Abstract
Deep-sea biological detection is essential for deep-sea resource research and conservation. However, due to the poor image quality and insufficient image samples in the complex deep-sea imaging environment, resulting in poor detection results. Furthermore, most existing detection models accomplish high precision at the expense of increased complexity, and leading cannot be well deployed in the deep-sea environment. To alleviate these problems, a detection method for deep-sea organisms based on lightweight YOLOv5n is proposed. First, a lightweight YOLOv5n is created. The proposed image enhancement method based on global and local contrast fusion (GLCF) is introduced into the input layer of YOLOv5n to address the problem of color deviation and low contrast in the image. At the same time, a Bottleneck based on the Ghost module and simAM (GS-Bottleneck) is developed to achieve a lightweight model while ensuring sure detection performance. Second, a transfer learning strategy combined with knowledge distillation (TLKD) is designed, which can reduce the dependence of the model on the amount of data and improve the generalization ability to enhance detection accuracy. Experimental results on the deep-sea biological dataset show that the proposed method achieves good detection accuracy and speed, outperforming existing methods.
1. Introduction
Deep-sea biological activities are crucial in shaping the marine ecosystem and regulating global climate, driving the oceanic element cycling from short to long timescales [1,2]. Underwater target detection is an efficient way to study and conserve deep-sea biological resources. However, the imaging environment in the deep sea is highly complex, leading to significant challenges in capturing high-quality deep-sea optical images using underwater cameras. These images often exhibit color shifts, low contrast, and limited sample size, which ultimately hamper the accuracy of deep-sea biological object detection.
In recent years, extensive research has been conducted in the field of underwater biological detection. The current underwater biological detection algorithms can be divided into two types of methods: traditional machine learning-based and deep learning-based. Traditional machine learning-based methods extract object features and feed them to a classifier for detection. Zhang et al. [3] first enhanced underwater images, removed target features through image segmentation and feature extraction, and used support vector machines for detection. Chen et al. [4] employed the speed-up robust features algorithm to extract target features, represent features using the bag of words method, and use random forests for detection. However, difficulties in feature extraction and poor robustness are encountered due to the complexity of underwater environments and the need to manually design various window sizes and feature extractors in traditional machine learning-based algorithms.
Deep learning-based algorithms can be classified into two categories. The first category is two-stage algorithms, in which a region proposal network is employed to generate regions of interest. These selected regions are subsequently classified using the network. Exemplary algorithms within this category comprise R-CNN [5] and Faster R-CNN [6]. Tan et al. [7] designed an image preprocessing method of the MSRCR and median filtering, improved the neck network using attention mechanisms, and achieved high accuracy. Although this class of methods achieves high accuracy, they tend to have slower detection speeds. Another category consists of one-stage algorithms, exemplified by YOLO [8]. These algorithms treat object detection’s localization and classification tasks as regression questions, leading to faster detection speeds. Hao et al. [9] applied the automatic color enhancement algorithm to enhance the color and brightness of MSRCR-processed images, replacing residual modules in the YOLOv3 feature extraction network with dense blocks to improve accuracy. Wageeh Y et al. [10] used the MSRCR to enhance the quality of underwater images. They combined the YOLO algorithm with the optical flow to achieve fish detection and tracking. Zhang et al. [11] proposed an underwater target detection model based on channel attention and feature fusion. They also designed a data augmentation method based on concatenation and fusion to effectively reduce the occurrence of false positives and false negatives in the model.
The above research on deep learning-based algorithms has progressed. However, there are three primary challenges for deep-sea biological detection: (1) those due to the deep-sea biological images acquired in the low-light deep-sea environment, in addition to color deviation, and the image having low contrast, overexposure, and underexposure, which affect detection accuracy; (2) the acquisition of deep-sea biological images is expensive, leading to insufficient image samples and limited model generalization ability; and (3) most current models for underwater biological detection improve detection accuracy at the cost of complexity, resulting in high model complexity that may not be more conducive for deployment in small deep-sea detection devices.
To solve the abovementioned challenges, a deep-sea biological detection method based on the lightweight YOLOv5n is proposed. The main contributions of this paper are:
(1) We propose an image enhancement method based on global and local contrast fusion for low-quality deep-sea biological images. Gamma correction, CLAHE, and PCA are applied to improve the contrast of the image after correcting the image color based on the grayscale world.
(2) A lightweight Bottleneck module is designed, which combines the advantages of cheap operation of the Ghost module and the advantages of simAM to focus on important biological features and realizes the lightweight of the model under a certain detection performance.
(3) We propose a transfer learning strategy combined with knowledge distillation for insufficient deep-sea biological image samples. The strategy migrates similar characteristics of shallow-sea organisms into the model and further improves the generalization ability of the model by knowledge distillation to mitigate the effect of insufficient data on the detection accuracy without increasing the model complexity.
2. Methods
2.1. Overall Structure of the Method
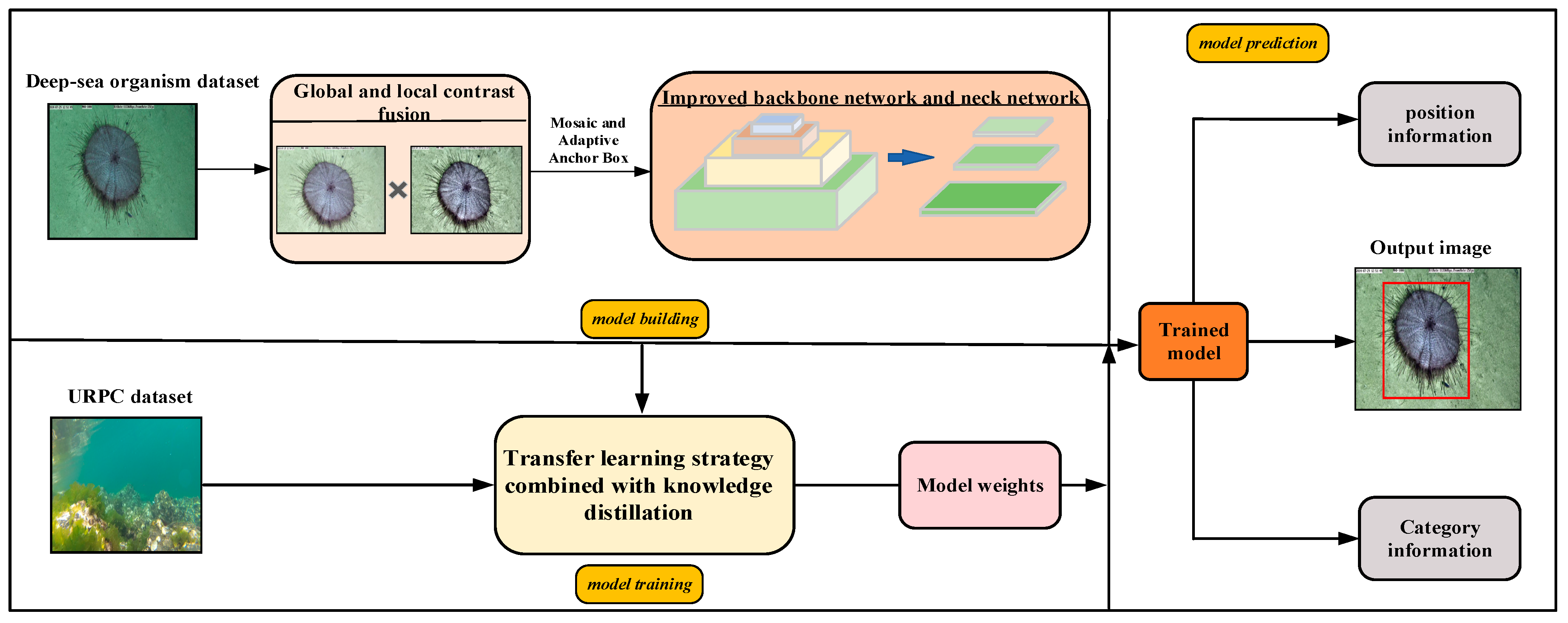
This method mainly consists of constructing a lightweight YOLOv5n detection model and a transfer learning strategy combined with knowledge distillation. As shown in Figure 1, in terms of model construction, the designed image enhancement method based on global and local fusion is added to the model to enhance deep-sea biological images. Secondly, to build a lightweight model, a GS-Bottleneck is designed based on the Ghost module and the simAM, and it is used to replace the neck network in the original backbone network and neck network to obtain the improved backbone network and neck network. In terms of model training, the models are trained on the deep-sea organism dataset and shallow-sea biological dataset using a transfer learning strategy combined with knowledge distillation. After several iterations, the weight parameters are assigned to the model. The trained model can detect the position information and class information of the organisms in the image.
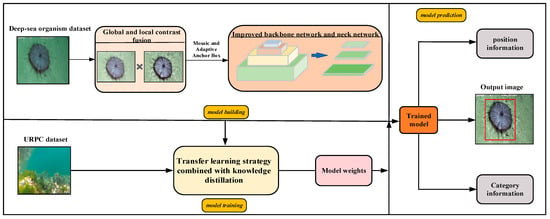
Figure 1.
Overall framework of the proposed method.
2.2. Lightweight YOLOv5n Detection Model
2.2.1. Overall Framework of the Model
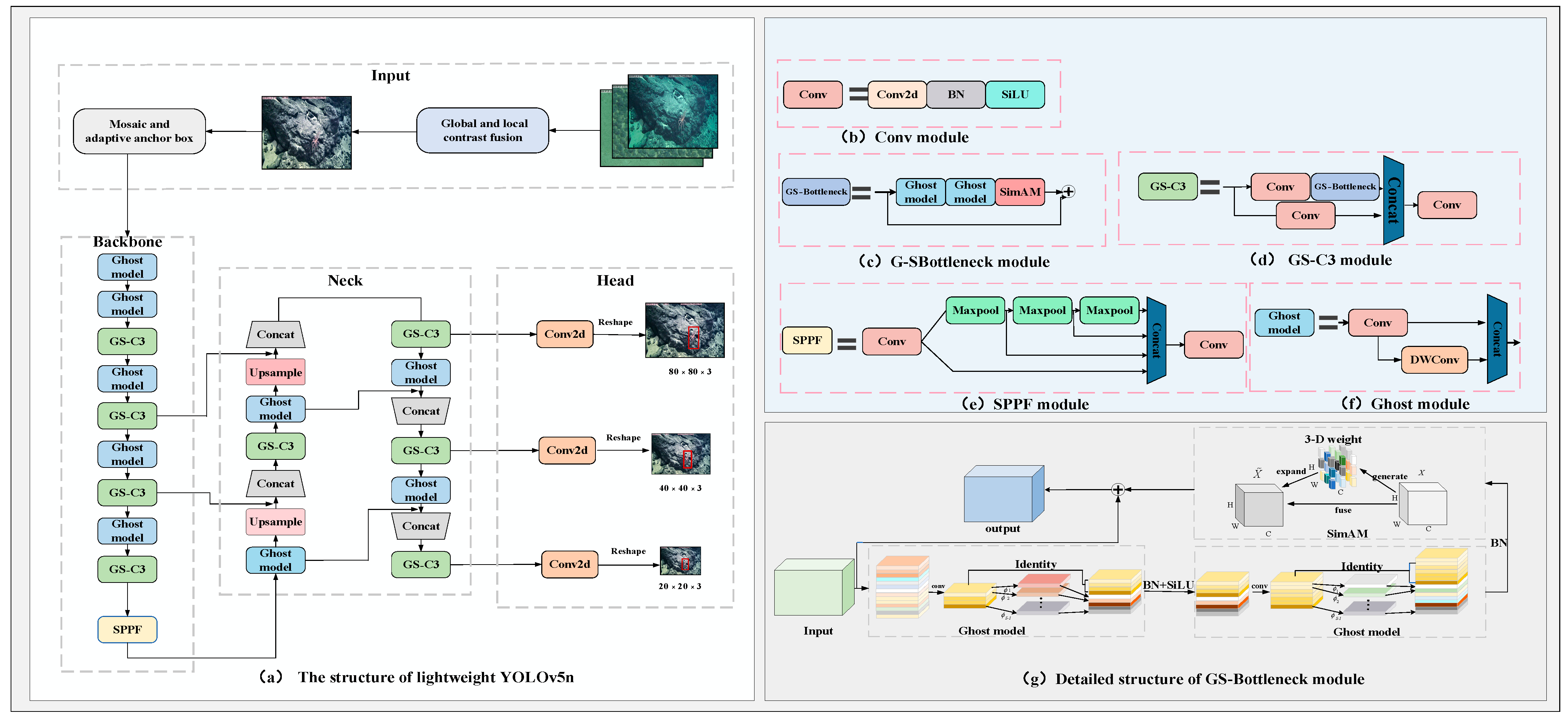
In order to decrease the complexity of the model and solve the impact of low-quality images on the model’s accuracy, a lightweight YOLOv5n model is designed based on the YOLOv5n model [12]. As shown in Figure 2, in the input layer of the model, the designed image enhancement method based on global and local contrast fusion is introduced to correct the image’s color, improve the image contrast, and facilitate the feature extraction of the model. In the backbone network and neck network of the model, the Bottleneck module is substituted with GS-Bottleneck, which is based on the Ghost module and simAM. This substitution significantly decreases the complexity of the model while possessing reliable detection performance. The GS-Bottleneck module substitutes the Bottleneck module in the original C3, leading to the creation of GS-C3. Finally, the Ghost module is used to replace the rest of the ordinary convolutions in the backbone network and the neck network.
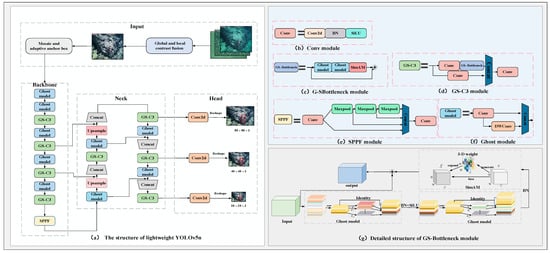
Figure 2.
Overall structure and basic modules of lightweight YOLOv5n.
2.2.2. Deep-Sea Biological Image Enhancement Method Based on Global and Local Contrast Fusion
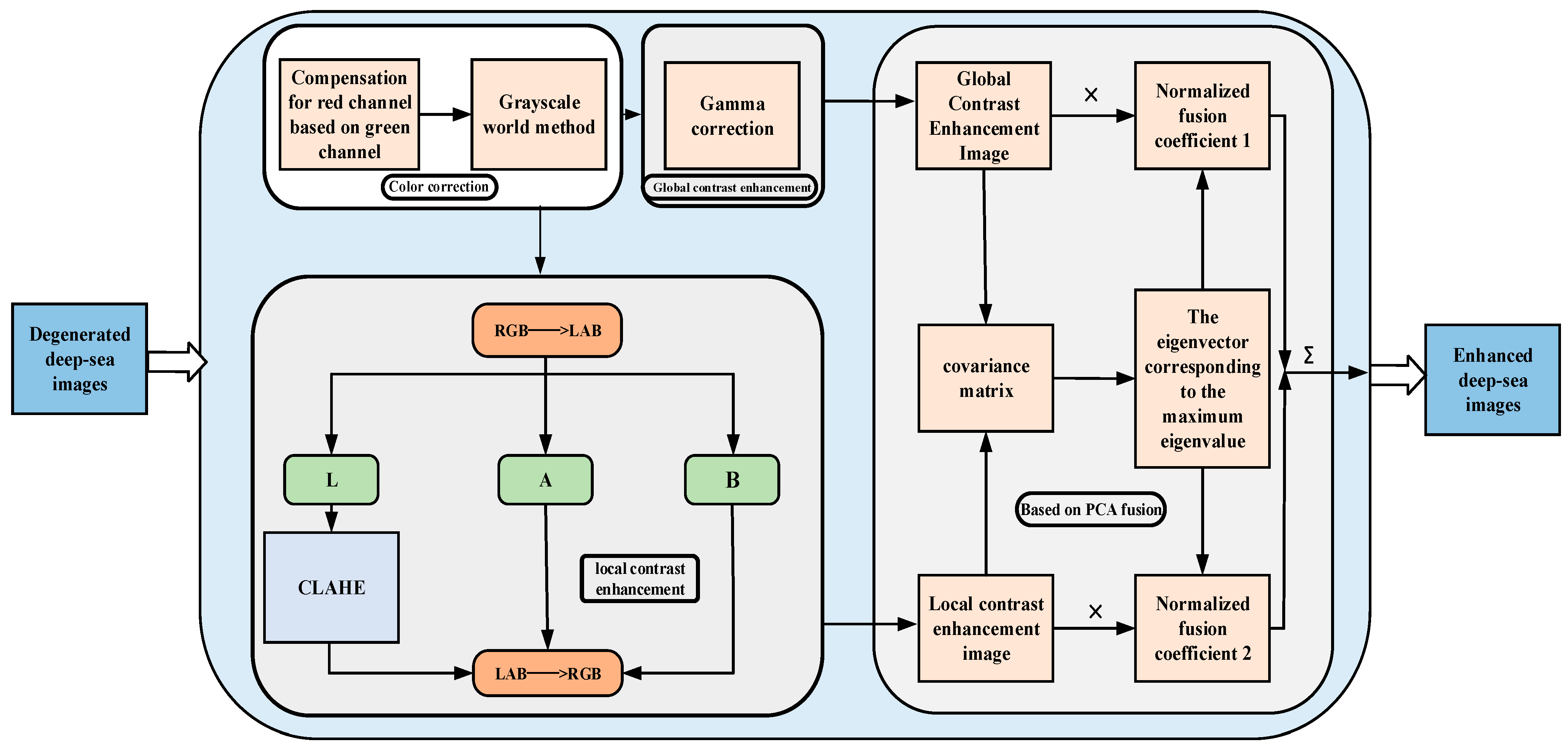
The natural light in the deep-sea environment has disappeared, and manned submersibles must use artificial light to take images of deep-sea organisms. In addition to the color shift problem, the main challenges of images under such imaging conditions are local overexposure, surrounding underexposure, and low contrast. Such degraded deep-sea images can affect the accuracy of object detection. Therefore, this section proposes a deep-sea biological image enhancement method based on global and local contrast fusion to solve the above problems. As shown in Figure 3, first, a grayscale world-based color correction method is designed, which pre-compensates the r-channel with the g-channel and removes the image’s color cast using the grayscale world method. Second, gamma correction is applied to the color-corrected image to obtain a globally contrast-enhanced version. At the same time, the color-corrected image is converted to LAB space, and CLAHE is applied to the L channel to obtain a locally contrast-enhanced version. Finally, to integrate the complementary advantages between the two versions, the PCA algorithm is used to fuse the two versions to obtain the enhanced images. The fusion strategy maintains the enhanced image’s advantages of global contrast, local contrast, and natural color. In addition, the algorithm has low complexity and fast computation speed to meet the real-time enhancement requirements.
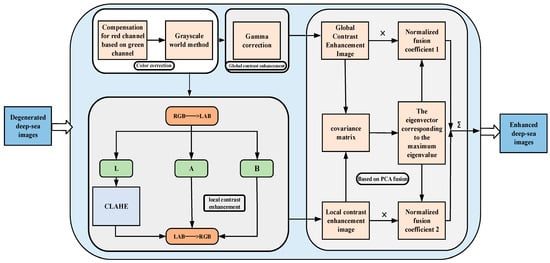
Figure 3.
Technology roadmap of deep-sea biological image enhancement method based on global and local contrast fusion.
When light propagates in seawater, the red color decays the fastest, resulting in a blue-green bias in the image. Moreover, it has been proven in the literature [13] that color domain shift causes the loss of model accuracy. This paper uses a color correction method based on the gray world to correct the color cast. Considering the particularity of the propagation and attenuation of visible light, the pixel mean of the red channel of the deep-sea image is relatively small, and the gray world assumes that the pixel mean of different channels in the scene should be equal. Therefore, when using the gray world method for color restoration, the red channel is excessively increased, resulting in color artifacts in the enhanced deep-sea image. To solve the problem, firstly, the red channel is pre-compensated through Equation (2):
where and are the red channel values after and before compensation, and are the mean values of the blue and red channels, respectively. is a constant parameter. After the red channel is compensated, the color cast of the image is corrected using the gray world method [14], which adjusts the color of each pixel by calculating the average gray value of the image (the average of all pixel values), so that the gray value of each pixel matches the average gray value of the whole image, so as to realize the equalization and naturalization of the image color. Then, gamma correction is applied to the color-corrected image to obtain a global contrast-enhanced image. Gamma correction performs a nonlinear transformation of the brightness value of the image through Equation (2) to adjust the overall contrast of the image.
where is the input image intensity and is the output image intensity. m and n represent pixel coordinates, while c represents the color channel index. γ and v are the parameters used to adjust the shape of the gamma function.
In order to better enhance the local detail features in the image, and considering that gamma correction has a good enhancement effect on underexposed images, the CLAHE algorithm has obvious advantages in overexposed image enhancement [15]. Hence, this paper uses CLAHE for local contrast enhancement of images. CLAHE [16] is an adaptive histogram equalization method that divides the image into small blocks and limits the number of pixels in each gray level to make the gray level distribution in each small block more uniform, and finally uses the interpolation method to obtain the contrast-enhanced image. Therefore, we transfer the color-corrected images from the RGB space to the LAB space and use the CLAHE method in the L channel to reduce the computational effort and avoid color distortion while improving the local contrast of the image.
The global and local contrast enhancement of the integrated enhanced image can highlight the details and texture features of the image while maintaining the overall contrast of the image. Therefore, an image fusion method based on PCA [17] is designed in this section, and the characteristics of PCA are used to efficiently fuse the two images to achieve complementary advantage features. The core of the method is that PCA can retain the main information in the original data, the covariance matrix of the data is obtained from the source image, and the eigenvector corresponding to the largest eigenvalue of the covariance matrix is used to determine the weighting coefficient in the image fusion algorithm. Finally, the fused image is obtained through the coefficient and the source image. The fusion method can quickly retain the information of both images to achieve complementary advantages. For two images, G1 and G2, each image is treated as an n-dimensional vector denoted by Po, o = 1, 2, and the image fusion process is as follows:
(1) Compute the covariance matrix W of Po:
where is the variance of the image.
(2) Compute the eigenvalues (K1, K2) and eigenvectors (ξ1, ξ2) of the covariance matrix W.
(3) Choose the large eigenvalue :
(4) Calculate the weight coefficient according to the eigenvector corresponding to the larger eigenvalue and obtain the fused image R:
2.2.3. GS-Bottleneck
To reduce the model complexity while maintaining a certain level of feature extraction ability, the Bottleneck module in YOLOv5n is improved by using the Ghost module and simAM. This modification resulted in the GS-Bottleneck, as shown in Figure 2g. In the GS-Bottleneck, the ordinary convolution module is substituted with the Ghost module. The Ghost module is known for reducing the number of parameters and calculations, effectively decreasing the model complexity. Although the Ghost module reduces model complexity, it may also result in a decrease in feature extraction ability compared to the original Bottleneck module. This trade-off is a consideration when using the Ghost module. Therefore, the simAM is concatenated after two Ghost modules to focus on important biological features so as to decrease the impact of model accuracy reduction caused by the Ghost modules to a certain extent without increasing the number of parameters.
The Ghost module [18] is a lightweight feature extraction module that makes full use of the redundant characteristics of feature maps generated by ordinary convolution to reduce the number of parameters and calculations. The essence is to decompose one convolutional multiplication into the sum of two convolutional multiplications, thus reducing the number of parameters. The Ghost module first obtains a small number of intrinsic feature maps using one 1 × 1 ordinary convolution. Secondly, cross-feature point feature extraction is performed using depthwise separable convolutions to generate the corresponding additional feature maps. Finally, the obtained two kinds are concatenated to obtain the output feature map. Assuming that the input feature map size is h1 × w1 × c, the output feature map size is h2 × w2 × n, the convolution kernel size is k × k, and the step size is s, the FLOPs of the conventional convolution are as follows:
The FLOPs of the Ghost module are:
The ratio of the two is:
The ratio of the two shows that the computational complexity of the Ghost module is only 1/s times that of conventional convolution. As a result, by replacing the conventional convolution with the Ghost module, we can achieve an equivalent number of feature maps while reducing the computational load and the number of parameters in the model.
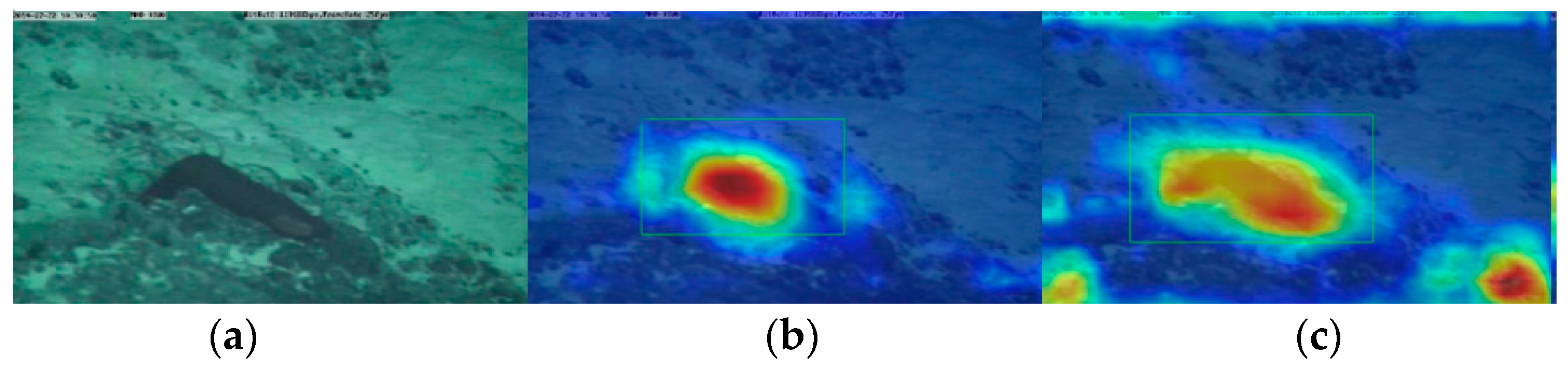
The simAM [19] derives three dimension values for the feature map based on brain theory. This allows the model to focus more on the deep feature spatial information of deep-sea organisms, considering the spatial and channel dimensions. Importantly, this attention mechanism achieves this without the need for additional parameters. Specifically, it is believed in neuroscience that neurons with more information have unique firing patterns and inhibit the activity of other neurons, so these neurons can be found by calculating the linear separability between a target neuron and other neurons. The activation heat map of the network was generated using the Grad-CAM [20] algorithm, as shown in Figure 4. The Grad-CAM algorithm can clearly show the area of concern of the network. The figure shows that the model pays more attention to deep-sea organisms after adding simAM. In short, simAM is a lightweight, simple, and effective module. After adding it to the two Ghost modules, it can help the model to screen important deep-sea biological features and make up for the lost accuracy caused by the Ghost module to some extent.

Figure 4.
Visualization of heatmap: (a) input; (b) heatmap before adding simAM; (c) heatmap after adding simAM.
2.3. Transfer Learning Strategy Combined with Knowledge Distillation
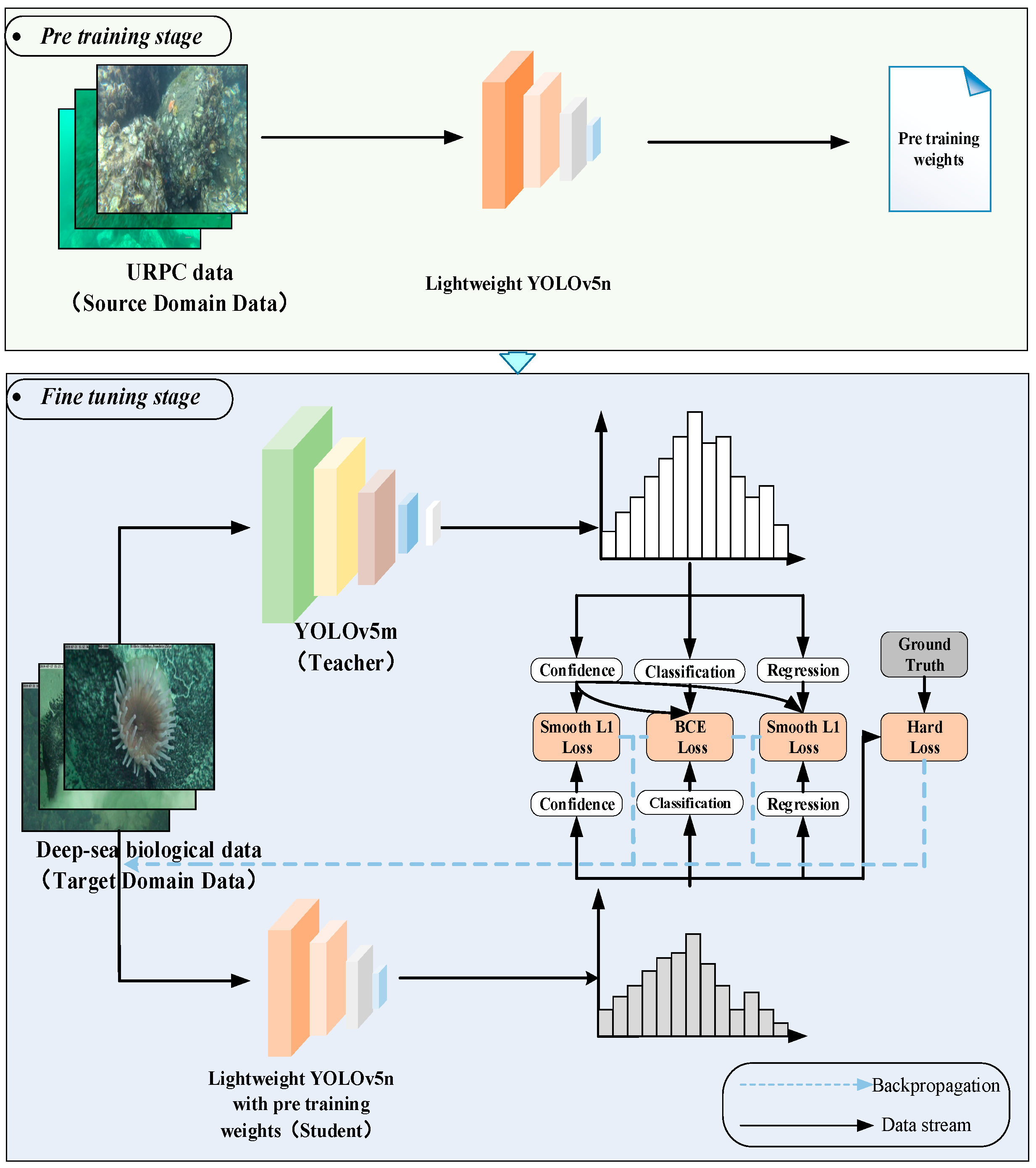
Deep-sea biological images need to be acquired using manned submersibles or other deep-sea detection equipment. Using this equipment is costly, so the number of deep-sea biological image samples obtained is limited. For the problem of small sample data leading to insufficient generalization ability and low detection accuracy of the model, this section proposes a transfer learning strategy combined with knowledge distillation. This method is based on the framework of transfer learning. As shown in Figure 5, during the pretraining stage, the lightweight YOLOv5n undergoes pretraining using the shallow-sea biological dataset (source domain dataset). This allows the model to learn similar characteristics between shallow-sea and deep-sea biological images. The pretraining weights obtained are then used as initialization parameters for the model in the subsequent fine-tuning stage, thereby improving its performance on the target domain dataset. During the fine-tuning stage, the deep-sea biological dataset (target domain dataset) and a designed knowledge distillation method are utilized to train the model with the pretraining weights. This further optimizes the model’s generalization performance for deep-sea biological detection tasks. YOLOv5n is the least complex version of YOLOv5, so we choose YOLOv5m as the teacher model. In addition, in order to reduce the risk of overfitting of the teacher model, we employ the training technique of early stopping when training the teacher model.
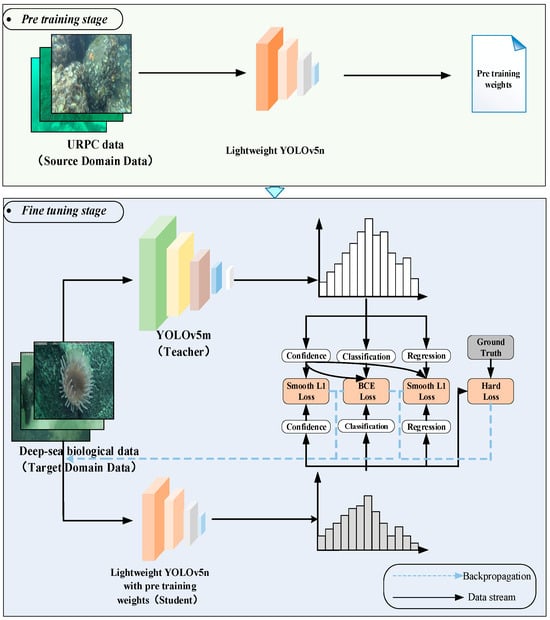
Figure 5.
Technology roadmap of transfer learning strategy combined with knowledge distillation.
Transfer learning helps to train a reliable decision function in the target domain by transferring auxiliary information source knowledge to solve the learning problem when the sample data in the target domain is unlabeled or has a small number of labeled samples. At the same time, transfer learning releases the restriction of traditional machine learning methods that training data and test data obey the same probability distribution and only require a specific similarity relationship between the source domain and the target domain [21]. In this paper, the URPC dataset is selected as the source data, the lightweight YOLOv5n is pretrained, and its pretrained model weights are retained as the initial weights of the model in the fine-tuning stage.
In order to further improve the generalization ability of the model and increase the detection accuracy of the model on the deep-sea biological dataset with insufficient data, knowledge distillation [22] is introduced into the fine-tuning stage of transfer learning. When retraining on the deep-sea biological image datasets (target domain), the teacher network is used to assist the lightweight YOLOv5n training. One fact is that more complex models often have strong generalization ability, so complex teacher models can achieve higher detection accuracy in deep-sea biological detection tasks. Knowledge distillation is an effective method to improve the model’s generalization ability. It can transfer the knowledge learned by the complex and good performance of the teacher network to the low complexity and poor performance of the student network so that the student network can obtain the accuracy and generalization ability close to the teacher network. In short, in knowledge distillation used in this paper, the knowledge from the teacher model serves as a form of regularization and guides the student model toward better generalization. The loss function of the student network in the object detection task is:
where , , and are the labeled bounding box coordinate value, labeled class probability value, and labeled confidence value, respectively. , , and are the bounding box coordinate values, class probability values, and confidence values predicted by the object detection model, respectively.
The knowledge distillation based on label knowledge [23] is a commonly used knowledge distillation method. In the process of using this distillation method, there is a problem in that the student network learns a large number of bounding box knowledge predicted by the teacher network in the background area, which affects the bounding box coordinate regression training of the student network. In response to this problem, inspired by the literature [24], this paper redesigns the loss function of the student network. The sigmoid function processes the confidence of the output of the teacher network. At this time, the little confidence tends to 0 after sigmoid function processing, and the student network learns less from the output of the teacher network. On the contrary, when the confidence of the deep-sea biological target predicted by the teacher network is high, the prediction results of the teacher network have a strong guiding effect on the student network. Then, the student network learns the bounding box coordinates and classification probabilities predicted by the teacher network. The confidence loss for the student network is as follows:
The bounding box regression loss for the student network is as follows:
where is the confidence of the teacher network prediction, is the bounding box coordinate value of the teacher network prediction, and are the mean squared error loss function, and is the equilibrium factor. The classification loss for the student network is as follows:
where is the class probability predicted by the teacher, is the cross-entropy loss function, and T is the temperature at the time of distillation. Combined with the above losses, the loss function for the student network can be expressed as follows:
3. Experiments
3.1. Dataset
3.1.1. Deep-Sea Biological Dataset
The dataset in this paper comes from video data taken by a Jiaolong manned submersible on the seabed, and the dataset is constructed according to the process shown in Figure 6. Firstly, key frame images from the video are intercepted, then the images are simply expanded using simple data augmentation such as flipping and rotating, and the images are labeled using the labeling tool to obtain 6144 images and the corresponding labels.
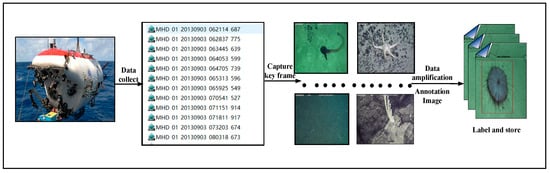
Figure 6.
Flow chart of dataset creation.
3.1.2. URPC Dataset
This paper selects the URPC dataset of the Killer Whale open-source project of Pengcheng Laboratory as the source domain dataset during transfer learning. The dataset is curated from the URPC dataset over the years and contains images of multiple scenes, including images taken using underwater robots and divers carrying cameras in shallow seas. The dataset contains a total of 8200 multi-scene images of five categories of underwater biological targets, including sea cucumbers, sea urchins, scallops, starfish, and water plants. Some of these images are shown in Figure 7.

Figure 7.
The URPC dataset: (a) water plants; (b) scallops; (c) sea cucumbers; (d) sea urchins; (e) starfish.
3.2. Experimental Environment and Parameter Configuration
The parameters of the experimental environment are shown in Table 1. The optimizer used is stochastic gradient descent, and the learning rate is dynamically adjusted using the cosine annealing algorithm. The batch size is 8 for 100 epochs. The images are all 640 × 640 pixels in size.

Table 1.
Experimental environment.
3.3. Performance Evaluation Metrics for Algorithms
This paper evaluates the lightweights of the model from two aspects: the number of parameters (Param) and the floating point operations (FLOPs), and assesses the detection accuracy of the model using mAP0.5 and mAP0.5:0.95. Furthermore, the algorithm’s detection speed is evaluated using frames per second (FPS). mAP0.5 represents the area under the precision–recall curve when the IOU threshold is set to 0.5. Similarly, mAP0.5:0.95 is the weighted average of the areas under the precision–recall curves when the IOU threshold is set from 0.5 to 0.95 with a step size of 0.05. The calculation formulas for precision and recall are as follows:
where TP is true positive, FP is false positive, and FN is false negative.
Precision = TP/(TP + FP)
Recall = TP/(TP + FN)
3.4. Experimental Results and Analysis
3.4.1. Experimental Results Obtained with Lightweight YOLOv5n
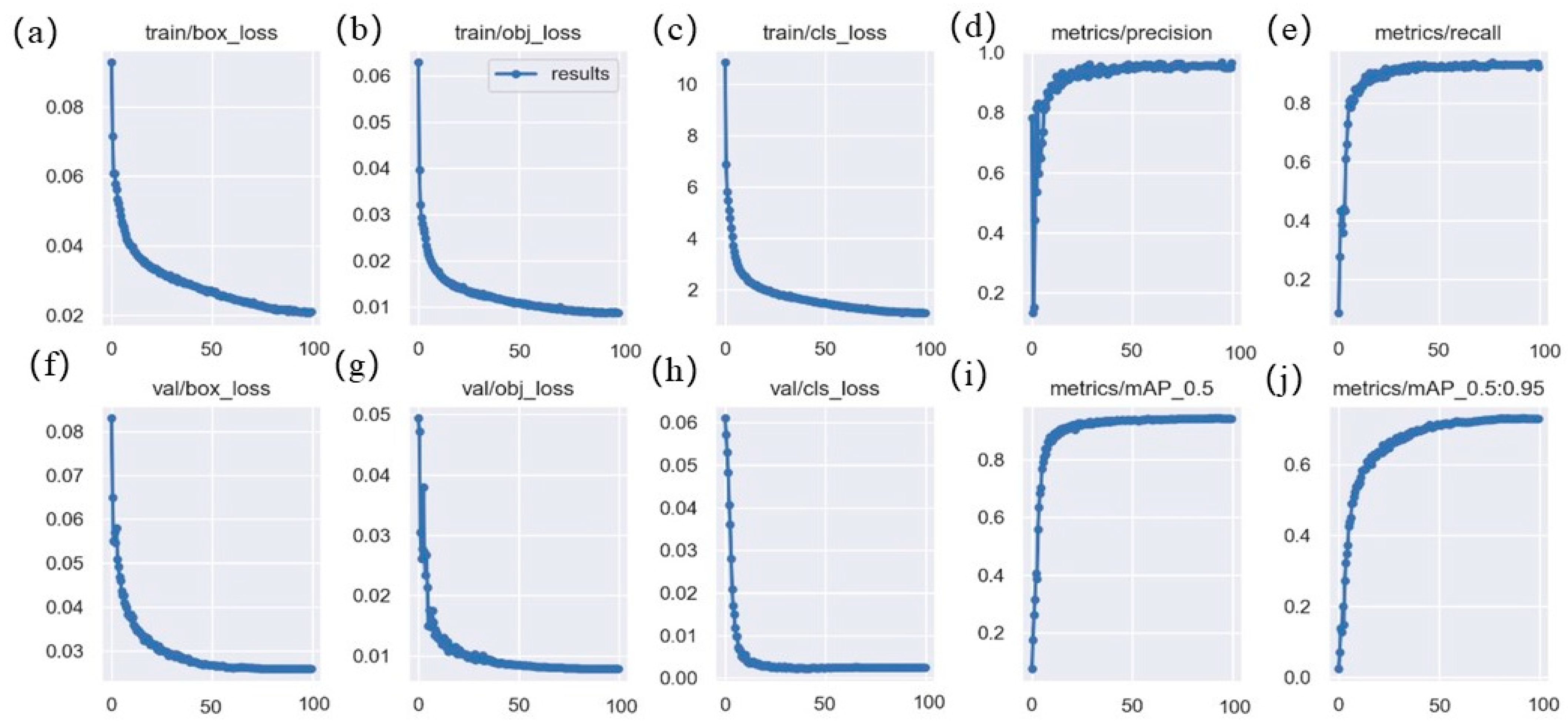
The loss of the proposed model on the training dataset, the loss on the validation set, and the change of precision, recall, and mAP are shown in Figure 8, where a, b, and c represent the change curves of the bounding box regression loss, confidence loss, and class loss of the model, and f, g, and h are the change curves of the loss on the corresponding validation set, respectively. From these curves, we can see that as the amount of training increases, the various losses of the model also decrease. This shows that the proposed model has a good fitting effect and high stability, where d, e, i, j are the change curves of various accuracy evaluation indexes of the model on the validation set, and it can be seen from these curves that the detection accuracy of the model increases with the increase of training times. In conclusion, the proposed model has strong fitting ability, good stability, and high accuracy for deep-sea biological detection tasks.
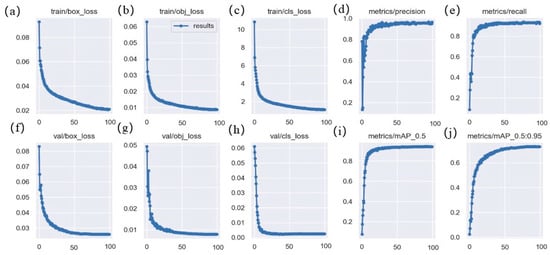
Figure 8.
Loss curves of the proposed model on deep-sea biological datasets: (a) bounding box regression loss on the training set; (b) confidence loss on the training set; (c) classification loss on the training set; (d) precision on the validation set; (e) recall on the validation set; (f) bounding box regression loss on the validation set; (g)confidence loss on the validation set; (h) classification loss on the validation set; (i) mAP0.5 on the validation set; (j) mAP0.5:0.95 on the validation set.
3.4.2. Comparison Experiments with Other Algorithms
To validate the detection performance of the proposed model, we compare the proposed model with the current popular object detection models on the deep-sea biological dataset.
The comparative experimental results are shown in Table 2. Specifically, mAP0.5 and mAP0.5:0.95 are only slightly lower than YOLOv3 but far superior to YOLOv3 in terms of detection speed and model complexity. In terms of the number of parameters and the amount of computation, the number of parameters is 0.9 M, and the amount of computation is 2.0 GFLOPs, which is the lowest among all models. In terms of FPS, this method is only lower than the fastest YOLOv5n, which can also achieve real-time detection. In addition, we also choose YOLOv8s algorithm, which performs better on public datasets, for comparative experiments. However, from the algorithm performance evaluation metrics shown in Table 2, it can be seen that the YOLOv5-based algorithm has a better balance between performance and accuracy compared with version 8s on the deep-sea biological detection task. This also justifies our choice of YOLOv5n as the base version to implement deep-sea biological detection. In summary, compared with the current popular target detection models, the proposed model has better detection accuracy and lightweight characteristics and achieves a better balance between detection accuracy and lightweight. It is more suitable for exploration missions in deep-sea environments.
Table 2.
Comparative experimental results of different algorithms.
3.4.3. Ablation Experiments
This section verifies the effectiveness of each submodule and method in deep-sea biological detection tasks. As seen in Table 3, the mAP0.5 and mAP0.5:0.95 of the original model on the deep-sea biological dataset are 93.6% and 72.9%, and the amount of calculation and parameter is 4.2 GFLOPS and 1.8 M. After introducing GS-Bottleneck into the model, the model’s parameters and computational quantities are reduced by about 50% and 52%. But the detection accuracy is reduced by 0.8% and 1.5% for mAP0.5 and mAP0.5:0.95. This indicates that the Ghost module and the simAM can guarantee a sure detection accuracy of the model while significantly reducing the model complexity. After introducing image enhancement methods based on global and local contrast fusion, the mAP0.5 and mAP0.5:0.95 are improved by 1% and 3.3%. Aiming at the serious color cast and low contrast of deep-sea images, two sets of contrast experiments were carried out. The visual inspection results of Model 1 and Model 2 are shown in Figure 9, where Model 2 is based on Model 1 with the image enhancement method we designed. The visual inspection results and the results in Table 3 show that the enhancement method can better correct the color of the image, improve the contrast of the image, increase the confidence of the model detection, reduce the occurrence of missed detection, and then improve the detection accuracy of the model for the degraded image. In brief, the designed image enhancement method can enhance image contrast, correct image color, and improve detection performance. After incorporating the transfer learning combined with knowledge distillation, the model shows a noticeable enhancement in performance. Specifically, it achieves a 1% increase in mAP0.5 and a 2% improvement in mAP0.5:0.95. This indicates that the strategy can be useful in helping the model to learn similar characteristics to those of deep-sea organisms in shallow-sea organisms and improve the generalization ability through knowledge transfer of the teacher model, which in turn reduces the dependence of the model on the amount of data and improves the detection accuracy of the model.
Table 3.
Results of ablation experiments.

Figure 9.
Visualization of detection results: (a) labels; (b) detection results of Model 2; (c) detection results of Model 3.
Finally, visualizing the detection of the modified model and the unmodified model on the deep-sea biological dataset is shown in Figure 10, where it can be seen that the unmodified model has false detections before the detection of deep-sea organisms. In contrast, the modified model has no false detections. At the same time, the confidence of the improved model in detecting each deep-sea organism is relatively improved. The experimental results demonstrate that each submethod and module proposed in this paper is effective, and the proposed model has higher detection accuracy and lower model complexity than the original model.

Figure 10.
Visualization of detection results: (a) labels; (b) detection results of YOLOv5n; (c) detection results of the proposed method.
4. Conclusions
In the real deep-sea environment, aiming at the problem of low detection accuracy caused by poor image quality and insufficient sample size and the problem of high model complexity, we proposed a lightweight YOLOv5n for deep-sea biological detection. The image enhancement method based on local and global contrast fusion can achieve color correction and contrast enhancement for poor-quality deep-sea biological images so as to improve detection accuracy. The GS-Bottleneck module can enable a lightweight model and ensure detection accuracy. Through the transfer learning strategy combined with knowledge distillation, similar characteristics of shallow-sea organisms are transferred to the model, and the generalization ability of the model is further improved by using the knowledge distillation, which can alleviate the impact of insufficient data volume on the detection accuracy. Experimental results demonstrate that our proposed method achieves a notable improvement of 1.2% in mAP0.5 and 3.8% in mAP0.5:0.9. Remarkably, this is accomplished with a minimal number of parameters (0.9 M) and computational volume (2.0 GFLOPs), making it highly suitable for deployment in deep-sea detection devices for high-precision real-time detection in complex deep-sea imaging environments.
Our method achieved good detection results, but there is still a drawback. Although the inference speed of the model can meet the requirements of real-time detection, it decreased compared with the preimprovement, due to the use of image enhancement methods. Therefore, in future work, we will improve the model to have a faster inference speed. In addition, there is still room for improvement in the fusion part of our image enhancement method, so this method will be further improved in the future to further improve the accuracy of the model for the classification and localization of deep-sea organisms.
Author Contributions
Writing—original draft, C.L.; Writing—review and editing, D.L. and G.Y.; Supervision, Z.D. All authors have read and agreed to the published version of the manuscript.
Funding
This work was financially supported by Key projects funded by the National Key Research and Development Plan of China (no. 2017YFC0306600), Key Research and Development Program of Shandong Province of China (no. 2020JMRH0101), National Key Research and Development Project of China (no. 2021YFC2802100).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Informed consent was obtained from all subjects involved in this study.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this paper:
| YOLOv5n | You Only Look Once Version 5n |
| YOLOv5m | You Only Look Once Version 5m |
| CLAHE | Contrast-limited adaptive histogram equalization |
| PCA | Principal component analysis |
| R-CNN | Region-based convolutional neural networks |
| Fast R-CNN | Fast region-based convolutional neural networks |
| MSRCR | Multi-scale retinex with color restoration |
| simAM | Simple, parameter-free attention module |
| URPC | Underwater Robot Photography Competition |
| mAP | Mean average precision |
| IoU | Intersection over union |
References
- Zhang, Y. Application and prospect of environmental simulation technology and in-situ test technology in the study of deep-sea biology. Prospect. Sci. Technol. 2022, 1, 134–144. [Google Scholar]
- Ding, Z.; Feng, Z.; Li, H.; Meng, D.; Zhang, Y.; Li, D. Experimental Study of Deep Submersible Structure Defect Monitoring Based on Flexible Interdigital Transducer Surface Acoustic Wave Technology. Sensors 2023, 23, 1184. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Li, C.; Zhang, Y. Research on underwater target detection method based on traditional machine learning. In Proceedings of the 2015 International Conference on Electrical and Information Technologies (ICEIT), Nanjing, China, 19–20 June 2015. [Google Scholar]
- Chen, J.; Zhao, Z.; Liu, C. Research on underwater target detection algorithm based on traditional machine learning. IEEE Access 2017, 5, 22084–22094. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Wu, W.; Yin, Y.; Wang, X.; Xu, D. Face detection with different scales based on faster R-CNN. IEEE Trans. Cybern. 2018, 49, 4017–4028. [Google Scholar] [CrossRef] [PubMed]
- Tan, H.Q.; Li, Y.X.; Zhu, M.; Deng, Y.X.; Tong, M.H. Overlap fish tail detection using image enhancement and improved Faster-RCNN network. Trans. Chin. Soc. Agric. Eng. 2022, 38, 167–176. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Hao, K.; Wang, K.; Zhao, L.; Wang, B.B.; Wang, C.Q. Underwater biodetection algorithm based on image enhancement and improved YOLOv3. J. Jilin Univ. Eng. Technol. Ed. 2022, 52, 1088–1097. [Google Scholar]
- Wageeh, Y.; Mohamed, H.E.D.; Fadl, A.; Anas, O.; ElMasry, N.; Nabil, A.; Atia, A. YOLO fish detection with Euclidean tracking in fish farms. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 5–12. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, X.S.; Sun, Y.M.; Liu, S.D. Underwater target detection algorithm based on channel attention and feature fusion. J. Northwestern Polytech. Univ. 2022, 40, 433–441. [Google Scholar] [CrossRef]
- Jocher, G. YOLOv5 by Ultralytics. Available online: https://github.com/ultralytics/yolov5 (accessed on 10 August 2023).
- Chen, X.; Lu, Y.; Wu, Z.; Yu, J.; Wen, L. Reveal of domain effect: How visual restoration contributes to object detection in aquatic scenes. arXiv 2020, arXiv:2003.01913. [Google Scholar]
- Ancuti, C.O.; Ancuti, C.; De Vleeschouwer, C. Colorbalance and fusion for underwater image enhancement. IEEE Trans. Image Process. 2018, 27, 379–393. [Google Scholar] [CrossRef]
- Kou, H.; Su, Y.; Li, H.; Deng, Y.; Chen, G. Gamma Transform and CLAHE Fusion-Based Method for Pantograph Monitoring Under Illumination Variations. Laser J. 2022, 133, 83–87. [Google Scholar]
- Yuan, Z.; Zeng, J.; Wei, Z. CLAHE-Based Low-Light Image Enhancement for Robust Object Detection in Overhead Power Transmission System. IEEE Trans. Power Deliv. 2023, 38, 2–8. [Google Scholar] [CrossRef]
- Kurita, T. Principal component analysis (PCA). In Computer Vision: A Reference Guide; Springer: Berlin/Heidelberg, Germany, 2019; pp. 1–4. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Yang, L.; Zhang, R.Y.; Li, L.; Xie, X. Simam: A simple, parameter-free attention module for convolutional neural networks. In Proceedings of the 38th International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Zhou, K.; Jiang, M. Research progress and prospect of small sample target recognition based on transfer learning. Aeronaut. Sci. Technol. 2023, 34, 1–9. [Google Scholar]
- Chen, Z.; Zhang, L.; Cao, Z.; Guo, J. Distilling the knowledge from handcrafted features for human activity recognition. IEEE Trans. Ind. Inform. 2018, 14, 4334–4342. [Google Scholar] [CrossRef]
- Shao, R.R.; Liu, Y.A.; Zhang, W.; Wang, J. Review of knowledge distillation in deep learning. J. Comput. 2022, 45, 1638–1673. [Google Scholar]
- Mehta, R.; Ozturk, C. Object detection at 200 frames per second. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).