
ROMI: A Real-Time Optical Digit Recognition Embedded System for Monitoring Patients in Intensive Care Units

Abstract
1. Introduction
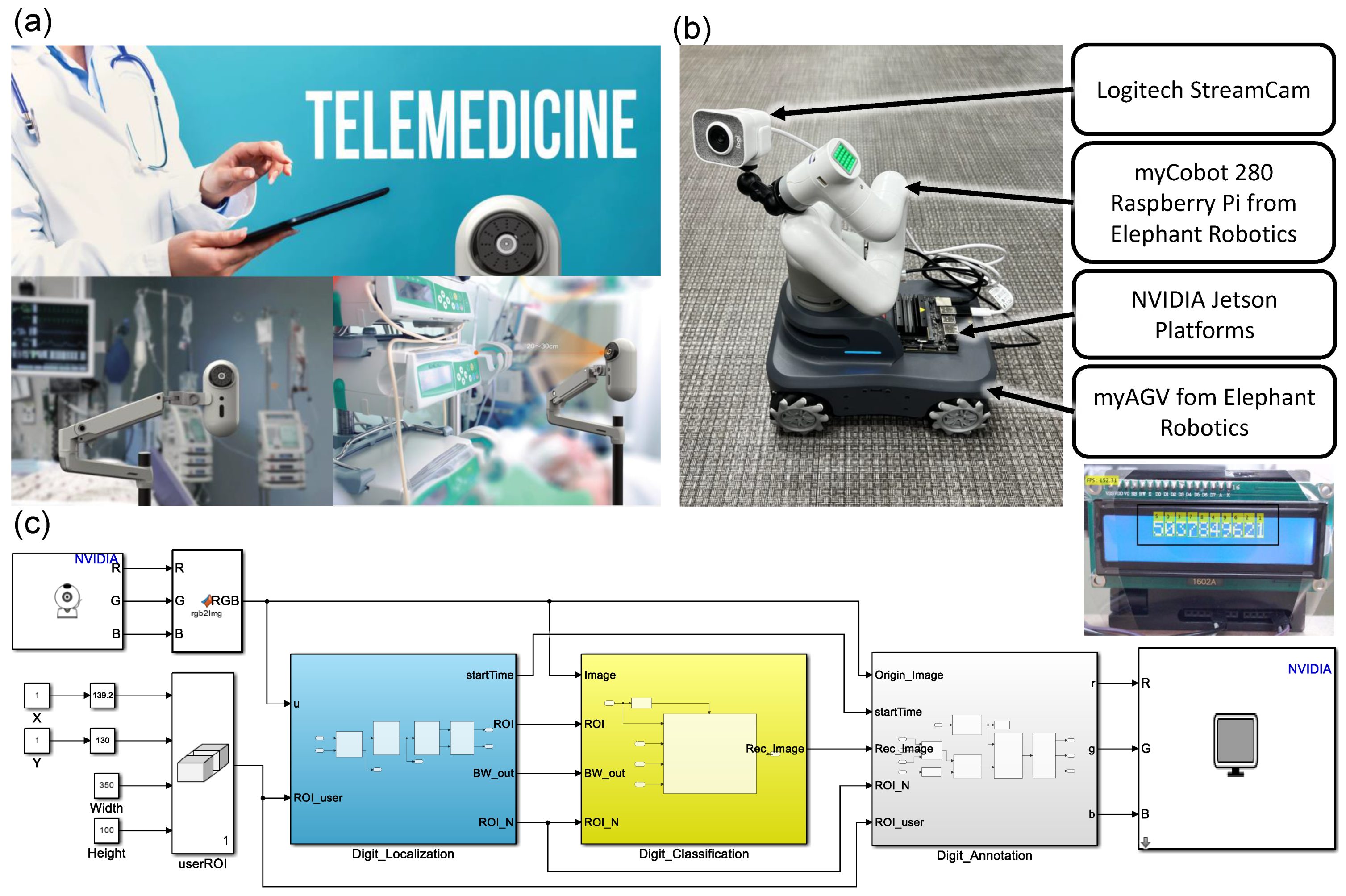
- We propose a real-time digit recognition embedded system called ROMI. ROMI consists of three subsystems, i.e., digit localization, digit classification, and digit annotation. The subsystems of ROMI were developed by using Matlab Simulink. In this work, we demonstrate the entire process for developing ROMI—from data acquisition and model development to embedded system deployment—as a proof-of-concept study.
- Not all OCR algorithms are perfect under real-world conditions. Implementing deep learning (DL) models in the real world requires calibration, which involves collecting new training datasets and training/fine-tuning the models. We used data augmentation on a small training dataset to easily and quickly calibrate DL models in the initial setup.
- We retrained ten pre-trained CNN models to develop a digit recognition model with transfer learning. We then selected the best DL model, i.e., alexnet, through a comprehensive recognition performance evaluation.
- We created a benchmark for ROMI by deploying ten trained DL models on three NVIDIA graphics processing unit (GPU) embedded platforms to analyze the runtime performance.
2. Related Work
3. Methods
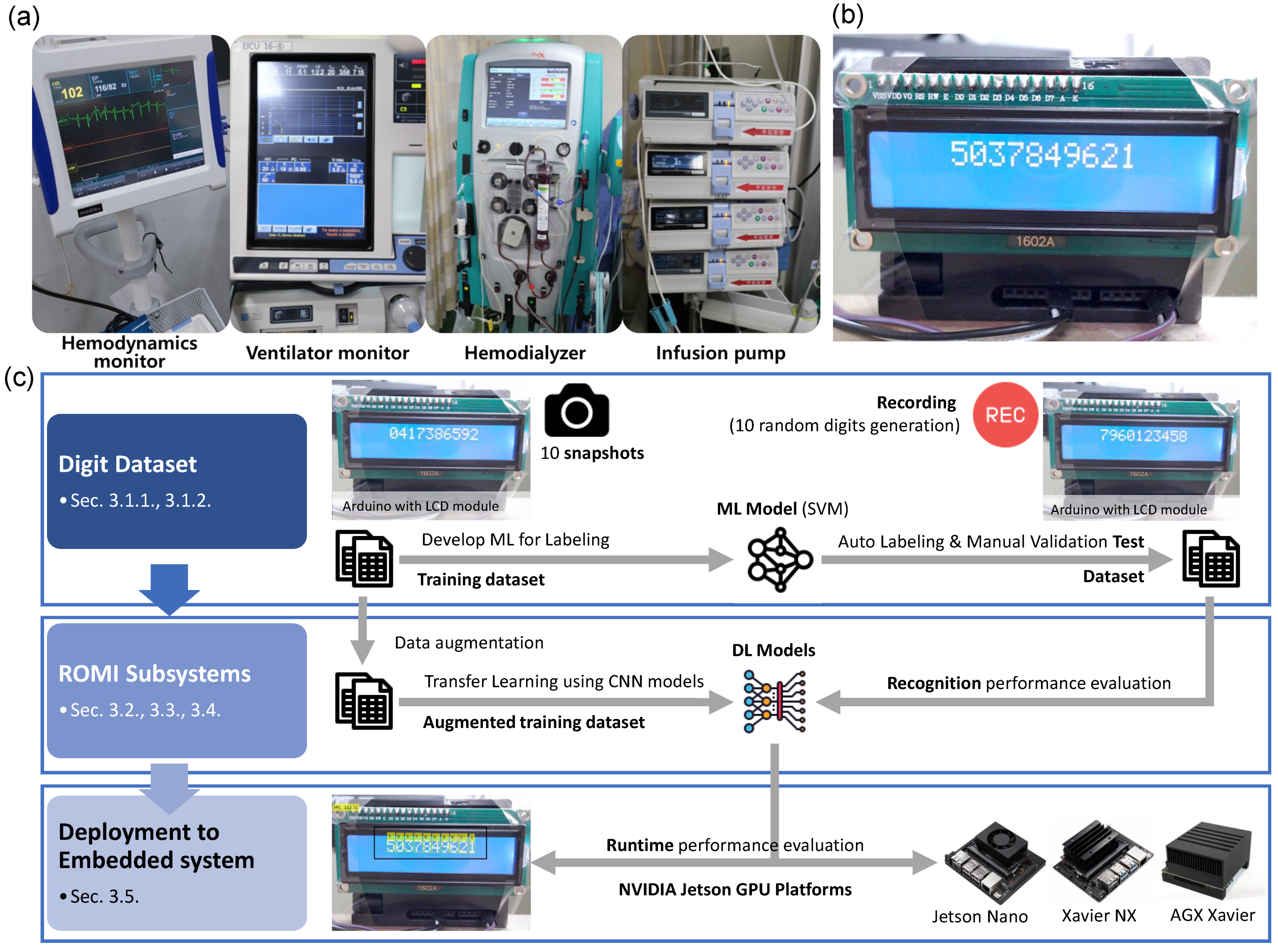
3.1. Proof-of-Concept Study
3.1.1. Raw Digit Data
3.1.2. Dataset Labeling
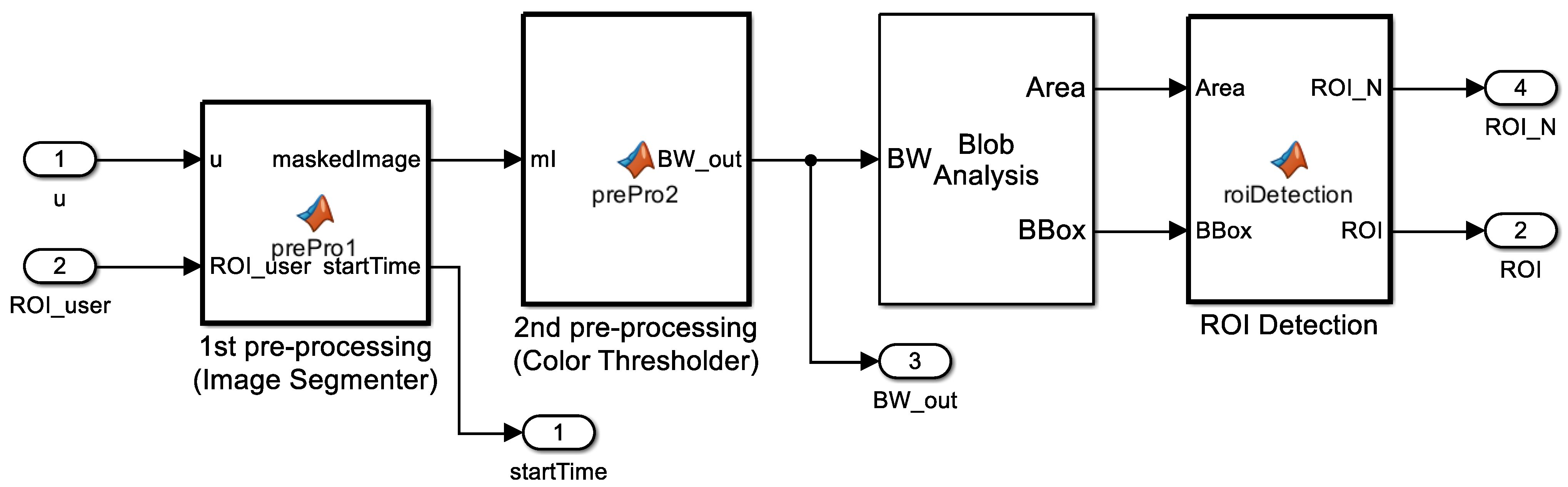
3.2. Digit Localization (ROMI Subsystem 1)
3.2.1. Image Segmenter
3.2.2. Color Thresholder
3.2.3. Blob Analysis
3.2.4. ROI Detection
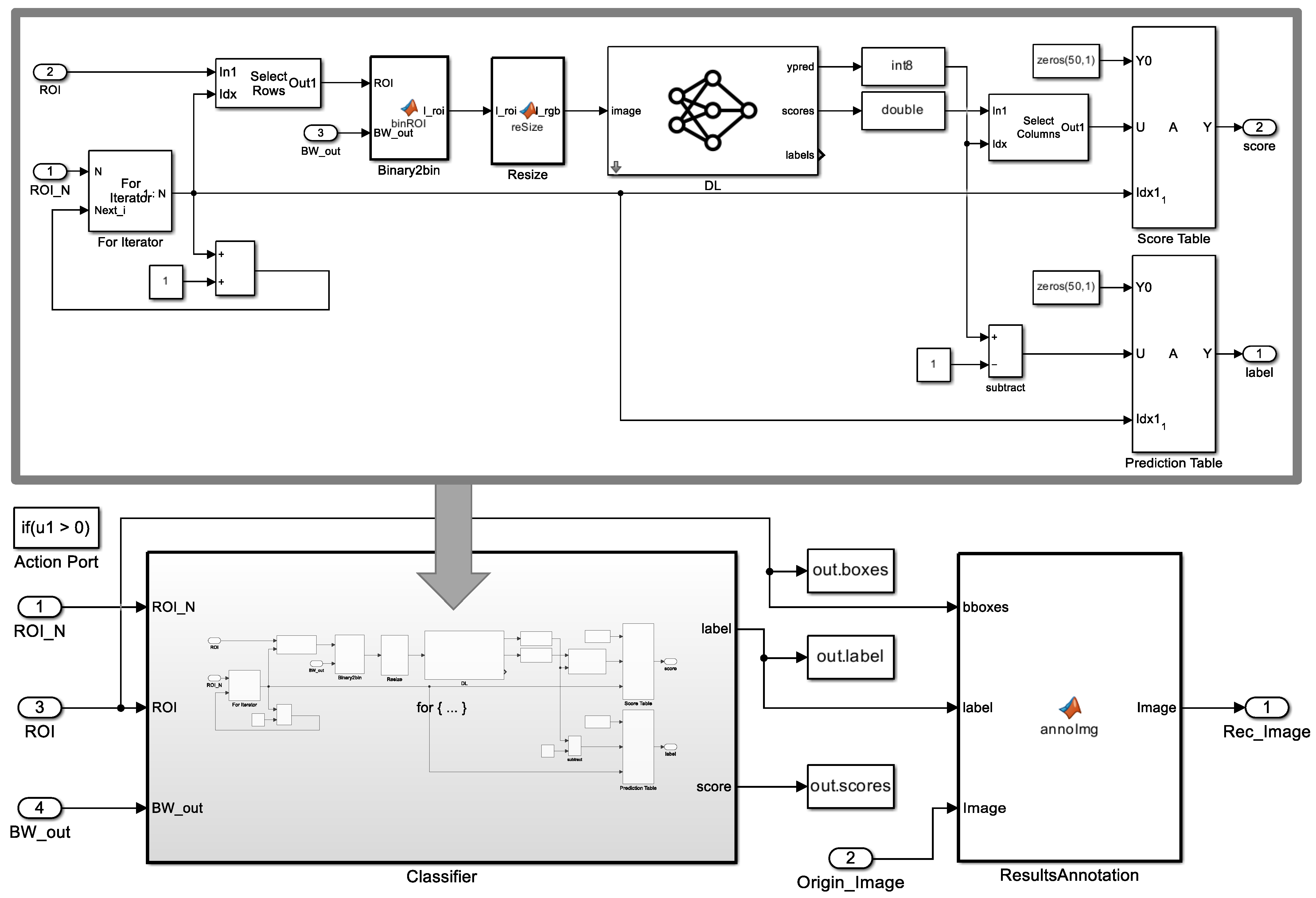
3.3. Digit Classification (ROMI Subsystem 2)
3.3.1. Zero Padding
3.3.2. Complemented Binary Image
3.3.3. Resizing
3.3.4. Image Classifier
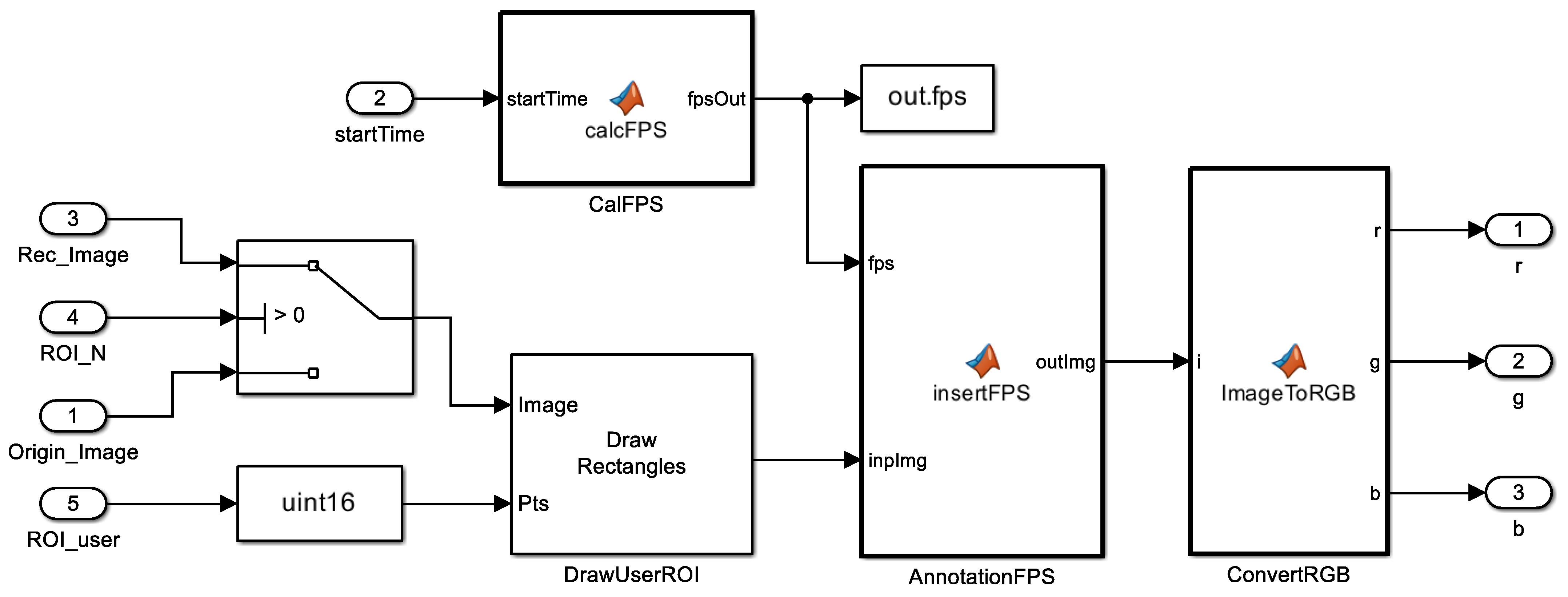
3.4. Digit Annotation (ROMI Subsystem 3)
3.5. Deployment on Embedded Hardware Platforms
4. Evaluations
4.1. Evaluation Setup
4.1.1. Evaluation Metric for Digit Recognition
- : The model predicts that the predicted bounding box is where the ground-truth box is (positive), and the prediction is correct (true).
- : The model predicts that the predicted bounding box is where the ground-truth box is (positive), and the prediction is wrong (false).
- : The model predicts that the predicted bounding box is not where the ground-truth box is (negative), and the prediction is wrong (false).
- : The model predicts that the predicted bounding box is not where the ground-truth box is (negative), and the prediction is correct (true).
4.1.2. Evaluation Metric for Runtime Performance
4.2. Digit Recognition Performance Evaluation
4.2.1. Data Augmentation for Training the DL Model
4.2.2. Trained DL Model Analysis
4.3. Runtime Performance Evaluation
4.3.1. NVIDIA Jetson GPU Platforms
4.3.2. DL Model Deployment
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ICUs | Intensive Care Units |
| EMR | Electronic Medical Record |
| HL7 | Health Level 7 |
| IoT | Internet of Things |
| OCR | Optical Characteristic Recognition |
| CNN | Convolutional Neural Network |
| DL | Deep Learning |
| GPU | Graphics Processing Unit |
| MSER | Maximally Stable Extremal Regions |
| MDD | Medical Device Dongle |
| SpO2 | Oxygen saturation |
| ECG | Electrocardiogram |
| LCD | Liquid Crystal Display |
| ML | Machine Learning |
| SVM | Support Vector Machine |
| HOG | Histogram of Oriented Gradients |
| ROI | Region of Interest |
| HSV | Hue, Saturation, and Value |
| ILSVRC | ImageNet Large-Scale Visual Recognition Challenge |
| SGDM | Stochastic Gradient Descent with Momentum |
| FPS | Frames per Second |
| mFPS | Mean Frames per Second |
| cuDNN | NVIDIA CUDA Library |
| AIoT | Artificial Intelligence of Things |
| GFLOPs | GPU Floating-Point Operations Per Second |
| TOPs | Tera-Operations per Second |
| AP | Average Precision |
| mAP | Mean Average Precision |
| MNIST | Modified National Institute of Standards and Technology database |
| IoU | Intersection over Union |
| TP | True Positive |
| FP | False Positive |
| FN | False Negative |
| TN | True Negative |
References
- Jackson, M.; Cairns, T. Care of the critically ill patient. Surgery 2021, 39, 29–36. [Google Scholar] [CrossRef] [PubMed]
- Marshall, J.C.; Bosco, L.; Adhikari, N.K.; Connolly, B.; Diaz, J.V.; Dorman, T.; Fowler, R.A.; Meyfroidt, G.; Nakagawa, S.; Pelosi, P.; et al. What is an intensive care unit? A report of the task force of the World Federation of Societies of Intensive and Critical Care Medicine. J. Crit. Care 2017, 37, 270–276. [Google Scholar] [CrossRef] [PubMed]
- Baig, M.M.; Afifi, S.; GholamHosseini, H.; Ullah, E. Deterioration to decision: A comprehensive literature review of rapid response applications for deteriorating patients in acute care settings. Health Technol. 2020, 10, 567–573. [Google Scholar] [CrossRef]
- Khanna, A.K.; Hoppe, P.; Saugel, B. Automated continuous noninvasive ward monitoring: Future directions and challenges. Crit. Care 2019, 23, 194. [Google Scholar] [CrossRef] [PubMed]
- Middleton, P.; Davies, S. Noninvasive hemodynamic monitoring in the emergency department. Curr. Opin. Crit. Care 2011, 17, 342–350. [Google Scholar] [CrossRef] [PubMed]
- The Argos Cardiac Output Monitor Interface Is Declared Compatible with Philips IntelliBridge, Enabling Seamless Data Transfer to Hospital Electronic Medical Record (EMR) Systems. Available online: https://www.prnewswire.com/news-releases/the-argos-cardiac-output-monitor-interface-is-declared-compatible-with-philips-intellibridge-enabling-seamless-data-transfer-to-hospital-electronic-medical-record-emr-systems-301493953.html (accessed on 23 December 2022).
- Medical Devices Landscape: Current and Future Adoption, Integration with EMRs, and Connectivity. Available online: https://www.lantronix.com/wp-content/uploads/pdf/Medical-Devices-Landscape_Lantonix_HIMMS_WP.pdf (accessed on 7 December 2022).
- De Georgia, M.A.; Kaffashi, F.; Jacono, F.J.; Loparo, K.A. Information technology in critical care: Review of monitoring and data acquisition systems for patient care and research. Sci. World J. 2015, 2015, 727694. [Google Scholar] [CrossRef]
- AlQudah, A.A.; Al-Emran, M.; Shaalan, K. Medical data integration using HL7 standards for patient’s early identification. PLoS ONE 2021, 16, e0262067. [Google Scholar] [CrossRef]
- Nguyen, H.; Ivanov, R.; DeMauro, S.B.; Weimer, J. Repulmo: A remote pulmonary monitoring system. ACM SIGBED Rev. 2019, 16, 46–50. [Google Scholar] [CrossRef]
- Kong, H.J.; An, S.; Lee, S.; Cho, S.; Hong, J.; Kim, S.; Lee, S. Usage of the Internet of Things in Medical Institutions and its Implications. Healthc. Inform. Res. 2022, 28, 287–296. [Google Scholar] [CrossRef] [PubMed]
- Hussain, F. Internet of everything. In Internet of Things; Springer: Berlin/Heidelberg, Germany, 2017; pp. 1–11. [Google Scholar]
- Pradhan, B.; Bhattacharyya, S.; Pal, K. IoT-based applications in healthcare devices. J. Healthc. Eng. 2021, 2021, 6632599. [Google Scholar] [CrossRef]
- Flohr, L.; Beaudry, S.; Johnson, K.T.; West, N.; Burns, C.M.; Ansermino, J.M.; Dumont, G.A.; Wensley, D.; Skippen, P.; Görges, M. Clinician-driven design of vitalpad—An intelligent monitoring and communication device to improve patient safety in the intensive care unit. IEEE J. Transl. Eng. Health Med. 2018, 6, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Torres, C.; Fried, J.C.; Manjunath, B. Healthcare event and activity logging. IEEE J. Transl. Eng. Health Med. 2018, 6, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Balaguera, H.U.; Wise, D.; Ng, C.Y.; Tso, H.W.; Chiang, W.L.; Hutchinson, A.M.; Galvin, T.; Hilborne, L.; Hoffman, C.; Huang, C.C.; et al. Using a medical Intranet of Things system to prevent bed falls in an acute care hospital: A pilot study. J. Med. Internet Res. 2017, 19, e7131. [Google Scholar] [CrossRef] [PubMed]
- Wu, W.; Zhang, Y.; Wang, P.; Zhang, L.; Wang, G.; Lei, G.; Xiao, Q.; Cao, X.; Bian, Y.; Xie, S.; et al. Psychological stress of medical staffs during outbreak of COVID-19 and adjustment strategy. J. Med. Virol. 2020, 92, 1962–1970. [Google Scholar] [CrossRef] [PubMed]
- Razu, S.R.; Yasmin, T.; Arif, T.B.; Islam, M.; Islam, S.M.S.; Gesesew, H.A.; Ward, P. Challenges faced by healthcare professionals during the COVID-19 pandemic: A qualitative inquiry from Bangladesh. Front. Public Health 2021, 9, 647315. [Google Scholar] [CrossRef] [PubMed]
- Garzotto, F.; Comoretto, R.I.; Ostermann, M.; Nalesso, F.; Gregori, D.; Bonavina, M.G.; Zanardo, G.; Meneghesso, G. Preventing infectious diseases in Intensive Care Unit by medical devices remote control: Lessons from COVID-19. J. Crit. Care 2021, 61, 119–124. [Google Scholar] [CrossRef] [PubMed]
- Lee, N.; Jeong, M.; Kim, Y.; Shin, J.; Joe, I.; Jeon, S. IoT-based Architecture and Implementation for Automatic Shock Treatment. KSII Trans. Internet Inf. Syst. 2022, 16, 2209–2224. [Google Scholar]
- de Morais Barroca Filho, I.; Aquino, G.; Malaquias, R.S.; Girão, G.; Melo, S.R.M. An IoT-based healthcare platform for patients in ICU beds during the COVID-19 outbreak. IEEE Access 2021, 9, 27262–27277. [Google Scholar] [CrossRef]
- Shen, Y.; Guo, D.; Long, F.; Mateos, L.A.; Ding, H.; Xiu, Z.; Hellman, R.B.; King, A.; Chen, S.; Zhang, C.; et al. Robots under COVID-19 pandemic: A comprehensive survey. IEEE Access 2020, 9, 1590–1615. [Google Scholar] [CrossRef]
- Holland, J.; Kingston, L.; McCarthy, C.; Armstrong, E.; O’Dwyer, P.; Merz, F.; McConnell, M. Service robots in the healthcare sector. Robotics 2021, 10, 47. [Google Scholar] [CrossRef]
- Khan, Z.H.; Siddique, A.; Lee, C.W. Robotics utilization for healthcare digitization in global COVID-19 management. Int. J. Environ. Res. Public Health 2020, 17, 3819. [Google Scholar] [CrossRef] [PubMed]
- Patel, C.; Patel, A.; Patel, D. Optical character recognition by open source OCR tool tesseract: A case study. Int. J. Comput. Appl. 2012, 55, 50–56. [Google Scholar] [CrossRef]
- Smith, R. An overview of the Tesseract OCR engine. In Proceedings of the Ninth IEEE International Conference on Document Analysis and Recognition (ICDAR 2007), Curitiba, Brazil, 23–26 September 2007; Volume 2, pp. 629–633. [Google Scholar]
- Aljelawy, Q.M.; Salman, T.M. Detecting License Plate Number Using OCR Technique and Raspberry Pi 4 with Camera. In Proceedings of the 2022 2nd IEEE International Conference on Computing and Machine Intelligence (ICMI), Istanbul, Turkey, 15–16 July 2022; pp. 1–5. [Google Scholar]
- Maitrichit, N.; Hnoohom, N. Intelligent Medicine Identification System Using a Combination of Image Recognition and Optical Character Recognition. In Proceedings of the 2020 15th IEEE International Joint Symposium on Artificial Intelligence and Natural Language Processing (iSAI-NLP), Bangkok, Thailand, 18–20 November 2020; pp. 1–5. [Google Scholar]
- Shenoy, V.N.; Aalami, O.O. Utilizing smartphone-based machine learning in medical monitor data collection: Seven segment digit recognition. AMIA Annu. Symp. Proc. 2017, 2017, 1564–1570. [Google Scholar] [PubMed]
- Kanagarathinam, K.; Sekar, K. Text detection and recognition in raw image dataset of seven segment digital energy meter display. Energy Rep. 2019, 5, 842–852. [Google Scholar] [CrossRef]
- Bieniecki, W.; Grabowski, S.; Rozenberg, W. Image preprocessing for improving ocr accuracy. In Proceedings of the 2007 IEEE International Conference on Perspective Technologies and Methods in MEMS Design, Lviv, Ukraine, 23–26 May 2007; pp. 75–80. [Google Scholar]
- Kulkarni, P.H.; Kute, P.D. Optical numeral recognition algorithm for seven segment display. In Proceedings of the 2016 IEEE Conference on Advances in Signal Processing (CASP), Pune, India, 9–11 June 2016; pp. 397–401. [Google Scholar]
- Tsiktsiris, D.; Kechagias, K.; Dasygenis, M.; Angelidis, P. Accelerated Seven Segment Optical Character Recognition Algorithm. In Proceedings of the 2019 IEEE Panhellenic Conference on Electronics & Telecommunications (PACET), Volos, Greece, 8–9 November 2019; pp. 1–5. [Google Scholar]
- Popayorm, S.; Titijaroonroj, T.; Phoka, T.; Massagram, W. Seven segment display detection and recognition using predefined HSV color slicing technique. In Proceedings of the 2019 16th IEEE International Joint Conference on Computer Science and Software Engineering (JCSSE), Chonburi, Thailand, 10–12 July 2019; pp. 224–229. [Google Scholar]
- Finnegan, E.; Villarroel, M.; Velardo, C.; Tarassenko, L. Automated method for detecting and reading seven-segment digits from images of blood glucose metres and blood pressure monitors. J. Med. Eng. Technol. 2019, 43, 341–355. [Google Scholar] [CrossRef] [PubMed]
- Wannachai, A.; Boonyung, W.; Champrasert, P. Real-Time Seven Segment Display Detection and Recognition Online System Using CNN. In Proceedings of the International Conference on Bio-Inspired Information and Communication Technologies, Shanghai, China, 7–8 July 2020; pp. 52–67. [Google Scholar]
- Da Costa, C.A.; Pasluosta, C.F.; Eskofier, B.; Da Silva, D.B.; da Rosa Righi, R. Internet of health things: Toward intelligent vital signs monitoring in hospital wards. Artif. Intell. Med. 2018, 89, 61–69. [Google Scholar] [CrossRef]
- Lesh, K.; Weininger, S.; Goldman, J.M.; Wilson, B.; Himes, G. Medical device interoperability-assessing the environment. In Proceedings of the 2007 IEEE Joint Workshop on High Confidence Medical Devices, Software, and Systems and Medical Device Plug-and-Play Interoperability (HCMDSS-MDPnP 2007), Boston, MA, USA, 25–27 June 2007; pp. 3–12. [Google Scholar]
- Asare, P.; Cong, D.; Vattam, S.G.; Kim, B.; King, A.; Sokolsky, O.; Lee, I.; Lin, S.; Mullen-Fortino, M. The medical device dongle: An open-source standards-based platform for interoperable medical device connectivity. In Proceedings of the 2nd ACM SIGHIT International Health Informatics Symposium, Miami, FL, USA, 28–30 January 2012; pp. 667–672. [Google Scholar]
- Malan, D.J.; Fulford-Jones, T.; Welsh, M.; Moulton, S. Codeblue: An ad hoc sensor network infrastructure for emergency medical care. In Proceedings of the International Workshop on Wearable and Implantable Body Sensor Networks, London, UK; 2004. [Google Scholar]
- Arney, D.; Plourde, J.; Goldman, J.M. OpenICE medical device interoperability platform overview and requirement analysis. Biomed. Eng. Tech. 2018, 63, 39–47. [Google Scholar] [CrossRef] [PubMed]
- Wood, A.D.; Stankovic, J.A.; Virone, G.; Selavo, L.; He, Z.; Cao, Q.; Doan, T.; Wu, Y.; Fang, L.; Stoleru, R. Context-aware wireless sensor networks for assisted living and residential monitoring. IEEE Netw. 2008, 22, 26–33. [Google Scholar] [CrossRef]
- Ko, J.; Lim, J.H.; Chen, Y.; Musvaloiu-E, R.; Terzis, A.; Masson, G.M.; Gao, T.; Destler, W.; Selavo, L.; Dutton, R.P. MEDiSN: Medical emergency detection in sensor networks. ACM Trans. Embed. Comput. Syst. (TECS) 2010, 10, 11. [Google Scholar] [CrossRef]
- Ko, J.; Lu, C.; Srivastava, M.B.; Stankovic, J.A.; Terzis, A.; Welsh, M. Wireless sensor networks for healthcare. Proc. IEEE 2010, 98, 1947–1960. [Google Scholar] [CrossRef]
- Prudenzi, A.; Fioravanti, A.; Regoli, M. A low-cost internet of things integration platform for a centralized supervising system of building technology systems in hospitals. In Proceedings of the 2018 IEEE International Conference on Environment and Electrical Engineering and 2018 IEEE Industrial and Commercial Power Systems Europe (EEEIC/I&CPS Europe), Palermo, Italy, 12–15 June 2018; pp. 1–6. [Google Scholar]
- Vanek, J.; Macık, M. VentConnect, system for remote monitoring of medical instruments. In Proceedings of the 24th Bilateral Student Workshop CTU Prague and HTW Dresden-User Interfaces & Visualization, Dresden, Germany, 2018; pp. 12–16. [Google Scholar]
- Boonnag, C.; Saengmolee, W.; Seesawad, N.; Chinkamol, A.; Rattanasomrerk, S.; Veerakanjana, K.; Thanontip, K.; Limpornchitwilai, W.; Ittichaiwong, P.; Wilaiprasitporn, T. PACMAN: A framework for pulse oximeter digit detection and reading in a low-resource setting. arXiv 2022, arXiv:2212.04964. [Google Scholar]
- myCobot 280: 6-Axis Collaborative Robotic Arm. Available online: https://www.elephantrobotics.com/en/mycobot-pi/ (accessed on 7 December 2022).
- myAGV: Autonomous Navigation Smart 4-Wheel Drive Vehicle. Available online: https://www.elephantrobotics.com/en/myagv-new-en/ (accessed on 7 December 2022).
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Chen, S.; Haralick, R.M. Recursive erosion, dilation, opening, and closing transforms. IEEE Trans. Image Process. 1995, 4, 335–345. [Google Scholar] [CrossRef] [PubMed]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Pretrained Deep Neural Networks. Available online: https://www.mathworks.com/help/deeplearning/ug/pretrained-convolutional-neural-networks.html (accessed on 7 December 2022).
- Embedded Systems with Jetson: Advanced AI Embedded Systems. Available online: https://www.nvidia.com/en-us/autonomous-machines/embedded-systems/ (accessed on 7 December 2022).
- Padilla, R.; Netto, S.L.; Da Silva, E.A. A survey on performance metrics for object-detection algorithms. In Proceedings of the 2020 IEEE International Conference on Systems, Signals and Image Processing (IWSSIP), Niteroi, Brazil, 1–3 July 2020; pp. 237–242. [Google Scholar]
- Padilla, R.; Passos, W.L.; Dias, T.L.; Netto, S.L.; Da Silva, E.A. A comparative analysis of object detection metrics with a companion open-source toolkit. Electronics 2021, 10, 279. [Google Scholar] [CrossRef]
- Biørn-Hansen, A.; Grønli, T.M.; Ghinea, G. Animations in cross-platform mobile applications: An evaluation of tools, metrics and performance. Sensors 2019, 19, 2081. [Google Scholar] [CrossRef]
- Zhou, P.; Ni, B.; Geng, C.; Hu, J.; Xu, Y. Scale-transferrable object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 528–537. [Google Scholar]
- Leon-Garza, H.; Hagras, H.; Peña-Rios, A.; Owusu, G.; Conway, A. A fuzzy logic based system for cloud-based building information modelling rendering optimization in augmented reality. In Proceedings of the 2020 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Glasgow, UK, 19–24 July 2020; pp. 1–6. [Google Scholar]
- Perez, L.; Wang, J. The effectiveness of data augmentation in image classification using deep learning. arXiv 2017, arXiv:1712.04621. [Google Scholar]
- Taylor, L.; Nitschke, G. Improving deep learning with generic data augmentation. In Proceedings of the 2018 IEEE Symposium Series on Computational Intelligence (SSCI), Bangalore, India, 18–21 November 2018; pp. 1542–1547. [Google Scholar]
- Data Sets for Deep Learning. Available online: https://www.mathworks.com/help/deeplearning/ug/data-sets-for-deep-learning.html (accessed on 26 December 2022).
- Stäcker, L.; Fei, J.; Heidenreich, P.; Bonarens, F.; Rambach, J.; Stricker, D.; Stiller, C. Deployment of Deep Neural Networks for Object Detection on Edge AI Devices with Runtime Optimization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 1015–1022. [Google Scholar]
- Alatise, M.B.; Hancke, G.P. A review on challenges of autonomous mobile robot and sensor fusion methods. IEEE Access 2020, 8, 39830–39846. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Target Medical Device | Solution/Approach | Problem/Challenge |
|---|---|---|---|
| CodeBlue [40] | A ventilator and ECG | MICA2 motes | Limited data logging |
| OpenICE [41] | Bedside medical devices | BeagleBone single-board computers | Limited data logging |
| AlarmNet [42] | Heart rate, pulse oximetry, ECG, body movement | MicaZ and Telos Sky motes | Limited data logging |
| MEDiSN [43] | Various vital signs, such as pulse oximetry and pulse rate | miTag motes | Limited data logging |
| VentConnect [46] | Ventilators | Capture device via a display interface converter | Ventilator only |
| PACMAN [47] | Pulse oximeter | Digit OCR of images taken with smartphone cameras | Pulse oximeter only and model calibration |
| ROMI (Ours) | Multiple ICU medical devices | Medical device digit OCR using a robotic system | Model calibration |
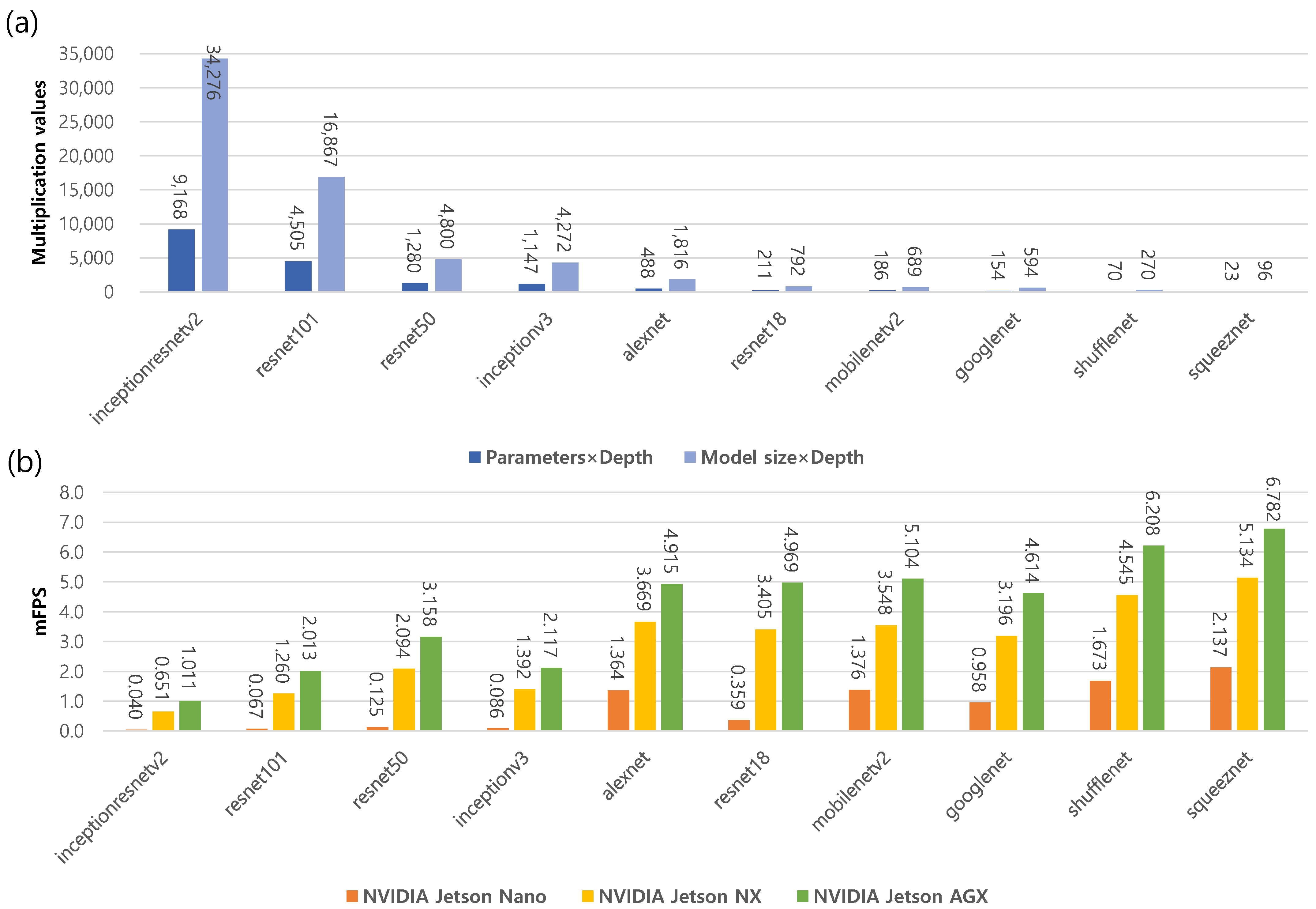
| Network | Depth | Size [MB] | Parameters (Millions) | Input Size |
|---|---|---|---|---|
| squeeznet | 18 | 5.2 | 1.24 | 227 × 227 × 3 |
| shufflenet | 50 | 5.4 | 1.4 | 224 × 224 × 3 |
| mobilenetv2 | 53 | 13 | 3.5 | 224 × 224 × 3 |
| googlenet | 22 | 27 | 7.0 | 224 × 224 × 3 |
| resnet18 | 18 | 44 | 11.7 | 224 × 224 × 3 |
| inceptionv3 | 48 | 89 | 23.9 | 299 × 299 × 3 |
| resnet50 | 50 | 96 | 25.6 | 224 × 224 × 3 |
| resnet101 | 101 | 167 | 44.6 | 224 × 224 × 3 |
| inceptionresnetv2 | 164 | 209 | 55.9 | 299 × 299 × 3 |
| alexnet | 8 | 227 | 61.0 | 227 × 227 × 3 |
| DL Model | Jetson Nano | Jetson Xavier NX | Jetson AGX Xavier |
|---|---|---|---|
| GPU | 128-core Maxwell | 384-core NVIDIA Volta™ GPU with 48 Tensor Cores | NVIDIA Volta architecture with 512 NVIDIA CUDA cores and 64 Tensor cores |
| AI Performance | 472 GFLOPs | 21 TOPs | 32 TOPs |
| CPU | Quad-core ARM A57 @ 1.43 GHz | 6-core NVIDIA Carmel ARM® v8.2 64-bit CPU 6 MB L2 + 4 MB L3 | 8-core NVIDIA Carmel Armv8.2 64-bit CPU 8 MB L2 + 4 MB L3 |
| Memory | 4 GB 64-bit LPDDR4 25.6 GB/s @ 1.43 GHz | 8 GB 128-bit LPDDR4x 59.7 GB/s | 32 GB 256-bit LPDDR4x 136.5 GB/s |
| Storage | microSD | 16 GB eMMC 5.1 | 32 GB eMMC 5.1 |
| Power | 5 W|10 W | 10 W|15 W|20 W | 310 W|15 W|30 W |
| DL Model | Ten Images without DA | Ten Images with DA (Ours) | Digits Dataset (Open Dataset) | MNIST Dataset (Open Dataset) |
|---|---|---|---|---|
| squeeznet | 0.790 | 0.976 | 0.073 | 0.397 |
| shufflenet | 0.530 | 0.885 | 0.013 | 0.158 |
| mobilenetv2 | 0.579 | 0.958 | 0.010 | 0.264 |
| googlenet | 0.964 | 0.988 | 0.153 | 0.535 |
| resnet18 | 0.540 | 0.888 | 0.097 | 0.104 |
| inceptionv3 | 0.754 | 0.956 | 0.011 | 0.072 |
| resnet50 | 0.680 | 0.932 | 0.015 | 0.133 |
| resnet101 | 0.830 | 0.963 | 0.011 | 0.198 |
| inceptionresnetv2 | 0.329 | 0.781 | 0.014 | 0.010 |
| alexnet | 0.984 | 0.989 | 0.138 | 0.489 |
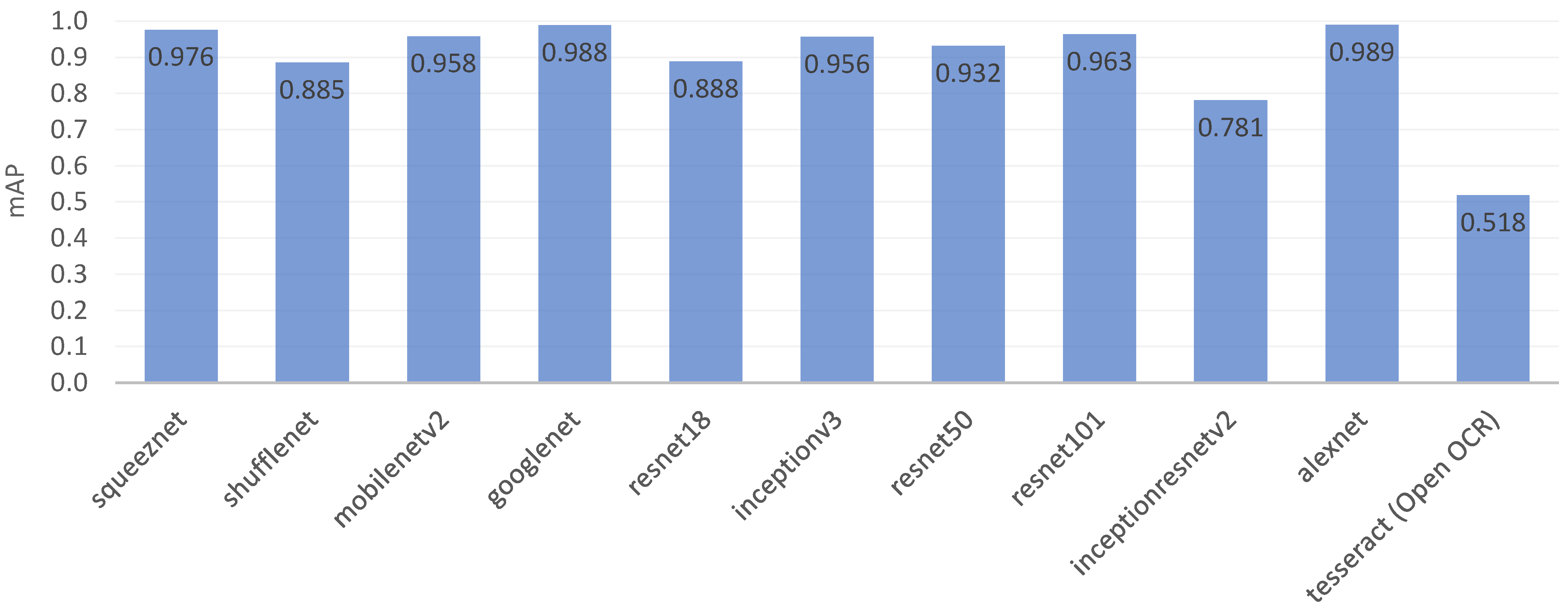
| OCR Model | Digit 0 | Digit 1 | Digit 2 | Digit 3 | Digit 4 | Digit 5 | Digit 6 | Digit 7 | Digit 8 | Digit 9 | Total |
|---|---|---|---|---|---|---|---|---|---|---|---|
| squeeznet | 0.985 | 0.989 | 0.988 | 0.992 | 0.991 | 0.935 | 0.992 | 0.991 | 0.982 | 0.914 | 0.976 |
| shufflenet | 0.775 | 0.990 | 0.633 | 0.910 | 0.991 | 0.898 | 0.918 | 0.874 | 0.952 | 0.908 | 0.885 |
| mobilenetv2 | 0.985 | 0.990 | 0.987 | 0.990 | 0.990 | 0.980 | 0.822 | 0.976 | 0.911 | 0.947 | 0.958 |
| googlenet | 0.986 | 0.990 | 0.989 | 0.992 | 0.991 | 0.991 | 0.993 | 0.992 | 0.984 | 0.977 | 0.988 |
| resnet18 | 0.985 | 0.990 | 0.989 | 0.893 | 0.991 | 0.988 | 0.693 | 0.985 | 0.739 | 0.627 | 0.888 |
| inceptionv3 | 0.984 | 0.990 | 0.967 | 0.973 | 0.988 | 0.922 | 0.944 | 0.991 | 0.934 | 0.869 | 0.956 |
| resnet50 | 0.968 | 0.990 | 0.984 | 0.977 | 0.990 | 0.973 | 0.869 | 0.992 | 0.939 | 0.634 | 0.932 |
| resnet101 | 0.986 | 0.990 | 0.981 | 0.898 | 0.974 | 0.991 | 0.992 | 0.992 | 0.842 | 0.984 | 0.963 |
| inceptionresnetv2 | 0.944 | 0.987 | 0.504 | 0.988 | 0.858 | 0.890 | 0.528 | 0.949 | 0.556 | 0.606 | 0.781 |
| alexnet | 0.986 | 0.990 | 0.989 | 0.992 | 0.991 | 0.991 | 0.993 | 0.992 | 0.984 | 0.985 | 0.989 |
| tesseract (Open OCR) | 0.129 | 0.978 | 0.445 | 0.252 | 0.006 | 0.700 | 0.902 | 0.484 | 0.490 | 0.795 | 0.518 |
| DL Model | NVIDIA Jetson Nano | NVIDIA Jetson Xavier NX | NVIDIA Jetson AGX Xavier |
|---|---|---|---|
| squeeznet | 2.147 | 5.134 | 6.782 |
| shufflenet | 1.673 | 4.545 | 6.208 |
| mobilenetv2 | 1.376 | 3.548 | 5.104 |
| googlenet | 0.958 | 3.196 | 4.614 |
| resnet18 | 0.359 | 3.405 | 4.969 |
| inceptionv3 | 0.086 | 1.392 | 2.117 |
| resnet50 | 0.125 | 2.094 | 3.158 |
| resnet101 | 0.067 | 1.260 | 2.013 |
| inceptionresnetv2 | 0.040 | 0.651 | 1.011 |
| alexnet | 1.364 | 3.669 | 4.915 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jeon, S.; Ko, B.S.; Son, S.H. ROMI: A Real-Time Optical Digit Recognition Embedded System for Monitoring Patients in Intensive Care Units. Sensors 2023, 23, 638. https://doi.org/10.3390/s23020638
Jeon S, Ko BS, Son SH. ROMI: A Real-Time Optical Digit Recognition Embedded System for Monitoring Patients in Intensive Care Units. Sensors. 2023; 23(2):638. https://doi.org/10.3390/s23020638
Chicago/Turabian StyleJeon, Sanghoon, Byuk Sung Ko, and Sang Hyuk Son. 2023. "ROMI: A Real-Time Optical Digit Recognition Embedded System for Monitoring Patients in Intensive Care Units" Sensors 23, no. 2: 638. https://doi.org/10.3390/s23020638
APA StyleJeon, S., Ko, B. S., & Son, S. H. (2023). ROMI: A Real-Time Optical Digit Recognition Embedded System for Monitoring Patients in Intensive Care Units. Sensors, 23(2), 638. https://doi.org/10.3390/s23020638