
Smart Data Placement Using Storage-as-a-Service Model for Big Data Pipelines
 , ,
, ,
Abstract
:1. Introduction
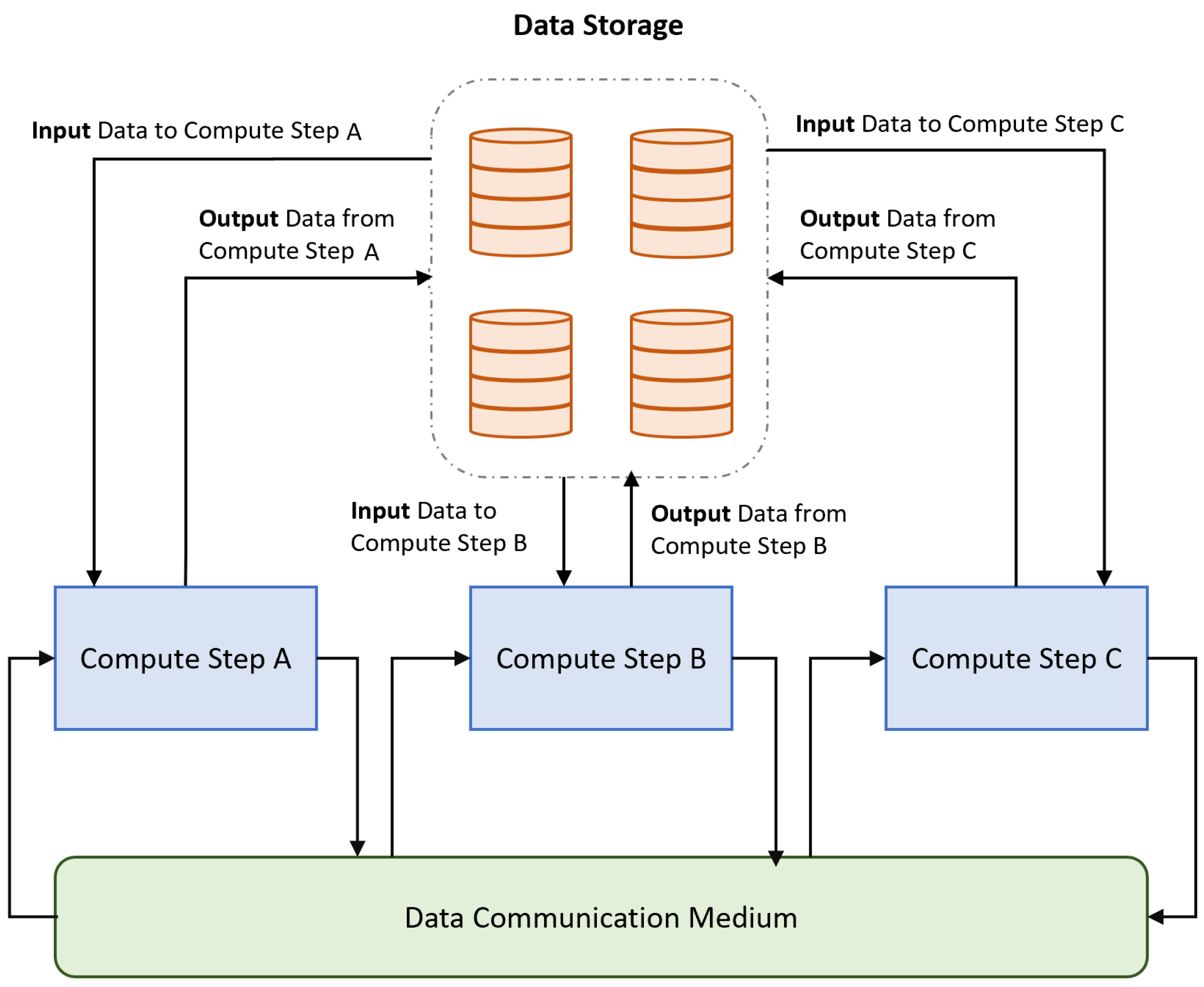
2. Background
3. Related Work
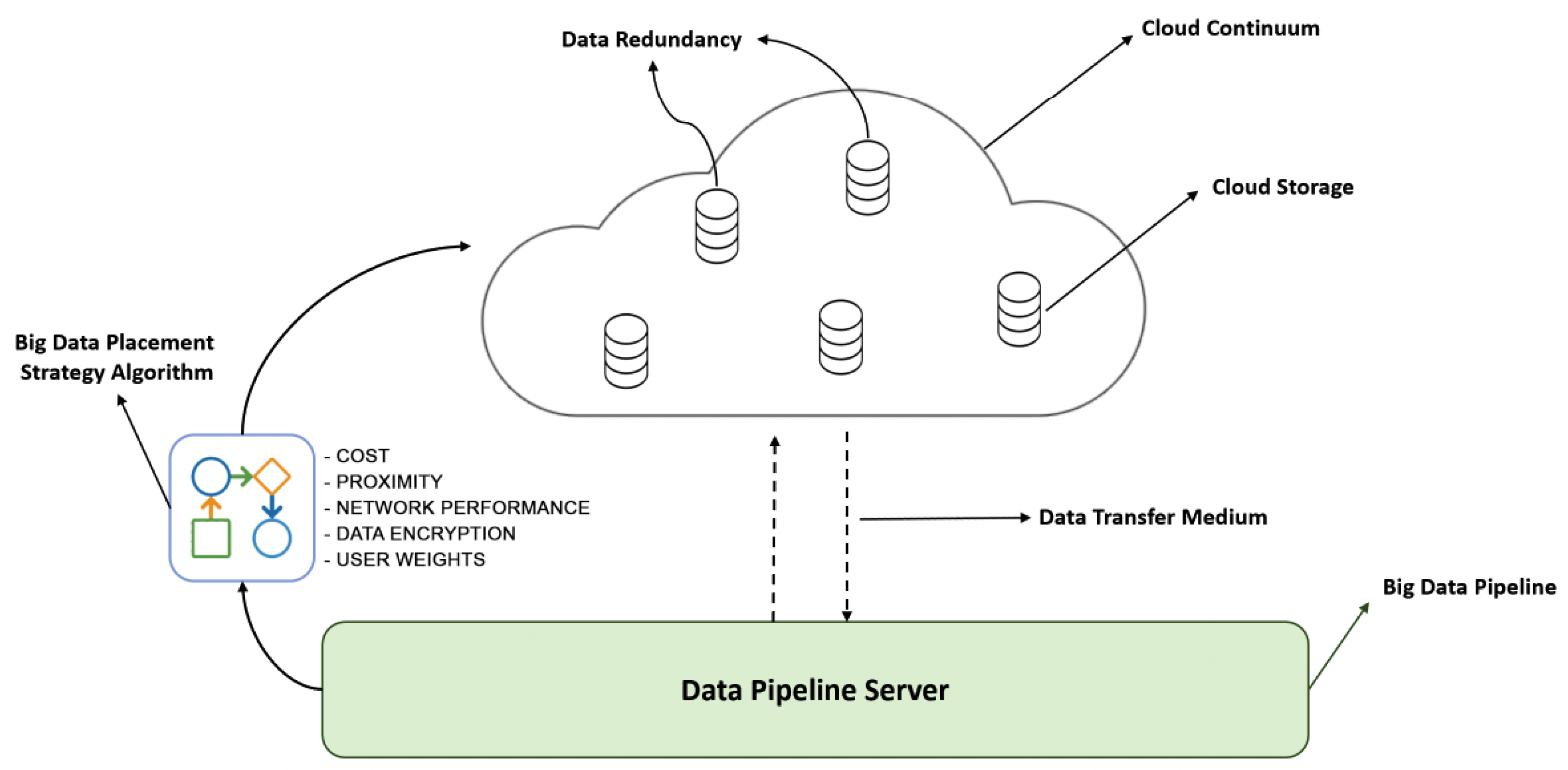
4. Smart Data Placement
4.1. Cost Model
4.2. Proximity
4.3. Network Performance
4.4. Server-Side Encryption
4.5. Ranking Method
4.5.1. Determine and Define the Alternatives and Criteria—Construct the Decision Matrix
4.5.2. Normalize the Decision Matrix
4.5.3. Obtain the Weighted Normalized Decision Matrix
4.5.4. Calculate the Values for and
4.5.5. Calculate the Values
4.5.6. Analyze the Results
- Condition 1 deals with the acceptable advantage.Assume that and are the first- and second-best alternatives, and is .If , it means Condition 1, an acceptable advantage is met.
- Condition 2 deals with the acceptable stability in decision-making.Alternative must also be the best-ranked by S and/or R.
5. Evaluation
5.1. Performance Comparison
5.2. Cost Comparison
5.3. User Scenarios
5.3.1. Scenario 1: Temporary Requirements
5.3.2. Scenario 2: Highly Variable Workloads
5.3.3. Scenario 3: High-Security, Low-Scale/Volume Solutions
5.3.4. Scenario 4: Dormant Workloads
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| STaaS | Storage-as-a-service |
| HDD | Hard disk drives |
| RAID | Redundant array of independent disks |
| EBS | Elastic block storage |
| HDFS | Hadoop Distributed File System |
References
- Barika, M.; Garg, S.; Zomaya, A.Y.; Wang, L.; Moorsel, A.V.; Ranjan, R. Orchestrating Big Data Analysis Workflows in the Cloud: Research Challenges, Survey, and Future Directions. ACM Comput. Surv. 2019, 52, 1–41. [Google Scholar] [CrossRef] [Green Version]
- Yousefpour, A.; Fung, C.; Nguyen, T.; Kadiyala, K.; Jalali, F.; Niakanlahiji, A.; Kong, J.; Jue, J.P. All one needs to know about fog computing and related edge computing paradigms: A complete survey. J. Syst. Archit. 2019, 98, 289–330. [Google Scholar] [CrossRef]
- Robinson, S.; Ferguson, R. The storage and transfer challenges of big data. MIT Sloan Manag. Rev. 2012, 7. Available online: https://sloanreview.mit.edu/article/the-storage-and-transfer-challenges-of-big-data/ (accessed on 15 November 2022).
- Mansouri, Y.; Toosi, A.N.; Buyya, R. Data Storage Management in Cloud Environments: Taxonomy, Survey, and Future Directions. ACM Comput. Surv. 2017, 50, 1–51. [Google Scholar] [CrossRef]
- Yang, C.; Xu, Y.; Nebert, D. Redefining the possibility of digital Earth and geosciences with spatial cloud computing. Int. J. Digit. Earth 2013, 6, 297–312. [Google Scholar] [CrossRef]
- Buyya, R.; Srirama, S.N.; Casale, G.; Calheiros, R.; Simmhan, Y.; Varghese, B.; Gelenbe, E.; Javadi, B.; Vaquero, L.M.; Netto, M.A.S.; et al. A Manifesto for Future Generation Cloud Computing: Research Directions for the Next Decade. ACM Comput. Surv. 2018, 51, 1–38. [Google Scholar] [CrossRef] [Green Version]
- Padgavankar, M.; Gupta, S. Big data storage and challenges. Int. J. Comput. Sci. Inf. Technol. 2014, 5, 2218–2223. [Google Scholar]
- Khan Quddus, A.; Nikolov, N.; Matskin, M.; Prodan, R.; Song, H.; Roman, D.; Soylu, A. Smart Data Placement for Big Data Pipelines: An Approach based on the Storage-as-a-Service Model. In Proceedings of the UCC 2022, Vancouver, WA, USA, 6–9 December 2022. [Google Scholar]
- Khan, A.Q. Smart Data Placement for Big Data Pipelines with Storage-as-a-Service Integration. Master’s Thesis, Norwegian University of Science and Technology, Trondheim, Norway, 2022. [Google Scholar]
- Celes, C.; Boukerche, A.; Loureiro, A.A.F. Crowd Management: A New Challenge for Urban Big Data Analytics. IEEE Commun. Mag. 2019, 57, 20–25. [Google Scholar] [CrossRef]
- De, S.; Jassat, U.; Wang, W.; Perera, C.; Moessner, K. Inferring Latent Patterns in Air Quality from Urban Big Data. IEEE Internet Things Mag. 2021, 4, 20–27. [Google Scholar] [CrossRef]
- El-Sayed, H.; Sankar, S.; Prasad, M.; Puthal, D.; Gupta, A.; Mohanty, M.; Lin, C.T. Edge of things: The big picture on the integration of edge, IoT and the cloud in a distributed computing environment. IEEE Access 2017, 6, 1706–1717. [Google Scholar] [CrossRef]
- Kimovski, D.; Mathá, R.; Hammer, J.; Mehran, N.; Hellwagner, H.; Prodan, R. Cloud, Fog, or Edge: Where to Compute? IEEE Internet Comput. 2021, 25, 30–36. [Google Scholar] [CrossRef]
- Ahmed, E.; Ahmed, A.; Yaqoob, I.; Shuja, J.; Gani, A.; Imran, M.; Shoaib, M. Bringing computation closer toward the user network: Is edge computing the solution? IEEE Commun. Mag. 2017, 55, 138–144. [Google Scholar] [CrossRef]
- Roman, D.; Prodan, R.; Nikolov, N.; Soylu, A.; Matskin, M.; Marrella, A.; Kimovski, D.; Elvesaeter, B.; Simonet-Boulogne, A.; Ledakis, G.; et al. Big Data Pipelines on the Computing Continuum: Tapping the Dark Data. IEEE Internet Comput. 2022, 55, 74–84. [Google Scholar] [CrossRef]
- Xiong, Z.; Zhang, Y.; Niyato, D.; Wang, P.; Han, Z. When Mobile Blockchain Meets Edge Computing. IEEE Commun. Mag. 2018, 56, 33–39. [Google Scholar] [CrossRef] [Green Version]
- Corodescu, A.A.; Nikolov, N.; Khan, A.Q.; Soylu, A.; Matskin, M.; Payberah, A.H.; Roman, D. Big data workflows: Locality-aware orchestration using software containers. Sensors 2021, 21, 8212. [Google Scholar] [CrossRef]
- Nikolov, N.; Dessalk, Y.D.; Khan, A.Q.; Soylu, A.; Matskin, M.; Payberah, A.H.; Roman, D. Conceptualization and scalable execution of big data workflows using domain-specific languages and software containers. Internet Things 2021, 16, 100440. [Google Scholar] [CrossRef]
- Elshater, Y.; Martin, P.; Rope, D.; McRoberts, M.; Statchuk, C. A Study of Data Locality in YARN. In Proceedings of the 2015 IEEE International Congress on Big Data, New York, NY, USA, 27 June–2 July 2015; pp. 174–181. [Google Scholar] [CrossRef]
- Renner, T.; Thamsen, L.; Kao, O. CoLoc: Distributed data and container colocation for data-intensive applications. In Proceedings of the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016; pp. 3008–3015. [Google Scholar] [CrossRef]
- Naik, N.S.; Negi, A.; B.R., T.B.; Anitha, R. A data locality based scheduler to enhance MapReduce performance in heterogeneous environments. Future Gener. Comput. Syst. 2019, 90, 423–434. [Google Scholar] [CrossRef]
- Zhao, Y.; Fei, X.; Raicu, I.; Lu, S. Opportunities and Challenges in Running Scientific Workflows on the Cloud. In Proceedings of the 2011 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery, Beijing, China, 10–12 October 2011; pp. 455–462. [Google Scholar] [CrossRef] [Green Version]
- Deelman, E.; Singh, G.; Livny, M.; Berriman, B.; Good, J. The cost of doing science on the cloud: The montage example. In Proceedings of the SC ’08: Proceedings of the 2008 ACM/IEEE Conference on Supercomputing, Austin, TX, USA, 15–21 November 2008; pp. 1–12. [Google Scholar] [CrossRef] [Green Version]
- Iosup, A.; Ostermann, S.; Yigitbasi, M.N.; Prodan, R.; Fahringer, T.; Epema, D. Performance analysis of cloud computing services for many-tasks scientific computing. IEEE Trans. Parallel Distrib. Syst. 2011, 22, 931–945. [Google Scholar] [CrossRef]
- Abouelhoda, M.; Issa, S.A.; Ghanem, M. Tavaxy: Integrating Taverna and Galaxy workflows with cloud computing support. BMC Bioinform. 2012, 13, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Altintas, I. Early cloud experiences with the kepler scientific workflow system. Procedia Comput. Sci. 2012, 9, 1630–1634. [Google Scholar] [CrossRef] [Green Version]
- Celesti, A.; Galletta, A.; Fazio, M.; Villari, M. Towards hybrid multi-cloud storage systems: Understanding how to perform data transfer. Big Data Res. 2019, 16, 1–17. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, W.; Song, J. A novel solution of distributed file storage for cloud service. In Proceedings of the 2012 IEEE 36th Annual Computer Software and Applications Conference Workshops, Izmir, Turkey, 16–20 July 2012; pp. 26–31. [Google Scholar] [CrossRef]
- Yuan, D.; Yang, Y.; Liu, X.; Chen, J. A data placement strategy in scientific cloud workflows. Future Gener. Comput. Syst. 2010, 26, 1200–1214. [Google Scholar] [CrossRef]
- Lee, C.W.; Hsieh, K.Y.; Hsieh, S.Y.; Hsiao, H.C. A dynamic data placement strategy for hadoop in heterogeneous environments. Big Data Res. 2014, 1, 14–22. [Google Scholar] [CrossRef]
- Wei-wei, L. An improved data placement strategy for Hadoop. J. South China Univ. Technol. (Nat. Sci. Ed.) 2012, 1, 28. [Google Scholar]
- Xie, J.; Yin, S.; Ruan, X.; Ding, Z.; Tian, Y.; Majors, J.; Manzanares, A.; Qin, X. Improving mapreduce performance through data placement in heterogeneous hadoop clusters. In Proceedings of the 2010 IEEE International Symposium on Parallel & Distributed Processing, Workshops and Phd Forum (IPDPSW), Atlanta, GA, USA, 19–23 April 2010; pp. 1–9. [Google Scholar] [CrossRef] [Green Version]
- Er-Dun, Z.; Yong-Qiang, Q.; Xing-Xing, X.; Yi, C. A data placement strategy based on genetic algorithm for scientific workflows. In Proceedings of the 2012 Eighth International Conference on Computational Intelligence and Security, Guangzhou, China, 17–18 November 2012; pp. 146–149. [Google Scholar] [CrossRef]
- Milani, O.H.; Motamedi, S.A.; Sharifian, S.; Nazari-Heris, M. Intelligent Service Selection in a Multi-Dimensional Environment of Cloud Providers for Internet of Things Stream Data through Cloudlets. Energies 2021, 14, 8601. [Google Scholar] [CrossRef]
- Ilieva, G.; Yankova, T.; Hadjieva, V.; Doneva, R.; Totkov, G. Cloud service selection as a fuzzy multi-criteria problem. TEM J. 2020, 9, 484. [Google Scholar] [CrossRef]
- Liu, S.; Zhang, C.; Chen, Y. HASG: Security and efficient frame for accessing cloud storage. China Commun. 2018, 15, 86–94. [Google Scholar] [CrossRef]
- Oki, E.; Kabeko, R.; Kitsuwan, N.; Kurimoto, T.; Urushidani, S. Cloud provider selection models for cloud storage services to satisfy availability requirements. IEICE Trans. Commun. 2017, E100.B, 1406–1418. [Google Scholar] [CrossRef]
- Xiahou, J.; Lin, F.; Huang, Q.; Zeng, W. Multi-datacenter cloud storage service selection strategy based on AHP and backward cloud generator model. Neural Comput. Appl. 2018, 29, 71–85. [Google Scholar] [CrossRef]
- Zhao, P.; Shang, J.; Lin, J.; Li, B.; Sun, X. A dynamic convergent replica selection strategy based on cloud storage. In Proceedings of the 2019 International Conference on Artificial Intelligence and Advanced Manufacturing (AIAM), Dublin, Ireland, 16–18 October 2019; pp. 473–478. [Google Scholar] [CrossRef]
- Mell, P. What’s Special about Cloud Security? IT Prof. 2012, 14, 6–8. [Google Scholar] [CrossRef]
- Wang, J.; Han, D.; Yin, J.; Zhou, X.; Jiang, C. ODDS: Optimizing Data-Locality Access for Scientific Data Analysis. IEEE Trans. Cloud Comput. 2020, 8, 220–231. [Google Scholar] [CrossRef]
- Toledo, K.; Breitgand, D.; Lorenz, D.; Keslassy, I. CloudPilot: Flow Acceleration in the Cloud. In Proceedings of the 2022 IFIP Networking Conference (IFIP Networking), Catania, Italy, 13–16 June 2022; pp. 1–9. [Google Scholar] [CrossRef]
- Sahin, B.; Yip, T.L.; Tseng, P.-H.; Kabak, M.; Soylu, A. An Application of a Fuzzy TOPSIS Multi-Criteria Decision Analysis Algorithm for Dry Bulk Carrier Selection. Information 2020, 11, 251. [Google Scholar] [CrossRef]
- Shao, M.; Han, Z.; Sun, J.; Xiao, C.; Zhang, S.; Zhao, Y. A review of multi-criteria decision making applications for renewable energy site selection. Renew. Energy 2020, 157, 377–403. [Google Scholar] [CrossRef]
- Ishizaka, A.; Nemery, P. Multi-Criteria Decision Analysis: Methods and Software; John Wiley & Sons: New York, NY, USA, 2013. [Google Scholar]
- Watróbski, J.; Jankowski, J.; Ziemba, P.; Karczmarczyk, A.; Zioło, M. Generalised framework for multi-criteria method selection. Omega 2019, 86, 107–124. [Google Scholar] [CrossRef]
- Opricović, S. Multicriteria Optimization of Civil Engineering Systems. Ph.D. Thesis, Faculty of Civil Engineering, University of Belgrade, Beograd, Serbia, 1998. [Google Scholar]
- Opricovic, S.; Tzeng, G.H. Compromise solution by MCDM methods: A comparative analysis of VIKOR and TOPSIS. Eur. J. Oper. Res. 2004, 156, 445–455. [Google Scholar] [CrossRef]
- Billur, E.; Aktas, A.; Kabak, M. Green supplier selection of a textile manufacturer: A hybrid approach based on AHP and VIKOR. MANAS J. Eng. 2019, 7, 126–135. [Google Scholar]
- Akram, M.; Kahraman, C.; Zahid, K. Group decision-making based on complex spherical fuzzy VIKOR approach. Knowl.-Based Syst. 2021, 216, 106793. [Google Scholar] [CrossRef]
- Bag, S. Fuzzy VIKOR approach for selection of big data analyst in procurement management. J. Transp. Supply Chain Manag. 2016, 10, 1–6. [Google Scholar] [CrossRef]
- Kazançoğlu, Y.; Sağnak, M.; Lafcı, Ç.; Luthra, S.; Kumar, A.; Taçoğlu, C. Big data-enabled solutions framework to overcoming the barriers to circular economy initiatives in healthcare sector. Int. J. Environ. Res. Public Health 2021, 18, 7513. [Google Scholar] [CrossRef]
- Rezaee, S.; Sadeghi-Niaraki, A.; Shakeri, M.; Choi, S.M. Personalized Augmented Reality Based Tourism System: Big Data and User Demographic Contexts. Appl. Sci. 2021, 11, 6047. [Google Scholar] [CrossRef]
- Çalı, S.; Balaman, Ş.Y. Improved decisions for marketing, supply and purchasing: Mining big data through an integration of sentiment analysis and intuitionistic fuzzy multi criteria assessment. Comput. Ind. Eng. 2019, 129, 315–332. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Azure (EU West) | AWS (EU Stockholm) | ||
|---|---|---|---|
| Space TB | Price Per GB | Space TB | Price Per GB |
| 0–50 | 0.02 | 0–50 | 0.023 |
| 51–500 | 0.0188 | 51–500 | 0.022 |
| 51–500 | 0.018 | 51–500 | 0.021 |
| Bandwidth IN | Price Per GB | Bandwidth IN | Price Per GB |
| All | 0.00 | All | 0.00 |
| Bandwidth OUT | Price Per GB | Bandwidth OUT | Price Per GB |
| 0-5 | 0.0 | 0–5 | 0.09 |
| 6–15 | 0.08 | 0–10 | 0.09 |
| 16–55 | 0.065 | 11–50 | 0.085 |
| 56–155 | 0.06 | 51–150 | 0.07 |
| 156–500 | 0.04 | >150 | 0.05 |
| Operations | Price Per 10,000 | Operations | Price Per 10,000 |
| Write | 0.07 | Write | 0.05 |
| Read | 0.006 | Read | 0.04 |
| Rank | Alternatives | Si | Ri | Qi |
|---|---|---|---|---|
| 1 | AWS | 0.25 | 0.15 | 0 |
| 2 | GCP | 0.28 | 0.25 | 0.52 |
| 3 | Azure | 0.75 | 0.25 | 1 |
| Rank | Alternatives | Si | Ri | Qi |
|---|---|---|---|---|
| 1 | Azure | 0.3 | 0.1 | 0 |
| 2 | AWS | 0.45 | 0.42 | 0.45 |
| 3 | GCP | 0.71 | 0.70 | 0 |
| Rank | Alternatives | Si | Ri | Qi |
|---|---|---|---|---|
| 1 | AWS | 0.08 | 0.06 | 0 |
| 2 | GCP | 0.10 | 0.10 | 0.04 |
| 3 | Azure | 0.90 | 0.80 | 1 |
| Rank | Alternatives | Si | Ri | Qi |
|---|---|---|---|---|
| 1 | GCP | 0.11 | 0.1 | 0.01 |
| 2 | AWS | 0.14 | 0.08 | 0.02 |
| 3 | Azure | 0.90 | 0.70 | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, A.Q.; Nikolov, N.; Matskin, M.; Prodan, R.; Roman, D.; Sahin, B.; Bussler, C.; Soylu, A. Smart Data Placement Using Storage-as-a-Service Model for Big Data Pipelines. Sensors 2023, 23, 564. https://doi.org/10.3390/s23020564
Khan AQ, Nikolov N, Matskin M, Prodan R, Roman D, Sahin B, Bussler C, Soylu A. Smart Data Placement Using Storage-as-a-Service Model for Big Data Pipelines. Sensors. 2023; 23(2):564. https://doi.org/10.3390/s23020564
Chicago/Turabian StyleKhan, Akif Quddus, Nikolay Nikolov, Mihhail Matskin, Radu Prodan, Dumitru Roman, Bekir Sahin, Christoph Bussler, and Ahmet Soylu. 2023. "Smart Data Placement Using Storage-as-a-Service Model for Big Data Pipelines" Sensors 23, no. 2: 564. https://doi.org/10.3390/s23020564