



PMIndoor: Pose Rectified Network and Multiple Loss Functions for Self-Supervised Monocular Indoor Depth Estimation


Abstract
:1. Introduction
- We propose a new pose rectified network (PRN) to solve the camera pose problem, while also using the pose rectified network loss to remove the rotational motion between adjacent frames.
- We use multiple loss functions, such as patch-based multi-view photometric consistency loss, Manhattan normal loss, and Co-planar loss, to solve the problem of non-textured regions.
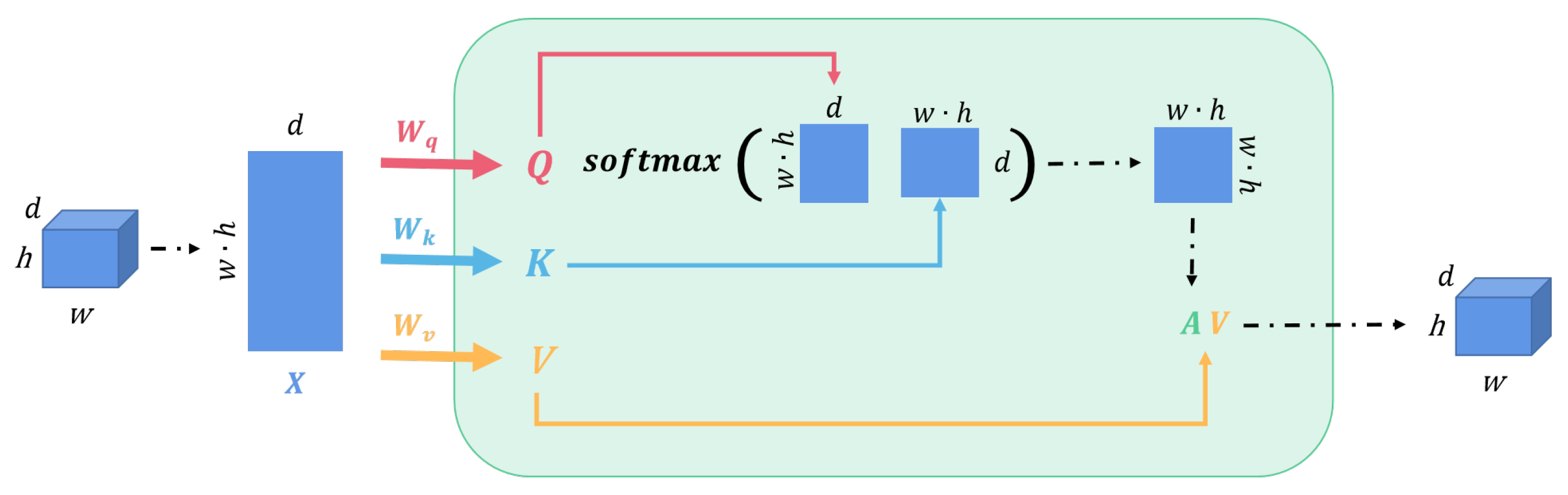
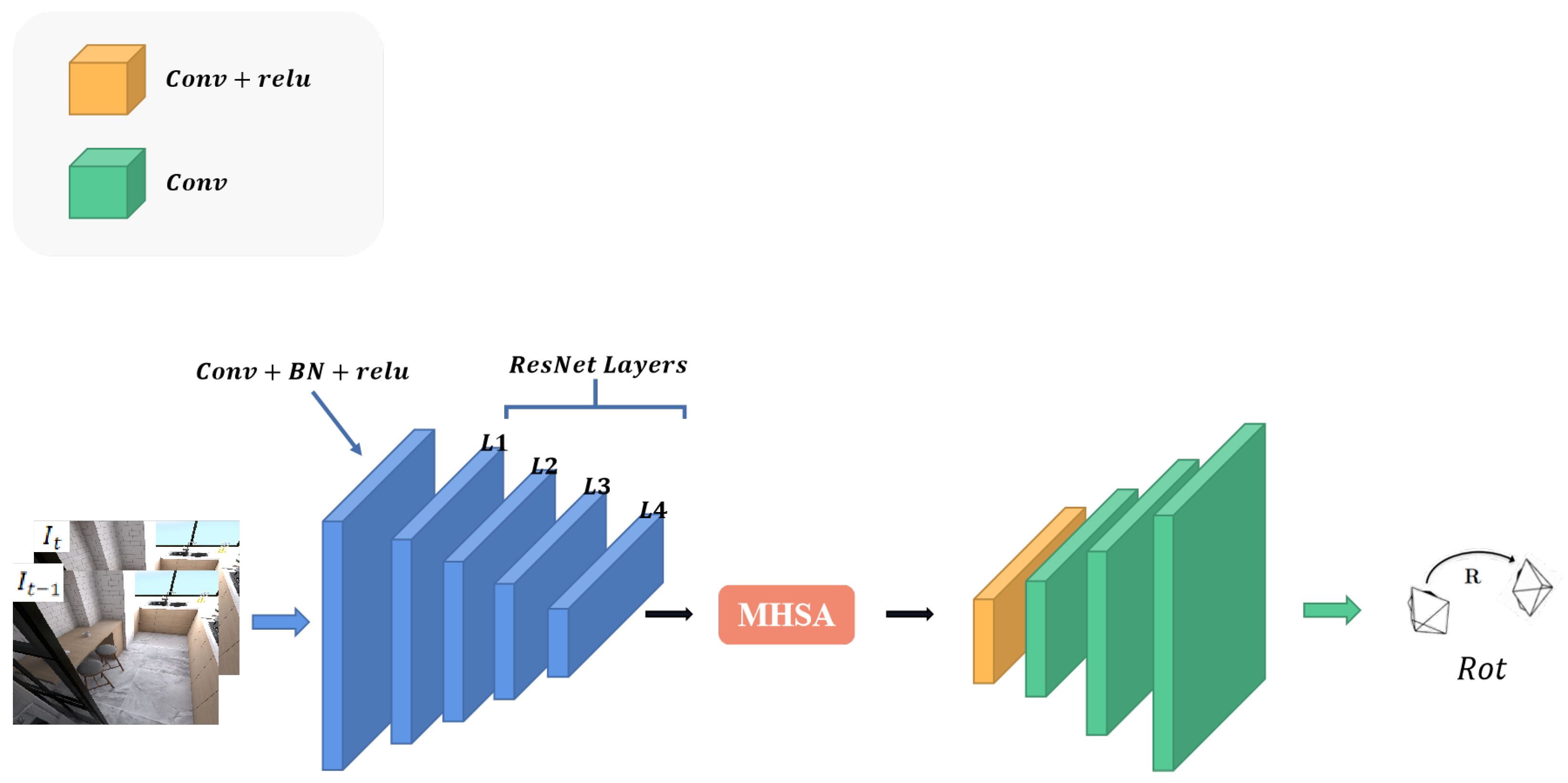
- We add multi-head self-attention (MHSA) modules to the depth estimation network to improve the expression and generalization of the model.
- The experimental results on the indoor benchmark dataset NYUv2 [23] demonstrate that our method PMIndoor outperforms many existing state-of-the-art methods.
2. Method
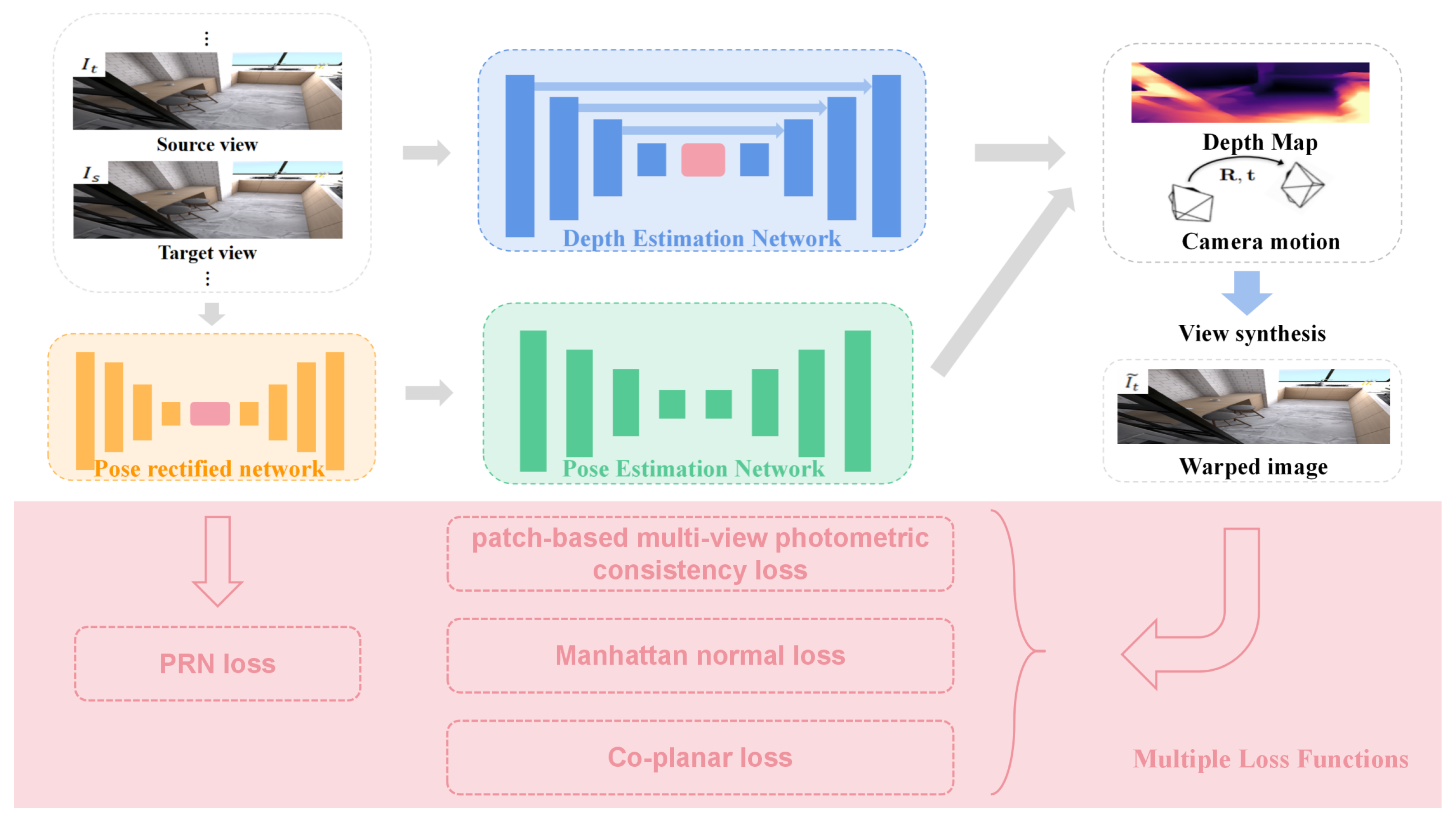
2.1. Overview
2.2. Depth Estimation Network
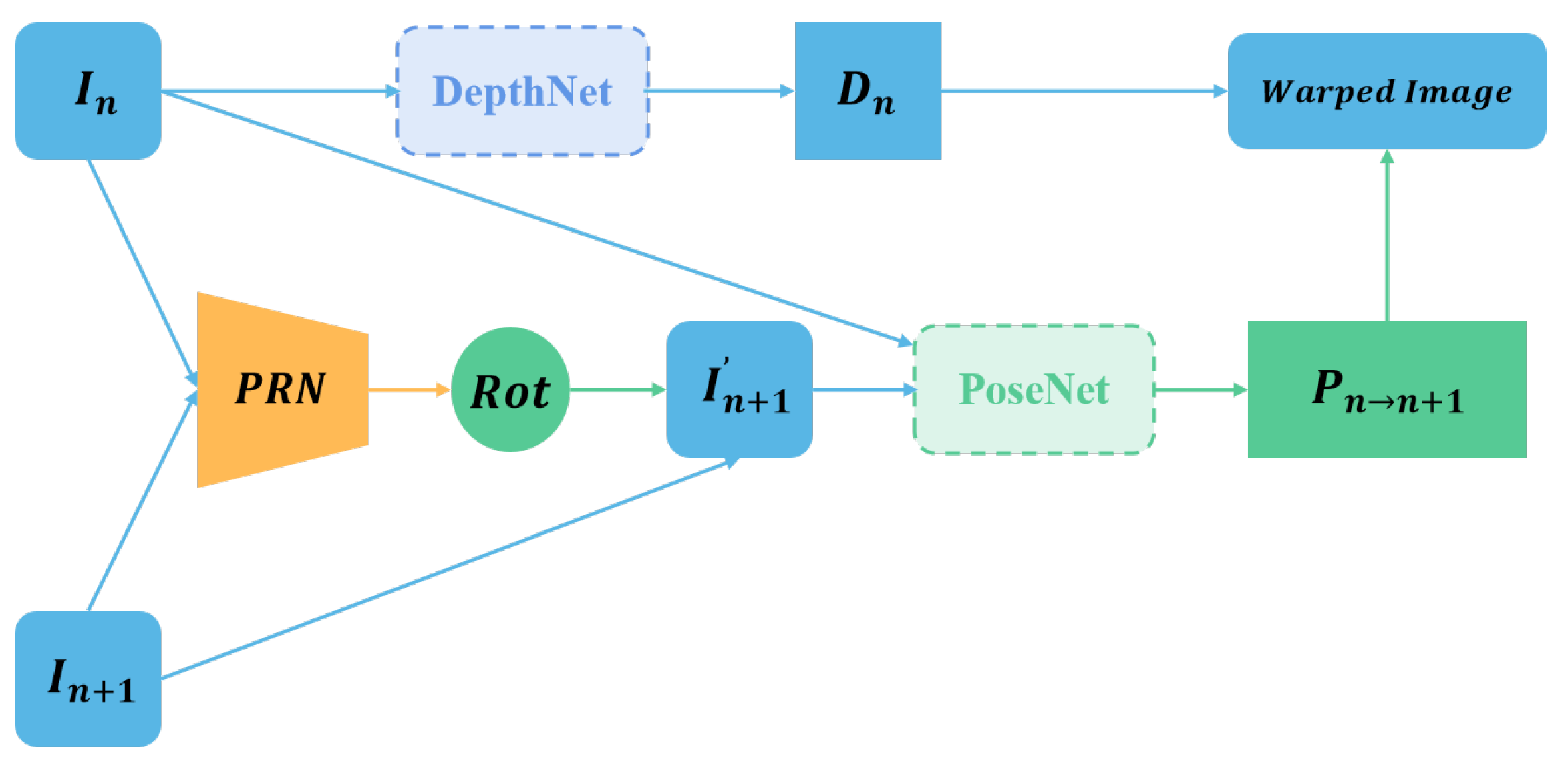
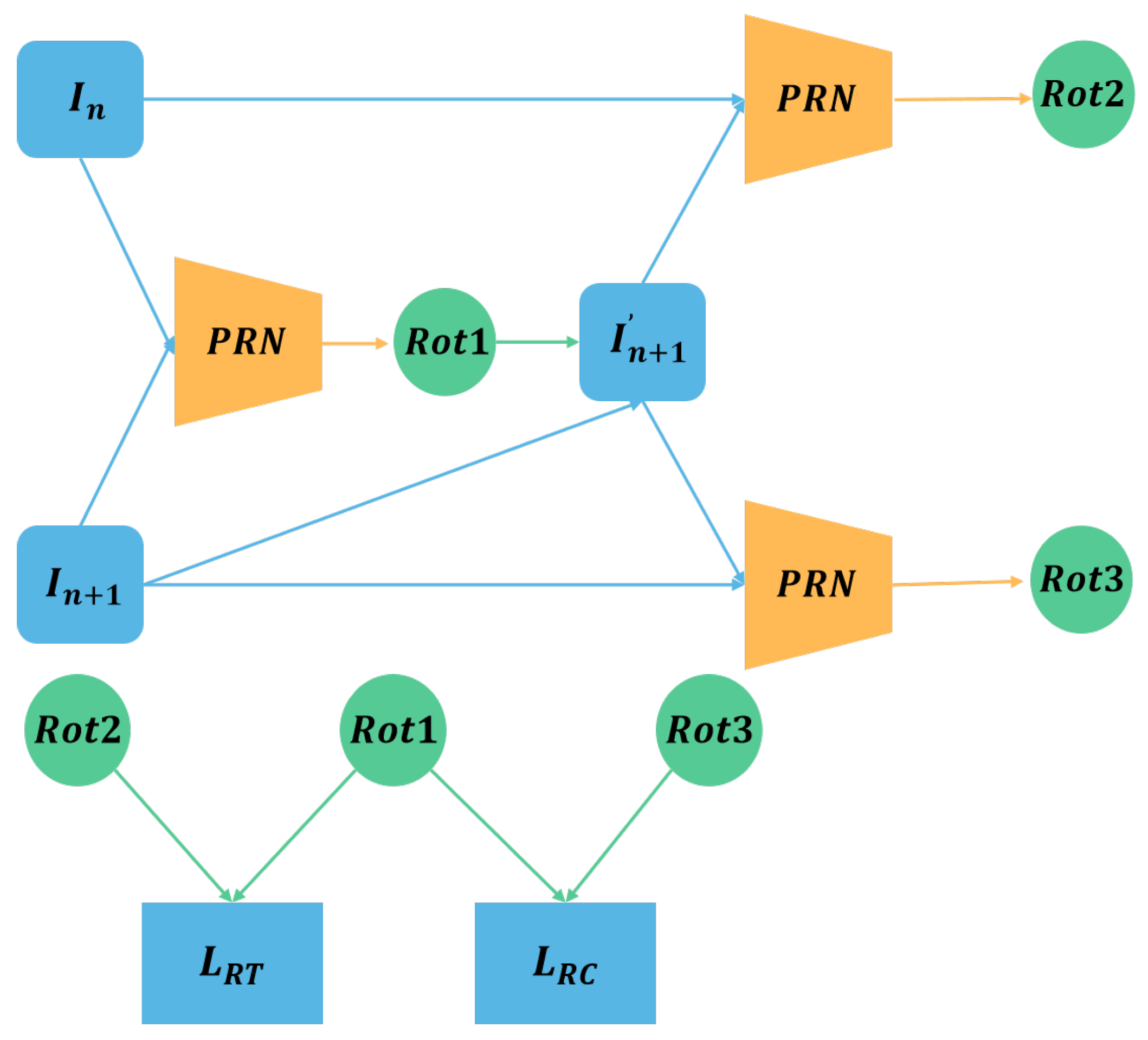
2.3. Pose Rectified Network
2.4. Multiple Loss Functions
2.4.1. Patch-Based Multi-View Photometric Consistency Loss
2.4.2. Manhattan Normal Loss and Co-Planar Loss
2.4.3. PRN Loss
2.4.4. Edge-Aware Smoothness Loss
2.4.5. Total Loss
3. Experimental Results
3.1. Implemention Details
3.2. Dataset and Metrics
3.2.1. NYUv2 [23]
3.2.2. Evaluation Metrics
3.3. Results on the NYUv2 [23] Dataset
3.3.1. Quantitative Results
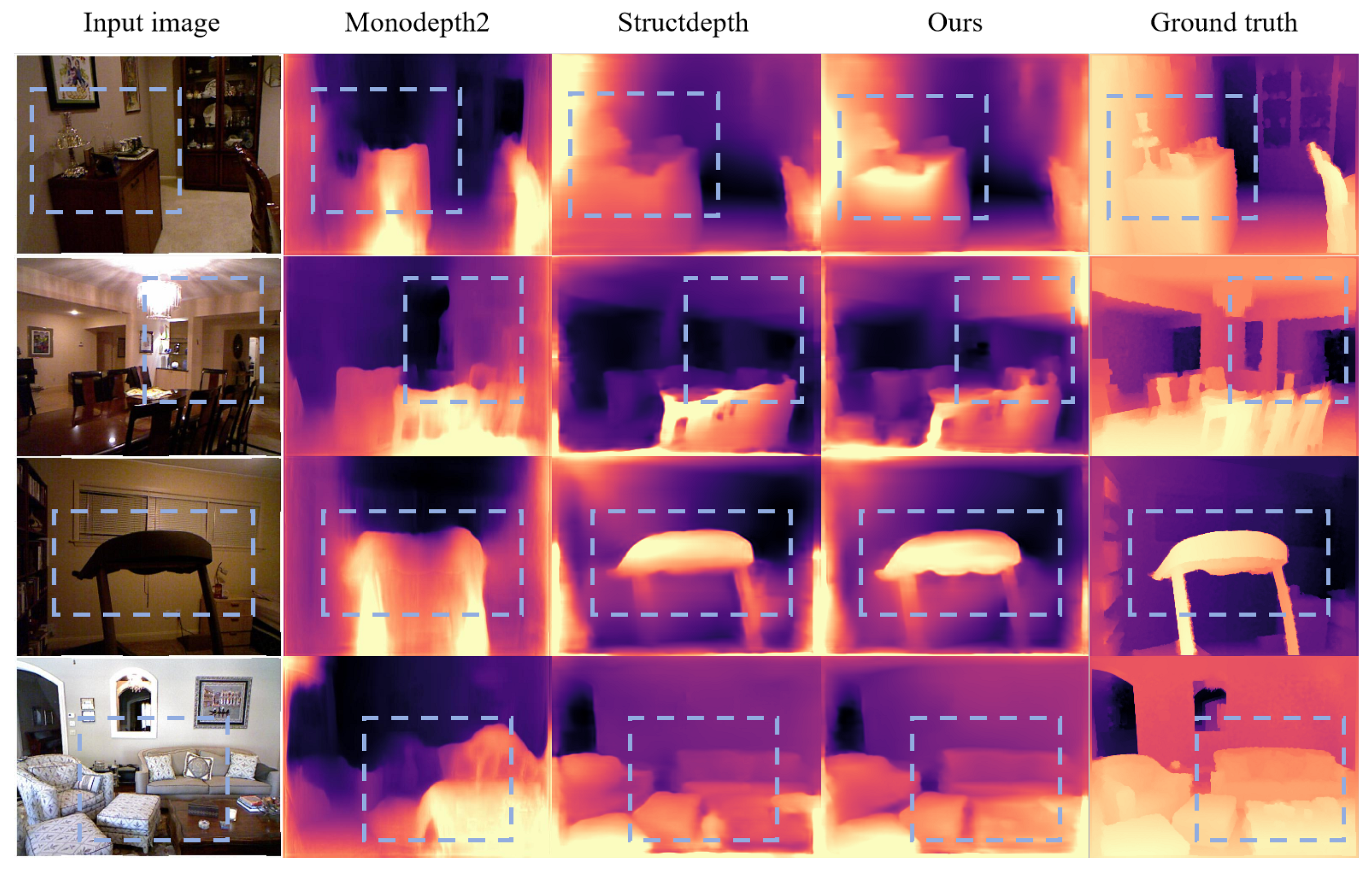
3.3.2. Qualitative Results
3.4. Ablation Studies
3.4.1. Effects of Network Design for the PMIndoor Network
3.4.2. Effects of the Proposed Losses
3.5. Real-Time Performance Comparison
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dong, X.; Garratt, M.A.; Anavatti, S.G.; Abbass, H.A. Towards real-time monocular depth estimation for robotics: A survey. IEEE Trans. Intell. Transp. Syst. 2022, 23, 16940–16961. [Google Scholar] [CrossRef]
- Walz, S.; Gruber, T.; Ritter, W.; Dietmayer, K. Uncertainty depth estimation with gated images for 3D reconstruction. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–8. [Google Scholar]
- Liu, L.; Liu, Y.; Lv, Y.; Xing, J. LANet: Stereo matching network based on linear-attention mechanism for depth estimation optimization in 3D reconstruction of inter-forest scene. Front. Plant Sci. 2022, 13, 978564. [Google Scholar] [CrossRef]
- Xue, F.; Zhuo, G.; Huang, Z.; Fu, W.; Wu, Z.; Ang, M.H. Toward hierarchical self-supervised monocular absolute depth estimation for autonomous driving applications. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 2330–2337. [Google Scholar]
- Kalia, M.; Navab, N.; Salcudean, T. A real-time interactive augmented reality depth estimation technique for surgical robotics. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 8291–8297. [Google Scholar]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. Adv. Neural Inf. Process. Syst. 2014, 27. [Google Scholar]
- Bhat, S.F.; Alhashim, I.; Wonka, P. Adabins: Depth estimation using adaptive bins. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4009–4018. [Google Scholar]
- Li, J.; Klein, R.; Yao, A. A two-streamed network for estimating fine-scaled depth maps from single rgb images. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3372–3380. [Google Scholar]
- Cao, Y.; Wu, Z.; Shen, C. Estimating depth from monocular images as classification using deep fully convolutional residual networks. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 3174–3182. [Google Scholar] [CrossRef]
- Cao, Y.; Zhao, T.; Xian, K.; Shen, C.; Cao, Z.; Xu, S. Monocular depth estimation with augmented ordinal depth relationships. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 2674–2682. [Google Scholar] [CrossRef]
- Song, M.; Lim, S.; Kim, W. Monocular depth estimation using laplacian pyramid-based depth residuals. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 4381–4393. [Google Scholar] [CrossRef]
- Xu, D.; Wang, W.; Tang, H.; Liu, H.; Sebe, N.; Ricci, E. Structured attention guided convolutional neural fields for monocular depth estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3917–3925. [Google Scholar]
- Garg, R.; Bg, V.K.; Carneiro, G.; Reid, I. Unsupervised cnn for single view depth estimation: Geometry to the rescue. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part VIII 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 740–756. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Brostow, G.J. Unsupervised monocular depth estimation with left-right consistency. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 270–279. [Google Scholar]
- Zhou, T.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised learning of depth and ego-motion from video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1851–1858. [Google Scholar]
- Bian, J.; Li, Z.; Wang, N.; Zhan, H.; Shen, C.; Cheng, M.M.; Reid, I. Unsupervised scale-consistent depth and ego-motion learning from monocular video. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Firman, M.; Brostow, G.J. Digging into self-supervised monocular depth estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3828–3838. [Google Scholar]
- Zhou, J.; Wang, Y.; Qin, K.; Zeng, W. Moving indoor: Unsupervised video depth learning in challenging environments. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8618–8627. [Google Scholar]
- Yu, Z.; Jin, L.; Gao, S. P2net: Patch-match and plane-regularization for unsupervised indoor depth estimation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 206–222. [Google Scholar]
- Li, B.; Huang, Y.; Liu, Z.; Zou, D.; Yu, W. StructDepth: Leveraging the structural regularities for self-supervised indoor depth estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 12663–12673. [Google Scholar]
- Li, R.; Ji, P.; Xu, Y.; Bhanu, B. Monoindoor++: Towards better practice of self-supervised monocular depth estimation for indoor environments. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 830–846. [Google Scholar] [CrossRef]
- Bian, J.W.; Zhan, H.; Wang, N.; Chin, T.J.; Shen, C.; Reid, I. Auto-rectify network for unsupervised indoor depth estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 9802–9813. [Google Scholar] [CrossRef] [PubMed]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor segmentation and support inference from rgbd images. In Proceedings of the Computer Vision–ECCV 2012: 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Proceedings, Part V 12. Springer: Berlin/Heidelberg, Germany, 2012; pp. 746–760. [Google Scholar]
- Wang, C.; Buenaposada, J.M.; Zhu, R.; Lucey, S. Learning depth from monocular videos using direct methods. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2022–2030. [Google Scholar]
- Felzenszwalb, P.F.; Huttenlocher, D.P. Efficient graph-based image segmentation. Int. J. Comput. Vis. 2004, 59, 167–181. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Zhao, W.; Liu, S.; Shu, Y.; Liu, Y.J. Towards better generalization: Joint depth-pose learning without posenet. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 9151–9161. [Google Scholar]
- Saxena, A.; Sun, M.; Ng, A.Y. Make3d: Learning 3d scene structure from a single still image. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 31, 824–840. [Google Scholar] [CrossRef]
- Liu, M.; Salzmann, M.; He, X. Discrete-continuous depth estimation from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 716–723. [Google Scholar]
- Wang, P.; Shen, X.; Lin, Z.; Cohen, S.; Price, B.; Yuille, A.L. Towards unified depth and semantic prediction from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2800–2809. [Google Scholar]
- Eigen, D.; Fergus, R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2650–2658. [Google Scholar]
- Chakrabarti, A.; Shao, J.; Shakhnarovich, G. Depth from a single image by harmonizing overcomplete local network predictions. Adv. Neural Inf. Process. Syst. 2016, 29. [Google Scholar]
- Laina, I.; Rupprecht, C.; Belagiannis, V.; Tombari, F.; Navab, N. Deeper depth prediction with fully convolutional residual networks. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 239–248. [Google Scholar]
- Yin, W.; Liu, Y.; Shen, C.; Yan, Y. Enforcing geometric constraints of virtual normal for depth prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5684–5693. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Supervision | Error ↓ | Accuracy ↑ | ||||
|---|---|---|---|---|---|---|---|
| AbsRel | Log10 | RMSE | |||||
| Make3D [28] | ✓ | 0.349 | - | 1.214 | 44.7 | 74.5 | 89.7 |
| Liu et al. [29] | ✓ | 0.335 | 0.127 | 1.060 | - | - | - |
| Wang et al. [30] | ✓ | 0.220 | 0.094 | 0.745 | 60.5 | 89.0 | 97.0 |
| Eigen et al. [31] | ✓ | 0.158 | - | 0.641 | 76.9 | 95.0 | 98.8 |
| Chakrabarti et al. [32] | ✓ | 0.149 | - | 0.620 | 80.6 | 95.8 | 98.7 |
| Li et al. [8] | ✓ | 0.143 | 0.063 | 0.635 | 78.8 | 95.8 | 99.1 |
| Laina et al. [33] | ✓ | 0.127 | 0.055 | 0.573 | 81.1 | 95.3 | 98.8 |
| VNL [34] | ✓ | 0.108 | 0.048 | 0.416 | 87.5 | 97.6 | 99.4 |
| MovingIndoor [18] | ✗ | 0.208 | 0.086 | 0.712 | 67.4 | 90.0 | 96.8 |
| TrainFlow [27] | ✗ | 0.189 | 0.079 | 0.686 | 70.1 | 91.2 | 97.8 |
| Monodepth2 [17] | ✗ | 0.161 | 0.068 | 0.600 | 77.1 | 94.8 | 98.7 |
| P2Net(3-frame) [19] | ✗ | 0.159 | 0.068 | 0.599 | 77.2 | 94.2 | 98.4 |
| P2Net(5-frame) [19] | ✗ | 0.150 | 0.064 | 0.561 | 79.6 | 94.8 | 98.6 |
| Structdepth [20] | ✗ | 0.142 | 0.060 | 0.540 | 81.3 | 95.4 | 98.8 |
| Baseline (P2Net [19] w/o planar loss) | ✗ | 0.166 | - | 0.612 | 75.8 | 94.5 | 98.5 |
| PMIndoor (Ours) | ✗ | 0.138 | 0.059 | 0.528 | 82.0 | 95.6 | 98.9 |
| Methods (w/o PRN Loss) | Error ↓ | Accuracy ↑ | ||||
|---|---|---|---|---|---|---|
| AbsRel | Log10 | RMSE | ||||
| Original | 0.142 | 0.060 | 0.540 | 81.3 | 95.4 | 98.8 |
| PRN-Only | 0.141 | 0.060 | 0.538 | 81.4 | 95.5 | 98.8 |
| MHSA-Only | 0.140 | 0.059 | 0.533 | 81.8 | 95.5 | 98.9 |
| Ours (full) | 0.138 | 0.059 | 0.530 | 82.1 | 95.6 | 98.9 |
| Methods | Error ↓ | Accuracy ↑ | ||||
|---|---|---|---|---|---|---|
| AbsRel | Log10 | RMSE | ||||
| Original | 0.147 | 0.062 | 0.560 | 80.6 | 95.3 | 98.8 |
| PRN loss-Only | 0.146 | 0.062 | 0.556 | 80.7 | 95.4 | 98.8 |
| Manhattan loss + Co-planar loss-Only | 0.138 | 0.059 | 0.530 | 82.1 | 95.6 | 98.9 |
| Ours (full loss) | 0.138 | 0.059 | 0.528 | 82.0 | 95.6 | 98.9 |
| Methods | FPS | Error ↓ | Accuracy ↑ | ||||
|---|---|---|---|---|---|---|---|
| AbsRel | Log10 | RMSE | |||||
| Monodepth2 [17] | 45.2 | 0.161 | 0.068 | 0.600 | 77.1 | 94.8 | 98.7 |
| Structdepth [20] | 55.8 | 0.142 | 0.060 | 0.540 | 81.3 | 95.4 | 98.8 |
| PMIndoor (Ours) | 55.2 | 0.138 | 0.059 | 0.528 | 82.0 | 95.6 | 98.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.; Zhu, Y.; Liu, H. PMIndoor: Pose Rectified Network and Multiple Loss Functions for Self-Supervised Monocular Indoor Depth Estimation. Sensors 2023, 23, 8821. https://doi.org/10.3390/s23218821
Chen S, Zhu Y, Liu H. PMIndoor: Pose Rectified Network and Multiple Loss Functions for Self-Supervised Monocular Indoor Depth Estimation. Sensors. 2023; 23(21):8821. https://doi.org/10.3390/s23218821
Chicago/Turabian StyleChen, Siyu, Ying Zhu, and Hong Liu. 2023. "PMIndoor: Pose Rectified Network and Multiple Loss Functions for Self-Supervised Monocular Indoor Depth Estimation" Sensors 23, no. 21: 8821. https://doi.org/10.3390/s23218821
APA StyleChen, S., Zhu, Y., & Liu, H. (2023). PMIndoor: Pose Rectified Network and Multiple Loss Functions for Self-Supervised Monocular Indoor Depth Estimation. Sensors, 23(21), 8821. https://doi.org/10.3390/s23218821