





RST: Rough Set Transformer for Point Cloud Learning

Abstract
:1. Introduction
- 1
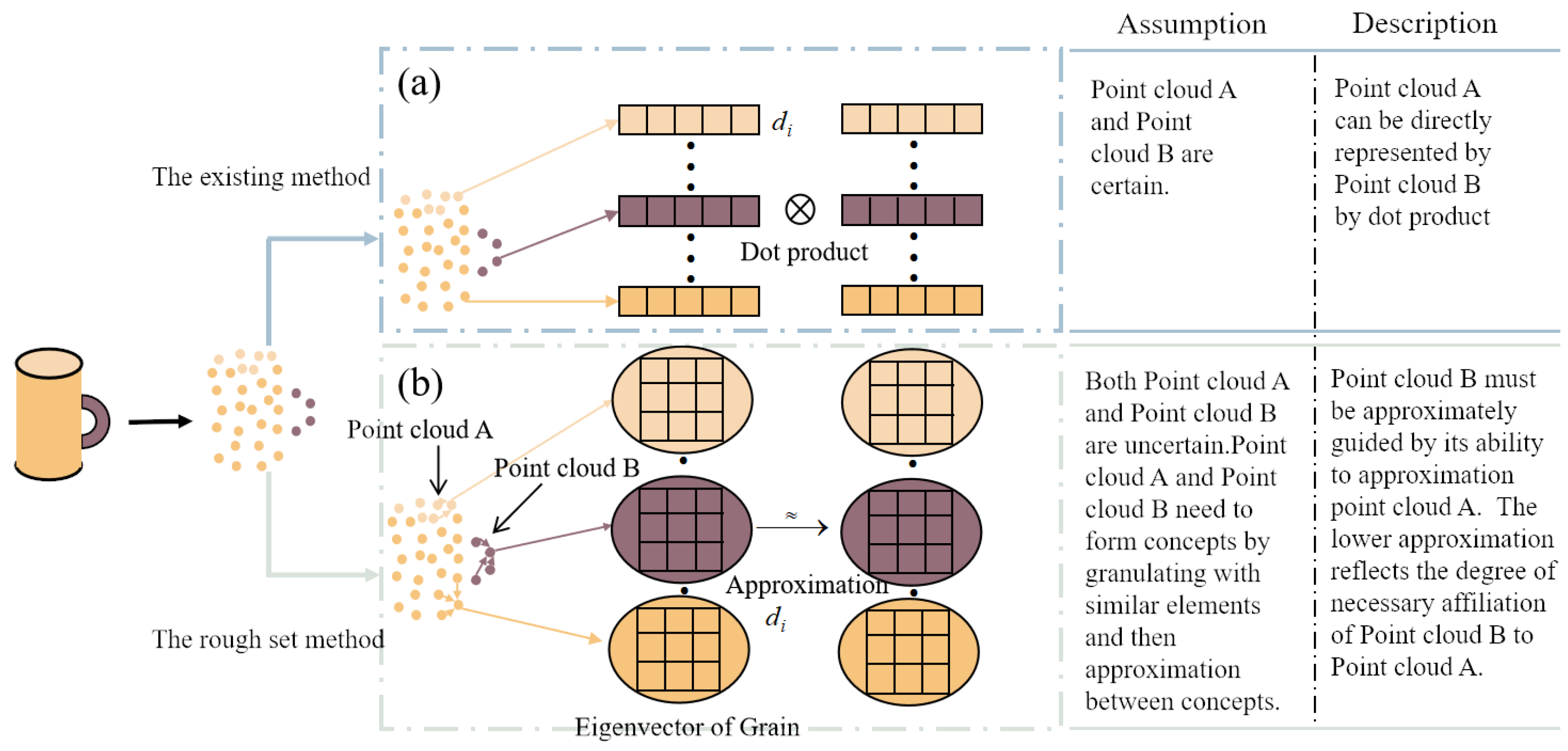
- We redefine the granulation and lower-approximation expressions for neighborhood rough set to conform to the fundamental definition of rough sets and enhance their applicability in deep learning. Through empirical investigation, we have determined that this marks the initial fusion of rough set theory and deep learning network models in the context of point cloud learning.
- 2
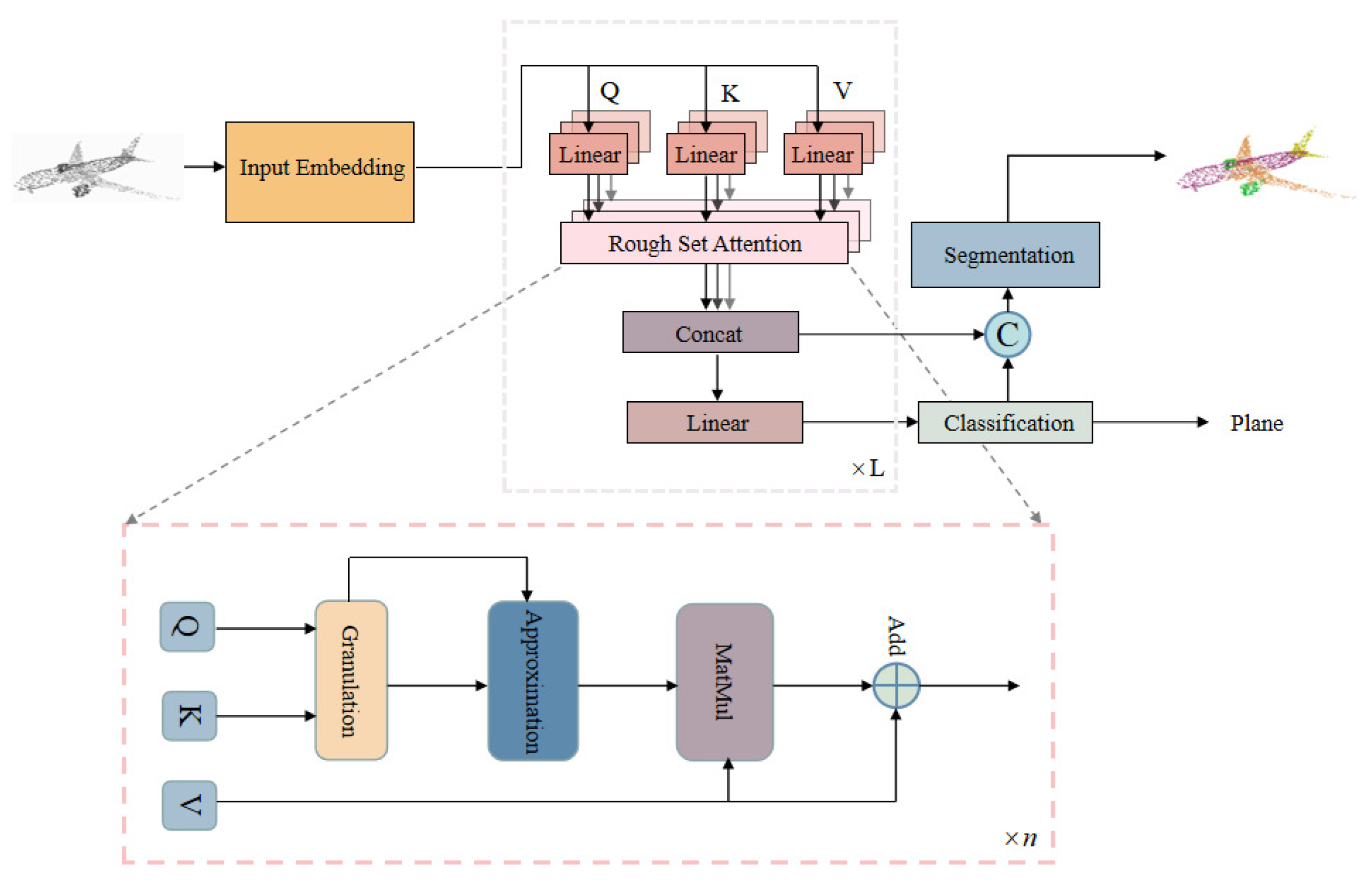
- We propose a novel rough set-based attention mechanism to replace the dot product attention, thereby constructing a transformer network structure (RST) tailored for point cloud learning. This network directly takes point cloud data as inputs and extracts features using multi-head rough set attention. In comparison to the traditional transformer model, the RST network exhibits a stronger ability to provide an objective relationship guidance for uncertain point cloud data.
- 3
- The model is evaluated through point cloud classification and segmentation experiments using the ModelNet40 [9] and ShapeNet [10] datasets. All the results demonstrate that our method outperforms the most advanced networks. Additionally, we conduct a visual analysis to elucidate the improvements over traditional attention mechanisms. The resource codes are validated at https://github.com/WinnieSunning/RST, (accessed on 7 November 2023).
2. Related Work
2.1. Traditional Point Cloud Learning Methods
2.2. Transformer-Based Point Cloud Learning Methods
2.3. Other Advanced Point Cloud Learning Methods
3. Method
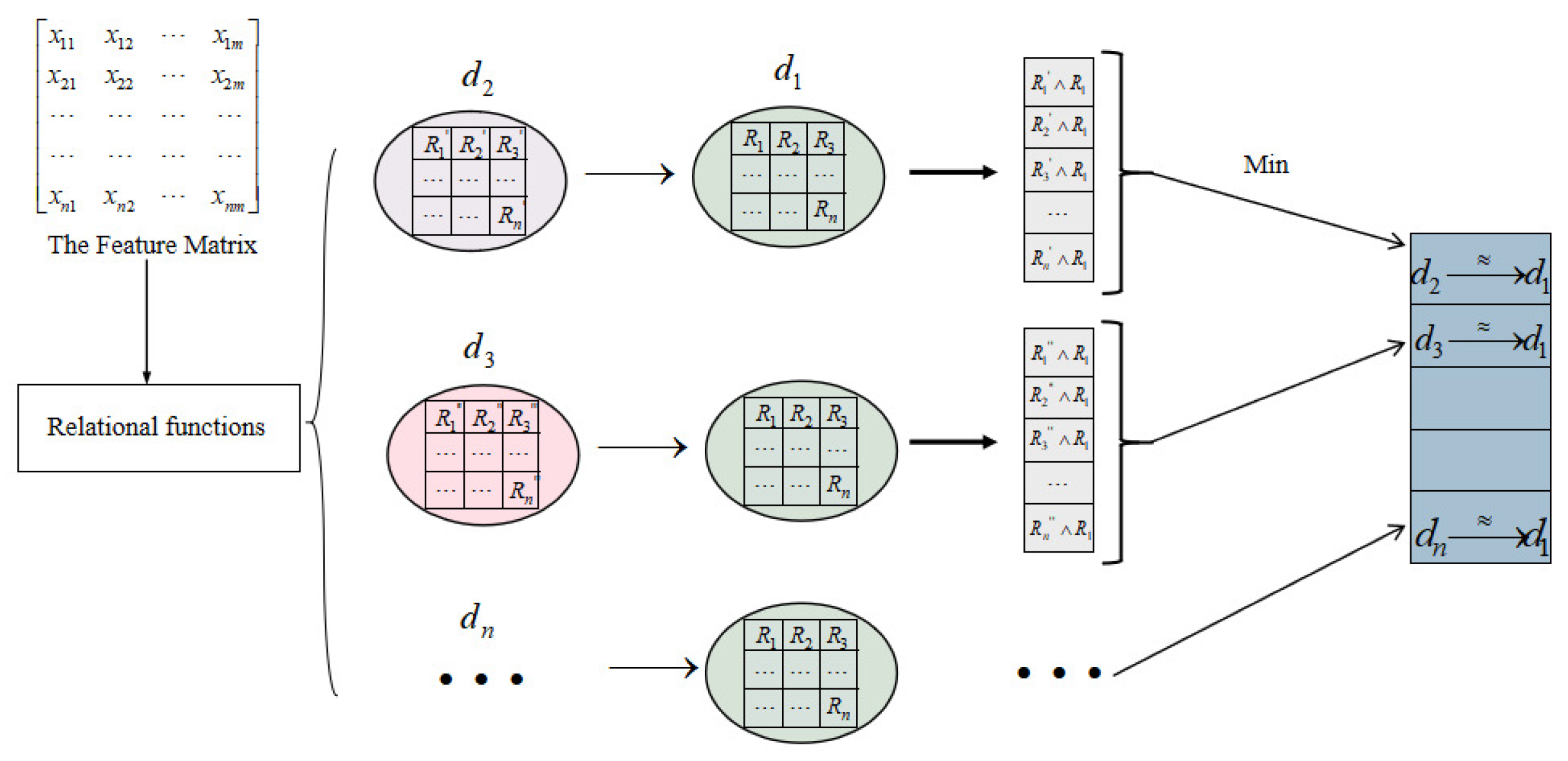
3.1. The Rough Set-Based Attention Mechanism
| Algorithm 1 Approximate guided representation methods based on rough set |
|
3.2. Transformer Network for Point Cloud Learning
4. Experiments
4.1. Classification on ModelNet40
4.2. Part Segmentation on ShapeNet
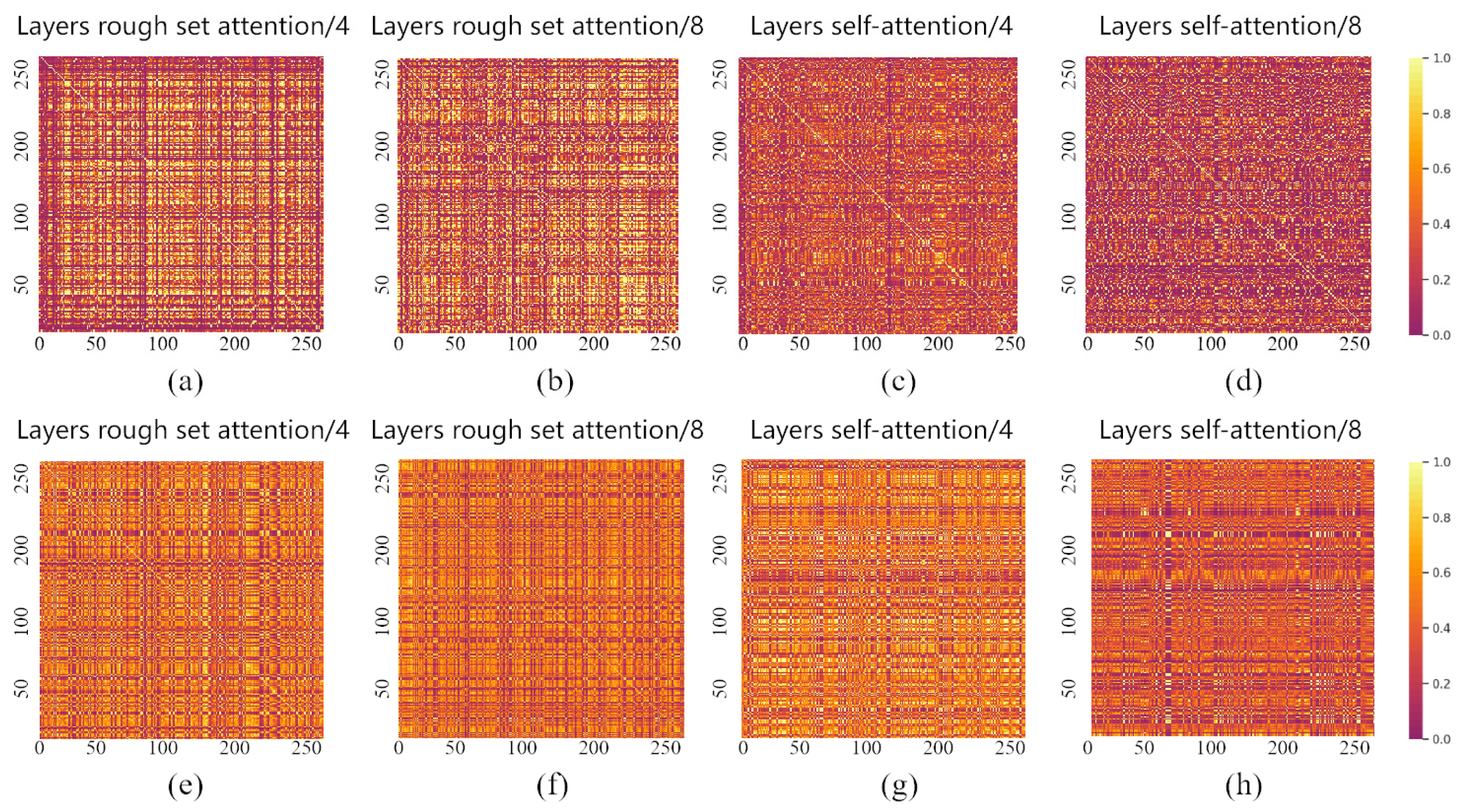
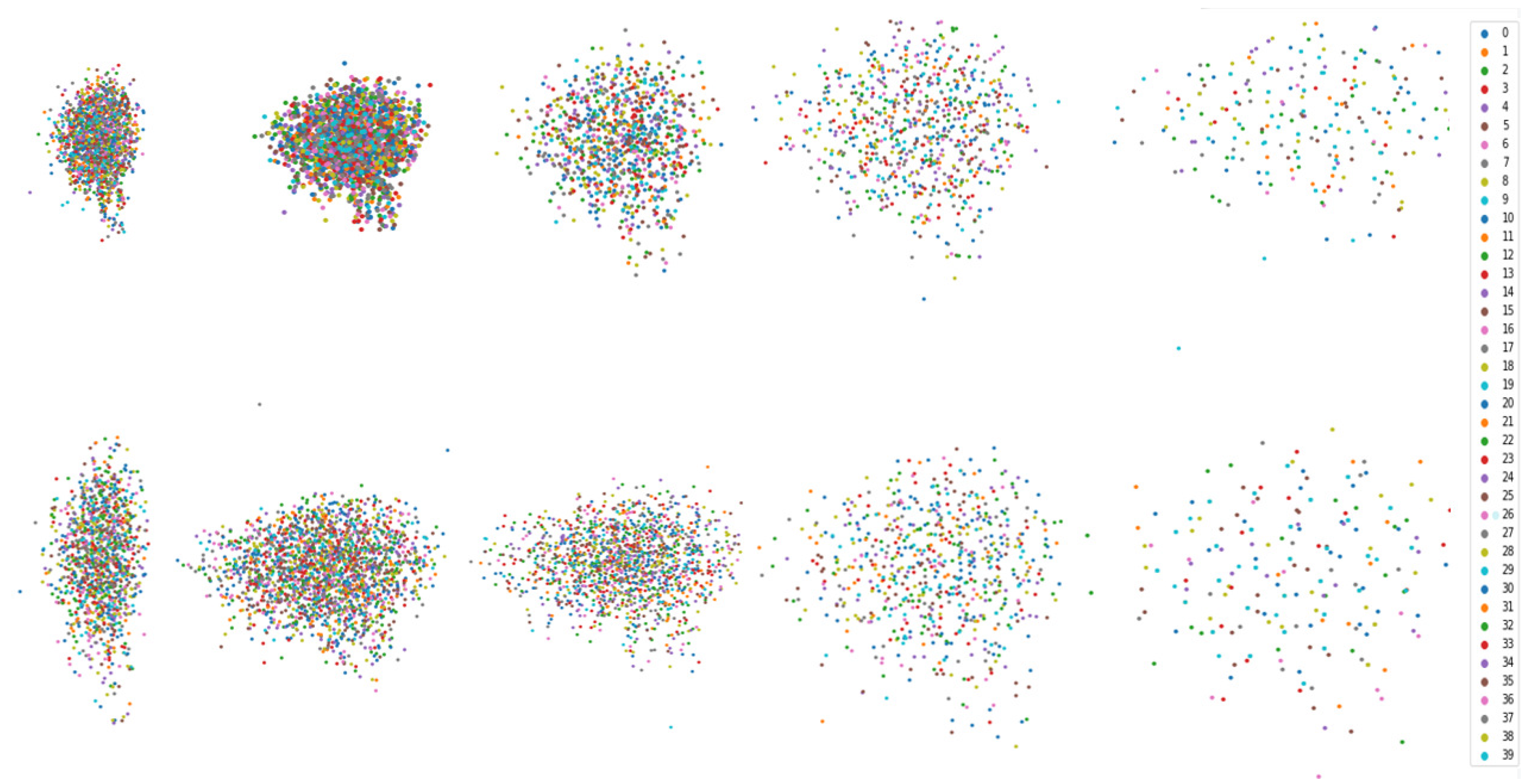
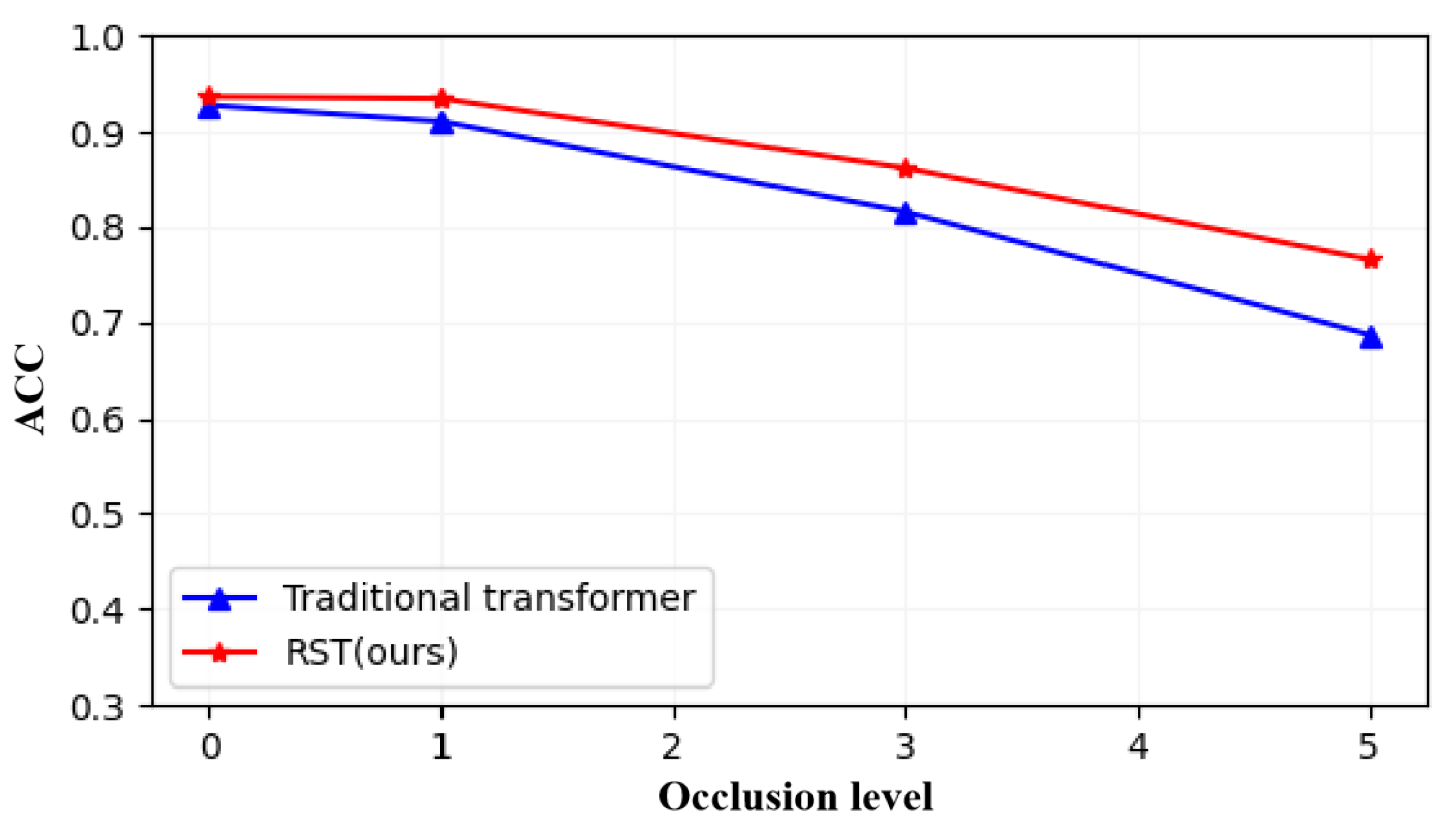
4.3. Visualization Analysis Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, Y.; Zuo, Y.; Du, Z.; Song, X.; Luo, T.; Hong, X.; Wu, J. MInet: A Novel Network Model for Point Cloud Processing by Integrating Multi-Modal Information. Sensors 2023, 23, 6327. [Google Scholar] [CrossRef] [PubMed]
- Villa, F.; Severini, F.; Madonini, F.; Zappa, F. SPADs and SiPMs arrays for long-range high-speed light detection and ranging(LiDAR). Sensors 2021, 21, 3839. [Google Scholar] [CrossRef] [PubMed]
- Xie, Z.; Chen, J.; Peng, B. Point clouds learning with attention-based graph convolution networks. Neurocomputing 2020, 402, 245–255. [Google Scholar] [CrossRef]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. Pointcnn: Convolution on x-transformed points. In Proceedings of the Annual Conference on Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Atzmon, M.; Maron, H.; Lipman, Y.; Feldman, Y.A. Point Convolutional Neural Networks by Extension Operators. ACM Trans. Graph. 2018, 37, 1–12. [Google Scholar] [CrossRef]
- Wu, W.; Qi, Z.; Li, F. PointConv: Deep Convolutional Networks on 3D Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9621–9630. [Google Scholar]
- Pattaraintakorn, P.; Cercone, N. Integrating rough set theory and medical applications. Appl. Math. Lett. 2008, 21, 400–403. [Google Scholar] [CrossRef]
- Zhao, F.F.; Pang, B.; Mi, J.S. A new approach to generalized neighborhood system-based rough sets via convex structures and convex matroids. Inf. Sci. 2022, 612, 1187–1205. [Google Scholar] [CrossRef]
- Wu, Z. 3D ShapeNets: A Deep Representation for Volumetric Shapes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 1912–1920. [Google Scholar]
- Yi, L. A scalable active framework for region annotation in 3D shape collections. ACM Trans. Graph. 2016, 35, 1–12. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5099–5108. [Google Scholar]
- Peyghambarzadeh, S.M.M.; Azizmalayeri, F.; Khotanlou, H.; Salarpour, A. Point-PlaneNet: Plane kernel based convolutional neural network for point clouds analysis. Digit. Signal Process. 2020, 98, 102633. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic graph cnn for learning on point clouds. ACM Trans. Graph. 2020, 38, 1–12. [Google Scholar] [CrossRef]
- Wijaya, K.T.; Paek, D.; Kong, S. Advanced feature learning on point clouds using multi-resolution features and learnable pooling. arXiv 2022, arXiv:2205.09962. [Google Scholar]
- Boulch, A. ConvPoint: Continuous convolutions for point cloud processing. Comput. Graph. 2020, 88, 24–34. [Google Scholar] [CrossRef]
- Zhao, H. Point transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 16259–16268. [Google Scholar]
- Guo, M.H.; Cai, J.X.; Liu, Z.N.; Mu, T.J.; Martin, R.R.; Hu, S.M. Pct: Point cloud transformer. Comput. Vis. Media 2021, 7, 187–199. [Google Scholar] [CrossRef]
- Han, X.; He, Z.; Chen, J.; Xiao, G. 3CROSSNet: Cross-level cross-scale cross-attention network for point cloud representation. IEEE Robot. Autom. Lett. 2022, 7, 3718–3725. [Google Scholar] [CrossRef]
- Xinyi, L.; Yinlong, L.; Yan, X.; Venkatnarayanan, L.; Hu, C.; Feihu, Z.; Uwe, S.; Alois, K. Fast and deterministic (3+1)DOF point set registration with gravity prior. ISPRS J. Photogramm. Remote. Sens. 2023, 199, 118–132. [Google Scholar]
- Xia, Y.; Xu, Y.; Li, S.; Wang, R.; Du, J.; Cremers, D.; Stilla, U. SOE-Net: A Self-Attention and Orientation Encoding Network for Point Cloud based Place Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Kuala Lumpur, Malaysia, 18–20 December 2021; pp. 11343–11352. [Google Scholar]
- Wu, X.; Tian, Z.; Wen, X.; Peng, B.; Liu, X.; Yu, K.; Zhao, H. Towards Large-scale 3D Representation Learning with Multi-dataset Point Prompt Training. arXiv 2023, arXiv:2308.09718. [Google Scholar]
- Zhu, H.; Yang, H.; Wu, X.; Huang, D.; Zhang, S.; He, X.; He, T.; Zhao, H.; Shen, C.; Qiao, Y.; et al. PonderV2: Pave the Way for 3D Foundation Model with A Universal Pre-training Paradigm. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver Convention Center, Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]
- Yu, D.; Hu, Q.; Bao, W. Combining multiple neural networks for classification based on rough set reduction. Int. Conf. Neural Netw. Signal Process. 2003, 1, 543–548. [Google Scholar]
- Hu, Q.; Yu, D.; Liu, J.; Wu, C. Neighborhood rough set based heterogeneous feature subset selection. Inf. Sci. 2008, 178, 3577–3594. [Google Scholar] [CrossRef]
- Liu, X. Point2Sequence: Learning the Shape Representation of 3D Point Clouds with an Attention-based Sequence to Sequence Network. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 8778–8785. [Google Scholar]
- Lee, D.; Lee, J.; Lee, J.; Lee, H.; Lee, M.; Woo, S.; Lee, S. Regularization Strategy for Point Cloud via Rigidly Mixed Sample. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Kuala Lumpur, Malaysia, 18–20 December 2021; pp. 15895–15904. [Google Scholar]
- Yang, D.; Gao, W. PointManifold: Using Manifold Learning for Point Cloud Classification. In Proceedings of the IEEE/CVF International Conference on Image Processing, New York, NY, USA, 7–20 February 2020; pp. 1–5. [Google Scholar]
- Sun, C.; Zheng, Z.; Wang, X.; Xu, M.; Yang, Y. Self-supervised Point Cloud Representation Learning via Separating Mixed Shapes. IEEE Trans. Multimed. 2022, 25, 6207–6218. [Google Scholar] [CrossRef]
- Yan, X.; Zheng, C.; Li, Z.; Wang, S.; Cui, S. PointASNL: Robust Point Clouds Processing Using Nonlocal Neural Networks with Adaptive Sampling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5588–5597. [Google Scholar]
- Yu, J.; Zhang, C.; Wang, H.; Zhang, D.; Song, Y.; Xiang, T.; Liu, D.; Cai, W. 3D Medical Point Transformer: Introducing Convolution to Attention Networks for Medical Point Cloud Analysis. arXiv 2021, arXiv:2112.04863. [Google Scholar]
- Cheng, Z.; Wan, H.; Shen, X.; Wu, Z. PatchFormer: An Efficient Point Transformer with Patch Attention. In Proceedings of the IEEE/CVF International Conference on Computer Vision, New Orleans, LA, USA, 19–24 June 2022; pp. 11789–11798. [Google Scholar]
- Huang, Z.; Zhao, Z.; Li, B.; Han, J. LCPFormer: Towards Effective 3D Point Cloud Analysis via Local Context Propagation in Transformers. arXiv 2022, arXiv:2210.12755. [Google Scholar] [CrossRef]
- Liu, Y. Relationshape convolutional neural network for point cloud analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8887–8896. [Google Scholar]
- Xie, X.; Zheng, J.; Gao, Z. Attentional ShapeContextNet for Point Cloud Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–26 June 2018; pp. 4606–4615. [Google Scholar]
- Li, Y.; Wang, J.; Zhang, J.; Chen, H. DT-Net: Dynamic Transformation Network for Point Cloud Completion. arXiv 2021, arXiv:2109.06385. [Google Scholar]
- Qiu, S.; Anwar, S.; Barnes, N. Geometric back-projection network for point cloud classification. IEEE Trans. Multimed. 2021, 24, 1943–1955. [Google Scholar] [CrossRef]
- Raghu, M.; Unterthiner, T.; Kornblith, S.; Zhang, C.; Dosovitskiy, A. Do vision transformers see like convolutional neural networks? In Proceedings of the Conference on Neural Information Processing Systems, Online, 6–14 December 2021; pp. 12116–12128. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Input | Input Size | OA (%) | mA (%) |
|---|---|---|---|---|
| PointNet [11] | P | 1024 × 3 | 89.2 | 86.2 |
| PointNet++ [12] | P,N | 5120 × 6 | 91.9 | – |
| PlaneNet [13] | P | 1024 × 3 | 92.1 | 90.5 |
| PointConv [5] | P,N | 1024 × 6 | 92.5 | 88.1 |
| PointCNN [6] | P | 1024 × 3 | 92.2 | 88.1 |
| DGCNN [14] | P | 2048 × 6 | 93.5 | 90.7 |
| Point2Seq [26] | P | 1024 × 3 | 92.2 | 90.4 |
| RSMix [27] | P | 1024 × 3 | 93.5 | – |
| Manifold [28] | P | 2048 × 6 | 93.0 | 90.4 |
| PointStack [15] | P | 1024 × 3 | 93.3 | 89.6 |
| DGCNN+MD [29] | P | 1024 × 3 | 93.3 | 89.99 |
| OGNet+MD [29] | P | 1024 × 3 | 93.39 | 90.71 |
| PointASNL [30] | P,N | 1024 × 6 | 93.31 | – |
| Add-attention | P | 1024 × 3 | 92.4 | 88.0 |
| Bmm-attention | P | 1024 × 3 | 92.8 | 89.0 |
| PCT [18] * | P | 1024 × 3 | 93.2 | 90.0 |
| 3DMedPT [31] | P | 1024 × 3 | 93.4 | – |
| 3CROSSNet [19] | P | 1024 × 3 | 93.5 | – |
| PatchFormer [32] | P,N | 1024 × 6 | 93.6 | – |
| PT [17] | P,N | 1024 × 6 | 93.7 | 90.6 |
| LCPFormer [33] | P | 1024 × 3 | 93.6 | 90.7 |
| RST (ours) | P | 1024 × 3 | 93.7 | 90.8 |
| Granulation Relations | OA (%) | mA (%) |
|---|---|---|
| Dominant Relationship | 93.0 | 90.0 |
| Euclidean Norm | 93.2 | 90.2 |
| Multiquadric Kernel | 93.6 | 90.4 |
| Gaussian Kernel | 93.8 | 90.8 |
| Method | Points | Error (%) |
|---|---|---|
| PointNet [11] | 1k | 0.47 |
| PointNet++ [12] | 1k | 0.29 |
| PCNN [5] | 1k | 0.19 |
| RS-CNN [34] | 1k | 0.15 |
| PCT [18] | 1k | 0.13 |
| RST (ours) | 1k | 0.11 |
| Method | mIoU (%) |
|---|---|
| PointNet [11] | 83.7 |
| 3DMedPT [31] | 84.3 |
| ShapeContextNet [35] | 84.6 |
| PointNet++ [12] | 85.1 |
| P2Sequence [26] | 85.1 |
| DGCNN [14] | 85.2 |
| DT-Net [36] | 85.6 |
| PointConv [5] | 85.7 |
| 3CROSSNet [19] | 85.9 |
| CAA [37] | 85.9 |
| PT [17] | 85.9 |
| NPCT [18] * | 85.2 |
| SPCT [18] * | 85.8 |
| PointCNN [6] | 86.1 |
| RS-CNN [34] | 86.2 |
| RST (ours) | 86.5 |
| Method | Epochs (Convergence) | Average Training Time | Average Testing Time |
|---|---|---|---|
| PCT | 250 | 79.13 s/epoch | 8.58 s |
| RST (ours) | 300 | 79.58 s/epoch | 8.67 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, X.; Zeng, K. RST: Rough Set Transformer for Point Cloud Learning. Sensors 2023, 23, 9042. https://doi.org/10.3390/s23229042
Sun X, Zeng K. RST: Rough Set Transformer for Point Cloud Learning. Sensors. 2023; 23(22):9042. https://doi.org/10.3390/s23229042
Chicago/Turabian StyleSun, Xinwei, and Kai Zeng. 2023. "RST: Rough Set Transformer for Point Cloud Learning" Sensors 23, no. 22: 9042. https://doi.org/10.3390/s23229042
APA StyleSun, X., & Zeng, K. (2023). RST: Rough Set Transformer for Point Cloud Learning. Sensors, 23(22), 9042. https://doi.org/10.3390/s23229042