Abstract
This article presents an automatic gaze-tracker system to assist in the detection of minimal hepatic encephalopathy by analyzing eye movements with machine learning tools. To record eye movements, we used video-oculography technology and developed automatic feature-extraction software as well as a machine learning algorithm to assist clinicians in the diagnosis. In order to validate the procedure, we selected a sample () of cirrhotic patients. Approximately half of them were diagnosed with minimal hepatic encephalopathy (MHE), a common neurological impairment in patients with liver disease. By using the actual gold standard, the Psychometric Hepatic Encephalopathy Score battery, PHES, patients were classified into two groups: cirrhotic patients with MHE and those without MHE. Eye movement tests were carried out on all participants. Using classical statistical concepts, we analyzed the significance of 150 eye movement features, and the most relevant (p-values ≤ 0.05) were selected for training machine learning algorithms. To summarize, while the PHES battery is a time-consuming exploration (between 25–40 min per patient), requiring expert training and not amenable to longitudinal analysis, the automatic video oculography is a simple test that takes between 7 and 10 min per patient and has a sensitivity and a specificity of 93%.
1. Introduction
Data analysis in the medical context has been usually based on classic statistics, but the emergence of high-throughput technologies and the need to incorporate them into decision making has provoked the incorporation of modern machine learning approaches. In fact, among the different domains in which machine learning (ML) is developed, healthcare has been pointed out as one of them due to its great impact on society and its possible development and application, as has been widely proven [1].
Nowadays, ML is starting to be applied in clinical practice for diagnosis. Using previous diagnosis, it is possible to train ML algorithms in order to improve diagnostic performance. Moreover, by applying ML to recorded data, it is also possible to predict the evolution of a disease or to prevent complications. ML algorithms have dealt with the scarcity of specialized doctors, the rejection of non-specialized doctors, and an increased use of unnecessary or inappropriate tests. Machine learning allows the generation of expert systems that, based on objective quantification of neurological tests from clinical examination, can improve the diagnostic capacity of non-specialized doctors and even support expert doctors in decision making. One of the most complex parts of the neurological examination is the evaluation of eye movement disorders. Routine clinical examination is insensitive to subtle abnormalities, and sometimes, the use of instrumental systems is required. Even with these systems, the interpretation of eye movement remains complex and requires significant expertise. Solutions to simplify the evaluation of eye movement disorders are highly desirable, and ML could potentially contribute to a better diagnostic and prognostic decision making.
Video-oculography is a well-known technique to analyze alterations in eye movements. There are three main methods to measure eye movements:
- 1.
- Scleral Search Coil (SSC). The transducer element is a contact lens with a coil that is physically attached to the pupil. Although it is considered the gold standard of measurement, the system is an invasive method that is uncomfortable for patients, and it must be handled by an expert [2].
- 2.
- Electro-oculography (EOG). The transducer element is a group of electrodes attached around the eyeball. The electrical potential generated by the muscles is recorded with electromyography devices. This technique was the most used until the last decade, even though noise signals are common [3].
- 3.
- Video-oculography (VOG). Here, one or more cameras record the eye movements, and gaze data are computed thanks to the processing of the images. Nowadays, this non-invasive technique is the most used [4,5], but this method needs to be standardized.
Due to technological advances, the measurements of eye movements and the objective quantification of some potential alterations arise as a rich source of information to improve diagnosis [6,7,8,9,10,11,12,13]. In spite of this, the available technology is not suitable for clinical practice because the results are difficult to understand, requiring time-consuming interventions of scarce experts as they are not related directly to a particular behavior of the brain disease. This limits the use of eye movement in research environments and decreases its implementation in routine clinical practice.
Recently, more evidence has arisen in the literature related to the sensitivity and sensibility of eye movement to assist in cognitive impairment by measuring eye movements [14,15,16,17]. Additionally, authors have experience in the development of devices for measuring eye movement [18,19], as well as in feature extraction and analysis in people affected by a neurological disease [20,21,22,23].
Minimal hepatic encephalopathy (MHE) is the earliest form of hepatic encephalopathy and can affect up to 80% of cirrhotic patients. By definition, it has no obvious clinical manifestation and is characterized by neurocognitive impairment in attention, vigilance, and integrative function [24]. The gold standard for the diagnosis of MHE is a time-consuming psychometric test called the Psychometric Hepatic Encephalopathy Score (PHES) [25,26] that must be corrected by the age and education level of the patient, and then highly specialized personnel are required to perform the PHES battery. As a consequence, MHE remains under-diagnosed because the current gold standard is not a reliable procedure to be used in clinical practice. Moreover, some studies reveal that the PHES battery is not sensitive enough to assess an early diagnosis [27,28,29], while eye movements can significantly improve the diagnosis [30].
The PHES is a battery of five psychometric tests—the digit symbol test (DST), the number connection test A (NCT-A), the number connection test B (NCT-B), the serial dotting test (SD), and the line tracing test (LTT)—which evaluates mainly mental processing speed, motor speed, attention, and visuo-spatial coordination. In spite of this consensus, the PHES battery has some drawbacks. In the last decade, different groups have realized that the PHES is not sensitive enough to detect all patients with mild cognitive and/or motor impairment. There is a population of cirrhotic patients who are classified as not having MHE by the PHES but show impaired performance in psychometric tests assessing certain neurological functions more specifically [27,28,29].
Therefore, there is a clear necessity to find new tools and procedures for the early detection of MHE in a feasible and reliable way in clinical settings.
New approaches include different physiological signal-processing methods, including cardiac and cerebral activity, thanks to the analysis of electrocardiogram (ECG) and electroencephalogram (EEG) signals. While [31] proposed a normalization and optimization of PHES thanks to EEG analysis, ref. [32] analyzed different parameters extracted from a P300 wave, obtaining statistically significant differences. Other approaches are focused on cardiac activity: Reference [33] built a deep learning model for the diagnosis of cirrhosis. Moreover, the diagnosis of hepatic encephalopathy in cirrhotic patients is also tackled with ML models trained with unbalanced data [34]. Most of these features are general demographic data.
This paper presents a novel approach to assist in the diagnosis of MHE in a clinical setting based on high-resolution eye movement measurements with VOG technology and machine learning techniques. The result is a reliable, non-invasive, and affordable medical tool to be applied in clinical settings.
The concept is sketched in Figure 1. After recording specific eye movements with an IR camera at 100 FPS, computer vision algorithms are used to obtain the position, velocity, and acceleration of the patient’s gaze. After computing the main features of the recorded signals, the most significant of them (p-value ≤ 0.05) are used to train ML algorithms. Finally, a PDF file report is sent back to the clinician with measured values and ML results.
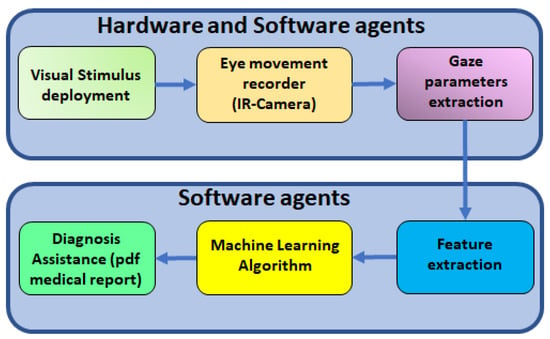
Figure 1.
Scheme of the ML concept applied to the diagnosis of cognitive impairment using an automatic video-oculography register.
In order to validate our proposal, we applied it to a group of patients with liver cirrhosis. Forty-seven cirrhotic patients were included, twenty-four of whom had been diagnosed with minimal hepatic encephalopathy (MHE). This particular impairment is common in 30 to of cirrhotic patients.
2. Materials and Methods
2.1. Material
2.1.1. Video-Oculography System
The gaze tracker used to measure eye movement is based on the VOG technique to record eye movement [18]. An infrared camera at 100 FPS is used to capture the movement of the dominant eye. A conventional chin rest is used to prevent head movements; then, a pure eye movement is measured. The chin rest is placed at 60 cm from the screen used to deploy visual stimulus. This is a typical setup in video-oculography systems [19,22,23,35,36]. The hardware consists of three key elements:
- Structural components, which are the body of the device. They are in charge of the correct fitting of the camera through two degrees of freedom.
- Fixation components, which prevent head movements during tests. Patients may place their heads on the forehead and chin rest.
- Recording components, which include the camera, infrared LEDs, hot mirror, and both monitors. To ensure eye recording and the use of infrared light while patients are undergoing tests, a hot mirror allows the reflection of IR light and data recording, while patients can follow stimuli on the monitor through it thanks to its characteristic transparency.
Table 1 shows the technical characteristics of the measurement.

Table 1.
Gaze-tracker’s technical properties.
The Human–Machine Interface (HMI) is a relevant element of this system. This platform has two HMIs deployed on two screens. One of them is used to show visual stimuli according to medical protocol. This screen is 60 cm from the capture system. To ensure this monitor has a higher refreshing rate than the human sampling rate (60–80 Hz), the refreshing rate of the stimuli in the monitor is 120 Hz.
The other screen is for medical use. Here, the technician can configure the video-oculography session and visualize the result of measurement. Moreover, the data acquisition process, video processing for pupil detection, and a “demo” version of each test are some of the main functionalities of this interface.
2.1.2. Patients
The current gold standard for MHE diagnosis is a battery of psychometric tests called PHES (Psychometric Hepatic Encephalopathy Score) [25,26]. PHES comprises a battery of 5 psychometric tests: digit symbol test (DST), number connection test A (NCT-A), number connection test B (NCT-B), serial dotting test (SD), and the line tracing test (LTT) [25]. DST test evaluates processing speed and working memory, NCT-A and NCT-B evaluate mental processing speed and attention, and SD and LTT are related to visuospatial coordination.
The global PHES scores were calculated with Spanish normality tables (http://www.redeh.org/phesapp/datos.html (accessed on 20 September 2023)) adjusted for age and education level. Patients were defined as having an MHE with a points [25].
This battery is time-consuming, requires expert personnel, and needs manual correction according to age and education [37].
In order to demonstrate how artificial intelligence could be a powerful tool to assist in the diagnosis of a particular disease, we selected a group of patients with liver cirrhosis. Between 30 and 70% of cirrhosis patients suffer a subtle cognitive defect known as minimal hepatic encephalopathy (MHE). This impairment brings a poor quality of life, poor driving performance, and increased mortality. Nevertheless, there are efficient treatments that can reverse symptoms. For these reasons, an early diagnosis is critical for this group of patients [38].
Forty-seven age-matched cirrhotic patients were selected. PHES battery and ocular movement tests were performed on the group. Based on the PHES battery results (Table 2), patients were classified into two groups: twenty-three cirrhotic patients without MHE and twenty-four cirrhotic patients with MHE.
Table 2.
Characteristics of patients in the study and classification according to PHES score. Values are expressed as mean ± SEM.
2.2. Methods
In this section, we present a brief description related to the steps followed to analyze the data. Details are explained in depth in Section 2.2.2.
Figure 2 shows the procedure to find alterations of ocular movements in cirrhotic patients. The first step is to record ocular movements according to medical protocol; then, OSCANN’s software provides a wide list of features that should be carefully analyzed. The reader is referred to [35] for a full description of the internal process in OSCANN’s software. In order to obtain those typical alterations of eye movement in cirrhotic patients, we performed two different analyses in the Matlab environment (see Figure 2). Initially, we separated variables into parametric and non-parametric using the Shapiro–Wilk test (S-W). If the feature is parametric, p-value is computed through the ANOVA test and through Kruskal–Wallis in the other case.
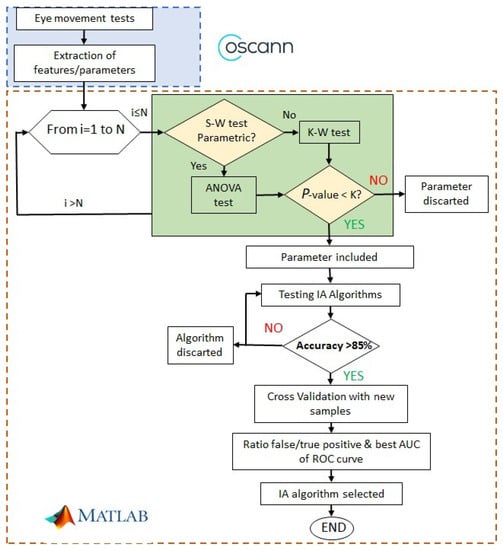
Figure 2.
Process followed to select significant features and machine learning algorithms.
If the p-value < 0.01, then the features are considered with potential significance to be included in the machine learning algorithm. In other cases, the feature is discarded from the analysis.
After computing the p-value of each feature, we analyzed the accuracy of a group of machine learning algorithms. If it was higher than , we checked the ROC curve, more specifically, the area under the curve (AUC). That area represents a ratio between the true and false values. Finally, we selected the best AUC value and, consequently, the algorithm used to obtain it.
2.2.1. Data Acquisition and Preprocessing
All included patients performed the full battery of ocular movement tests selected by protocol [35]. This protocol was designed to characterize the ocular movements of voluntary participants with no previous cognitive impairment in order to establish a control group. In this case, the biomedical procedure established the following steps:
- Revision of the patient’s condition.
- 1.
- PHES evaluation and clinical diagnosis.
- 2.
- Participants are asked to remove make-up and any kind of lenses before the ocular movement tests in order to guarantee the precision and accuracy of the eye-tracking algorithm.
- Ocular movement tests: Each test must be clearly explained to the patient, and there is a demo version available if needed.
- 1.
- Visually guided saccades tests (VGST).
- 2.
- Antisaccades tests (AST).
- 3.
- Memory-guided saccades tests (MGST).
- 4.
- Smooth pursuit tests (SPT).
- 5.
- Fixation test (FIXT).
Each participant in the experiment followed this protocol based on the analysis and design of a group of specialists that tried to guarantee the attention of the participant. A simple test, VGST, is used to present the experiment. Then, the most difficult tests are captured (AST and MGST), and, finally, the easiest ones are presented to complete the ocular movement experiment.
In order to obtain an accurate ocular movement measurement, the patient’s head must remain fixed; a conventional chin rest is used. The system offers twenty-three different ocular movement tests, but according to the study design following the previous literature and feasibility criteria, cirrhotic patients carried out horizontal and vertical saccadic paradigms (visually guided saccades, memory-guided saccades, and antisaccades) without a gap or overlap and a horizontal and vertical smooth pursuit test. Furthermore, all patients performed a fixation test.
The visual stimulus is a green dot (diameter = 1 cm) deployed on a black background. In each position, the stimulus remains for 1500 ms in each position.
As mentioned previously, the saccadic paradigm includes three tests and each one is performed in the horizontal and vertical directions. Here, eye movements are guided by one stimulus, which appears in the centre of the screen and then moves randomly to the left or right position (horizontal test) or the up or down position (vertical test).
In the visually guided saccades test (VGST), the instruction to the patient is to look at the green dot. The visual stimulus performance is shown in Figure 3.
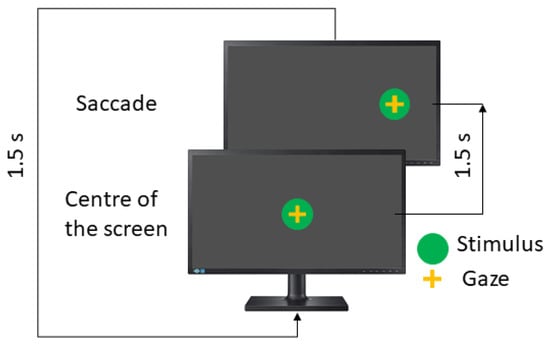
Figure 3.
Visual saccades test.
In the antisaccades test (AST), the patient is asked to look in the opposite direction to the stimulus, such as a mirror. Here, the instruction to the patient is to look to the opposite side of the green dot. Figure 4 shows the concept.
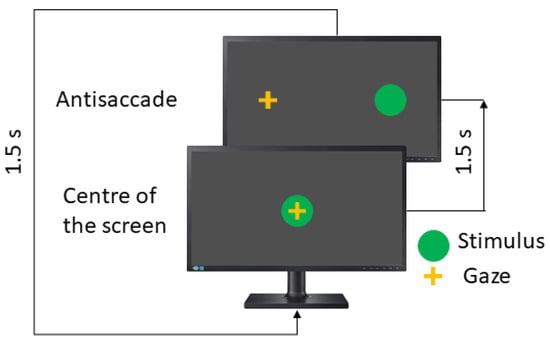
Figure 4.
Visual antisaccades test.
The memory-guided saccades test (MGST) is the longest test in the saccadic paradigms. Here, the stimulus appears in a particular position, remains there for 1500 ms, and then comes back to the screen’s center and disappears. The patient must remember the stimulus position and then perform a saccadic movement toward that. The user has an extra 1500 ms; for this reason, this test takes double the time (see Figure 5).
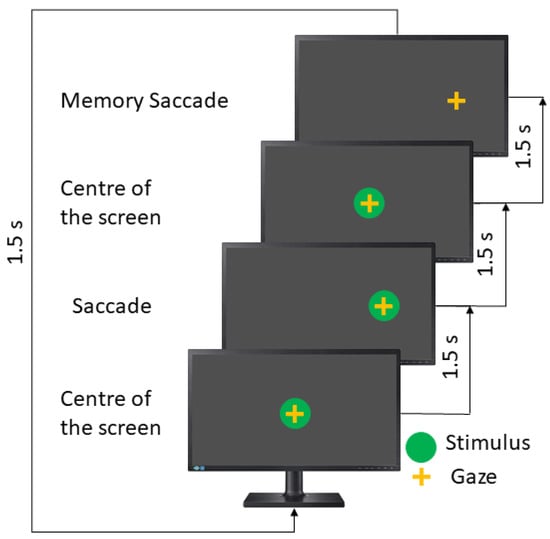
Figure 5.
Memory saccades test.
In this test, the instruction to the patient is to remember the position of the last stimulus and move your eyes toward it.
Table 3 describes the recommended parameters. The visually guided saccades and antisaccade take 36 s and 24 s in the horizontal and vertical directions, respectively, while the memory-guided saccades test takes double the time.
Table 3.
Default parameter for Saccadic Paradigm.
The Smooth Pursuit test (SPT) is also performed in the horizontal and vertical directions, and the stimulus moves following a linear wave. The recommended parameters are summarized in Table 4. In linear smooth pursuit, the explored visual field is , while velocity remains constant and each lap takes 8 s (see Figure 6).
Table 4.
Default parameters for Smooth Pursuit test.
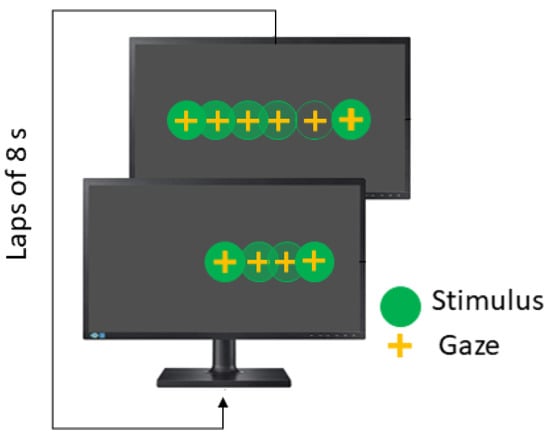
Figure 6.
Horizontal smooth pursuit test.
Finally, in the fixation test (FIXT), the stimulus remains in the screen’s center for five seconds. The objective of this test is to measure involuntary eye movements such as microsaccades, drifts or square ware jerks, and distractions.
After data acquisition is completed, videos have to be pre-processed in order to compute the position, velocity, and acceleration of the subject’s pupil. Consequently, the patient’s gaze is determined and, and test performance can be analyzed properly.
Before explaining the next steps in our algorithm, it is necessary to focus on the way cirrhotic patients perform eye movement tests. This circumstance is identified due to the inability to obtain data from all tests. Specifically, this problem shows up with bad eye movement recording due to eye morphology; for example, fallen eyelid impairments cause the impossibility of detecting a patient’s line of sight correctly.
Another common situation is patients who could not collaborate in performing all tests because of fatigue, stress, or nervousness. However, this is not the case for cirrhotic patients, since the patients collaborated and the environment where the tests were performed was quiet and comfortable. Then, all patients completed the eye movement tests.
In Section 3, there are more details on the number of patients who have missing tests.
2.2.2. Data Analysis
Before the classification task can be carried out, data analysis process is needed in two distinct phases. On the one hand, feature extraction from ocular movement registration is the first step. On the other hand, the most significant features have to be selected in order to train machine learning algorithms. Therefore, finding the best combination of features allows the best possible classification results to be obtained.
Prioritizing this objective, two theoretical methods are proposed: while signal theory is used for computing features, statistical theory is used for selecting significant features.
Feature extraction process
By analyzing the signal generated as a response to the visual stimulus, it is possible to define the features of the eye movement [9]. From each visual test, different features are computed, and then more than 150 features are evaluated.
In VGST, features such as response time or latency toward the stimulus and latency back toward the center of the screen, mean velocity and velocity peaks, accuracy (dysmetria), and the account of the number of blinks or anticipated saccades (the ones too fast made before 80 milliseconds after the stimulus changes) are examples of variables that are measured [39].
In MGST, the account of the number of correct memory saccades, together with visual saccades features, are evaluated in this test. Features such as latencies, accuracy, or velocity features are assessed on the memory saccades.
In AST, when the patient looks in the opposite direction to the stimulus directly, these saccadic movements are considered to constitute correct antisaccade performance. If the patient performs a saccade movement to look at the stimulus and then to look in the opposite direction, these saccade movements are considered “reflexive” saccades, but if they do not look in the opposite direction, there will be an incorrect antisaccade [39]. In this test, other features are measured like in the two previous cases.
In FIXT, as mentioned before, the account of saccades, microsaccades, drifts, square ware jerks, and distractions are measured. Also, different characteristics of each type of micromovement are computed [7,40].
In SPT, it is important to care about the account of catch-up saccades, which are performed by the patient to achieve the stimulus when the gaze is lagging behind it, and back-up saccades, which are performed in the opposite direction of the movement of the stimulus when the gaze is ahead [6]. In addition, some indices related to the time following the stimulus or errors of performance are measured [41].
Finally, Table 5 summarizes the number of features extracted from each test used in this study.
Table 5.
Number of features extracted in each test.
Significance analysis
After processing feature extraction, the significance of each ocular movement feature is assessed using classical statistics. First, the normality of each feature must be tested (see Figure 2) to properly generate p-values. According to the number of samples (), the Shapiro–Wilk (SW) test is one of the most suitable methods to evaluate the features’ normality [42,43]. Regardless of this, in [44], it is also stated that the SW test can be used with sample sets with more than hundreds or thousands of samples. A second validation of the features’ normality was made using Lilliefors (LF) in order to guarantee feature significance with both methods.
The second step is to obtain the measure of the significance of each feature. To accomplish this, the p-value of each variable is computed for assessing the rejection of the null hypothesis. After features were classified as parametric or non-parametric variables, the p-values were computed, and just those variables with p-values less than or equal to , , and were included in the following steps.
- A one-way analysis of variance (ANOVA) test was used for parametric features in a lot of fields of medicine such as cancer [45] or mammogram mass classification [46], biological data analysis [47], etc. As another parametric test, ANOVA starts from the assumption that the data set fits normally distributed data. This test is a simple case of the linear regression model.
- For nonparametric variables, the Kruskal–Wallis (KW) test is used [48]. This test is equivalent to ANOVA. In KW, it is not assumed that data obey a particular distribution, and then the normality of data set is not supposed. Furthermore, in [49], it is demonstrated that KW is suitable for a sample set size like the one used in this article.
2.2.3. Classification Algorithm and Validation
The MATLAB™application Classification Learner provides a useful tool for training multiple classification algorithms, including parameter variations for a specific algorithm. Therefore, it is a powerful tool to easily test all these algorithms in order to select them properly.
For instance, in the case of the well-known Supported Vector Machine algorithm (SVM), linear, quadratic, cubic, and Gaussian kernel functions are available for testing. The SVM classification algorithm has demonstrated very useful qualities such as speed, efficiency, and robustness, which are extremely important for classification tasks [50,51,52].
The best classifiers were selected depending on the accuracy, area under the ROC curve (AUC) [53], and the number of features used. After that, cross-validation was performed using five folds or subsets. One of these folds, which corresponds to 20% of the available samples, was used for testing, while the remaining four were used for training. The samples of each class were equally divided into the different folds.
In this study, we used the cross-validation method where the data set is aleatory, divided into five subsets following a stratified k-fold division strategy. In order to compute the significance and statistical accuracy of the procedure, the selected classifier algorithm was executed 1000 times in an iterative loop, which corresponds with the two last stages shown in the flowchart of Figure 2. All result metrics are computed as the mean value of the errors in each iteration; Figure 7a,b also shows the distribution over these iterations.
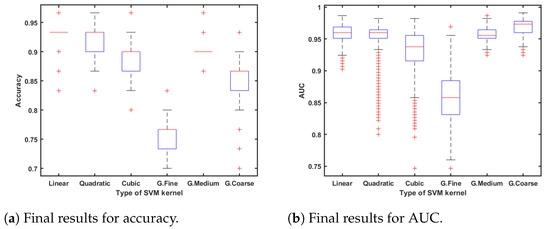
Figure 7.
Statistical classification results.
Therefore, the training data set and test data set are statistically evaluated. Moreover, the probability of belonging to one of both classes is calculated via predicted class scores [54]. This metric allows us to know if a sample is in the borderline between sets or, even worse, if it is classified in the wrong set.
3. Results
The main results of this work are related to the computation of classification algorithms to train and validate SVM classifiers. A few samples were excluded because some of them had missing values in some tests; a full description is included at the end of this section. Section 4 provides details about how to deal with this typical situation in patients with cognitive impairment.
The Classification Learner App provides very useful information about the best algorithm to make the classification task. Table 6 summarizes the results of the best algorithms.
Table 6.
Best accuracy results for each classification algorithm.
First, the SVM algorithm behaved better than the others, so different kernel functions were computed to know the best way to perform the classification task. Figure 7a,b show the results of this classification study; statistical values of accuracy and AUC are shown as the results of 1000 iterations.
As observed in Figure 7a,b, linear SVM has the best results due to its statistical values in accuracy and AUC. In addition, for a larger detail of the results, scores were computed as the distance to decision boundaries. After that, the probabilities of belonging to a group were compared. Table 7 indicates the score results.
Table 7.
Mean scores and posterior probabilities after 1000 iterations.
The sigmoid function used to make the transformation of scores to posterior probabilities is represented in Figure 8a, where the slope parameter was and the intercept parameter was .
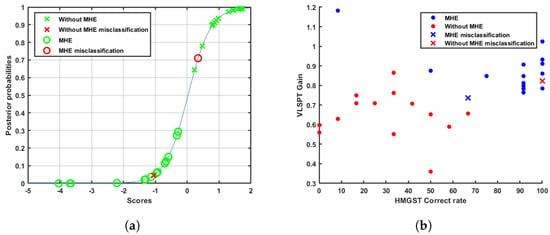
Figure 8.
Examples of sample separation. (a) Representation of sigmoid function and patients. (b) Scatter plot. Patient-discrimination example.
According to the classification results, the data engineering process was successful thanks to the large amount of significant ocular features. By applying the methodology described above (Section 2.2), Table 8 summarizes the p-value threshold computed for each feature.
Table 8.
Significance features of each test.
Then, by considering the p-values threshold, there were fourteen features with significant values to discriminate between two groups. These features belonged mainly to memory-guided saccades, antisaccades, and linear smooth pursuit tests, while features from the visually guided saccades test and fixation test are less significant than the first ones. Table 9 presents the measured statistical values expressed as mean value ± standard deviation (SD) for both patient groups and their associated p-values.
Table 9.
Values of significance of ocular movements.
Finally, missing values in cirrhotic patients appeared as one feature to consider. Table 10 shows the number of patients in each group of cirrhotic patients that have missing values. Section 4 discusses the convenience of being able to include these patients in the classification task.
Table 10.
Data set. Selection of the subset with full eye movement parameters.
4. Discussion
As established in the introduction section, this study attempts to address a problem concerning the clinical diagnosis of MHE in cirrhotic patients. Currently, this reversible manifestation is under-diagnosed due to the low specificity and sensitivity of its gold standard, the PHES. Furthermore, it is a time-consuming test with subjective nuances based on the age and education of the patient, which requires specialized personnel and makes its clinical practice difficult. In this study, we have focused on the use of eye-tracking technology for the evaluation of eye movement and some cognitive functions to detect this manifestation with better results than the gold standard.
According to the performance of the different classifiers, the linear SVM classification algorithm obtains the best results, as shown in Table 6. Furthermore, KNN and discriminant algorithms achieve at least 90% of maximum accuracy, so everything leads us to remark that the two different classes are clearly differentiated. Figure 8b illustrates how patients are discriminated against using the best two features indicated in Table 9. In this figure, colour represents each cirrhotic patient class while crosses mean misclassification. At this point, it is interesting to point out the great results obtained with linear SVM. This algorithm achieves, as is shown in Figure 7a, 0.935 of mean accuracy, which agrees with two misclassifications, one in each class. In addition, 0.959 mean AUC (Figure 7b) is remarkable, and even coarse Gaussian SVM improved it. This result remains an excellent performance, which ensures data separability.
In the same way, scores and posterior probability results point to visible distances between groups. However, even though twenty-eight out of thirty patients were classified properly, four of them show up within the limits of thresholds, as can be seen in Figure 8a. Numerical results appear in Table 7. Cases with a distance shorter than 0.5 are not considered completely differentiated, which allows them to be called atypical. We do not consider that the detection of complications should be closed categories. There are patients who are borderline that need to be detected and specifically managed. These cases have to be studied and will have more relevance when the number of patients in each group increases. Moreover, Figure 8b shows remarkable differences between classification errors in both classes. While the misclassified cirrhotic patient without MHE is within the limit of thresholds concerning atypical cases, the misclassified MHE patient shows explicit features typical of cirrhotic patients who do not have neurological complications.
According to the statistical correlation between both types of cirrhotic patients, the most significant tests (MGST, AST, and SPT) are the ones that assess cognitive functions such as working memory, inhibitory control, and the capacity to continuously focus their gaze to trace the stimulus position across the visual field. This evidence provides proof that this novel tool is able to detect the manifestation of cognitive impairment in MHE patients according to the previously reported symptoms [28,55,56,57,58]. Moreover, test duration has been reduced to at least a third compared to the current gold standard, which makes it available for better longitudinal analysis.
Concerning the reason why missing values appear in some patients, missing data could arise for many reasons:
- The patient feels uncomfortable with the device.
- The patient’s eye movement does not present some particular feature. For example, if there is no reflexive saccade in the antisaccade test, there would be an empty value for this feature.
- From a medical point of view, the presence of empty values in some measurements could indicate that some particular tasks would present greater difficulty. This difficulty could be associated with the presence of cognitive impairment to some degree. The fact that there are also empty values in the group of patients without MHE could be explained by the fact that there are patients who, although in the PHES and classified as without MHE, may present some cognitive alterations detectable with other more specific tests [28] that the eye-movement test would also detect.
Taking into account the previous comment, there are several reasons for empty values in the data set. Then, in this work, we studied the performance of different algorithms under this condition without considering the potential reasons for them. After looking for the best combination of patients, significant features, and non-missing values, the results show that the neurological evaluation through eye tracking is a promising tool to assist with the clinical diagnosis.
To conclude, the current methodology ensures complete repeatability of the results, as it includes the cross-validation technique. This stage was included due to the biggest limitation of this study, the number of data samples. From the beginning of this study, gathering patients with these cirrhotic manifestations has been the main issue as medical specialists should adapt to the use of the device, patients should be interested in the development of the eye tracking tasks, and the biomedical protocol should be followed to guarantee the highest quality of the samples. To achieve this, training sessions dedicated to each specialist were accomplished, as well as a continuous improvement in the protocols involved.
5. Conclusions
In this article, the first automatic video-oculography system to assist in the diagnosis of cognitive impairment in cirrhotic patients is presented. A group of patients with liver cirrhosis was selected. Around 50% of them were diagnosed with cognitive impairment using the medical gold standard, the PHES battery.
Cirrhotic patients carried out the ocular test with OSCANN desk 100. According to the visual tests performed, a set of features was computed and statistically evaluated. The most significant features were extracted from the memory-guided saccades test, the smooth pursuit test, and the antisaccades test. These features were used to train the ML classifier. The algorithm obtained has a sensitivity of 93% and a 93% specificity, which is better than the actual gold standard.
Taking into account the results and the limitations of our research, we plan to increase the sample size of both sets (cirrhotic patients with and without MHE diagnosis) in order to validate the aid to the diagnosis for the clinicians. The sample size of this work is limited but promising, improving the actual gold standard results. Moreover, the high decrease in test duration, its objectivity, and its simplicity make this inexpensive tool especially indicated for improving the help to the clinical diagnosis of this cognitive impairment.
Finally, it would be interesting to analyze the eye movement of patients with MHE under medical treatment to evaluate the effect of the drugs as well as the dose, in improving the MHE of cirrhotic patients.
Author Contributions
Conceptualization: A.C.C., C.E.G.C. and C.M.; Patients selection: C.M., Development of technology C.E.G.C., machine learning tool A.C.C.; formal analysis: A.C.C., C.E.G.C. and C.M.; investigation: A.C.C., C.E.G.C., C.M.; methodology, C.E.G.C. and C.M.; software: A.C.C.; supervision: C.E.G.C.; validation: A.C.C., C.E.G.C. and C.M.; writing:A.C.C., C.E.G.C. and C.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research was partially funded by RoboCity2030-DIH-CM Madrid Robotics Digital Innovation Hub (“Robotica aplicada a la mejora de la calidad de vida de los ciudadanos, Fase IV”; S2018/NMT-4331), funded by Comunidad de Madrid and cofunded by Structural Funds of the EU, and by grants from Ministerio de Ciencia e Innovación (PID2022-136625OB-I00); Universidad de Valencia, Ayudas para Acciones Especiales (UV-INV AE-2633839) to C.M; Agencia Valenciana de Innovación, Generalitat Valenciana (Consolidació Cadena Valor) to C.M.; Consellería Educación, Generalitat Valenciana (CIPROM2021/082) co-funded by European Regional Development Funds (ERDF); F. Sarabia (PRV00225) donation, to CM.
Institutional Review Board Statement
This study was performed in line with the principles of the Declaration of Helsinki. Study protocols were approved by the Scientific and Ethical Committees (No. 2017/291) of Hospitals Clinico and Arnau de Vilanova, Valencia, Spain. All participants were included after written informed consent.
Informed Consent Statement
All subjects gave their informed consent for inclusion before they participated in the study. The study was conducted in accordance with the Declaration of Helsinki, and the protocol was approved by the Ethics Committee of Clinical Hospital of Valencia.
Data Availability Statement
Restrictions apply to the availability of these data. Data are unavailable due to privacy restrictions.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| MHE | Minimal Hepatic Encephalopaty |
| PHES | Psychometric Hepatic Encephalopathy Score |
| ML | Machine learning |
| SSC | Scleral Search Coil |
| EOG | Electro-oculography |
| VOG | Video-oculography |
| FPS | Frames per second |
| AUC | Area under the curve |
| VGST | Visually guided saccades test |
| AST | Antisaccades test |
| MGST | Memory-guided saccades test |
| LSPT | Linear smooth pursuit test |
| FIXT | Fixation test |
| SVM | Supported vector machine |
| KNN | K-nearest neighbour |
| IR | Infrared |
References
- Beam, A.L.; Kohane, I.S. Big data and machine learning in health care. JAMA 2018, 319, 1317–1318. [Google Scholar] [CrossRef] [PubMed]
- Davison, D. A Method of Measuring Eye Movement Using a Scleral Search Coil. IEEE Trans. Bio-Med. Electron. 1963, 10, 137–145. [Google Scholar]
- Noor, N.M.M.; bin Kamarudin, M.Q. Study the different level of eye movement based on electrooculography (EOG) technique. In Proceedings of the 2016 IEEE EMBS Conference on Biomedical Engineering and Sciences (IECBES), Kuala Lumpur, Malaysia, 4–8 December 2016; pp. 792–796. [Google Scholar]
- Park, J.; Kong, Y.; Nam, Y. A low-cost video-oculography system for vestibular function testing. In Proceedings of the 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Jeju Island, Republic of Korea, 11–15 July 2017; pp. 4078–4081. [Google Scholar] [CrossRef]
- Wierts, R.; Janssen, M.J.A.; Kingma, H. Measuring Saccade Peak Velocity Using a Low-Frequency Sampling Rate of 50 Hz. IEEE Trans. Biomed. Eng. 2008, 55, 2840–2842. [Google Scholar] [CrossRef] [PubMed]
- Flechtner, K.M.; Steinacher, B.; Sauer, R.; Mackert, A. Smooth pursuit eye movements of patients with schizophrenia and affective disorder during clinical treatment. Eur. Arch. Psychiatry Clin. Neurosci. 2002, 252, 49–53. [Google Scholar] [CrossRef]
- Martinez-Conde, S.; Macknik, S.L.; Troncoso, X.G.; Hubel, D.H. Microsaccades: A neurophysiological analysis. Trends Neurosci. 2009, 32, 463–475. [Google Scholar] [CrossRef]
- Termsarasab, P.; Thammongkolchai, T.; Rucke, J.; Frucht, S. The diagnostic value of saccades in movement disorder patients: A practical guide and review. J. Clin. Mov. Disord. 2015, 1, 14. [Google Scholar] [CrossRef]
- Holmqvist, K.; Nystrom, N.; Andersson, R.; Dewhurst, R.; Jarodzka, H.; Van de Weijer, J. Eye Tracking: A Comprehensive Guide to Methods and Measures; Oxford University Press: Oxford, UK, 2011. [Google Scholar]
- Catz, N.; Their, P. Neural Control of Saccadic Eye Movements. J. Dev. Ophthalmol. 2007, 40, 52–75. [Google Scholar]
- Antoniades, C.; Ettinger, U.; Gaymard, B.E.A. An internationally standardised antisaccade protocol. Vis. Res. 2013, 84, 1–5. [Google Scholar] [CrossRef]
- Pierrot-Deseilligny, C.; Müri, R.; Nyffeler, T.; Milea, D. The role of the human dorsolateral prefrontal cortex in ocular motor behavior. Ann. N. Y. Acad. Sci. 2005, 1039, 239–251. [Google Scholar] [CrossRef]
- Johnston, K.; Koval, M.; Lomber, S.; Everling, S. Macaque dorsolateral prefrontal cortex does not suppress saccaderelated activity in the superior colliculus. Cereb Cortex 2014, 24, 1373–1388. [Google Scholar] [CrossRef][Green Version]
- Tadokoro, K.; Yamashita, T.; Fukui, Y.; Nomura, E.; Ohta, Y.; Ueno, S.; Nishina, S.; Tsunoda, K.; Wakutani, Y.; Takao, Y.; et al. Early detection of cognitive decline in mild cognitive impairment and Alzheimer’s disease with a novel eye tracking test. J. Neurol. Sci. 2021, 427, 117529. [Google Scholar] [CrossRef] [PubMed]
- Tao, L.; Wang, Q.; Liu, D.; Wang, J.; Zhu, Z.; Feng, L. Eye tracking metrics to screen and assess cognitive impairment in patients with neurological disorders. Neurol. Sci. 2020, 41, 1697–1704. [Google Scholar] [CrossRef] [PubMed]
- Wolf, A.; Ueda, K. Contribution of eye-tracking to study cognitive impairments among clinical populations. Front. Psychol. 2021, 12, 590986. [Google Scholar] [CrossRef]
- Liu, Z.; Yang, Z.; Gu, Y.; Liu, H.; Wang, P. The effectiveness of eye tracking in the diagnosis of cognitive disorders: A systematic review and meta-analysis. PLoS ONE 2021, 16, e0254059. [Google Scholar] [CrossRef]
- Hernández, E.; Hernández, S.; Molina, D.; Acebrón, R.; García Cena, C. OSCANN: Technical characterization of a novel gaze tracking analyzer. Sensors 2018, 18, 522. [Google Scholar] [CrossRef]
- Garcia Cena, C.E.; Andres, D.G.; Valdeoliva, I.P.; Lopez, R.A.; Gomez, R.E.; Vazquez, S.R. Device for Synchronized Measure of Ocular and Cephalic Movements. WO Patent WO2017191303A1, 5 May 2017. [Google Scholar]
- García Cena, C.; Costa, M.C.; Saltarén Pazmiño, R.; Santos, C.P.; Gómez-Andrés, D.; Benito-León, J. Eye movement alterations in post-COVID-19 condition: A proof-of-concept study. Sensors 2022, 22, 1481. [Google Scholar] [CrossRef]
- García Cena, C.E.; Gómez-Andrés, D.; Pulido-Valdeolivas, I.; Sánchez-Seco, V.G.; Domingo-Santos, A.; Moreno-García, S.; Benito-León, J. Toward an Automatic Assessment of Cognitive Dysfunction in Relapsing–Remitting Multiple Sclerosis Patients Using Eye Movement Analysis. Sensors 2022, 22, 8220. [Google Scholar] [CrossRef] [PubMed]
- Lage, C.; López-García, S.; Bejanin, A.; Kazimierczak, M.; Aracil-Bolaños, I.; Calvo-Córdoba, A.; Pozueta, A.; García-Martínez, M.; Fernández-Rodríguez, A.; Bravo-González, M.; et al. Distinctive Oculomotor Behaviors in Alzheimer’s Disease and Frontotemporal Dementia. Front. Aging Neurosci. 2021, 12, 525. [Google Scholar] [CrossRef]
- Guerrero-Molina, M.P.; Rodriguez-López, C.; Panadés-de Oliveira, L.; de Urabayen, D.U.P.; Garzo-Caldas, N.; García-Cena, C.E.; Saiz-Díaz, R.A.; Benito-León, J.; de la Aleja, J.G. Antisaccades and memory-guided saccades in genetic generalized epilepsy and temporal lobe epilepsy. Epilepsy Behav. 2021, 123, 108236. [Google Scholar] [CrossRef]
- Mattarozzi, K.; Stracciari, A.; Vignatelli, L.; D’Alessandro, R.; Morelli, M.C.; Guarino, M. Minimal hepatic encephalopathy: Longitudinal effects of liver transplantation. Arch. Neurol. 2004, 61, 242–247. [Google Scholar] [CrossRef] [PubMed]
- Weissenborn, K.; Ennen, J.C.; Schomerus, H.; Rückert, N.; Hecker, H. Neuropsychological characterization of hepatic encephalopathy. J. Hepatol. 2001, 34, 768–773. [Google Scholar] [CrossRef]
- Ferenci, P.; Lockwood, A.; Mullen, K.; Tarter, R.; Weissenborn, K.; Blei, A.T. Hepatic encephalopathy—definition, nomenclature, diagnosis, and quantification: Final report of the working party at the 11th World Congresses of Gastroenterology, Vienna, 1998. Hepatology 2002, 35, 716–721. [Google Scholar] [CrossRef] [PubMed]
- Butz, M.; Timmermann, L.; Braun, M.; Groiss, S.; Wojtecki, L.; Ostrowski, S.; Krause, H.; Pollok, B.; Gross, J.; Südmeyer, M.; et al. Motor impairment in liver cirrhosis without and with minimal hepatic encephalopathy. Acta Neurol. Scand. 2010, 122, 27–35. [Google Scholar] [CrossRef]
- Gimenéz Garzó, C.; Garcés, J.; Urios, A.; Mangas Losada, A.; García-García, R.; González López, O.; Giner Durán, R.; Escudero García, D.; Serra, M.; Soria, E.; et al. The PHES battery does not detect all cirrhotic patients with early neurological deficits, which are different in different patients. PLoS ONE 2017, 12, e0171211. [Google Scholar] [CrossRef] [PubMed]
- Bajaj, J.; Thacker, L.; Heuman, D.; Fuchs, M.; Sterling, R.; Sanyal, A. The Stroop smartphone application is a short and valid method to screen for minimal hepatic encephalopathy. Hepatology 2013, 58, 1122–1132. [Google Scholar] [CrossRef]
- Ouerfelli-Ethier, J.; Elsaeid, B.; Desgroseilliers, J.; Munoz, D.; Blohm, G.; Khan, A. Anti-saccades predict cognitive functions in older adults and patients with Parkinson’s disease. PLoS ONE 2018, 13, e0207589. [Google Scholar] [CrossRef]
- Amodio, P.; Campagna, F.; Olianas, S.; Iannizzi, P.; Mapelli, D.; Penzo, M.; Angeli, P.; Gatta, A. Detection of minimal hepatic encephalopathy: Normalization and optimization of the Psychometric Hepatic Encephalopathy Score. A neuropsychological and quantified EEG study. J. Hepatol. 2008, 49, 346–353. [Google Scholar] [CrossRef]
- Fernando Caporal-Montes de Oca, L.; Daniel Santana-Vargas, Á.; Giovanni Ramírez-Chavarría, R.; Misaghian, K.; Eduardo Lugo-Arce, J.; Pérez-Pacheco, A. Hjorth Parameters in Event-Related Potentials to Detect Minimal Hepatic Encephalopathy. In Proceedings of the International Conference on Trends in Electronics and Health Informatics, Puebla, Mexico, 7–9 December 2022; pp. 267–280. [Google Scholar]
- Ahn, J.C.; Attia, Z.I.; Rattan, P.; Mullan, A.F.; Buryska, S.; Allen, A.M.; Kamath, P.S.; Friedman, P.A.; Shah, V.H.; Noseworthy, P.A.; et al. Development of the AI-Cirrhosis-ECG (ACE) Score: An electrocardiogram-based deep learning model in cirrhosis. Am. J. Gastroenterol. 2022, 117, 424. [Google Scholar] [CrossRef]
- Yang, H.; Li, X.; Cao, H.; Cui, Y.; Luo, Y.; Liu, J.; Zhang, Y. Using machine learning methods to predict hepatic encephalopathy in cirrhotic patients with unbalanced data. Comput. Methods Programs Biomed. 2021, 211, 106420. [Google Scholar] [CrossRef]
- Garcia Cena, C.E.; Gomez Andre, D.; Pulido Valdeolivas, I. Measurement and analysis of eye movements performance to predict healthy brain aging. IEEE Access 2020, 8, 87201–87213. [Google Scholar] [CrossRef]
- Larrazabal, A.; Cena, C.G.; Martínez, C. Video-oculography eye tracking towards clinical applications: A review. Comput. Biol. Med. 2019, 108, 57–66. [Google Scholar] [CrossRef] [PubMed]
- Ortiz, M.; Jacas, C.; Córdoba, J. Minimal hepatic encephalopathy: Diagnosis, clinical significance and recommendations. J. Hepatol. 2005, 42, S45–S53. [Google Scholar] [CrossRef] [PubMed]
- Cunniffe, N.; Munby, S.C.; Saatci, D.; Edison, E.; Carpenter, R.; Massey, D. Using saccades to diagnose covert hepatic encephalopathy. Metab. Brain Dis. 2015, 30, 821–828. [Google Scholar] [CrossRef] [PubMed]
- Leigh, R.J.; Zee, D.S. The Neurology of Eye Movements; Oxford University Press: New York, NY, USA, 2015. [Google Scholar]
- Martinez-Conde, S.; Macknik, S.L.; Hubel, D.H. The role of fixational eye movements in visual perception. Nat. Rev. Neurosci. 2004, 5, 229. [Google Scholar] [CrossRef] [PubMed]
- Montagnese, S.; Gordon, H.M.; Jackson, C.; Smith, J.; Tognella, P.; Jethwa, N.; Sherratt, R.M.; Morgan, M.Y. Disruption of smooth pursuit eye movements in cirrhosis: Relationship to hepatic encephalopathy and its treatment. Hepatology 2005, 42, 772–781. [Google Scholar] [CrossRef]
- Mendes, M.; Pala, A. Type I error rate and power of three normality tests. Pak. J. Inf. Technol. 2003, 2, 135–139. [Google Scholar]
- Razali, N.M.; Wah, Y.B. Power comparisons of shapiro-wilk, kolmogorov-smirnov, lilliefors and anderson-darling tests. J. Stat. Model. Anal. 2011, 2, 21–33. [Google Scholar]
- Royston, P. Remark AS R94: A remark on algorithm AS 181: The W-test for normality. J. R. Stat. Society. Ser. C (Appl. Stat.) 1995, 44, 547–551. [Google Scholar] [CrossRef]
- Bharathi, A.; Natarajan, A. Cancer classification of bioinformatics datausing anova. Int. J. Comput. Theory Eng. 2010, 2, 369. [Google Scholar] [CrossRef]
- Surendiran, B.; Vadivel, A. Feature selection using stepwise ANOVA discriminant analysis for mammogram mass classification. Int. J. Recent Trends Eng. Technol. 2010, 3, 55–57. [Google Scholar]
- Smilde, A.K.; Jansen, J.J.; Hoefsloot, H.C.; Lamers, R.J.A.; Van Der Greef, J.; Timmerman, M.E. ANOVA-simultaneous component analysis (ASCA): A new tool for analyzing designed metabolomics data. Bioinformatics 2005, 21, 3043–3048. [Google Scholar] [CrossRef]
- Kruskal, W.H.; Wallis, W.A. Use of ranks in one-criterion variance analysis. J. Am. Stat. Assoc. 1952, 47, 583–621. [Google Scholar] [CrossRef]
- Siegel, S. Nonparametric statistics. Am. Stat. 1957, 11, 13–19. [Google Scholar]
- Hua, S.; Sun, Z. Support vector machine approach for protein subcellular localization prediction. Bioinformatics 2001, 17, 721–728. [Google Scholar] [CrossRef]
- Xu, H.; Caramanis, C.; Mannor, S. Robustness and regularization of support vector machines. J. Mach. Learn. Res. 2009, 10, 1485–1510. [Google Scholar]
- Hsu, C.W.; Lin, C.J. A comparison of methods for multiclass support vector machines. IEEE Trans. Neural Netw. 2002, 13, 415–425. [Google Scholar]
- Fawcett, T. ROC graphs: Notes and practical considerations for researchers. Mach. Learn. 2004, 31, 1–38. [Google Scholar]
- Platt, J. Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods. Adv. Large Margin Classif. 1999, 10, 61–74. [Google Scholar]
- Felipo, V.; Ordoño, J.F.; Urios, A.; El Mlili, N.; Giménez-Garzó, C.; Aguado, C.; González-Lopez, O.; Giner-Duran, R.; Serra, M.A.; Wassel, A.; et al. Patients with minimal hepatic encephalopathy show impaired mismatch negativity correlating with reduced performance in attention tests. Hepatology 2012, 55, 530–539. [Google Scholar] [CrossRef]
- Liao, L.m.; Zhou, L.x.; Le, H.b.; Yin, J.j.; Ma, S.h. Spatial working memory dysfunction in minimal hepatic encephalopathy: An ethology and BOLD-fMRI study. Brain Res. 2012, 1445, 62–72. [Google Scholar] [CrossRef] [PubMed]
- García-García, R.; Cruz-Gómez, Á.J.; Mangas-Losada, A.; Urios, A.; Forn, C.; Escudero-Garcia, D.; Kosenko, E.; Ordoño, J.F.; Tosca, J.; Giner-Duran, R.; et al. Reduced resting state connectivity and gray matter volume correlate with cognitive impairment in minimal hepatic encephalopathy. PLoS ONE 2017, 12, e0186463. [Google Scholar] [CrossRef] [PubMed]
- Heuer, H.W.; Mirsky, J.B.; Kong, E.L.; Dickerson, B.C.; Miller, B.L.; Kramer, J.H.; Boxer, A.L. Antisaccade task reflects cortical involvement in mild cognitive impairment. Neurology 2013, 81, 1235–1243. [Google Scholar] [CrossRef] [PubMed]








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).