
A Lightweight and Efficient Method of Structural Damage Detection Using Stochastic Configuration Network
Abstract
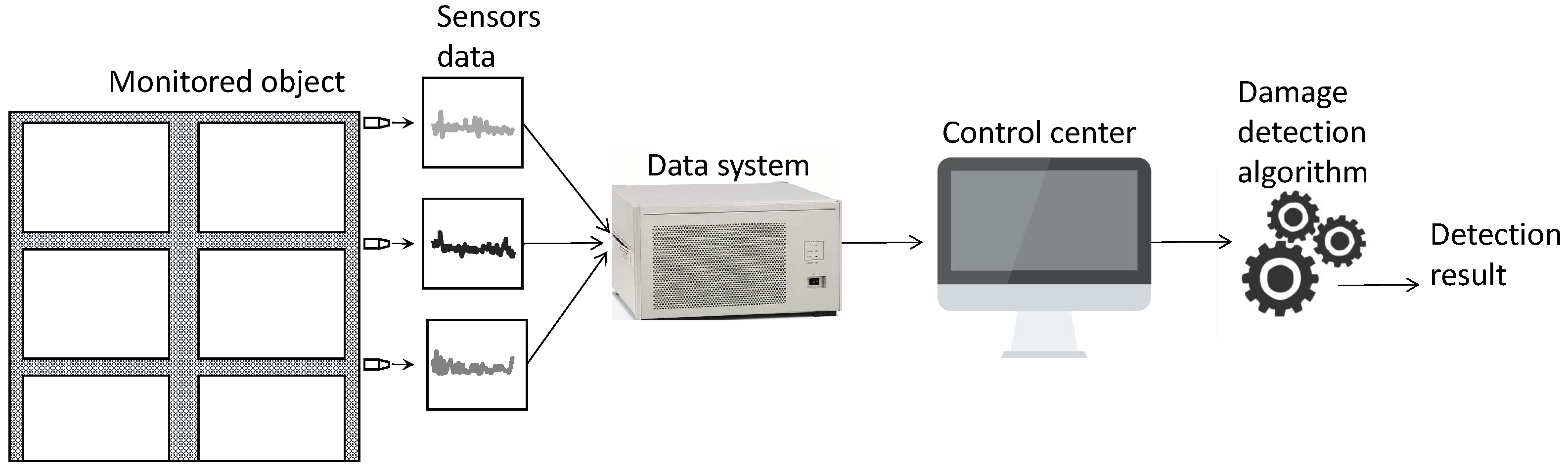
:1. Introduction
2. Methods
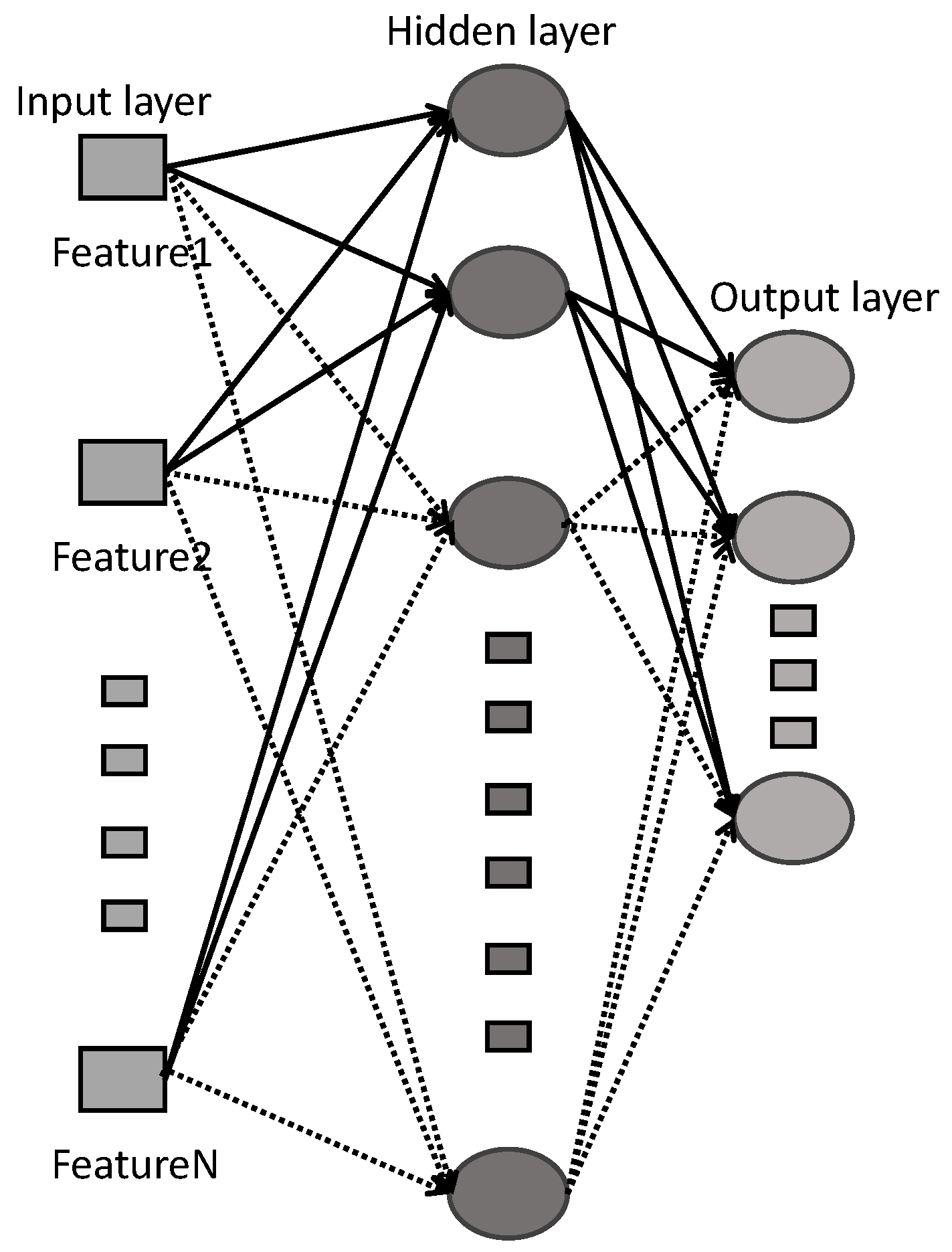
2.1. Review of SCN
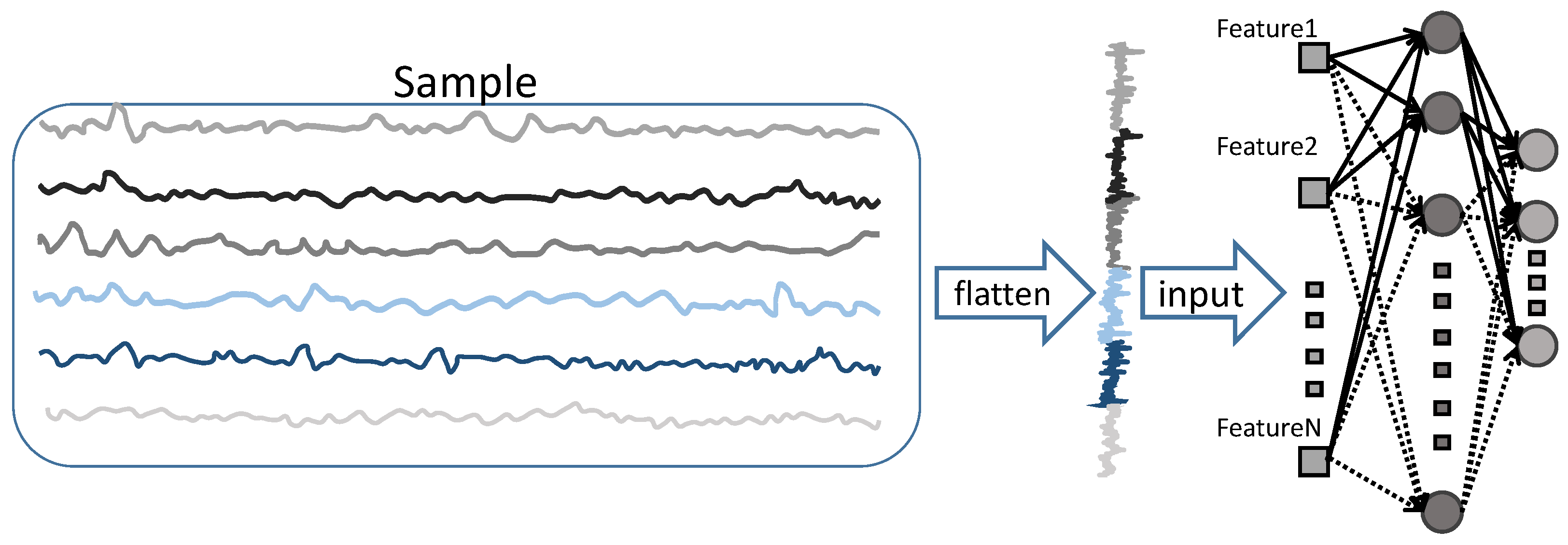
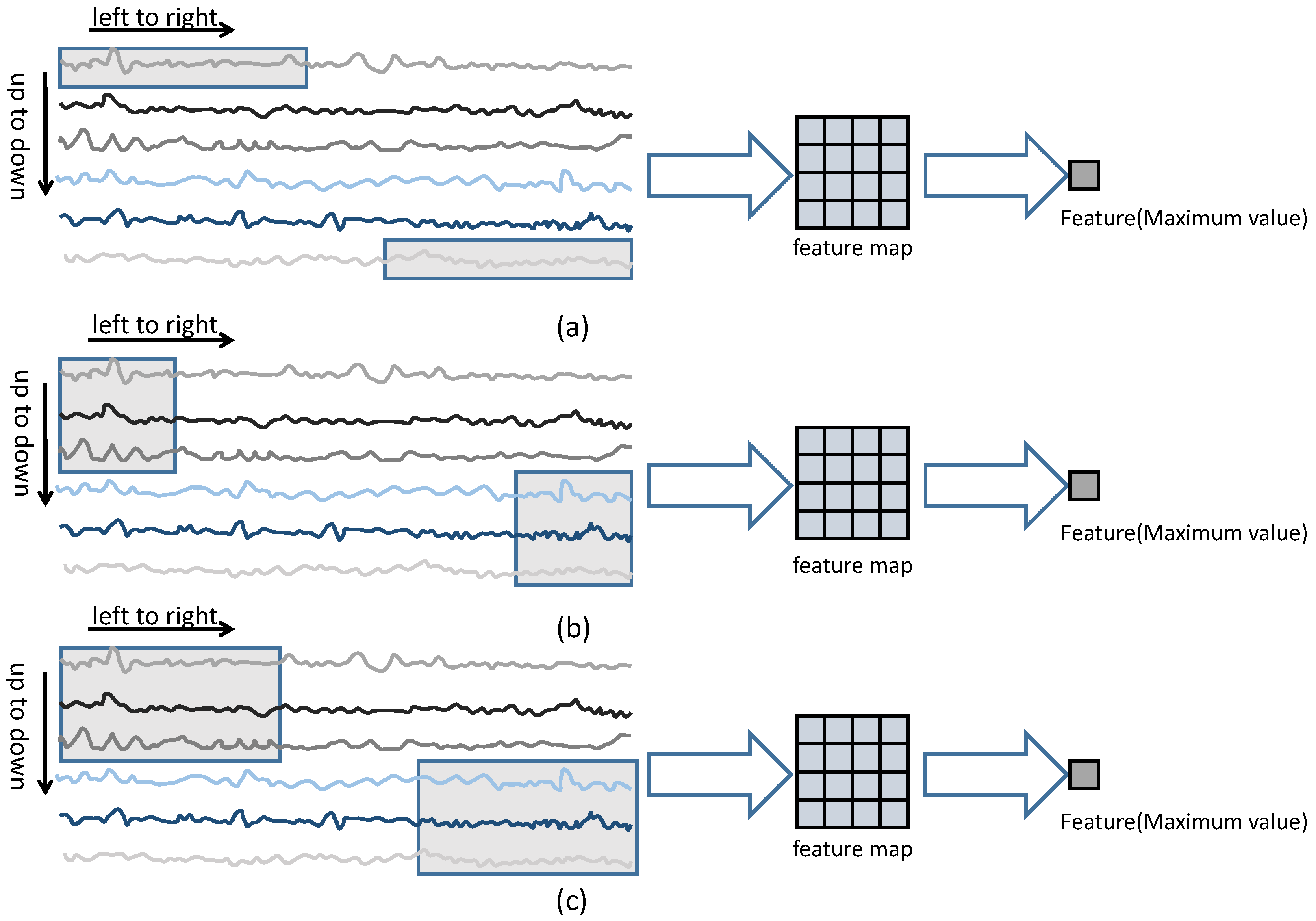
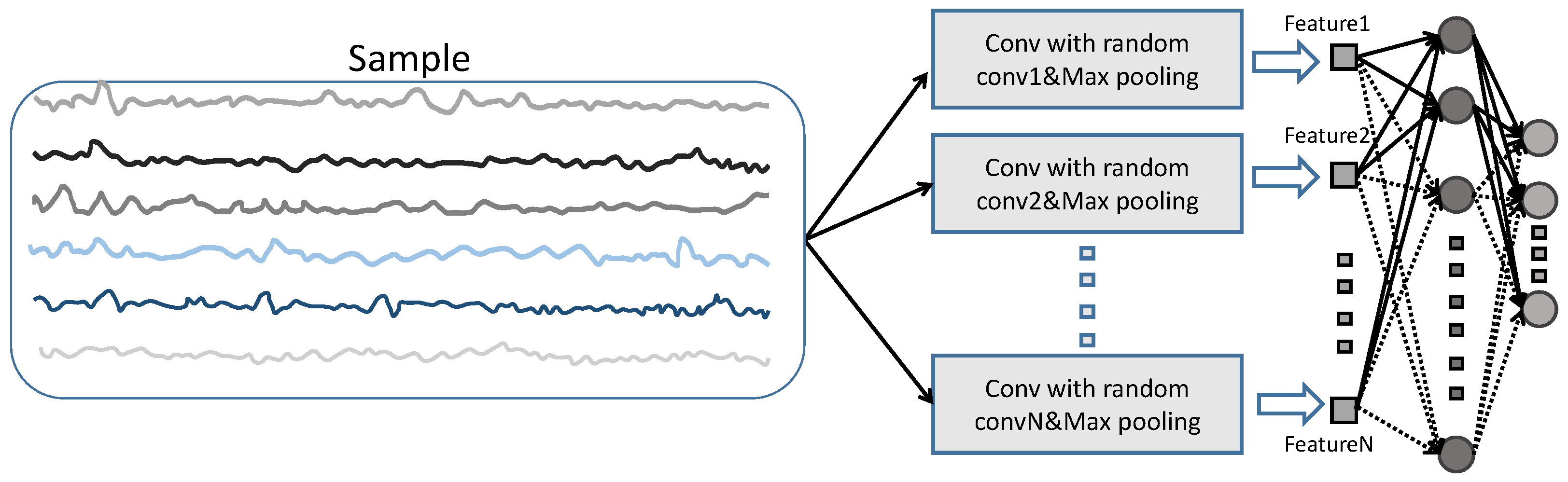
2.2. Feature Extraction Method Based on Randomly Parameterized Rectangular Convolution
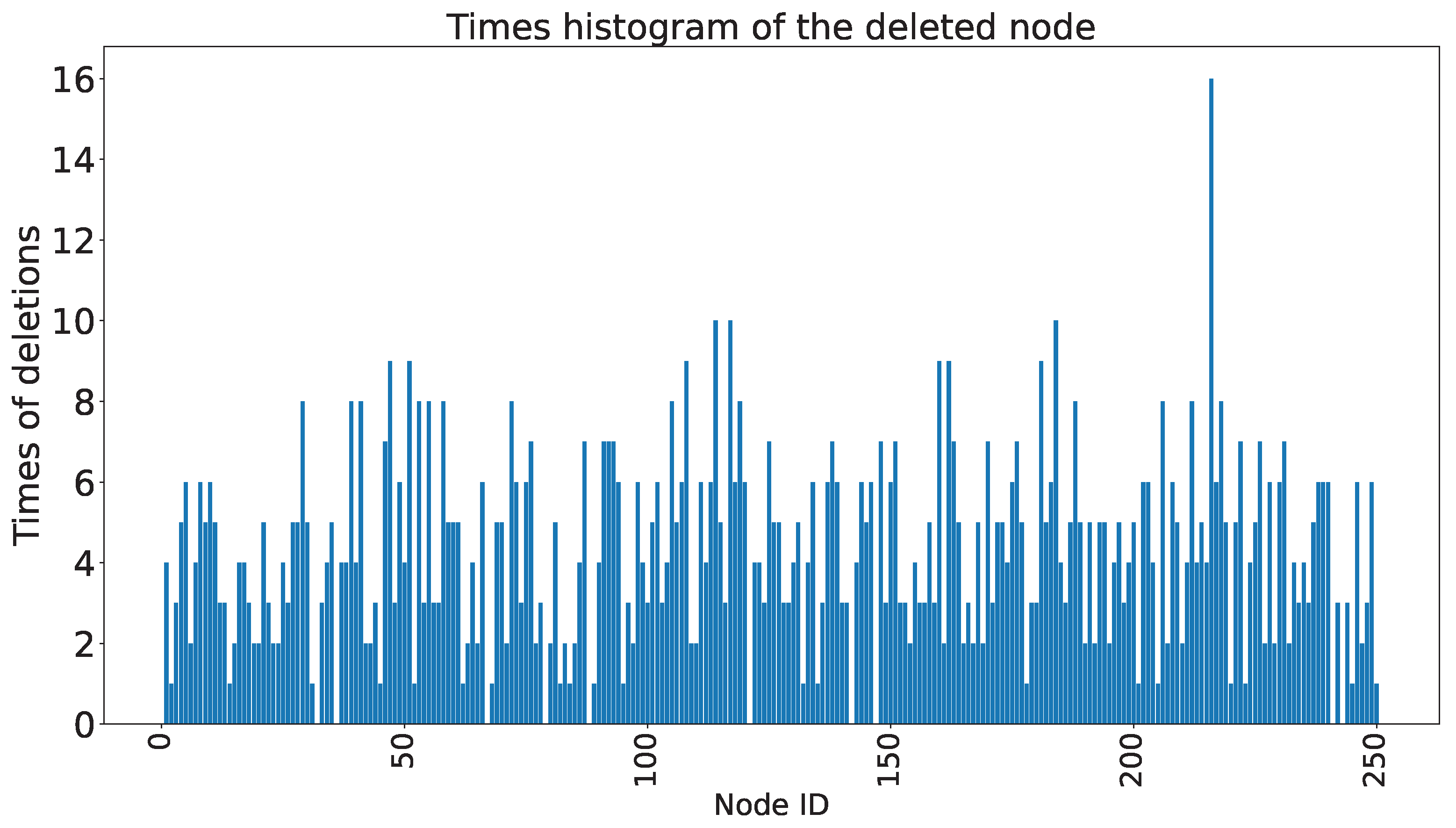
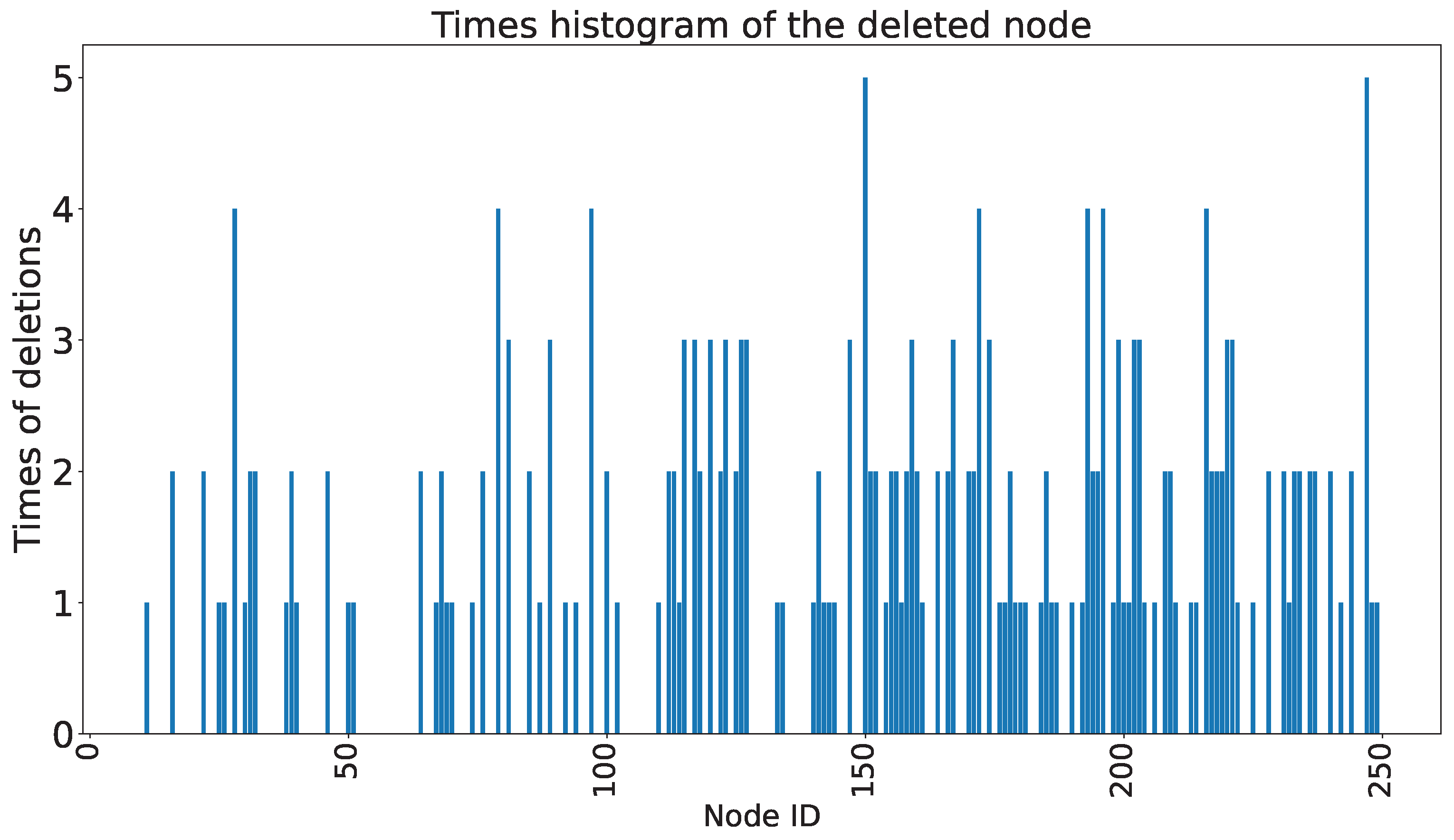
2.3. Random Node Deletion Algorithm
| Algorithm 1. Node Random Pruning Algorithm. |
| Given the parameters to be deleted, ,,, |
| where L is the number of node; the initial accuracy of the network, ; test data ; |
| setting an acceptable accuracy ; and the maximum number of nodes that |
| can be deleted, . |
| 1. Initialize ,, |
| 2. For To Do |
| 3. ,, |
| 4. If |
| 5. |
| 6. For To Do |
| 7. Randomly choice of n nodes from original nodes. |
| 8. Remove the corresponding nodes from the original list |
| based on the of the nodes to be deleted. |
| 9. delete |
| 10. delete |
| 11. delete |
| 12. Calculate the accuracy of the model after removing the nodes. |
| 13. accuracy_score |
| 14. If |
| 15. append |
| 16. append |
| 17. End For (corresponds to Step 4) |
| 18. append |
| 19. max max |
| 20. End For (corresponds to Step 2) |
| 21. Return . |
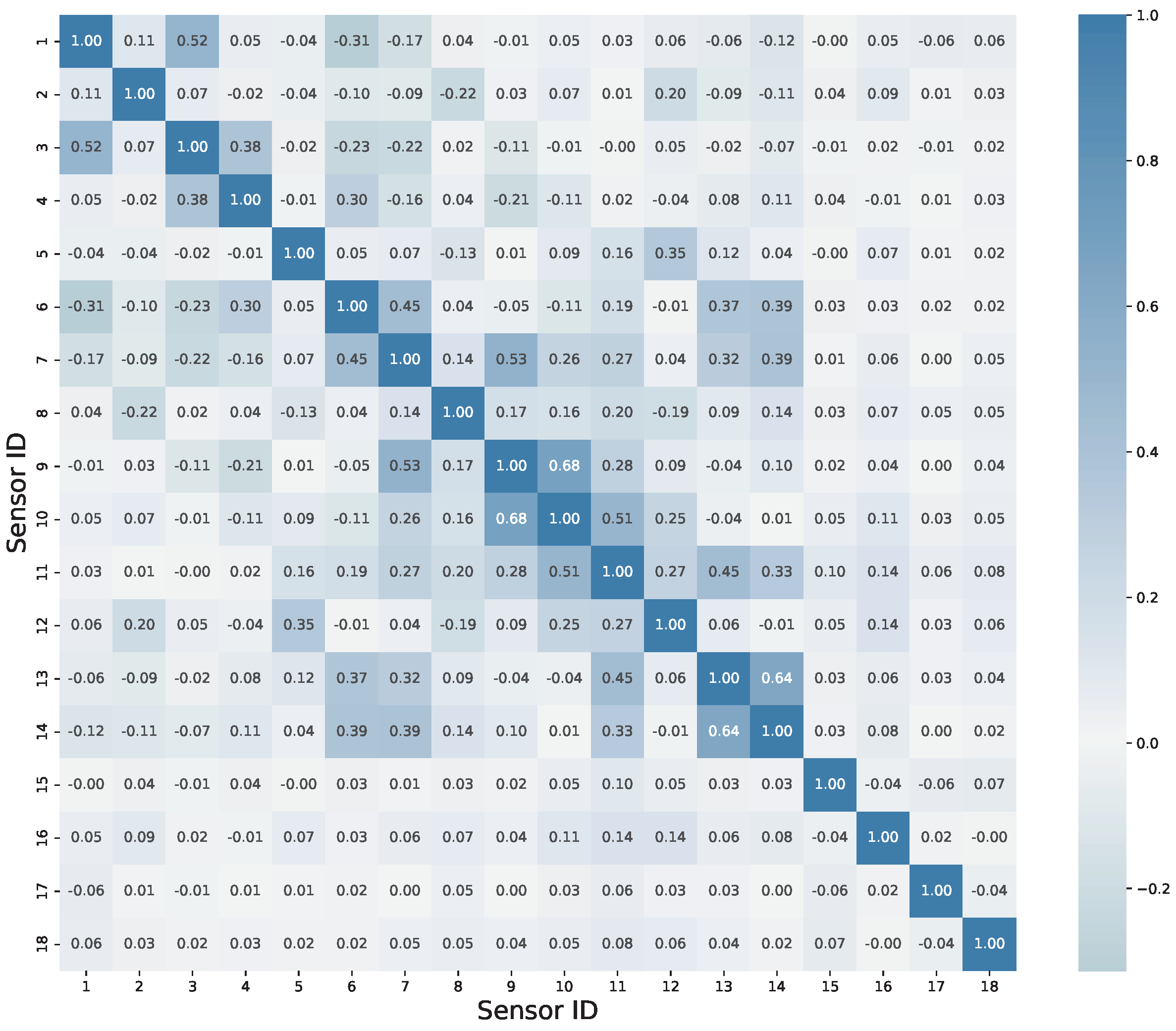
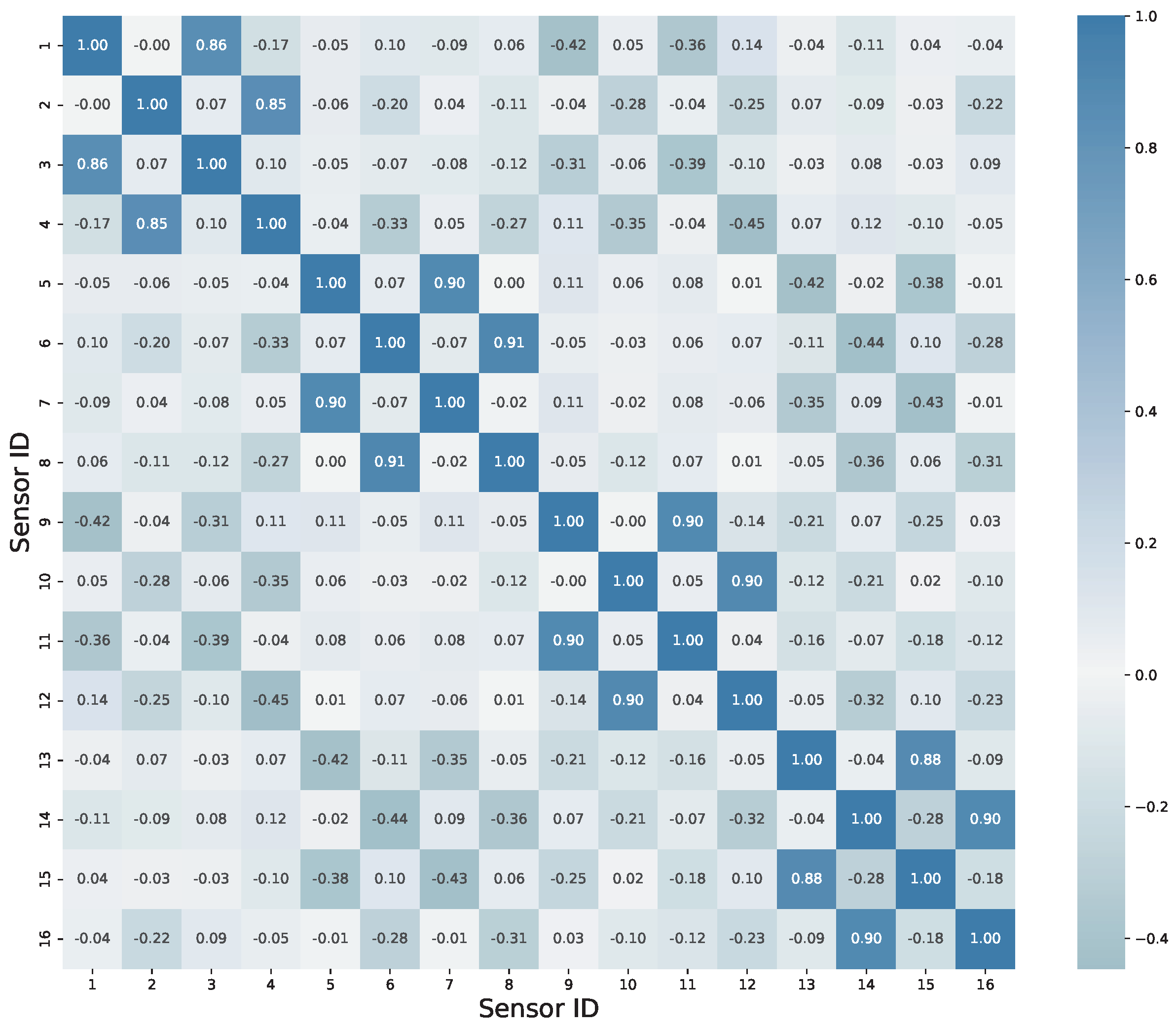
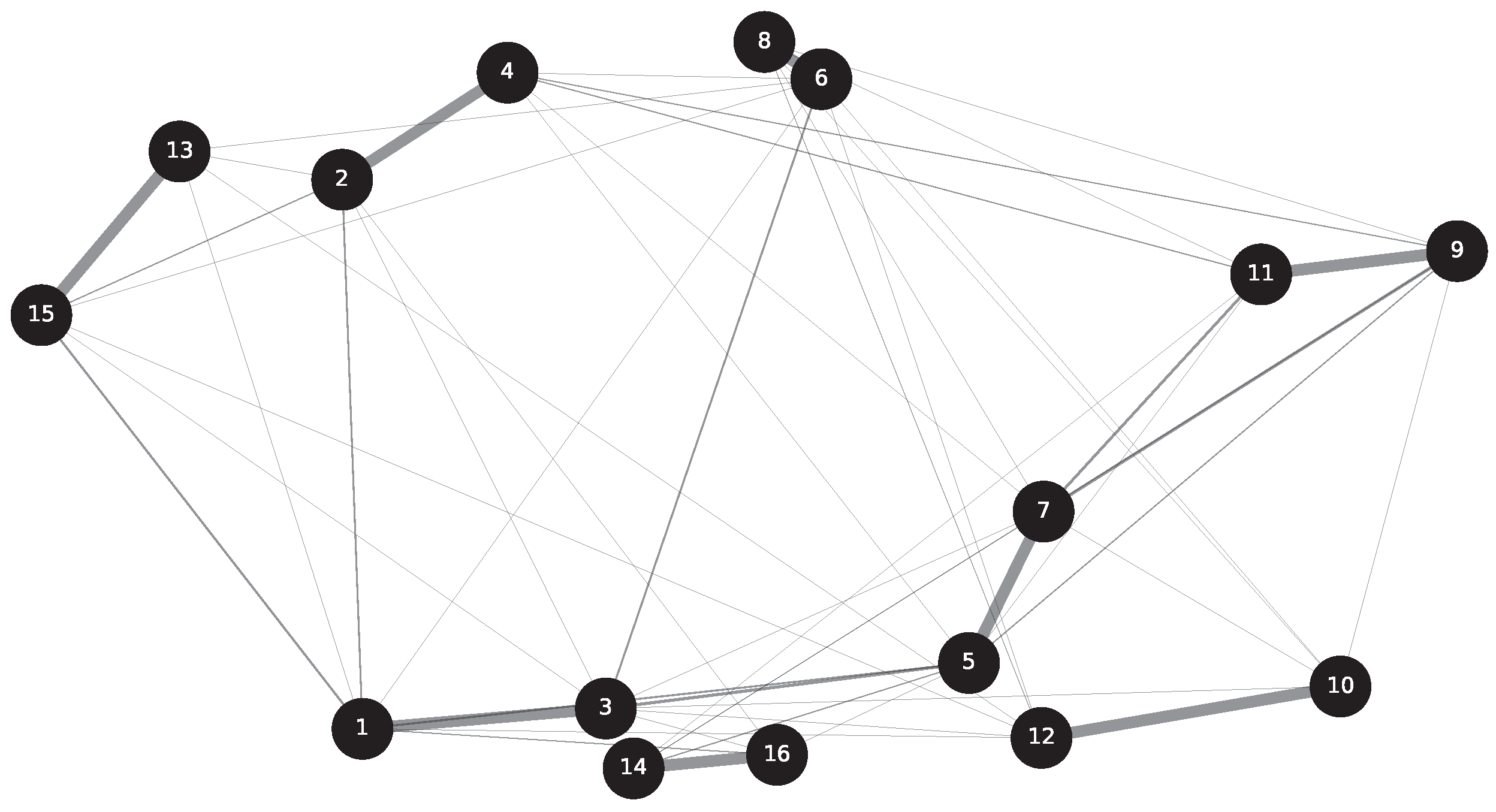
3. Explanation of Experimental Dataset
4. Experiments
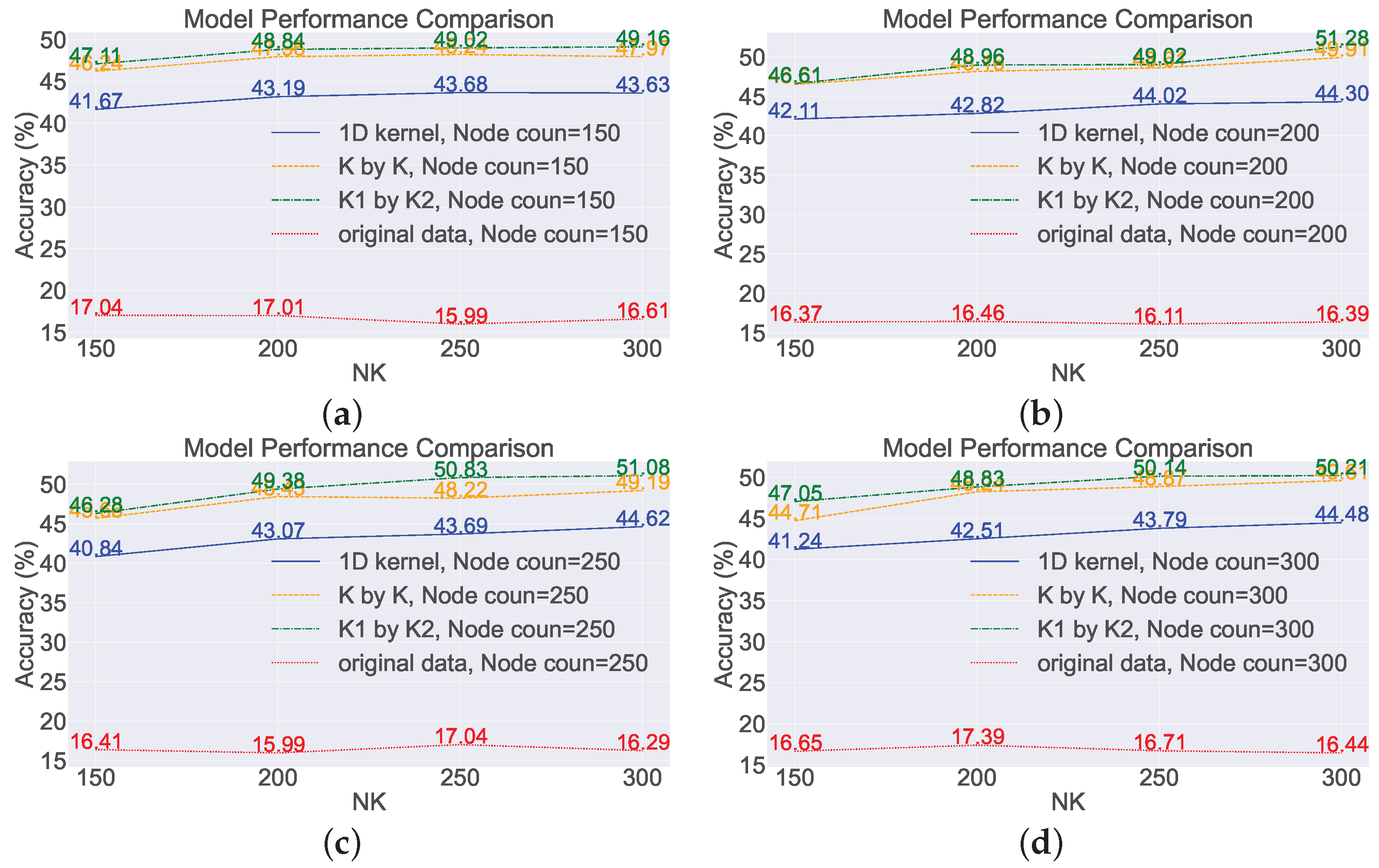
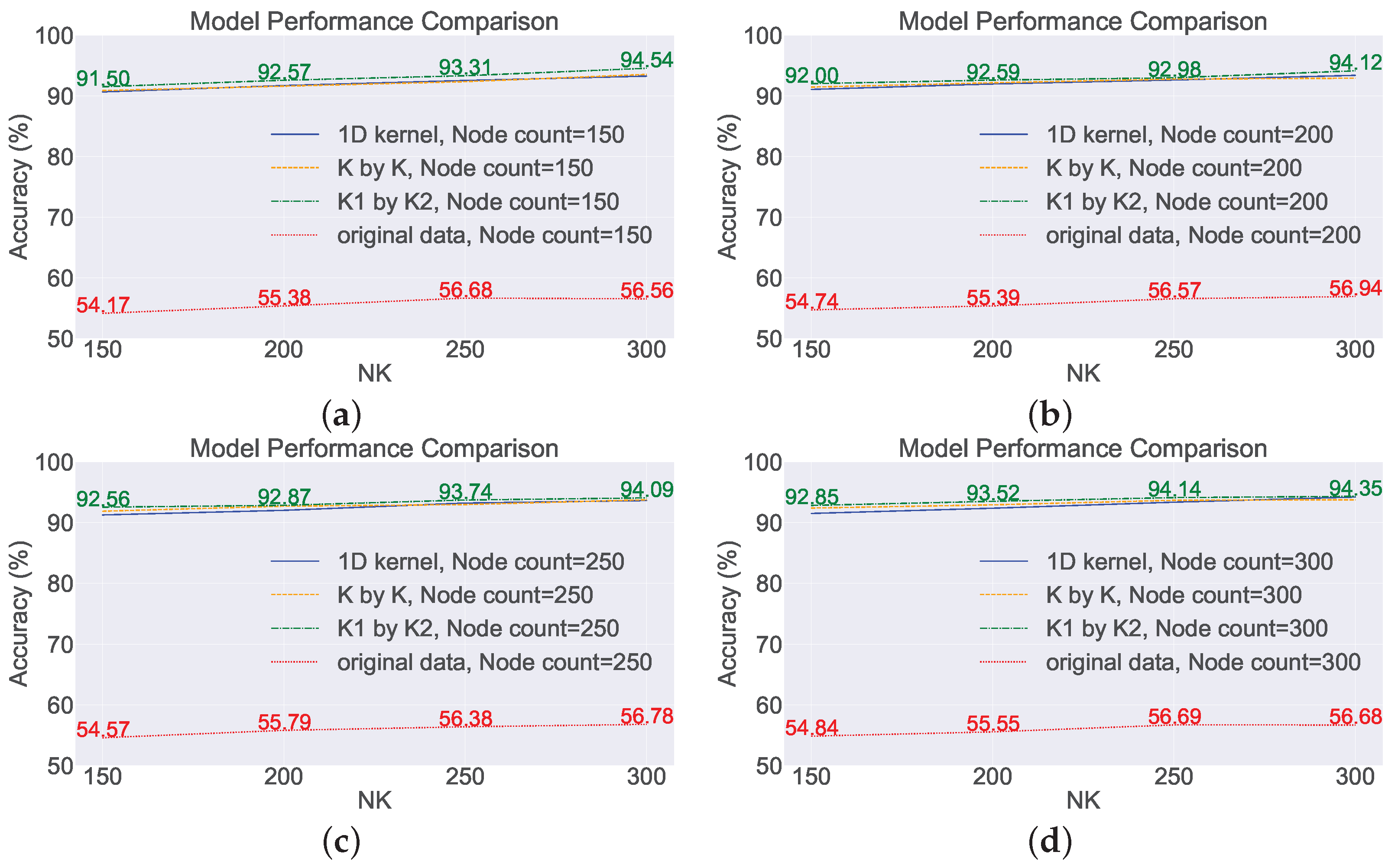
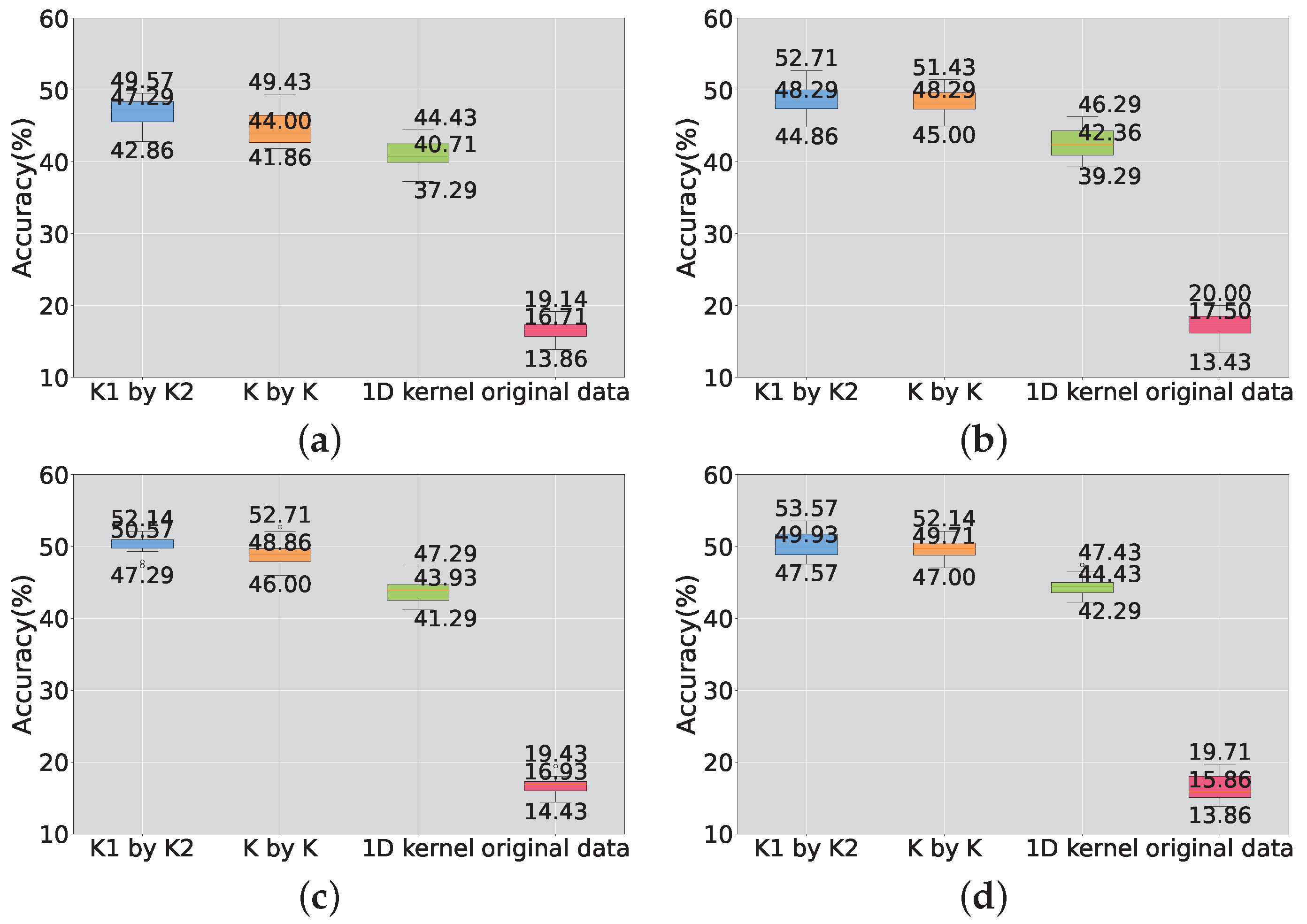
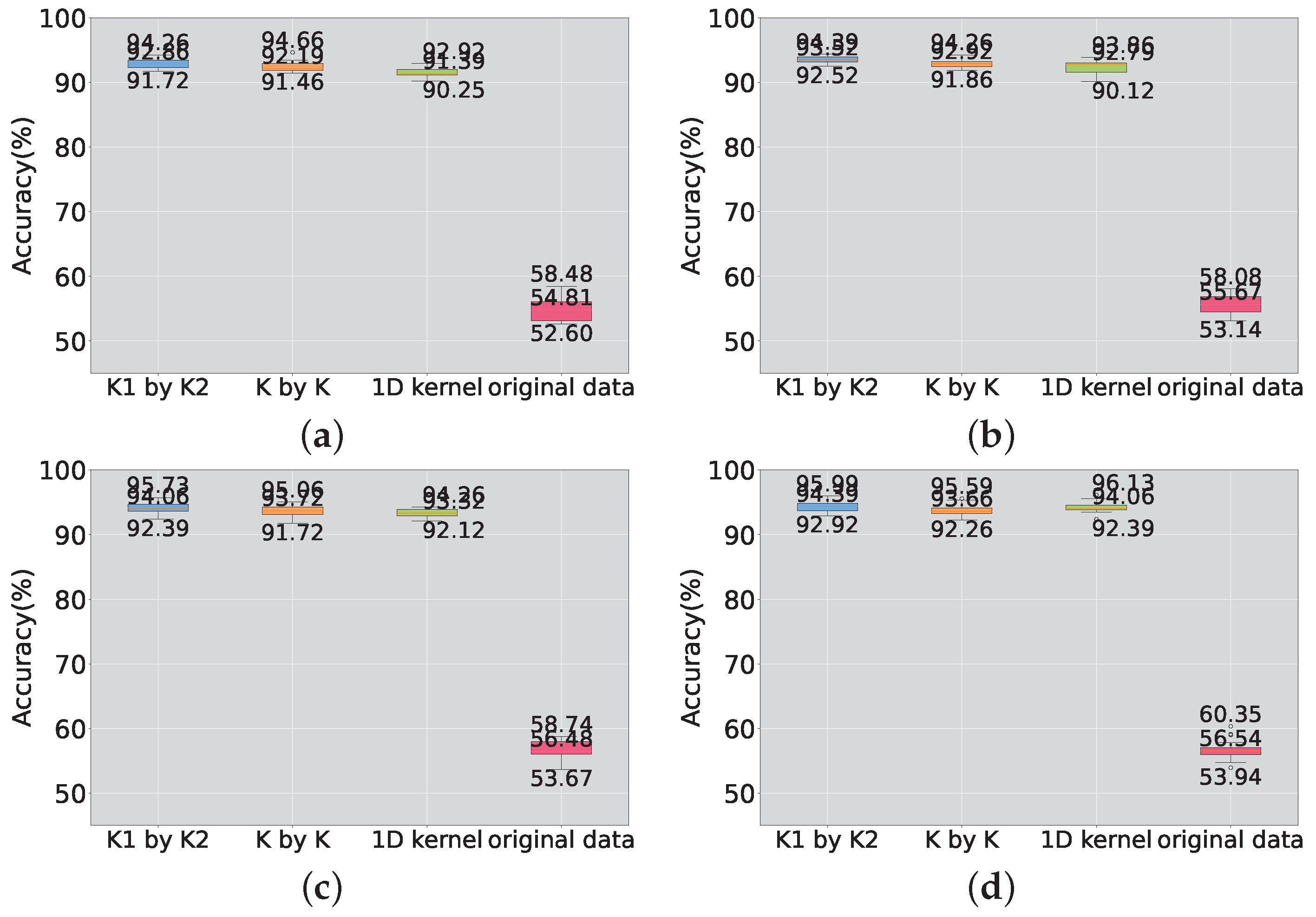
4.1. Experiments on the Random Feature Extraction Algorithm
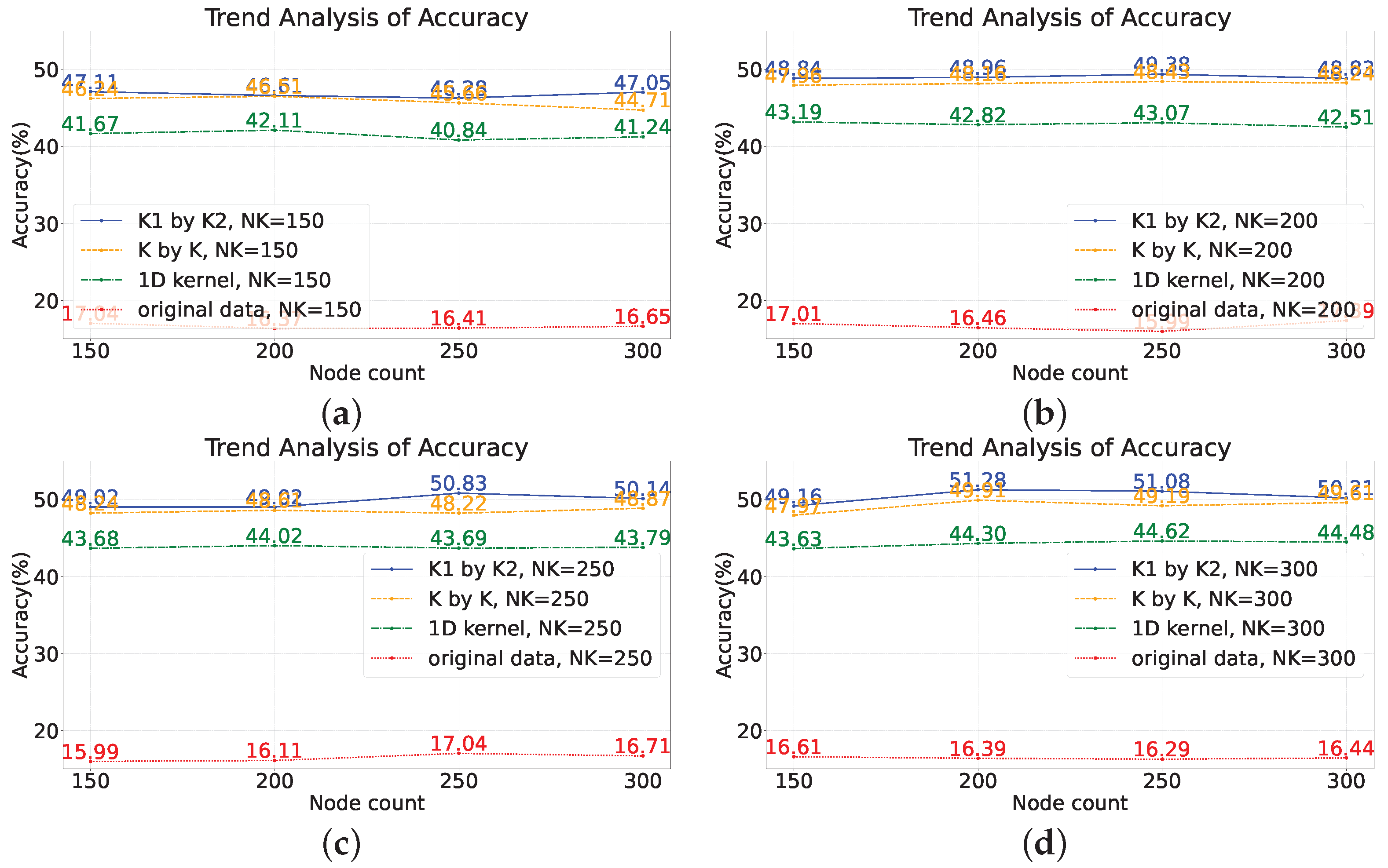
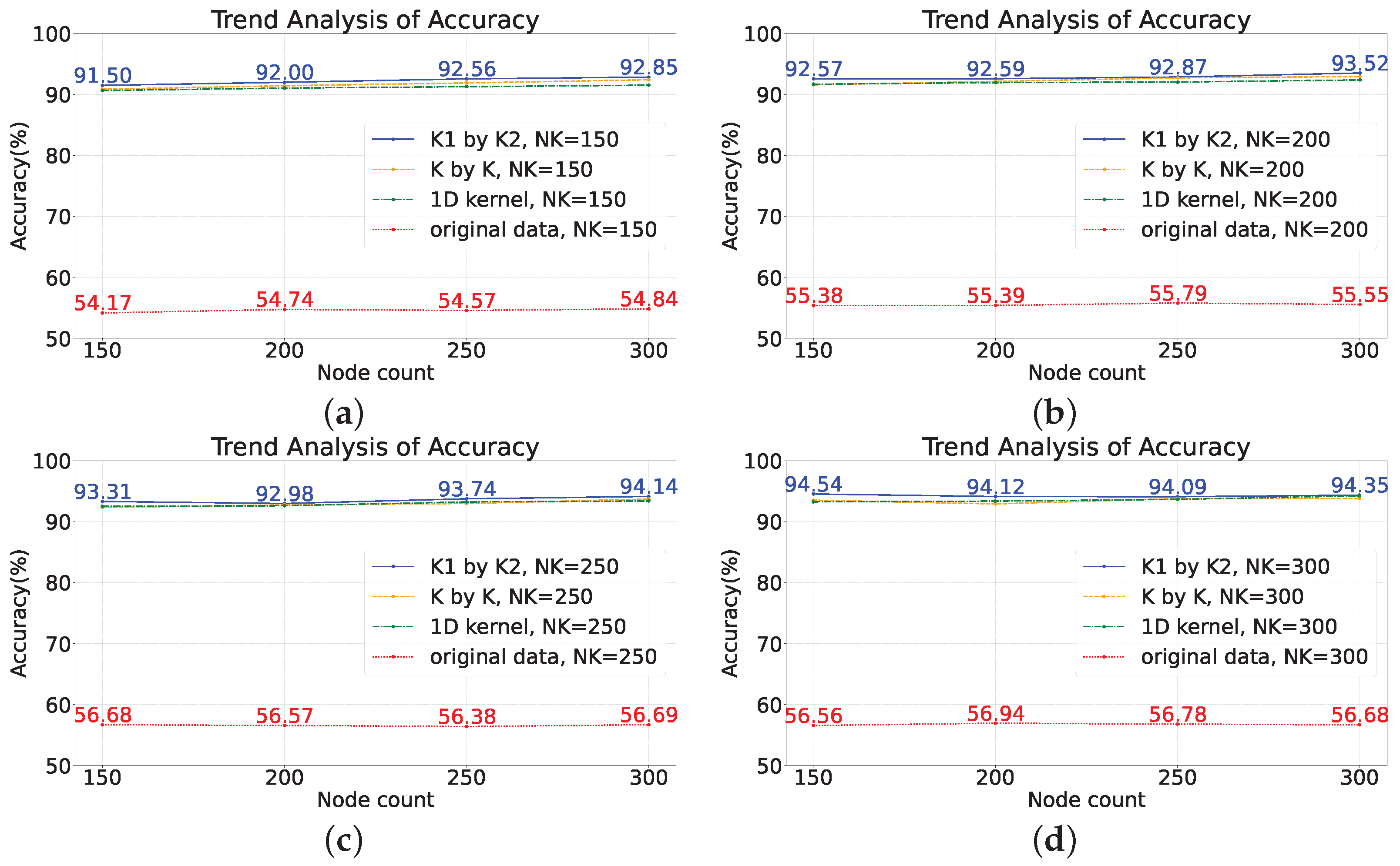
4.2. Experiments on the Random Node Deletion Algorithm
4.2.1. Experiments on the Random Node Deletion Algorithm in the Benchmark Dataset
4.2.2. Experiments on the Scaled-Down Model
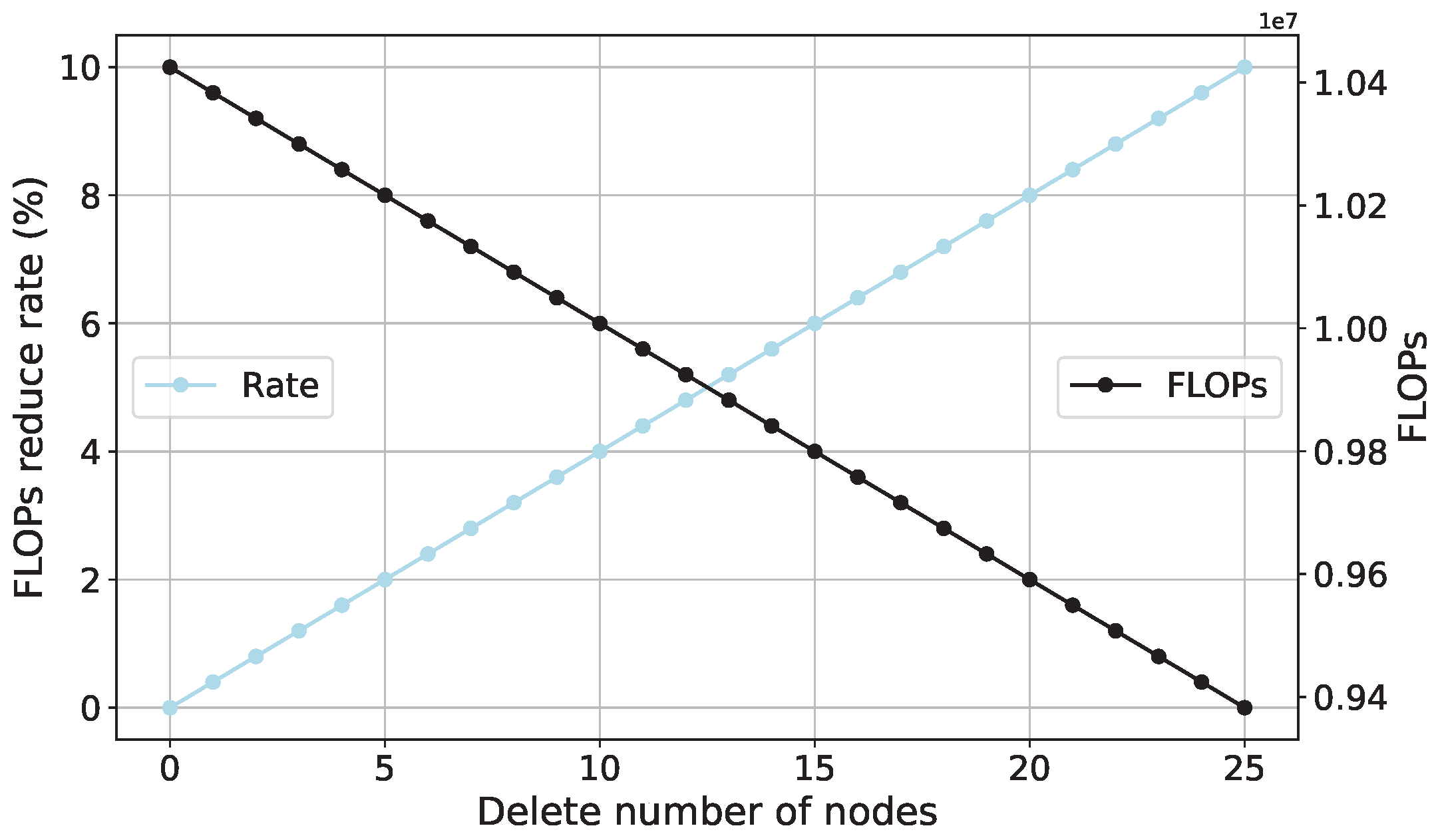
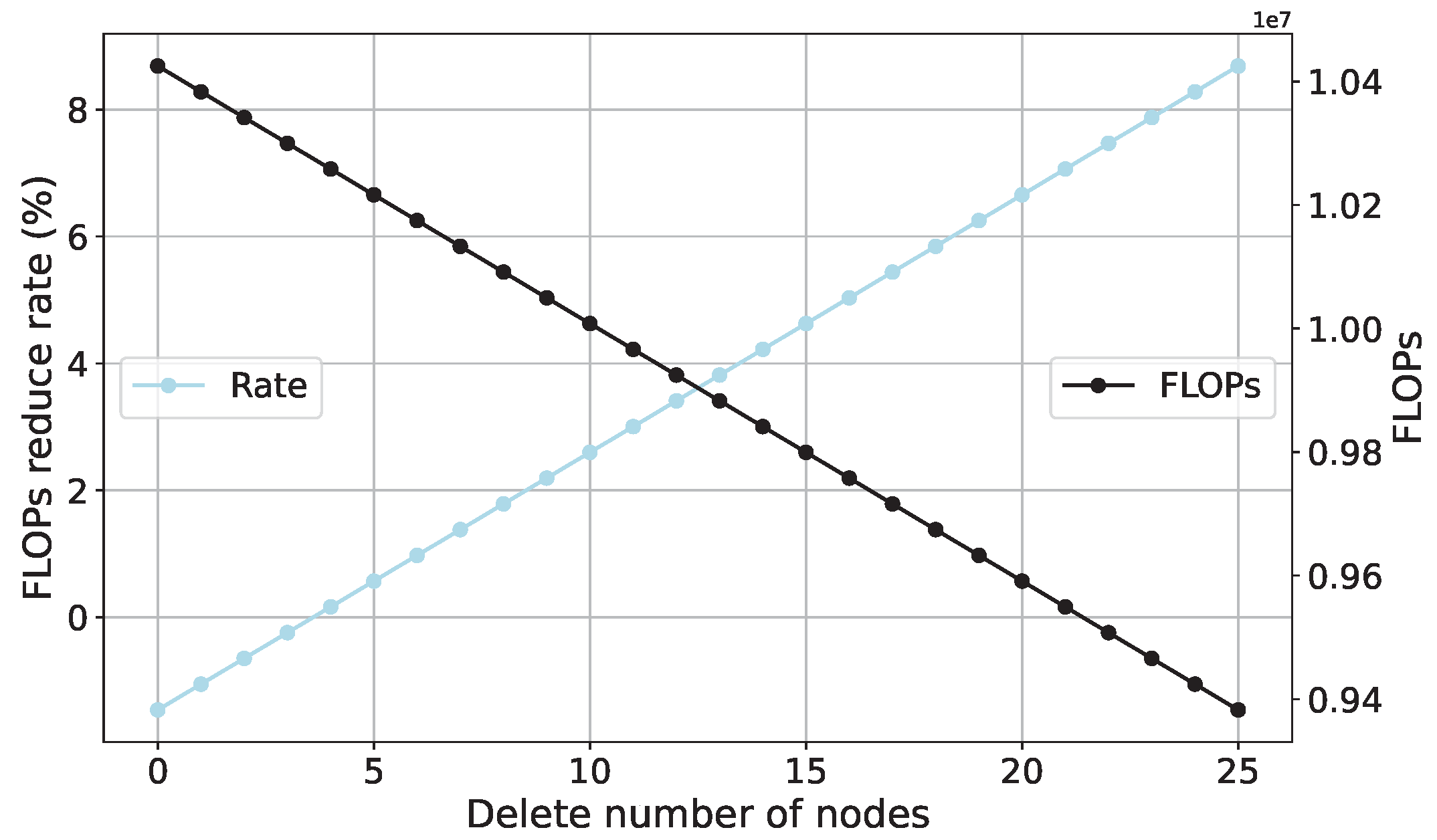
4.3. FLOPs Analysis of SCN
5. Conclusions
- Key Findings: The study’s primary findings can be summarized in three key points:
- a.
- Using raw multisensor data directly as input for the self-constructing network (SCN) is unsuitable.
- b.
- Employing randomly generated rectangular convolutional kernels for feature extraction is effective.
- c.
- SCNs contain redundant nodes, and the random node deletion algorithm efficiently eliminates them.
- Feature Extraction Enhancement: In traditional deep learning, a fully connected network handles classification by extracting features. SCNs operate similarly but lack robust feature extraction capabilities for complex monitoring data. To address this, we introduce a convolution-based feature extraction approach inspired by deep learning, utilizing randomly generated rectangular convolutional kernels. This method is validated through experimental results.
- Improved Model Performance: Concatenating raw data as input leads to information loss between sensors and low accuracy. The introduction of feature extraction using random convolutional kernels significantly improves model performance, with accuracy increasing by approximately 30%. Notably, rectangular convolutional kernels outperform one-dimensional kernels similar to Rocket.
- Random Node Deletion: The experiments with the random node deletion algorithm demonstrate its potential for enhancing model performance, particularly when used on benchmark datasets. This approach achieves parameter reduction and improved performance.
- Overall Implications: The experimental results emphasize the impact of employing random feature extraction, adjusting convolutional kernels, and node deletion on model performance. These findings are valuable for optimizing model design and parameter selection in monitoring data processing.
- SCN for Multisensor Data: Conventional SCNs are not suitable for multisensor monitoring data. The study introduces random 2D convolutional kernels for feature extraction in this context. Future research should explore improved feature extraction methods and enhanced random mapping approaches.
- Future Applications: While this paper primarily focuses on loss recognition, the framework has the potential to extend to other monitoring tasks, such as anomaly detection, remaining useful life prediction, and vehicle load modeling.
- The method proposed in this paper is better suited for data with small mean fluctuations (such as acceleration data oscillating around zero), and is not applicable to data where mean values suddenly increase or decrease, such as deflection and strain [48]. When sampling from non-Gaussian or mixed probability distributions, it is relatively easier to collect data with skewed characteristics, heavy tails, and the presence of outliers as compared to the Gaussian distribution. This poses a significant challenge for time series models. Subsequent research will consider more universally applicable models for data of different distributions.
Author Contributions
Funding
Conflicts of Interest
References
- Chesné, S.; Deraemaeker, A. Damage localization using transmissibility functions: A critical review. Mech. Syst. Signal Process. 2013, 38, 569–584. [Google Scholar] [CrossRef]
- Amezquita-Sanchez, J.P.; Adeli, H. Signal processing techniques for vibration-based health monitoring of smart structures. Arch. Comput. Methods Eng. 2016, 23, 1–15. [Google Scholar] [CrossRef]
- Meruane, V.; Heylen, W. An hybrid real genetic algorithm to detect structural damage using modal properties. Mech. Syst. Signal Process. 2011, 25, 1559–1573. [Google Scholar] [CrossRef]
- Wu, R.T.; Jahanshahi, M.R. Data fusion approaches for structural health monitoring and system identification: Past, present, and future. Struct. Health Monit. 2020, 19, 552–586. [Google Scholar] [CrossRef]
- Yang, J.; Xiang, F.; Li, R.; Zhang, L.; Yang, X.; Jiang, S.; Zhang, H.; Wang, D.; Liu, X. Intelligent bridge management via big data knowledge engineering. Autom. Constr. 2022, 135, 104118. [Google Scholar] [CrossRef]
- Li, R.; Mo, T.; Yang, J.; Li, D.; Jiang, S.; Wang, D. Bridge inspection named entity recognition via BERT and lexicon augmented machine reading comprehension neural model. Adv. Eng. Inform. 2021, 50, 101416. [Google Scholar] [CrossRef]
- Yang, J.; Huang, L.; Tong, K.; Tang, Q.; Li, H.; Cai, H.; Xin, J. A Review on Damage Monitoring and Identification Methods for Arch Bridges. Buildings 2023, 13, 1975. [Google Scholar] [CrossRef]
- Cosenza, E.; Manfredi, G. Damage indices and damage measures. Prog. Struct. Eng. Mater. 2000, 2, 50–59. [Google Scholar] [CrossRef]
- Kaouk, M.; Zimmerman, D.C. Structural damage assessment using a generalized minimum rank perturbation theory. AIAA J. 1994, 32, 836–842. [Google Scholar] [CrossRef]
- Zimmerman, D.C.; Kaouk, M. Structural damage detection using a minimum rank update theory. J. Vib. Acoust. Trans. ASME 1994. [Google Scholar] [CrossRef]
- Farrar, C.R.; Worden, K. An introduction to structural health monitoring. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2007, 365, 303–315. [Google Scholar] [CrossRef] [PubMed]
- Farrar, C.R.; Worden, K. Structural Health Monitoring: A Machine Learning Perspective; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar] [CrossRef]
- Avci, O.; Abdeljaber, O.; Kiranyaz, S.; Hussein, M.; Inman, D.J. Wireless and real-time structural damage detection: A novel decentralized method for wireless sensor networks. J. Sound Vib. 2018, 424, 158–172. [Google Scholar] [CrossRef]
- Chaabane, M.; Hamida, A.B.; Mansouri, M.; Nounou, H.N.; Avci, O. Damage detection using enhanced multivariate statistical process control technique. In Proceedings of the 2016 17th International Conference on Sciences and Techniques of Automatic Control and Computer Engineering (STA), Sousse, Tunisia, 19–21 December 2016; pp. 234–238. [Google Scholar] [CrossRef]
- Catbas, F.N.; Celik, O.; Avci, O.; Abdeljaber, O.; Gul, M.; Do, N.T. Sensing and monitoring for stadium structures: A review of recent advances and a forward look. Front. Built Environ. 2017, 3, 38. [Google Scholar] [CrossRef]
- Park, S.; Yun, C.B.; Roh, Y.; Lee, J.J. PZT-based active damage detection techniques for steel bridge components. Smart Mater. Struct. 2006, 15, 957. [Google Scholar] [CrossRef]
- Farrar, C.R.; Doebling, S.W.; Nix, D.A. Vibration–based structural damage identification. Philos. Trans. R. Soc. Lond. Ser. A Math. Phys. Eng. Sci. 2001, 359, 131–149. [Google Scholar] [CrossRef]
- Xia, Y.; Jian, X.; Yan, B.; Su, D. Infrastructure safety oriented traffic load monitoring using multi-sensor and single camera for short and medium span bridges. Remote Sens. 2019, 11, 2651. [Google Scholar] [CrossRef]
- Hu, L.; Bao, Y.; Sun, Z.; Meng, X.; Tang, C.; Zhang, D. Outlier Detection Based on Nelder-Mead Simplex Robust Kalman Filtering for Trustworthy Bridge Structural Health Monitoring. Remote Sens. 2023, 15, 2385. [Google Scholar] [CrossRef]
- Adewuyi, A.; Wu, Z. Vibration-Based Structural Health Monitoring Technique Using Statistical Features from Strain Measurements. J. Eng. Appl. Sci. 2006, 4, 3. Available online: https://www.researchgate.net/publication/237143477_Vibration-based_structural_health_monitoring_technique_using_statistical_features_from_strain_measurements (accessed on 11 September 2023).
- Noori Hoshyar, A.; Rashidi, M.; Yu, Y.; Samali, B. Proposed Machine Learning Techniques for Bridge Structural Health Monitoring: A Laboratory Study. Remote Sens. 2023, 15, 1984. [Google Scholar] [CrossRef]
- Li, J.; Yang, C.; Chen, J. Sound Damage Detection of Bridge Expansion Joints Using a Support Vector Data Description. Sensors 2023, 23, 3564. [Google Scholar] [CrossRef]
- Osornio-Rios, R.A.; Amezquita-Sanchez, J.P.; Romero-Troncoso, R.J.; Garcia-Perez, A. MUSIC-ANN analysis for locating structural damages in a truss-type structure by means of vibrations. Comput.-Aided Civ. Infrastruct. Eng. 2012, 27, 687–698. [Google Scholar] [CrossRef]
- Jayaswal, P.; Verma, S.N.; Wadhwani, A.K. Application of ANN, fuzzy logic and wavelet transform in machine fault diagnosis using vibration signal analysis. J. Qual. Maint. Eng. 2010, 16, 190–213. [Google Scholar] [CrossRef]
- Diez, A.; Khoa, N.L.D.; Makki Alamdari, M.; Wang, Y.; Chen, F.; Runcie, P. A clustering approach for structural health monitoring on bridges. J. Civ. Struct. Health Monit. 2016, 6, 429–445. [Google Scholar] [CrossRef]
- Alamdari, M.M.; Rakotoarivelo, T.; Khoa, N.L.D. A spectral-based clustering for structural health monitoring of the Sydney Harbour Bridge. Mech. Syst. Signal Process. 2017, 87, 384–400. [Google Scholar] [CrossRef]
- Malhi, A.; Gao, R.X. PCA-based feature selection scheme for machine defect classification. IEEE Trans. Instrum. Meas. 2004, 53, 1517–1525. [Google Scholar] [CrossRef]
- Wang Di, Y.S.X. Intelligent Feature Extraction, Data Fusion and Detection of Concrete Bridge Cracks: Current Development and Challenges. Intell. Robot. 2022, 2, 391–406. [Google Scholar] [CrossRef]
- Tang, Q.; Zhou, J.; Xin, J.; Zhao, S.; Zhou, Y. Autoregressive model-based structural damage identification and localization using convolutional neural networks. KSCE J. Civ. Eng. 2020, 24, 2173–2185. [Google Scholar] [CrossRef]
- Xu, Y.; Wei, S.; Bao, Y.; Li, H. Automatic seismic damage identification of reinforced concrete columns from images by a region-based deep convolutional neural network. Struct. Control Health Monit. 2019, 26, e2313. [Google Scholar] [CrossRef]
- Abdeljaber, O.; Avci, O.; Kiranyaz, M.S.; Boashash, B.; Sodano, H.; Inman, D.J. 1-D CNNs for structural damage detection: Verification on a structural health monitoring benchmark data. Neurocomputing 2018, 275, 1308–1317. [Google Scholar] [CrossRef]
- Yang, J.; Zhang, L.; Chen, C.; Li, Y.; Li, R.; Wang, G.; Jiang, S.; Zeng, Z. A hierarchical deep convolutional neural network and gated recurrent unit framework for structural damage detection. Inf. Sci. 2020, 540, 117–130. [Google Scholar] [CrossRef]
- Yang, J.; Yang, F.; Zhou, Y.; Wang, D.; Li, R.; Wang, G.; Chen, W. A data-driven structural damage detection framework based on parallel convolutional neural network and bidirectional gated recurrent unit. Inf. Sci. 2021, 566, 103–117. [Google Scholar] [CrossRef]
- Liao, S.; Liu, H.; Yang, J.; Ge, Y. A channel-spatial-temporal attention-based network for vibration-based damage detection. Inf. Sci. 2022, 606, 213–229. [Google Scholar] [CrossRef]
- Pao, Y.H.; Takefuji, Y. Functional-link net computing: Theory, system architecture, and functionalities. Computer 1992, 25, 76–79. [Google Scholar] [CrossRef]
- Gorban, A.N.; Tyukin, I.Y.; Prokhorov, D.V.; Sofeikov, K.I. Approximation with random bases: Pro et contra. Inf. Sci. 2016, 364, 129–145. [Google Scholar] [CrossRef]
- Li, M.; Wang, D. Insights into randomized algorithms for neural networks: Practical issues and common pitfalls. Inf. Sci. 2017, 382, 170–178. [Google Scholar] [CrossRef]
- Wang, D.; Li, M. Stochastic configuration networks: Fundamentals and algorithms. IEEE Trans. Cybern. 2017, 47, 3466–3479. [Google Scholar] [CrossRef]
- Dai, W.; Li, D.; Zhou, P.; Chai, T. Stochastic configuration networks with block increments for data modeling in process industries. Inform. Sci. 2019, 484, 367–386. [Google Scholar] [CrossRef]
- Zhang, C.; Ding, S. A stochastic configuration network based on chaotic sparrow search algorithm. Knowl.-Based Syst. 2021, 220, 106924. [Google Scholar] [CrossRef]
- Liu, J.; Hao, R.; Zhang, T.; Wang, X. Vibration fault diagnosis based on stochastic configuration neural networks. Neurocomputing 2021, 434, 98–125. [Google Scholar] [CrossRef]
- Li, W.; Tao, H.; Li, H.; Chen, K.; Wang, J. Greengage grading using stochastic configuration networks and a semi-supervised feedback mechanism. Inf. Sci. 2019, 488, 1–12. [Google Scholar] [CrossRef]
- Johnson, E.A.; Lam, H.F.; Katafygiotis, L.S.; Beck, J.L. Phase I IASC-ASCE structural health monitoring benchmark problem using simulated data. J. Eng. Mech. 2004, 130, 3–15. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Dempster, A.; Petitjean, F.; Webb, G.I. ROCKET: Exceptionally fast and accurate time series classification using random convolutional kernels. Data Min. Knowl. Discov. 2020, 34, 1454–1495. [Google Scholar] [CrossRef]
- Zhao, H.W.; Ding, Y.L.; Li, A.Q.; Chen, B.; Wang, K.P. Digital modeling approach of distributional mapping from structural temperature field to temperature-induced strain field for bridges. J. Civ. Struct. Health Monit. 2023, 13, 251–267. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar] [CrossRef]
- Zhao, H.; Ding, Y.; Meng, L.; Qin, Z.; Yang, F.; Li, A. Bayesian Multiple Linear Regression and New Modeling Paradigm for Structural Deflection Robust to Data Time Lag and Abnormal Signal. IEEE Sens. J. 2023, 23, 19635–19647. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | |||
|---|---|---|---|
| Kernel size | randint [1, 10] | randint [1, 10] | randint [1, 10] |
| I/O channels | 1 | 1 | 1 |
| Stride | randint [1, 3] | randint [1, 3] | randint [1, 3] |
| Padding | randint [1, 3] | randint [1, 3] | randint [1, 3] |
| Dilation | randint [1, 3] | randint [1, 3] | randint [1, 3] |
| Groups | 1 | 1 | 1 |
| Bias | |||
| Weight |
| Case | Descriptions |
|---|---|
| D1 | No damage in the bridge structure. |
| D2 | One crack with width of 0.06 mm. |
| D3 | Two cracks in the mid-span of scale model with widths of (0.11–0.13) mm and (0.02–0.04) mm, respectively. |
| D4 | Two cracks in the mid-span of scale model with widths of 0.12 mm and (0.06–0.08) mm, respectively. |
| Case | Descriptions |
|---|---|
| D1 | No damage. |
| D2 | Remove all diagonal supports on the first floor. |
| D3 | Remove all diagonal supports on the first and second floors. |
| D4 | Remove one diagonal support on the first floor. |
| D5 | Remove a diagonal support on the first and third floors. |
| D6 | D4 + Weaken the left side of the 18 element (first layer beam element). |
| D7 | Reserve 2/3 of an oblique support area on the first floor. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, Y.; Wang, D.; Liu, D.; Yang, X. A Lightweight and Efficient Method of Structural Damage Detection Using Stochastic Configuration Network. Sensors 2023, 23, 9146. https://doi.org/10.3390/s23229146
Lu Y, Wang D, Liu D, Yang X. A Lightweight and Efficient Method of Structural Damage Detection Using Stochastic Configuration Network. Sensors. 2023; 23(22):9146. https://doi.org/10.3390/s23229146
Chicago/Turabian StyleLu, Yuanming, Di Wang, Die Liu, and Xianyi Yang. 2023. "A Lightweight and Efficient Method of Structural Damage Detection Using Stochastic Configuration Network" Sensors 23, no. 22: 9146. https://doi.org/10.3390/s23229146
APA StyleLu, Y., Wang, D., Liu, D., & Yang, X. (2023). A Lightweight and Efficient Method of Structural Damage Detection Using Stochastic Configuration Network. Sensors, 23(22), 9146. https://doi.org/10.3390/s23229146