Abstract
Media content forgery is widely spread over the Internet and has raised severe societal concerns. With the development of deep learning, new technologies such as generative adversarial networks (GANs) and media forgery technology have already been utilized for politicians and celebrity forgery, which has a terrible impact on society. Existing GAN-generated face detection approaches rely on detecting image artifacts and the generated traces. However, these methods are model-specific, and the performance is deteriorated when faced with more complicated methods. What’s more, it is challenging to identify forgery images with perturbations such as JPEG compression, gamma correction, and other disturbances. In this paper, we propose a global–local facial fusion network, namely GLFNet, to fully exploit the local physiological and global receptive features. Specifically, GLFNet consists of two branches, i.e., the local region detection branch and the global detection branch. The former branch detects the forged traces from the facial parts, such as the iris and pupils. The latter branch adopts a residual connection to distinguish real images from fake ones. GLFNet obtains forged traces through various ways by combining physiological characteristics with deep learning. The method is stable with physiological properties when learning the deep learning features. As a result, it is more robust than the single-class detection methods. Experimental results on two benchmarks have demonstrated superiority and generalization compared with other methods.
1. Introduction
With the development of generative adversarial networks (GANs) [1], massive GAN-based deepfake methods are proposed to replace, modify, and synthesize human faces. The GAN-based deepfake methods can be divided into two main categories, i.e., the facial replacement-based methods and the expression attribute modification-based methods. The facial replacement methods [2,3,4] exchange two faces by style conversion [5] and face reconstruction [6] to modify the identities of two persons. Expression attribute methods leverage the expressions or actions of a person to manipulate the target person, which includes personal image reconstruction [7], rendering network [8,9], expression migration [10], and expression matching [11]. Recently, mobile phone applications with deepfake methods, such as ZAO and Avatarify, have been utilized commercially and have achieved great success.
Due to the malicious use of the above deepfake methods, media credibility has been seriously endangered, resulting in negative impacts on social stability and personal reputation. Various deepfake detection methods have been proposed to reduce the negative impacts. Some methods [12,13,14] focus on detecting local regions such as the eye, nose, lip, and other facial parts to find out the forgery traces. Matern et al. [12] propose detection of forgeries through the missing details and light reflection in eyes and teeth regions. Meanwhile, they also use discordant features such as facial boundaries and nose tips to detect forgery. Hu et al. [14] propose judging image authenticity by modeling the consistency of highlighted patterns on the corneas of both eyes. Nirkin et al. [13] introduce a semantic context recognition network based on hair, ears, neck, etc. Meanwhile, some approaches [15,16,17] detect the whole face to find the forgery trace. For instance, Wang et al. [17] propose a multi-modal multi-scale transformer model to detect local inconsistencies on different spatial levels. The classification methods enable the model to distinguish real images from fake ones by extracting image features and using data-driven approaches. Nataraj et al. [15] propose judging the generator noises by combining a co-occurrence matrix. Chen et al. [16] propose combining the space domain, frequency domain, and attention mechanism for fake trace identification. In general, the detection method based on physical features is robust. However, with the evolution of synthetic methods, forgery traces have become less noticeable, which limits the physical detecting approaches.
In recent years, some approaches [18,19,20] have synthesized the local and global features to detect forgeries. The above methods focus on the point that GAN-generated faces are more likely to produce traces in local regions, so they strengthen the forgery detection in the local area and use it to supply the global detection results.
In this paper, we establish a deepfake detection method to detect the deepfake images generated by GANs. Our approach comprises a global region branch for global information detection and a local region branch for eyes’ physical properties detection. The contributions of our work are summarized as follows:
- (1)
- We establish a mechanism to identify forgery images by combining both physiological methods, such as iris color, pupil shape, etc., and deep learning methods.
- (2)
- We propose a novel deepfake detection framework, which includes a local region detection branch and a global detection branch. The two branches are trained end-to-end to generate comprehensive detection results.
- (3)
- Extensive experiments have demonstrated the effectiveness of our method in detection accuracy, generalization, and robustness when compared with other approaches.
2. Related Work
GAN-generated face detection methods can be divided into two categories, i.e., the detection method based on the physical properties and the classification method using deep learning methods [21,22]. Among them, the physiological properties are mainly to detect the forgery traces. Meanwhile, the deep learning detection methods are primarily focused on global image information.
2.1. Physical Properties Detection Method
Physical properties’ detection is to detect inconsistencies and irrationalities caused by the forgery process, from physical device attributes to physiological inconsistencies.
Using physical devices such as cameras and smartphones, particular traces will be left out, which can be regarded as fingerprints for forensics. The image can be identified as a forgery if multiple fingerprints exist in the same image. Most of the methods aim to detect the fingerprint of an image [23] to determine the authenticity, including the detection method based on the twin network [24] and the comparison method based on CNN [25]. Face X-ray [26] converts facial regions into X-rays to determine if those facial regions are from a single source.
Physiological inconsistencies play a vital role in image or video deepfake detection. These methods detect the physiological signal features from contextual environments or persons, including illumination mistakes, the reflection of the differences in human eyes and faces, and blinking and breathing frequency disorders.
These methods include:
- (1)
- Learning human physiology, appearance, and semantic features [12,13,14,27,28] to detect forgeries.
- (2)
- Using 3D pose, shape, and expression factors to detect manipulation of the face [29].
- (3)
- Using the visual and sound consistency to distinguish the multi-modal approaches [30].
- (4)
- Using the artifact identification of affected contents through Daubechies wavelet features [31] and edge features [32].
The physical detection methods are generally robust, especially in detecting the GAN-generated face. However, with the improvement of the GAN model, the artifact of synthetic image is no longer apparent, and the applicability of some detection methods is weakened.
2.2. Deep Learning Detection Method
Deep learning detection method is the most commonly used in forgery detection. Earlier methods included the classification of forgery contents by learning the intrinsic features [33], the generator fingerprint [34] of images generated by GANs, the co-occurrence matrix inconsistency [15] detection in the color channel, the inconsistency between spectral bands [35], or detection of synthetic traces of the CNN model [36,37,38]. However, with the development of generation approaches, the forgery trace is becoming challenging to be detected.
Meanwhile, most of the studies try to solve the problem caused by superimposed noise. Hu et al. [39] proposed a two-stream method by analyzing the frame-level and temporality-level of compressed deepfake media, aiming to detect the forensics of compressed videos. Chen et al. [40] considered both the luminance components and chrominance components of dual-color spaces to detect the post-processed face images generated by GAN. He et al. [41] proposed to re-synthesize the test images and extract visual cues for detection. Super-resolution, denoising, and colorization are also utilized in the re-synthesis. Zhang et al. [42] proposed an unsupervised domain adaptation strategy to improve the performance in the generalization of GAN-generated image detection by using only a few unlabeled images from the target domain.
With the deepening of research, some current methods utilize the local features of the face to enhance the global features to obtain more acceptable results. Ju et al. [18] proposed a two-branch model to combine global spatial information from the whole image and local features from multiple patches selected by a novel patch selection module. Zhao et al. [20] proposed a method containing global information and local information. The fusion features of the two streams are fed into the temporal module to capture forgery clues.
The deep learning detection method uses the deep learning model to detect the synthetic contents. Most processes take the entire image as input. Meanwhile, the physical properties of the image are not fully considered. Many approaches still have space for progress.
This paper proposes a global–local dual-branch GAN-generated detection framework by combining the physical properties and deep learning. Specifically, the local region detection branch aims to extract iris color and pupil shape artifacts. The global detection branch is devoted to detecting the holistic forgery in images. The evaluation is based on the fusion results from those two branches by a ResNeSt model. Finally, a logical operation determines the forgery images.
3. Proposed Method
In this section, we elaborate the dual-branch architecture GLFNet, which is combined with the physical properties and deep learning method. The local region detection branch is adopted for consistent judgment of physiological features, including iris color comparison and pupil shape estimation. Meanwhile, the global detection branch detects global information from the image residuals. Following ResNeSt [43], we extract the residual features and classify them. Finally, we use a classifier to predict the results of the two branches by logical operation. The overall architecture is shown in Figure 1.
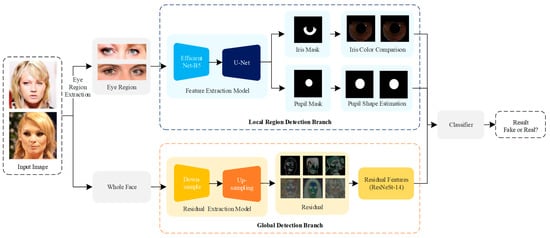
Figure 1.
The pipeline of the proposed method. We utilize the local region feature extraction branch to extract the local region features and employ the global feature extraction branch to obtain the residual feature. Meanwhile, a classifier fuses the physical and global elements to estimate the final result.
3.1. Motivation
Existing forgery detection approaches [12,14] are encountered with inconsistencies and traces that appear in local areas. Some methods [41,44] use global features to detect forgery. However, the results show that the critical region, such as the eyes, has more different features than other areas.
Figure 2a [41] illustrates the results by detecting the artifacts of the perceptual network at the pixel- and stage5-level, in which artifacts are more easily detected in eyes, lips, and hair. Figure 2b [44] adopts a schematic diagram of residual error-guided attention, catching the apparent residuals in the eyes, nose, lips, and other vital regions.

Figure 2.
The feature visualization of [41,44]. (a) Pixel-level (left) and Stage 5-level (right). (b) Residual guided attention model.
Based on this, we propose a novel framework to combine the local region and global full-face detection. We use iris color comparison and pupil shape estimation in local region detection to provide more robust detection results and assist the global detection branch.
3.2. Local Region Detection Branch
The local region detection branch is designed to model the local regions’ consistency and illumination, including iris and pupil segmentation, iris color comparison, and pupil shape estimation.
3.2.1. Iris and Pupil Segmentation
We utilize the HOG SVM shape predictor in the Dlib toolbox to obtain 68 facial coordinate points in the face ROI. The eye landmarks extracted as local regions are illustrated in Figure 3a. The white line takes a landmark from the eyes, the red box takes the iris, the yellow box takes the pupil, and the blue arrows point to the sclera.
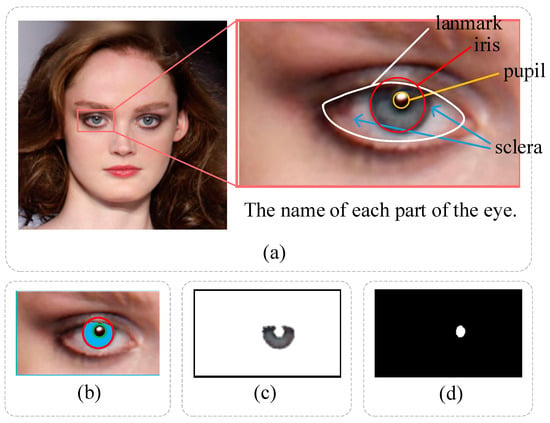
Figure 3.
Schematic diagram of eye detection. (a) interception of the eye region. (b) the iris and pupil regions were segmented by EyeCool. (c) the iris region for color detection. (d) the pupil region for shape detection.
Following [45], we segment the iris and pupil regions using EyeCool, which adopts the U-Net [46] as the backbone. The segmentation results are shown in Figure 3b. EyeCool employs EfficientNet-B5 [47] as an encoder and U-Net as a decoder. Meanwhile, the decoder comprises a boundary attention module, which can improve the detection effect on the object boundary.
3.2.2. Iris Color Detection
In an actual image, the pupil color of a person’s left and right eyes is supposed to be the same. However, some GAN-generated images do not consider the pupil color globally. As shown in Figure 4a, the color differences between the left and right eyes are obvious. Like the first image in row 1, the left eye’s iris is blue, and the right is brown, which does not happen in common people. At the same time, we also listed the iris colors in two authentic images. As shown in the two right pictures of Figure 4a, the iris colors of the left and right eyes are the same. Therefore, we can detect inconsistencies in terms of iris color to distinguish the GAN-generated images.
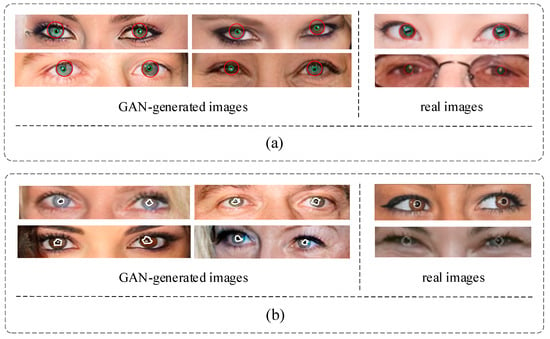
Figure 4.
The example of the iris color and pupil boundary in real and GAN-generated images. (a) iris color. (b) pupil boundary.
We tag the left and right iris regions as and from EyeCool, as shown in Figure 3c. The differences of and in RGB color space are calculated as:
where , , , , , and are average values of R, G, and B of the left and right eye pixels after segmentation.
3.2.3. Pupil Shape Estimation
In the actual image, the shape of the pupils is mainly oval, as shown in the two right pictures of Figure 4b. The pupil regions of the actual image are marked by the white line. However, the pupils generated by GAN may have irregular shapes, as shown in the four left pictures of Figure 4b, which show the pupil shape difference between the left and right eyes. The irregular pupil shape is marked by the white lines, which would not occur in natural images.
After Figure 3b, we employ the ellipse fitting method for the pupil boundary, such as in Figure 3d. Following [48], we use the least squares fitting approach to determine the ellipse parameter’s to make the parameter ellipse and pupil boundary points as close as possible. We calculate the algebraic distance of a 2D point to the ellipse by:
where denotes the transpose operation, and to are the parameters of general ellipse [49]. Meanwhile, the best result is . Moreover, we minimize the sum of squared distances (SSD) at the pupil boundary, and we show the pseudo-code in Algorithm 1.
where L represents two paradigm forms, and w is a constant decremented in each round. We avoid the trivial solution of and ensure the positive definiteness.
| Algorithm 1 Pseudo-code of SSD |
| Input: ,, epochs Output:
|
After that, we use Boundary IoU (BIoU) to evaluate the pupil mask pixels. The bigger the BIoU value is, the better the boundary-fitting effect.
where is the predicted pupil mask, and is the fitted ellipse mask. controls the sensitivity of the formula, and it is directly proportional to the boundary fitting sensitivity. and mean the mask pixels within distance from the expected and fitted boundaries. Following [48], we take in pupil shape estimation.
3.3. Global Detection Branch
The global detection branch is mainly used to classify the natural and generated faces by calculating the residual from the images, which contains downsampling, upsampling, and residual feature extraction.
3.3.1. Downsample
In the global detection branch, we perform a downsampled in image by four times operation, to provide space for upsampling in the global detection branch.
where represents the four times downsampling function, and represents downsampling image.
3.3.2. Upsampling
We employ a super-resolution model to upsample the image to obtain its residuals. Following [41], we utilize the pre-trained perceptual loss to train to enhance the detection of high-level information, which is made by [50] and supervised by the pixel loss as well as the VGG-based perceptual loss [51,52].
In the training stage, is trained by the real set . The loss function of the regression task is formulated as follows:
where is a hyper-parameter to control the feature importance during the training process. And represents the feature extractor. The loss function is calculated by the sparse first normal form mapping on each stage for calculation convenience.
3.3.3. Residual Features Extraction
After training , we construct a union dataset using and . The union dataset is used to train the ResNeSt-14, extract the residual image features, and classify them. The input of the ResNest-14 is a residual feature map of size . The network radix, cardinality, and width are set to 2, 1, and 64, respectively.
Following [41], the detection result is calculated as:
where is a pixel-level classifier. is a classifier at the different perceptual loss training stage. is used to control the importance of the classifier.
3.4. Classifier
We employ and fuse the three results , , and from the two branches. The detection result is actual if all the results satisfy the accurate parameters. We can calculate the fusion results as :
where , , and are the judgment thresholds.
4. Experiments
4.1. Dataset
4.1.1. Real Person Data
CelebA [53]: The CelebA dataset includes 10,177 identities and 202,599 aligned face images, which are used as the natural face dataset.
CelebA-HQ [14]: The CelebA-HQ is derived from CelebA images, which contains 30k 10241024 images. Following [41], we use 25k real images and 25k fake images as the training set, and we use 2.5k real images and 2.5k fake images as the testing set.
FFHQ [54]: FFHQ consists of 70,000 high-quality images at 1024 × 1024 resolution. It includes more variation than CelebA-HQ regarding age, ethnicity, and image background. Additionally, it has coverage of accessories such as eyeglasses, sunglasses, hats, etc.
4.1.2. GAN-Generated Methods
ProGAN [4]: ProGAN is used to grow both the generator and discriminator progressively. It starts from a low resolution, and the authors add new layers that model increasingly fine details as training progresses. Meanwhile, the authors construct a higher-quality version of the CelebA dataset.
StyleGAN [54]: StyleGAN is an architecture with an automatically learned, unsupervised separation of high-level attributes and borrowing from style transfer literature. It considers high-level features and stochastic variation during training, making the generated content more intuitive. At the same time, the author proposed the corresponding dataset.
StyleGAN2 [55]: Based on StyleGAN, StyleGAN2 redesigned the generator normalization, revisited progressive growing, and regularized the generator to encourage good conditioning in the mapping from latent codes to images.
4.2. Implementation Details
In the local region detection branch, the length of the eye regions is resized to 1000 pixels. We utilized ResNeSt as a feature extractor in the global detection branch. The comparison methods include PRNU [34], FFT-2d magnitude [38], Re-Synthesis [41], Xception [36], and GramNet [56], etc.
Meanwhile, we also perform the experiments of hyper-parameter analysis in ablation studies such as , , and .
4.3. Results and Analysis
4.3.1. Ablation Study
We test our approach on CelebA-HQ dataset. Using ProGAN and StyleGAN to generate images, each category has 2500 pictures [41]. We chose 1250 synthesized images and mixed them with 1250 authentic images to make up the test dataset. We utilized an ablation study to test the local region detection branch and verify the noise immunity of the physical detection method.
Ablation Study in Hyper-Parameter Analysis
Table 1 shows the correlation between the RGB scores in the left and right eye. The value of will influence the detection of the eye color. We set five groups of pixel comparison experiments, including 1, 3, 5, 7, and 9 to select the optimal comparison results when and .

Table 1.
Hyper-parameter analysis in iris color detection (Test criteria adopt accuracy (%)).
We can conclude from Table 1 that and false positives have negative correlation, and and missed detection rate have positive correlation. Therefore, obtaining a balance is necessary. Based on the experimental results, we adopted as the parameter in subsequent experiments.
Table 2 shows the hyper-parameter analysis in pupil shape estimation. We conduct parameter ablation studies of varying in [0.1, 0.3, 0.5, 0.7, 0.9] when and .
Table 2.
Hyper-parameter analysis in pupil shape estimation (Test criteria adopt accuracy (%)).
In Table 2, the model has achieved the best result when . Meanwhile, Table 3 shows the hyper-parameter analysis in the global detection branch. We also set a five-group parameter experiment of varying in [0.1, 0.3, 0.5, 0.7, 0.9] when and . And we can see from Table 3 that the best result is obtained when .
Table 3.
Hyper-parameter analysis in global detection (Test criteria adopt accuracy (%)).
Ablation Study in Local Detection Branch
We set the different groups, including raw images (Raw) and noisy images. The noise types include spectrum regularization (+R), spectrum equalization (+E), spectral-aware adversarial training (+A), and an ordered combination of image perturbations (+P), which is shown in Table 4. In addition, the ICD represents iris color detection result, PSE represents pupil shape estimation result, LRD (All) represents the local region detection result combining the two methods, NUM represents the number of detected forged images, and ACC (%) represents accuracy rate.
Table 4.
The ablation study in the local region detection branch using ProGAN and StyleGAN. (Test criteria adopt accuracy (%)).
The experimental results show that both ICD and PSE can detect forgery images. The ICD can identify the color of the left and right iris. If the image is below the threshold, it will be identified as a forgery, as shown in Figure 5a. Additionally, the PSE can identify images with pupil abnormalities, as shown in Figure 5b. Furthermore, LRD (All) has a slightly higher detection accuracy than the two detection methods, which also demonstrates the stability of the branch. We utilize LRD (All) as the local region detection branch results in subsequent experiments.
Figure 5.
Example of ICD and PSE detection results. (a) the forgery images detected by the ICD. (b) the forgery images detected by the PSE.
Ablation Study in Two Branches
We test the effects of the local region detection branch and global detection branch in Table 5. The LRD evaluates the effectiveness of the local region detection branch. GD refers to the global detection branch. Dual refers to the detection results combining both the LRD and the GD. Experiment shows that the dual-branch detection result outperforms each single-branch detection result. Meanwhile, we only utilize the authentic images to train the feature extractor of the global detection branch.
Table 5.
The ablation study in two branches (Test criteria adopt accuracy (%)).
Figure 6 shows the visualization results in the global detection branch. Figure 6a shows the residuals of the actual images, and Figure 6b shows the residuals of the fake images. We can see that the features of residual graphs from real and fake images are different. We train the classifier to distinguish the difference.

Figure 6.
Example of the residual images extracted from the global detection branch. (a) The real image groups. (b) The fake image groups.
4.3.2. Noise Study
In this section, we set a noise study to test the robustness of our method. We compare our approach with baselines in CelebA-HQ, including PRNU [34], FFT-2d magnitude [38], GramNet [56], and Re-Synthesis [41]. As shown in Table 6, the results are referred from [22,41]. “ProGAN -> StyleGAN” denotes utilizing ProGAN for training and using StyleGAN for testing.
Table 6.
Comparison of classification accuracy (%) with baselines.
From Table 6, double-branch detection is more effective than the single branch from the average accuracy. Furthermore, double-branch detection is more generalized and robust. Compared with Re-Synthesis [41], our method has shown some advantages in all groups. Primarily our approach performs well in the experimental group of +P, and the accuracy is stable between 83.3% and 86.9%. We noticed that the local detection branch is stable, with accuracy between 82.6% and 93.1%. It proves that our approach has specific stability in processing fake images with superposition noise.
Meanwhile, we observe that the dual branches have complementary performances. Like Figure 7a, the upper line shows the human face that was only detected by the local branch, and the lower line shows the results only detected from the global branch.

Figure 7.
Example of complementary performances in two branches. (a) the image detected by the local branch. (b) the image detected by the global branch.
The local branch is straightforward in detecting the anomalies and changes in physical features, such as iris color changes and pupil shape changes, which can effectively complement the detection results of the global detection branch. Meanwhile, the global branch can also detect the GAN-generated images with complete physical properties.
4.3.3. Comparison with the Physical Approaches
Following [57], we set the AUC comparison experiment to verify the effectiveness of our method, which mainly compares some state-of-the-art methods in physical theory. We selected four typical methods [12,14,48,58] that provide AUC scores. Hu et al. [14] and Guo et al. [48] employed the actual images from FFHQ and used StyleGAN2 to make synthetic images. Matern et al. [12] selected 1000 real images in CelebA as the actual image and used ProGAN to produce the synthesis image. The actual images with enlarged sizes had the lowest AUC (0.76). Yang et al. [58] selected more than 50,000 real images in CelebA and used ProGAN for image synthesis. The lowest AUC (0.91) is derived from color classification, and the highest AUC (0.94) is derived from the K-NN classification.
We set up three groups of experiments. The first group chose 1000 real images in FFHQ and used StyleGAN2 as the generated method. The second and third ones selected 1000 images in CelebA as the actual image, using ProGAN as the generated method. Meanwhile, we set the source image size to be enlarged and reduced by 50% to verify the robustness, as shown in Table 7: “raw” means raw images, “u-s” means the image after 50% upsampling, “d-s” means the image after 50% downsampling. Some of the results are excerpted from [57].
Table 7.
Comparison of classification AUC (%) with state-of-the-art methods.
Experimental results show that our method is significantly better on AUC, because the global detection branch with the deep learning model can detect the images without evident physical traces, as shown in Figure 8. There are some synthetic images generated by ProGAN. The physical properties of the first three images are realistic, while the last three use some stylizing methods. The forgery of these images is not apparent, which makes detection by the local branch challenging. These images require the global branch for detection.
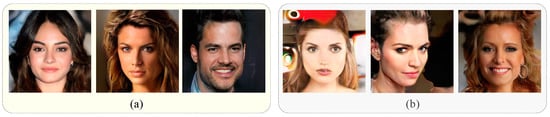
Figure 8.
Example of images that are not easy to be detected by local branches. (a) the images without the apparent physical traces. (b) the images with style transfer.
Meanwhile, we also compared the influence of image upsampling and downsampling in our method. We made a line chart for the last three rows in Table 7, as shown in Figure 9. The results show that our method is robust when equipped with image sampling, which proved that the physical method has some influence.
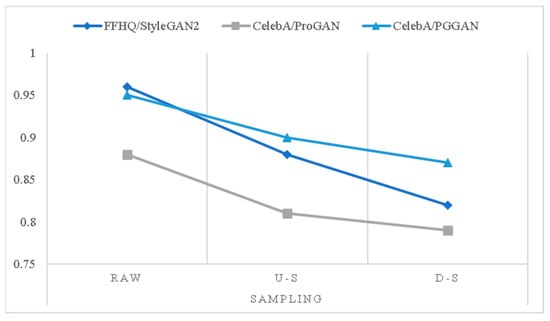
Figure 9.
The line chart from Table 7.
4.3.4. Comparison with the State-of-the-Arts
Comparative Experiment
We followed the results in [42] and conducted the experiments to compare with the state-of-the-art methods, as shown in Table 8, where all the images in the target domain are unlabeled.
Table 8.
Comparison of classification accuracy (%) with state-of-the-art methods.
Experiments prove that our method has higher accuracy than others. The early approach cannot detect all types of GAN-generated images. For example, when using Mi’s method [37] to find the faces made by StyleGAN, the accuracy rate is only 50.4%, while the methods proposed recently have a certain degree of robustness.
Experiments with Post-Processing Operations
Following [40], we used the CelebA dataset [53] to obtain 202,599 face images generated by ProGAN [4]. Meanwhile, we also set several widely used post-processing operations, such as JPEG compression with different compression quality factors (JPEG compression/compression quality) 90, 70, and 50; gamma correction with different gamma values (gamma correction/gamma) 1.1, 1.4, and 1.7; median blurring with different kernel sizes (median blurring/kernel size) 3 × 3, 5 × 5, and 7 × 7; Gaussian blurring with different kernel sizes (Gaussian blurring/kernel size) 3 × 3, 5 × 5, and 7 × 7; Gaussian noising with different standard deviation values (Gaussian noising/standard deviation) 3, 5, and 7; and resizing with the upscaling factor (resizing/upscaling) of 1%, 3%, and 5%. The images are center-cropped with size 128 × 128. The state-of-the-art methods include Xception [36], GramNet [56], Mi’s method [37], and Chen’s method [40].
We followed the results in [40] and tested our proposed method. The detection accuracies of the state-of-the-art methods are shown in Table 9. We can conclude from Table 9 that our approach has a good performance in classification accuracy. Meanwhile, Figure 9 shows the line chart from Table 9: the X-axis represents the disturbance parameters, and the y-axis represents the accuracy. We observed that our approach is more stable in all groups. As shown in Figure 10, our approach shows better adaptability in JPEG compression, gamma correction, and other disturbances. With the limiting threshold becoming worse, such as the lower JPEG compression rate and a larger kernel size of Gaussian blurring, the accuracy of our method has little impact. It is because the physical method is not sensitive to image scaling, filling, noise, and other disturbances. The robustness of the model is improved.
Table 9.
Comparison of classification accuracy (%) in post-processing operations with state-of-the-art methods.
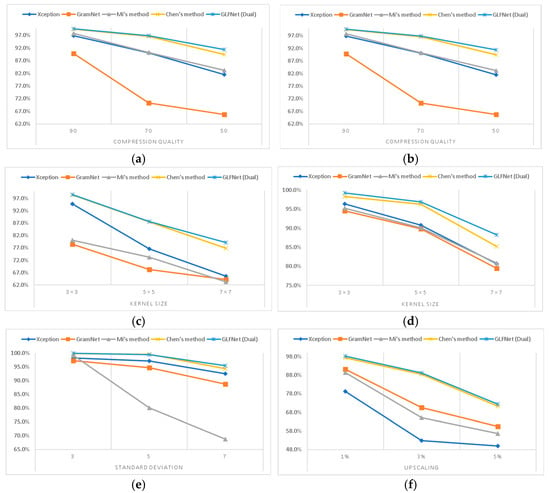
Figure 10.
The line chart from Table 9. (a) JPEG compression. (b) gamma correction. (c) median blurring. (d) Gaussian blurring. (e) Gaussian noising. (f) resizing.
5. Conclusions and Outlook
In this paper, we proposed a novel deepfake detection method that integrates global and local facial features, namely GLFNet. GLFNet comprises a local region detection branch and a global detection branch, which are designed for forgery detection on iris color, pupil shape, and forgery trace in the whole image. It delivers a new deepfake detection method that combines physiological and deep neural network methods.
Four kinds of experiments are conducted to verify the effectiveness of our method. Firstly, we demonstrated the effectiveness of two branches using ablation studies. Secondly, we tested the anti-interference performance of our approach. Thirdly, we demonstrated the effectiveness of our method against the physical detection methods. Finally, we set experiment groups to evaluate the method’s accuracy with state-of-the-art methods. The added noises include JPEG compression, gamma correction, median blurring, Gaussian blurring, Gaussian noising, and resizing. Experiments show that our method is robust because the local detection branch adopts the physiological detection strategy, which can adapt to image noise and disturbance. In future work, we will research the physical attributes in cross-datasets.
Author Contributions
Conceptualization, Z.X. and X.J.; methodology, Z.X.; software, Q.L.; validation, Z.X.; formal analysis, Z.X.; investigation, Z.X. and Z.W.; writing—original draft preparation, Z.X. and Q.L.; writing—review and editing, X.J. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Fiscal Expenditure Program of China under Grant 130016000000200003 and partly by the National Key R&D Program of China under Grant 2021YFC3320100.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8789–8797. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D.N. Stackgan++: Realistic image synthesis with stacked generative adversarial networks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1947–1962. [Google Scholar] [CrossRef]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of GANs for improved quality, stability, and variation. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Korshunova, I.; Shi, W.; Dambre, J.; Theis, L. Fast face-swap using convolutional neural networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3677–3685. [Google Scholar]
- Nirkin, Y.; Keller, Y.; Hassner, T. Fsgan: Subject agnostic face swapping and reenactment. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 7184–7193. [Google Scholar]
- Thies, J.; Zollhöfer, M.; Theobalt, C.; Stamminger, M.; Nießner, M. Headon: Real-time reenactment of human portrait videos. ACM Trans. Graph. (TOG) 2018, 37, 164. [Google Scholar] [CrossRef]
- Kim, H.; Garrido, P.; Tewari, A.; Xu, W.; Thies, J.; Niessner, M.; Pérez, P.; Richardt, C.; Zollhöfer, M.; Theobalt, C. Deep video portraits. ACM Trans. Graph. (TOG) 2018, 37, 163. [Google Scholar] [CrossRef]
- Thies, J.; Zollhöfer, M.; Nießner, M. Deferred neural rendering: Image synthesis using neural textures. ACM Trans. Graph. (TOG) 2019, 38, 66. [Google Scholar] [CrossRef]
- Lample, G.; Zeghidour, N.; Usunier, N.; Bordes, A.; Denoyer, L.; Ranzato, M.A. Fader networks: Manipulating images by sliding attributes. Adv. Neural Inf. Process. Syst. 2017, 30, 5967–5976. [Google Scholar]
- Averbuch-Elor, H.; Cohen-Or, D.; Kopf, J.; Cohen, M.F. Bringing portraits to life. ACM Trans. Graph. (TOG) 2017, 36, 196. [Google Scholar] [CrossRef]
- Matern, F.; Riess, C.; Stamminger, M. Exploiting visual artifacts to expose deepfakes and face Manipulations. In Proceedings of the 2019 IEEE Winter Applications of Computer Vision Workshops (WACVW), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 83–92. [Google Scholar]
- Nirkin, Y.; Wolf, L.; Keller, Y.; Hassner, T. DeepFake detection based on discrepancies between faces and their context. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 6111–6121. [Google Scholar] [CrossRef]
- Hu, S.; Li, Y.; Lyu, S. Exposing GAN-generated Faces Using Inconsistent Corneal Specular Highlights. In Proceedings of the ICASSP 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 2500–2504. [Google Scholar]
- Nataraj, L.; Mohammed, T.M.; Manjunath, B.S.; Chandrasekaran, S.; Flenner, A.; Bappy, J.H.; Roy-Chowdhury, A.K. Detecting GAN generated fake images using co-occurrence matrices. Electron. Imaging 2019, 2019, 532-1–532-7. [Google Scholar] [CrossRef]
- Chen, Z.; Yang, H. Manipulated face detector: Joint spatial and frequency domain attention network. arXiv 2020, arXiv:2005.02958. [Google Scholar]
- Wang, J.; Wu, Z.; Chen, J.; Han, X.; Chen, J.; Jiang, Y.G.; Li, S.N. M2TR: Multi-modal Multi-scale Transformers for Deepfake Detection. arXiv 2021, arXiv:2104.09770. [Google Scholar]
- Ju, Y.; Jia, S.; Ke, L.; Xue, H.; Nagano, K.; Lyu, S. Fusing Global and Local Features for Generalized AI-Synthesized Image Detection. arXiv 2022, arXiv:2203.13964. [Google Scholar]
- Chen, B.; Tan, W.; Wang, Y.; Zhao, G. Distinguishing between Natural and GAN-Generated Face Images by Combining Global and Local Features. Chin. J. Electron. 2022, 31, 59–67. [Google Scholar]
- Zhao, X.; Yu, Y.; Ni, R.; Zhao, Y. Exploring Complementarity of Global and Local Spatiotemporal Information for Fake Face Video Detection. In Proceedings of the ICASSP 2022, Singapore, 23–27 May 2022; pp. 2884–2888. [Google Scholar]
- Tolosana, R.; Vera-Rodriguez, R.; Fierrez, J.; Morales, A.; Ortega-Garcia, J. Deepfakes and beyond: A survey of face manipulation and fake detection. Inf. Fusion 2020, 64, 131–148. [Google Scholar] [CrossRef]
- Li, X.; Ji, S.; Wu, C.; Liu, Z.; Deng, S.; Cheng, P.; Yang, M.; Kong, X. A Survey on Deepfakes and Detection Techniques. J. Softw. 2021, 32, 496–518. [Google Scholar]
- Cozzolino, D.; Verdoliva, L. Noiseprint: A CNN-based camera model fingerprint. IEEE Trans. Inf. Forensics Secur. 2019, 15, 144–159. [Google Scholar] [CrossRef]
- Verdoliva, D.C.G.P.L. Extracting camera-based fingerprints for video forensics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Cozzolino, D.; Verdoliva, L. Camera-based Image Forgery Localization using Convolutional Neural Networks. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018. [Google Scholar]
- Li, L.; Bao, J.; Zhang, T.; Yang, H.; Chen, D.; Wen, F.; Guo, B. Face X-ray for more general face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5001–5010. [Google Scholar]
- Ciftci, U.A.; Demir, I.; Yin, L. Fakecatcher: Detection of synthetic portrait videos using biological signals. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef]
- Agarwal, S.; Farid, H.; El-Gaaly, T.; Lim, S.N. Detecting deep-fake videos from appearance and behavior. In Proceedings of the 2020 IEEE International Workshop on Information Forensics and Security (WIFS), New York City, NY, USA, 6–11 December 2020; pp. 1–6. [Google Scholar]
- Peng, B.; Fan, H.; Wang, W.; Dong, J.; Lyu, S. A Unified Framework for High Fidelity Face Swap and Expression Reenactment. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 3673–3684. [Google Scholar] [CrossRef]
- Mittal, T.; Bhattacharya, U.; Chandra, R.; Bera, A.; Manocha, D. Emotions don’t lie: An audio-visual deepfake detection method using affective cues. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2823–2832. [Google Scholar]
- Zhang, Y.; Goh, J.; Win, L.L.; Thing, V.L. Image Region Forgery Detection: A Deep Learning Approach. SG-CRC 2016, 2016, 1–11. [Google Scholar]
- Salloum, R.; Ren, Y.; Kuo, C.C.J. Image splicing localization using a multi-task fully convolutional network (MFCN). J. Vis. Commun. Image Represent. 2018, 51, 201–209. [Google Scholar] [CrossRef]
- Xuan, X.; Peng, B.; Wang, W.; Dong, J. On the generalization of GAN image forensics. In Proceedings of the Chinese Conference on Biometric Recognition, Zhuzhou, China, 12–13 October 2019; Springer: Cham, Switzerland, 2019; pp. 134–141. [Google Scholar]
- Marra, F.; Gragnaniello, D.; Verdoliva, L.; Poggi, G. Do gans leave artificial fingerprints? In Proceedings of the 2019 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), San Jose, CA, USA, 28–30 March 2019; pp. 506–511. [Google Scholar]
- Barni, M.; Kallas, K.; Nowroozi, E.; Tondi, B. CNN detection of GAN-generated face images based on cross-band co-occurrences analysis. In Proceedings of the 2020 IEEE International Workshop on Information Forensics and Security (WIFS), New York, NY, USA, 6–11 December 2020; pp. 1–6. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Mi, Z.; Jiang, X.; Sun, T.; Xu, K. Gan-generated image detection with self-attention mechanism against gan generator defect. IEEE J. Sel. Top. Signal Process. 2020, 14, 969–981. [Google Scholar] [CrossRef]
- Wang, S.Y.; Wang, O.; Zhang, R.; Owens, A.; Efros, A.A. CNN-generated images are surprisingly easy to spot… for now. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8695–8704. [Google Scholar]
- Hu, J.; Liao, X.; Wang, W.; Qin, Z. Detecting Compressed Deepfake Videos in Social Networks Using Frame-Temporality Two-Stream Convolutional Network. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 1089–1102. [Google Scholar] [CrossRef]
- Chen, B.; Liu, X.; Zheng, Y.; Zhao, G.; Shi, Y.Q. A robust GAN-generated face detection method based on dual-color spaces and an improved Xception. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 3527–3538. [Google Scholar] [CrossRef]
- He, Y.; Yu, N.; Keuper, M.; Fritz, M. Beyond the spectrum: Detecting deepfakes via re-synthesis. arXiv 2021, arXiv:2105.14376. [Google Scholar]
- Zhang, M.; Wang, H.; He, P.; Malik, A.; Liu, H. Improving GAN-generated image detection generalization using unsupervised domain adaptation. In Proceedings of the 2022 IEEE International Conference on Multimedia and Expo (ICME), Taipei, Taiwan, 18–22 July 2022; pp. 1–6. [Google Scholar]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Lin, H.; Zhang, Z.; Sun, Y.; He, T.; Mueller, J.; Manmatha, R.; et al. Resnest: Split-attention networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 2736–2746. [Google Scholar]
- Luo, Y.; Zhang, Y.; Yan, J.; Liu, W. Generalizing Face Forgery Detection with High-frequency Features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 16317–16326. [Google Scholar]
- Wang, C.; Wang, Y.; Zhang, K.; Muhammad, J.; Lu, T.; Zhang, Q.; Tian, Q.; He, Z.; Sun, Z.; Zhang, Y.; et al. NIR iris challenge evaluation in non-cooperative environments: Segmentation and localization. In Proceedings of the 2021 IEEE International Joint Conference on Biometrics (IJCB), Shenzhen, China, 4–7 August 2021; pp. 1–10. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International conference on machine learning, Beach, CA, USA, 10–15 June 2019; pp. 6105–6114. [Google Scholar]
- Guo, H.; Hu, S.; Wang, X.; Chang, M.C.; Lyu, S. Eyes tell all: Irregular pupil shapes reveal GAN-generated faces. In Proceedings of the ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 2904–2908. [Google Scholar]
- Wikipedia. Ellipse[EB/OL]. Available online: https:en.wikipedia.org/wiki/Ellipse#Parameters (accessed on 24 December 2022).
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2472–2481. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 694–711. [Google Scholar]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8798–8807. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8110–8119. [Google Scholar]
- Liu, Z.; Qi, X.; Torr, P.H.S. Global texture enhancement for fake face detection in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8060–8069. [Google Scholar]
- Wang, X.; Guo, H.; Hu, S.; Chang, M.C.; Lyu, S. Gan-generated faces detection: A survey and new perspectives. arXiv 2022, arXiv:2202.07145. [Google Scholar]
- Yang, X.; Li, Y.; Qi, H.; Lyu, S. Exposing GAN-synthesized faces using landmark locations. In Proceedings of the ACM Workshop on Information Hiding and Multimedia Security, Paris, France, 3–5 July 2019; pp. 113–118. [Google Scholar]
- Gragnaniello, D.; Cozzolino, D.; Marra, F.; Poggi, G.; Verdoliva, L. Are GAN generated images easy to detect? A critical analysis of the state-of-the-art. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]










Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).