1. Introduction
The rapid advancement of deep neural networks has meant significant progress in hand pose estimation (HPE), a critical component in AI-driven applications such as human–computer interaction (HCI) and virtual reality (VR). However, HPE remains a complex task due to the flexibility of hand joints, local similarities, and severe occlusions, including self- and object occlusion [
1]. Therefore, it is crucial to investigate efficient HPE architectures that effectively address these challenges [
2]. Over the past decade, numerous 2D methods, including multiview RGB models [
3,
4], depth-based architectures [
5,
6,
7], and monocular RGB methods [
8,
9], have been developed in the HPE field to overcome these problems. More recently, 3D HPE has acquired increased interest due to its enhanced accuracy and performance.
Nevertheless, 2D HPE remains a vital research direction, as it forms the foundational building block for 3D algorithms, which achieve estimation results by transposing feature maps from 2D to 3D space [
10,
11]. Reflecting the importance of 2D HPE from a monocular RGB image is a central point of the experiment. In HPE, extracting valuable feature maps is a vital and challenging task for precisely identifying and tracking the position and orientation of keypoints of each joint of the hand in each scene. These feature maps include edges, corners, textures, or other complex patterns unique to hand structures. These features serve as the input to deep learning (DL) models, allowing them to learn the spatial and temporal relationships among various joints and accurately localize the coordinates of each joint. Enhanced versions of features impact the accuracy of HPE models, even in challenging situations such as self- or object occlusion, varying lighting conditions, or frequent hand movements.
With the advent of DL, the Convolutional Pose Machine (CPM) [
12] emerged as a pioneering model for human pose estimation, and it has also become a significant model in the realm of 2D HPE. CPM can learn robust feature maps but frequently struggles to comprehend the geometric constraints among joints. This often leads to inconsistencies in the final joint predictions, a particularly noticeable challenge in human pose estimation tasks. The issue can be even more pronounced in 2D HPE due to the increased articulation and severity of self-occlusion. To better understand the interconnections among joints, various research work has investigated the potential of integrating deep convolutional neural networks (DCNNs) with the Pose Graph Model (PGM) for tasks related to HPE. These approaches utilize a self-independent Pose Graph Model (PGM) applied to the score maps produced by DCNNs [
13,
14,
15]. The PGM parameters are learned during the end-to-end training process. Subsequently, these parameters are fixed and uniformly applied to all input data during the prediction.
Attention mechanisms have significantly advanced deep learning, particularly in enhancing focus on crucial data segments. Visual attention, a key application of this concept, has shown remarkable efficacy across various domains, including image and text processing. In this study, we present the Spatial Deep Feature Pose Graph Network (SDFPoseGraphNet), building upon our previous work [
16]. This network extends our previous approach by integrating the self attention (SA) module with the VGG-19 model in the backbone. The SA module enables the network to dynamically prioritize important spatial regions in the input image that are crucial for accurate pose estimation. This integration aims to enhance the model’s feature representation capacity, leading to improved performance in HPE tasks. To address the challenge mentioned above for accurate HPE, we incorporate a PGM into the SDFPoseGraphNet. The PGM utilizes Second Inference Module (SIM) parameters that are adaptively learned from the deep feature maps extracted by VGG-19. This adaptivity allows the parameters to be tailored to the characteristics of each individual input image, leading to improved performance in pose estimation. In addition, our model utilizes the First Inference Module (FIM) potentials, which are score maps indicating the location of each hand joint, obtained from another module of the SDFPoseGraphNet. These FIM potentials, combined with the SIM parameters, contribute to the final pose estimation by the PGM. The inference process involves techniques like message passing, which enable the model to refine and enhance the accuracy of the joint predictions. A significant advantage of the SDFPoseGraphNet is its end-to-end trainable nature, where all components, including VGG-19 and the PGM, can be jointly optimized during the training process. This general optimization ensures that the deep feature maps extracted by VGG-19 via spatial attention (SA) [
17] and the adaptively learned parameters of the PGM work well to achieve precise and reliable HPE.
Our contribution is three-fold and is stated below as follows:
We introduce SDFPoseGraphNet, a novel framework that enhances the capabilities of VGG-19 by incorporating SA mechanisms; our model effectively captures spatial information from hand images, allowing VGG-19 to extract deep feature maps that capture intricate relationships among various hand joints.
To address the challenge of accurate pose estimation, we incorporate a PGM into SDFPoseGraphNet. This model utilizes adaptively learned SIM parameters, derived from the deep feature maps extracted by VGG-19, to model the geometric constraints among hand joints. The adaptivity of the parameters enables personalized pose estimation, tailoring the model to the unique characteristics of each individual input image.
The model combines FIM potentials and SIM parameters, which play a crucial role in the final pose estimation performed by the PGM. The inference process incorporates techniques like message passing, refining, and enhancing the accuracy of the joint predictions.
This article follows a structured approach with several sections.
Section 2 presents an overview of prior research conducted in the same field.
Section 3 elaborates on the comprehensive methodology of our proposed model.
Section 4 covers pertinent information regarding the experimental setup and implementation details. The results and analysis are presented in
Section 5, while in
Section 6, we conclude our work.
2. Related Works
HPE is a complex task that faces several challenges, including variations in hand poses, limited depth information, and issues related to appearance and occlusion. Researchers have been actively exploring different approaches and techniques to tackle these challenges. One effective approach is the use of multi-view RGB models [
4,
18,
19,
20], which address the problem of self/object occlusion and achieve notable accuracy in HPE. However, the practical implementation of multi-view RGB models [
21,
22] is constrained by the requirement for specific camera setups, limiting their performance in real-world scenarios. Depth-based models [
23,
24,
25] offer advantages in accurately locating and identifying hands based on depth values, resulting in faster processing. However, these models can be sensitive to lighting conditions and noise, making them more suitable for controlled environments where such factors can be regulated. In recent years, RGB cameras have been widely adopted in HPE tasks due to their anti-interference capabilities, affordability, and portability. The research community has been actively developing methods to directly estimate 3D hand poses from RGB images. Some approaches involve fitting 3D models using estimated 2D joint locations. It is important to note that the accuracy of 2D HPE greatly influences the overall performance of 3D HPE techniques [
9,
26].
CNNs are crucial for HPE [
2,
27], leveraging their exceptional feature extraction capabilities. The automatic learning of feature representations in modern deep learning eliminates the need for manual feature engineering. However, the quality of learned features relies on the network architecture used. Thus, exploring network design methods becomes imperative for extracting tailored features for accurate hand pose estimation. These methods aim to identify optimal configurations that extract highly discriminative and informative features, enhancing system accuracy and robustness. Some research work focuses on directly mapping the input image to the coordinates of keypoints in a 2D or 3D space, known as holistic regression [
28,
29]. This approach eliminates the need for intermediate representations, such as pixel-wise classification, while capturing global constraints and correlations between keypoints. However, concerns have been raised regarding the generalization capability of holistic regression and its sensitivity to translational variance, which can lead to diminished prediction accuracy [
30]. CPM, which enforces CNN to generate heatmaps, indicates the location of keypoints. Heatmap-based methods have resulted in a significant increase in performance; therefore, we followed the heatmap-based approach for precise prediction of the keypoints pertaining to each joint of the hand.
3. SDFPoseGraphNet
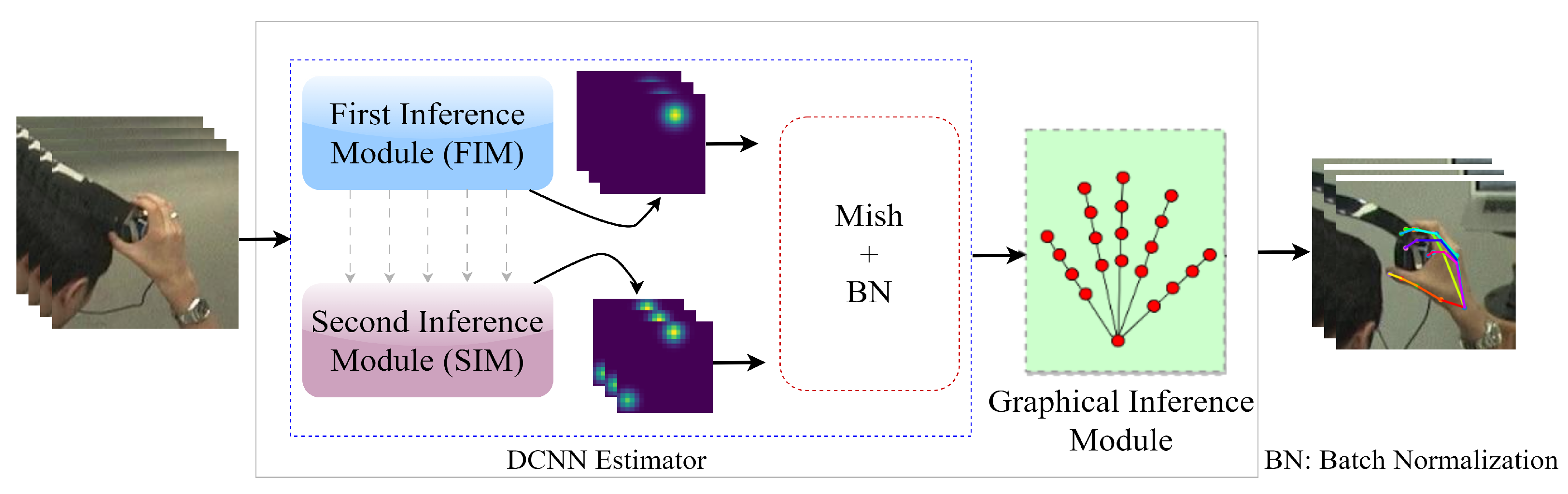
The CPM, although capable of learning strong feature maps, often encounters difficulties in capturing the geometric relationships between joints. As a result, the final predictions of joint positions can exhibit inconsistencies, which pose a significant challenge in tasks involving human pose estimation. This challenge becomes even more prominent in 2D HPE due to the higher level of articulation and the presence of self-occlusion, which further exacerbates the problem. To solve these limitations, we propose SDFPoseGraphNet, a novel framework that enhances the capabilities of VGG-19 with SA, visually depicted in
Figure 1.
The proposed model incorporates two modules called the First Inference Module (FIM) and the Second Inference Module (SIM). A final Graphical Inference Module is employed to connect the FIM and SIM sequentially. The FIM produces a provisional feature score for the keypoints
K of the hand during the preliminary stage. The VGG-19 block’s revert feature score can readily integrate with the proposed SDFPoseGraphNet. The final module utilizes the parameters generated by the SIM, which depict spatial constraints among the critical points of the hand. The suggested framework for HPE differentiates itself from previous frameworks by leveraging the SIM, which enables the association of the final graphical module with DCNN [
13,
14]. In our work, the parameters of the PGM are not considered as independent parameters. Rather, they are tightly linked to the input image through VGG-19, making them adaptable and responsive to different variations in the input images. This integration allows the model to capture and utilize relevant information from the input image effectively, resulting in improved performance and adaptability in various circumstances, as mentioned earlier.
The process of predicting hand poses can be formally described through a graph represented by
, which consists of vertices
and edges
. In other words, it can be denoted as
. Here, the vertices
are directly associated with the salient keypoints of the hand, denoted as
K, and can be expressed as
. Each vertex
corresponds to a specific two-dimensional keypoint, represented as
, which provides the position of that keypoint relative to
. The subsequent equation, labeled as (
1), expresses the joint probability of the hand poses.
In this equation,
represents the set of hand keypoints, and
i and
j denote their positions. The term
signifies the cardinality, or the number of elements, in the set
.
and
correspond to the input image. The parameter
encompasses the combination of FIM and SIM;
.
In this context, the equation models the joint probability of hand poses by considering the interrelationships between keypoints and their positions within a graphical structure. It provides a formal representation of the predictive process used to estimate hand poses, where various components, such as the hand keypoints and the input image, are considered in the calculation of this probability. The parameter encapsulates the combination of specific modules that contribute to the overall predictive model.
Further information and comprehensive explanations regarding each component of the proposed model SDFPoseGraphNet are introduced in the following subsections.
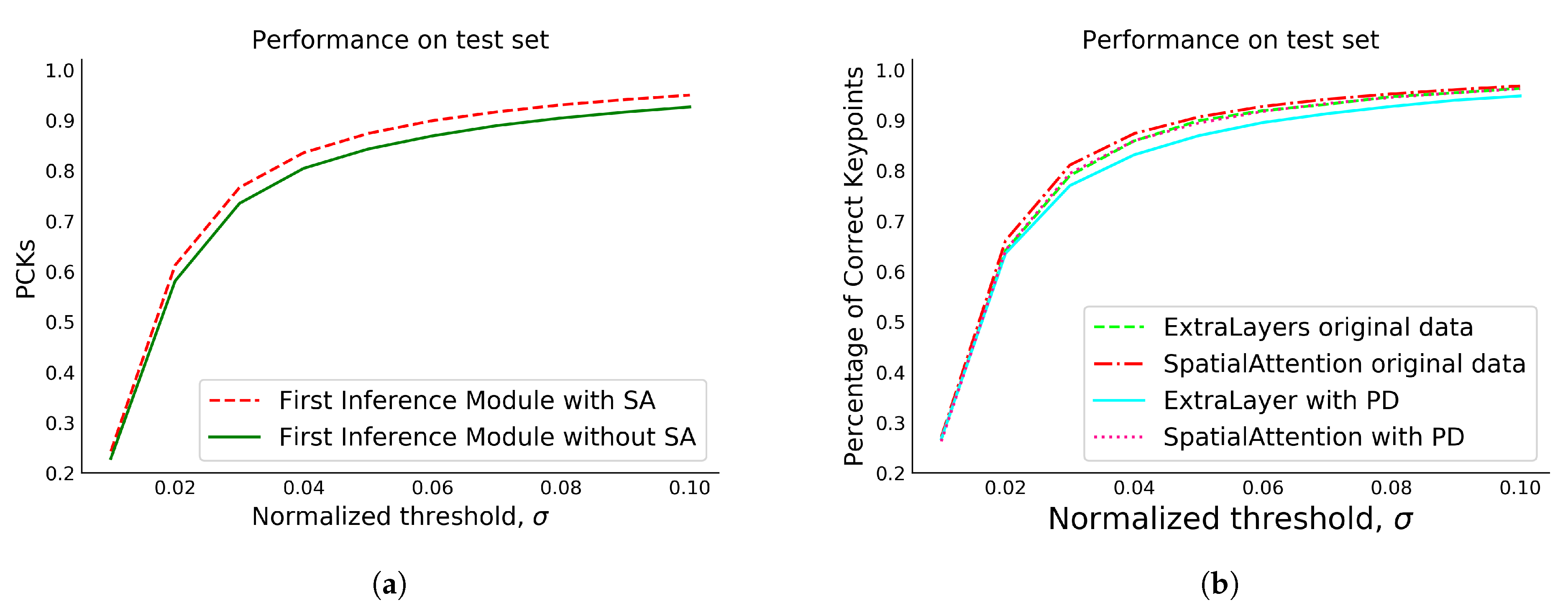
3.1. Optimized VGG-19 Backbone with SA Module Integration for Improved 2D HPE Feature Extraction
In a neural network, attention systems enhance focus on crucial portions of the input data while diminishing the importance of less relevant components. This significant approach, known as visual attention, has made substantial strides in the realm of DL research. These attention mechanisms have shown efficacy in dealing with both text and image data. To augment the existing efficiency of convolutions, numerous methods incorporating visual attention have been developed. This study proposes an innovative approach for HPE tasks by integrating the SA module with the VGG-19 model. This fusion leverages the known effectiveness of the VGG-19 architecture in feature extraction and the ability of attention mechanisms to zero in on salient spatial regions, thus creating a potent combination [
31]. These SA modules allow each feature map to implement a distinct SA mechanism. Attention maps created this way are assembled along the channel dimension and are then passed through a convolutional layer with a kernel size
k to yield the final attention map. To ensure that the values lie between 0 and 1, this final attention map is passed through a sigmoid activation function, which normalizes the range. These normalized values indicate the significance of each spatial location in the model.
VGG-19 produces five distinct feature maps
, as shown in
Figure 2. SA
and
were implemented on the first four feature maps, along with
convolution for channel reduction, to obtain the attention maps as formulated in Equations (
1) and (
2).
Here,
is the attention map after applying the spatial attention module
to feature map
from VGG-19.
is the feature map after channel reduction, and
C denotes a convolution operation. This series of convolutional layers reduces the channel dimension of the feature maps to a value of 128.
where ⊗ indicates element-wise multiplication, and
represents the attention feature map. To align the spatial dimensions, the interpolation process is executed by utilizing bilinear interpolation (F.interpolate) from torch.nn.functional, as shown in Equation (
5).
represents attention maps after interpolation, and
t is the target size
, which is the last feature map without spatial attention. After interpolation, we fused the attention maps with the last feature map from the backbone by element-wise addition, as shown in Equation (
6):
where
is the fused attention map.
3.2. Architectural and Operational Insights into the FIM
In the initial module, the VGG-19 architecture was used up to Conv
as the fundamental feature extraction network followed by three convolutional layers that facilitated the generation of the initial heatmap. The VGG-19 architecture was enhanced by incorporating an SA module, generating 128 feature maps. The produced feature maps undergo information processing through a module that consists of six stages. These stages involve a series of continuous convolution layers with a specific kernel size
, each incorporating a heatmap label as a supervisory mechanism. The generation of these labels was achieved by applying a Gaussian function to the corresponding ground truth, which is shown below.
The symbol
denotes the extent of the heatmap, while
and
represent the underlying coordinates on the ground. The final stage produces 21 unique feature maps that serve as a representation of each keypoint. These feature maps are utilized as static weights during the training of the graphical module. The output of the initial module is denoted as
. It is important to note that the dimensions of the output heatmaps are determined by the corresponding values of the height
and width
.
Figure 3 shows the sequential procedure for convolutional detailing of the FIM.
3.3. Architectural and Operational Insights into the SIM
The SIM follows a similar methodology as the FIM. In particular, it upholds the most recent framework for 128 feature maps, but it generates 40 feature maps instead of 21 feature maps. The 40 channels or feature maps generated by the SIM represent information about the relationships between hand keypoints. These feature maps capture and encode information about the relative positions, distances, and interactions between different pairs of keypoints on the hand. The result produced by SIM is represented as , which is indicative of the SIM channel kernels. The purpose of the SIM is to learn the relative positions between hand keypoints.
When training the SIM, we maintain the weights of the FIM in a fixed state, effectively ’freezing’ them. As depicted by the gray arrows in
Figure 1, there is a directional flow of information originating from the FIM that moves towards the SIM at the end of each stage. During this information flow process, the feature sets generated at each FIM stage are merged with those from the corresponding SIM stages. For instance, the features from the first stage of the FIM are combined with those from the first stage of the SIM, and this composite feature set is then fed into the second stage of the SIM. This method of consistent information exchange is applied throughout all the stages of the SIM’s training phase. The detailed structure of this architecture is illustrated in
Figure 3.
3.4. Final Graph Inference Module
The message-passing algorithm is widely utilized in graphical model inference. It typically facilitates the effective calculation of marginal probabilities by using the sum-product operation within a graphical module. The equation for the marginal probability can be expressed in Equation (
8).
In this scenario, the function of argmax probability is employed to optimize the marginal probability for predicting the location of the hand keypoint labeled as
i:
where
is the collection of all parameters, which amalgamate the parameters of the initial two modules. In the graphical model, each vertex
has the ability to both send and receive messages
to and from its corresponding neighboring nodes
. The sum-product algorithm is responsible for updating the messages sent from hand keypoints from
i to
j. The complete message exchange is denoted by
; here,
depicts the entire formulation of the message passing.
Given that
assumes values from a grid point set with dimensions of
, we approximate the marginal probabilities as follows, after multiple iterations and upon convergence:
where
represents a message from node
k to node
i, and
is the normalization.
This research work adopted a tree-structured graphical model. One significant advantage of this model is the ability to accurately derive the marginal probability outlined in the earlier equation using belief propagation.
Figure 4 illustrates the hand model arranged in a tree-like structure. Precise marginals can be determined by transmitting messages from the bottom-most nodes to the topmost node, and then back down to the lowest nodes. Numerical values are presented next to each arrow in
Figure 4 with the schedule of message updates denoted by the number 3. In total, 40 message transmissions are adequate for obtaining accurate marginals.
4. Experimental Setup
4.1. Dataset
The Carnegie Mellon University (CMU) Panoptic Hand Dataset was utilized during our study to assess the proposed model. The dataset consists of a total of 14,817 annotations that correspond to the right hand of individuals captured in images from the Panoptic Studio. The current research examines the process of HPE, as opposed to hand detection. To achieve this objective, annotated hand image patches were extracted from the initial images using a square bounding box with dimensions 2.2 times larger than the hand size. The dataset was partitioned into three subgroups using a random sampling technique as shown in
Table 1. Specifically, these subgroups were designated as: the training set, comprising
of the data; the validation set, comprising
of the data; and the test set, comprising
.
4.2. Implementation Details
The proposed model is implemented using the PyTorch framework version . The present model underwent a tripartite training process, where each stage was trained with a consistent learning rate of , a batch size of 32, and four workers. The first two stages of the model were trained for 100 epochs, and an early stop technique was implemented to mitigate overfitting. In contrast, the last stage was trained for a notably shorter duration of 10 epochs with a weight decay of 0.01.
4.3. Loss Function
The mean squared error (MSE) is utilized as the loss function in the model. To prevent the diminution of the loss from reaching nominal values, the loss function is scaled by a coefficient of 35.
The formulation of the loss calculation for a model involves a weighted sum of the loss function of each inference.
is the MSE loss of FIM, represents the MSE loss of SIM, and denotes the PGM MSE loss. These loss terms collectively drive the training process for enhanced model performance. While , , and are the coefficients for fine-tuning the model, the values are set to 1, 0.1, and 0.1, respectively.
4.4. Model Optimization
An optimizer aims to decrease the loss function and steer the network toward improved performance by identifying optimal parameter values. Utilizing a newly derived variation of the Adam optimizer called AdamW can bolster the refinement of model optimization techniques. In contrast to its predecessor, the Adam optimizer, the AdamW algorithm effectively disentangles the weight decay component from the learning rate, allowing for individualized optimization of each component. This feature effectively addresses the issue of excessive overfitting. The outcomes reveal that the models optimized through AdamW exhibit superior generalization performance compared to those trained using other optimizers, particularly Adam. The AdamW optimizer was employed in the training of our final graphical module.
4.5. Activation Functions
Several activation functions, namely ReLU, SoftMax, and Mish, introduce nonlinear components to the neural network, allowing it to comprehend complex patterns and correlations in the data. The Mish activation function has demonstrated superior performance to alternative activation functions, primarily due to its nonlinear nature [
32]. The definition of the term can be expressed using the following formula:
The experimental findings demonstrate that the efficacy of Mish surpasses that of widely utilized activation functions, including ReLU and SoftMax, among others, in diverse deep network architectures operating on complex datasets.
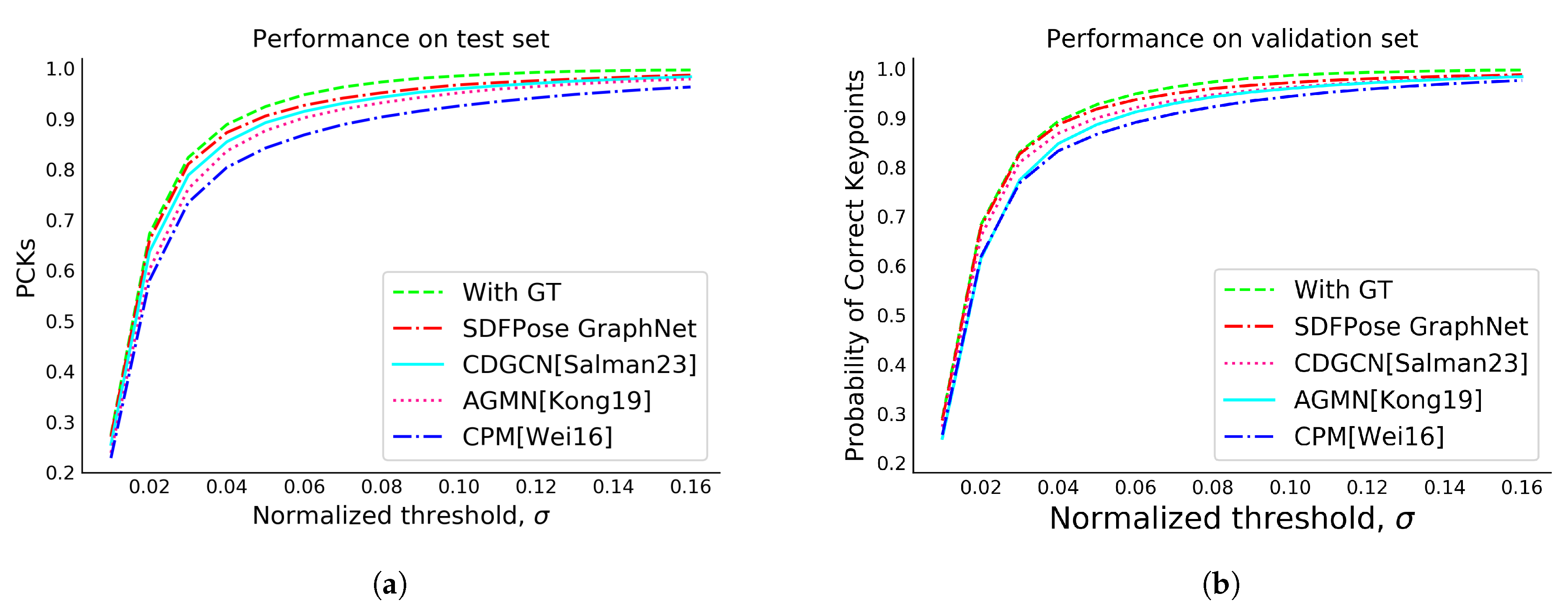
4.6. Evaluation Metric
We normalized the Percentage of Correct Keypoints (PCK) [
4] for our study. The PCK metric [
4] is a commonly employed evaluation measure for HPE. Specifically, it quantifies the likelihood that a predicted keypoint is located within a designated distance threshold, denoted as
, from its corresponding ground truth coordinate. The application of
, restricted to the scale of the hand bounding box, is utilized within this study. The threshold was uniformly distributed within the range of 0 to 0.16, and the PCK formula is
where
is the ground truth of the keypoint, 1 is the indicator function, and
is the predicted keypoint.
k represents the number of keypoints,
D represents the number of test or validation samples, and
h and
w represent the height and width of the sample images, respectively.
6. Conclusions
This research proposed the SDFPoseGraphNet, a novel framework that combines the power of VGG-19 and spatial attention to improve hand pose estimation. By leveraging the deep feature maps extracted by VGG-19, the model captures spatial information and learns the relationships among hand joints. The incorporation of a Pose Graph Model with dynamically learned SIM parameters further enhances accuracy. FIM potentials obtained from another module contribute to pose estimation, and message-passing techniques refine joint predictions. The SDFPoseGraphNet is end-to-end trainable, allowing for joint optimization of all components, resulting in precise and reliable hand pose estimation. The present model possesses the attribute of generality, rendering its potential applicability useful in various forthcoming computer vision undertakings, such as the estimation of 3D hand poses and human poses, among others.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}