1. Introduction
Sports have become more data driven in recent years. In competitive and professional sports, all athletes are monitored in nearly every game and, if possible, also during training. The monitoring provides data that can be analysed to further improve the performance of individual athletes or the team, but it can also deliver information about opposition teams, their tactics and strategy, strength and weaknesses, etc. [
1,
2,
3,
4,
5]. As the amount of available data is too large to be processed efficiently by coaches and analysts, the state of the art in the analysis of such data comprises a mixture of computer-aided and human analysis and evaluation [
2,
5,
6,
7,
8]. The computer-aided part of the analysis is mostly based on modern algorithms, e.g., methods of machine learning [
9,
10,
11,
12,
13], though before any analysis can be carried out, the data has to be gathered. Hence, some sort of monitoring device or sensor is needed.
The digi sporting consortium has published an overview of electronic performance and tracking systems (EPTS) under [
14], which reflects the state of the art, how monitoring of athletes is achieved in many sports, such as running, soccer and rugby. The major information that should be monitored is highly dependent on the sport. Therefore, a wide range of EPTS are used throughout various sports. Nevertheless, they rely on mostly the same measurement methods to gain the data.
In many sports, the position of an athlete is a highly relevant information, so the major methods to determine an athletes position are either optically based or inertial measurement unit (IMU) based. In some cases, the IMU-based method is extended and combined with some global navigation satellite systems (GNSS), depending on the sport. Saramento et al. reviewed the most common methods for match analysis in soccer in many parts of the world, which relied mostly on video data [
4]. At the same time, companies such as Statsports provide products reliant on IMU and GNSS data to determine the performance in soccer and other sports [
15,
16]. Positions and their change over time were also measured optically by [
17,
18,
19] in their studies throughout several sports. In the context of American football, the position information is also relevant, but there are other metrics relevant from a positional perspective. A more detailed performance analysis, with respect to the position of e.g., a wide receiver, would also include the outcome of a catch attempt.
Pass-receiving athletes are monitored throughout the season of the NFL and NCAA leading to statistics such as the number of receptions, the catch rate or similar statistics [
20]. Some more detailed statistics might be the defense-adjusted yards above replacement or the defense-adjusted value over average metric [
21]. Unfortunately, there are some major problems with the given data. All mentioned statistics about catching are derived from various actions and outcomes during games in a season. By definition, this statistic excludes a major part of each team, including the practice squad in NFL teams or any athlete without game time. Furthermore, athletes with a relatively low amount of minutes during a game do not have enough opportunities to catch a pass. Therefore, no meaningful analysis of their performance can be derived. In leagues that do not have such statistics, due to the lack of someone to gathers and processes the data, no analysis can be accomplished at all. This means that for the majority of athletes in American football no statistic or performance metric exists, which reflects the catching performance.
This major drawback can be resolved by introducing a system that can gather data from exercises during regular training in American football. By gaining data there, the availability of such data increases drastically. For that reason, Hollaus et al. introduced a system that can distinguish between a successful and an unsuccessful catch attempt [
22] that is applicable in regular training. The system was based on IMUs along with a machine learning algorithm, that classifies catch attempts as catch or drop. Several disadvantages go along with the system such as mistriggering, catch attempts might not be recognized as such and the need that all pass receivers must wear two wearables on their wrists that might hinder them in their catching motion. Another possible way to gain information about a catch attempt in training would be based on an IMU in the American football ball. A similar approach is currently taken in sports such as soccer, cricket and recently also American football [
23,
24,
25]. The major drawback there is that it is not very suitable for a regular catch training routine including many athletes, as different balls that contain the IMU would be required. Additionally, it would be necessary to pair every athlete to one ball to guarantee that all catch attempts are performed by the same athlete and enable an individual analysis. By reviewing all potential methods to classify a catch attempt, it became clear that all of the mentioned methods and the given measurement systems have benefits and drawbacks concerning at least one of the following features: accuracy, precision, mobility, robustness, etc. Based on the authors’ experience, a major requirement for any system in sport is that any recording system must not hinder or restrict the athletes in their regular training activities.
Due to this fact, it is investigated whether it is possible to classify audio and video recordings of American football catch training. As the necessary camera and microphone would not be placed on the athletes, these systems do not hinder them in their catch attempt and would represent a major improvement over the original IMU system. In contrast to the approach with an IMU in the ball, a central audio and video recording system would be scalable and independent of the number of athletes participating in the training. Therefore, it is potentially more cost efficient. Additionally, it does not wear out as an American football ball would. Nevertheless, some drawbacks also exist for an audio and video recording system. One of them would be that the information, which can be generated from such a system, only covers the outcome of a catch attempt. It would be much better if the outcome of a catch attempt can be related to a specific catch scenario (e.g., catch a pass over the shoulder during a deep run down the field or catch a quickly thrown screen pass in front of the receivers chest or catch an nearly underthrown pass). If a human quarterback should throw the passes with high precision and accuracy within such a scenario, major limitations to the catch training would be given. The number of passes is limited by the strength of the quarterback, as well as accuracy and precision, which tend to decrease with fatigue. Therefore, a human quarterback is not the ideal solution to the given problem. If the systems should also be able to set a scenario for the catch attempt, it is mandatory to control the pass to the athlete via a passing machine. At the same time, it enables a more detailed analysis of the catch attempt under specific scenarios. For this paper, the recording system should be seen as a part of the passing machine, not as a stand alone system.
As the recording system was integrated into a passing machine, it became necessary to further define, which passing machine should be used. Passing machines have existed in American football for several decades [
26,
27]. In the last few years passing machines became more automized and controllable. A company named Monarc introduced a fully automated passing machine called the Seeker [
28]. All the given systems have no open interface for integrating external hardware. Therefore the passing machine, which was designed by Hollaus et al. [
29,
30], is the only one that enables the development of the catch recognition system, based on audio and video recordings. Still, the passing machine and the recording system only enable a profound analysis of the catching abilities of receiving athletes but an algorithm that analyzes is still missing.
The field of action recognition in sports heavily relies on algorithms based on machine learning [
31]. As the data are manifold in the given circumstance, there is the need of a so-called time series classification algorithm on a signal basis for the audio data, but there is an additional need to process a series of images containing the catch attempt of the respective athlete. In the classification of time series data, Fazle et al. showed excellent results when using a Long Short-Term Memory Fully Convolutional Network (LSTM-FCN) [
32]. Fazle et al. also adopted this concept and could further improve the accuracy of the classification [
33]. Ref. [
34] shows an overview of common methods for classifying time series data. The classification of video or image series data is, due to the high computational complexity, challenging. However, recent research results show very good results in the area of activity recognition [
35]. Tran et al. showed a method for classifying videos using Channel-Separated Convolutional Network (CSN). Very good results in activity recognition are shown by Donahue et al. A Long-Term Reccurent Convolutional Network (LRCN) is used as the model architecture [
36]. In the field of sports, machine learning has been used to classify sports [
37]. There are also studies on human activity recognition, gait analysis or human pose estimation [
38,
39,
40,
41,
42,
43]. In human pose estimation, the classification is performed mainly using data from image capture [
44]. Based on the literature and state of the art in close fields, it can be imagined that it is possible to analyze catch attempts in an automized way by applying the mentioned methods on audio and video data of automated catch training.
Therefore, the main goal of this paper is to provide a system and an algorithm that allows the automated analysis of a catch attempt in American football based on audio and video data. The analysis should identify a catch or a drop with reasonable accuracy. Based on [
22] the accuracy should be at least close to or better than 93%.
2. Material and Methods
In this section the used methods are given in chronological order. First, the audiovisual recording device and its integration into the given passing machine is outlined. The data acquisition phase is shown secondly. Next, the preprocessing algorithms, including labeling, are explained in detail. This section closes with the development of neural networks for audio and video classification.
2.1. Audiovisual Recording System
To train the neural networks, a recording system is needed for data acquisition. This system should independently record and store an audio and video sequence of an athlete during a catch attempt via an external trigger. The recording system is integrated into the passing machine [
29,
30], which triggers the start of the recording. A camera and a microphone with a directional pattern are mounted on the ball-throwing machine. After triggering, an audio sequence and an independent video sequence are recorded. An overview of the recording system is shown in the system topology in
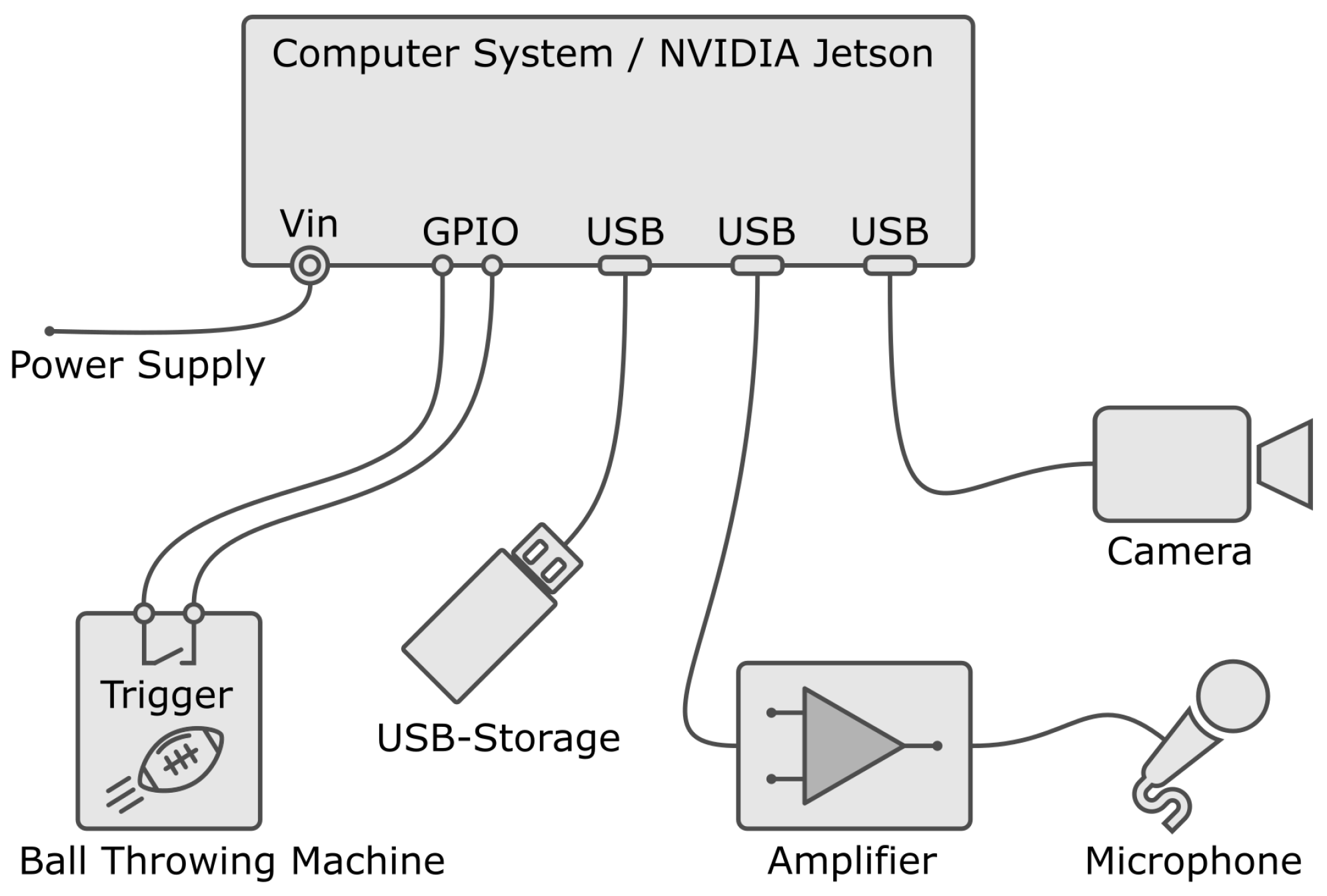
Figure 1. The central point of the system is the computer system. The camera, the microphone with the amplifier, the external USB memory storage and the trigger contact of the passing machine are connected to it.
For the video recording, it was necessary to choose a camera that fits the requirements of the experiment. The requirements were defined as follows. The receiving athlete may attempt to catch the pass in a distance between 10
to 50
away from the passing machine. For the whole range, it is necessary to record the entire body of the athlete during catching. As various scenarios for the catch attempts are considered, including a catch attempt while running or jumping, it is necessary to have at least a field of view of 4
. This requirement can be met with an opening angle of 22.7° and a sensor size of at least
. Therefore the optics were chosen according to given need with the lens Edmund Optics 16 mm f/2.8 Ci-Series. From a camera perspective, it was important to determine the minimum frame rate, recording time and resolution. As the catch attempt starts when the pass is thrown and ends when the pass is successfully caught or not, the recording time was considered to be several seconds. Within the recorded seconds, the information about the outcome of a catch attempt should be easily visible within the recorded frames. Considering a frame rate of 1 fps and a recording time of 5 s, five recorded frames would be the outcome, with images before and after the potential catch happened. The authors assumed that a classification is possible based on a few frames that show the catching motion before and after the respective catch happens. Nevertheless, a camera was chosen that can record a frame rate of 60 fps, to have a better coverage and be able to find the minimum frame rate based on an experimental approach, not on an assumption. The camera was configured with a resolution of 640 × 512 pixels, since machine learning algorithms that use images as an input often only need even lower resolutions than 640 × 512 pixels [
45].
A microphone should be used to record the characteristic catching sounds of the football. Since the sounds should also be recorded up to a distance of 50 , a microphone with directional characteristic needs to be chosen. This is also beneficial for the damping of any external noise that comes from other sound sources in the surroundings. Most of the directional microphones need so-called phantom power along with an amplifier to have a well established recording quality. Based on the given requirements, many possible microphone setups would be the outcome. The authors chose Rode NTG-2, but also state that many other setups would be possible. Since the microphone requires external 48 phantom power, the recommended audio amplifier Steinberg UR22mk2 is used. The operation was performed via a USB 2.0 interface. The audio signal was recorded with a sampling rate of 48 , which is sufficient for the needs of the experiment.
A central computer system is used to record the audio and video sequence. In the scientific community, different central computer systems are accepted, especially within image processing [
46]. The system which was chosen for the experiment is a powerful System-on-Module (SOM) from
NVIDIA called
NVIDIA JETSON. It features a dedicated
NVIDIA Maxwell graphics processor with 128 cores, a
quad-core ARM A57 processor and 4 GB
LPDDR4 RAM. The power supply is provided by a 5
/ 4
plug-in power supply. The operating system is loaded onto an SD card. To reduce the write access to the SD card, the audio and video sequences are stored on an external data carrier (USB3.0/ 128 GB) as can be seen as USB storage in
Figure 1. A metal case was used to protect the system from damage. The general purpose input/output (GPIO) to trigger recording is routed to a housing connector.
2.2. Experimental Setup and Data Acquisition
The data that are necessary to train the networks were gathered in an experiment. The experimental setup always consisted of a passing machine [
30] which also carried the recording system. The recording system was connected to rotate horizontally according to the azimuth of the launch unit of the passing machine. Therefore, the orientation of the microphone and camera is always the same as the horizontal orientation of the launch unit of the passing machine. The passing machine was instructed to run a pass routine by pressing a button on the machine. The pass routine starts with a short acoustic warning signal. This warns the receiving athletes so they are aware that a pass will be released just after the warning signal ends. This also triggers the audio and video recording so the catch attempt is covered from pass release to a few seconds after the end of a catch attempt was made. The recordings were then stored on the external USB-Storage according to
Figure 1.
All participants were only instructed to attempt to catch the pass and try various catch motions (e.g., faced toward the machine, while running, over-the-shoulder catches, or similar). There were no further instructions for the catching process. The experiment was designed to have as much variability as reasonably possible. Therefore, the experiment was carried out with a total of thirteen different athletes. All the players were amateurs. Most players have never caught an American football ball before and are not entrusted with catching techniques. In this data, it is important to note that four of the thirteen players with percentages of 67.57% are included in the dataset.
The experimental design was approved by the ethics committee of the MCI and all participants have signed a declaration of consent. To enhance variability within the dataset, the data recording was performed at two different locations, the auditorium at MCI and a parking lot. The recordings at the MCI auditorium site were made indoors in the building and recordings at the parking lot were made outdoors. At each location, passes are taken with different background types. This should lead to a higher robustness of the neural network with respect to a change in the environmental parameters. A total of five different background types were chosen. In the outdoor area, the background types shrubbery, shrubbery & wall and building are included in the dataset. In the indoor environment, two background types are recorded, glass doors and a light background. The recorded dataset, in a volume of 2276 passes, forms the basis for training the neural networks.
2.3. Labeling and Data Processing
The labeling of the data is indispensable for the training of neural networks. Therefore, the labeling of the individual data is performed by the file name and consists of several parts. The name of the recording system, information about key frames of the video, the class and subclass, the recording location and the player are stored. Audio and video recordings are stored separately. To still be able to assign the data to each other, they are labeled exactly the same—except for the file extension. In addition to the two main classes Catch and Drop, subclasses are also formed. These subclasses contain the movement pattern of the athlete during the catch the pass. The subclasses Jump, One-handed, Run and Stand are formed. The catch types are not used for training the neural networks. However, the subclasses can be used to analyze the dataset and for more future work. An important metric for training is the ratio of caught passes (class: Catch) and uncaught passes (class: Drop). This ratio can be seen in
Table 1.
The Drop class has a significantly smaller share of the total amount of data with 669 recorded passes. When training the neural network, this can lead to the fact that data belonging to the class Drop are not classified with the same high accuracy as data of the class Catch [
47].
Before the data ar fed to the neural network, it was processed in three steps. First, the data were preprocessed, then duplicated, and finally stored in a specific file format.
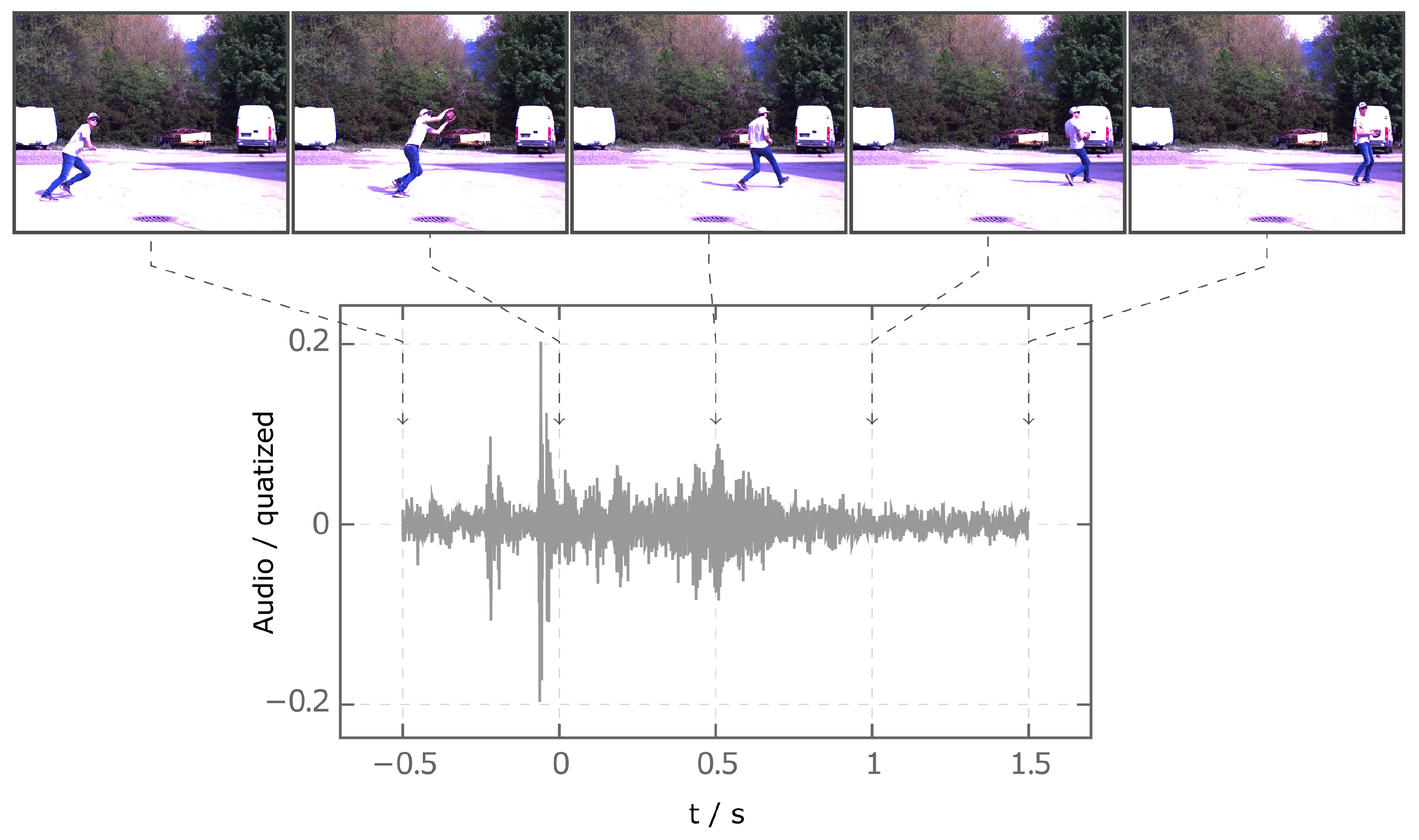
When the video data were processed, the individual recordings are converted into a four-dimensional matrix of the form . To train the neural network with different datasets, the videos are scaled differently and their frame counts are varied. The OpenCV scaling function is used to scale down the video. The frames are reduced to four different sizes , , and pixels. In addition to reducing the size of the frames, the number of frames in the video is reduced. The reduction is performed using the number of the key frame at which the player touches the ball. Based on this time point, only frames that are before and after this time point are further used. Thus, the time range is 2 . Three time intervals , , and are defined between frames. The resulting videos have frame counts of 5, 12, and 21. After data reduction, the videos are normalized to the range of values . The audio data, similar to the video data, are trimmed, interpolated and stored as a matrix. The audio data, like the video data, are trimmed to a period of 2 . before and after the player touches the ball are used for the sequence. The data are reduced to a size of 50,000 × 1 via interpolation. Analogous to the video data, the audio data are also normalized. The normalization is performed to the range of values .
Figure 2 shows the normalized audio and video data of class Catch. Here, the video has the format
. The audio and video data are time-synchronized. For every trimmed sequence, the recorded time is given a unique offset such that the time is 0
when the athlete first touches the ball.
To increase the accuracy and robustness of the neural network, the data are multiplied. Too little data can cause the neural network to generalize poorly and thus produce poor results on unknown data [
48]. Duplication of the data is applied to the video data and to the audio data [
48]. The video data are duplicated using four different methods [
49]. The horizontal mirroring and cropping of the image, the addition of noise, and histogram equalization. Duplicating the audio data is also performed with four methods. Two methods, adding noise and adjusting gain, change the amplitude of the signal. Two other methods make changes to the time course of the signal. Shifting and stretching or compressing the audio signal. Especially when augmenting input data, overfitting of the network must be cautiously avoided. Therefore, all network performances are judged using test data as shown in the Results and Discussion section. Since the processing of the data takes a lot of time and the dataset cannot be completely loaded into the working memory, it must be cached on the hard disk and loaded sequentially for the training of the neural network. The
Tensorflow proprietary
TFRecord format is used to store the data. This simple binary format is used for storing large datasets and is optimized for
Tensorflow [
50]. In the initial development phase tensorflow version 2.2.0 was used. In addition to conversion, data are split before saving. Splitting is performed into a partial dataset for training (64.9%), validation (12.2%), testing (22.9%). The splitting of the dataset is achieved with the function
StratifiedShuffleSplit, of the
scikit-learn library. This function has the advantage that the splitting of the classes is evenly distributed in all splits.
2.4. Development of Neural Networks
The recordings contained in the dataset, consisting of audio and video data, are used to train neural network models. These models are designed to perform binary classification. The audio recordings consist of univariate time series data. The video data, on the other hand, is composed of images in a specific time sequence. Several models are implemented for classification due to the different data types. The optimization of the model structure and hyper-parameters of all models is performed empirically. The optimization process is performed in two stages. The optimization of the models is achieved using only the training dataset of the raw data. No data duplication is used to reduce the computation time. In the first stage the model structure is optimized and with the next stage a fine optimization of the hyper-parameters was performed.
2.4.1. Classification Based on Audio Data
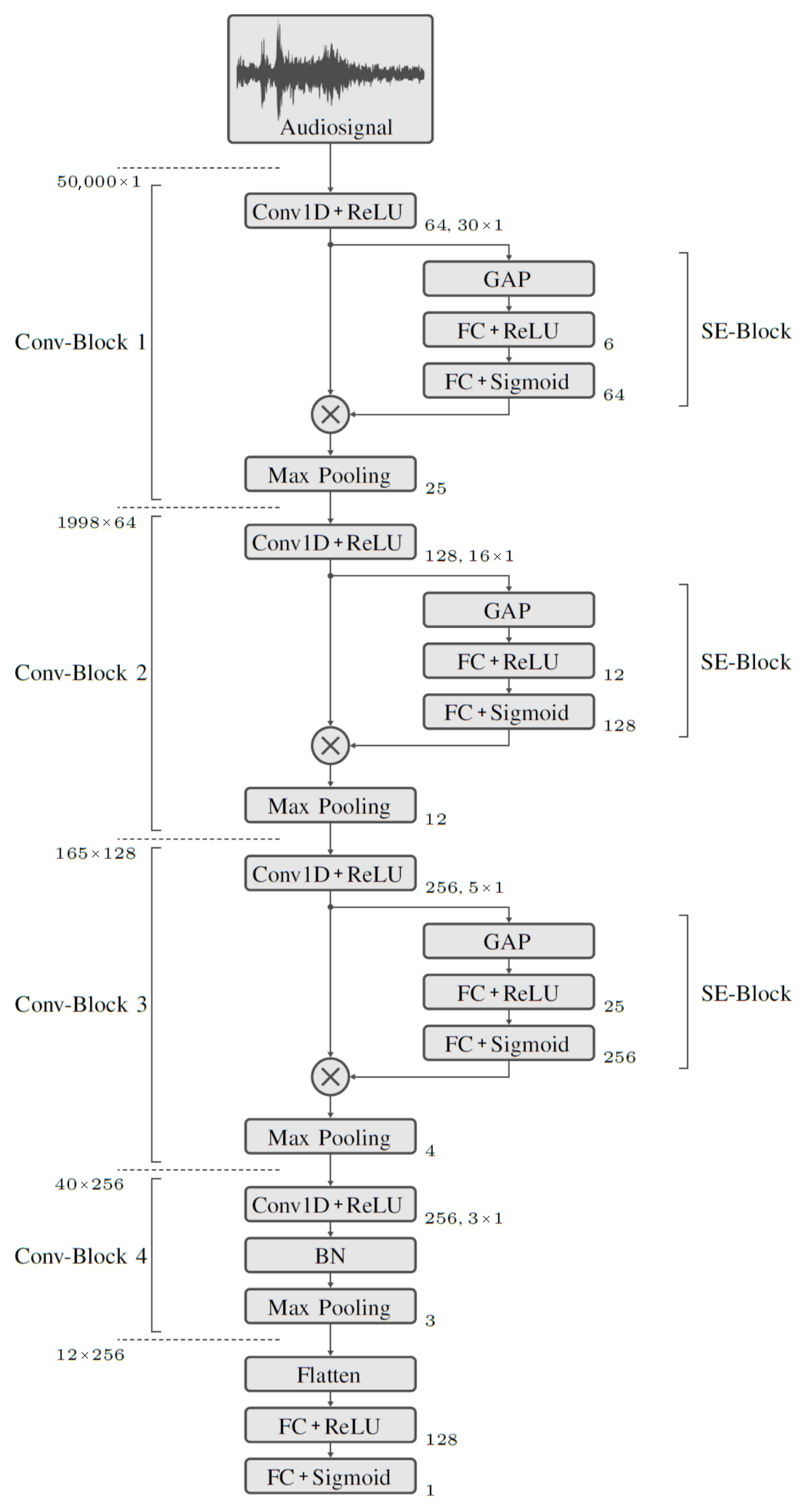
The classification whether a record belongs to the class Drop or to the class Catch is performed with a first model purely based on the audio recordings. For classification, a model architecture with several Convolutional layers connected in series and a fully meshed output layer is used. An overview of the network structure of this model is shown in
Figure 3. The input to the model is the audio signal in the form of a one-dimensional tensor with 50,000 elements. This is followed by four convolutional blocks,
Conv-Block 1 through
Conv-Block 4. These are used to extract signal features. The final classification is performed using Fully Connected (FC) layers. The special feature of
Conv-Block 1 to
Conv-Block 3 is the downstream Squeeze and Excitation (SE) block. Ref. [
51] demonstrates that SE blocks provide significant performance improvements with little additional computational overhead. The model is trained with the training dataset. Since the classification is binary, the
Binary Crossentropy loss function is chosen. As an optimization function, for updating the weights during training, Adam [
52] is used. The batch size is set to 5. During training, the learning rate is adjusted after each epoch. The best results are obtained with an initially higher learning rate of 1 × 10
−5, which decreases linearly over 20 epochs to 8 × 10
−6. This is kept stable over 40 epochs and then exponentially reduced to 2 × 10
−6.
2.4.2. Classification Based on Video Data
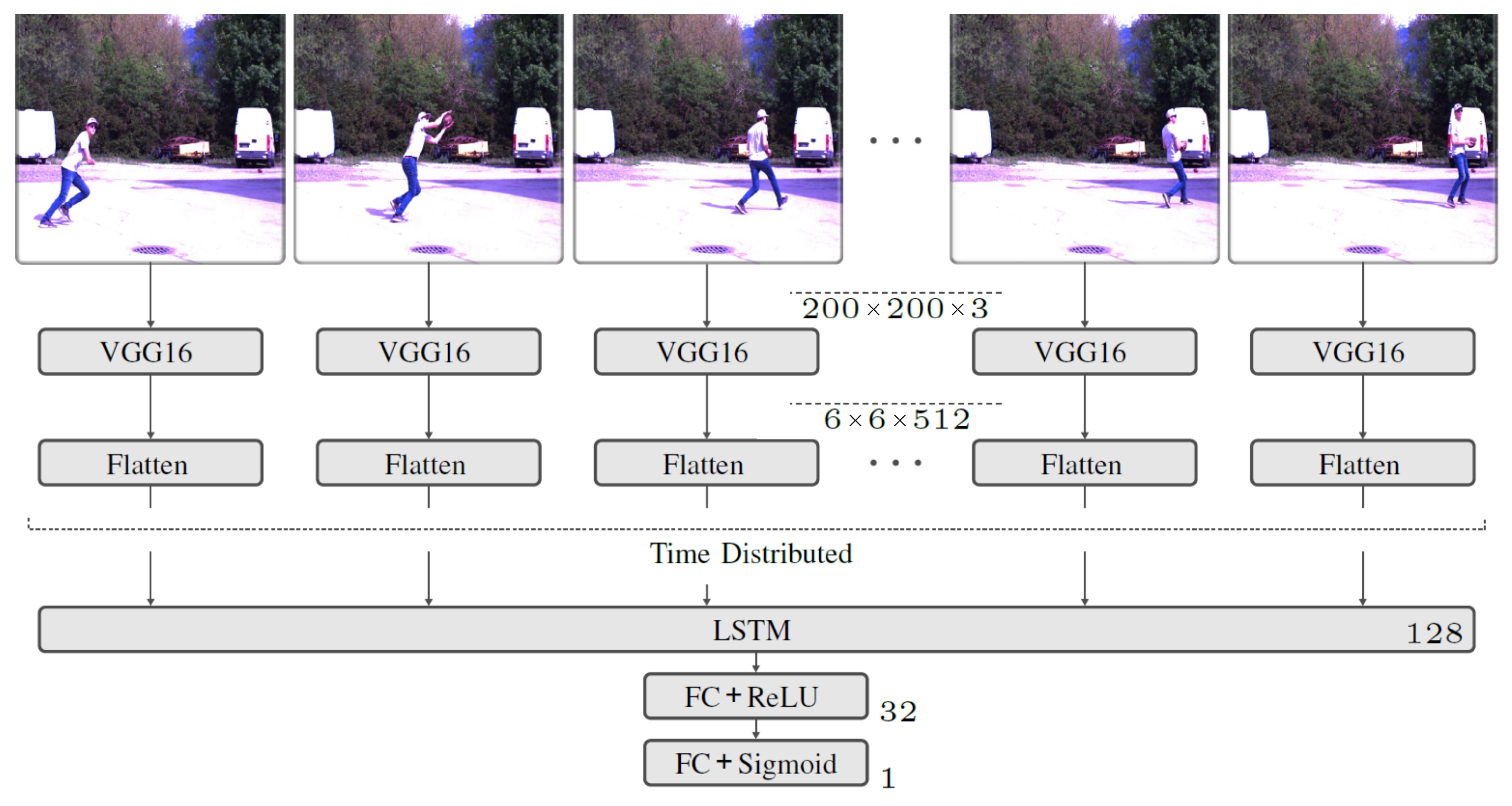
A CNN is used to extract the features contained in the individual images. However, since training a CNN to classify image data requires a very large dataset to achieve high accuracy, pre-trained network is used for feature extraction. Specifically, the VGG16 [
45] Network is embedded. This is a very compact mesh with relatively few parameters. The network was developed to classify images and has been used with 1.28 × 10
6 Images trained on 1000 classes. It gives very good results on the
ImageNet dataset. Since a video consists of multiple frames, feature extraction is applied to all frames separately using
TimeDistributed function. The output of the feature extraction has an additional dimension that describes the temporal flow of the extracted features. An LSTM is used to account for temporal dependencies between the extracted features. The network structure of the implemented model is shown in
Figure 4.
The model input is a tensor of the form . An image dimension of is chosen because the VGG16 network was developed with images of dimension and is optimized for this purpose. Finally, the feature extraction contains a flatten operation to suitably restructure the tensor for use with the LSTM. To learn the temporal dependencies between the extracted features, an LSTM with 128 cells is used. The final block, which also contains the final output layer for classification, is formed by FC layers, similar to the audio model. The training dataset is used to train the model. Since the classification is binary, Binary Crossentropy is chosen as the loss function. Adam is used as the optimization function. A batch size of 6 is used. During training, the learning rate is adapted after each epoch. The best results are obtained with an initial learning rate of 2 × 10−5. This is exponentially reduced from epoch 2 to 8 × 10−6.
2.4.3. Classification Based on Audio and Video Data
The pre-trained models for audio and video classification were integrated and linked into a third model. This should lead to higher accuracy in the classification of the data, since the entire dataset with the audio and video source is used for the prediction. The network structure shown in
Figure 5 provides an overview of the model. The video data are processed using a model branch with the video classification model already trained. The input tensor of the video data has the same size as the input tensor of the video classification model.
The second network’s input is the audio data. The input processing is performed with the already trained network of audio classification. The input tensor of the audio data has the same dimension and size as the input tensor of the audio model. The last layers, which are used for classification, are removed in both models. Instead, a fully connected (FC) layer with a Rectified Linear Unit (ReLU) activation function is used. The two model branches for processing the audio and video data are linked using the Concatenate function. Two FC layers follow. The output layer for binary classification is an FC layer with a sigmoid activation function. The training of the model is performed with the audio and video training datasets. Binary Crossentropy is chosen as the loss function since the classification is binary. A batch size of 3 is used. During training, the learning rate is adjusted after an epoch change. The highest accuracy on the test dataset is obtained with an initial learning rate of 1 × 10−5. The learning rate is exponentially reduced to 5 × 10−6 from epoch 2.
4. Discussion
The results showed that, when using only the audio network it is not possible to classify the data reliably. This model cannot be used as an independent system due to low accuracy in the classification. The information content of the recorded audio data was too low to achieve a higher accuracy. Analyses of the dataset show that in some cases no audio signal of the ball hitting the player is recorded. This happens when the player is too far away from the microphone or when too much ambient noise overlays the recording. Recordings in a sports hall would show an improvement. The ambient noise can be minimized and the quality of the audio recording can be increased.
The evaluation of the video network shows that classification of video data is possible. The class Catch can be determined very well. The hit rate for the class Drop is still not sufficient for a reliable classification of the data with 79%. However, it is important to keep in mind that the size of the dataset is very small. With a larger dataset, higher accuracy may be achieved. An increase in accuracy when using a larger dataset can already be observed when optimizing the model.
The combined use of the audio and video network shows a strong improvement in the classification of catch attempts. In comparison with the IMU approach in [
22] the performance is close. An overall accuracy on the test dataset of 92.19% is not yet sufficient for the use of the model in a fully automatic training system. However, this result demonstrates the feasibility of such a system.
There are also limitations of the system regarding its performance outside the given scenarios of the experiment. In the experiment, only amateurs participated in two different locations. This means, that other backgrounds, other athletes wearing other sportswear that have other individual catching skills, might lead to worse accuracy. This issue can only be solved by creating more versatile data in many different places with many different athletes that have a wide range of catching skill level. Nevertheless, the initial goal was to show that catch recognition can be achieved in American football using machine learning based on audio and video data. This goal was achieved.
Another major limitation was the number of athletes within the area of sight of the camera. In a training scenario, the background might not be as static as it was in the given scenarios during the experiment. On a pitch, there might be more dynamic backgrounds, which could lead to a worse performance. As no dynamic backgrounds were part of the dataset, the network did not learn how to deal with them properly. As already mentioned, the amount of data and the versatility of it is a major limitation of the given system. Though, within the given constraints of the dataset the outcome is acceptable.
5. Conclusions
As part of the paper, an audiovisual recording system was developed. This offers the possibility to record a football athlete during catch training. Together with an automatic ball-throwing machine, a comprehensive dataset was created. The dataset consists of audio and video recordings with a dataset of 2276 recorded catch attempts. This was preprocessed and duplicated by applying different augmentation methods. Three neural networks were developed and optimized to classify the data. An evaluation of the three models showed that the classification of the data was possible. From the individual model tests, it was found that the audio model achieved the worst result in the classification. The model for classifying the video data achieved good accuracy. The best performance was achieved with a combination of the audio and video network. It was shown that the classification of audio and video data is possible. The achieved accuracies of classification of 92.19% confirm this study. Through the research accomplished in this work, a system for automatic training of athletes can be developed. With such a system, it is especially possible to gain new knowledge in the field of training athletes and developing training methods with fully automatic systems. In comparison to the IMU-based system, the performance of the combined network is slightly worse. Nevertheless, the major advantage of the combined audio video approach is that there is no need to put wearables on the athlete. Therefore, the training routine of receivers does not change, which most likely would result in better acceptance of the system by coaches and athletes.
According to the authors, further research should focus on identifying the subclasses of the catch motion, such as Jump, One-handed, etc. Another question that remains unanswered is whether the improvement in audio quality allows for reliable audio-only classification. Likewise, the classification using only video data could have interesting applications in broadcast recordings of sports matches.
Another area that was not researched yet is the automated training and the development of a performance index according to the data, recorded during automated training. It can be imagined that an automated passing machine, that throws a pass accurately, can throw passes athletes in a randomized way (e.g., 100 passes in total within the area of reach of an athlete, 25 passes in each quadrant from seen from the athletes chest). Based on the information if the athlete caught a pass or not, a performance index could be derived, according to the quadrants. This approach could be extended to any other catching scenario in American football catch training as the information is surely useful for coaches, scouting, athletes, fans, etc.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}