


Emergency Floor Plan Digitization Using Machine Learning

 , , , and
, , , and
Abstract
:1. Introduction
2. Related Work
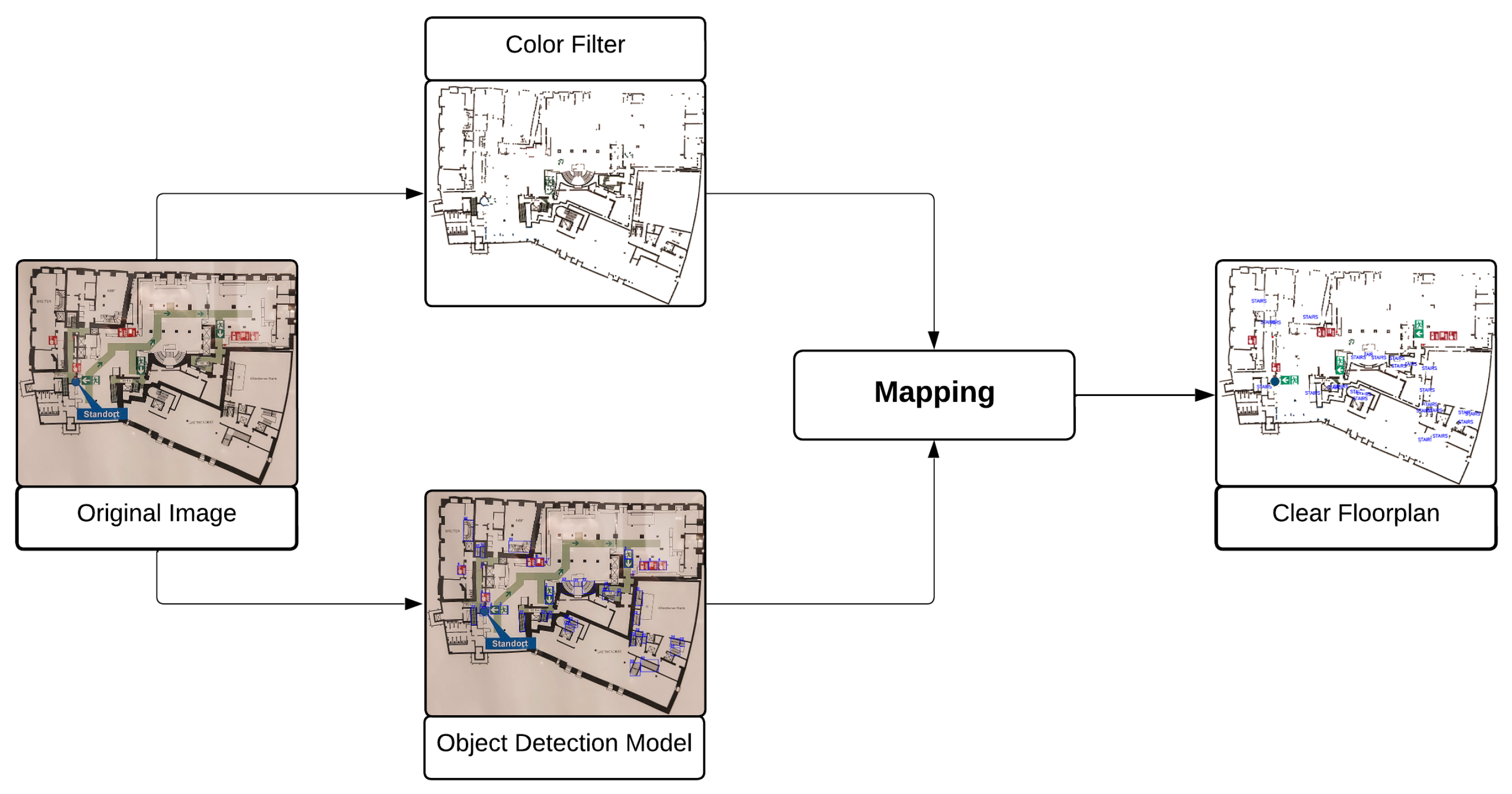
3. Methodology
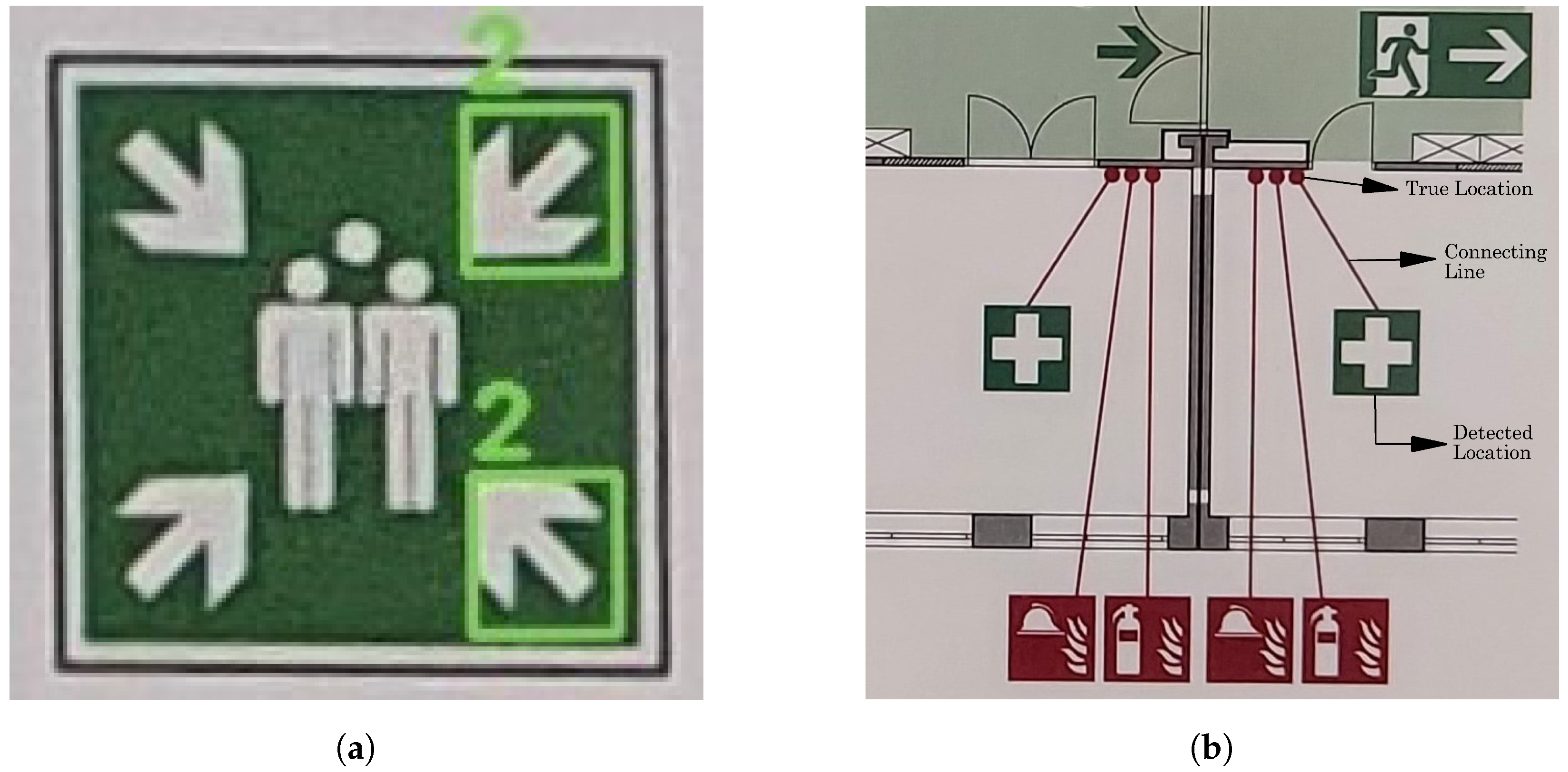
3.1. Object Detection Model
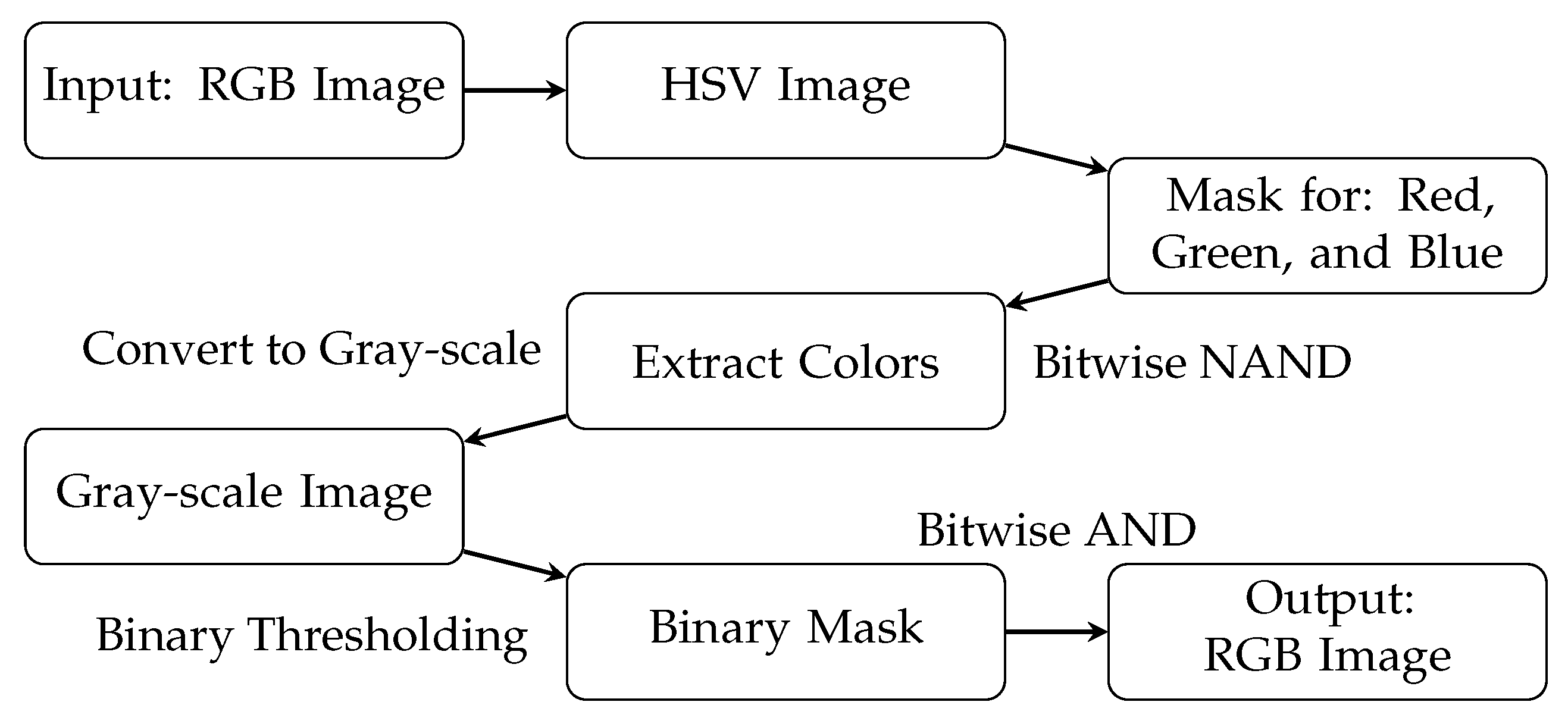
3.2. Color Filter Model
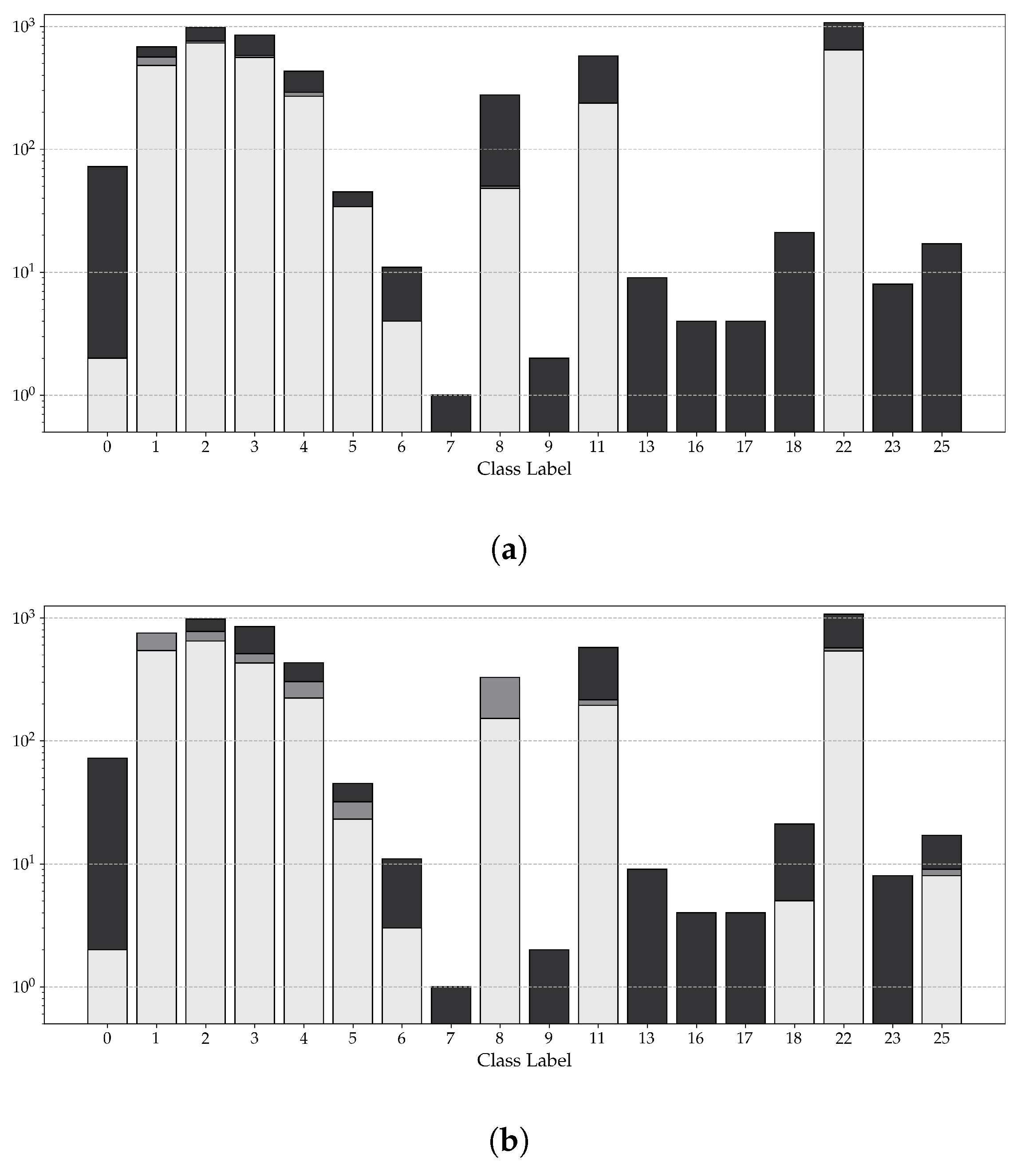
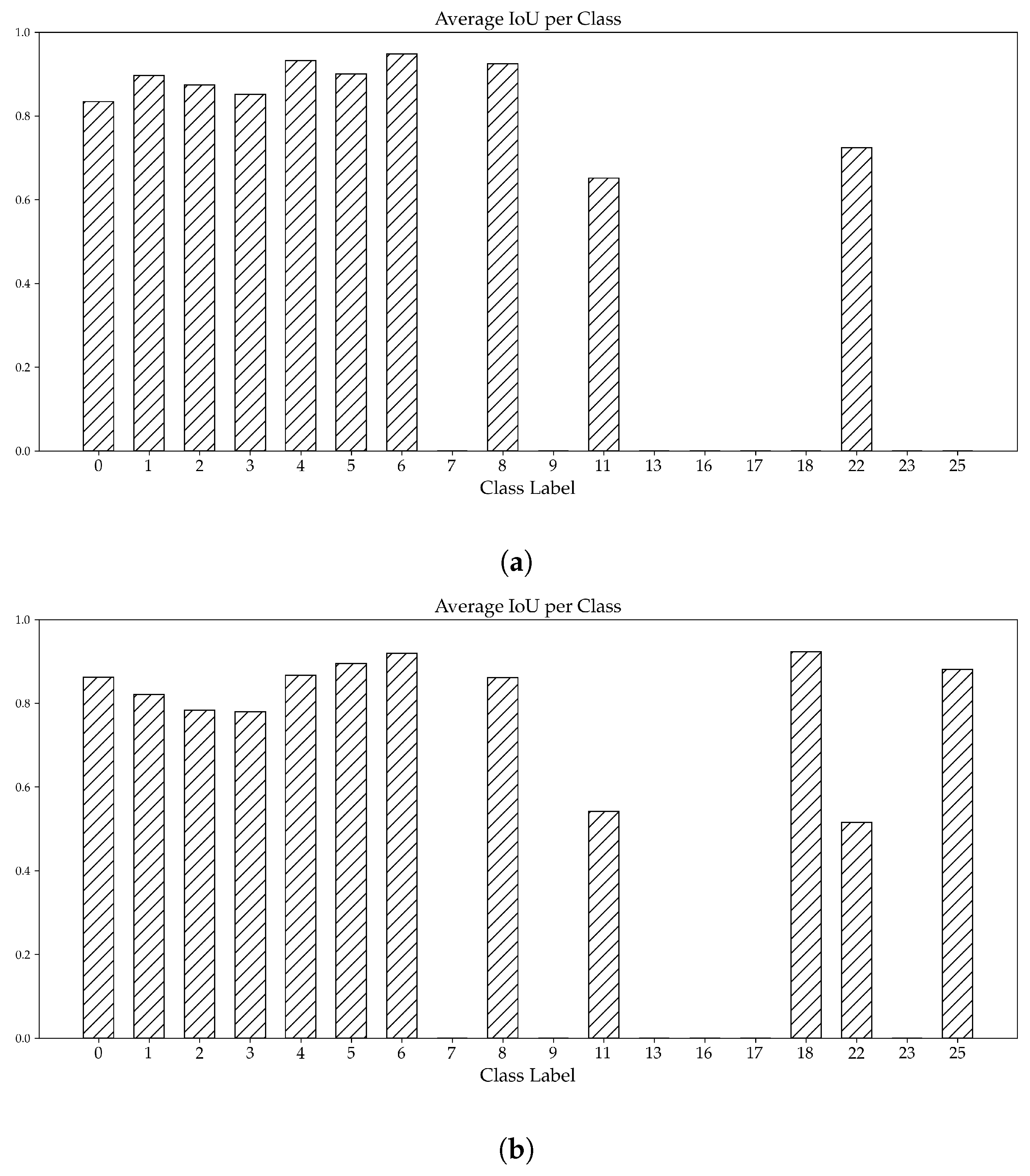
4. Experiments and Results
4.1. Datasets
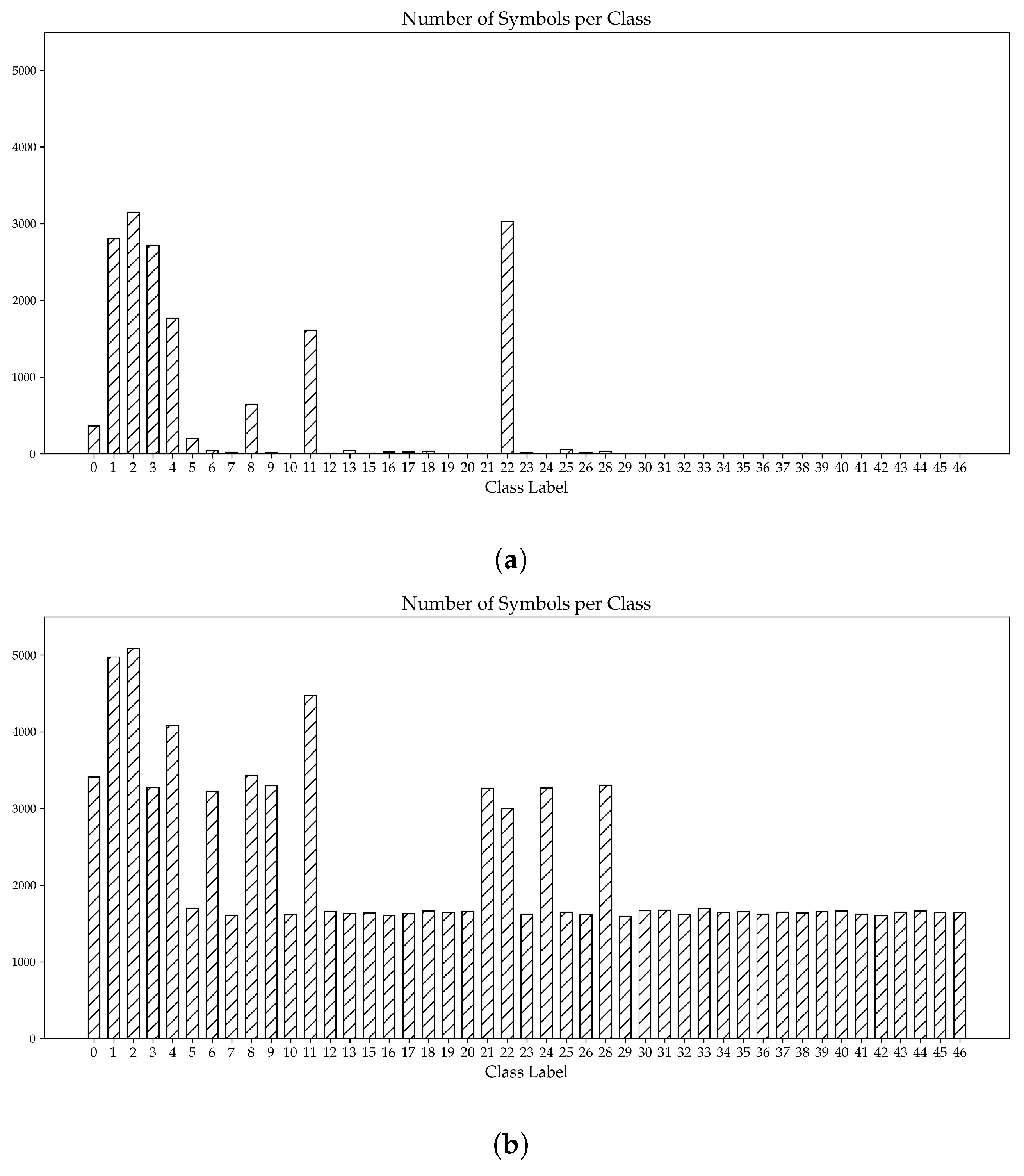
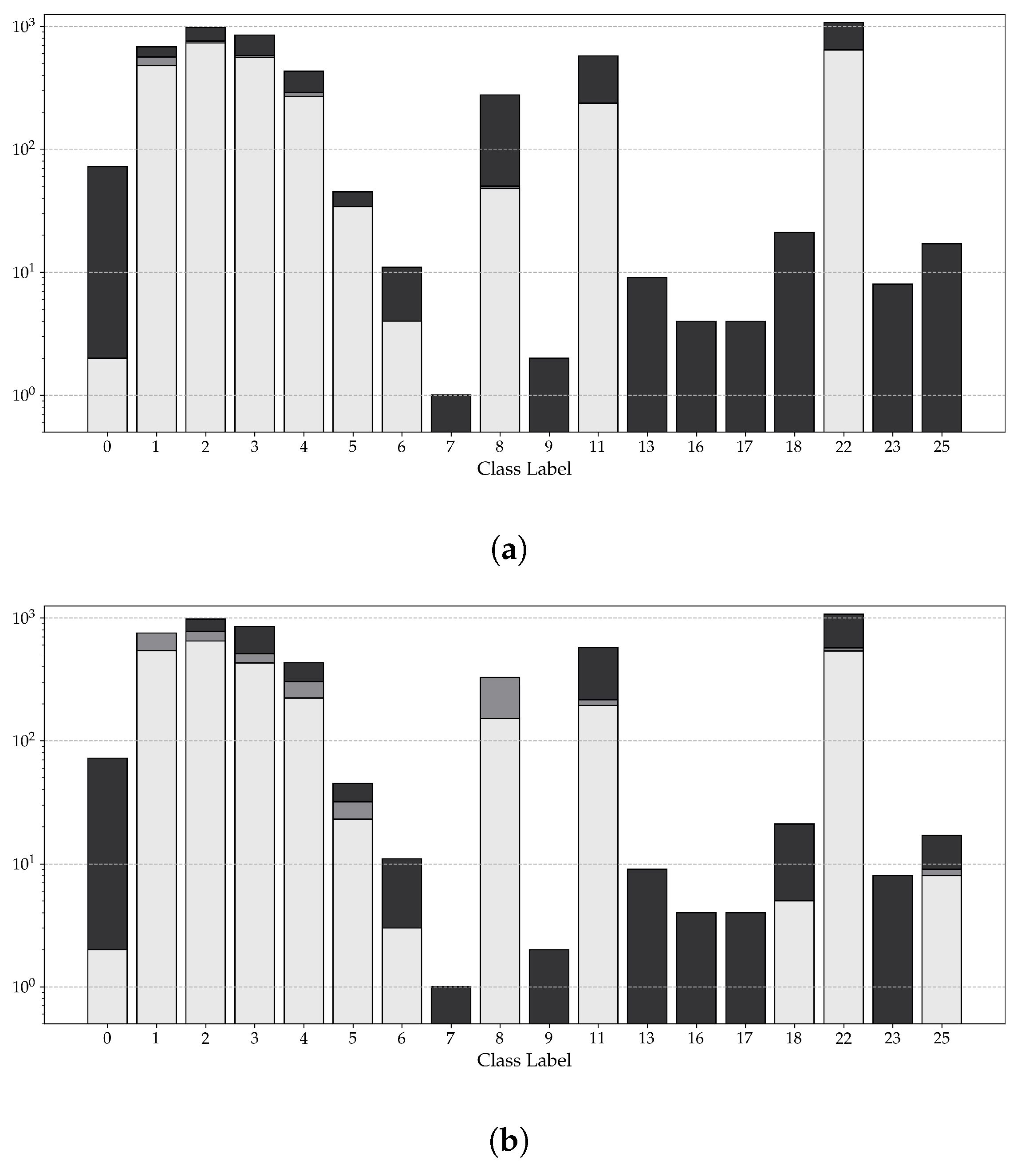
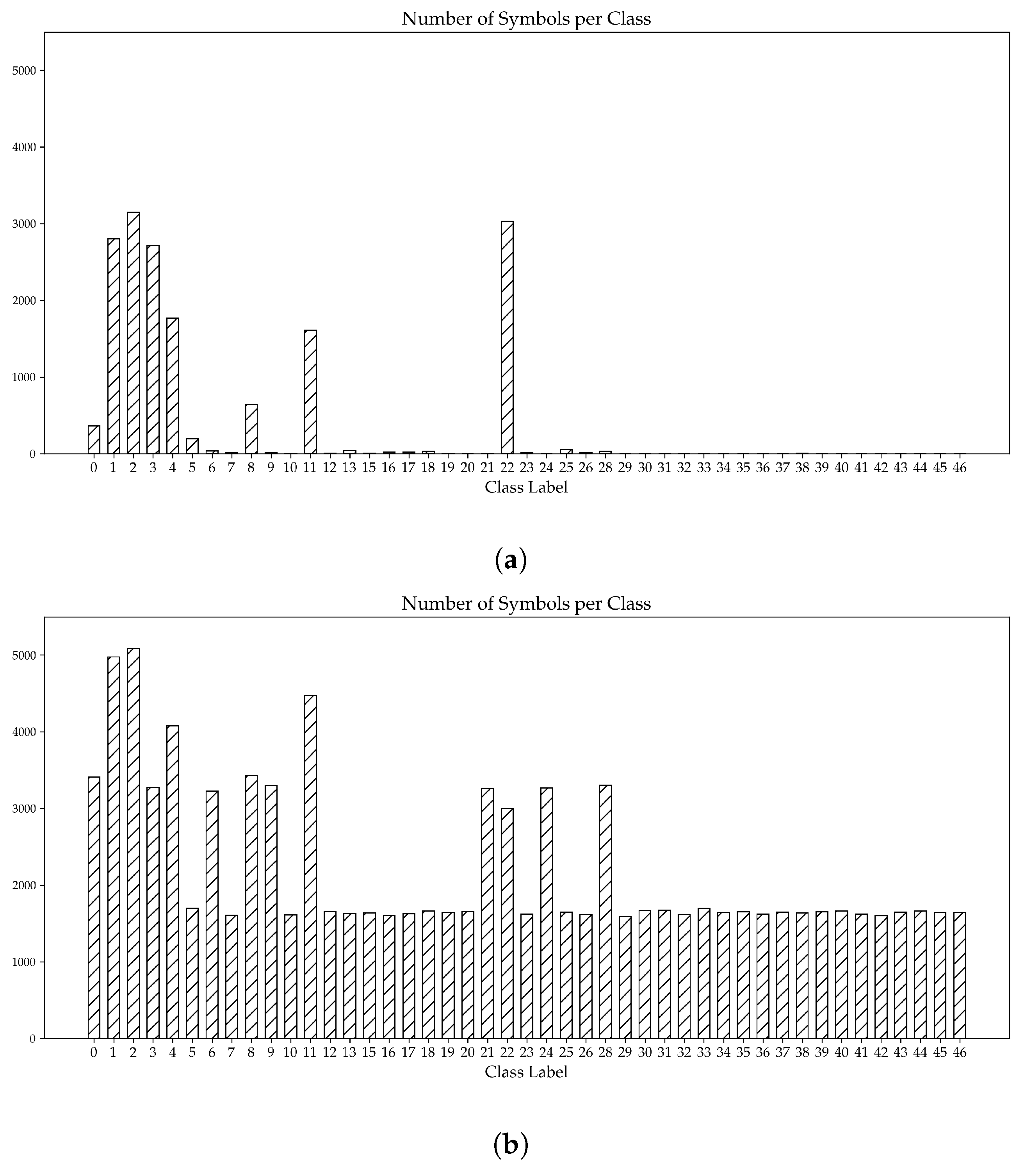
4.1.1. Relevant Symbols
4.1.2. Labeling
4.2. Preprocessing—COD Model
Synthetic Data
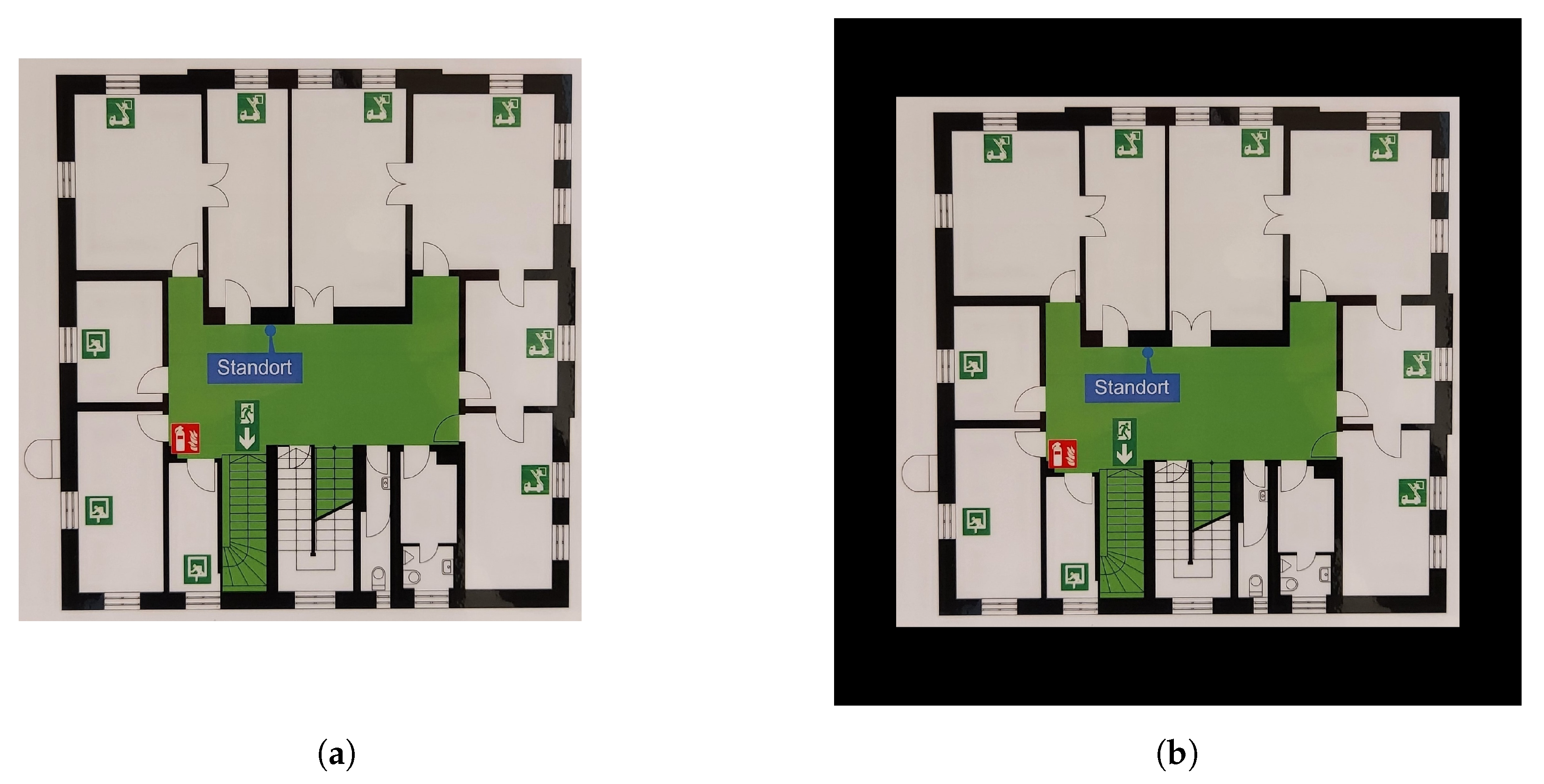
4.3. Preprocessing—CF Model
4.4. Inference—COD Model
4.5. Inference—CF Model
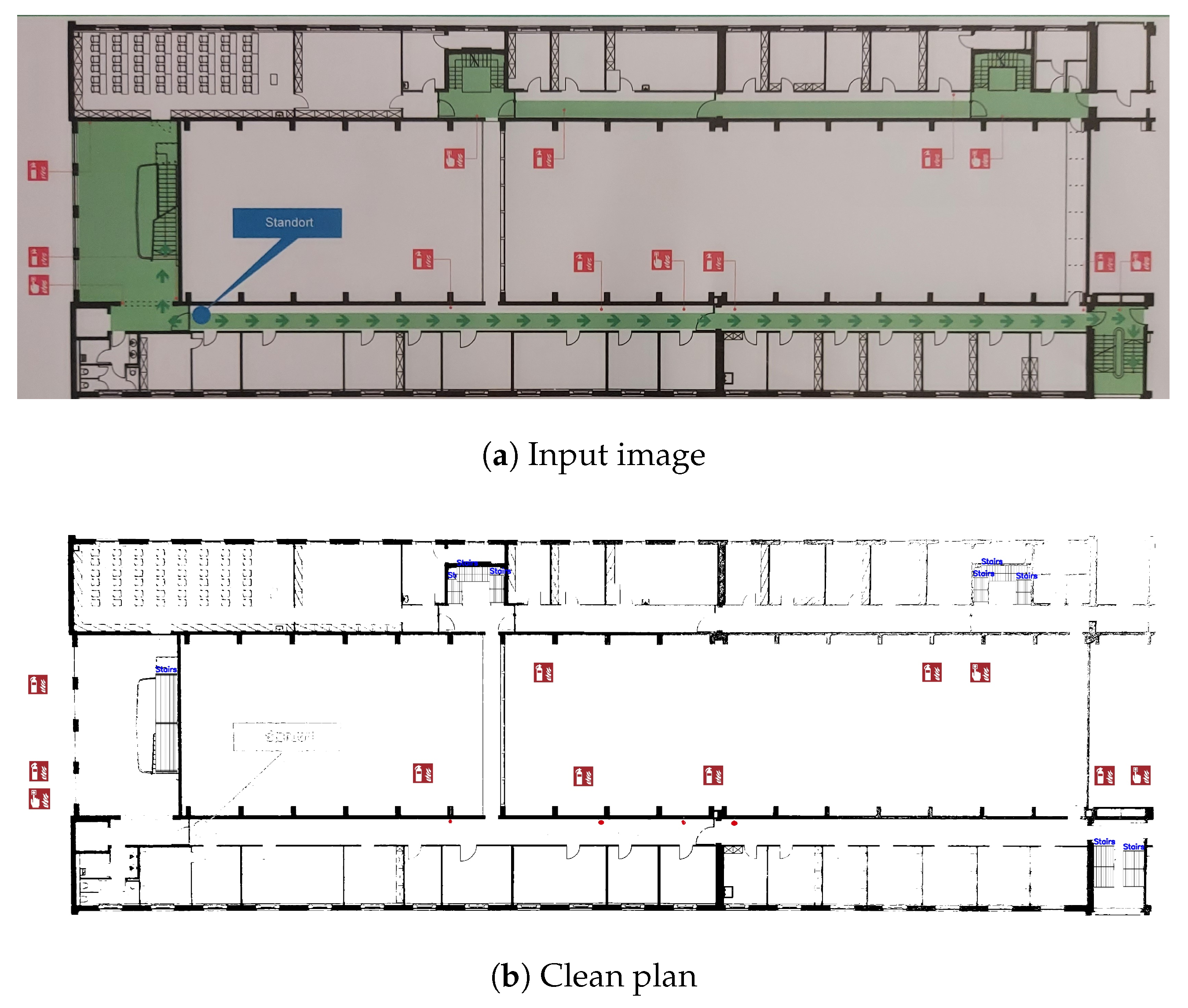
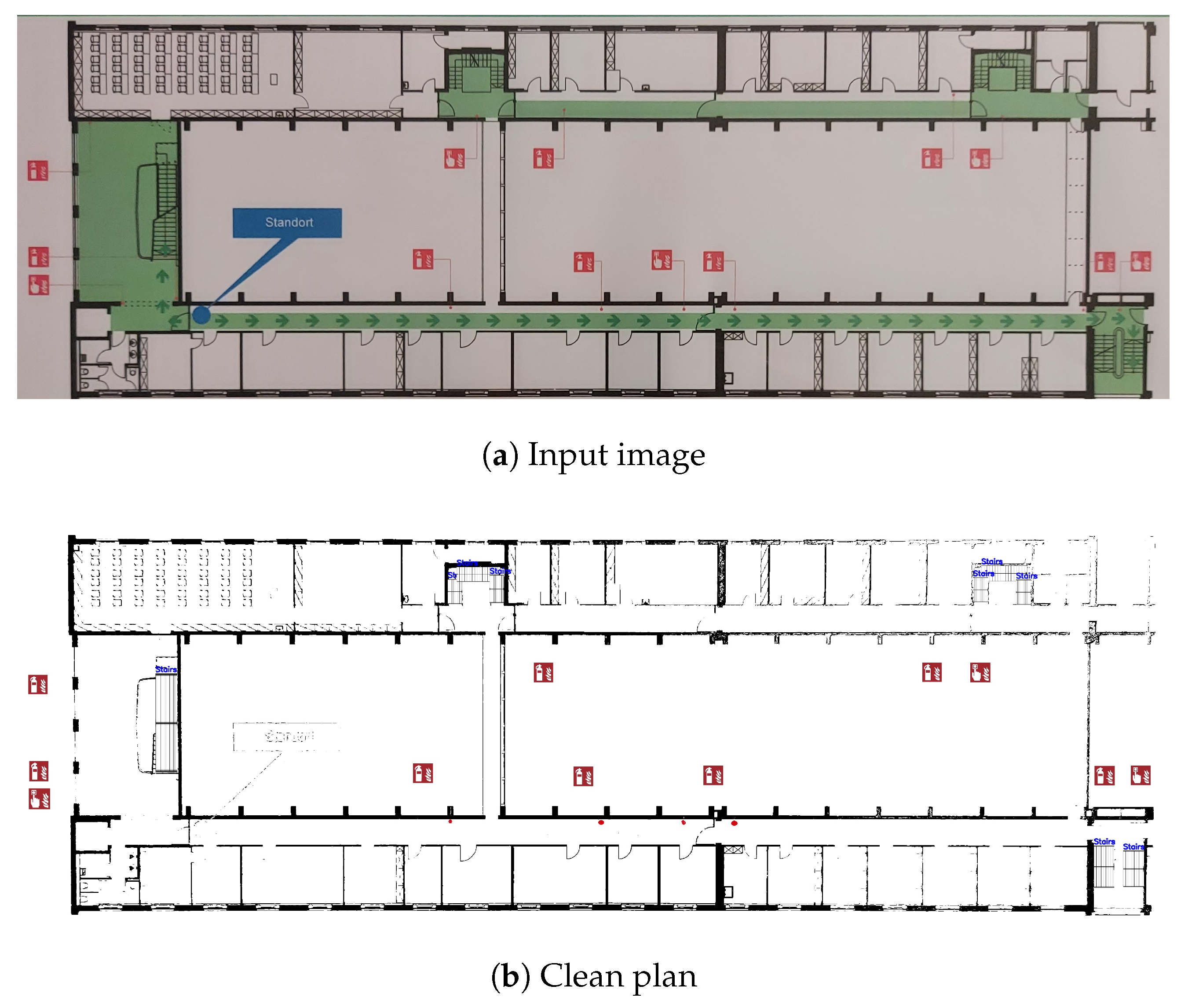
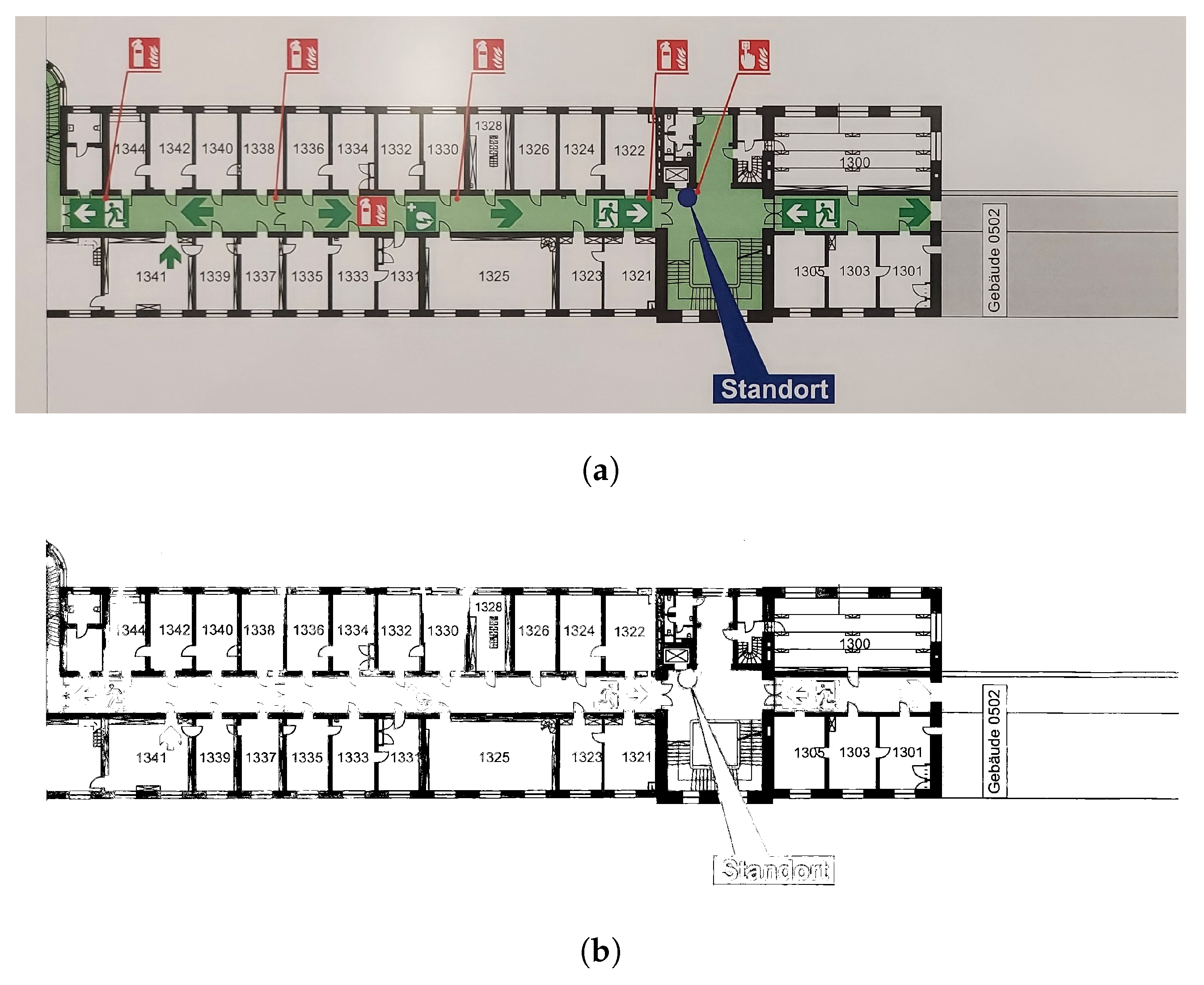
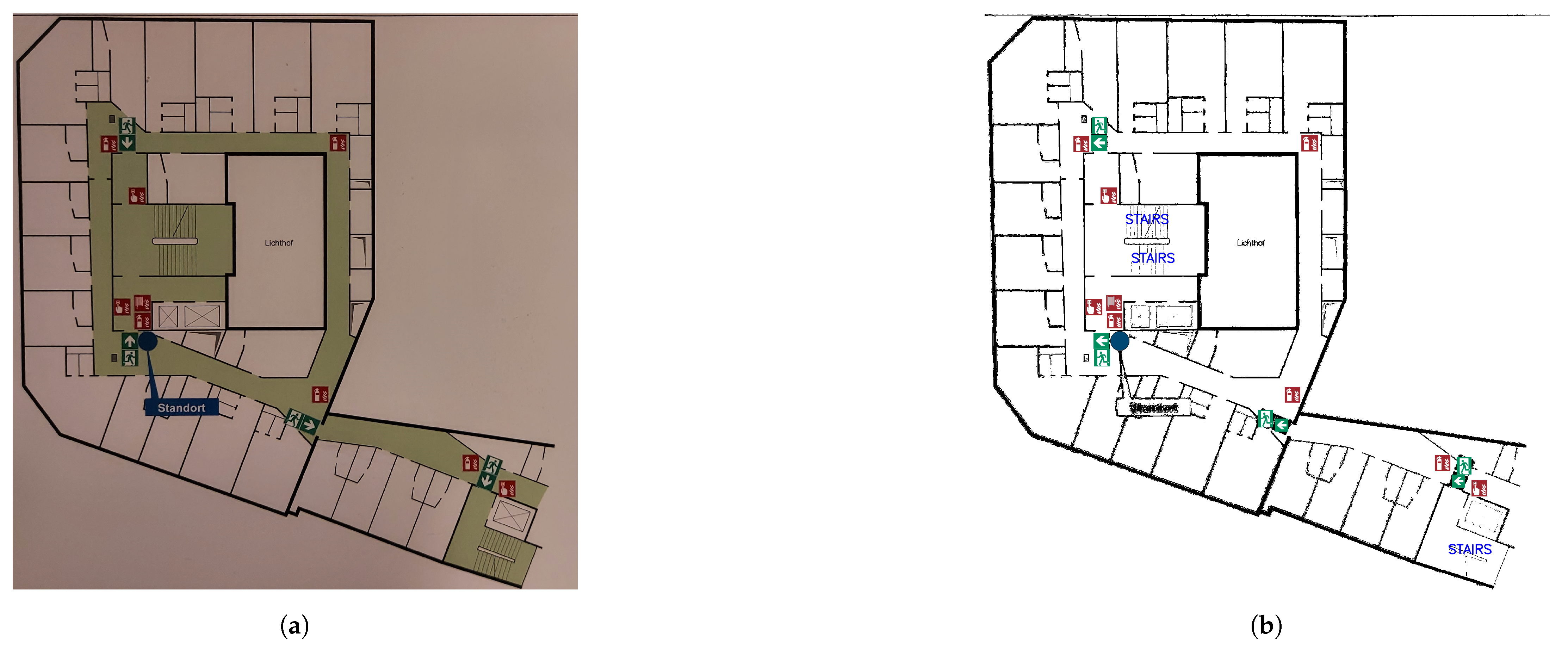
4.6. Clean Plan
4.7. Limitations
5. Concluding Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label (Ger) | Label (Eng) | Numeration | Symbols |
|---|---|---|---|
| Standort | Location | 0 |  |
| Standort | Location | 0_4844-2 |  |
| Feuerlöscher | Fire extinguisher | 1 |  |
| Feuerlöscher | Fire extinguisher | 1_4844-2 |  |
| Richtungsangabe | Direction | 2 |  |
| Richtungsangabe | Direction | 2_4844-2 |  |
| Notausgang | Emergency exit | 3 |  |
| Druckknopfmelder | Push button alarm | 4 |  |
| Druckknopfmelder | Push button alarm | 4_4844-2 |  |
| Erste Hilfe | First aid | 5 |  |
| Sammelstelle | Assembly location | 6 |  |
| Sammelstelle | Assembly location | 6_4844-2 |  |
| Notruftelefon | Telephone | 7 |  |
| Wandhydrant | Wall hydrant | 8_4844-2 |  |
| Mittel und Geräte zur Brandbekämpfung | Fire blanket | 9 |  |
| Mittel und Geräte zur Brandbekämpfung | Fire blanket | 9_4844-2 |  |
| Fahrbarer Feuerlöscher | Mobile fire extinguisher | 10 |  |
| Symbolposition | Symbol location | 11 |  |
| Symbolposition | Symbol location | 11_1 |  |
| Augenspueleinrichtung | Eyewash device | 12 |  |
| Automatisierter externer Defibrillator (AED) | Defibrillator | 13 |  |
| Notdusche | Emergency shower | 15 |  |
| Notausstieg | Escape hatch | 16_4844-2 |  |
| Notausstieg mit Fluchtleiter | Escape hatch with emergency ladder | 17 |  |
| Rettungsausstieg | Rescue exit/mooring | 18 |  |
| Notausgang für nicht-gehfähige oder gehbeeinträchtigte Personen | Barrier-free emergency exit | 19 |  |
| Vorläufige Evakuierungsstelle | Temporary evacuation point for impaired persons | 20 |  |
| Feuerleiter | Fire ladder | 21 |  |
| Feuerleiter | Fire ladder | 21_4844-2 |  |
| Treppe | Staircase | 22 |  |
| Krankentrage | Stretcher | 23 |  |
| Arzt | Doctor | 24 |  |
| Arzt | Doctor | 24_4844-2 |  |
| Auslösung RWA | SHEV triggering | 25 |  |
| Warnung vor elektrischer Spannung | Dangerous electrical voltage | 26 |  |
| Brandmeldetelefon | Emergency phone | 28 |  |
| Brandmeldetelefon | Emergency phone | 28_4844-2 |  |
| Brandschutztuer | Fire safety door | 29 |  |
| Notausgangsvorrichtung, die nach Zerschlagen einer Scheibe zu erreichen ist | Emergency exit device, which can be reached after breaking a pane | 30 |  |
| Fest eingebaute Feuerlöschmittel-Batterie | Fixed fire extinguishing battery | 31 |  |
| Tragbare Schaumlösch-Einheit | Portable foam extinguishing unit | 32 |  |
| Wassernebelrohr | Water fog pipe | 33 |  |
| Fest eingebaute Feuerlösch-Einrichtung | Fixed fire extinguishing unit | 34 |  |
| Fest eingebaute Feuerlösch-Flasche | Fixed fire extinguishing bottle | 35 |  |
| Auslösestation fuer Raumschutz | Sounding station for room protection | 36 |  |
| Feuerlöschmonitor | Fire extinguishing monitor | 37 |  |
| Warnung vor feuergefährlichen Stoffen | Fire hazard warning | 39 |  |
| Nothammer | Emergency hammer | 40 |  |
| Medizinischer Notfallkoffer | Emergency medical kit | 41 |  |
| Wiederbelebungsgerät | Resuscitator | 42 |  |
| Warnung vor brandfördernden Stoffen | Warning against flammable substances | 43 |  |
| Warnung vor Gasflaschen | Warning against gas cylinders | 44 |  |
| Fluchtretter | Escape rescue device | 45 |  |
| Richtungsangabe | Direction | 46_4844-2 |  |
References
- Chou, J.S.; Cheng, M.Y.; Hsieh, Y.M.; Yang, I.T.; Hsu, H.T. Optimal path planning in real time for dynamic building fire rescue operations using wireless sensors and visual guidance. Autom. Constr. 2019, 99, 1–17. [Google Scholar] [CrossRef]
- Dugstad, A.; Dubey, R.K.; Abualdenien, J.; Borrmann, A. BIM-based disaster response: Facilitating indoor path planning for various agents. In ECPPM 2022—eWork and eBusiness in Architecture, Engineering and Construction 2022; CRC Press: London, UK, 2023; pp. 477–484. [Google Scholar] [CrossRef]
- Ronchi, E.; Nilsson, D. Modelling total evacuation strategies for high-rise buildings. Build. Simul. 2014, 7, 73–87. [Google Scholar] [CrossRef]
- Kodur, V.K.R.; Venkatachari, S.; Naser, M.Z. Egress Parameters Influencing Emergency Evacuation in High-Rise Buildings. Fire Technol. 2020, 56, 2035–2057. [Google Scholar] [CrossRef]
- Beata, P.A.; Jeffers, A.E.; Kamat, V.R. Real-Time Fire Monitoring and Visualization for the Post-Ignition Fire State in a Building. Fire Technol. 2018, 54, 995–1027. [Google Scholar] [CrossRef]
- Wang, C.; Luo, J.; Zhang, C.; Liu, X. A Dynamic Escape Route Planning Method for Indoor Multi-floor Buildings Based on Real-time Fire Situation Awareness. In Proceedings of the 2020 IEEE 26th International Conference on Parallel and Distributed Systems (ICPADS), Hong Kong, 2–4 December 2020; pp. 222–229. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems (NIPS 2015), Montreal, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Czerniawski, T.; Leite, F. Automated digital modeling of existing buildings: A review of visual object recognition methods. Autom. Constr. 2020, 113, 103131. [Google Scholar] [CrossRef]
- Dodge, S.; Xu, J.; Stenger, B. Parsing floor plan images. In Proceedings of the 2017 Fifteenth IAPR International Conference on Machine Vision Applications (MVA), Nagoya, Japan, 8–12 May 2017; pp. 358–361. [Google Scholar] [CrossRef]
- Gimenez, L.; Robert, S.; Suard, F.; Zreik, K. Automatic reconstruction of 3D building models from scanned 2D floor plans. Autom. Constr. 2016, 63, 48–56. [Google Scholar] [CrossRef]
- Kim, H.; Kim, S.; Yu, K. Automatic Extraction of Indoor Spatial Information from Floor Plan Image: A Patch-Based Deep Learning Methodology Application on Large-Scale Complex Buildings. ISPRS Int. J. Geo-Inf. 2021, 10, 828. [Google Scholar] [CrossRef]
- Lv, X.; Zhao, S.; Yu, X.; Zhao, B. Residential floor plan recognition and reconstruction. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 16712–16721. [Google Scholar] [CrossRef]
- Kim, H. Evaluation of Deep Learning-Based Automatic Floor Plan Analysis Technology: An AHP-Based Assessment. Appl. Sci. 2021, 11, 4727. [Google Scholar] [CrossRef]
- Yin, X.; Wonka, P.; Razdan, A. Generating 3D building models from architectural drawings: A survey. IEEE Comput. Graph. Appl. 2009, 29, 20–30. [Google Scholar] [CrossRef] [PubMed]
- Hakert, A.; Schönfelder, P. Informed Machine Learning Methods for Instance Segmentation of Architectural Floor Plans. Forum Bauinformatik 2022, 33, 395–403. [Google Scholar]
- Guo, Y.; Liu, Y.; Georgiou, T.; Lew, M.S. A review of semantic segmentation using deep neural networks. Int. J. Multimed. Inf. Retr. 2018, 7, 87–93. [Google Scholar] [CrossRef]
- Noh, H.; Hong, S.; Han, B. Learning Deconvolution Network for Semantic Segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Manugunta, R.K.; Maskeliūnas, R.; Damaševičius, R. Deep Learning Based Semantic Image Segmentation Methods for Classification of Web Page Imagery. Future Internet 2022, 14, 277. [Google Scholar] [CrossRef]
- Han, J.; Zhang, D.; Cheng, G.; Liu, N.; Xu, D. Advanced Deep-Learning Techniques for Salient and Category-Specific Object Detection: A Survey. IEEE Signal Process. Mag. 2018, 35, 84–100. [Google Scholar] [CrossRef]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep Learning for Generic Object Detection: A Survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef]
- Surikov, I.Y.; Nakhatovich, M.A.; Belyaev, S.Y.; Savchuk, D.A. Floor Plan Recognition and Vectorization Using Combination UNet, Faster-RCNN, Statistical Component Analysis and Ramer-Douglas-Peucker. In Computing Science, Communication and Security; Chaubey, N., Parikh, S., Amin, K., Eds.; Springer: Singapore, 2020; Volume 1235, pp. 16–28. [Google Scholar] [CrossRef]
- Mishra, S.; Hashmi, K.A.; Pagani, A.; Liwicki, M.; Stricker, D.; Afzal, M.Z. Towards Robust Object Detection in Floor Plan Images: A Data Augmentation Approach. Appl. Sci. 2021, 11, 11174. [Google Scholar] [CrossRef]
- Gupta, M.; Wei, C.; Czerniawski, T. Automated Valve Detection in Piping and Instrumentation (P&ID) Diagrams. In Proceedings of the 39th International Symposium on Automation and Robotics in Construction, Bogota, Colombia, 12–15 July 2022. [Google Scholar] [CrossRef]
- Hjelseth, E.; Sujan, S.F.; Scherer, R.J. Inferring Interconnections of Construction Drawings for Bridges Using Deep Learning-based Methods. In ECPPM 2022—eWork and eBusiness in Architecture, Engineering and Construction 2022; CRC Press: Boca Raton, FL, USA, 2023; pp. 343–350. [Google Scholar] [CrossRef]
- Kaarmukilan, S.P.; Poddar, S.; K, A.T. FPGA based Deep Learning Models for Object Detection and Recognition Comparison of Object Detection Comparison of object detection models using FPGA. In Proceedings of the 2020 Fourth International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 11–13 March 2020; pp. 471–474. [Google Scholar] [CrossRef]
- Huang, J.; Rathod, V.; Sun, C.; Zhu, M.; Korattikara, A.; Fathi, A.; Fischer, I.; Wojna, Z.; Song, Y.; Guadarrama, S.; et al. Speed/accuracy Trade-Offs for Modern Convolutional Object Detectors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Sanchez, S.A.; Romero, H.J.; Morales, A.D. A review: Comparison of performance metrics of pretrained models for object detection using the TensorFlow framework. IOP Conf. Ser. Mater. Sci. Eng. 2020, 844, 012024. [Google Scholar] [CrossRef]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the importance of initialization and momentum in deep learning. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 17–19 June 2013; pp. 1139–1147. [Google Scholar]
- Merschbacher, A. Flucht-und Rettungswege; Springer: Wiesbaden, Germany, 2021. [Google Scholar] [CrossRef]



| Network | Parameter | Loss Function |
|---|---|---|
| RPN | Class | Cross Entropy (binary) |
| RPN | Bounding Box | Smoothed |
| ResNet-50-FPN | Class | Cross Entropy (normal) |
| ResNet-50-FPN | Bounding Box | Smoothed |
| Mask | Upper Limit | Lower Limit |
|---|---|---|
| First Red | ||
| Second Red | ||
| Green | ||
| Blue |
| Transformation | Probability (p) |
|---|---|
| Horizontal Flip | 50 |
| Random Rotation (90°) | 50 |
| Motion Blur | 20 |
| Median Blur | 10 |
| Blur | 10 |
| Component | Details |
|---|---|
| GPU | Nvidia Quadro RTX 8000 |
| CPU | AMD Ryzen Threadripper 3990X 64-Core Processor |
| RAM | 251.4 GiB |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hassaan, M.; Ott, P.A.; Dugstad, A.-K.; Torres, M.A.V.; Borrmann, A. Emergency Floor Plan Digitization Using Machine Learning. Sensors 2023, 23, 8344. https://doi.org/10.3390/s23198344
Hassaan M, Ott PA, Dugstad A-K, Torres MAV, Borrmann A. Emergency Floor Plan Digitization Using Machine Learning. Sensors. 2023; 23(19):8344. https://doi.org/10.3390/s23198344
Chicago/Turabian StyleHassaan, Mohab, Philip Alexander Ott, Ann-Kristin Dugstad, Miguel A. Vega Torres, and André Borrmann. 2023. "Emergency Floor Plan Digitization Using Machine Learning" Sensors 23, no. 19: 8344. https://doi.org/10.3390/s23198344
APA StyleHassaan, M., Ott, P. A., Dugstad, A.-K., Torres, M. A. V., & Borrmann, A. (2023). Emergency Floor Plan Digitization Using Machine Learning. Sensors, 23(19), 8344. https://doi.org/10.3390/s23198344