
Research on Lane Line Detection Algorithm Based on Instance Segmentation


Abstract
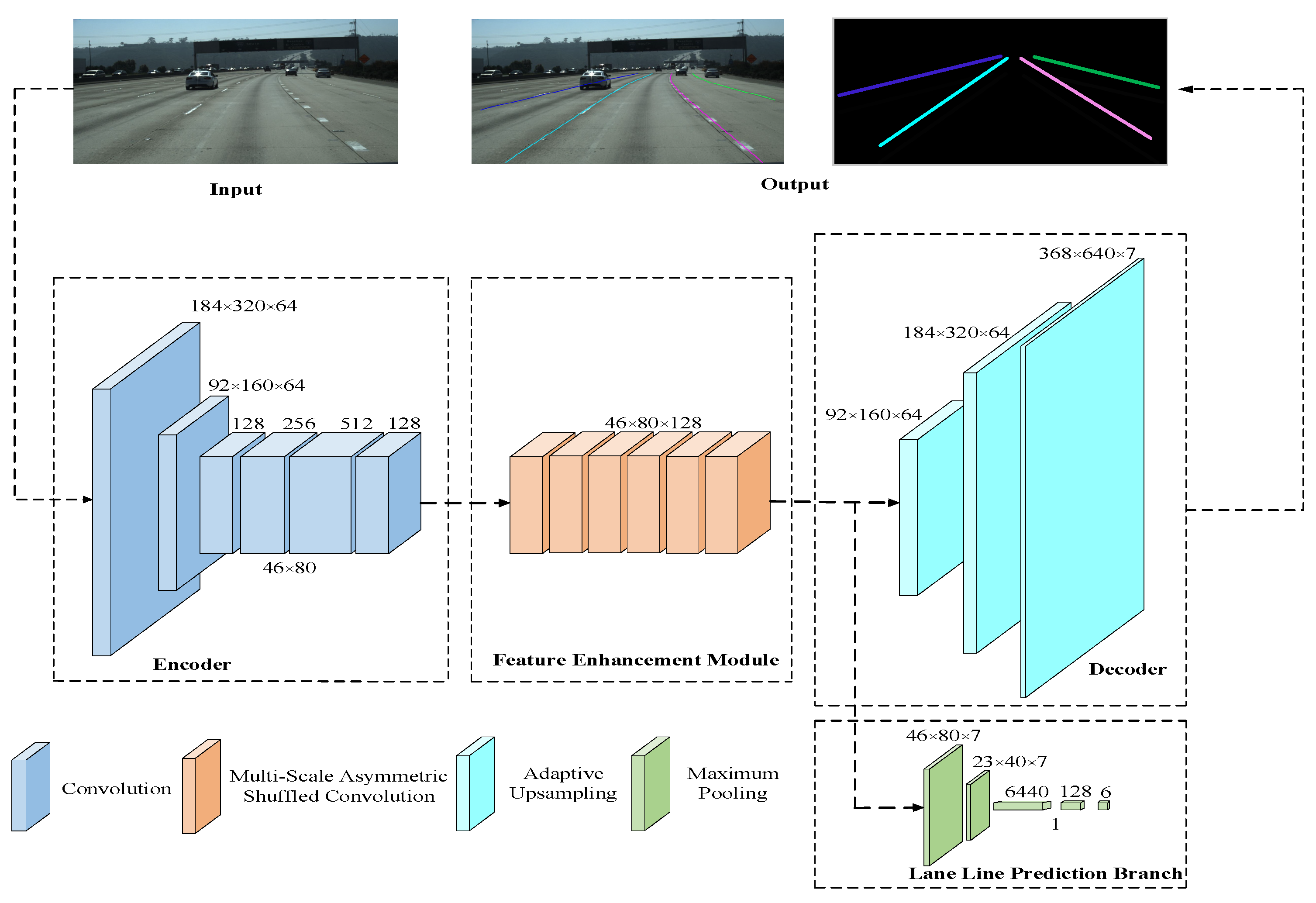
:1. Introduction
- Improve the RepVgg-A0 network to expand the receptive field of the network without increasing the amount of calculations, and propose a multi-size asymmetric shuffled convolution model to enhance the extraction of sparse and slender lane lines ability.
- An adaptive upsampling model is proposed, which allows the network to select the weight of the two upsampling methods at each position; at the same time, a lane line prediction branch is added to facilitate the output of lane line confidence.
- Deploy the lane line detection algorithm to the embedded platform Jetson Nano, and use the TensorRT framework for half-precision acceleration to make its detection speed meet the needs of real-time detection.
2. Design of Lane Line Detection Model
2.1. Design of Encoder Network Structure
2.2. Design of Feature Enhancement Model
2.3. Design of Decoder Network Structure
2.4. Design of Lane Line Prediction Branch
2.5. Proposed Lane Detection Model
3. Experimental Results and Analysis
3.1. Dataset and Preprocessing
3.2. Experiment Preparation
3.3. Model Evaluation Index and Performance Comparison of Different Models
3.4. Comparison of Loss Function Curves
3.5. Comparison of Lane Line Detection Effects
3.6. Lane Line Detection and Mobile Terminal Deployment in Different Scenarios
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Haris, M.; Hou, J. Obstacle Detection and Safely Navigate the Autonomous Vehicle from Unexpected Obstacles on the Driving Lane. Sensors 2020, 20, 4719. [Google Scholar] [CrossRef] [PubMed]
- Yang, W.; Zhang, X.; Lei, Q. Lane Position Detection Based on Long Short-Term Memory (LSTM). Sensors 2020, 20, 3115. [Google Scholar] [CrossRef] [PubMed]
- Mammeri, A.; Boukerche, A.; Tang, Z. A real-time lane marking localization, tracking and communication system. Comput. Commun. 2015, 73, 229. [Google Scholar] [CrossRef]
- Sotelo, N.; Rodríguez, J.; Magdalena, L. A Color Vision-Based Lane Tracking System for Autonomous Driving on Unmarked Roads. Auton. Robot. 2004, 1, 95–116. [Google Scholar] [CrossRef] [Green Version]
- Ozgunalp, N.; Dahnoun, N. Lane detection based on improved feature map and efficient region of interest extraction. In Proceedings of the 2015 IEEE Global Conference Signal and Information Process (GlobalSIP, IEEE 2015), Orlando, FL, USA, 14–16 December 2015. [Google Scholar] [CrossRef]
- Chi, F.H.; Huo, Y.H. Forward vehicle detection system based on lane-marking tracking with fuzzy adjustable vanishing point mechanism. In Proceedings of the 2012 IEEE International Conference on Fuzzy Systems, Brisbane, QLD, Australia, 10–15 June 2012. [Google Scholar] [CrossRef] [Green Version]
- Lin, H.Y.; Dai, J.M.; Wu, L.T.; Chen, L.Q. A Vision-Based Driver Assistance System with Forward Collision and Overtaking Detection. Sensors 2020, 20, 5139. [Google Scholar] [CrossRef] [PubMed]
- Li, K.; Shao, J.; Guo, D. A Multi-Feature Search Window Method for Road Boundary Detection Based on LIDAR Data. Sensors 2019, 19, 1551. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cao, Y.; Chen, Y.; Khosla, D. Spiking deep convolutional neural networks for energy-efficient object Recognition. Int. J. Comput. Vis. 2014, 113, 54–66. [Google Scholar] [CrossRef]
- Zhang, X.; Yang, W.; Tang, X.; Wang, Y. Lateral distance detection model based on convolutional neural network. IET Intell. Transp. Syst. 2019, 13, 31–39. [Google Scholar] [CrossRef]
- Kim, J.; Kim, J.; Jang, G.-J.; Lee, M. Fast learning method for convolutional neural networks using extreme learning machine and its application to lane detection. Neural Netw. 2017, 87, 109–121. [Google Scholar] [CrossRef] [PubMed]
- Aly, M. Real time detection of lane markers in urban streets. In Proceedings of the IEEE Intelligent Vehicles Symposium, Eindhoven, The Netherlands, 4–6 June 2008. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Park, C. End-To-End Ego Lane Estimation Based on Sequential Transfer Learning for Self-Driving Cars. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW, 2017), Honolulu, HI, USA, 21–26 July 2017; p. 1194. [Google Scholar] [CrossRef]
- Neven, D.; de Brabandere, B.; Georgoulis, S.M. Towards End-to-End Lane Detection: An Instance Segmentation Approach. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium(IV), Changshu, China, 26–30 June 2018; p. 286. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 6, 1137. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 9, 1904. [Google Scholar] [CrossRef] [Green Version]
- Haris, M.; Jin, H.; Xiao, W. Lane line detection and departure estimation in a complex environment by using an asymmetric kernel convolution algorithm. Vis. Comput. 2022, 1–10. [Google Scholar] [CrossRef]
- Liu, R.; Yuan, Z.; Liu, T. End-to-end lane shape prediction with transformers. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Online, 5–9 January 2021; pp. 3694–3702. [Google Scholar]
- Chao, M.; Dean, L.; He, H. Lane Line Detection Based on Improved Semantic Segmentation. Sens. Mater. 2021, 33, 4545–4560. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T. Shufflenet v2: Practical guidelines for efficient CNN architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021; pp. 13733–13742. [Google Scholar]
- Qiu, S.; Xu, X.; Cai, B. FReLU: Flexible rectified linear units for improving convolutional neural networks. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 1223–1228. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Zheng, T.; Fang, H.; Zhang, Y. Resa: Recurrent feature-shift aggregator for lane detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 35, pp. 3547–3554. [Google Scholar]
- Romera, E.; Alvarez, J.M.; Bergasa, L. Erfnet: Efficient residual factorized convnet for real-time semantic segmentation. IEEE Trans. Intell. Transp. Syst. 2017, 19, 263–272. [Google Scholar] [CrossRef]
- Wang, P.; Chen, P.; Yuan, Y. Understanding convolution for semantic segmentation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), IEEE, Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Paszke, A.; Chaurasia, A.; Kim, S. Enet: A deep neural network architecture for real-time semantic segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Lu, P.; Xu, S.; Peng, H. Graph-Embedded Lane Detection. IEEE Trans. Image Process. 2021, 30, 2977–2988. [Google Scholar] [CrossRef] [PubMed]
- Pan, X.; Shi, J.; Luo, P. Spatial as deep: Spatial cnn for traffic scene understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Hou, Y.; Ma, Z.; Liu, C. Learning lightweight lane detection CNNS by self attention distillation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1013–1021. [Google Scholar]
- Wang, B.; Wang, Z.; Zhang, Y. Polynomial regression network for variable-number lane detection. In Proceedings of the European Conference on Computer Vision, Online, 23–28 August 2020; pp. 719–734. [Google Scholar]
- Su, J.; Chen, C.; Zhang, K. Structure guided lane detection. arXiv 2021, arXiv:2105.05403. [Google Scholar]
- Liu, Y.B.; Zeng, M.; Meng, Q.H. Heatmap-based vanishing point boosts lane detection. arXiv 2020, arXiv:2007.15602. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Output Size | Convolution Kernel | Step | Hole Rate | Number of Stacks | Output Channels |
|---|---|---|---|---|---|---|
| Input | 368 × 640 | 3 | ||||
| Stage0 | 184 × 320 | 3 × 3 | 2 | 1 | 1 | 48 |
| Stage1 | 92 × 160 | 3 × 3 | 2 | 1 | 2 | 48 |
| Stage2 | 46 × 80 | 3 × 3 | 2 | 2 | 4 | 96 |
| Stage3 | 46 × 80 | 3 × 3 | 1 | 2 | 14 | 192 |
| Stage4 | 46 × 80 | 3 × 3 | 1 | 4 | 1 | 1280 |
| Conv5 | 46 × 80 | 1 × 1 | 1 | 1 | 1 | 128 |
| Name | Value |
|---|---|
| Batch size | 8 |
| Iterations | 300 |
| Initial learning rate | 0.02 |
| Optimizer | SGD |
| Optimizer decay factor | 0.0001 |
| Net | Acc (%) | FP | FN | Params (M) | FLOPs (G) | FPS |
|---|---|---|---|---|---|---|
| ENet-SAD | 90.13 | 0.0875 | 0.0810 | 11.12 | 56.33 | 75.1 |
| Res34-VP | 90.42 | 0.0891 | 0.0801 | 20.15 | 75.65 | 37.6 |
| RESA-50 | 92.14 | 0.0876 | 0.0296 | 20.22 | 41.96 | 36.7 |
| SGLD-34 | 92.18 | 0.0798 | 0.0589 | 13.56 | 45.12 | 59.3 |
| Res18-Seg | 92.69 | 0.0948 | 0.0822 | 12.03 | 42.63 | 79.3 |
| Res34-Seg | 92.84 | 0.0918 | 0.0796 | 22.14 | 79.88 | 34.2 |
| ENet | 93.02 | 0.0886 | 0.0734 | 0.95 | 2.20 | 72.6 |
| LaneNet | 96.38 | 0.0780 | 0.0224 | 20.66 | 111.31 | 35.8 |
| SCNN | 96.53 | 0.0617 | 0.0180 | 12.63 | 42.67 | 64.7 |
| Our model | 96.70 | 0.0359 | 0.0282 | 9.57 | 36.67 | 77.5 |
| Baseline | Adaptive Upsampling Module | Feature Enhancement Module | Acc/% |
|---|---|---|---|
| √ | 95.81 | ||
| √ | 96.01(+0.20) | ||
| √ | 96.63(+0.82) | ||
| √ | √ | 96.70(+0.89) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, W.; Wang, X.; Mao, B. Research on Lane Line Detection Algorithm Based on Instance Segmentation. Sensors 2023, 23, 789. https://doi.org/10.3390/s23020789
Cheng W, Wang X, Mao B. Research on Lane Line Detection Algorithm Based on Instance Segmentation. Sensors. 2023; 23(2):789. https://doi.org/10.3390/s23020789
Chicago/Turabian StyleCheng, Wangfeng, Xuanyao Wang, and Bangguo Mao. 2023. "Research on Lane Line Detection Algorithm Based on Instance Segmentation" Sensors 23, no. 2: 789. https://doi.org/10.3390/s23020789