Rapid Method of Wastewater Classification by Electronic Nose for Performance Evaluation of Bioreactors with Activated Sludge †

 ,
,  , , , , and
, , , , and 
Abstract
:1. Introduction
2. Machine Learning Methods for Multidimensional Data Analysis
- Homogeneity (), which shows whether created clusters only contain points from one class and completeness (), which gives the information whether the class observations are assigned to the same cluster. These measures are calculated for sets of classes and set of clusters resulting from the carried out algorithm with the following formulas:The conditional entropies are defined as , , individual entropies as , , and the joint entropy as . Additionally, is the number of data points from class assigned to cluster , is the number of observations assigned to class , is the number of observations from class , and is the cardinality of the whole dataset [50]. Both measures belong to the set , where values closer to 1 indicate better clustering performance.
- Adjusted mutual information is also a measure connected to the entropy measure. The mutual information necessary to calculate this measure is defined aswhere and are the individual entropies, and and are the conditional entropies defined beforehand for homogeneity and completeness measures. Then, the adjusted mutual information is calculated aswhere is the expected value of mutual information of classes and clusters . The score for the measure reaches a maximum value of , where indicates a perfect match [52].
- The adjusted Rand index, as presented by Hubert and Arabie in [53], is also a measure of agreement between the true classes of object () and the groups assigned by the clustering method (). The Rand index is defined as follows:where is the number of pairs of data points in the same group in and in the same group in , is the number of pairs of data points that are in different groups in and in different groups in , and is the total number of pairs in the whole data set. The adjusted Rand index is given by the formula:where is the expected value of . The score for the ARI measure is between and , where indicates a perfect match [54].
- The last measure is the silhouette coefficient, as presented in [55], which can be counted for an -th observation in the dataset aswhere is the average distance between the given point and all the other points in the sample cluster, and is the average distance between the point and all the other points in the next closest on the average cluster. To obtain the silhouette coefficient for the entire dataset, the arithmetic mean of all values is calculated. Its values are from the set , where indicate the worst possible clustering, near mean that the clusters are overlapping, and points to the fact that the obtained clustering is the best [50].
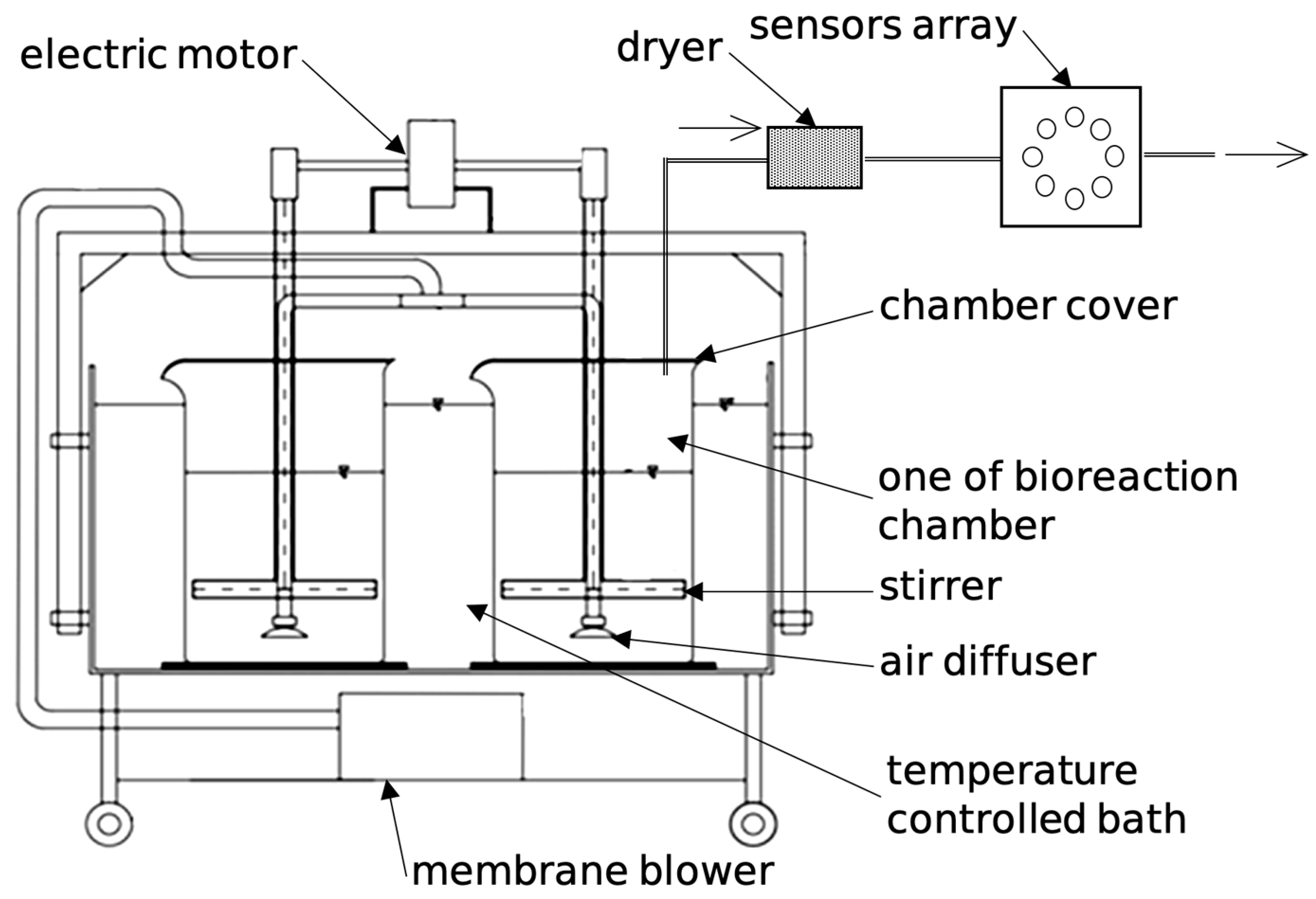
3. Materials and Methods
4. Results
- n_estimators—number of trees trained in algorithm;
- min_samples_leaf—minimum number of observations to form a leaf node in a tree;
- max_features—number of variables drawn at each node, which are then used for creating a split.
5. Discussion
6. Summary and Conclusions
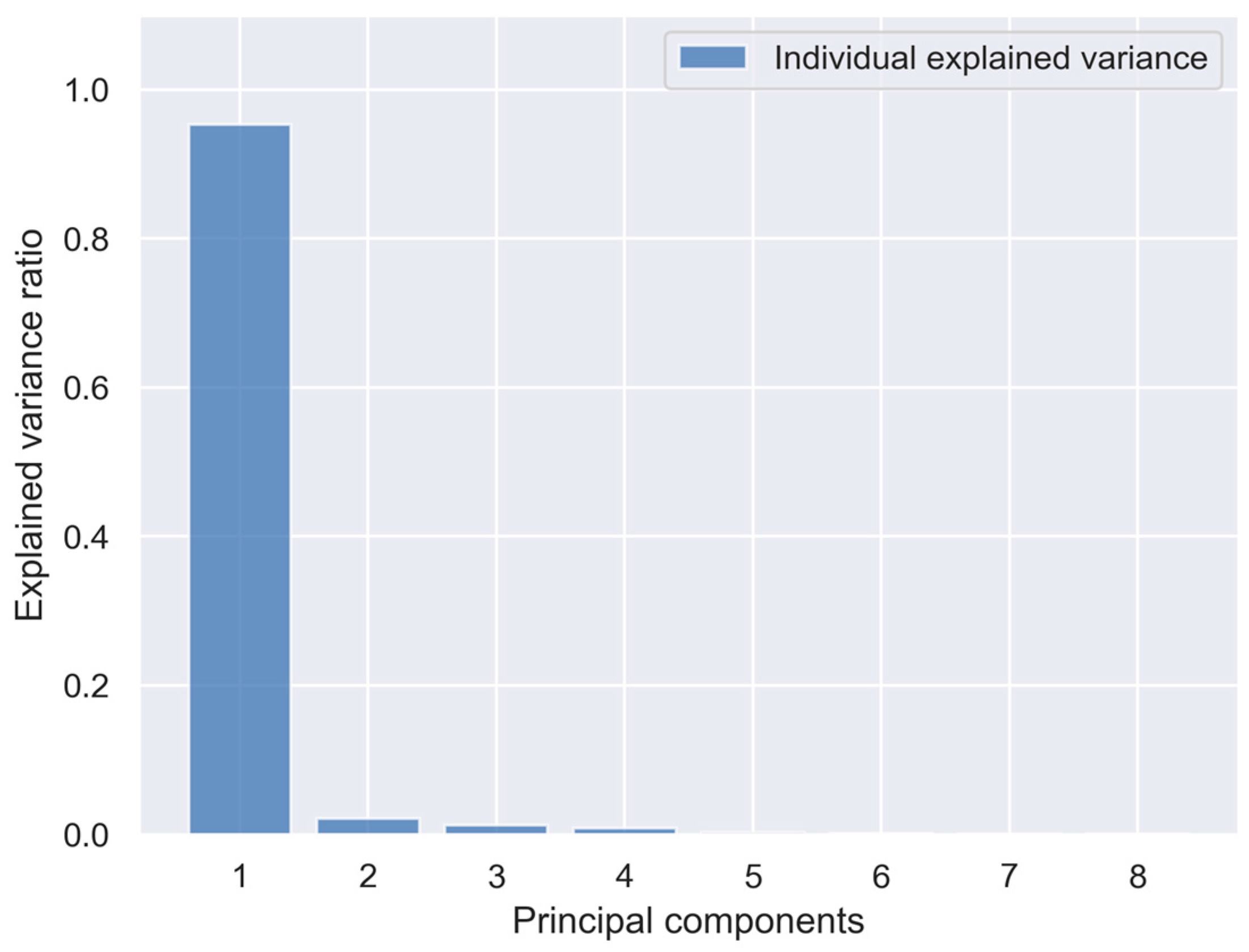
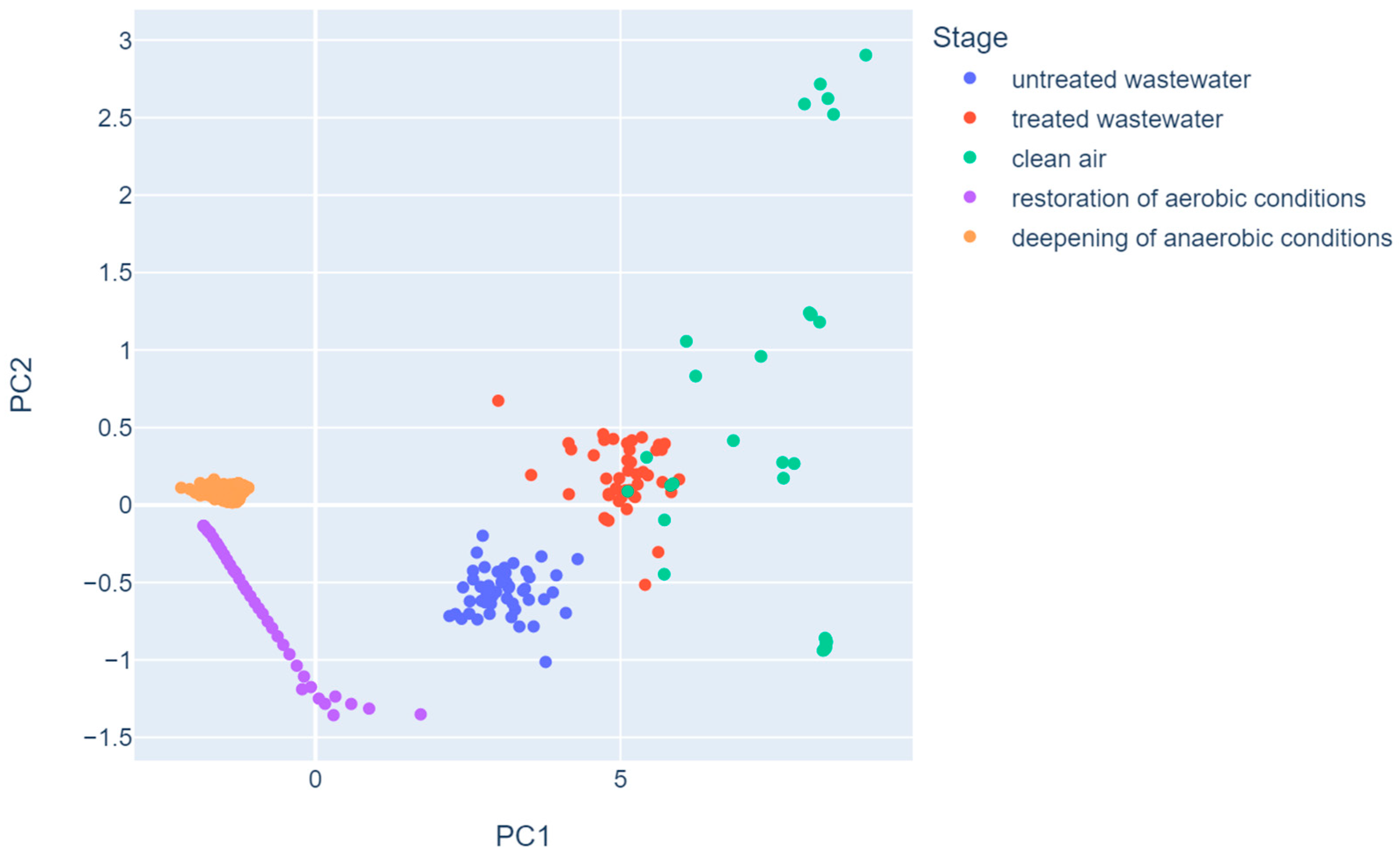
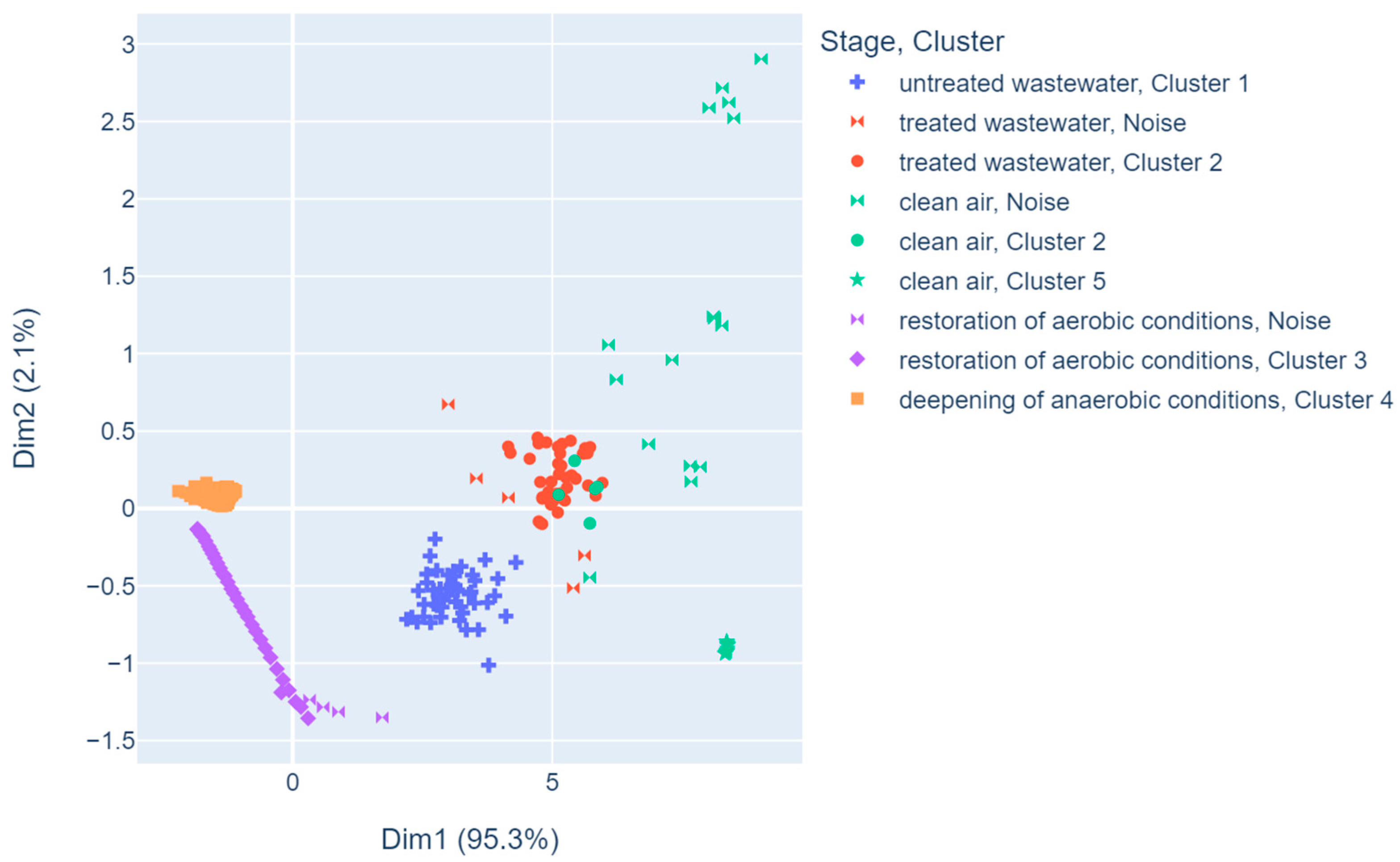
- Principal component analysis allows one to distinguish observations related to deviations and normal bioreactor operation, while the first two principal components explained over 95% of variance. However, not all stages are desegregated, as some of them overlap in the plot.
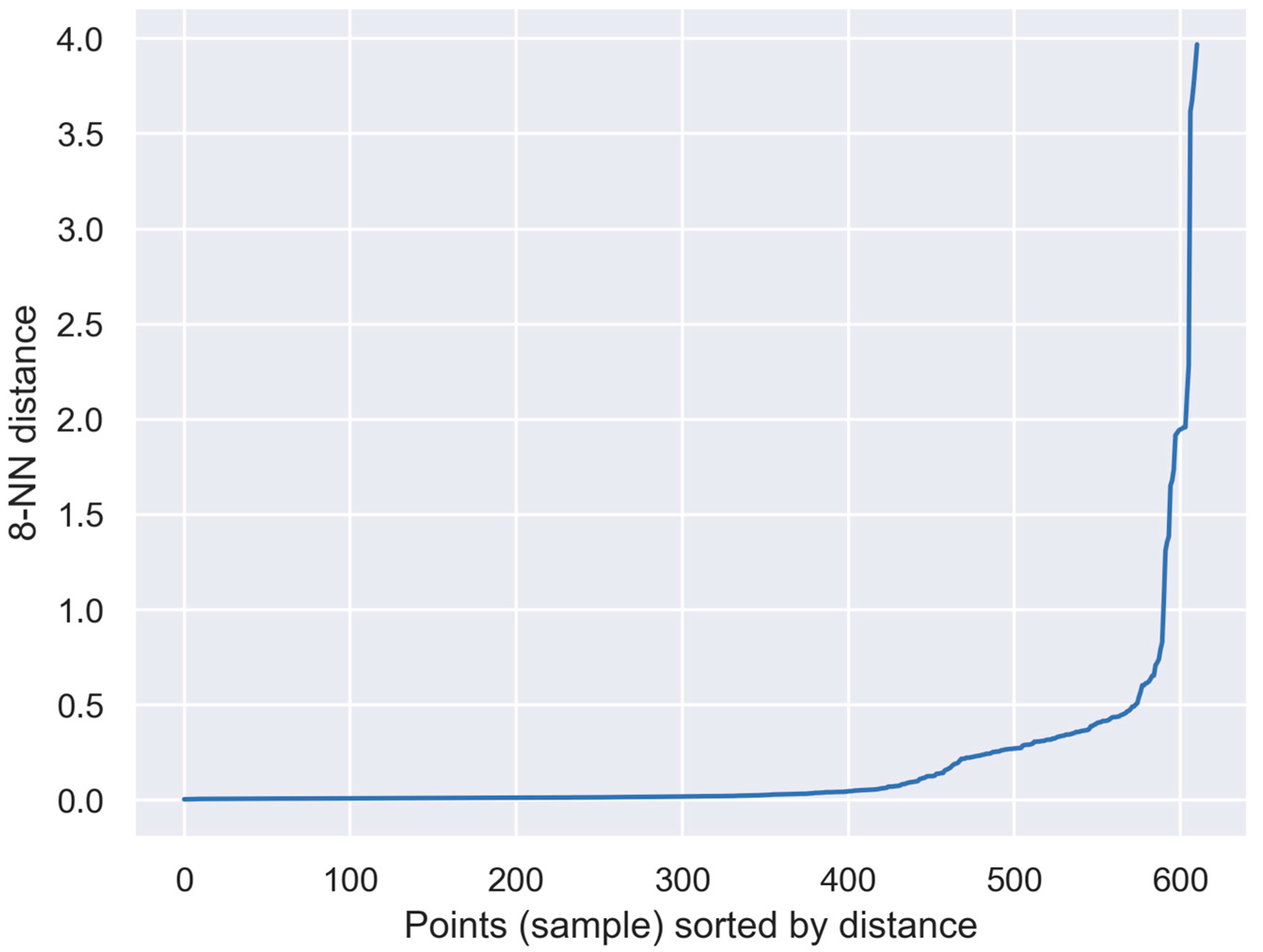
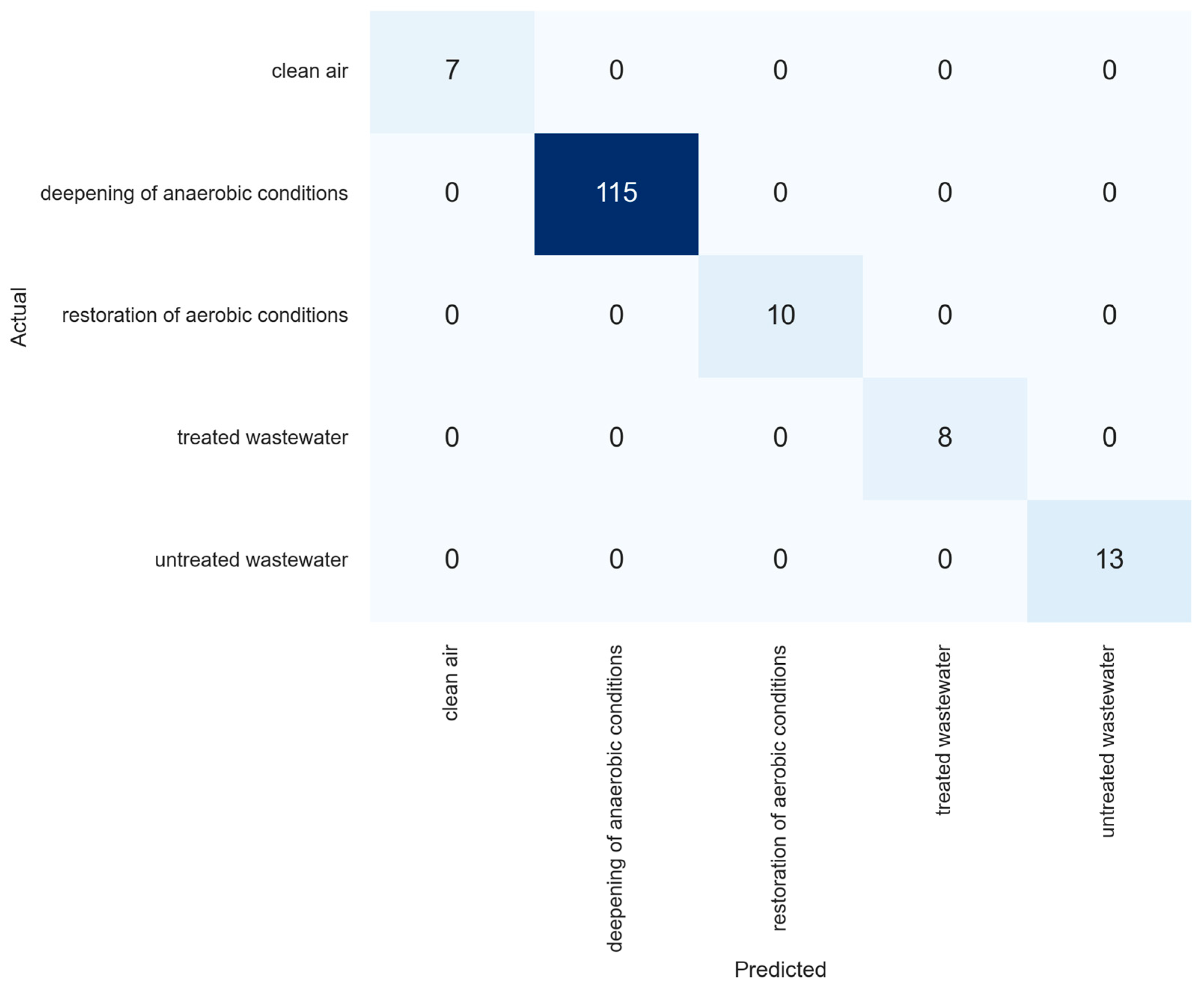
- The density-based clustering method DBSCAN managed to cluster the data into five groups, which is the same number as the true number of stage classes. However, not all observations were classified into the appropriate clusters.
- Although the restoration of the anaerobic conditions class arranged itself into a chain of points on the graph, owing to the ability of the DBSCAN algorithm to group data arranged into different shapes (not just spherical), the algorithm joined these observations into a single cluster. In addition, different clustering measures confirm that clustering with this algorithm was of good quality.
- Some observations from the classes of treated wastewater, clean air, and restoration of aerobic conditions were classified by DBSCAN as noise. Such an occurrence may herald the occurrence of an abnormal situation in the bioreactor and should be investigated for failure prevention.
- The extra trees supervised learning algorithm performed much better on the task of classifying objects into the appropriate classes. With optimal values of grid search parameters, it achieved 100% classification accuracy on the test set.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Aghdam, E.; Mohandes, S.R.; Manu, P.; Cheung, C.; Yunusa-Kaltungo, A.; Zayed, T. Predicting Quality Parameters of Wastewater Treatment Plants Using Artificial Intelligence Techniques. J. Clean. Prod. 2023, 405, 137019. [Google Scholar] [CrossRef]
- Ansari, M.; Othman, F.; El-Shafie, A. Optimized Fuzzy Inference System to Enhance Prediction Accuracy for Influent Characteristics of a Sewage Treatment Plant. Sci. Total Environ. 2020, 722, 137878. [Google Scholar] [CrossRef] [PubMed]
- Henze, M.; van Loosdrecht, M.C.M.; Ekama, G.A.; Brdjanovic, D. Biological Wastewater Treatment: Principles, Modelling and Design; IWA Publishing: London, UK, 2008; ISBN 9781780401867. [Google Scholar]
- Łagód, G.; Drewnowski, J.; Guz, Ł.; Piotrowicz, A.; Suchorab, Z.; Drewnowska, M.; Jaromin-Gleń, K.; Szeląg, B. Rapid On-Line Method of Wastewater Parameters Estimation by Electronic Nose for Control and Operating Wastewater Treatment Plants toward Green Deal Implementation. Desalin. Water Treat. 2022, 275, 56–68. [Google Scholar] [CrossRef]
- Corominas, L.; Garrido-Baserba, M.; Villez, K.; Olsson, G.; Cortés, U.; Poch, M. Transforming Data into Knowledge for Improved Wastewater Treatment Operation: A Critical Review of Techniques. Environ. Model. Softw. 2018, 106, 89–103. [Google Scholar] [CrossRef]
- Jouanneau, S.; Recoules, L.; Durand, M.J.; Boukabache, A.; Picot, V.; Primault, Y.; Lakel, A.; Sengelin, M.; Barillon, B.; Thouand, G. Methods for Assessing Biochemical Oxygen Demand (BOD): A Review. Water Res. 2014, 49, 62–82. [Google Scholar] [CrossRef]
- Wu, D.; Hu, Y.; Liu, Y. A Review of Detection Techniques for Chemical Oxygen Demand in Wastewater. Am. J. Biochem. Biotechnol. 2022, 18, 23–32. [Google Scholar] [CrossRef]
- APHA. Standard Methods for the Examination of Water and Wastewater, 23rd ed.; Baird, R., Rice, E.W., A.D. Eaton, L.B., Eds.; American Health Association: Washington, DC, USA, 2017. [Google Scholar]
- Craven, M.A.; Gardner, J.W.; Bartlett, P.N. Electronic Noses—Development and Future Prospects. TrAC Trends Anal. Chem. 1996, 15, 486–493. [Google Scholar] [CrossRef]
- Arshak, K.; Moore, E.; Lyons, G.M.; Harris, J.; Clifford, S. A Review of Gas Sensors Employed in Electronic Nose Applications. Sens. Rev. 2004, 24, 181–198. [Google Scholar] [CrossRef]
- Bieganowski, A.; Józefaciuk, G.; Bandura, L.; Guz, Ł.; Łagód, G.; Franus, W. Evaluation of Hydrocarbon Soil Pollution Using E-Nose. Sensors 2018, 18, 2463. [Google Scholar] [CrossRef]
- Garbacz, M.; Malec, A.; Duda-Saternus, S.; Suchorab, Z.; Guz, Ł.; Łagód, G. Methods for Early Detection of Microbiological Infestation of Buildings Based on Gas Sensor Technologies. Chemosensors 2020, 8, 7. [Google Scholar] [CrossRef]
- Bergman, L.E.; Wilson, J.M.; Small, M.J.; VanBriesen, J.M. Application of Classification Trees for Predicting Disinfection By-Product Formation Targets from Source Water Characteristics. Environ. Eng. Sci. 2016, 33, 455–470. [Google Scholar] [CrossRef]
- Dixon, S.J.; Brereton, R.G. Comparison of Performance of Five Common Classifiers Represented as Boundary Methods: Euclidean Distance to Centroids, Linear Discriminant Analysis, Quadratic Discriminant Analysis, Learning Vector Quantization and Support Vector Machines, as Dependent On. Chemom. Intell. Lab. Syst. 2009, 95, 1–17. [Google Scholar] [CrossRef]
- Piłat-Rożek, M.; Łazuka, E.; Majerek, D.; Szeląg, B.; Duda-Saternus, S.; Łagód, G. Application of Machine Learning Methods for an Analysis of E-Nose Multidimensional Signals in Wastewater Treatment. Sensors 2023, 23, 487. [Google Scholar] [CrossRef]
- Fu, J.; Huang, C.; Xing, J.; Zheng, J. Pattern Classification Using an Olfactory Model with PCA Feature Selection in Electronic Noses: Study and Application. Sensors 2012, 12, 2818–2830. [Google Scholar] [CrossRef]
- Dewettinck, T.; Van Hege, K.; Verstraete, W. The Electronic Nose as a Rapid Sensor for Volatile Compounds in Treated Domestic Wastewater. Water Res. 2001, 35, 2475–2483. [Google Scholar] [CrossRef]
- Guz, Ł.; Łagód, G.; Jaromin-Gleń, K.; Suchorab, Z.; Sobczuk, H.; Bieganowski, A. Application of Gas Sensor Arrays in Assessment of Wastewater Purification Effects. Sensors 2015, 15, 1–21. [Google Scholar] [CrossRef]
- Onkal-Engin, G.; Demir, I.; Engin, S.N. Determination of the Relationship between Sewage Odour and BOD by Neural Networks. Environ. Model. Softw. 2005, 20, 843–850. [Google Scholar] [CrossRef]
- Stuetz, R.M.; Fenner, R.A.; Engin, G. Characterisation of Wastewater Using an Electronic Nose. Water Res. 1999, 33, 442–452. [Google Scholar] [CrossRef]
- Kośmider, J.; Mazur-Chrzanowska, B.; Wyszyński, B. Odory; Wydawnictwo Naukowe PWN: Warsaw, Poland, 2012; ISBN 83-01-13744-4. [Google Scholar]
- Pomiès, M.; Choubert, J.-M.; Wisniewski, C.; Coquery, M. Modelling of Micropollutant Removal in Biological Wastewater Treatments: A Review. Sci. Total Environ. 2013, 443, 733–748. [Google Scholar] [CrossRef]
- Govind, R.; Lai, L.; Dobbs, R. Integrated Model for Predicting the Fate of Organics in Wastewater Treatment Plants. Environ. Prog. 1991, 10, 13–23. [Google Scholar] [CrossRef]
- Byrns, G. The Fate of Xenobiotic Organic Compounds in Wastewater Treatment Plants. Water Res. 2001, 35, 2523–2533. [Google Scholar] [CrossRef]
- Struijs, J.; Stoltenkamp, J.; van de Meent, D. A Spreadsheet-Based Box Model to Predict the Fate of Xenobiotics in a Municipal Wastewater Treatment Plant. Water Res. 1991, 25, 891–900. [Google Scholar] [CrossRef]
- Lee, K.-C.; Rittmann, B.E.; Shi, J.; McAvoy, D. Advanced Steady-State Model for the Fate of Hydrophobic and Volatile Compounds in Activated Sludge. Water Environ. Res. 1998, 70, 1118–1131. [Google Scholar] [CrossRef]
- Capelli, L.; Sironi, S.; Céntola, P.; Del Rosso, R.; Il Grande, M. Electronic Noses for the Continuous Monitoring of Odours from a Wastewater Treatment Plant at Specific Receptors: Focus on Training Methods. Sens. Actuators B Chem. 2008, 131, 53–62. [Google Scholar] [CrossRef]
- Nake, A.; Dubreuil, B.; Raynaud, C.; Talou, T. Outdoor in Situ Monitoring of Volatile Emissions from Wastewater Treatment Plants with Two Portable Technologies of Electronic Noses. Sens. Actuators B Chem. 2005, 106, 36–39. [Google Scholar] [CrossRef]
- Giuliani, S.; Zarra, T.; Nicolas, J.; Naddeo, V.; Belgiorno, V.; Romain, A.C. An Alternative Approach of the E-Nose Training Phase in Odour Impact Assessment. Chem. Eng. Trans. 2012, 30. [Google Scholar] [CrossRef]
- Littarru, P. Environmental Odours Assessment from Waste Treatment Plants: Dynamic Olfactometry in Combination with Sensorial Analysers “Electronic Noses”. Waste Manag. 2007, 27, 302–309. [Google Scholar] [CrossRef]
- Stuetz, R.M.; Fenner, R.A.; Engin, G. Assessment of Odours from Sewage Treatment Works by an Electronic Nose, H2S Analysis and Olfactometry. Water Res. 1999, 33, 453–461. [Google Scholar] [CrossRef]
- Masłoń, A. Impact of Uneven Flow Wastewater Distribution on the Technological Efficiency of a Sequencing Batch Reactor. Sustainability 2022, 14, 2405. [Google Scholar] [CrossRef]
- Cheng, Q.; Chunhong, Z.; Qianglin, L. Development and Application of Random Forest Regression Soft Sensor Model for Treating Domestic Wastewater in a Sequencing Batch Reactor. Sci. Rep. 2023, 13, 9149. [Google Scholar] [CrossRef]
- Dutta, A.; Sarkar, S. Sequencing Batch Reactor for Wastewater Treatment: Recent Advances. Curr. Pollut. Rep. 2015, 1, 177–190. [Google Scholar] [CrossRef]
- Wilderer, P.A.; Irvine, R.L.; Goronszy, M.C. (Eds.) Sequencing Batch Reactor Technology; IWA Publishing: London, UK, 2007; ISBN 9781780402246. [Google Scholar]
- Łagód, G.; Guz, Ł.; Sabba, F.; Sobczuk, H. Detection of Wastewater Treatment Process Disturbances in Bioreactors Using the E-Nose Technology. Ecol. Chem. Eng. S 2018, 25, 405–418. [Google Scholar] [CrossRef]
- Guz, Ł.; Łagód, G.; Jaromin-Gleń, K.; Guz, E.; Sobczuk, H. Assessment of Batch Bioreactor Odour Nuisance Using an E-Nose. Desalin. Water Treat. 2016, 57, 1327–1335. [Google Scholar] [CrossRef]
- Jiang, H.; Li, J.; Yi, S.; Wang, X.; Hu, X. A New Hybrid Method Based on Partitioning-Based DBSCAN and Ant Clustering. Expert Syst. Appl. 2011, 38, 9373–9381. [Google Scholar] [CrossRef]
- Abdi, H.; Williams, L.J. Principal Component Analysis. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef]
- Pearson, K. On Lines and Planes of Closest Fit to Systems of Points in Space. Dublin Philos. Mag. J. Sci. 1901, 2, 559–572. [Google Scholar] [CrossRef]
- Hotelling, H. Analysis of a Complex of Statistical Variables into Principal Components. J. Educ. Psychol. 1933, 24, 498–520. [Google Scholar] [CrossRef]
- Mardia, K.V.; Kent, T.; Bibby, J. Multivariate Analysis; Academic Press Limited: Cambridge, MA, USA, 1979. [Google Scholar]
- Kaiser, H.F. The Application of Electronic Computers to Factor Analysis. Educ. Psychol. Meas. 1960, 20, 141–151. [Google Scholar] [CrossRef]
- Jolliffe, I.T. Choosing a Subset of Principal Components or Variables. In Principal Component Analysis; Springer: New York, NY, USA, 2002; pp. 111–149. [Google Scholar]
- Łagód, G.; Piłat-Rożek, M.; Majerek, D.; Łazuka, E.; Suchorab, Z.; Guz, Ł.; Kočí, V.; Černý, R. Application of Dimensionality Reduction and Machine Learning Methods for the Interpretation of Gas Sensor Array Readouts from Mold-Threatened Buildings. Appl. Sci. 2023, 13, 8588. [Google Scholar] [CrossRef]
- Astel, A.; Tsakovski, S.; Barbieri, P.; Simeonov, V. Comparison of Self-Organizing Maps Classification Approach with Cluster and Principal Components Analysis for Large Environmental Data Sets. Water Res. 2007, 41, 4566–4578. [Google Scholar] [CrossRef]
- Shrestha, S.; Kazama, F. Assessment of Surface Water Quality Using Multivariate Statistical Techniques: A Case Study of the Fuji River Basin, Japan. Environ. Model. Softw. 2007, 22, 464–475. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Hahsler, M.; Piekenbrock, M.; Doran, D. Dbscan: Fast Density-Based Clustering with R. J. Stat. Softw. 2019, 91. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Rosenberg, A.; Hirschberg, J. V-Measure: A Conditional Entropy-Based External Cluster Evaluation Measure. In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL), Prague, Czech Republic, 28–30 June 2007; pp. 410–420. [Google Scholar]
- Vinh, N.X.; Epps, J.; Bailey, J. Information Theoretic Measures for Clusterings Comparison: Variants, Properties, Normalization and Correction for Chance. J. Mach. Learn. Res. 2010, 11, 2837–2854. [Google Scholar]
- Hubert, L.; Arabie, P. Comparing Partitions. J. Classif. 1985, 2, 193–218. [Google Scholar] [CrossRef]
- Chacón, J.E.; Rastrojo, A.I. Minimum Adjusted Rand Index for Two Clusterings of a given Size. Adv. Data Anal. Classif. 2023, 17, 125–133. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A Graphical Aid to the Interpretation and Validation of Cluster Analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Hu, X.; Han, Y.; Yu, B.; Geng, Z.; Fan, J. Novel Leakage Detection and Water Loss Management of Urban Water Supply Network Using Multiscale Neural Networks. J. Clean. Prod. 2021, 278, 123611. [Google Scholar] [CrossRef]
- Syafrudin, M.; Alfian, G.; Fitriyani, N.; Rhee, J. Performance Analysis of IoT-Based Sensor, Big Data Processing, and Machine Learning Model for Real-Time Monitoring System in Automotive Manufacturing. Sensors 2018, 18, 2946. [Google Scholar] [CrossRef]
- Iyer, S.; Thakur, S.; Dixit, M.; Katkam, R.; Agrawal, A.; Kazi, F. Blockchain and Anomaly Detection Based Monitoring System for Enforcing Wastewater Reuse. In Proceedings of the 2019 10th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kanpur, India, 6–8 July 2019; pp. 1–7. [Google Scholar]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely Randomized Trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef]
- Godfrey Nnabuife, S.; Kuang, B.; Whidborne, J.F.; Rana, Z. Non-Intrusive Classification of Gas-Liquid Flow Regimes in an S-Shaped Pipeline Riser Using a Doppler Ultrasonic Sensor and Deep Neural Networks. Chem. Eng. J. 2021, 403, 126401. [Google Scholar] [CrossRef]
- Yarveicy, H.; Saghafi, H.; Ghiasi, M.M.; Mohammadi, A.H. Decision Tree-Based Modeling of CO 2 Equilibrium Absorption in Different Aqueous Solutions of Absorbents. Environ. Prog. Sustain. Energy 2019, 38, S441–S448. [Google Scholar] [CrossRef]
- Bhamare, D.K.; Saikia, P.; Rathod, M.K.; Rakshit, D.; Banerjee, J. A Machine Learning and Deep Learning Based Approach to Predict the Thermal Performance of Phase Change Material Integrated Building Envelope. Build. Environ. 2021, 199, 107927. [Google Scholar] [CrossRef]
- TGS Figaro Sensors Datasheets for: TGSTGS 2602, TGS 2610, TGS 2611, TGS 2612, TGS 2620. Available online: https://www.figarosensor.com/product/ (accessed on 29 August 2023).
- Dallas Semiconductor DS18B20 Datasheet. Available online: www.dalsemi.com (accessed on 29 August 2023).
- Sensing and Control Honeywell Honeywell HIH-4000 Datasheet. Available online: www.honeywell.com (accessed on 29 August 2023).
- Kluyver, T.; Ragan-Kelley, B.; Pérez, F.; Granger, B.; Bussonnier, M.; Frederic, J.; Kelley, K.; Hamrick, J.; Grout, J.; Corlay, S.; et al. Jupyter Notebooks—A Publishing Format for Reproducible Computational Workflows. Elpub 2016, 26, 87–90. [Google Scholar]
- Van Rossum, G.; Drake, F.L., Jr. Python Reference Manual; Centrum voor Wiskunde en Informatica Amsterdam: Amsterdam, The Netherlands, 1995. [Google Scholar]
- McKinney, W. Data Structures for Statistical Computing in Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010; pp. 56–61. [Google Scholar]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array Programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef]
- Waskom, M. Seaborn: Statistical Data Visualization. J. Open Source Softw. 2021, 6, 3021. [Google Scholar] [CrossRef]
- Hunter, J.D. Matplotlib: A 2D Graphics Environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- Plotly Technologies Inc. Collaborative Data Science. Available online: https://plot.ly (accessed on 16 August 2023).
- Bourgeois, W.; Hogben, P.; Pike, A.; Stuetz, R.M. Development of a Sensor Array Based Measurement System for Continuous Monitoring of Water and Wastewater. Sens. Actuators B Chem. 2003, 88, 312–319. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensor ID | Type and Manufacturer | Description and Technical Parameters |
|---|---|---|
| 1 | TGS2600-B00 Figaro | Gas sensor: general air contaminants, methane, CO, isobutane, ethanol, hydrogen; detection range, 1–30 ppm (for hydrogen); resistance, 10–90 kΩ for clean air. |
| 2 | TGS2602-B00 Figaro | Gas sensor: general air contaminants, VOC, ammonia, hydrogen sulfide, ethanol, toluene, odorous compounds; detection range, 1–30 ppm (for ethanol); resistance, 10–100 kΩ for clean air. |
| 3 | TGS2610-C00 Figaro | Gas sensor: LP gas and vapor detection, ethanol, hydrogen, methane, isobutane, propane. Butane; detection range, 500–10 k ppm; resistance, 0.68–6.8 kΩ for iso-butane. |
| 4 | TGS2610-D00 Figaro (with carbon filter) | Gas sensor: LP gas and vapor detection, ethanol, hydrogen, methane, isobutane, propane. Butane; detection range, 500–10 k ppm; resistance, 0.68–6.8 kΩ for iso-butane. |
| 5 | TGS2611-C00 Figaro | Gas sensor: methane, hydrogen, iso-butane, ethanol; detection range, 500–10 k ppm; resistance, 0.68–6.8 kΩ for methane. |
| 6 | TGS2611-E00 Figaro (with carbon filter) | Gas sensor: methane, hydrogen, iso-butane (uses filter material in its housing, which eliminates the influence of interference gases such as alcohol); detection range, 500–10 k ppm; 0.68–6.8 kΩ for methane. |
| 7 | TGS2612-D00 Figaro | Gas sensor: mostly LNG and LPG methane, propane, iso-butane, solvent vapors; detection range, 1–25% LEL; resistance, 0.68–6.8 kΩ for methane. |
| 8 | TGS2620-C00 Figaro | Gas sensor: alcohol, solvent vapors; detection range, 50–5 k ppm; resistance, 1–5 kΩ for ethanol 300 ppm. |
| Clustering Quality Measure | Value |
|---|---|
| Homogeneity | 0.935 |
| Completeness | 0.897 |
| V-measure | 0.916 |
| Adjusted Mutual Information | 0.914 |
| Adjusted Rand Index | 0.988 |
| Silhouette Coefficient | 0.690 |
| Parameter | Vector of Checked Values | Optimal Value |
|---|---|---|
| n_estimators | [50, 100, 200] | 50 |
| min_samples_leaf | [2, 5, 20] | 2 |
| max_features | [2, 5, 8] | 8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Piłat-Rożek, M.; Dziadosz, M.; Majerek, D.; Jaromin-Gleń, K.; Szeląg, B.; Guz, Ł.; Piotrowicz, A.; Łagód, G. Rapid Method of Wastewater Classification by Electronic Nose for Performance Evaluation of Bioreactors with Activated Sludge. Sensors 2023, 23, 8578. https://doi.org/10.3390/s23208578
Piłat-Rożek M, Dziadosz M, Majerek D, Jaromin-Gleń K, Szeląg B, Guz Ł, Piotrowicz A, Łagód G. Rapid Method of Wastewater Classification by Electronic Nose for Performance Evaluation of Bioreactors with Activated Sludge. Sensors. 2023; 23(20):8578. https://doi.org/10.3390/s23208578
Chicago/Turabian StylePiłat-Rożek, Magdalena, Marcin Dziadosz, Dariusz Majerek, Katarzyna Jaromin-Gleń, Bartosz Szeląg, Łukasz Guz, Adam Piotrowicz, and Grzegorz Łagód. 2023. "Rapid Method of Wastewater Classification by Electronic Nose for Performance Evaluation of Bioreactors with Activated Sludge" Sensors 23, no. 20: 8578. https://doi.org/10.3390/s23208578
APA StylePiłat-Rożek, M., Dziadosz, M., Majerek, D., Jaromin-Gleń, K., Szeląg, B., Guz, Ł., Piotrowicz, A., & Łagód, G. (2023). Rapid Method of Wastewater Classification by Electronic Nose for Performance Evaluation of Bioreactors with Activated Sludge. Sensors, 23(20), 8578. https://doi.org/10.3390/s23208578