Abstract
GPS-based maneuvering target localization and tracking is a crucial aspect of autonomous driving and is widely used in navigation, transportation, autonomous vehicles, and other fields.The classical tracking approach employs a Kalman filter with precise system parameters to estimate the state. However, it is difficult to model their uncertainty because of the complex motion of maneuvering targets and the unknown sensor characteristics. Furthermore, GPS data often involve unknown color noise, making it challenging to obtain accurate system parameters, which can degrade the performance of the classical methods. To address these issues, we present a state estimation method based on the Kalman filter that does not require predefined parameters but instead uses attention learning. We use a transformer encoder with a long short-term memory (LSTM) network to extract dynamic characteristics, and estimate the system model parameters online using the expectation maximization (EM) algorithm, based on the output of the attention learning module. Finally, the Kalman filter computes the dynamic state estimates using the parameters of the learned system, dynamics, and measurement characteristics. Based on GPS simulation data and the Geolife Beijing vehicle GPS trajectory dataset, the experimental results demonstrated that our method outperformed classical and pure model-free network estimation approaches in estimation accuracy, providing an effective solution for practical maneuvering-target tracking applications.
1. Introduction
GPS tracking is a crucial field in autonomous driving and machine learning applications, such as motion robotics [1,2], computer vision [3,4], motion training [5,6], autonomous driving [7,8], and so on. GPS tracking uses state-of-the-art estimation methods to estimate the actual trajectory from measurements. The Kalman filter (KF) [9], a popular state estimation method, is a recursive filter designed to estimate the state and signal of a system from noisy, limited, and incomplete measurements. It has several advantages, such as accurately estimating the system’s state and signal in the presence of incomplete measurements and uncertainty. Additionally, the Kalman filter is computationally efficient, easy to implement, and widely used in various systems, such as navigation, communication, control, signal processing, and machine learning.
Although the Kalman filter is effective in many situations, it has some limitations. The Kalman filter assumes that the noise follows a Gaussian distribution and relies on model parameters. In practical autonomous driving applications, especially at levels four and five, there are various challenging environments that can affect GPS data accuracy. These environments include areas with high buildings, dense trees, long tunnels, multilayer junctions, underpasses, and bridges. Additionally, severe weather conditions such as snow, wet roads, old roads, grassy areas, foggy weather, and roads that have been shoveled can further impact the accuracy of GPS data. In these situations, the GPS data often experience different types of noise, including colored noise and outliers. Obtaining accurate statistical characteristics for these noise types can be difficult, and this in turn affects the accuracy of the filters used to process the GPS data.
As for the nonlinear estimation problem, researchers have proposed a series of nonlinear Kalman filters, such as the extended Kalman filter [10] (EKF), the unscented Kalman filter [11] (UKF), etc. The EKF calculates a Jacobi matrix to linearize nonlinear system models using first-order Taylor expansion. Therefore, it is only appropriate for low nonlinearity. The UKF obtains nonlinear equations by performing an unscented transformation on sampling points, approximating the probability density function of nonlinear states. The UKF’s estimation accuracy can be within the second order and it has performed better than the EKF. However, similarly to the EKF, the UKF must transfer the state covariance matrix, where mathematical operations can cause the covariance matrix to lose its positive definiteness and symmetry, leading to filter failure.To address the limitations of the EKF and UKF, a particle filter [12], also known as the Monte Carlo filter, was introduced. The particle filter is a non-parametric approach that uses a set of particles to approximate the posterior distribution of the state variables.
Therefore, researchers have proposed various improved filters such as model-free, particle filter, wavelet transform, Gaussian mixture model, adaptive filtering, etc. The different filters have pros and cons that must be considered and adjusted based on the specific application requirements. Model-free filters and particle filters [13] are two popular improved filters. The former method does not require an a priori model and can adaptively estimate the statistical characteristics of noise, showing better robustness. For example, based on the expectation maximization (EM) algorithm [14], Shumway and Stoffer proposed an algorithm for estimating Kalman filter parameters using the EM algorithm [15]. Another EM algorithm proposed combines the Kalman filter for linear dynamic system state estimation and the EM algorithm for parameter estimation [16]. The latter, through simulation and approximating the posterior probability distribution through sampling, can handle nonlinear and non-Gaussian problems and is more flexible and robust. Although model-free and particle filters can improve the robustness and resilience, they have issues with accuracy and computational efficiency.
In addition, wavelet transform filters, Gaussian mixture model filters, and adaptive filters are also widely used. The wavelet transform filter [17] is primarily suitable for static signal processing and has limitations for signals with a non-stationary behavior. The Gaussian mixture model filter [18] requires the specification of prior and mixture model counts, and its computational complexity is high. The adaptive filter [19] does not require the establishment of an accurate model, but it still requires some prior knowledge or empirical parameters. Therefore, it is necessary to select a filter method based on the specific application needs and to perform a comprehensive analysis and optimization to improve the performance of these algorithms. In summary, despite their unique benefits, these filters have shortcomings regarding their adaptability, computational complexities, and modeling assumptions.
The above filters are based on model parameters. This means they must use prior knowledge to guarantee filtering performance, as they do not fully utilize the measurement data. As previously mentioned, severe environments and weather in autonomous driving will complicate the statistical characteristics of GPS data, and this system model information will be included in the measurement data. Using measurement big data in filtering algorithms is becoming increasingly crucial and practical, and this can capture complex patterns and relationships among hidden variables, providing high-dimensional information for data modeling. Additionally, it can train machine learning models, such as artificial neural networks, capable of learning highly nonlinear and complex relationships. By leveraging big data and modern machine learning techniques, more efficient filtering algorithms can be developed, to handle the complexity and diversity of real-world data streams. Hence, it is crucial to study the use of big data for feature extraction and develop improved filtering methods, to increase accuracy and efficiency.
Leveraging the vast amount of sensor-collected big data can greatly enhance our understanding of synthesized signals and facilitate the identification of environmental noise [20]. This underscores the significance of utilizing such datasets for feature extraction. By harnessing these extensive and intricate datasets, it becomes possible to develop various filters or enhance the effectiveness and performance of the existing ones. Since these datasets are typically large-scale and intricate, leveraging advanced machine learning techniques like neural networks becomes crucial for improving filtering performance. These powerful algorithms enable the analysis and processing of sensor-collected big data, leading to the extraction of more accurate features, such as periodicity, high-frequency components, and mixed noise. The combination of sensor-collected big data and modern machine learning techniques can thus drive the advancement of filtering algorithms, enabling them to effectively handle the diversity and complexity of real-world scenarios.
Researchers have started investigating network-based estimation methods based on the views mentioned above. In recent years, deep learning networks have been widely used in trajectory tracking, utilizing their powerful modeling capabilities and ability to extract potential features from the data. Recurrent neural networks (RNNs) [21] are commonly used for analyzing time-series data, as they are able to capture the dependencies between data points. The long short-term memory (LSTM) network, a variant of the RNN network, was introduced by Hochreiter et al. (1997) [22]. LSTMs employ a complex architecture, incorporating a hidden state unit to determine the importance of input data. This additional layer enhances the network’s ability to capture long-term dependencies by preventing the vanishing gradient problem frequently encountered in regular RNNs. To effectively overcome the issue of gradient explosion, LSTMs employ distinct activation functions and calculation methods, such as the use of gates (e.g., input gates, forget gates, and output gates), which regulate the flow of information through the network, enabling it to model complex, long-term sequences with greater accuracy. LSTMs have become increasingly popular in various fields, such as natural language processing, speech recognition, and image recognition.
Chang-hao Chenet al. [23] proposed IONet, to investigate motion estimation using IMUs based on the Bi-LSTM model, which has a more accurate tracking effect than traditional pedestrian dead reckoning (PDR). The extended nine-axis IONet proposed by Won-Yeol Kim et al. [24] improves trajectory tracking using both gravitational acceleration and geomagnetic data from the IMU. By reducing the data based on the original six-axis IONet input, the estimation accuracy of the position change is improved. Rui-peng Gao et al. [25] proposed a method to track a vehicle in real-time using a temporal convolutional network (TCN), to obtain historical data from the IMU in a mobile phone, when a GPS signal is unavailable.
Deep learning methods have a good learning capability, but in the era of big data, neural networks often need a large amount of input information [26]. This information usually contains a lot of useless or less valuable data, making it difficult for the neural network to learn, reducing the learning efficiency of deep learning methods, and potentially falling into overfitting, which remains a challenge for complex target tracking problems. Recently, the attention mechanism [27] has been used to solve this problem. The attention mechanism can be seen as a simulation of human attention; that is, humans can pay attention to valuable information, while ignoring useless information. A new attention mechanism architecture, a transformer based on the self-attention Seq2seq [28] model, has demonstrated powerful capabilities in sequential data processing, such as natural language processing [29], audio processing [30], and even computer vision [31]. Unlike a RNN, transformer allows the model to access any part of history without considering the distance, making it more suitable for mastering repeated patterns with long-term dependencies and for preventing overfitting. Currently, applying this framework to model tracking has attracted extensive attention from researchers.
Based on the aforementioned disadvantages, traditional estimation methods are usually based on statistical principles, with relatively low computational requirements and a lower requirement for an accurate number of samples. However, conventional estimation methods may not be able to account for nonlinear relationships among multiple variables. On the other hand, deep learning methods can handle large-scale datasets using techniques such as neural networks and can discover more complex patterns and extract critical features. Moreover, deep learning models can adaptively learn relationship patterns in a dataset, reducing the risk of dependence on human rules and prior knowledge. Therefore, combining deep learning with traditional estimation methods can find a balance between model interpretability and high accuracy, thereby improving model performance and robustness, making this more suitable for practical problems.
However, the existing methods rely on predefined parameters and have difficulty with complex nonlinear models. This article intends to use neural networks to learn parameters and address the limitations of traditional methods. To better estimate the trajectory of maneuvering targets, this paper proposes a new tracking method, to solve the problems faced in practice by estimation methods: learning measurement data using a mechanism containing transformer multi-headed self-attention and LSTM, to obtain the statistical properties of its complex motion; at the same time, based on the output of the network, the EM method is used to estimate the dynamics and measurement characteristics of moving targets, and real-time system parameter modeling is carried out in the estimation, to provide more accurate model parameters for the Kalman filter. After learning, the EM algorithm can obtain more real-time and accurate system parameters and improve the trajectory tracking estimation accuracy.
The remainder of this paper is structured as follows: In Section 2, we provide a comprehensive description of the proposed model, which includes a detailed explanation of the network model structure, the mathematical background of the EM algorithm, the Kalman filter, and the overall model framework. Specifically, we present the design of different components, including the input layer, hidden layer, and output layer, as well as the training process for the network. Additionally, we delve into the EM algorithm, which is used to estimate the parameters of the deep learning model, and the Kalman filter, which is applied to smooth the hidden states of a dynamic system. In Section 3, we present the dataset used in the experiment, describe the experimental environment, detail the contents and evaluation metrics of the experiment, and finally analyze the results. Specifically, we describe the characteristics, size, sources of the dataset, and experimental setup, including the software, hardware, and preprocessing steps. In Section 4, we provide the conclusions of the paper and future directions for research.
2. Parameter-Free State Estimation
Generally, the linear system model is as follows:
where is the state, are the measurement data, A is the State transform matrix, Q is the state noise, is the state noise covariance, C is the measurement matrix formula, R is the measurement noise, is the measurement noise covariance, and are the mean and covariance of the initial state, respectively. Usually, the above parameters can be modeled based on historical knowledge or system mechanisms. (The use of linear models can reduce the model complexity, simplify algorithm derivation and calculation, and make problems easier to model and solve, which is beneficial for explaining the principles of the algorithm.)
The Kalman filter is the optimal autoregressive data processing algorithm, and the Kalman filtering process is as follows:
and,
In the above equation, K is the Kalman filter gain. It is clear from the above equation that the Kalman filtering algorithm consists of two steps. Equation (2) is the estimation process, where the estimates are estimated from the previous one obtained. Equation (3) is the update process, the estimation is based on the filtering gain of the update.
The classic Kalman filter method relies on accurate model parameters, which can be challenging to obtain in practical applications. Additionally, the simplified linear model used in the Kalman filter may have a significant discrepancy from the actual nonlinear model, due to the inherent nonlinear characteristics of real-world systems. This discrepancy becomes evident in the measurement data collected from the system.
In this paper, we address this issue by incorporating measured data to complement the linear ideal model mentioned in Equation (1). Specifically, we utilize a deep neural network to train the relationship between the measured data and the reference state offline. This approach allows us to capture the nonlinearities present in the system model and bridge the gap between the simplified linear model and the actual system. The overall system model and the integration of the deep neural network are illustrated in Figure 1.

Figure 1.
System Model Learner.
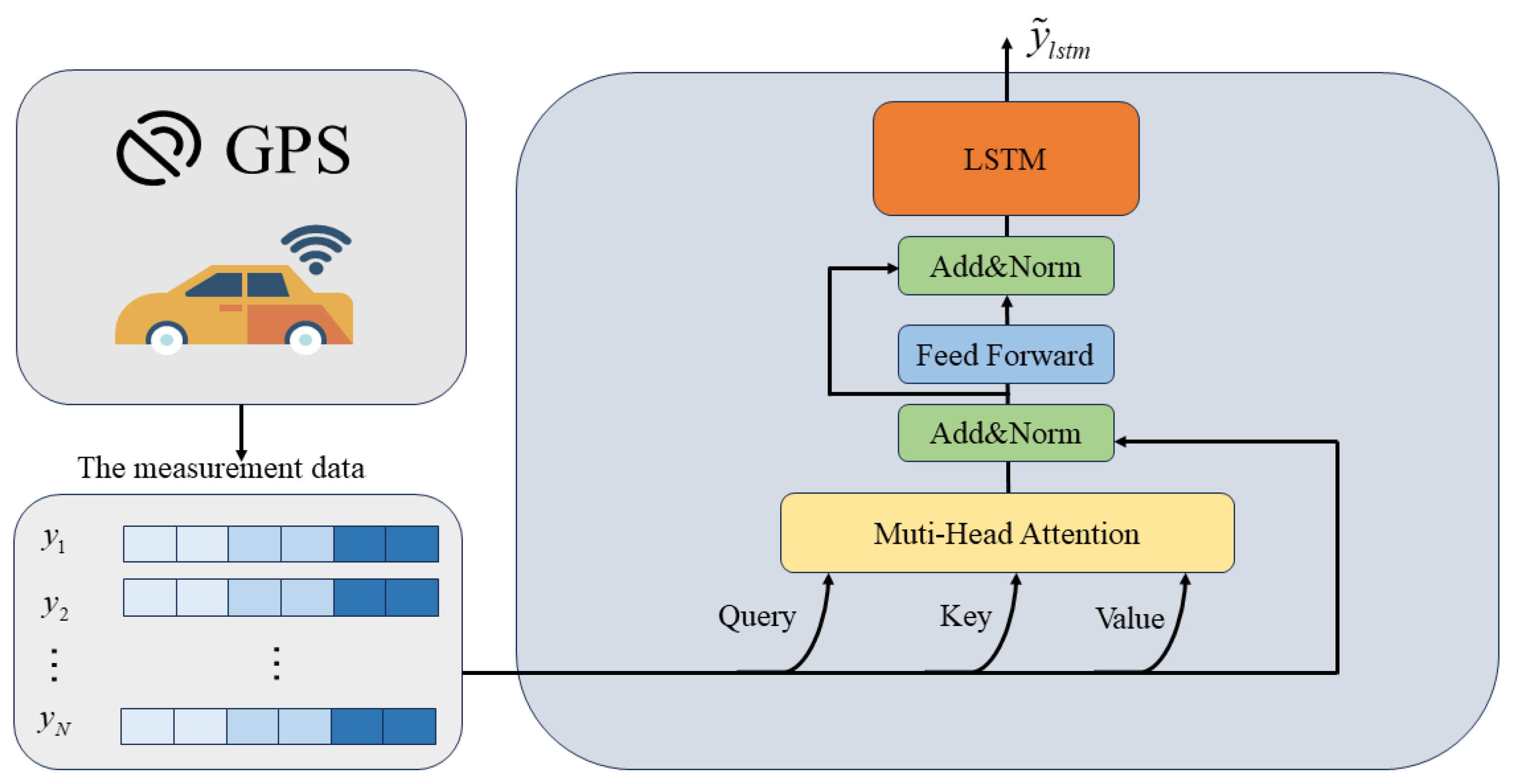
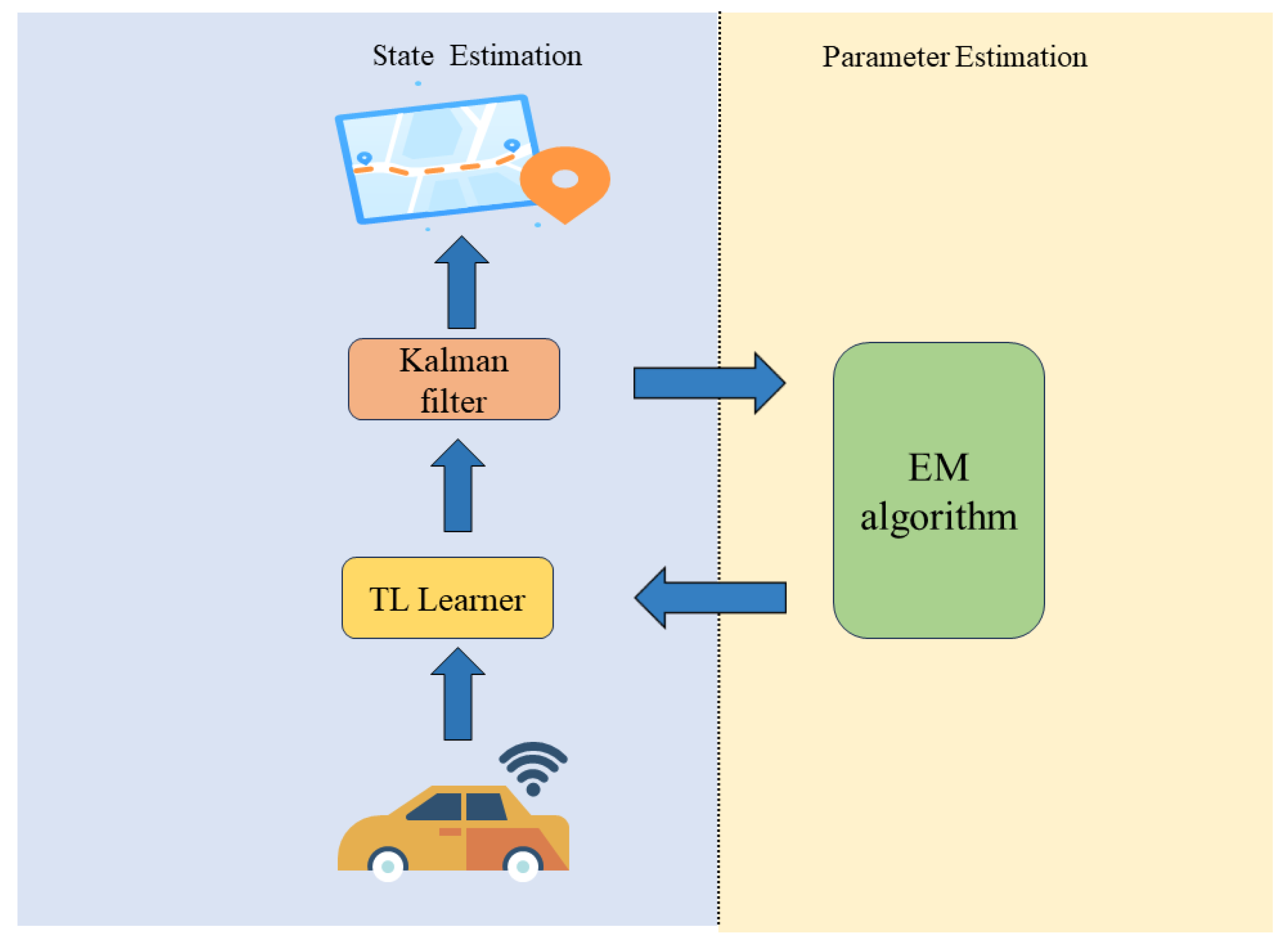
The proposed model structure in this paper consists of two steps: (1) Offline training: The offline training involves training a system model learner based on LSTM with attention, using the system’s initial parameters (Figure 2). By combining the encoding attention structure of a transformer and LSTM, the model learns from observation data without modeling system dynamics and measurement characteristics, capturing the motion characteristics of the system through neural network training. (2) Online estimation: During estimation, measurement data are input into the attention LSTM learning module to obtain accurate dynamic characteristics, the online part employs the EM algorithm to update the model parameters in real-time. Kalman filtering is then used for online recursive estimation (Figure 3).

Figure 2.
Offline training system learner based on attention and LSTM.

Figure 3.
Online Kalman filtering based on EM.
2.1. Offline Training System Learner
The transformer’s ability to capture long-term dependencies is due to its integration of multi-head self-attention and residual connections, which enhances the model’s training depth and reduces the risk of overfitting. The combination of LSTM and a transformer encoder enhances the structural advantages and sequence modeling ability of the transformer encoder (shown as Figure 2). This model can leverage the known information of the system’s mechanistic model and also obtain the complex dependency relationship of the system from historical measurement data through training the network model.
Multi-headed self-attention [28] generates multiple attentions in the network, acting on features separately and in parallel, with the input to the module being the observed data , the attention task-related query vector represented as , and information such as the input features represented as key-value pairs, and , respectively. , , and are obtained by linearly varying the input measurements . The process of attentional action can be represented as follows:
where , , and are trainable parameter projection matrices and is the feature dimension of . According to the input and , the data can be used to obtain the dot product, the weights corresponding to the elements of the input data can then be obtained from the function. is used to scale the dot product, to prevent the obtained dot product from being too large, which is conducive to rapid learning.
The essence of the multi-headed self-attendance mechanism is a linear transformation after stitching together the results of multiple attention calculations. This mechanism allows the model to use different feature information obtained at different locations, thus increasing the diversity of features. The multi-headed self-attention is calculated as shown below.
where t is the total number of heads, is the weight matrix for ensuring that the target dimension is met, is the splicing operation of the vector, and denotes the features of the i header.
In this paper, a transformer encoder structure is used to encode and learn the underlying dynamical properties of the observed data, using the multi-headed attention mechanism to construct higher dimensional, multi-channel attentional information and uncover rich information. The attention-based learning module feeds the observed data into the transformer encoder module, which encodes the location of the observed data and feeds the encoded data into the multi-headed self-attentive layer. To prevent network degradation and accelerate convergence, the encoder is also structured with residual connections, layer-norm layers, and feed-forward neural networks. We output potential coding features through the transformer encoder module.
After the transformer, we use the LSTM to learn longer dependencies between the measurement data.
where indicates the hidden state at the previous moment.
The system model learner (as shown in Figure 2) achieves the learning of system dynamics through offline training. The input–output pairs for learning are the observed data and the reference state of the system. The transformer encoder structure with multi-head self-attention and LSTM networks are utilized to learn the latent features of the data. This approach eliminates the need for modeling system dynamics and measurement characteristics. First, the transformer encoder learns the long-term dependencies of the observed data through a self-attention mechanism. Then, the LSTM network further enhances the modeling ability of the sequence data. The combination of the two can effectively extract the features required for parameter estimation. The goal of this deep neural network is to learn the dynamic characteristics of the system, and its output will be input into the EM algorithm as observation data.
2.2. Online Kalman Filtering Based on EM Algorithm
The EM algorithm uses the observation data output from deep neural networks to estimate parameters such as the state transition matrix, observation matrix, and noise covariance matrix required for Kalman filter.
After offline training, the network model still deviates from the actual system. During the estimation process, the online estimation part uses the EM algorithm to update the model parameters in real time. Specifically, the measurement data are input into the trained attention LSTM learning module, to obtain accurate dynamic characteristics data that characterize the motion sequence. Then, online recursive estimation is performed through Kalman filtering. Furthermore, the EM algorithm is used to update the current state-transition matrix, measurement matrix, state noise, measurement noise variance, and other parameters (as shown in Figure 3).
The left side of Figure 3 shows the EM algorithm, according to Jenson’s inequality, we have
where is the hidden variable, is the unknown parameter to be estimated, and denotes the parameter at the nth iteration. The PDFs of the latent variables are
Substituting (13) into (12), we obtain
It can be seen that the latter term of the above equation is not relevant to and can be omitted. For state estimation, maximization of the measurement of the PDF is equivalent to maximization of the log likelihood of .
The EM algorithm starts with an initial estimate and then iterates over the E and M steps of Algorithm 1.
| Algorithm 1 EM algorithm |
|
Let the state to be estimated for the system be and the measured value be , with the probability distribution of
Therefore, by extending the probability distribution function in Equation (14) to an exponential function, we obtain
where u and v are the dimensions of the state transfer matrix and measurement matrix, respectively.
Under the assumptions of the Markov property of states and the conditional independence of measurements, the current state is only related to the previous state, and the current observation is only related to the current state.Based on the above assumptions, the joint probability distribution can be obtained:
Therefore,
Combining (21) and (15), substitute the probability density function of the hidden variable into Jensen’s inequality, and note that the parameter independent term in the density function can be omitted. We can obtain the expected form of the parameter:
Based on the maximum value theory, calculate the partial derivative of (22) and obtain the parameters:
Utilizing the offline training system learner mentioned in Section 2.2, we can capture the long-term dependence between data and the potential correlations between data, which can better estimate the parameters of the filter model. Based on the linear least squares method, the observations and state estimators output by the neural network are constructed into a linear regression model, and the state transition matrix A and observation matrix C are obtained by solving the covariance matrix of the estimators, then there are
where denotes the estimate of the filter at step k.
Then, based on , statistical modeling based on the error of state estimators and calculating the covariance matrix of state noise Q, construct a statistical model of observation noise using the covariance matrix of residuals and obtain the covariance matrix of observation noise R:
Using recursive output states through Kalman filtering, the estimated trajectory is obtained. When using Kalman filter, A is the state-transition matrix calculated using (24), Q is the state noise covariance calculated using (26), C is the measurement matrix formula (25), and R is the measurement noise covariance calculated using Formula (27).
3. Experiment
3.1. Experiment Set-Up
To construct the network models, we utilized the Pytorch deep learning framework as an open-source library. All experiments described in this paper were conducted on a personal computer with an Intel Core i5-7300HQ @2.50 GHz CPU processor and 8 GB RAM. In our experiment, we used an LSTM model with 64 hidden vectors and a self attention network with 8 heads as encoders, while training the model through the Adam algorithm.The neural network model was initialized with default parameters in Pytorch, which included weight initialization for deterministic deep learning networks. Furthermore, the random number seed was fixed on the computer for all experiments, to ensure result reproducibility.
To comprehensively evaluate the forecasting performance of the different models, this study employed four evaluation metrics. These metrics were the root mean square error (RMSE), mean absolute error (MAE), symmetric mean absolute percentage error (SMAPE), mean square error (MSE), and Pearson correlation coefficient (P). The formulas for these four evaluation metrics are shown in Equations (28)–(32).
where n is the total number of samples in the dataset, is the k-th true value of the reference trajectory, is the mean of the true values of the reference trajectory, is the k-th estimate of the estimated trajectory obtained by the model, and is the average of the estimated trajectories obtained by the model. The first three of the four evaluation indicators mean that the smaller the resulting value, the more accurate the model estimation. The significance of the evaluation indicator R is that the larger the result value, the better the fit of the reference trajectory to the estimated trajectory.
3.2. Results and Discussion
(1) Case 1: In this case, the trajectory path dataset utilized for simulation was obtained from the work of btbuIntelliSense (https://github.com/btbuIntelliSense, accessed on 20 October 2023). A total of 4200 trajectory paths were provided, each consisting of 201 data points. Each data point included the horizontal and vertical coordinate values of longitude and latitude, which were used to simulate the real movement path. The simulated data spanned a two-dimensional plane ranging from 0 to 100, with the addition of pink noise signals. The noise was generated utilizing a MATLAB signal processing toolbox function known as “ColoredNoise”. In order to evaluate the improvement in filter performance using parameter self-learning modules, the selected were compared with various traditional Kalman filter models, including the Kalman filter along with the process models CA [32], CV [33], Singer [34], current statistical [35], and EM Kalman filter [16]. At the same time, we also compared the combination methods of neural networks and filtering models, including the experimental results of transformer-EF and LSTM-EF, which will be of great benefit to our research, as shown in Table 1.

Table 1.
Evaluation of the different filter estimation results for the simulation trajectory dataset.
We conducted a comprehensive comparison of the trajectory tracking performance of the different filter models, and the results are presented in Table 2. The proposed model exhibited the lowest error evaluation metric values compared to the other models, reflected by the highest p-value, RMSE, MAE, SMAPE, MSE, and p values of 1.71, 1.35, 4.36, 2.92, and 0.99, respectively.
Compared with the other five filter models, our proposed model had the advantage of not requiring complex manual parameter adjustment processes. This adjustment process typically requires extensive domain knowledge and is difficult to optimize. Compared with the other two neural network combined filter models, our proposed model effectively improved the estimation accuracy. In comparison to the other seven models, our model achieved a reduction in RMSE estimation accuracy of 20.5%, 34.5%, 30.4%, 70.2%, 72.1%, 29.3%, and 10.9%, respectively. The MAE was also reduced by 10.0%, 11.7%, 10.6%, 59.8%, 61.9%, 19.1%, and 3.6%, respectively. Furthermore, the MSE was reduced by 36.7%, 57.1%, 51.7%, 91.9%, 92.2%, 50.1%, and 20.8%, respectively. Additionally, our model resulted in an increase in SMAPE by 27.1%, 33.6%, 30.6%, 68.3%, 57.5%, 6.6%, and 3.3%, respectively.The proposed model’s largest p value from the index signifies an excellent estimation accuracy, indicating the strongest correspondence between the estimated and true values.
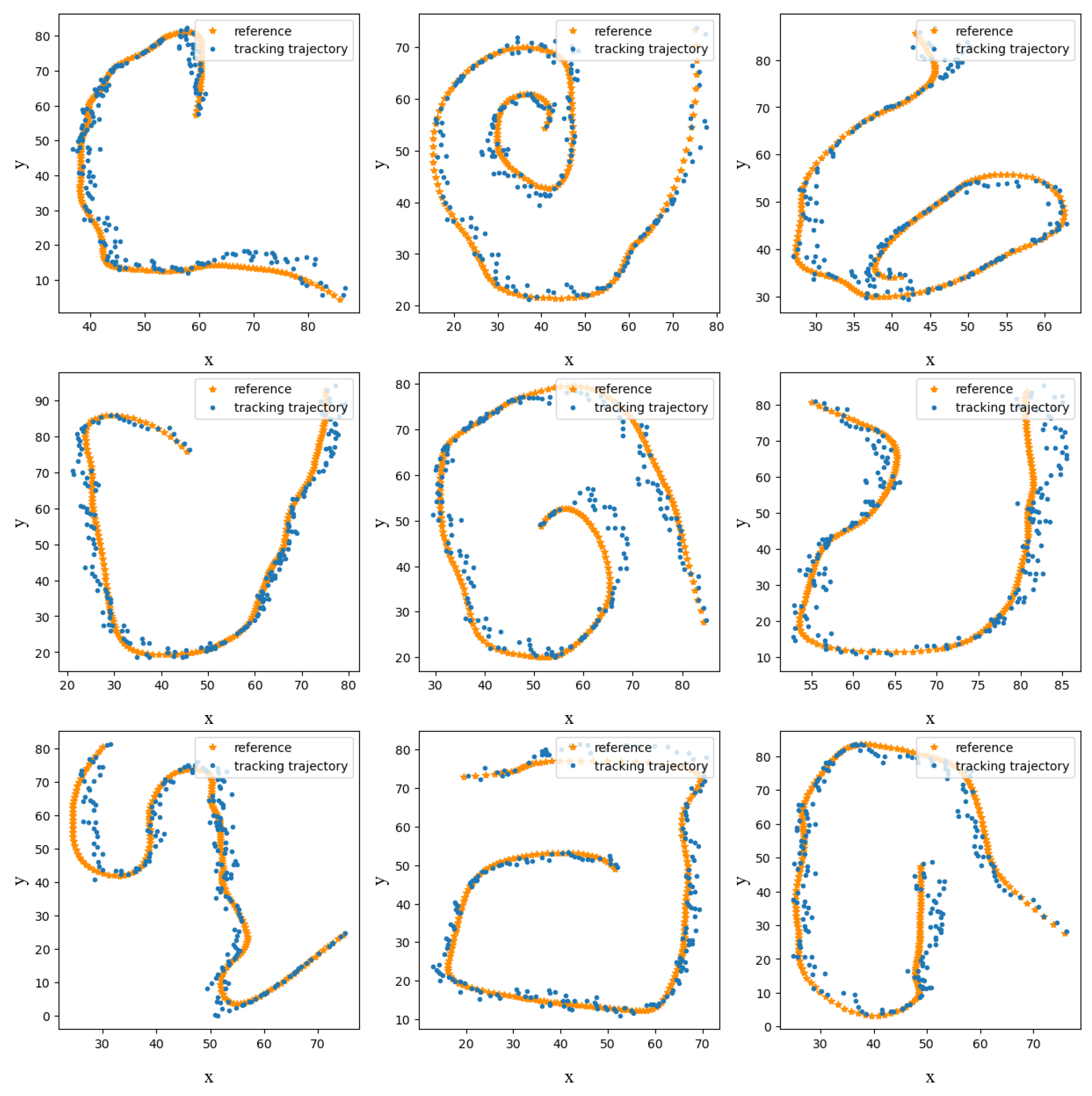
Our proposed model was found to have the best fit between the estimated values and true values, as indicated by the P-index. The experimental data analysis confirmed that our model outperformed the other filter models in terms of the estimation accuracy and result fit. Specifically, we evaluated the effectiveness of integrating neural networks with filtering models and found that this combination enhanced the performance of our proposed model by refining the estimated parameters of the EM algorithm. This successful combination of neural networks with filter algorithms demonstrated the applicability of our model in the field of trajectory tracking, compared to the traditional methods (Figure 4 and Figure 5).

Figure 4.
Examples of tracking results.
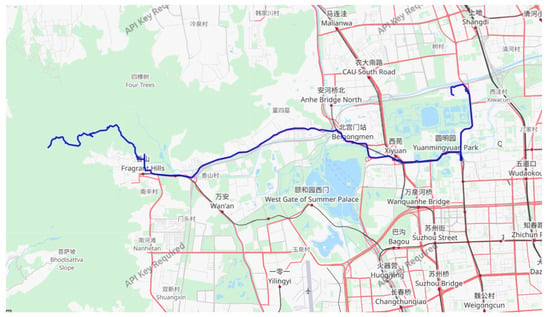
Figure 5.
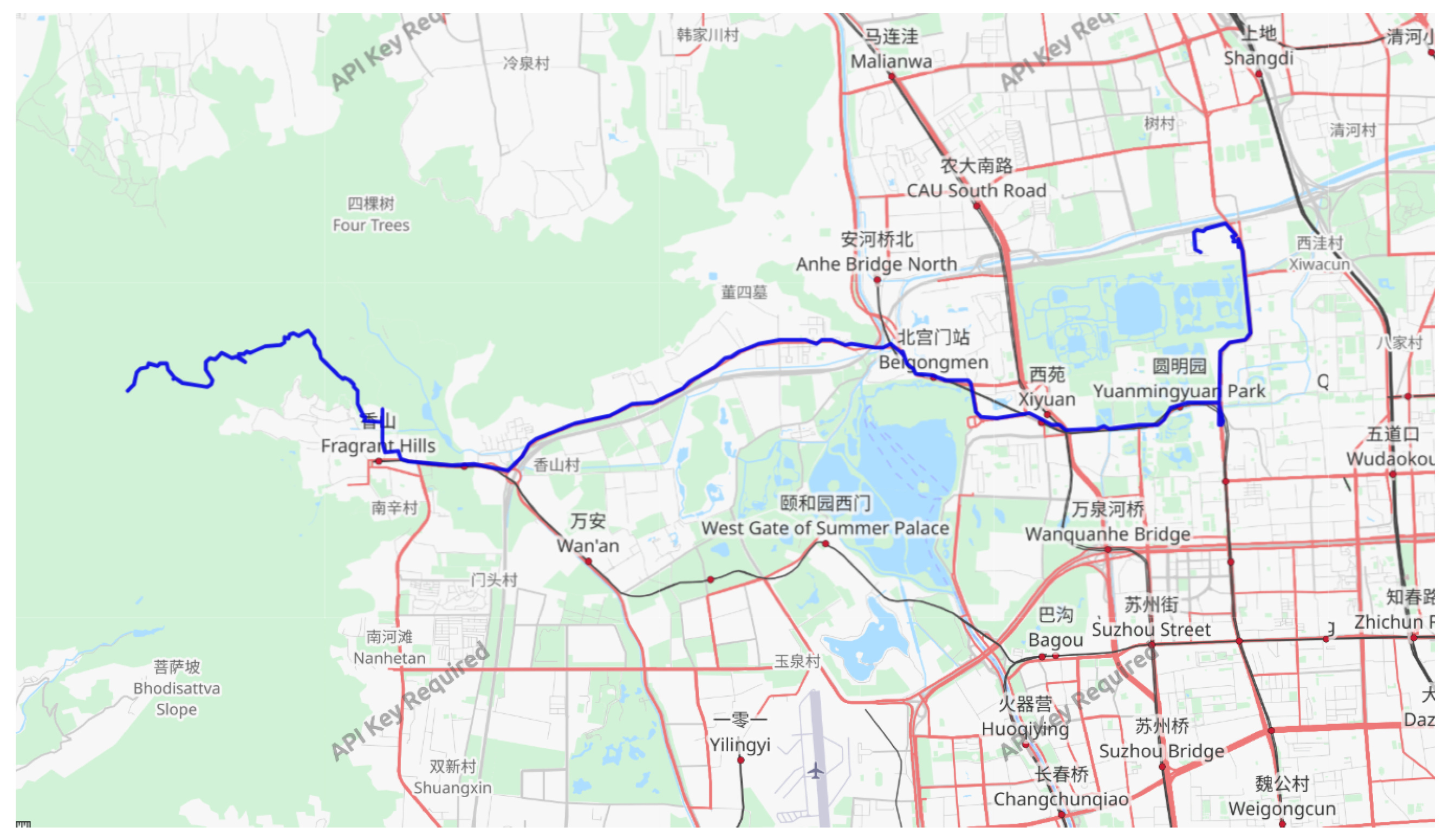
An example of the Geolife Beijing vehicle GPS motion track dataset.
(2) Case 2: For this case, we utilized the Geolife Beijing vehicle GPS trajectory dataset (https://www.gpsvisualizer.com/, accessed on 20 October 2023), which consists of 13,987 GPS coordinates, where the GPS coordinates are composed of longitude and latitude values. Among these, 80% were chosen as the training set for the model, while the remaining 20% were used as the test set. Figure 6 showcases an example trajectory from this dataset.

Figure 6.
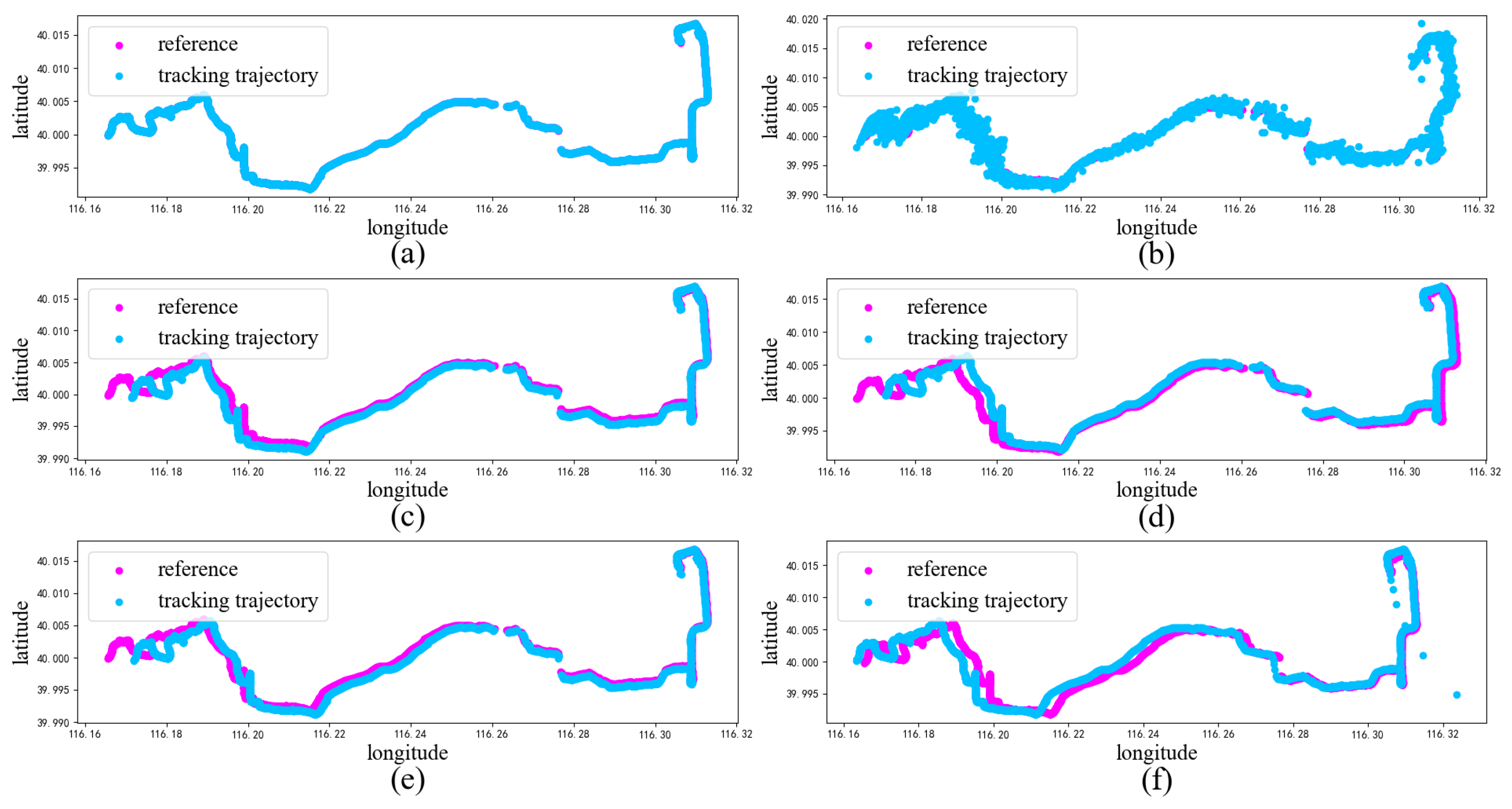
Comparison of the tracking results for GPS trajectories: (a) trajectory estimated using the proposed method, (b) trajectory estimated using PFVAE, (c) trajectory estimated using LSTM, (d) trajectory estimated using GRU, (e) trajectory estimated using CNN-LSTM, (f) trajectory estimated using ConvLSTM.
Considering the complexity of actual scenarios, we chose some of the latest literature methods for end-to-end deep learning, to comprehensively compare the advantages of our method.
We applied the proposed model to the Beijing vehicle trajectory dataset. Given the intricacy of real-life situations, we meticulously selected a few state-of-the-art end-to-end deep learning modules. Our goal was to holistically evaluate the merits of our approach through comparative experiments, which involved five other models, namely LSTM [22], GRU [36], CNN-LSTM [37], ConvLSTM [38], and PFVAE [39]. For each of these comparison models, we set specific parameters. As an example, for the GRU model, we used 50 hidden neural units, a learning rate of 0.0001, 1000 iterations, and a batch size of 30. The GRU model consisted of two network layers, each containing 50 hidden units. In terms of the sliding window strategy, we applied the same recursive estimation approach as the filter model. The predicted results of all six models utilized in the experiment are presented in Table 2.
Table 2.
Evaluation of the different filter estimation results for Beijing vehicle GPS motion track data.
Table 2.
Evaluation of the different filter estimation results for Beijing vehicle GPS motion track data.
| Model | RMSE | MAE | SMAPE | MSE | P |
|---|---|---|---|---|---|
| LSTM [22] | 3.84 | 3.97 | 3.75 | 14.75 | 0.99 |
| GRU [36] | 6.83 | 5.52 | 4.29 | 46.64 | 0.99 |
| CNN-LSTM [37] | 5.92 | 4.47 | 3.87 | 35.04 | 0.99 |
| ConvLSTM [36] | 5.76 | 4.69 | 3.15 | 33.17 | 0.99 |
| PFVAE [39] | 2.52 | 1.97 | 1.90 | 6.35 | 0.99 |
| The proposed method | 1.82 | 1.32 | 0.97 | 3.31 | 0.99 |
As shown in Table 2, our proposed TL-EF model showed significant performance improvements compared to the LSTM, GRU, CNN-LSTM, ConvLSTM, and PFVAE models. Specifically, the TL-EF model achieved 52.6%, 73.8%, 69.2%, 68.4%, and 27.7% reductions in RMSE, and 66.7%, 76.1%, 70.5%, 71.8%, and 32.9% reductions in MAE, respectively, when compared to these models. Furthermore, the MSE was reduced by 77.6%, 92.9%, 90.6%, 90.0%, and 47.8%, respectively. The improvement rates for SMAPE were 74.1%, 77.3%, 74.9%, 69.2%, and 48.9%, respectively. Additionally, the TL-EF model obtained P indicators that were comparable to those of the LSTM, GRU, CNN-LSTM, ConvLSTM, and PFVAE models.
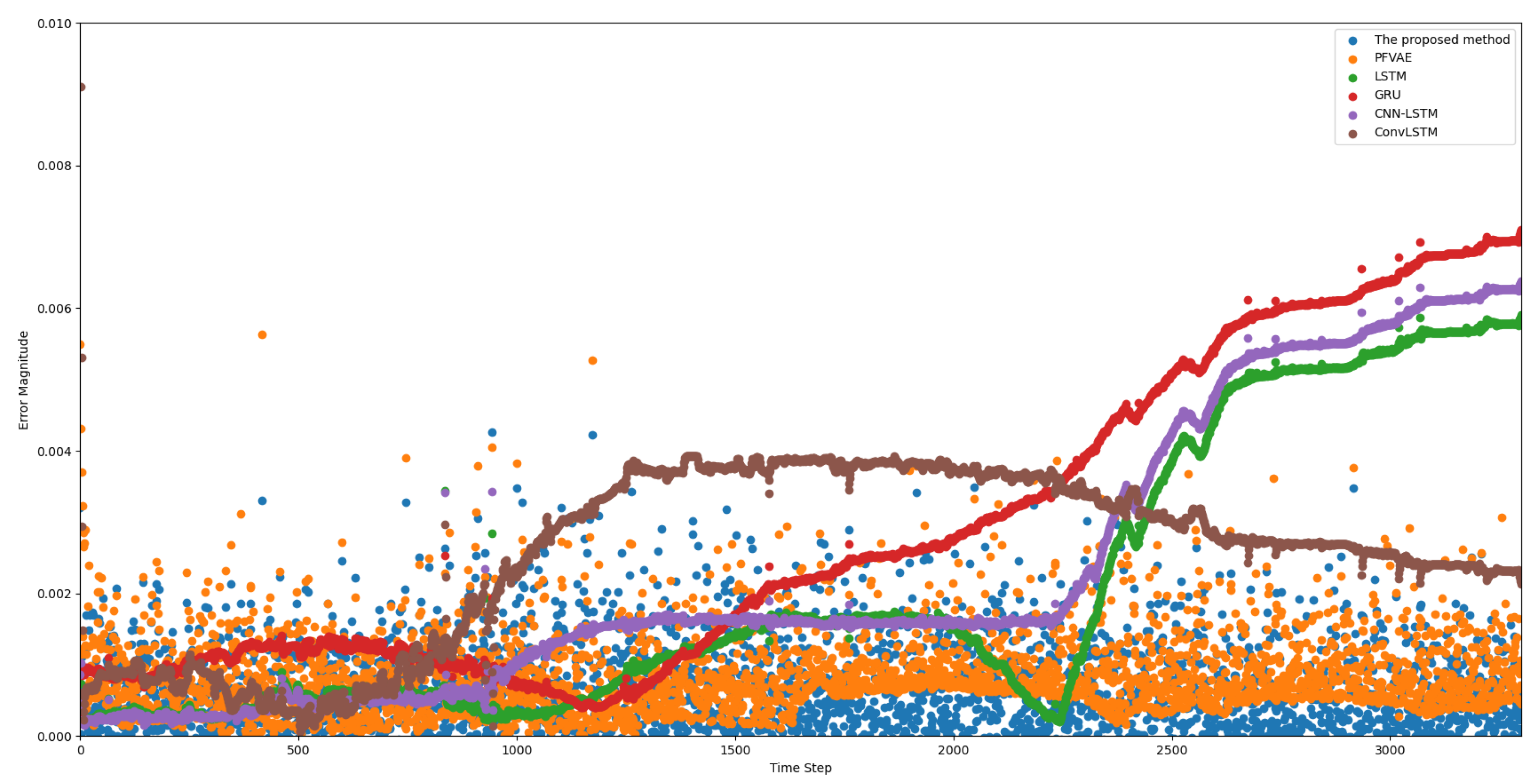
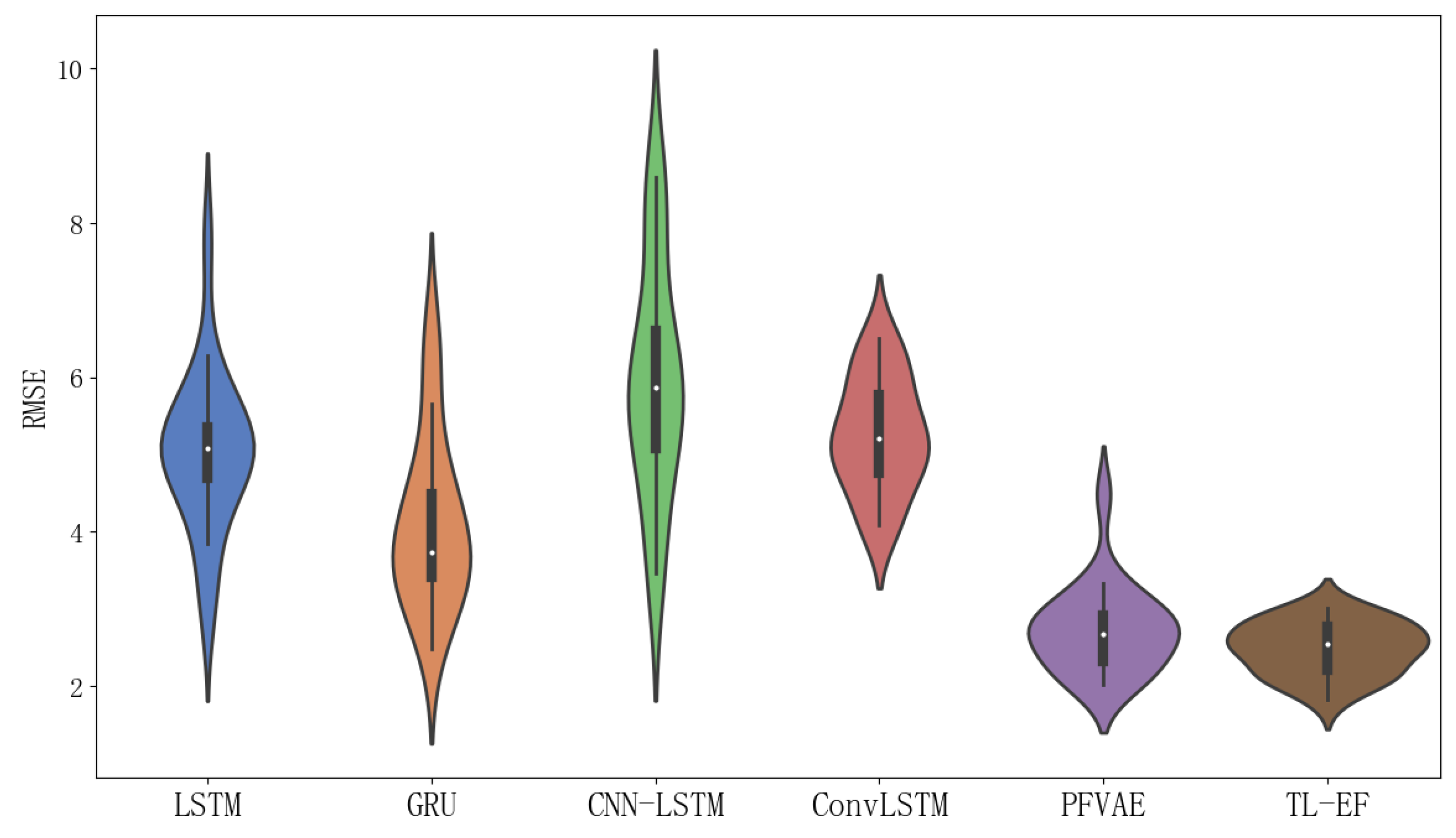
In Figure 6, a scatter plot of the estimated and true values for each model trajectory is presented. The estimated values align closely with the true longitude and latitude values of the corresponding scattered points, demonstrating the accurate estimation results of the model. In Figure 7, we provide scatter plots of distance errors for the different estimation models in GPS Euclidean. Euclidean distance refers to the linear distance between two points in 2D, and the Euclidean distance error represents the degree of proximity between the estimated position and the actual position, thus reflecting the accuracy and accuracy of the positioning estimation system. Our proposed model had less fluctuation in the error scatter plot, which verified that our proposed model had a better estimation accuracy. To ensure objectivity, we independently repeated each model 20 times using different random seeds on the Beijing vehicle GPS motion trajectory dataset and recorded the RMSE value. In Figure 8, we used a violin chart to display the statistical results, and the results showed that our proposed method had a smaller error fluctuation range, a more uniform error distribution, and higher estimation accuracy and stability compared to the other models. Based on the above analysis, it can be concluded that the proposed model exhibited a higher accuracy and stability in estimating GPS trajectories, surpassing the traditional and deep learning models. This makes it a valuable application in the field of trajectory tracking. The model holds great significance for state estimation methods and provides reliable technical support for further research.

Figure 7.
Scatter plot of Euclidean distance errors in GPS estimations using the different estimation models.

Figure 8.
RMSE violin plot for each model with 20 independent repetitions of the experiment on the Beijing vehicle GPS motion trajectory dataset.
4. Conclusions and Future Work
GPS tracking is a critical research field with numerous applications, including autonomous driving, unmanned vehicles, and drones. However, it faces several challenges, particularly when dealing with highly maneuverable targets or complex measurement data containing colored noise. For instance, the GPS navigation signal received by users’ terminals may be too strong, due to high dynamic Doppler shift, or weak, due to occlusion, multipath, flicker, and other factors. Hence, there is an urgent need to develop novel and effective estimation algorithms to overcome these challenges and enhance the accuracy of state estimation.
To address this challenge, this paper proposed a Kalman estimation method that incorporates a learning module based on transformer and LSTM. By combining a transformer encoder structure with LSTM, a neural network parameter learning module was designed to capture the motion characteristics of the system through learning offline state measurement data, eliminating the need to model system dynamics and measurement characteristics. Each model’s parameters for estimating Kalman filter estimates are then obtained using the EM algorithm based on the neural network parameter learning module’s output. This approach enables accurate state estimation for parametric position systems using Kalman filters.
In the future, further research could explore the utilization of different deep learning networks or fine-tune the trade-off between estimation accuracy and computational complexity, to enhance the practicality of state estimation systems. By addressing these challenges, we could unlock new possibilities for advancing and deploying state estimation systems in various applications.
Author Contributions
Conceptualization, X.-B.J. and W.C.; methodology, X.-B.J. and W.C.; software, W.C.; validation, X.-B.J. and W.C.; formal analysis, J.-L.K.; investigation, Y.-T.B. and T.-L.S.; resources, X.-B.J. and J.-L.K.; data curation, W.C., Y.-T.B. and T.-L.S.; writing—original draft preparation, X.-B.J. and W.C.; writing—review and editing, X.-B.J. and W.C.; visualization, W.C.; supervision, J.-L.K., Y.-T.B., H.-J.M. and T.-L.S.; project administration, X.-B.J., H.-J.M. and J.-L.K.; funding acquisition, X.-B.J. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Natural Science Foundation of China, No. 62006008, 62173007, 61903009.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data in the experiment used to support the findings of this study are available from the corresponding authors upon request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Cui, T.; Ding, F.; Jin, X.B.; Alsaedi, A.; Hayat, T. Joint multi-innovation recursive extended least squares parameter and state estimation for a class of state-space systems. Int. J. Control Autom. Syst. 2020, 18, 1412–1424. [Google Scholar] [CrossRef]
- Yi, S.; Zorzi, M. Robust kalman filtering under model uncertainty: The case of degenerate densities. IEEE Trans. Autom. Control 2021, 67, 3458–3471. [Google Scholar] [CrossRef]
- Kong, J.; Wang, H.; Yang, C.; Jin, X.; Zuo, M.; Zhang, X. A spatial feature-enhanced attention neural network with high-order pooling representation for application in pest and disease recognition. Agriculture 2022, 12, 500. [Google Scholar] [CrossRef]
- Kong, J.; Wang, H.; Wang, X.; Jin, X.; Fang, X.; Lin, S. Multi-stream hybrid architecture based on cross-level fusion strategy for fine-grained crop species recognition in precision agriculture. Comput. Electron. Agric. 2021, 185, 106134. [Google Scholar] [CrossRef]
- Jin, X.B.; Wang, Z.Y.; Kong, J.L.; Bai, Y.T.; Su, T.L.; Ma, H.J.; Chakrabarti, P. Deep spatio-temporal graph network with self-optimization for air quality prediction. Entropy 2023, 25, 247. [Google Scholar] [CrossRef]
- Jin, X.B.; Wang, Z.Y.; Gong, W.T.; Kong, J.L.; Bai, Y.T.; Su, T.L.; Ma, H.J.; Chakrabarti, P. Variational bayesian network with information interpretability filtering for air quality forecasting. Mathematics 2023, 11, 837. [Google Scholar] [CrossRef]
- Jin, X.B.; Gong, W.T.; Kong, J.L.; Bai, Y.T.; Su, T.L. A variational Bayesian deep network with data self-screening layer for massive time-series data forecasting. Entropy 2022, 24, 335. [Google Scholar] [CrossRef]
- Jin, X.; Zhang, J.; Kong, J.; Su, T.; Bai, Y. A reversible automatic selection normalization (RASN) deep network for predicting in the smart agriculture system. Agronomy 2022, 12, 591. [Google Scholar] [CrossRef]
- Liu, H.; Hu, F.; Su, J.; Wei, X.; Qin, R. Comparisons on Kalman-filter-based dynamic state estimation algorithms of power systems. IEEE Access 2020, 8, 51035–51043. [Google Scholar] [CrossRef]
- Kalman, R.E.; Bucy, R.S. New results in linear filtering and prediction theory. J. Basic Eng. 1961, 83, 95–108. [Google Scholar] [CrossRef]
- Julier, S.J.; Uhlmann, J.K.; Durrant-Whyte, H.F. A new approach for filtering nonlinear systems. In Proceedings of the 1995 American Control Conference-ACC’95, Seattle, WA, USA, 21–23 June 1995; Volume 3, pp. 1628–1632. [Google Scholar]
- Gordon, N.J.; Salmond, D.J.; Smith, A.F. Novel approach to nonlinear/non-Gaussian Bayesian state estimation. IEE Proc. Radar Signal Process. 1993, 140, 107–113. [Google Scholar] [CrossRef]
- Arjas, A.; Alles, E.J.; Maneas, E.; Arridge, S.; Desjardins, A.; Sillanpaa, M.J.; Hauptmann, A. Neural network kalman filtering for 3-d object tracking from linear array ultrasound data. IEEE Trans. Ultrason. Ferroelectr. Freq. Control 2022, 69, 1691–1702. [Google Scholar] [CrossRef] [PubMed]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. Methodol. 1977, 39, 1–22. [Google Scholar] [CrossRef]
- Shumway, R.H.; Stoffer, D.S. An approach to time series smoothing and forecasting using the EM algorithm. J. Time Ser. Anal. 1982, 3, 253–264. [Google Scholar] [CrossRef]
- Xin, D.J.; Shi, L.F. Kalman filter for linear systems with unknown structural parameters. IEEE Trans. Circuits Syst. II Express Briefs 2021, 69, 1852–1856. [Google Scholar] [CrossRef]
- Lichota, P. Wavelet transform-based aircraft system identification. J. Guid. Control Dyn. 2023, 46, 350–361. [Google Scholar] [CrossRef]
- Goswami, D.; Paley, D.A. Non-gaussian estimation and dynamic output feedback using the gaussian mixture kalman filter. J. Guid. Control Dyn. 2021, 44, 15–24. [Google Scholar] [CrossRef]
- Goff, G.M.; Showalter, D.; Black, J.T.; Beck, J.A. Parameter requirements for noncooperative satellite maneuver reconstruction using adaptive filters. J. Guid. Control Dyn. 2015, 38, 361–374. [Google Scholar] [CrossRef]
- Kong, J.L.; Fan, X.M.; Jin, X.B.; Su, T.L.; Bai, Y.T.; Ma, H.J.; Zuo, M. BMAE-Net: A data-driven weather prediction network for smart agriculture. Agronomy 2023, 13, 625. [Google Scholar] [CrossRef]
- Connor, J.T.; Martin, R.D.; Atlas, L.E. Recurrent neural networks and robust time series prediction. IEEE Trans. Neural Netw. 1994, 5, 240–254. [Google Scholar] [CrossRef]
- Choi, H.M.; Kim, M.K.; Yang, H. Abnormally high water temperature prediction using LSTM deep learning model. J. Intell. Fuzzy Syst. 2021, 40, 8013–8020. [Google Scholar] [CrossRef]
- Chen, C.; Lu, X.; Markham, A.; Trigoni, N. Ionet: Learning to cure the curse of drift in inertial odometry. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Kim, W.Y.; Seo, H.I.; Seo, D.H. Nine-Axis IMU-based Extended inertial odometry neural network. Expert Syst. Appl. 2021, 178, 115075. [Google Scholar] [CrossRef]
- Gao, R.; Xiao, X.; Zhu, S.; Xing, W.; Li, C.; Liu, L.; Ma, L.; Chai, H. Glow in the dark: Smartphone inertial odometry for vehicle tracking in GPS blocked environments. IEEE Internet Things J. 2021, 8, 12955–12967. [Google Scholar] [CrossRef]
- Kong, J.; Fan, X.; Jin, X.; Lin, S.; Zuo, M. A variational bayesian inference-based En-Decoder framework for traffic flow prediction. IEEE Trans. Intell. Transp. Syst. 2023, 1–10. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, NIPS 2017, Long Beach, CA, USA, 4–9 December 2017; Volume 30.
- Akbari, H.; Yuan, L.; Qian, R.; Chuang, W.H.; Chang, S.F.; Cui, Y.; Gong, B. Vatt: Transformers for multimodal self-supervised learning from raw video, audio and text. Adv. Neural Inf. Process. Syst. 2021, 34, 24206–24221. [Google Scholar]
- Liu, Y.; He, G.; Wang, Z.; Li, W.; Huang, H. NRT-YOLO: Improved YOLOv5 based on nested residual transformer for tiny remote sensing object detection. Sensors 2022, 22, 4953. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, X.; Chen, L.; Liu, S.; Han, J.; Shi, H.; Zhong, F. Driver’s Visual Attention Characteristics and Their Emotional Influencing Mechanism under Different Cognitive Tasks. Int. J. Environ. Res. Public Health 2022, 19, 5059. [Google Scholar] [CrossRef]
- Wang, L.; Zhou, G. Pseudo-spectrum based track-before-detect for weak maneuvering targets in range-Doppler plane. IEEE Trans. Veh. Technol. 2021, 70, 3043–3058. [Google Scholar] [CrossRef]
- Eltoukhy, M.; Ahmad, M.O.; Swamy, M. An adaptive turn rate estimation for tracking a maneuvering target. IEEE Access 2020, 8, 94176–94189. [Google Scholar] [CrossRef]
- Ye, X.; Zhang, O.; Li, X.; Qiu, Y. Tracking algorithm for cruise missile based on IMM-singer model. In Proceedings of the AIP Conference Proceedings, Wuhan, China, 13 February 2019; AIP Publishing: College Park, MD, USA, 2019; Volume 2073. [Google Scholar]
- Zhenkai, X.; Fanying, L.; Lei, Z. Study on Maneuvering Target On-axis Tracking Algorithm of Modified Current Statistical Model. In Proceedings of the MATEC Web of Conferences EDP Sciences, Chengdu, China, 12–14 January 2018; Volume 160, p. 02008. [Google Scholar]
- Ansari, M.S.; Bartoš, V.; Lee, B. GRU-based deep learning approach for network intrusion alert prediction. Future Gener. Comput. Syst. 2022, 128, 235–247. [Google Scholar] [CrossRef]
- Zha, W.; Liu, Y.; Wan, Y.; Luo, R.; Li, D.; Yang, S.; Xu, Y. Forecasting monthly gas field production based on the CNN-LSTM model. Energy 2022, 260, 124889. [Google Scholar] [CrossRef]
- Huang, H.; Zeng, Z.; Yao, D.; Pei, X.; Zhang, Y. Spatial-temporal ConvLSTM for vehicle driving intention prediction. Tsinghua Sci. Technol. 2021, 27, 599–609. [Google Scholar] [CrossRef]
- Jin, X.B.; Gong, W.T.; Kong, J.L.; Bai, Y.T.; Su, T.L. PFVAE: A planar flow-based variational auto-encoder prediction model for time series data. Mathematics 2022, 10, 610. [Google Scholar] [CrossRef]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).