
Data Mining and Fusion Framework for In-Home Monitoring Applications

 ,
,  ,
,  ,
, 
Abstract
:1. Introduction
1.1. Sensor Data Fusion Architectures
1.2. Data Mining Concepts
2. Related Work
2.1. Object Detection
2.2. Automobile Systems
2.3. Healthcare Applications
2.4. Cluster-Based Analysis
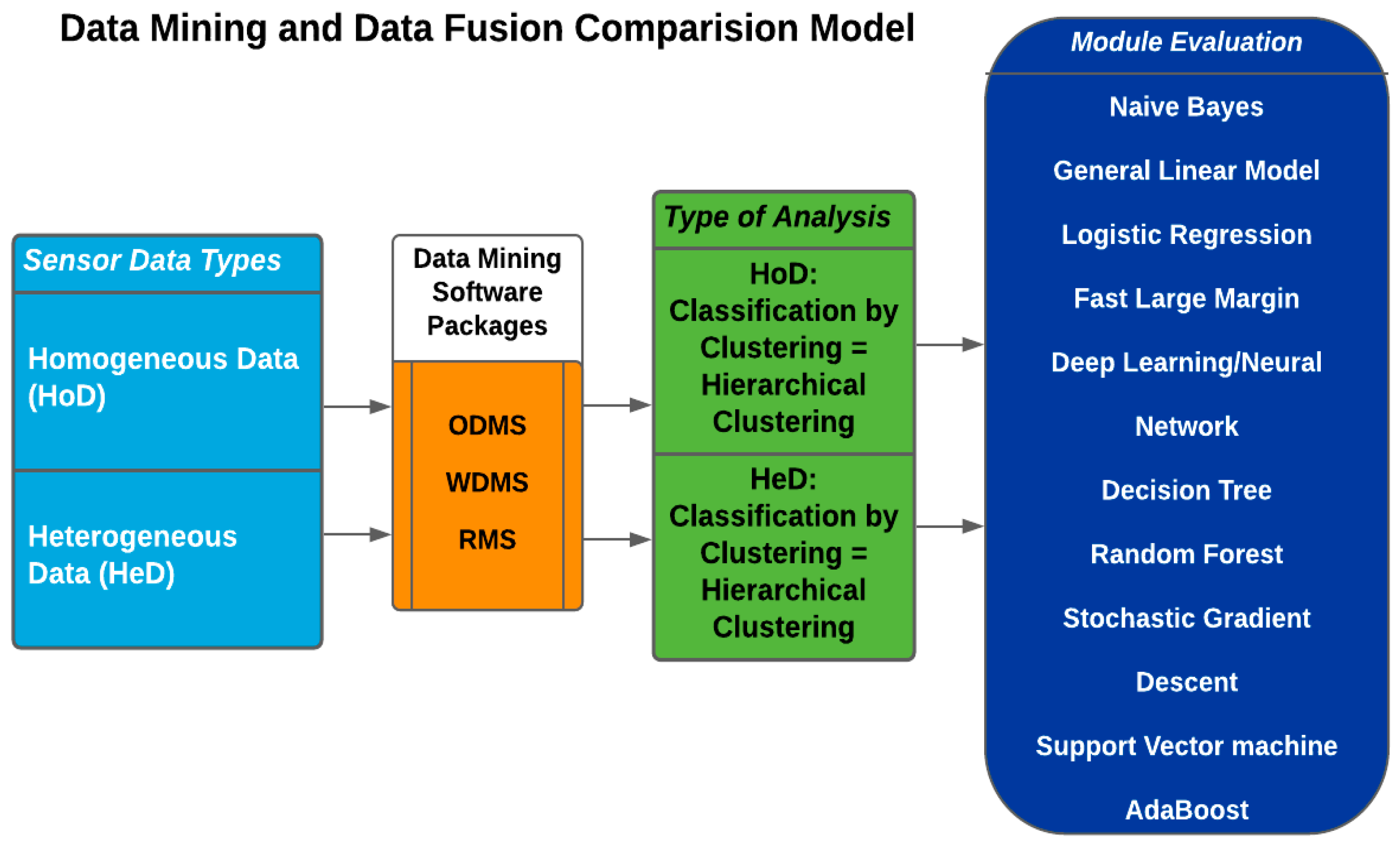
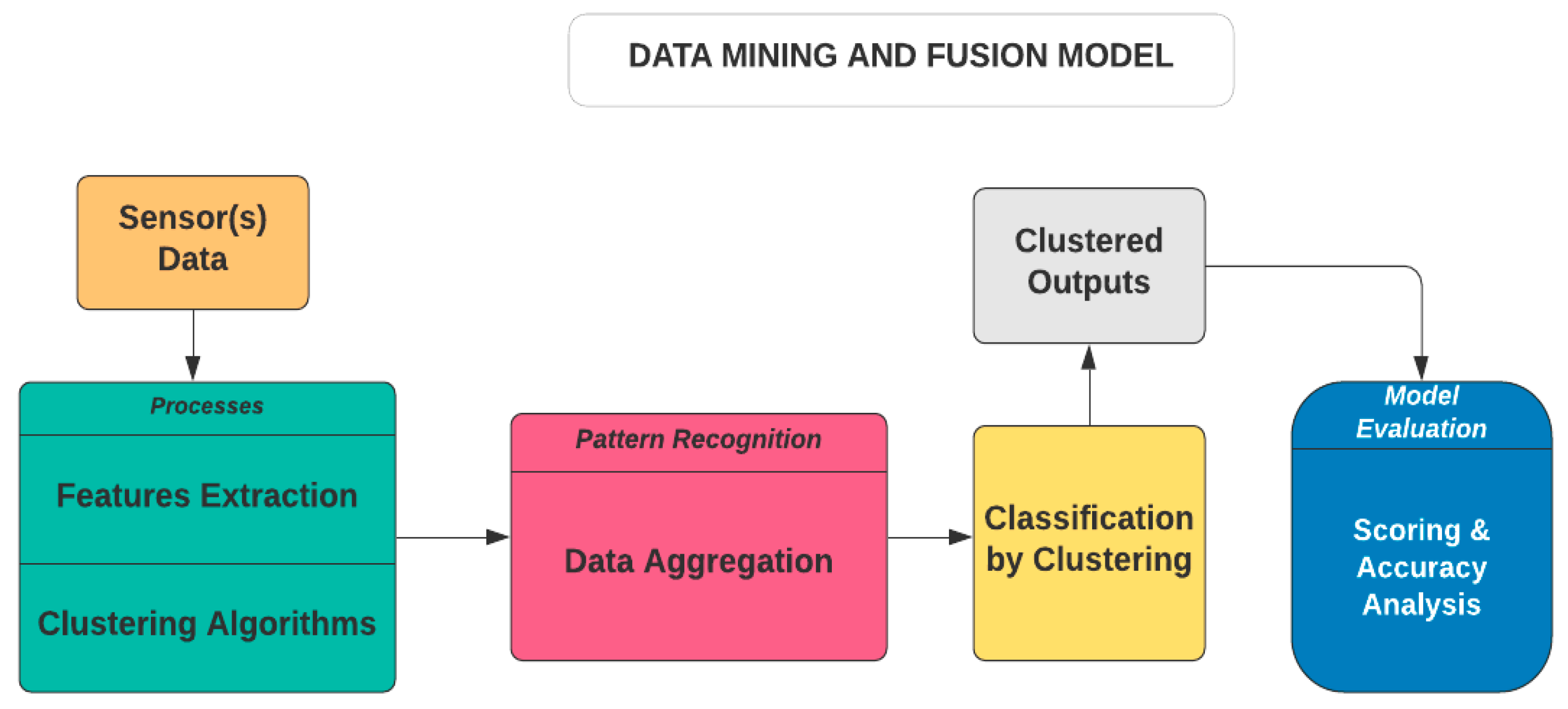
3. Materials and Methods
4. Results
4.1. Conceptual Findings
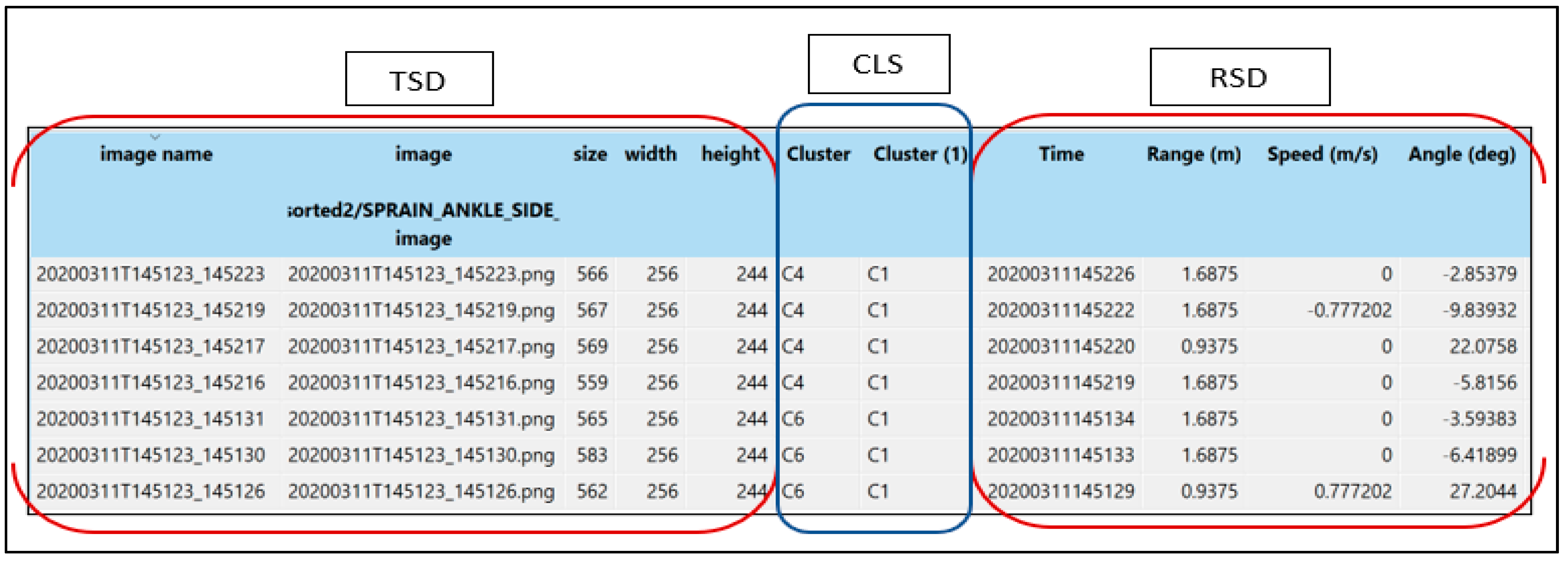
4.2. Homogeneous Data Analysis
4.3. Heterogeneous Data Analysis
4.4. Proposed Data Fusion Framework
5. Discussion
5.1. The Proposed Framework vs. Others
5.2. Advantages of the Proposed Framework
5.3. Limitation of the Proposed Framework
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jitendra, R. Multi-Sensor Data Fusion with MATLAB; CRC Press: Boca Raton, FL, USA, 2013; Volume 106, ISBN 9781439800058. [Google Scholar]
- Chen, C.Y.; Li, C.; Fiorentino, M.; Palermo, S. A LIDAR Sensor Prototype with Embedded 14-Bit 52 Ps Resolution ILO-TDC Array. Analog Integr. Circuits Signal Process. 2018, 94, 369–382. [Google Scholar] [CrossRef]
- Al-Dhaher, A.H.G.; Mackesy, D. Multi-Sensor Data Fusion Architecture. In Proceedings of the 3rd IEEE International Workshop on Haptic, Audio and Visual Environments and their Applications—HAVE 2004, Ottawa, ON, Canada, 2–3 October 2004; pp. 159–163. [Google Scholar]
- Lytrivis, P.; Thomaidis, G.; Amditis, A. Sensor Data Fusion in Automotive Applications; Intech: London, UK, 2009; Volume 490. [Google Scholar] [CrossRef]
- Dhiraj, A.; Deepa, P. Sensors and Their Applications. J. Phys. E 2012, 1, 60–68. [Google Scholar] [CrossRef]
- Elmenreich, W.; Leidenfrost, R. Fusion of Heterogeneous Sensors Data. In Proceedings of the 6th Workshop on Intelligent Solutions in Embedded Systems, WISES’08, Regensburg, Germany, 10–11 July 2008. [Google Scholar]
- Nobili, S.; Camurri, M.; Barasuol, V.; Focchi, M.; Caldwell, D.G.; Semini, C.; Fallon, M. Heterogeneous Sensor Fusion for Accurate State Estimation of Dynamic Legged Robots. In Proceedings of the 13th Robotics: Science and Systems 2017, Cambridge, MA, USA, 12–16 July 2017. [Google Scholar] [CrossRef]
- King, R.S. Cluster Analysis and Data Mining; David Pallai: Dulles, VA, USA, 2015; ISBN 9781938549380. [Google Scholar]
- Ashraf, I. Data Mining Algorithms and Their Applications in Education Data Mining. Int. J. Adv. Res. 2014, 2, 50–56. [Google Scholar]
- Kantardzic, M. Data Mining: Concepts, Models, Methods, and Algorithms, 3rd ed.; IEEE Press: Piscataway, NJ, USA, 2020; Volume 36, ISBN 9781119516040. [Google Scholar]
- Sadoughi, F.; Ghaderzadeh, M. A Hybrid Particle Swarm and Neural Network Approach for Detection of Prostate Cancer from Benign Hyperplasia of Prostate. Stud. Health Technol. Inform. 2014, 205, 481–485. [Google Scholar] [PubMed]
- Ghaderzadeh, M. Clinical Decision Support System for Early Detection of Prostate Cancer from Benign Hyperplasia of Prostate. Stud. Health Technol. Inform. 2013, 192, 928. [Google Scholar] [CrossRef]
- Mizuno, H.; Kosaka, M.; Yajima, H. Application of Neural Network to Technical Analysis of Stock Market Prediction. In Proceedings of the 2022 3rd International Conference on Intelligent Engineering and Management (ICIEM), London, UK, 27–29 April 2022; pp. 302–306. [Google Scholar] [CrossRef]
- Dharmarajan, A.; Velmurugan, T. Applications of Partition Based Clustering Algorithms: A Survey. In Proceedings of the 2013 IEEE International Conference on Computational Intelligence and Computing Research, Enathi, India, 26–28 December 2013; pp. 1–5. [Google Scholar] [CrossRef]
- Kotsiantis, S.B. Decision Trees: A Recent Overview. Artif. Intell. Rev. 2013, 39, 261–283. [Google Scholar] [CrossRef]
- Banerjee, A.; Shan, H. Model-Based Clustering BT. In Encyclopedia of Machine Learning; Sammut, C., Webb, G.I., Eds.; Springer: Boston, MA, USA, 2010; pp. 686–689. ISBN 978-0-387-30164-8. [Google Scholar]
- Suthaharan, S. Support Vector Machine BT. In Machine Learning Models and Algorithms for Big Data Classification: Thinking with Examples for Effective Learning; Suthaharan, S., Ed.; Springer: Boston, MA, USA, 2016; pp. 207–235. ISBN 978-1-4899-7641-3. [Google Scholar]
- Aouad, L.M.; An-Lekhac, N.; Kechadi, T. Grid-Based Approaches for Distributed Data Mining Applications. J. Algorithm. Comput. Technol. 2009, 3, 517–534. [Google Scholar] [CrossRef]
- Alcalá-Fdez, J.; Alcalá, R.; Herrera, F. A Fuzzy Association Rule-Based Classification Model for High-Dimensional Problems with Genetic Rule Selection and Lateral Tuning. IEEE Trans. Fuzzy Syst. 2011, 19, 857–872. [Google Scholar] [CrossRef]
- Mumtaz, K.; Studies, M.; Nadu, T. An Analysis on Density Based Clustering of Multi Dimensional Spatial Data. Indian J. Comput. Sci. Eng. 2010, 1, 8–12. [Google Scholar]
- Guo, Z.; Wu, S.; Ohno, M.; Yoshida, R. Bayesian Algorithm for Retrosynthesis. J. Chem. Inf. Model. 2020, 60, 4474–4486. [Google Scholar] [CrossRef] [PubMed]
- Ekerete, I.; Garcia-Constantino, M.; Konios, A.; Mustafa, M.A.; Diaz-Skeete, Y.; Nugent, C.; McLaughlin, J. Fusion of Unobtrusive Sensing Solutions for Home-Based Activity Recognition and Classification Using Data Mining Models and Methods. Appl. Sci. 2021, 11, 9096. [Google Scholar] [CrossRef]
- Märzinger, T.; Kotík, J.; Pfeifer, C. Application of Hierarchical Agglomerative Clustering (Hac) for Systemic Classification of Pop-up Housing (Puh) Environments. Appl. Sci. 2021, 11, 1122. [Google Scholar] [CrossRef]
- Oyelade, J.; Isewon, I.; Oladipupo, O.; Emebo, O.; Omogbadegun, Z.; Aromolaran, O.; Uwoghiren, E.; Olaniyan, D.; Olawole, O. Data Clustering: Algorithms and Its Applications. In Proceedings of the 2019 19th International Conference on Computational Science and Its Applications (ICCSA), St. Petersburg, Russia, 1–4 July 2019; pp. 71–81. [Google Scholar] [CrossRef]
- Morissette, L.; Chartier, S. The K-Means Clustering Technique: General Considerations and Implementation in Mathematica. Tutor. Quant. Methods Psychol. 2013, 9, 15–24. [Google Scholar] [CrossRef]
- Khan, S.S.; Ahamed, S.; Jannat, M.; Shatabda, S.; Farid, D.M. Classification by Clustering (CbC): An Approach of Classifying Big Data Based on Similarities. In Proceedings of International Joint Conference on Computational Intelligence. Algorithms for Intelligent Systems; Springer: Singapore, 2019; pp. 593–605. [Google Scholar]
- Ziebinski, A.; Mrozek, D.; Cupek, R.; Grzechca, D.; Fojcik, M.; Drewniak, M.; Kyrkjebø, E.; Lin, J.C.-W.; Øvsthus, K.; Biernacki1, P. Challenges Associated with Sensors and Data Fusion for AGV-Driven Smart Manufacturing. In Computational Science—ICCS 2021: 21st International Conference, Krakow, Poland, 16–18 June 2021, Proceedings, Part VI; Springer Nature Switzerland AG: Cham, Switzerland, 2021; ISBN 9783030779696. [Google Scholar]
- Luo, R.C.; Yih, C.-C.; Su, K.L. Multisensor Fusion and Integration: Approaches, Applications, and Future Research Directions. IEEE Sens. J. 2002, 2, 107–119. [Google Scholar] [CrossRef]
- Kim, T.; Kim, S.; Lee, E.; Park, M. Comparative Analysis of RADAR-IR Sensor Fusion Methods for Object Detection. In Proceedings of the 2017 17th International Conference on Control, Automation and Systems (ICCAS), Jeju, Republic of Korea, 18–21 October 2017; pp. 1576–1580. [Google Scholar]
- Lee, G.H.; Choi, J.D.; Lee, J.H.; Kim, M.Y. Object Detection Using Vision and LiDAR Sensor Fusion for Multi-Channel V2X System. In Proceedings of the 2020 International Conference on Artificial Intelligence in Information and Communication, ICAIIC 2020; Institute of Electrical and Electronics Engineers Inc., Fukuoka, Japan, 19–21 February 2020; pp. 1–5. [Google Scholar]
- Rezaei, M. Computer Vision for Road Safety: A System for Simultaneous Monitoring of Driver Behaviour and Road Hazards. Ph.D. Thesis, University of Auckland, Auckland, New Zealand, 2014. [Google Scholar]
- De Silva, V.; Roche, J.; Kondoz, A.; Member, S. Fusion of LiDAR and Camera Sensor Data for Environment Sensing in Driverless Vehicles. arXiv 2018, arXiv:1710.06230v2. [Google Scholar]
- Chen, Z.; Wang, Y. Infrared–Ultrasonic Sensor Fusion for Support Vector Machine–Based Fall Detection. J. Intell. Mater. Syst. Struct. 2018, 29, 2027–2039. [Google Scholar] [CrossRef]
- Kovács, G.; Nagy, S. Ultrasonic Sensor Fusion Inverse Algorithm for Visually Impaired Aiding Applications. Sensors 2020, 20, 3682. [Google Scholar] [CrossRef]
- Huang, P.; Luo, X.; Jin, J.; Wang, L.; Zhang, L.; Liu, J.; Zhang, Z. Improving High-Throughput Phenotyping Using Fusion of Close-Range Hyperspectral Camera and Low-Cost Depth Sensor. Sensors 2018, 18, 2711. [Google Scholar] [CrossRef]
- Liu, X.; Payandeh, S. A Study of Chained Stochastic Tracking in RGB and Depth Sensing. J. Control Sci. Eng. 2018, 2018, 2605735. [Google Scholar] [CrossRef]
- Kanwal, N.; Bostanci, E.; Currie, K.; Clark, A.F.A.F. A Navigation System for the Visually Impaired: A Fusion of Vision and Depth Sensor. Appl. Bionics Biomech. 2015, 2015, 479857. [Google Scholar] [CrossRef]
- Shao, F.; Lin, W.; Li, Z.; Jiang, G.; Dai, Q. Toward Simultaneous Visual Comfort and Depth Sensation Optimization for Stereoscopic 3-D Experience. IEEE Trans. Cybern. 2017, 47, 4521–4533. [Google Scholar] [CrossRef] [PubMed]
- Procházka, A.; Vyšata, O.; Vališ, M.; Ťupa, O.; Schätz, M.; Mařík, V. Use of the Image and Depth Sensors of the Microsoft Kinect for the Detection of Gait Disorders. Neural Comput. Appl. 2015, 26, 1621–1629. [Google Scholar] [CrossRef]
- Kepski, M.; Kwolek, B. Event-Driven System for Fall Detection Using Body-Worn Accelerometer and Depth Sensor. IET Comput. Vis. 2018, 12, 48–58. [Google Scholar] [CrossRef]
- Long, N.; Wang, K.; Cheng, R.; Yang, K.; Hu, W.; Bai, J. Assisting the Visually Impaired: Multitarget Warning through Millimeter Wave Radar and RGB-Depth Sensors. J. Electron. Imaging 2019, 28, 013028. [Google Scholar] [CrossRef]
- Salcedo-Sanz, S.; Ghamisi, P.; Piles, M.; Werner, M.; Cuadra, L.; Moreno-Martínez, A.; Izquierdo-Verdiguier, E.; Muñoz-Marí, J.; Mosavi, A.; Camps-Valls, G. Machine Learning Information Fusion in Earth Observation: A Comprehensive Review of Methods, Applications and Data Sources. Inf. Fusion 2020, 63, 256–272. [Google Scholar] [CrossRef]
- Bin Chang, N.; Bai, K. Multisensor Data Fusion and Machine Learning for Environmental Remote Sensing; CRC Press: Boca Raton, FL, USA, 2018; 508p. [Google Scholar] [CrossRef]
- Bowler, A.L.; Bakalis, S.; Watson, N.J. Monitoring Mixing Processes Using Ultrasonic Sensors and Machine Learning. Sensors 2020, 20, 1813. [Google Scholar] [CrossRef]
- Madeira, R.; Nunes, L. A Machine Learning Approach for Indirect Human Presence Detection Using IOT Devices. In Proceedings of the 2016 11th International Conference on Digital Information Management, ICDIM 2016, Porto, Portugal, 19–21 September 2016; pp. 145–150. [Google Scholar]
- Elbattah, M.; Molloy, O. Data-Driven Patient Segmentation Using K-Means Clustering: The Case of Hip Fracture Care in Ireland. In Proceedings of the ACSW ’17: Proceedings of the Australasian Computer Science Week Multiconference, Geelong, Australia, 30 January–3 February 2017; pp. 3–10. [Google Scholar] [CrossRef]
- Samriya, J.K.; Kumar, S.; Singh, S. Efficient K-Means Clustering for Healthcare Data. Adv. J. Comput. Sci. Eng. 2016, 4, 1–7. [Google Scholar]
- Bourobou, S.T.M.; Yoo, Y. User Activity Recognition in Smart Homes Using Pattern Clustering Applied to Temporal ANN Algorithm. Sensors 2015, 15, 11953–11971. [Google Scholar] [CrossRef]
- Liao, M.; Li, Y.; Kianifard, F.; Obi, E.; Arcona, S. Cluster Analysis and Its Application to Healthcare Claims Data: A Study of End-Stage Renal Disease Patients Who Initiated Hemodialysis Epidemiology and Health Outcomes. BMC Nephrol. 2016, 17, 25. [Google Scholar] [CrossRef]
- Ekerete, I.; Garcia-Constantino, M.; Diaz, Y.; Nugent, C.; Mclaughlin, J. Fusion of Unobtrusive Sensing Solutions for Sprained Ankle Rehabilitation Exercises Monitoring in Home Environments. Sensors 2021, 21, 7560. [Google Scholar] [CrossRef]
- Negi, N.; Chawla, G. Clustering Algorithms in Healthcare BT. In Intelligent Healthcare: Applications of AI in EHealth; Bhatia, S., Dubey, A.K., Chhikara, R., Chaudhary, P., Kumar, A., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 211–224. ISBN 978-3-030-67051-1. [Google Scholar]
- Garavand, A.; Behmanesh, A.; Aslani, N.; Sadeghsalehi, H.; Ghaderzadeh, M. Towards Diagnostic Aided Systems in Coronary Artery Disease Detection: A Comprehensive Multiview Survey of the State of the Art. Int. J. Intell. Syst. 2023, 2023, 6442756. [Google Scholar] [CrossRef]
- Garavand, A.; Salehnasab, C.; Behmanesh, A.; Aslani, N.; Zadeh, A.H.; Ghaderzadeh, M. Efficient Model for Coronary Artery Disease Diagnosis: A Comparative Study of Several Machine Learning Algorithms. J. Healthc. Eng. 2022, 2022, 5359540. [Google Scholar] [CrossRef] [PubMed]
- Smola, A.; Vishwanathan, S.V. Introduction to Machine Learning; Cambridge University Press: Cambridge, UK, 2008; Volume 252, Available online: https://alex.smola.org/drafts/thebook.pdf (accessed on 25 September 2023).
- Keogh, A.; Dorn, J.F.; Walsh, L.; Calvo, F.; Caulfield, B. Comparing the Usability and Acceptability of Wearable Sensors among Older Irish Adults in a Real-World Context: Observational Study. JMIR mHealth uHealth 2020, 8, e15704. [Google Scholar] [CrossRef] [PubMed]
- Rahman, M.S. The Advantages and Disadvantages of Using Qualitative and Quantitative Approaches and Methods in Language “Testing and Assessment” Research: A Literature Review. J. Educ. Learn. 2016, 6, 102. [Google Scholar] [CrossRef]
- Silva, C.A.; Santilli, G.; Sano, E.E.; Rodrigues, S.W.P. Qualitative Analysis of Deforestation in the Amazonian Rainforest from SAR, Optical and Thermal Sensors. Anu. Inst. Geociencias 2019, 42, 18–29. [Google Scholar] [CrossRef]
- Kelly, C.J.; Karthikesalingam, A.; Suleyman, M.; Corrado, G.; King, D. Key Challenges for Delivering Clinical Impact with Artificial Intelligence. BMC Med. 2019, 17, 195. [Google Scholar] [CrossRef]
- Hesamian, M.H.; Jia, W.; He, X.; Kennedy, P. Deep Learning Techniques for Medical Image Segmentation: Achievements and Challenges. J. Digit. Imaging 2019, 32, 582–596. [Google Scholar] [CrossRef]
- Motti, V.G. Wearable Health: Opportunities and Challenges. In Proceedings of the 13th EAI International Conference on Pervasive Computing Technologies for Healthcare, Trento, Italy, 20–23 May 2019; pp. 356–359. [Google Scholar]
- Cleland, I.; McClean, S.; Rafferty, J.; Synnott, J.; Nugent, C.; Ennis, A.; Catherwood, P.; McChesney, I. A Scalable, Research Oriented, Generic, Sensor Data Platform. IEEE Access 2018, 6, 45473–45484. [Google Scholar] [CrossRef]
- PAT Research 43 Top Free Data Mining Software. Available online: https://www.predictiveanalyticstoday.com/top-free-data-mining-software/ (accessed on 12 November 2020).
- Bhatia, P. Introduction to Data Mining. In Data Mining and Data Warehousing: Principles and Practical Techniques; Cambridge University Press: Cambridge, UK, 2019; pp. 17–27. [Google Scholar] [CrossRef]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-Level Accuracy with 50x Fewer Parameters and <0.5 MB Model Size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- De Meo, P.; Ferrara, E.; Fiumara, G.; Provetti, A. Generalized Louvain Method for Community Detection in Large Networks. In Proceedings of the 2011 11th International Conference on Intelligent Systems Design and Applications, Cordoba, Spain, 22–24 November 2011; pp. 88–93. [Google Scholar] [CrossRef]
- Mishra, A. Amazon Machine Learning. In Machine Learning in the AWS Cloud: Add Intelligence to Applications with Amazon SageMaker and Amazon Rekognition; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2019; pp. 317–351. [Google Scholar] [CrossRef]
- Caruso, M.; Sabatini, A.M.; Knaflitz, M.; Della Croce, U.; Cereatti, A. Extension of the Rigid-constraint Method for the Heuristic Suboptimal Parameter Tuning to Ten Sensor Fusion Algorithms Using Inertial and Magnetic Sensing. Sensors 2021, 21, 6307. [Google Scholar] [CrossRef]
- Rodrigo Marco, V.; Kalkkuhl, J.; Raisch, J.; Scholte, W.J.; Nijmeijer, H.; Seel, T. Multi-Modal Sensor Fusion for Highly Accurate Vehicle Motion State Estimation. Control Eng. Pract. 2020, 100, 104409. [Google Scholar] [CrossRef]
- Reis, I.; Baron, D.; Shahaf, S. Probabilistic Random Forest: A Machine Learning Algorithm for Noisy Data Sets. Astron. J. 2018, 157, 16. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classification Techniques | Application of Classification Techniques | Clustering Techniques | Application of Clustering Techniques |
|---|---|---|---|
| Neural Network | E.g., stock market prediction [13] | Partition-based | E.g., medical datasets analysis [14] |
| Decision Tree | E.g., Banking and finance [15] | Model-based | E.g., multivariate Gaussian mixture model [16] |
| Support Vector Machine | E.g., big data analysis [17] | Grid-based | E.g., large-scale computation [18] |
| Association-based | E.g., high dimensional problems [19] | Density-based | Applications with noise. E.g., DBSCAN [20] |
| Bayesian | E.g., retrosynthesis [21] | Hierarchy-based | E.g., Mood and abnormal activity prediction [22,23] |
| Parameters | ODMS (%) | RMS (%) | WDMS (%) | Anaconda (%) |
|---|---|---|---|---|
| Ease of Use Interface | 96.0 | 94.0 | 91.0 | 78.0 |
| Functionality and Features Management | 95.0 | 96.0 | 92.0 | 78.0 |
| Software Integration | 94.0 | 95.0 | 90.0 | 76.0 |
| Performance Index | 95.0 | 95.0 | 91.0 | 77.0 |
| Advanced Features Incorporation | 95.0 | 94.0 | 92.0 | 77.0 |
| User Rating on Implementation | 90.0 | 67.0 | 73.0 | 77.0 |
| Average Rating | 94.2 | 90.2 | 88.2 | 77.2 |
| Model | ODMS CA (%) | WDMS CA (%) | RMS CA (%) |
|---|---|---|---|
| Naive Bayes | 79.9 | 77.0 | 80.8 |
| Generalised Linear Model | NA | NA | 82.7 |
| Logistic Regression | 94.1 | 74 | 22.9 |
| Fast Large Margin | NA | NA | 83.3 |
| Deep Learning/Neural Network | 94.2 | NA | 86.1 |
| Decision Tree | 62.3 | 77.0 | NA |
| Random Forest | 73.9 | 83.0 | 55.1 |
| Stochastic Gradient Descent | 94.5 | 71.0 | 87.1 |
| Support Vector Machine | 94.0 | 75.0 | 78.3 |
| Average based on Available Models | 84.7 | 76.2 | 72.0 |
| Model | RMS CA (%) | WDMS CA (%) | ODMS CA (%) |
|---|---|---|---|
| Naive Bayes | 60.4 | 67.0 | 80.7 |
| Generalised Linear Model | 60.7 | NA | NA |
| Fast Large Margin | 62.2 | NA | NA |
| Deep Learning/Neural Network | 59.2 | NA | 98.9 |
| Decision Tree | 54.3 | 64.0 | 99.5 |
| Decision table | NA | 69.0 | NA |
| Random Forest | 59.2 | 70.0 | 89.9 |
| Stochastic Gradient Descent | 60.1 | NA | 99.3 |
| Support Vector Machine | 61.3 | 48.0 | 98.4 |
| K-Nearest Neighbours | NA | NA | 99.1 |
| CN2 Induction | NA | NA | 99.5 |
| J48 | NA | 70.0 | NA |
| Average | 59.7 | 64.7 | 95.7 |
| Model | AUC (%) | CA (%) | F1 (%) | Precision (%) | Recall (%) | Log Loss (%) |
|---|---|---|---|---|---|---|
| Random Forest | 85.2 | 96.8 | 96.0 | 95.8 | 96.8 | 0.2 |
| Neural Network | 95.5 | 98.6 | 98.6 | 98.6 | 98.6 | 0.1 |
| K-Nearest Neighbours | 95.5 | 95.5 | 94.6 | 93.7 | 95.5 | 0.1 |
| CN2 Induction | 87.8 | 94.6 | 94.6 | 94.6 | 94.6 | 0.1 |
| Average | 91.0 | 96.4 | 96.0 | 95.7 | 96.4 | 0.1 |
| Model | AUC (%) | CA (%) | F1 (%) | Precision (%) | Recall (%) | Log Loss (%) |
|---|---|---|---|---|---|---|
| Random Forest | 100.0 | 99.5 | 99.5 | 99.5 | 99.5 | 0.0 |
| Neural Network | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 0.0 |
| K-Near Neighbours | 98.7 | 98.2 | 98.0 | 98.0 | 98.2 | 0.1 |
| CN2 Induction | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 0.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ekerete, I.; Garcia-Constantino, M.; Nugent, C.; McCullagh, P.; McLaughlin, J. Data Mining and Fusion Framework for In-Home Monitoring Applications. Sensors 2023, 23, 8661. https://doi.org/10.3390/s23218661
Ekerete I, Garcia-Constantino M, Nugent C, McCullagh P, McLaughlin J. Data Mining and Fusion Framework for In-Home Monitoring Applications. Sensors. 2023; 23(21):8661. https://doi.org/10.3390/s23218661
Chicago/Turabian StyleEkerete, Idongesit, Matias Garcia-Constantino, Christopher Nugent, Paul McCullagh, and James McLaughlin. 2023. "Data Mining and Fusion Framework for In-Home Monitoring Applications" Sensors 23, no. 21: 8661. https://doi.org/10.3390/s23218661