5.1. Dataset and Evaluation Approach
Following the methodology introduced in
Section 4.2, the dataset is generated as a foundation for the evaluations performed in the following. In total, the data of nine tools are acquired over their lifetime.
Figure 6 shows the measured wear curves of the tools. In addition, the average material removal rate
according to Equation (
5) is shown per tool. A discrete number
of cutting time steps
represents the tool life. The total removed material volume per time step is denoted as
.
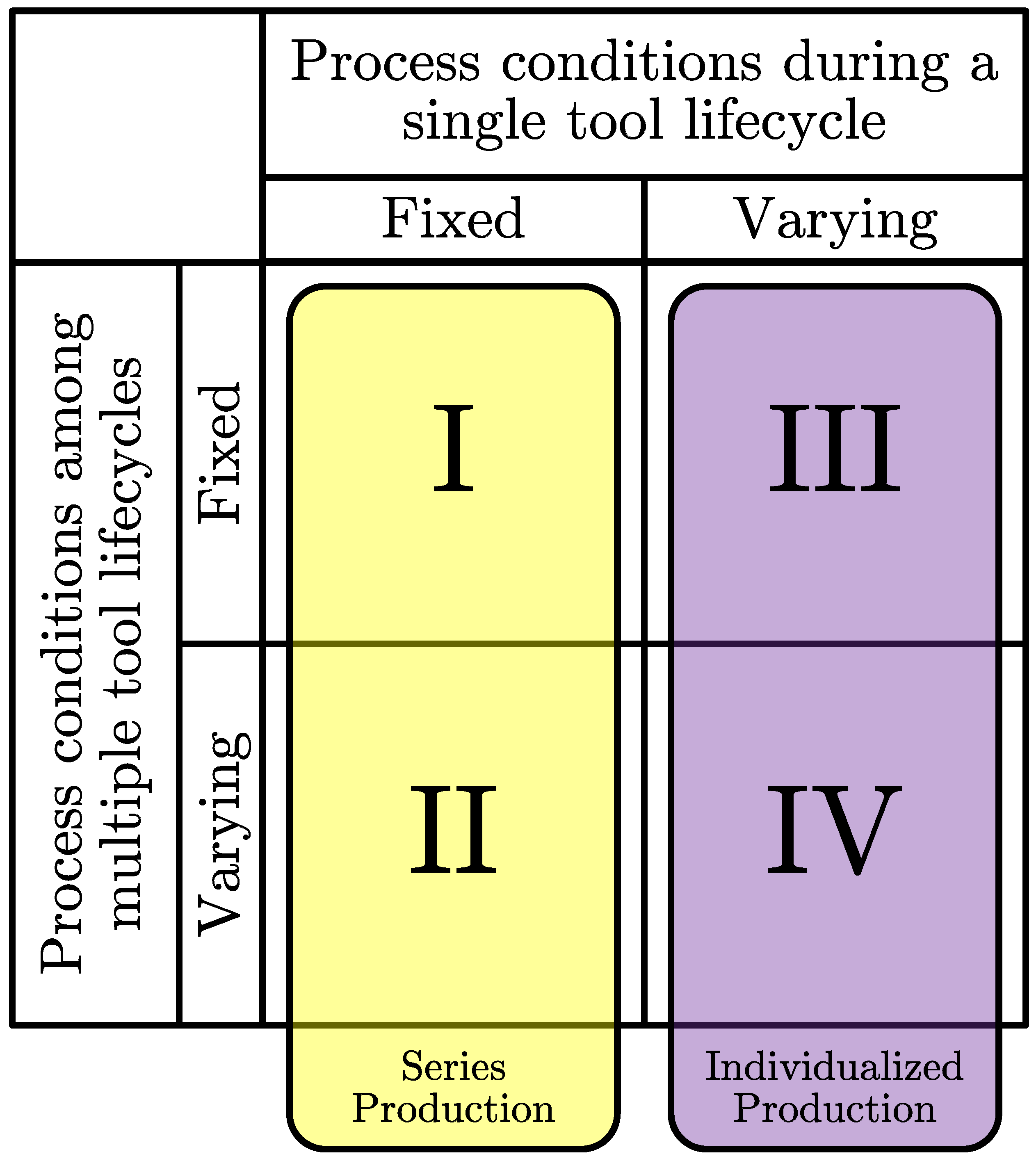
Tools 1 to 7 manufacture variable pocket geometries with variable cutting parameters. This results in material removal rates between 18.9 and 23.4 . Furthermore, the data during the lifetimes of two reference tools are acquired. Reference tool 1 manufactures variable pocket geometries under fixed cutting parameters. The cutting parameters are set to the maximum values of the intervals specified for tools 1 to 7. The maximized cutting parameters lead to an increase in to 34.2 since the machining time of the pockets decreases. Thus, higher productivity is achieved. Reference tool 2 is applied in pure face milling based on the zig-zag strategy with fixed, maximum cutting parameters. Since only face milling is performed, the workpiece geometry can also be considered fixed. In this case, the maximum material removal rate of 47.1 is achieved as no pocket milling is performed. The data from the reference tools are used to evaluate the generalization performance of the prediction models. For reference tools 1 and 2, the wear progress increases due to the increased productivity, while this is not the case for tools 1 to 7. An explanation for this is the influence of the varying workpiece geometries and, thus, loads on the tool cutting edges. Not only do the cutting parameters and the resulting machining speed affect the wear progress, but the combination with the workpiece geometry must always be considered.
To achieve an optimal test coverage of the prediction models with a limited number of available tools and ensure their robustness, the validation and test strategy shown in
Figure 7 based on the leave-one-group-out methodology is used. The strategy is denoted as leave-one-tool-out cross-validation and testing (LOTO-CVT).
The data from N tools are divided into training and test sets to generate the regression and forecasting models. The data of a particular test tool are excluded from model training. Each tool is used once for testing to ensure that the prediction methodology is functional for arbitrary permutations and that its performance is not just based on the random selection of individual test tools. The model architecture and hyperparameter search are then performed based on the training set containing the data of tools. Model architecture and hyperparameter configurations are sampled from a model pool. When searching for the best configuration, a search criterion is required, enabling the evaluation of the configurations and their optimization. As with training, the prediction error can be used for this purpose. However, an additional validation tool has to be kept out of the training set. The evaluation of a model using the data of the validation tool guides the search.
It is problematic that selecting a single random validation tool can overfit the models, thus misleading the architecture and hyperparameter search. Hence, each tool is used once for validation to generate a model robust to the test tool data. The resulting models of the validation folds are combined into a voting ensemble. The outputs of the models are averaged to compensate for overfitted models. After the model architecture and hyperparameter search is complete, the voting ensemble models are trained using the data from all training tools. Subsequently, the evaluation is performed based on the data of the test tool. The stochastic nature of the parameter initialization and optimization of machine learning models may lead to different model outputs for multiple training runs. Training and testing are repeated n times to enable reliable model quality assessment.
5.2. Prediction Model Evaluation
The ability of the model approach introduced in
Section 3.2 to predict tool wear and remaining tool life under variable process conditions is investigated using tools 1 to 7 in the following. First, the regression component and then the overall model extended by the forecasting component are investigated. The regression component quantifies the tool condition based on a tool wear prediction up to the current time point
. Previous approaches rely primarily on instantaneous features derived from sensor data as an input to tool wear prediction models. The reason for this is the fixed process conditions during a tool life cycle assumed in previous work, resulting in comparable cutting processes and a direct correlation with gradual tool wear. A common approach based on vibration data, as in [
30] or [
34], is to perform spectral analysis of the cutting operations, with frequency bins of power or amplitude spectra representing the features. Our methodology also incorporates spectral analysis in the form of the power spectral density. However, it goes beyond that by using the cumulative features, workpiece and cutting parameters as model inputs.
We evaluate the explainable state-of-the-art approach given in [
30] based on our dataset described in
Section 5.1 and the LOTO-CVT strategy. In [
30], the wear prediction is a classification problem based on a random forest model, which receives the frequency spectra from structure-borne sound signals acquired during cutting operations as input. The approach is transferable to our regression component since random forest models can also be used for regression problems. First, only the power spectra of the accelerometer signals are used as input to the regression model. Before the evaluation is performed using tools 1 to 7, the correlation of the power spectra with tool wear is ensured under fixed process conditions using the data from reference tool 2. We then compare the results based on the methodology described in [
30] with the wear predictions of our AutoML-based regression model using the extended feature set proposed in this paper.
For the regression model training, the Auto-sklearn environment is configured. Both the meta-learning and ensembling capabilities of Auto-sklearn are enabled. The maximum time budgets are set to 10 min for the entire CASH optimization and 30 s for training a single pipeline configuration with a memory limit of 20 GB per pipeline. The R2 score function is used as a metric for training. The training and testing steps are repeated five times according to the LOTO-CVT strategy. Since the regression is only required up to the end-of-life criterion
, the range for prediction and evaluation is limited to 0.8 mm.
Figure 8 shows the comparison of the regression results. For a comprehensive error analysis, the prediction errors in terms of root-mean-square error (RMSE) and mean absolute error (MAE) over the dataset are summarized in
Table 2.
Figure 8 and
Table 2 show that the state-of-the-art method for tool wear prediction described in [
30], which is purely based on the instantaneous spectral features, is not easily transferable to the case of variable process conditions during the tool life cycle. Estimating the wear measurement curve is only partially possible to a limited extent, as seen in
Figure 8a, e.g., for tools 2 and 4. In comparison, the predictions based on our method with the extended feature set achieve a reduction in the RMSE of between 43.4 and 80.2% and in the MAE of between 54.8 and 78.8%. As seen in
Figure 8b, the prediction is possible for all tools and is mainly within the measured wear value intervals of the tool cutting edges. For tool 3 only, the prediction lies outside the wear value interval starting from a cutting time of 40 min. An explanation for this could be that tool 3 has the highest material removal rate of tools 1 to 7. Thus, the wear curve represents an extreme case of the dataset and the regression model has to perform an extrapolation during inference, which is much more error-prone than an interpolation. Overall, the better performance of our method compared to purely spectral feature-based prediction can be explained by the additional features. Under variable process conditions, their influence on the signals dominates, reducing the correlation between the instantaneous features and the tool wear. Particularly, the new cumulative features allow our method to restore the comparability of the cutting operations. The feature importance is investigated in
Section 5.3 to confirm this hypothesis using Algorithm 1.
In advance, the evaluation of the remaining tool life prediction based on the previously trained regression component is performed. The goal is to analyze how the extension of the remaining tool life prediction model compared to the state-of-the-art method through the possibility of entering future feature estimates affects the predictions. For this purpose, the LSTM-based forecasting component, according to
Section 4.3, is trained and tested using the data from tools 1 to 7. Based on the LSTM output, the remaining tool life is calculated using Equation (
1). The forecasting component is first tuned and trained based on the LOTO-CVT strategy. The LSTM model has a single layer and a hidden dimension of 25. The length of the model input sequences between 12 and 60 samples and the output sequences between 1 and 36 samples is subject to the model tuning. Furthermore, the hyperparameters of the batch size in the range of
and learning rate in the range of
are tuned, guided by the MAE. An LSTM instance can train for a maximum of 30 epochs while early stopping is employed. In total, the training and testing of the models are repeated five times. In the testing phase, the outputs of the regression component shown in
Figure 8b are input to the LSTM. Additionally, an exploration of non-spectral feature combinations as future feature inputs is performed.
Figure 9 and
Table 3 show the remaining tool life prediction results for the LSTM without future features and the best-performing LSTM with future features.
The remaining tool life prediction without future features has an average RMSE of 9.5 min and an MAE of 7.8 min. With future features, the RMSE is reduced by 32% to 6.5 min and the MAE by 22% to 6.1 min. The results are achieved using the total cutting time
as a single future feature input. In
Figure 9, the difference in prediction accuracy between the two model instances becomes evident. Without future features, the prediction is primarily inaccurate in the early stages of tool life, as shown in
Figure 9a. Including the future features allows for a mostly accurate estimation of the remaining tool life at arbitrary time points. Only the predictions for tools 3, 4 and 5 in
Figure 9b are characterized by a constant offset error. However, for tools 4 and 5, the predictions converge toward the real remaining time in the last 10 min of their respective lifetime. For tool 3 only, the offset remains constant until the end of its life. In this case, the offset is because the wear regression lies outside the measured wear values, as already described in the context of
Figure 8b. Therefore, the regression error is propagated to the forecast and prevents the correct estimation of the future course of the wear curve. For tool 2, the maximum optimization of the prediction is achieved by an error reduction of 79% in RMSE and 78% in MAE. In addition, the dispersion of the predicted values over the entire tool life represented by the 5th-to-95th percentile range can be reduced using future features. The decreased dispersion indicates a reduction in the model uncertainty regarding the future. Overall, it can be confirmed that the remaining tool life prediction is possible under variable process conditions. In addition, an increase in accuracy and higher robustness of the prediction can be achieved by including process-describing information about future machining operations.
5.3. Feature Importance Analysis
Based on the evaluation of the remaining tool life prediction method in the previous section, the feature importance analysis is performed in the following. The aim is to demonstrate and evaluate the feature importance ranking method according to Algorithm 1. Furthermore, it should be investigated why state-of-the-art prediction methods for fixed process conditions based on instantaneous features, such as [
30], are not directly applicable to variable process conditions. Therefore,
Figure 10 shows the feature importance scores derived according to Algorithm 1 for all input features of the regression model whose predictions are depicted in
Figure 8b. The feature importance scores are averaged over the complete dataset, i.e., over all tools, and split by spectral and non-spectral features. The mean feature importance scores and the standard deviations are displayed.
The maximum feature importance scores of the cumulative features with mean values of 0.8, 0.7 and 0.3 for the total cutting time
, the total removed volume
V and the material removal rate
Q, respectively, indicate that they contribute more to the model decisions than the parameters or instantaneous features. The low weighting of the instantaneous spectral features supports the hypothesis that the correlation between the values of the spectra per frequency bin and the target, i.e., the tool wear, decreases due to the influence of the variable process conditions on the sensor signals. Due to their higher level of abstraction and inherent memory capability, cumulative features can maintain correlation with the target despite variable process conditions. The memory capability also distinguishes them significantly from the parameter features, which have low feature importance scores, similar to those of the instantaneous features. A detailed influence analysis of the separate feature subsets and individual high-importance features on the tool wear prediction performance can be found in
Appendix D.
It has to be noted that the methods for tool wear prediction studied in this paper, i.e., the state-of-the-art method from [
30] and our AutoML-based approach, rely purely on classical ML models. However, the influences of variable process parameters may be filtered out from the spectra using deep learning models, such as CNN-LSTMs, which are particularly good at representing spatio-temporal relationships. Thus, the correlation with the target could also be recovered for variable process parameters. Furthermore, the dataset used in this paper represents gradual tool wear. Abrupt tool wear, e.g., the breakage of the cutting edges due to excessive cutting forces caused by critical engagement conditions, is not included. Although the manufacturing of pocket geometries causes a variation in the engagement conditions, their influence on the sensor signals is only moderate. The influence increases for critical engagement conditions. Thus, the instantaneous features gain importance again for detecting abrupt tool wear. Moreover, the instantaneous features provide a simple wear indicator at fixed process conditions. Overall, despite their low feature importance for the dataset used in this paper, the instantaneous features are a necessary component of tool wear and tool life prediction models.
5.4. Generalization Performance
In the final evaluation step, the remaining tool life prediction method proposed in this paper is investigated in terms of its generalization performance. The aim is to evaluate whether a prediction of tool wear and remaining tool life is possible with increased productivity of the machining process by reducing the machining time without explicit training. Productivity is determined by the material removal rate derived from the cutting parameters feed per tooth and cutting speed defining the feed rate and the axial depth of cut . Increasing the cutting parameters introduces uncertainty regarding the changing tool wear development and its impact on the workpiece quality. If the approach proposed in this paper allows transferability to increased yet unknown cutting parameter configurations, process reliability can be ensured nonetheless.
The evaluation is performed using two reference tools, reference tools 1 and 2. The data from reference tool 1 represents the test set. It is based on pocket manufacturing at fixed, maximum cutting parameters, resulting in an increase in the material removal rate and thus productivity of between 32 and 45% compared to tools 1 to 7. Two training set scenarios are distinguished to study the transferability to the variable pocket manufacturing with increased productivity:
Tools 1–7 and reference tool 2: Knowledge of the target wear curve for variable pocket manufacturing using variable cutting parameters and of the wear curve for face milling using fixed, maximum cutting parameters.
Tools 1–7: Knowledge of the target wear curve for variable pocket manufacturing using variable cutting parameters only.
The regression and forecasting components are trained with both training sets.
Figure 11 and
Table 4 show the tool wear prediction results of the regression component.
Based on training set 1, the prediction results lie mostly within the wear measurement intervals, leading to an RMSE of 0.054 mm and an MAE of 0.041 mm. In the case of training set 2, excluding reference tool 2, the same behavior as for tool 3 in
Figure 8b is obtained. Reference tool 1 represents the tool life cycle with the maximum material removal rate and the fastest wear progress. This leads to a significant underestimation of the wear curve with an RMSE of 0.108 mm and an MAE of 0.078 mm. The result supports the hypothesis that the regression component of our approach is not able to extrapolate the wear curve. With additional knowledge of the wear curve for face milling (training set 1) with a material removal rate of 47.1
exhibiting faster wear progress than reference tool 1, the regression model performs an interpolation, leading to a feasible prediction. Furthermore, the investigation can also verify the high feature importance scores of the three cumulative features
,
V and
Q noted in
Section 5.3. The material removal rate and thus the two parameters
and
V define the wear progress in the considered scenario of gradual tool wear and are thus crucial for the regression. Overall, the transferability of the regression component to pocket milling at increased productivity is given, provided that the task represents an interpolation.
For evaluating the forecasting component, the output of the regression model based on training set 1 is used as the LSTM input in the testing phase. Furthermore, an exploration of non-spectral feature combinations as future feature inputs is performed, as in
Section 5.2. The results of the remaining tool life prediction for reference tool 2 are shown in
Figure 12 and
Table 5.
Figure 12 shows that, based on training set 2, the prediction is feasible with an RMSE of 4.9 min and an MAE of 3.5 min. In contrast to the regression component, which provides a feasible prediction based on training set 1, the forecasting component trained with training set 1 significantly underestimates the remaining tool life with an RMSE of 14.9 min and an MAE of 12.7 min. An explanation for this behavior is the sensitivity of the LSTM to the characteristic temporal wear curve progression during pocket manufacturing. In this context, face milling represents a modified workpiece geometry and, as part of the training set, mitigates the transferability of the LSTM to pocket manufacturing with different cutting parameter configurations. When the LSTM input is extended to include the future features, as shown in
Figure 12b, the prediction for the model based on training set 1 deteriorates with an RMSE of 22.8 min and an MAE of 19.3 min. For the feasible LSTM based on training set 2, the behavior already observed in
Figure 9b for tools 1 to 7 repeats. In the early stage of the tool life up to a cutting time of 40 min, the prediction accuracy can be increased and the uncertainty can be reduced. This results in minimum values of the RMSE of 2.2 min and the MAE of 1.8 min.
Overall, the remaining tool life prediction approach introduced in this paper allows transferability to pocket manufacturing at increased, previously unknown parameter configurations, thus ensuring process reliability at increased productivity. The evaluation in this paper refers to a specific combination of workpiece material and tool type within the milling process. Due to its general architecture, the remaining tool life prediction methodology applies to other combinations and machining processes without a loss of generality. However, the extent to which the model generated in this paper needs to be re-trained depends on the distance of the resulting data distributions.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}