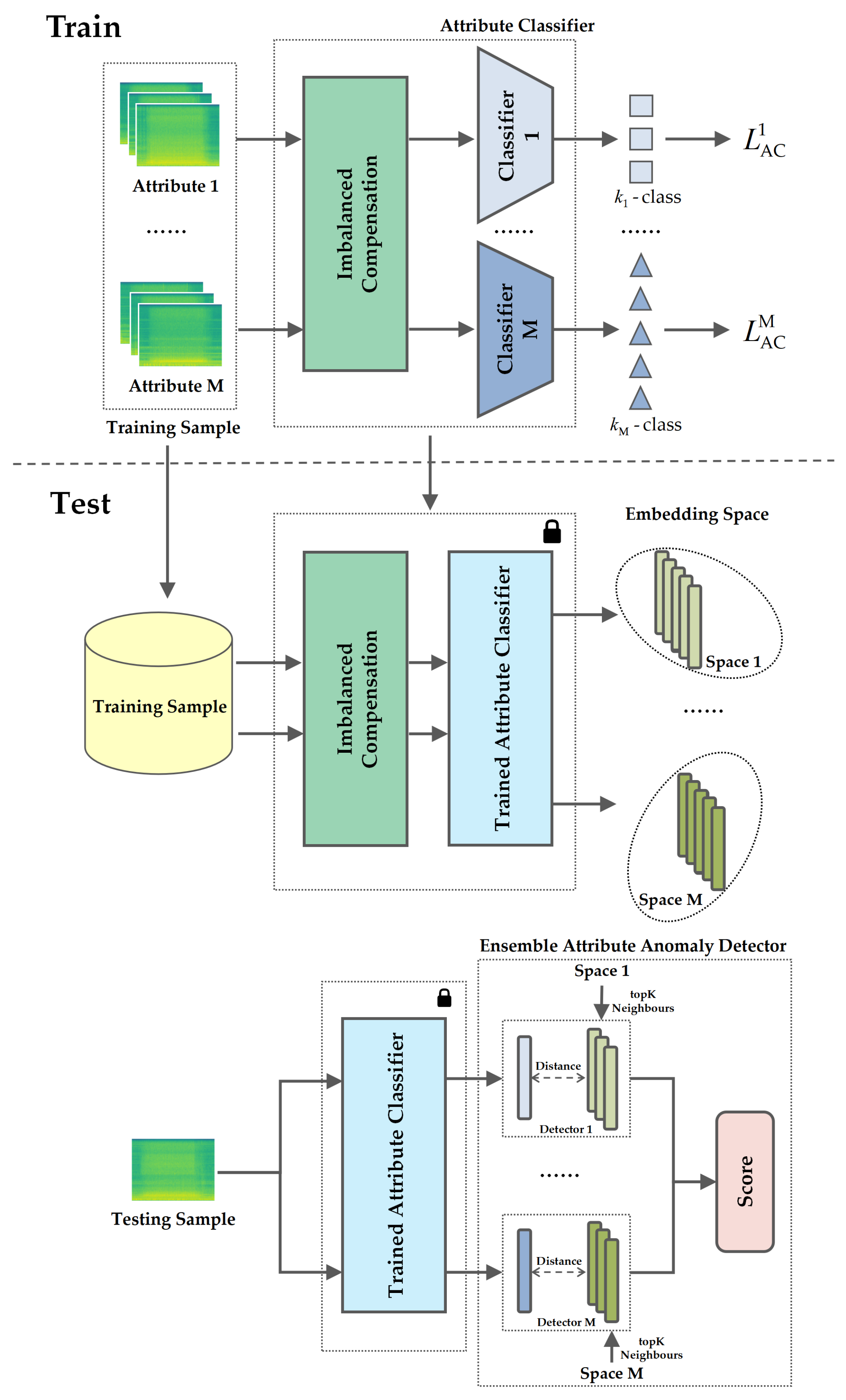
The AIC framework we propose contains an imbalanced compensation module,
M attribute classifiers, and an ensemble attribute anomaly detector. The overview of the overall framework is shown in
Figure 1. The overall framework consists of training and testing stages. First, the raw data are augmented via imbalanced compensation separately for each attribute. In the training stage, a classifier is trained for the augmented data of each attribute with cross-entropy loss. In the testing stage, the augmented data are fed into the trained classifiers to obtain embeddings, with each attribute corresponding to one embedding space. Then, the embedding of the test samples is extracted through the trained classifier, and KNN is used to calculate the score in the ensemble attribute anomaly detector.
2.1. Attribute Classifier
Although the previous work using machine ID for classification achieved good results [
1,
2], it is often more limited in practical applications, such as only one machine is working. In this case, strong prior knowledge such as machine ID cannot be used. Nevertheless, machines still have weak prior knowledge that is easy to obtain, such as attributes in
Table 1; both the ‘ToyCar’ and ‘ToyTrain’ have three types of weak attributes. Therefore, in this study, we propose to train the attribute classifier using such weak prior knowledge as attributes.
In real-world applications, different attributes of a machine may work under different operating status. These statuses can be easily collected and labeled. For example, as illustrated in
Table 2, in the ToyCar dataset provided by the DCASE2023 Challenge, the attribute ‘Mic’ has two types of operating status: ‘1’ and ‘2’. These status labels can be used to train an anomaly classifier, allowing it to distinguish between different operating status for each attribute. This approach helps the anomaly classifier learn the details of the training dataset more comprehensively and deeply, similar to observing the same object from different perspectives. The operating status information provided by DCASE [
21,
22] naturally accompanies machine operation and is readily accessible.
Similar to previous machine ID classifiers [
1], in our attribute classifier, we adopt the cross-entropy loss to classify each operating status of each attribute of each machine. As shown in
Figure 1 training classifier step, and both of
Table 1 and
Table 2, this can be described as training
M classifiers for
M attributes, where each classifier performs an
-class classification task and
represents the total distinct types of operating status for the
m-th attribute. We use ResNet18 [
23] as the backbone encoder of the classifier to obtain the embedding of each attribute. The proposed
m-th attribute classifier (AC) is trained with the cross-entropy loss function as
where
N means the total input samples of the
m-th attribute,
,
represent the
i-th input sample and its
k-th operating status in attribute
m.
is the softmax output of the encoder with parameters
. As depicted in
Figure 1 training detector step, following the independent training of the
M attribute classifiers, we correspondingly learn
M anomaly detectors, with each detector associated with one of the
M-trained attribute classifiers. We utilize KNN as the anomaly detector, with the embeddings extracted by the trained classifiers used as the training data. During testing, the test sample is passed through each of the
M-trained classifiers to obtain
M embeddings, which are then fed into their corresponding
M anomaly detectors to produce anomaly scores. The final aggregated anomaly score is obtained by taking the harmonic mean of the individual scores from each detector.
However, classifiers trained solely on operating status information for machine attributes often struggle to converge. Taking ToyCar dataset as an example, in
Table 2, the information of training samples is expressed in the form of ‘Category: #samples’, and we can see that different attributes have varying numbers of operating status categories. For example, ‘Car model’ has 10 categories from A1 to E2, ‘Speed’ has 5 categories, controlled by voltage levels from 2.8 V to 4.0 V, and ‘Mic’ includes 2 categories, 1 and 2. Additionally, the number of samples for each operating status category is highly unbalanced. These factors make machine attributes weaker prior knowledge compared to machine IDs and pose several challenges with using operating status alone for training attribute classifiers: (1) the inconsistency in the number of attributes and operating status categories across different types of machines makes it difficult to establish consistent classification boundaries; (2) the severe sample imbalance within the same attribute and operating status category affects the classifier’s ability to accurately characterize normal samples; (3) during testing, the machine attributes and their corresponding operating status are unknown, further complicating the classification process. As a result, classifiers trained only on operating status are prone to misclassifying normal unseen samples as anomalies. To address this issue, we need to propose a method that strengthens the weak attribute knowledge as prior information in anomaly detection models.
2.2. Imbalanced Compensation
To solve the problem of severe unbalanced samples among different operating status shown in
Table 2, in this section, we propose an imbalanced compensation module to enhance the proposed attribute classifier training. The module mainly includes two parts: (1) maximum expansion uniform sampling, and (2) robust data transformation.
Figure 2 illustrates the schematic diagram of the effects of imbalanced compensation on acoustic-sensing-based ASD training data.
In
Figure 2, different symbol shapes denote different categories with originally imbalanced number of samples. After maximum expansion and uniform sampling, the categories are balanced in terms of sample counts. Boundary shape changes following robust data transformation signify altered data distributions. In the first step, we identify the category with the maximum number of samples and expand all other categories to this level via oversampling. While this balances the quantities, the original data distributions remain unchanged, impeding effective training of the attribute classifier. Therefore, we subsequently apply robust data transformations, randomly augmenting the balanced data with 4 different techniques to alter the data distribution and simulate varied recording conditions. This enables successful training of the attribute classifier and enhances model robustness. In summary, our proposed pipeline tackles data imbalance through expansion and synthesizes robustness via data transformation, enabling learning from skewed real-world data.
The detail algorithm of our proposed imbalanced compensation module is presented in Algorithm 1. Given an unbalanced dataset with all
N samples for one attribute of one machine,
, which has
samples, it is classified into the
-th category of operating status for each attribute, satisfying
. With the
varying,
takes different values, resulting in an imbalance of data in each attribute.
| Algorithm 1 Proposed imbalanced compensation method in m-th attribute |
| Input: An unbalanced dataset of all N samples in m-th attribute, |
| Output: A balanced dataset of R samples after imbalanced compensation (IC) in m-th attribute, |
| 1. Find the maximum count of operating status |
| 2: Calculate the sample increment for each operating status |
| 3: Expand sample numbers to |
| 4: Get a balanced dataset after maximum expansion uniform sampling (MEUS) |
| 5: Sample R times in |
| 6: for in do |
| 7: |
| 8: end for |
| 9: Obtain the final dataset after imbalanced compensation |
Maximum Expansion Uniform Sampling: As shown in
Figure 2, we first introduce the maximum expansion uniform sampling to expand the original dataset to a balanced one. When we apply maximum expansion uniform sampling, we take the maximum value of
, set it to
. Then, for the
samples in each operating status, we copy the data to increase the number of samples defined as
. At this time, the total number of samples is expanded to
, and the number of samples among each operating status reaches balance. The original samples
can be represented as
after applying maximum expansion uniform sampling. Therefore, maximum expansion uniform sampling solves the problem of severe imbalance of training samples, allowing the classifier training to converge.
For example, the machine ToyCar has three attributes: ‘Car model’, ‘Speed’, and ‘Mic’. We train three separate classifiers for this machine. For the ‘Car model’ attribute, there are 10 categories ‘C1’–‘E1’ with extremely imbalanced quantities as shown in
Table 2. With imbalanced compensation, we first apply maximum expansion uniform sampling. Specifically, we take the number of samples in the largest category ‘C1’, which is 215. Then, we resample each category to have 215 samples, making the number of samples balanced across categories. Similarly, we apply the same procedure to the other two attributes of ToyCar, balancing the number of samples for each category within every attribute.
Robust Data Transformation: Based on the enhanced maximum expansion uniform sampling, we then perform robust data transformation to augment the environment robustness of training data for improving the generalization ability of the resulting attribute classifier model. When we apply robust data transformation, we first sample R times after maximum expansion uniform sampling according to the law of large numbers. When R is large enough, the distribution of samples after R sampling is the same as the balanced sample distribution after maximum expansion uniform sampling. At the same time, each sampling is accompanied by 4 data augmentations, which are
AddGaussianNoise: Directly adding a noise signal obeying a zero-mean Gaussian distribution to the original audio signal in the time domain. In practical environments, many background noises can be regarded as additive noise. After such noise addition to the audio signal, it can capture various and complicate acoustic characteristics of real environments.
TimeStretch: Changing the speed of audio without altering its pitch by a pre-defined rate. Here, we randomly applied rates in the range of [0.8, 1.25].
PitchShift: Randomly increased or decreased the original pitch. Here, we vary the pitch by pre-defined semitones in the range of [, 4].
TimeShift: Shifts the entire audio signal forward or backward. Here, the shift range was [, 0.5] of the total signal length.
The above augmentations are represented by , , , and , respectively. Specifically, these four data augmentations are applied to each sampled sample with a 50% probability, distorting the distribution after sampling. To some extent, robust data transformation simulates unknown samples and enhances the robustness of the classifier, making it less prone to errors when classifying completely unknown samples in the test set. In summary, the samples after robust data transformation can be expressed as .
Still taking ToyCar as an example, after applying maximum expansion uniform sampling, the number of samples is balanced across categories within each attribute. However, merely having a balanced quantity does not mean the data distribution is suitable for training classifiers. Therefore, we apply robust data transformation to transform the data. For each sample, there is a 50% chance to be applied with transformations of ‘AddGaussianNoise’, ‘TimeStretch’, ‘PitchShift’, and ‘TimeShift’, which can be combined. After applying robust data transformation to every sample, we discard the original samples. This completes imbalanced compensation.
In summary, the application of maximum expansion uniform sampling balanced the extremely imbalanced data between operating status. After maximum expansion uniform sampling, robust data transformation was applied, and each sampling was accompanied by 4 types of audio time domain conversion, which simulated various noises in real situations to some extent and improved the robustness of the model at the data level. In addition, the oversampling technique increased the sample size and achieved class balance, which solved the problem that the classifier was difficult to train.
2.3. Ensemble Attribute Anomaly Detector
Currently, in the field of anomaly detection, probability-based confidence methods [
24,
25] have been widely used. Specifically, this kind of method trains a classifier on normal samples for classification. During testing, normal samples will be classified into known categories by the classifier, while abnormal samples are difficult to distinguish. Intuitively, abnormal samples will receive a lower confidence score. However, incorrectly classifying samples during testing has a catastrophic impact on the performance of anomaly detection [
26]. In addition, this method relies on the quality of model training, but, in practical use, the model is often overfitting, which will also affect the performance of anomaly detection.
Instead, we propose ensemble attribute anomaly detector. The key is to combine the traditional machine learning algorithm KNN with the classifier obtained from deep learning to improve the fault tolerance and robustness of the model for anomaly detection. The detailed algorithm of our proposed module is presented in Algorithm 2. Utilizing the data after imbalanced compensation, which are also used to train the classifiers, we train
M separate KNN models. Specifically, the embeddings extracted from the trained
M classifiers are leveraged as quality training data for each KNN. After training a KNN search tree for each model, test embeddings are extracted by passing the test sample through the corresponding classifier. The trained
m-th KNN search tree is then utilized to find the
nearest neighbors of the test embedding, constructing the set
. Subsequently, the Euclidean distance
between
and the samples in
is computed to obtain the distance matrix
. The anomaly score is calculated as the maximum value in the distance matrix
| Algorithm 2 KNN for anomaly detection from the perspective of the m-th attribute |
| Input: Train data: , Test data: , Trained m-th classifier |
| Output: Anomaly score for test sample |
| 1: Extract embeddings by the m-th classifier from |
| 2: Extract embedding by the m-th classifier from |
| 3: Construct KNN search from |
| 4: Find nearest neighbors of using |
| 5: Let be the set comprising the nearest neighbors of |
| 6: Compute distance between and samples in |
| 7: Obtain score set of test distance |
| 8: return Anomaly score |
Finally, we take the mean of the results obtained for each attribute in the score domain to obtain the final ensemble anomaly value
Although KNN is a classic machine learning method, it is prone to curse of dimensionality when dealing with high-dimensional data, such as audio in this work. Naturally, we thought of using the outstanding feature extraction capability of deep neural networks to reduce the dimension of audio data to a low-dimensional space that KNN can characterize. Therefore, we use the attribute classifier mentioned above as a proxy task for the anomaly detection task and obtain supervision by distinguishing different operating status. After the training is completed, in the latent space, the samples of each operating status will gather together, while abnormal samples will be exposed because they are difficult to distinguish. Notably, our work trains multiple classifiers for each attribute, which enables each classifier to distinguish abnormal samples from different attribute perspectives. Such an operation improves the fault tolerance of anomaly detection. Even if one classifier makes a mistake, the results of other classifiers can compensate the errors.
Taking ToyCar as an example, after applying the imbalanced compensation module, we pretrain three separate classifiers for the three attributes, respectively. Meanwhile, using the training data after imbalanced compensation, three different embeddings are extracted via the three classifiers, which we term as embedding spaces. During testing, a test sample is fed into the three pretrained classifiers to obtain three test embeddings, each corresponding to one embedding space. Then, we apply a KNN algorithm to retrieve the nearest neighbors for each test embedding in its embedding space. The Euclidean distances between the test embedding and its neighbors are calculated. After obtaining the three sets of Euclidean distances, we take their average as the final anomaly score.
Therefore, for anomaly detection, the three different attributes provide three distinct detection perspectives for the same test sample. Fusing their scores allows the three perspectives to complement each other. Meanwhile, the imbalanced compensation technique enables classifier training and enhances classifier robustness through data augmentation. The resultant high-quality embeddings together with the proposed ensemble attribute anomaly detector boost anomaly detection performance.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}