


A Machine Learning Approach for Walking Classification in Elderly People with Gait Disorders


Abstract
:1. Introduction
- Is it applicable to develop a model that can classify the walking activity of patients with walking abnormalities, who suffer from dementia and Alzheimer’s disease?
- Is it possible to classify walking activities using only one sensor placed on the back of participants?
- How do the different Machine Learning (ML) algorithms perform on classifying walking (as one of the most effective and popular forms of activities) from non-walking activities in older adults?
2. Materials and Methods
2.1. Dataset
2.2. Data Preprocessing
2.3. Feature Extraction
2.4. Feature Subset Selection
- Initialize the positions and the velocities of the particles.
- Find and select the best particle () among the particles as leader.
- Repeat the following steps until the termination criteria is reached.
- Return the best particle as the most optimum solution.
2.5. Classification Models
2.5.1. k-Nearest Neighbors
2.5.2. Random Forest
2.6. Extreme Gradient Boosting
Stacking Ensemble
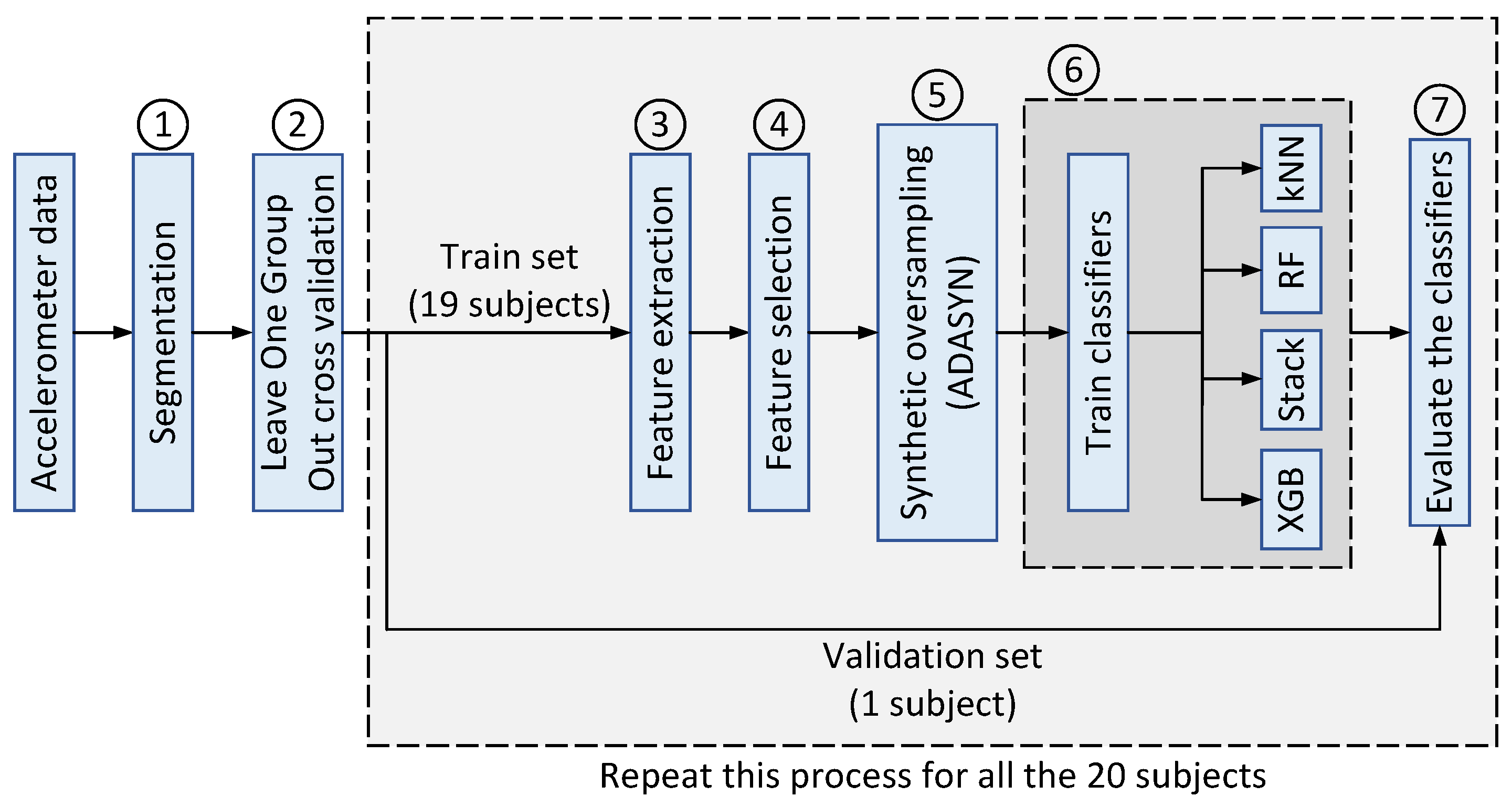
2.7. ML Based Walking Classification Framework
- 1.
- Segmentation: As mentioned in Section 2.2, the accelerometer time series are segmented into smaller chunks of 3, 6, and 9 s with 50% overlaps.
- 2.
- Cross validation: leave-one-group-out cross-validation (LOGO-CV) is applied to split the dataset into train and validation sets. In each iteration, all the individuals’ accelerometer data except one are used to train the classification algorithms. The remained subject/individual is then used to validate the models. This process is repeated twenty times in order to make sure that all the subjects are validated at least once.
- 3.
- Feature extraction: Three different types of features (i.e., statistical, temporal, and spectral), as listed in Table 2, are extracted from the segmented time series on all x-, y-, and z-axis. In total, 60 different features are extracted for each axis.
- 4.
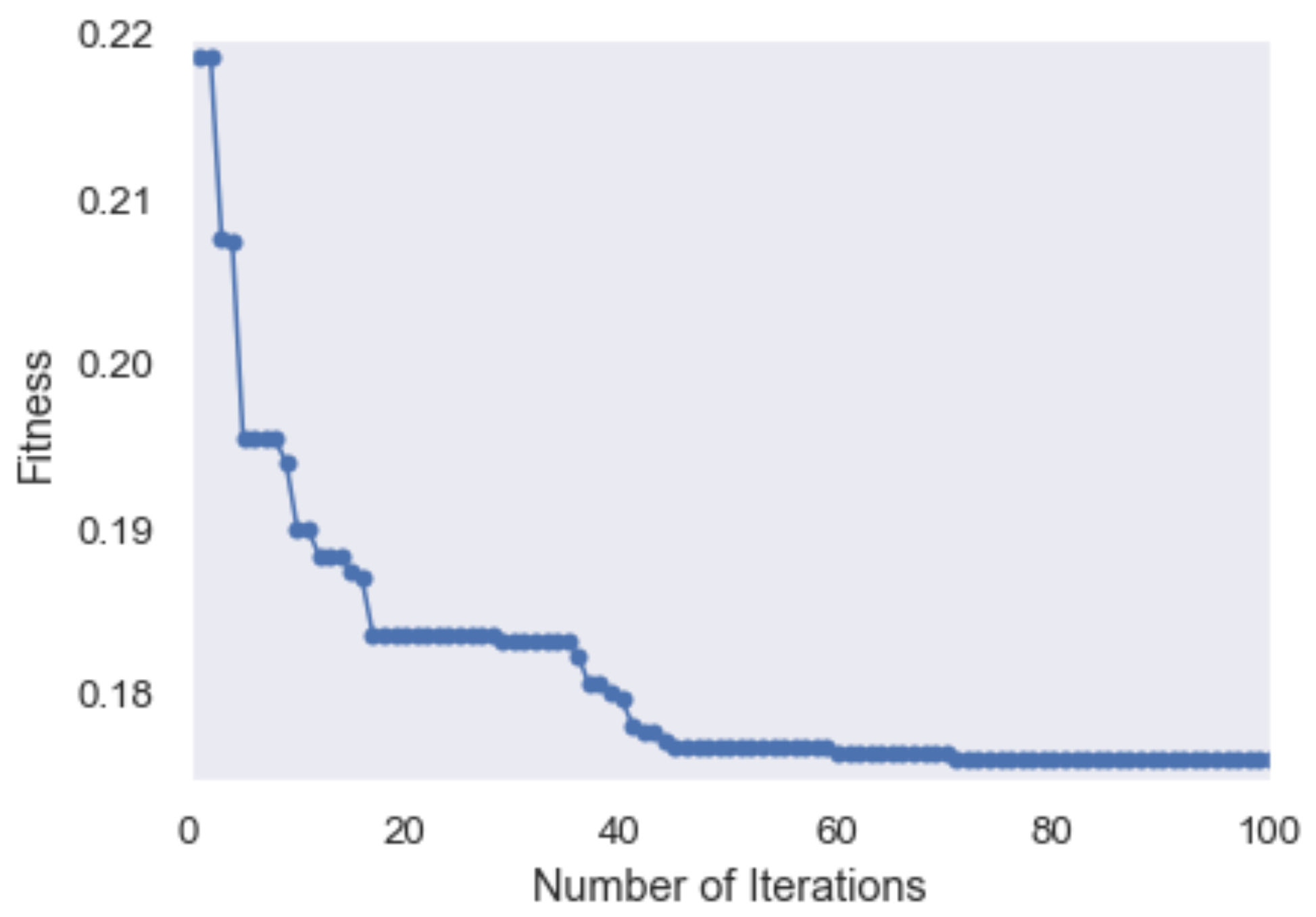
- Feature selection: A subset of extracted features are selected using the PSO algorithm as explained in Section 2.4. The fitness (objective) function applied in the PSO algorithm is a combination of the error value and the size of the selected feature. The objective function is given in (3).where and are the weight parameters equal to 0.9 and 0.1, respectively. Figure 4 shows the convergence of the PSO algorithm as the fitness value decreases by increasing the number of iterations.
- 5.
- Synthetic dataset oversampling: Since the length of walking episodes in the accelerometer data is shorter than the other activities (Figure 2), the number of extracted walking segments is smaller compared to non-walking segments. Therefore, the dataset is considered relatively imbalanced and the number of walking segments for training the classification algorithms is not sufficient. This increases the risk of a biased classification, which in turn leads to a higher error rate on the minority class (walking) [67]. To overcome this problem, the adaptive synthetic over-sampling technique (ADASYN) is applied to generate more samples for the minority class and to enable the classifiers to achieve their desired performance [67]. The ADASYN method consists of three main steps: (1) estimate the class imbalance degree to calculate the number of required synthetic samples for the minority class; (2) find the K nearest neighbors samples of the minority class using the well-known Euclidean distance; and (3) generate the synthetic samples for the minority class as follows:where represents a sample from the minority class, is one of the nearest neighbor samples chosen randomly, and is a random value. As illustrated in Figure 3, the oversampling is only applied on the train set to avoid any unrealistic evaluation of the validation set.
- 6.
- Classifiers training: In this step, the preprocessed accelerometer data from nineteen subjects/individuals is used to train all the classification algorithms.
- 7.
- Classifiers evaluation: Finally, the performances of the four trained classifiers are evaluated using the validation set (Figure 3) to determine their performance.
3. Results and Discussion
3.1. Evaluation Metrics
3.2. LOGO-CV Classification Performance
3.3. Inter-Subjects Analysis
3.4. Computational Resources
4. Conclusions, Limitations, and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Extracted Features
Appendix A.1. Empirical Cumulative Distribution Function
Appendix A.2. ECDF Percentile and ECDF Percentile Count
Appendix A.3. Histogram
Appendix A.4. Interquartile Range
Appendix A.5. Minimum, Maximum, Mean, and Median Value
Appendix A.6. Mean Absolute Deviation and Median Absolute Deviation
Appendix A.7. Root Mean Square
Appendix A.8. Variance and Standard deviation
Appendix A.9. Kurtosis & Skewness
Appendix A.10. Absolute and Total Energy, Centroid, and Area under the Curve
Appendix A.11. Autocorrelation
Appendix A.12. Shannon Entropy
Appendix A.13. Mean and Median Absolute Differences, Mean and Median Differences, and Sum of Absolute Differences
Appendix A.14. Positive and Negative Turning Points & Zero-Crossing Rate
Appendix A.15. Peak to Peak Distance
Appendix A.16. Traveled Distance
Appendix A.17. Slope of Signal
Appendix A.18. Number of Peaks from a Subsequence
Appendix A.19. Mean Frequency of a Spectrogram
Appendix A.20. Fundamental Frequency
Appendix A.21. Human Range Energy Ratio
Appendix A.22. Linear Prediction Cepstral Coefficients and Mel-Frequency Cepstral Coefficients
Appendix A.23. Spectral Positive Turning Points and Spectral Roll-Off and Roll-On
Appendix A.24. Spectral Entropy
Appendix A.25. Spectral Centroid, Spread, Skewness, and Kurtosis
Appendix A.26. Spectral Slope, Decrease, Variation, and Distance
Appendix A.27. Wavelet Entropy and Energy
Appendix A.28. Wavelet Absolute Mean, Standard Deviation, and Variance
Appendix A.29. Maximum Power Spectrum Density and Power Spectrum Density Bandwidth
Appendix A.30. Maximum and Median Frequency
References
- WHO for Europe. Strategy and Action Plan for Healthy Ageing in Europe, 2012–2020. Available online: https://www.euro.who.int/__data/assets/pdf_file/0008/175544/RC62wd10Rev1-Eng.pdf (accessed on 15 December 2021).
- Chodzko-Zajko, W.J.; Proctor, D.N.; Singh, M.A.F.; Minson, C.T.; Nigg, C.R.; Salem, G.J.; Skinner, J.S. Exercise and physical activity for older adults. Med. Sci. Sport. Exerc. 2009, 41, 1510–1530. [Google Scholar] [CrossRef] [PubMed]
- WHO, Geneva, Switzerland. Global Recommendations on Physical Activity for Health. Available online: https://www.who.int/dietphysicalactivity/global-PA-recs-2010.pdf (accessed on 15 December 2021).
- Allen, F.R.; Ambikairajah, E.; Lovell, N.H.; Celler, B.G. Classification of a known sequence of motions and postures from accelerometry data using adapted Gaussian mixture models. Physiol. Meas. 2006, 27, 935. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sekine, M.; Tamura, T.; Akay, M.; Fujimoto, T.; Togawa, T.; Fukui, Y. Discrimination of walking patterns using wavelet-based fractal analysis. IEEE Trans. Neural Syst. Rehabil. 2002, 10, 188–196. [Google Scholar] [CrossRef] [PubMed]
- Kamišalić, A.; Fister Jr, I.; Turkanović, M.; Karakatič, S. Sensors and functionalities of non-invasive wrist-wearable devices: A review. Sensors 2018, 18, 1714. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cleland, I.; Kikhia, B.; Nugent, C.; Boytsov, A.; Hallberg, J.; Synnes, K.; McClean, S.; Finlay, D. Optimal placement of accelerometers for the detection of everyday activities. Sensors 2013, 13, 9183–9200. [Google Scholar] [CrossRef] [Green Version]
- Khan, A.M.; Lee, Y.K.; Lee, S.Y.; Kim, T.S. A triaxial accelerometer-based physical-activity recognition via augmented-signal features and a hierarchical recognizer. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 1166–1172. [Google Scholar] [CrossRef]
- Leutheuser, H.; Schuldhaus, D.; Eskofier, B.M. Hierarchical, multi-sensor based classification of daily life activities: Comparison with state-of-the-art algorithms using a benchmark dataset. PLoS ONE 2013, 8, e75196. [Google Scholar] [CrossRef] [Green Version]
- Arif, M.; Bilal, M.; Kattan, A.; Ahamed, S.I. Better physical activity classification using smartphone acceleration sensor. J. Med Syst. 2014, 38, 1–10. [Google Scholar] [CrossRef]
- Shoaib, M.; Bosch, S.; Incel, O.D.; Scholten, H.; Havinga, P.J. Complex human activity recognition using smartphone and wrist-worn motion sensors. Sensors 2016, 16, 426. [Google Scholar] [CrossRef]
- Del Rosario, M.B.; Wang, K.; Wang, J.; Liu, Y.; Brodie, M.; Delbaere, K.; Lovell, N.H.; Lord, S.R.; Redmond, S.J. A comparison of activity classification in younger and older cohorts using a smartphone. Physiol. Meas. 2014, 35, 2269. [Google Scholar] [CrossRef]
- Usmani, S.; Saboor, A.; Haris, M.; Khan, M.A.; Park, H. Latest research trends in fall detection and prevention using machine learning: A systematic review. Sensors 2021, 21, 5134. [Google Scholar] [CrossRef] [PubMed]
- Preece, S.J.; Goulermas, J.Y.; Kenney, L.P.; Howard, D. A comparison of feature extraction methods for the classification of dynamic activities from accelerometer data. IEEE Trans. Biomed. Eng. 2008, 56, 871–879. [Google Scholar] [CrossRef] [PubMed]
- Bao, L.; Intille, S.S. Activity recognition from user-annotated acceleration data. In Proceedings of the International Conference on Pervasive Computing, Nottingham, UK, 7–10 September 2004; pp. 1–17. [Google Scholar]
- Guiry, J.J.; van de Ven, P.; Nelson, J.; Warmerdam, L.; Riper, H. Activity recognition with smartphone support. Med Eng. Phys. 2014, 36, 670–675. [Google Scholar] [CrossRef] [PubMed]
- Trabelsi, D.; Mohammed, S.; Chamroukhi, F.; Oukhellou, L.; Amirat, Y. An unsupervised approach for automatic activity recognition based on hidden Markov model regression. IEEE Trans. Autom. Sci. Eng. 2013, 10, 829–835. [Google Scholar] [CrossRef] [Green Version]
- Ganea, R.; Paraschiv-lonescu, A.; Aminian, K. Detection and classification of postural transitions in real-world conditions. IEEE Trans. Neural Syst. Rehabil. 2012, 20, 688–696. [Google Scholar] [CrossRef]
- Pedrero-Sánchez, J.F.; Belda-Lois, J.M.; Serra-Añó, P.; Inglés, M.; López-Pascual, J. Classification of healthy, Alzheimer and Parkinson populations with a multi-branch neural network. Biomed. Signal Process. Control 2022, 75, 103617. [Google Scholar] [CrossRef]
- Najafi, B.; Aminian, K.; Paraschiv-Ionescu, A.; Loew, F.; Bula, C.J.; Robert, P. Ambulatory system for human motion analysis using a kinematic sensor: Monitoring of daily physical activity in the elderly. IEEE Trans. Biomed. Eng. 2003, 50, 711–723. [Google Scholar] [CrossRef]
- Rehman, R.Z.U.; Del Din, S.; Guan, Y.; Yarnall, A.J.; Shi, J.Q.; Rochester, L. Selecting clinically relevant gait characteristics for classification of early parkinson’s disease: A comprehensive machine learning approach. Sci. Rep. 2019, 9, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Kwon, S.B.; Ku, Y.; Han, H.S.; Lee, M.C.; Kim, H.C.; Ro, D.H. A machine learning-based diagnostic model associated with knee osteoarthritis severity. Sci. Rep. 2020, 10, 1–8. [Google Scholar] [CrossRef]
- Awais, M.; Mellone, S.; Chiari, L. Physical activity classification meets daily life: Review on existing methodologies and open challenges. In Proceedings of the 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 25–29 August 2015; pp. 5050–5053. [Google Scholar]
- Awais, M.; Chiari, L.; Ihlen, E.A.; Helbostad, J.L.; Palmerini, L. Classical Machine Learning Versus Deep Learning for the Older Adults Free-Living Activity Classification. Sensors 2021, 21, 4669. [Google Scholar] [CrossRef]
- Scherder, E.; Eggermont, L.; Swaab, D.; van Heuvelen, M.; Kamsma, Y.; de Greef, M.; van Wijck, R.; Mulder, T. Gait in ageing and associated dementias; its relationship with cognition. Neurosci. Biobehav. Rev. 2007, 31, 485–497. [Google Scholar] [CrossRef]
- Della Sala, S.; Spinnler, H.; Venneri, A. Walking difficulties in patients with Alzheimer’s disease might originate from gait apraxia. J. Neurol. Neurosurg. Psychiatry 2004, 75, 196–201. [Google Scholar]
- Polikar, R. Ensemble based systems in decision making. IEEE Circuits Syst. Mag. 2006, 6, 21–45. [Google Scholar] [CrossRef]
- Okey, O.D.; Maidin, S.S.; Adasme, P.; Lopes Rosa, R.; Saadi, M.; Carrillo Melgarejo, D.; Zegarra Rodríguez, D. BoostedEnML: Efficient Technique for Detecting Cyberattacks in IoT Systems Using Boosted Ensemble Machine Learning. Sensors 2022, 22, 7409. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Zhang, L.; Zhao, K.; Ding, X.; Yu, M. MFDroid: A Stacking Ensemble Learning Framework for Android Malware Detection. Sensors 2022, 22, 2597. [Google Scholar] [CrossRef] [PubMed]
- Dutta, V.; Choraś, M.; Pawlicki, M.; Kozik, R. A deep learning ensemble for network anomaly and cyber-attack detection. Sensors 2020, 20, 4583. [Google Scholar] [CrossRef] [PubMed]
- Alsaedi, M.; Ghaleb, F.A.; Saeed, F.; Ahmad, J.; Alasli, M. Cyber Threat Intelligence-Based Malicious URL Detection Model Using Ensemble Learning. Sensors 2022, 22, 3373. [Google Scholar] [CrossRef] [PubMed]
- Talaei Khoei, T.; Ismail, S.; Kaabouch, N. Dynamic selection techniques for detecting GPS spoofing attacks on UAVs. Sensors 2022, 22, 662. [Google Scholar] [CrossRef]
- Derhab, A.; Guerroumi, M.; Gumaei, A.; Maglaras, L.; Ferrag, M.A.; Mukherjee, M.; Khan, F.A. Blockchain and random subspace learning-based IDS for SDN-enabled industrial IoT security. Sensors 2019, 19, 3119. [Google Scholar] [CrossRef] [Green Version]
- Yuan, J.; Liu, L.; Yang, Z.; Zhang, Y. Tool wear condition monitoring by combining variational mode decomposition and ensemble learning. Sensors 2020, 20, 6113. [Google Scholar] [CrossRef]
- Xu, G.; Liu, M.; Jiang, Z.; Söffker, D.; Shen, W. Bearing fault diagnosis method based on deep convolutional neural network and random forest ensemble learning. Sensors 2019, 19, 1088. [Google Scholar] [CrossRef]
- Beretta, M.; Julian, A.; Sepulveda, J.; Cusidó, J.; Porro, O. An ensemble learning solution for predictive maintenance of wind turbines main bearing. Sensors 2021, 21, 1512. [Google Scholar] [CrossRef] [PubMed]
- Ai, S.; Chakravorty, A.; Rong, C. Household power demand prediction using evolutionary ensemble neural network pool with multiple network structures. Sensors 2019, 19, 721. [Google Scholar] [CrossRef] [Green Version]
- Ku Abd. Rahim, K.N.; Elamvazuthi, I.; Izhar, L.I.; Capi, G. Classification of human daily activities using ensemble methods based on smartphone inertial sensors. Sensors 2018, 18, 4132. [Google Scholar] [CrossRef] [Green Version]
- Mahendran, N.; Vincent, D.R.; Srinivasan, K.; Chang, C.Y.; Garg, A.; Gao, L.; Reina, D.G. Sensor-assisted weighted average ensemble model for detecting major depressive disorder. Sensors 2019, 19, 4822. [Google Scholar] [CrossRef] [Green Version]
- Aljihmani, L.; Kerdjidj, O.; Zhu, Y.; Mehta, R.K.; Erraguntla, M.; Sasangohar, F.; Qaraqe, K. Classification of Fatigue Phases in Healthy and Diabetic Adults Using Wearable Sensor. Sensors 2020, 20, 6897. [Google Scholar] [CrossRef]
- Wall, C.; Zhang, L.; Yu, Y.; Kumar, A.; Gao, R. A deep ensemble neural network with attention mechanisms for lung abnormality classification using audio inputs. Sensors 2022, 22, 5566. [Google Scholar] [CrossRef]
- Peimankar, A.; Puthusserypady, S. An ensemble of deep recurrent neural networks for p-wave detection in electrocardiogram. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 1284–1288. [Google Scholar]
- Peimankar, A.; Puthusserypady, S. Ensemble learning for detection of short episodes of atrial fibrillation. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 66–70. [Google Scholar]
- Resmini, R.; Silva, L.; Araujo, A.S.; Medeiros, P.; Muchaluat-Saade, D.; Conci, A. Combining genetic algorithms and SVM for breast cancer diagnosis using infrared thermography. Sensors 2021, 21, 4802. [Google Scholar] [CrossRef] [PubMed]
- Dissanayake, T.; Rajapaksha, Y.; Ragel, R.; Nawinne, I. An ensemble learning approach for electrocardiogram sensor based human emotion recognition. Sensors 2019, 19, 4495. [Google Scholar] [CrossRef] [Green Version]
- Luo, J.; Gao, X.; Zhu, X.; Wang, B.; Lu, N.; Wang, J. Motor imagery EEG classification based on ensemble support vector learning. Comput. Methods Programs Biomed. 2020, 193, 105464. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.C.; Tsai, Y.C.; Wu, P.Y.; Lien, Y.H.; Chien, C.Y.; Kuo, C.F.; Hung, J.F.; Chen, S.C.; Kuo, C.H. Predictive modeling of blood pressure during hemodialysis: A comparison of linear model, random forest, support vector regression, XGBoost, LASSO regression and ensemble method. Comput. Methods Programs Biomed. 2020, 195, 105536. [Google Scholar] [CrossRef] [PubMed]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95-International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- SENS Innovation ApS. SENS Innovation ApS. Available online: https://sens.dk/en/ (accessed on 30 November 2022).
- Barandas, M.; Folgado, D.; Fernandes, L.; Santos, S.; Abreu, M.; Bota, P.; Liu, H.; Schultz, T.; Gamboa, H. TSFEL: Time series feature extraction library. SoftwareX 2020, 11, 100456. [Google Scholar] [CrossRef]
- Kira, K.; Rendell, L.A. A practical approach to feature selection. In Machine Learning Proceedings 1992; Elsevier: Amsterdam, The Netherlands, 1992; pp. 249–256. [Google Scholar]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Peimankar, A.; Weddell, S.J.; Jalal, T.; Lapthorn, A.C. Evolutionary multi-objective fault diagnosis of power transformers. Swarm Evol. Comput. 2017, 36, 62–75. [Google Scholar] [CrossRef]
- Peimankar, A.; Weddell, S.J.; Jalal, T.; Lapthorn, A.C. Multi-objective ensemble forecasting with an application to power transformers. Appl. Soft Comput. 2018, 68, 233–248. [Google Scholar] [CrossRef]
- Eberhart, R.C.; Shi, Y.; Kennedy, J. Swarm Intelligence; Elsevier: Amsterdam, The Netherlands, 2001. [Google Scholar]
- Shi, Y. Particle swarm optimization: Developments, applications and resources. In Proceedings of the 2001 Congress on Evolutionary Computation (IEEE Cat. No. 01TH8546), Seoul, Republic of Korea, 27–30 May 2001; Volume 1, pp. 81–86. [Google Scholar]
- Fix, E.; Hodges, J.L. Discriminatory analysis. Nonparametric discrimination: Consistency properties. Int. Stat. Rev. Int. De Statistique 1989, 57, 238–247. [Google Scholar] [CrossRef]
- Altman, N.S. An introduction to kernel and nearest-neighbor nonparametric regression. Am. Stat. 1992, 46, 175–185. [Google Scholar]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Routledge: London, UK, 2017. [Google Scholar]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 1, pp. 278–282. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Ting, K.M.; Witten, I.H. Stacked generalization: When does it work? In Proceedings of the Fifteenth International Joint Conference on Artifical Intelligence, Nagoya, Japan, 23–29 August 1997; Volume 2, pp. 866–871. [Google Scholar]
- Ting, K.M.; Witten, I.H. Issues in stacked generalization. J. Artif. Intell. Res. 1999, 10, 271–289. [Google Scholar] [CrossRef] [Green Version]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Harris, C.R.; Millman, K.J.; Van Der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef]
- McKinney, W. Data structures for statistical computing in python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010; Volume 445, pp. 51–56. [Google Scholar]
- Hunter, J.D. Matplotlib: A 2D graphics environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- Gubner, J.A. Probability and Random Processes for Electrical and Computer Engineers; Cambridge University Press: Cambridge, UK, 2006. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Pathria, R.K.; Beale, P.D. Statistical Mechanics; Butterworth-Heinemann: Oxford, UK, 2011. [Google Scholar]
- Sandra, L. PHB Practical Handbook of Curve Fitting; CRC Press: Boca Raton, FL, USA, 1994. [Google Scholar]
- Humpherys, J.; Jarvis, T.J.; Evans, E.J. Foundations of Applied Mathematics, Volume I: Mathematical Analysis; SIAM: Philadelphia, PA, USA, 2017; Volume 152. [Google Scholar]
- Christ, M.; Braun, N.; Neuffer, J.; Kempa-Liehr, A.W. Time series feature extraction on basis of scalable hypothesis tests (tsfresh–a python package). Neurocomputing 2018, 307, 72–77. [Google Scholar] [CrossRef]
- Cohen, L. Time-Frequency Analysis; Prentice Hall: Hoboken, NJ, USA, 1995; Volume 778. [Google Scholar]
- Kwong, S.; Gang, W.; Zheng, O.Y.J. Fundamental frequency estimation based on adaptive time-averaging Wigner-Ville distribution. In Proceedings of the IEEE-SP International Symposium on Time-Frequency and Time-Scale Analysis, Victoria, BC, Canada, 4–6 October 1992; pp. 413–416. [Google Scholar]
- Bogert, B.P. The quefrency alanysis of time series for echoes; Cepstrum, pseudo-autocovariance, cross-cepstrum and saphe cracking. Time Ser. Anal. 1963, 209–243. [Google Scholar]
- Reynolds, D.A. Speaker identification and verification using Gaussian mixture speaker models. Speech Commun. 1995, 17, 91–108. [Google Scholar] [CrossRef]
- Xu, M.; Duan, L.Y.; Cai, J.; Chia, L.T.; Xu, C.; Tian, Q. HMM-based audio keyword generation. In Proceedings of the Pacific-Rim Conference on Multimedia, Tokyo, Japan, 30 November–3 December 2004; pp. 566–574. [Google Scholar]
- Peeters, G. A large set of audio features for sound description (similarity and classification) in the CUIDADO project. CUIDADO Ist Proj. Rep. 2004, 54, 1–25. [Google Scholar]
- Fell, J.; Röschke, J.; Mann, K.; Schäffner, C. Discrimination of sleep stages: A comparison between spectral and nonlinear EEG measures. Electroencephalogr. Clin. Neurophysiol. 1996, 98, 401–410. [Google Scholar] [CrossRef]
- Peeters, G.; Giordano, B.L.; Susini, P.; Misdariis, N.; McAdams, S. The timbre toolbox: Extracting audio descriptors from musical signals. J. Acoust. Soc. Am. 2011, 130, 2902–2916. [Google Scholar] [CrossRef] [Green Version]
- Krimphoff, J.; McAdams, S.; Winsberg, S.; Petit, H.; Bakchine, S.; Dubois, B.; Laurent, B.; Montagne, B.; Touchon, J.; Robert, P.; et al. Characterization of the timbre of complex sounds. 2. Acoustic analysis and psychophysical quantification. J. Phys. 1994, 4, 625–628. [Google Scholar]
- Addison, P.S. The Illustrated Wavelet Transform Handbook: Introductory Theory and Applications in Science, Engineering, Medicine and Finance; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Yan, B.; Miyamoto, A.; Brühwiler, E. Wavelet transform-based modal parameter identification considering uncertainty. J. Sound Vib. 2006, 291, 285–301. [Google Scholar] [CrossRef]
- Welch, P. The use of fast Fourier transform for the estimation of power spectra: A method based on time averaging over short, modified periodograms. IEEE Trans. Audio Electroacoust. 1967, 15, 70–73. [Google Scholar] [CrossRef] [Green Version]
- Phinyomark, A.; Phukpattaranont, P.; Limsakul, C. Feature reduction and selection for EMG signal classification. Expert Syst. Appl. 2012, 39, 7420–7431. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Sex | Age | Walking Aids | Dementia Diagnosis |
|---|---|---|---|---|
| 1 | Male | 90 | Stick | Alzheimer’s disease |
| 2 | Male | 82 | None | Lewy body dementia |
| 3 | Female | 85 | Crutch | Unknown |
| 4 | Female | 75 | None | Alzheimer’s disease |
| 5 | Male | 63 | None | Lewy body dementia |
| 6 | Male | 68 | None | Alzheimer’s disease |
| 7 | Male | 62 | None | Alzheimer’s disease |
| 8 | Male | 80 | None | Dementia |
| 9 | Male | 89 | Walker | Unknown |
| 10 | Female | 84 | Walker | Unknown |
| 11 | Male | 66 | None | Unknown |
| 12 | Male | 73 | None | Parkinson’s disease |
| 13 | Male | 79 | Walker | Parkinson’s disease |
| 14 | Female | 72 | Walker | Unknown |
| 15 | Female | 87 | None | Alzheimer’s disease |
| 16 | Female | 72 | Walker | Vascular dementia |
| 17 | Male | 90 | None | Alzheimer’s disease |
| 18 | Male | 79 | None | Alcohol-related dementia |
| 19 | Male | 79 | None | Alzheimer’s disease |
| 20 | Male | 68 | None | Dementia |
| Feature Domain | ||
|---|---|---|
| Statistical | Temporal | Spectral |
| (1) Empirical cumulative distribution function | (17) Absolute energy | (35) Mean value of each spectrogram frequency |
| (2) ECDF percentile | (18) Total energy | (36) Fundamental frequency |
| (3) ECDF percentile count | (19) Centroid | (37) Human range energy ratio |
| (4) Histogram | (20) Area under the curve | (38) Linear prediction cepstral coefficients |
| (5) Interquartile range | (21) Autocorrelation | (39) Mel-frequency cepstral coefficients |
| (6) Minimum | (22) Shannon entropy | (40) Spectral positive turning points |
| (7) Maximum | (23) Mean absolute differences | (41) Spectral roll-off |
| (8) Mean | (24) Median absolute differences | (42) Spectral entropy |
| (9) Median | (25) Mean of differences | (43) Spectral roll-on |
| (10) Mean absolute deviation | (26) Median of differences | (44) Maximum power spectrum density |
| (11) Median absolute deviation | (27) Sum of absolute differences | (45) Maximum frequency |
| (12) Root Mean Square | (28) Positive turning points | (46) Median frequency |
| (13) Variance | (29) Negative turning points | (47) Power spectrum density bandwidth |
| (14) Standard Deviation | (30) Zero-crossing rate | (48) Spectral centroid |
| (15) Kurtosis | (31) Peak to peak distance | (49) Spectral decrease |
| (16) Skewness | (32) Traveled distance | (50) Spectral distance |
| (33) Slope of signal | (51) Spectral kurtosis | |
| (34) Number of peaks from a subsequence | (52) Spectral skewness | |
| (53) Spectral slope | ||
| (54) Spectral spread | ||
| (55) Spectral variation | ||
| (56) Wavelet absolute mean | ||
| (57) Wavelet energy | ||
| (58) Wavelet standard deviation | ||
| (59) Wavelet entropy | ||
| (60) Wavelet variance | ||
| Class | Imbalanced | Balanced |
|---|---|---|
| Walking | 20,456 | 70,779 |
| Non-walking (other activities) | 72,746 | 72,746 |
| Predicted Negative | Predicted Positive | |
|---|---|---|
| Actual negative | True negative (TN) | False positive (FP) |
| Actual positive | False negative (FN) | True positive (TP) |
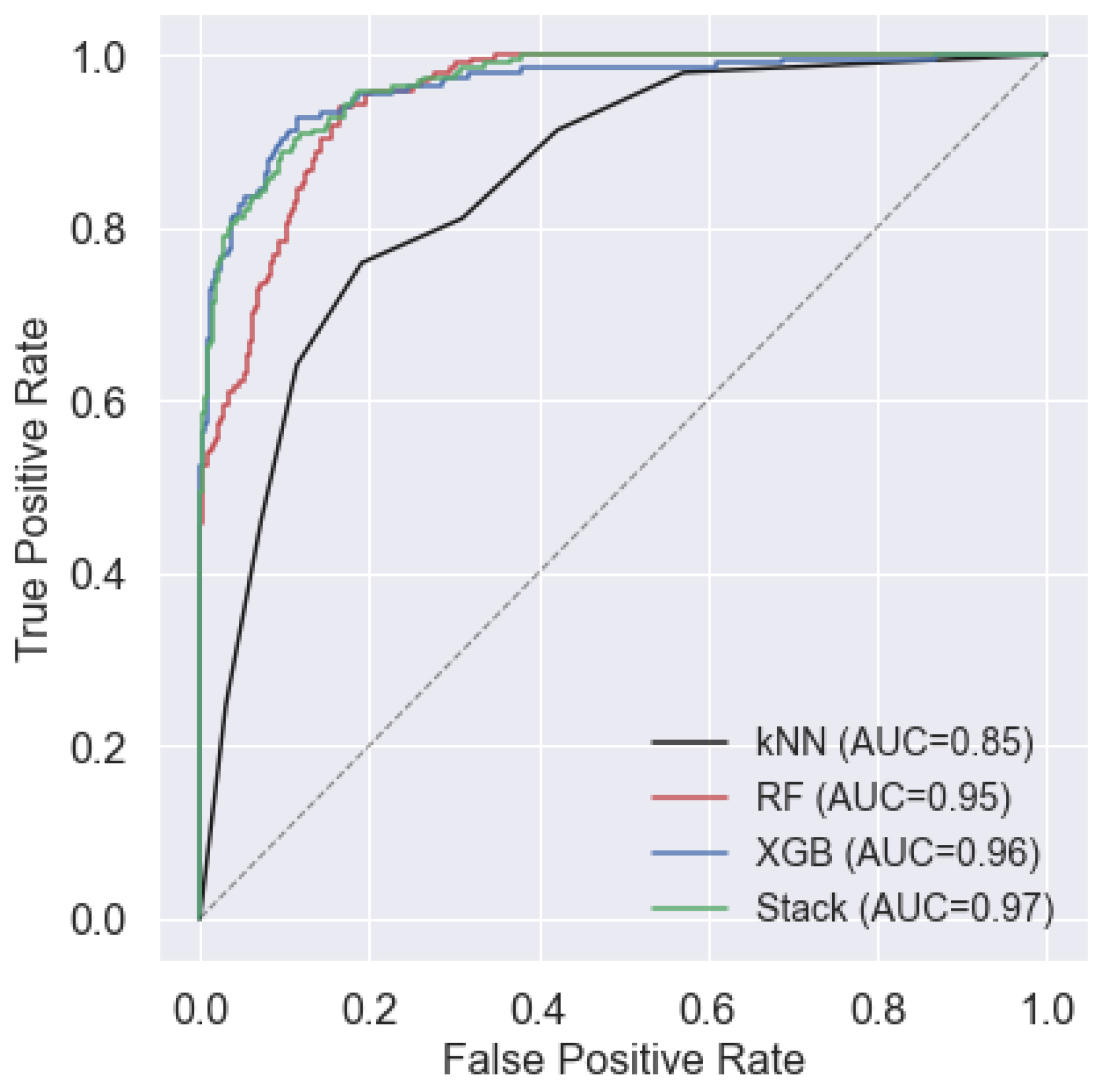
| Algorithm | Se | F1-Score | PPV | Acc |
|---|---|---|---|---|
| kNN | 77.38 | 76.58 | 74.95 | 79.75 |
| RF | 77.96 | 81.25 | 84.85 | 87.73 |
| XGB | 84.53 | 87.25 | 94.02 | 92.47 |
| Stack | 86.85 | 88.81 | 93.25 | 93.32 |
| ID | Se | F1-Score | PPV | Acc | Selected Features Numbers (Table 2) |
|---|---|---|---|---|---|
| 1 | 90 | 94 | 99 | 97 | 1–4, 8, 12, 13, 17, 19–21, 23, 35, 37–44, 52, 55–60 |
| 2 | 85 | 87 | 89 | 93 | 1–4, 6, 9–11, 14, 16, 17, 29, 31, 34, 35, 38, 39, 42–44, 48, 50–57, 60 |
| 3 | 90 | 93 | 97 | 97 | 1, 4, 10, 13, 21, 25, 28, 33–35, 37–42, 45, 48, 50, 52, 56–58, 60 |
| 4 | 86 | 92 | 98 | 98 | 1, 2, 4, 7, 9, 10, 15, 19, 20, 21, 25, 28, 29, 31, 35–38, 46, 47, 49, 52–58, 60 |
| 5 | 85 | 87 | 90 | 93 | 1, 3, 4, 6, 7, 9, 10, 13, 15-18, 21, 23, 31, 33, 35, 36, 38, 39, 41–43, 50, 51, 55–59, 60 |
| 6 | 90 | 91 | 92 | 94 | 1–6, 8, 12, 14, 23, 28, 29, 31, 33, 35-37, 39, 41, 44, 45, 47, 48, 50–53, 55-58, 60 |
| 7 | 93 | 96 | 100 | 98 | 1–4, 10, 12, 13, 16, 17, 18, 20, 21, 24, 30, 35–40, 43, 45, 47, 48, 50–52, 54–60 |
| 8 | 90 | 93 | 96 | 92 | 1, 3-5, 11, 13, 15, 16, 19, 29–31, 34–36, 38, 39, 43, 44, 48, 50–52, 54, 56–58, 60 |
| 9 | 75 | 72 | 81 | 73 | 1, 2, 4–7, 10, 21–23, 28, 31, 35, 36, 38, 39, 40, 41, 43, 48–51, 56–57, 60 |
| 10 | 73 | 75 | 80 | 81 | 1–5, 7, 9, 10, 13, 20–22, 23, 27, 28, 34–36, 38, 39, 53–56, 58–60 |
| 11 | 88 | 93 | 98 | 97 | 1, 2, 4, 16, 18–20, 22, 29, 30, 33–35, 38, 39, 41, 46, 50, 51, 54, 56–58, 60 |
| 12 | 90 | 94 | 98 | 98 | 1–4, 6, 9, 11, 13, 14, 15, 17, 20–24, 28, 33, 35–39, 41–43, 45, 49, 52, 56–58, 60 |
| 13 | 90 | 93 | 96 | 96 | 1–5, 8–11, 13, 15–17, 19–21, 26, 29, 34, 36, 38, 39, 49, 51–54, 56–58, 60 |
| 14 | 78 | 76 | 74 | 89 | 1, 3, 4, 6, 7, 9, 11, 14, 17, 18, 20, 22, 26–29, 31, 33, 38, 39, 41, 48, 49, 51, 56–58, 60 |
| 15 | 89 | 91 | 94 | 95 | 1, 4, 8, 10, 11, 13–15, 17–20, 25–27, 33–35, 38–41, 48, 49, 54, 57, 58, 60 |
| 16 | 90 | 92 | 95 | 95 | 1–4, 9, 10, 12, 14, 20, 23, 27, 28, 30, 31, 33, 37–39, 42, 47, 53, 56–58, 60 |
| 17 | 90 | 94 | 98 | 98 | 1–5, 8, 11–14, 17, 21, 30, 38, 39, 40, 41, 43, 45, 52, 54, 56, 57, 60 |
| 18 | 89 | 92 | 95 | 97 | 1, 3–6, 10, 12, 13–18, 21, 26, 28, 30, 34–39, 42, 45, 46, 51–54, 56–58, 60 |
| 19 | 90 | 94 | 98 | 98 | 1, 4, 5, 8–10, 12, 16, 18, 21, 24, 25, 35, 38, 39, 42, 43, 49, 50–53, 56–58, 60 |
| 20 | 89 | 93 | 97 | 94 | 1, 2, 4, 6, 7, 12, 15, 21, 22, 24–26, 28, 30, 31, 34, 35, 38, 39, 41, 43, 44, 47–50, 56–58, 60 |
| Algorithm | S = 3 | S = 6 | S = 9 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Se | F1-Score | PPV | Acc | Se | F1-Score | PPV | Acc | Se | F1-Score | PPV | Acc | |
| kNN | 77.89 | 79.19 | 77.89 | 82.39 | 78.39 | 76.01 | 74.84 | 79.53 | 82.30 | 81.12 | 80.22 | 84.57 |
| RF | 80.21 | 81.09 | 82.17 | 85.49 | 78.54 | 80.81 | 84.68 | 86.07 | 82.98 | 84.91 | 87.69 | 88.79 |
| XGB | 81.66 | 84.49 | 89.46 | 88.87 | 84.20 | 87.23 | 92.42 | 90.81 | 83.71 | 86.13 | 89.91 | 89.85 |
| Stack | 83.01 | 85.12 | 88.28 | 89.00 | 86.13 | 88.50 | 92.03 | 91.50 | 85.37 | 87.26 | 89.88 | 90.49 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peimankar, A.; Winther, T.S.; Ebrahimi, A.; Wiil, U.K. A Machine Learning Approach for Walking Classification in Elderly People with Gait Disorders. Sensors 2023, 23, 679. https://doi.org/10.3390/s23020679
Peimankar A, Winther TS, Ebrahimi A, Wiil UK. A Machine Learning Approach for Walking Classification in Elderly People with Gait Disorders. Sensors. 2023; 23(2):679. https://doi.org/10.3390/s23020679
Chicago/Turabian StylePeimankar, Abdolrahman, Trine Straarup Winther, Ali Ebrahimi, and Uffe Kock Wiil. 2023. "A Machine Learning Approach for Walking Classification in Elderly People with Gait Disorders" Sensors 23, no. 2: 679. https://doi.org/10.3390/s23020679
APA StylePeimankar, A., Winther, T. S., Ebrahimi, A., & Wiil, U. K. (2023). A Machine Learning Approach for Walking Classification in Elderly People with Gait Disorders. Sensors, 23(2), 679. https://doi.org/10.3390/s23020679