5.2. Data Set
To evaluate the capability of the proposed framework in gesture recognition, we consider eight different gestures, as shown in
Figure 8. The gestures can be classified into three categories, namely the
linear gestures, the
curved gestures and the
compound ones. The linear gestures consist of four different basic gestures, e.g., left to right motion, right to left motion, front to back motion, and back to front motion, and the curved gestures contain those drawing a circle and drawing a semicircle. The compound gestures can be decomposed into a combination of several basic linear and curved gestures. For example, the compound gesture of drawing a “Z” in the plane consists of three basic gestures: left to right “→”, front to back “↙” and left to right “→”.
Based on the gestures defined, a data set with 1600 samples is collected in real experiments. To enhance the diversity of the gesture data set and to better test the robustness of the proposed framework, 10 volunteers (six males and four females) with different heights, weights, and gesture habits were invited to perform the gestures. For each volunteer, each gesture was performed 20 times.
The 1600 samples in the data set are divided randomly into two groups, with the training set containing 1280 samples and the test set containing 320 samples. The training set is used to training the LSTM network, while the test set is used to assess the accuracy of gesture recognition.
5.3. Performance Evaluations
In this subsection, we evaluate the performance of our proposed hand gesture recognition framework.
For comparisons, we consider two methods as baselines. Specifically, the first baseline adopts the conventional classification method based on the m-D image extracted from the radars and a pre-trained CNN. The m-D image is the input feature and the CNN network acts as a classifier. The second baseline converts the motion velocity vector to an image and then uses a pre-trained CNN network as a classifier.
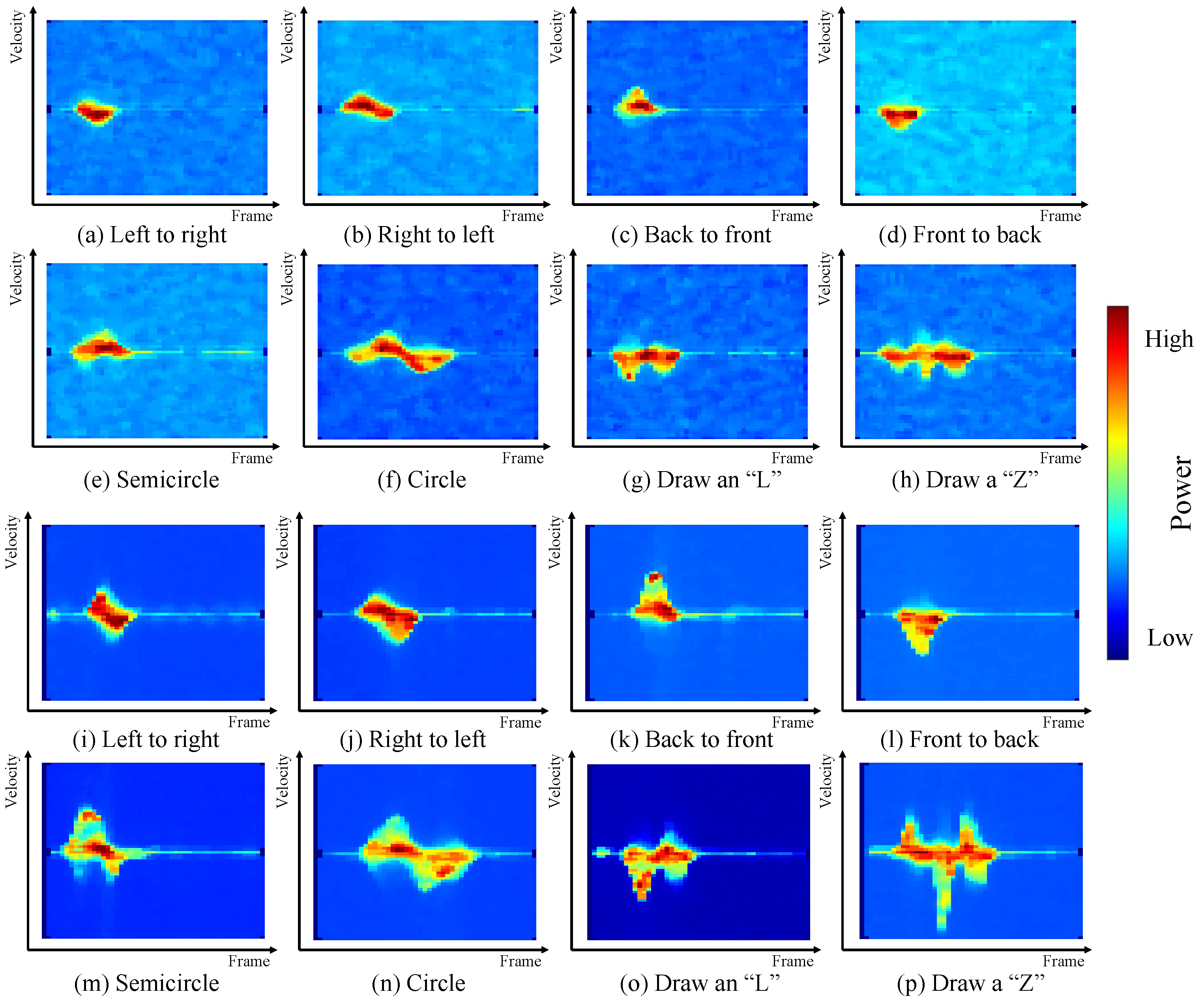
For the first baseline, we consider three types of input feature for a more comprehensive evaluation, including the m-D images obtained from IWR-6843-AOP-EVM (shown in
Figure 9a–h), the m-D image obtained from MMWCAS-DSP/RF-EVM (shown in
Figure 9i–p) and the m-D images from both radars. For the first two types of input features, a classical CNN architecture with two convolutional layers is adopted. Each layer has 16 convolutional filters and the dimensions of each filter are 3 by 3. For the training of the considered CNN network, the number of epochs is set to 100 and the learning rate is considered as a constant value of
.
While both the m-D images are adopted as the input features, we train a two-channel CNN network to classify the gestures. For each channel of the CNN network, there are two convolutional layers, each with 32 filters and a kernel size of . The outputs of these two channels of the CNN network are concatenated and flattened, which are then fed into a fully connected layer to produce the gesture label. When training the network, the number of epochs and the learning rate are set to 50 and , respectively.
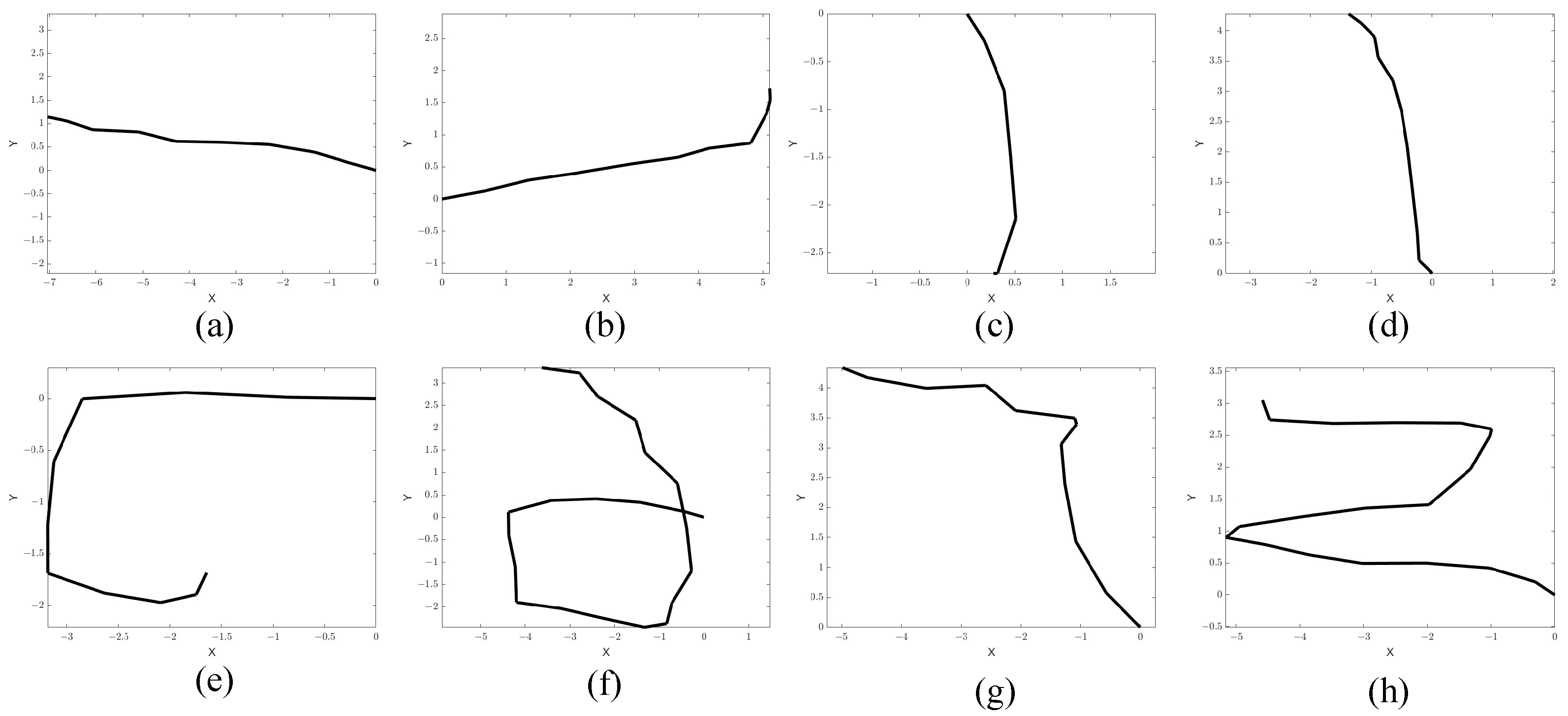
For the second baseline, the image input to the CNN is an image converted from the motion velocity vector extracted from the two radars. To convert the images, we regard each column as a vector in Cartesian coordinates and plot them in chronological order. In
Figure 10, we present several examples of the converted images. As can be seen from the figure, some gestures cannot be distinguished from the converted images, e.g., the right to left gesture and left to right gesture cannot be accurately distinguished from the generated images since they are almost same. The parameters of the CNN are identical to those used in baseline 1 with a single image as the input, but the CNN was trained using the motion images.
For the proposed solution, the size of the input feature is fixed at into with . The LSTM model has two LSTM layers, and each LSTM layer has 200 hidden units. ReLU is chosen as the activation function. In training process, the batch size is set to 3, while the number of epochs and learning rate are set to 100 and , respectively.
Table 4,
Table 5,
Table 6 and
Table 7 present the confusion matrix to illustrate the recognition accuracy of the proposed framework and the baselines. As can be seen from comparing
Table 4 to
Table 5, the gesture recognition accuracy for the MMWCAS-DSP/RF-EVM radar is slightly higher compared to that of the IWR-6843-AOP-EVM radar, as expected, since the former has better signal quality. This is evident in
Figure 9a–p, which show that MMWCAS-DSP/RF-EVM has lower background noise. However, for both radars, the conventional method using r-D images and CNN cannot offer satisfactory gesture recognition accuracy (from
Table 4 and
Table 5, the accuracies are
and
, respectively). Using the m-D images from both radars increases the accuracy to
. However, this performance is still inadequate for practical applications.
As a further enhancement, the second baseline, which utilizes the motion images and the CNN, achieves a significantly higher accuracy than those of baseline 1. As can be seen from
Table 7, the gesture recognition accuracy is about
. These results show the effectiveness of the motion features extracted from the dual-radar system.
The results of our proposed framework are illustrated in
Table 8. As can be seen from the table, our proposed framework achieves an accuracy of about
, which is significantly higher than the accuracy of all the baselines.
To further evaluate the robustness of our proposed gesture recognition framework against diverse gesture patterns, we perform the following experiment. In the experiment, the training set is built by using data sets extracted from eight randomly chosen volunteers, while the test set comes from the other two volunteers. In such circumstances, the LSTM network is trained only with a part of the volunteer data sets. The experimental results presented in
Table 9 show a similar overall accuracy to the ones presented in
Table 8, e.g.,
.
To test the proposed framework against environmental diverseness, we introduce changes in the background environment for gesture recognition, which are demonstrated via a comparison between
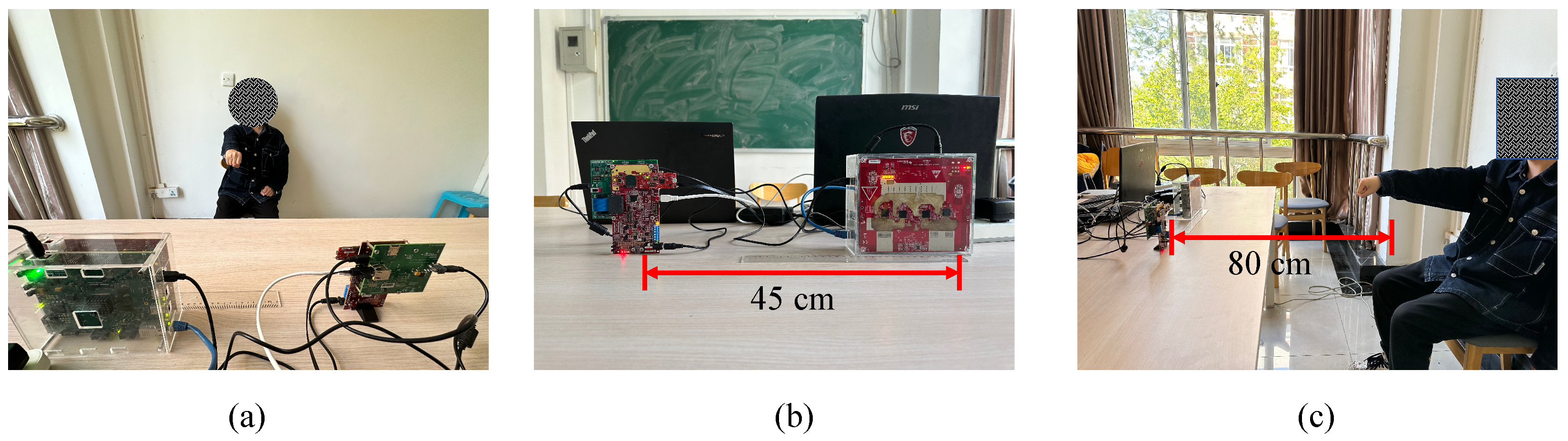
Figure 7a and
Figure 11. In order to keep all other testing conditions unchanged compared to the previous experiment, we ensure that the distance between the two radars remains at 45 cm and the distance between radars and the hand remains at 80 cm.
To simulate a practical environment, several chairs are placed close to the performers of the gestures, as shown in
Figure 11. Due to the implementation of the time division multiplexing mode in radar transmission during the experiment, the resulting beam coverage encompassed all regions within the radars’ FoVs. Consequently, non-target objects such as chairs exerted some influence on the recognition results.
By employing the same trained hyper-parameters of the LSTM network, as the previously conducted experiment, the results of which are presented in
Table 8, 160 samples for eight gestures are inputted for recognition, and the result for the background-changed comparison is
, as illustrated in
Table 10, which mirrors the gesture recognition performance given in
Table 8.
These comparison results validate the robustness of our proposed gesture recognition algorithm and demonstrate its resilience towards the changes in the background environment.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}