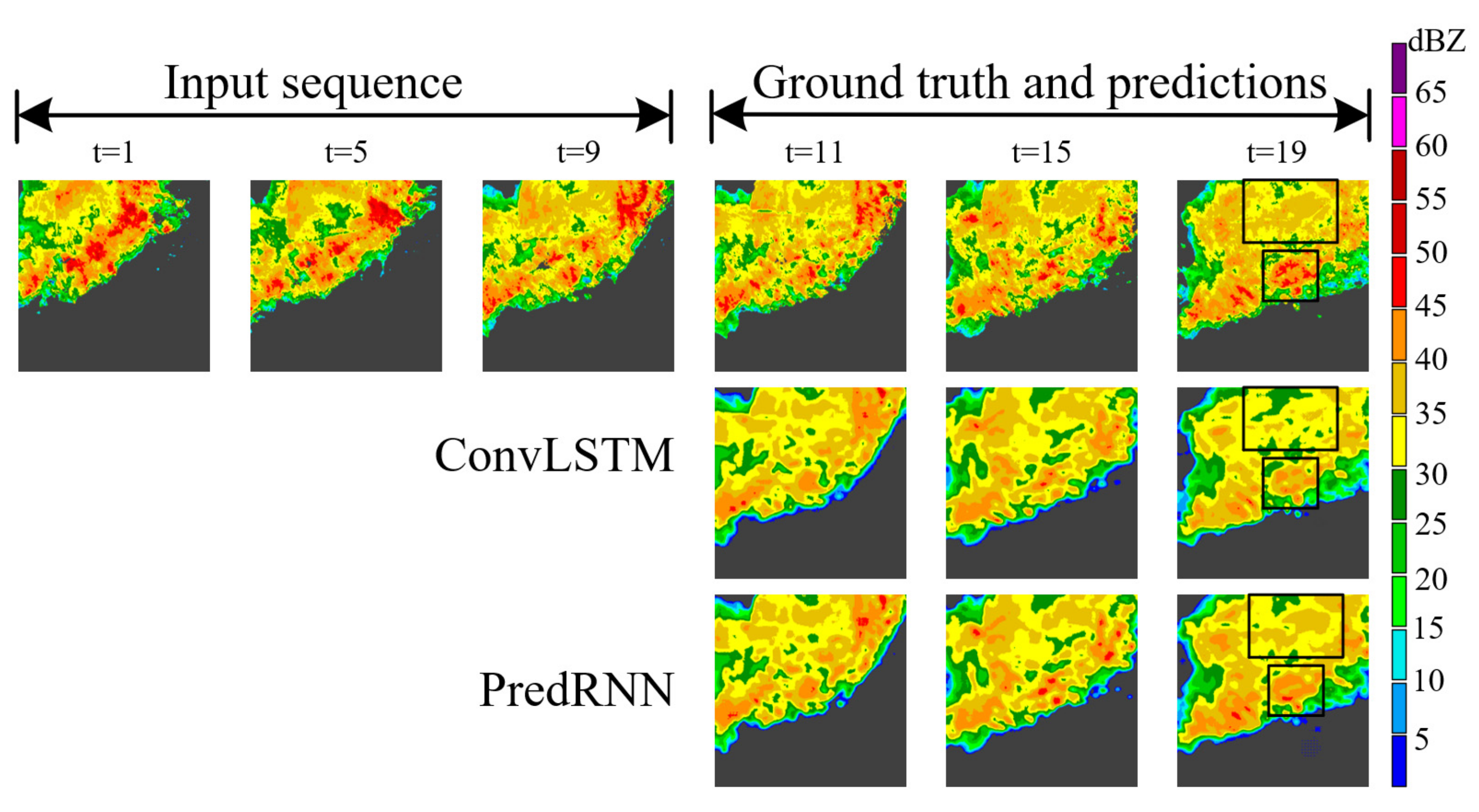
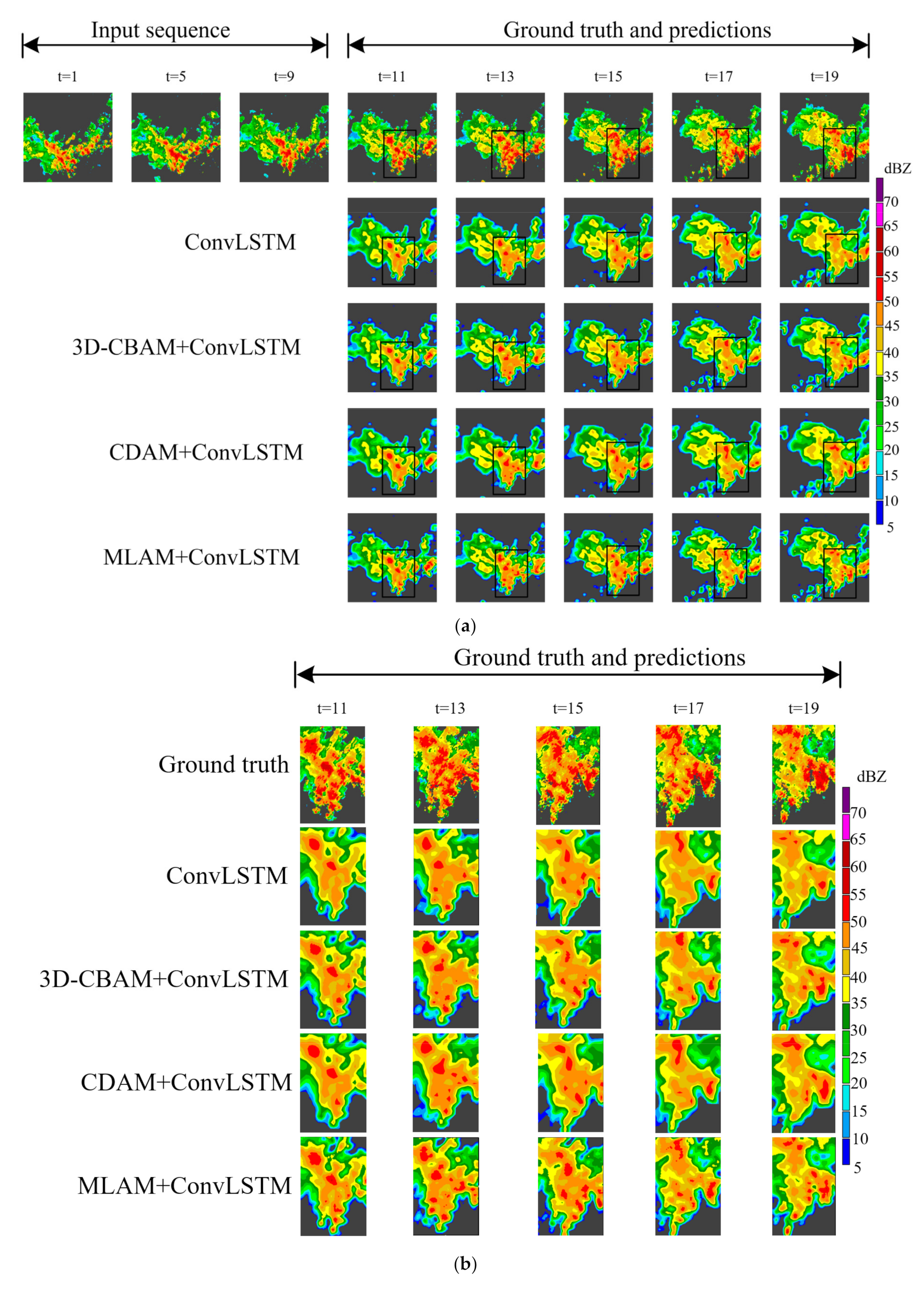
4.3. Comparative Study
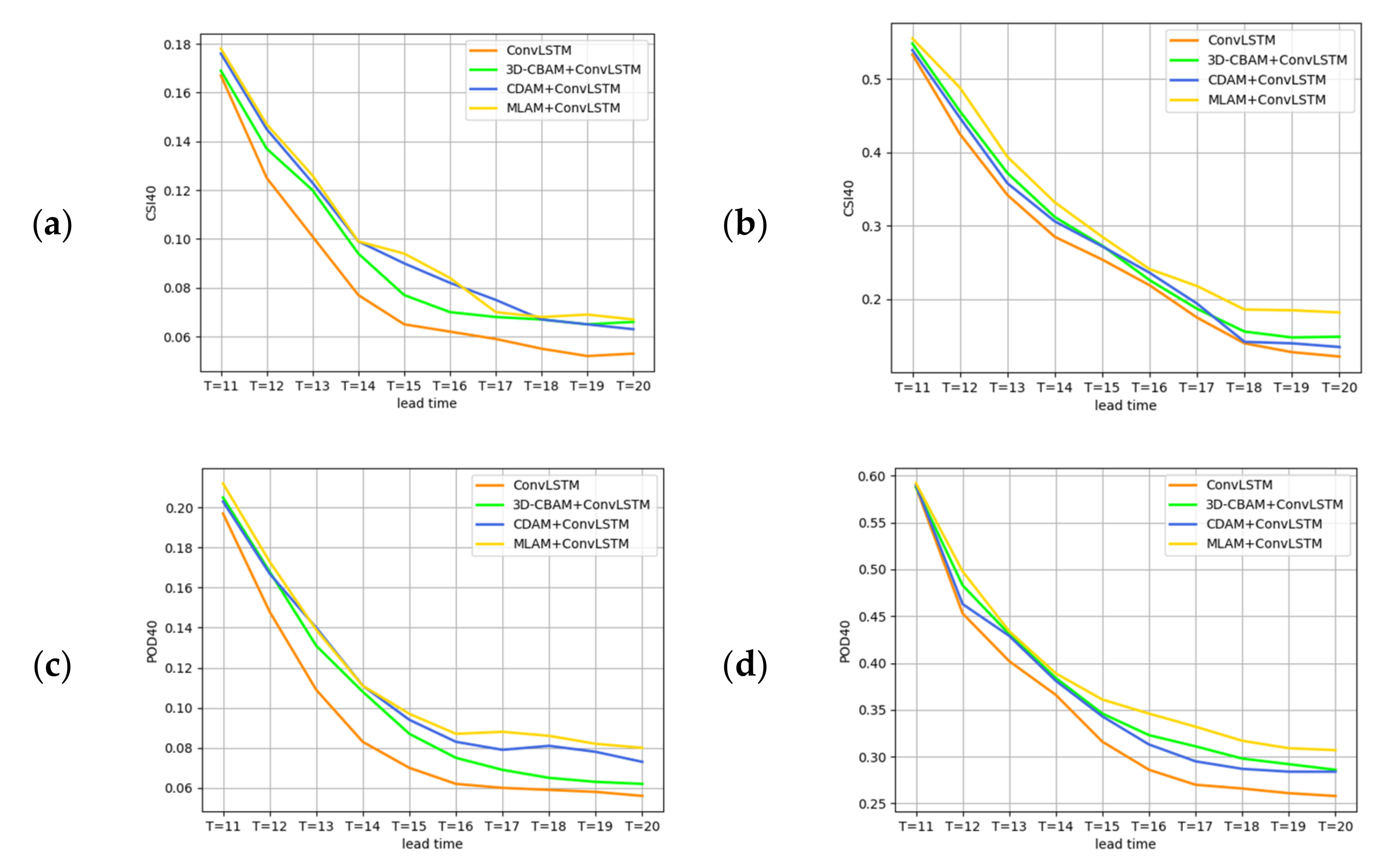
4.4. Ablation Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kusiak, A.; Wei, X.; Verma, A.; Roz, E. Modeling and prediction of rainfall using radar reflectivity data: A data-mining approach. IEEE Trans. Geosci. Remote Sens. 2012, 51, 2337–2342. [Google Scholar] [CrossRef]
- Tai, Q. Analysis of detection principle of dual-polarization weather radar. Sci. Technol. Vis. 2014, 17, 59. [Google Scholar]
- Li, L.; Schmid, W.; Joss, J. Nowcasting of motion and growth of precipitation with radar over a complex orography. J. Appl. Meteorol. Climatol. 1995, 34, 1286–1300. [Google Scholar] [CrossRef]
- Witt, A.; Johnson, J.T. An enhanced storm cell identification and tracking algorithm. In Proceedings of the 26th Conference on Radar Meteorology, Norman, OK, USA, 24–28 May 1993; American Meteorological Society: Boston, MA, USA, 1993; Volume 154, p. 156. [Google Scholar]
- Ayzel, G.; Heistermann, M.; Winterrath, T. Optical flow models as an open benchmark for radar-based precipitation nowcasting (rainymotion v0. 1). Geosci. Model Dev. 2019, 12, 1387–1402. [Google Scholar] [CrossRef]
- Seed, A.W.; Pierce, C.E.; Norman, K. Formulation and evaluation of a scale decomposition-based stochastic precipitation nowcast scheme. Water Resour. Res. 2013, 49, 6624–6641. [Google Scholar] [CrossRef]
- Pulkkinen, S.; Chandrasekar, V.; Niemi, T. Lagrangian Integro-Difference Equation Model for Precipitation Nowcasting. J. Atmos. Ocean. Technol. 2021, 38, 2125–2145. [Google Scholar]
- Liu, R. Overview of the basic principles of artificial neural networks. Comput. Prod. Circ. 2020, 6, 35. [Google Scholar]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Proceedings of the Conference on Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 802–810. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Agrawal, S.; Barrington, L.; Bromberg, C.; Burge, J.; Gazen, C.; Hickey, J. Machine learning for precipitation nowcasting from radar images. arXiv 2019, arXiv:1912.12132. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention, Proceedings of the MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Song, K.; Yang, G.; Wang, Q.; Xu, C.; Liu, J.; Liu, W.; Shi, C.; Wang, Y.; Zhang, G.; Yu, X.; et al. Deep learning prediction of incoming rainfalls: An operational service for the city of Beijing China. In Proceedings of the 2019 International Conference on Data Mining Workshops (ICDMW), Beijing, China, 8–11 November 2019; pp. 180–185. [Google Scholar]
- Trebing, K.; Staǹczyk, T.; Mehrkanoon, S. SmaAt-Unet: Precipitation nowcasting using a small attention-Unet architecture. Pattern Recognit. Lett. 2021, 145, 178–186. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer VISION (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Gao, Z.; Tan, C.; Wu, L.; Li, S.Z. Simvp: Simpler yet better video prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3170–3180. [Google Scholar]
- Wang, Y.; Long, M.; Wang, J.; Gao, Z.; Yu, P.S. Predrnn: Recurrent neural networks for predictive learning using spatiotemporal lstms. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; p. 30. [Google Scholar]
- Wang, Y.; Gao, Z.; Long, M.; Wang, J.; Yu, P.S. Predrnn++: Towards a resolution of the deep-in-time dilemma in spatiotemporal predictive learning. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 5123–5132. [Google Scholar]
- Wang, Y.; Zhang, J.; Zhu, H.; Long, M.; Wang, J.; Yu, P.S. Memory in memory: A predictive neural network for learning higher-order non-stationarity from spatiotemporal dynamics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9154–9162. [Google Scholar]
- Shi, X.; Gao, Z.; Lausen, L.; Wang, H.; Yeung, D.; Wong, W.; Woo, W. Deep learning for precipitation nowcasting: A benchmark and a new model. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; p. 30. [Google Scholar]
- Wang, Y.; Jiang, L.; Yang, M.H.; Li, L.-J.; Long, M.; Fei, L. Eidetic 3D LSTM: A model for video prediction and beyond. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Sun, N.; Zhou, Z.; Li, Q.; Jing, J. Three-Dimensional Gridded Radar Echo Extrapolation for Convective Storm Nowcasting Based on 3D-ConvLSTM Model. Remote Sens. 2022, 14, 4256. [Google Scholar]
- Wu, H.; Yao, Z.; Wang, J.; Long, M. MotionRNN: A flexible model for video prediction with spacetime-varying motions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15435–15444. [Google Scholar]
- Xu, Z.; Du, J.; Wang, J.; Jiang, C.; Ren, Y. Satellite image prediction relying on GAN and LSTM neural networks. In Proceedings of the ICC 2019—2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–6. [Google Scholar]
- Ravuri, S.; Lenc, K.; Willson, M.; Kangin, D.; Lam, R.; Mirowski, P.; Fitzsimons, M.; Athanassiadou, M.; Kashem, S.; Madge, S.; et al. Skilful precipitation nowcasting using deep generative models of radar. Nature 2021, 597, 672–677. [Google Scholar] [CrossRef] [PubMed]
- Lin, Z.; Li, M.; Zheng, Z.; Cheng, Y.; Yuan, C. Self-attention convlstm for spatiotemporal prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11531–11538. [Google Scholar]
- Luo, C.; Li, X.; Wen, Y.; Ye, Y.; Zhang, X. A novel LSTM model with interaction dual attention for radar echo extrapolation. Remote Sens. 2021, 13, 164. [Google Scholar] [CrossRef]
- Zhong, S.; Zeng, X.; Ling, Q.; Wen, Q.; Meng, W.; Feng, Y. Spatiotemporal convolutional LSTM for radar echo extrapolation. In Proceedings of the 2020 54th Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 1–4 November 2020; pp. 58–62. [Google Scholar]
- Yang, Z.; Ji, R.; Liu, Q.; Dai, F.; Zhang, Y.; Wu, Q.; Liu, X. An Improved LSTM-based Method Capturing Temporal Correlations and Using Attention Mechanism for Radar Echo Extrapolation. In Proceedings of the 2022 IEEE International Conference on Dependable, Autonomic and Secure Computing, International Conference on Pervasive Intelligence and Computing, International Conference on Cloud and Big Data Computing, International Conference on Cyber Science and Technology Congress (DASC/PiCom/CBDCom/CyberSciTech), Falerna, Italy, 12–15 September 2022; pp. 1–7. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; p. 30. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Rain Rate (mm/h) | |||
|---|---|---|---|---|
| HKO-7 | 97.09% | 1.35% | 1.14% | 0.42% |
| HMB | 66.19% | 20.27% | 9.56% | 3.96% |
| Dataset | Model | CSI ↑ | POD ↑ | SSIM ↑ | ||||
|---|---|---|---|---|---|---|---|---|
| 20 | 30 | 40 | 20 | 30 | 40 | |||
| (a) | ||||||||
| ConvLSTM [9] | 0.260 | 0.173 | 0.089 | 0.335 | 0.207 | 0.096 | 0.772 | |
| ConvGRU | 0.203 | 0.090 | 0.019 | 0.289 | 0.098 | 0.029 | 0.745 | |
| HKO-7 | PredRNN [18] | 0.317 | 0.191 | 0.097 | 0.405 | 0.214 | 0.123 | 0.802 |
| PredRNN++ [19] | 0.323 | 0.202 | 0.108 | 0.418 | 0.229 | 0.127 | 0.822 | |
| MotionRNN [24] | 0.351 | 0.242 | 0.143 | 0.463 | 0.277 | 0.154 | 0.843 | |
| MLAM+ConvLSTM | 0.298 | 0.194 | 0.102 | 0.386 | 0.254 | 0.121 | 0.777 | |
| MLAM+ConvGRU | 0.232 | 0.106 | 0.056 | 0.342 | 0.134 | 0.065 | 0.749 | |
| MLAM+PredRNN | 0.325 | 0.203 | 0.129 | 0.422 | 0.241 | 0.148 | 0.813 | |
| MLAM+PredRNN++ | 0.336 | 0.223 | 0.127 | 0.447 | 0.257 | 0.138 | 0.825 | |
| MLAM+MotionRNN | 0.357 | 0.251 | 0.153 | 0.476 | 0.290 | 0.166 | 0.844 | |
| ConvLSTM | 0.755 | 0.654 | 0.376 | 0.845 | 0.764 | 0.434 | 0.797 | |
| ConvGRU | 0.764 | 0.649 | 0.371 | 0.839 | 0.754 | 0.422 | 0.793 | |
| PredRNN | 0.771 | 0.663 | 0.354 | 0.884 | 0.777 | 0.486 | 0.868 | |
| HMB | PredRNN++ | 0.794 | 0.671 | 0.397 | 0.894 | 0.792 | 0.553 | 0.880 |
| MotionRNN | 0.764 | 0.651 | 0.388 | 0.874 | 0.783 | 0.464 | 0.875 | |
| MLAM+ConvLSTM | 0.778 | 0.668 | 0.411 | 0.863 | 0.789 | 0.467 | 0.811 | |
| MLAM+ConvGRU | 0.773 | 0.657 | 0.401 | 0.851 | 0.786 | 0.503 | 0.867 | |
| MLAM+PredRNN | 0.784 | 0.675 | 0.367 | 0.868 | 0.823 | 0.543 | 0.871 | |
| MLAM+PredRNN++ | 0.801 | 0.678 | 0.406 | 0.912 | 0.809 | 0.525 | 0.882 | |
| MLAM+MotionRNN | 0.787 | 0.656 | 0.432 | 0.897 | 0.794 | 0.502 | 0.893 | |
| (b) | ||||||||
| ConvLSTM | 0.222 | 0.140 | 0.082 | 0.299 | 0.165 | 0.090 | 0.739 | |
| ConvGRU | 0.171 | 0.068 | 0.015 | 0.240 | 0.074 | 0.025 | 0.683 | |
| HKO-7 | PredRNN | 0.255 | 0.167 | 0.096 | 0.350 | 0.197 | 0.106 | 0.740 |
| PredRNN++ | 0.263 | 0.171 | 0.096 | 0.360 | 0.202 | 0.106 | 0.748 | |
| MotionRNN | 0.301 | 0.217 | 0.130 | 0.420 | 0.256 | 0.143 | 0.746 | |
| MLAM+ConvLSTM | 0.248 | 0.169 | 0.101 | 0.355 | 0.211 | 0.116 | 0.748 | |
| MLAM+ConvGRU | 0.173 | 0.078 | 0.017 | 0.254 | 0.086 | 0.027 | 0.698 | |
| MLAM+PredRNN | 0.283 | 0.192 | 0.116 | 0.385 | 0.226 | 0.138 | 0.754 | |
| MLAM+PredRNN++ | 0.287 | 0.197 | 0.115 | 0.394 | 0.232 | 0.126 | 0.760 | |
| MLAM+MotionRNN | 0.305 | 0.218 | 0.136 | 0.422 | 0.261 | 0.152 | 0.758 | |
| ConvLSTM | 0.662 | 0.527 | 0.262 | 0.740 | 0.633 | 0.327 | 0.767 | |
| ConvGRU | 0.660 | 0.521 | 0.252 | 0.735 | 0.621 | 0.314 | 0.766 | |
| PredRNN | 0.670 | 0.522 | 0.258 | 0.757 | 0.656 | 0.403 | 0.787 | |
| HMB | PredRNN++ | 0.686 | 0.544 | 0.292 | 0.770 | 0.678 | 0.448 | 0.792 |
| MotionRNN | 0.666 | 0.536 | 0.285 | 0.748 | 0.645 | 0.360 | 0.829 | |
| MLAM+ConvLSTM | 0.675 | 0.547 | 0.308 | 0.748 | 0.648 | 0.389 | 0.784 | |
| MLAM+ConvGRU | 0.668 | 0.539 | 0.314 | 0.749 | 0.670 | 0.444 | 0.778 | |
| MLAM+PredRNN | 0.672 | 0.512 | 0.230 | 0.745 | 0.697 | 0.432 | 0.795 | |
| MLAM+PredRNN++ | 0.687 | 0.541 | 0.275 | 0.781 | 0.651 | 0.396 | 0.803 | |
| MLAM+MotionRNN | 0.684 | 0.562 | 0.329 | 0.761 | 0.666 | 0.415 | 0.841 | |
| Dataset | Model | CSI ↑ | POD ↑ | SSIM ↑ | ||||
|---|---|---|---|---|---|---|---|---|
| 20 | 30 | 40 | 20 | 30 | 40 | |||
| HKO-7 | ConvLSTM | 0.222 | 0.140 | 0.082 | 0.299 | 0.165 | 0.090 | 0.739 |
| 3D-CBAM+ConvLSTM | 0.236 | 0.159 | 0.093 | 0.339 | 0.189 | 0.103 | 0.743 | |
| CDAM+ConvLSTM | 0.246 | 0.165 | 0.099 | 0.350 | 0.206 | 0.111 | 0.743 | |
| MLAM+ConvLSTM | 0.248 | 0.169 | 0.101 | 0.355 | 0.211 | 0.116 | 0.748 | |
| HMB | ConvLSTM | 0.662 | 0.527 | 0.527 | 0.740 | 0.633 | 0.213 | 0.767 |
| 3D-CBAM+ConvLSTM | 0.668 | 0.531 | 0.531 | 0.772 | 0.672 | 0.237 | 0.780 | |
| CDAM+ConvLSTM | 0.671 | 0.541 | 0.541 | 0.750 | 0.648 | 0.212 | 0.777 | |
| MLAM+ConvLSTM | 0.675 | 0.547 | 0.547 | 0.748 | 0.648 | 0.203 | 0.784 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.; Wang, T.; Wang, S.; Fang, Z.; Huang, J.; Zhou, Z. MLAM: Multi-Layer Attention Module for Radar Extrapolation Based on Spatiotemporal Sequence Neural Network. Sensors 2023, 23, 8065. https://doi.org/10.3390/s23198065
Wang S, Wang T, Wang S, Fang Z, Huang J, Zhou Z. MLAM: Multi-Layer Attention Module for Radar Extrapolation Based on Spatiotemporal Sequence Neural Network. Sensors. 2023; 23(19):8065. https://doi.org/10.3390/s23198065
Chicago/Turabian StyleWang, Shengchun, Tianyang Wang, Sihong Wang, Zixiong Fang, Jingui Huang, and Zuxi Zhou. 2023. "MLAM: Multi-Layer Attention Module for Radar Extrapolation Based on Spatiotemporal Sequence Neural Network" Sensors 23, no. 19: 8065. https://doi.org/10.3390/s23198065
APA StyleWang, S., Wang, T., Wang, S., Fang, Z., Huang, J., & Zhou, Z. (2023). MLAM: Multi-Layer Attention Module for Radar Extrapolation Based on Spatiotemporal Sequence Neural Network. Sensors, 23(19), 8065. https://doi.org/10.3390/s23198065