
Bicycle Data-Driven Application Framework: A Dutch Case Study on Machine Learning-Based Bicycle Delay Estimation at Signalized Intersections Using Nationwide Sparse GPS Data

 , ,
, , 
Abstract
:1. Introduction
2. Framework for Bicycle Data-Driven Applications
3. Application on Bike Delay Estimation
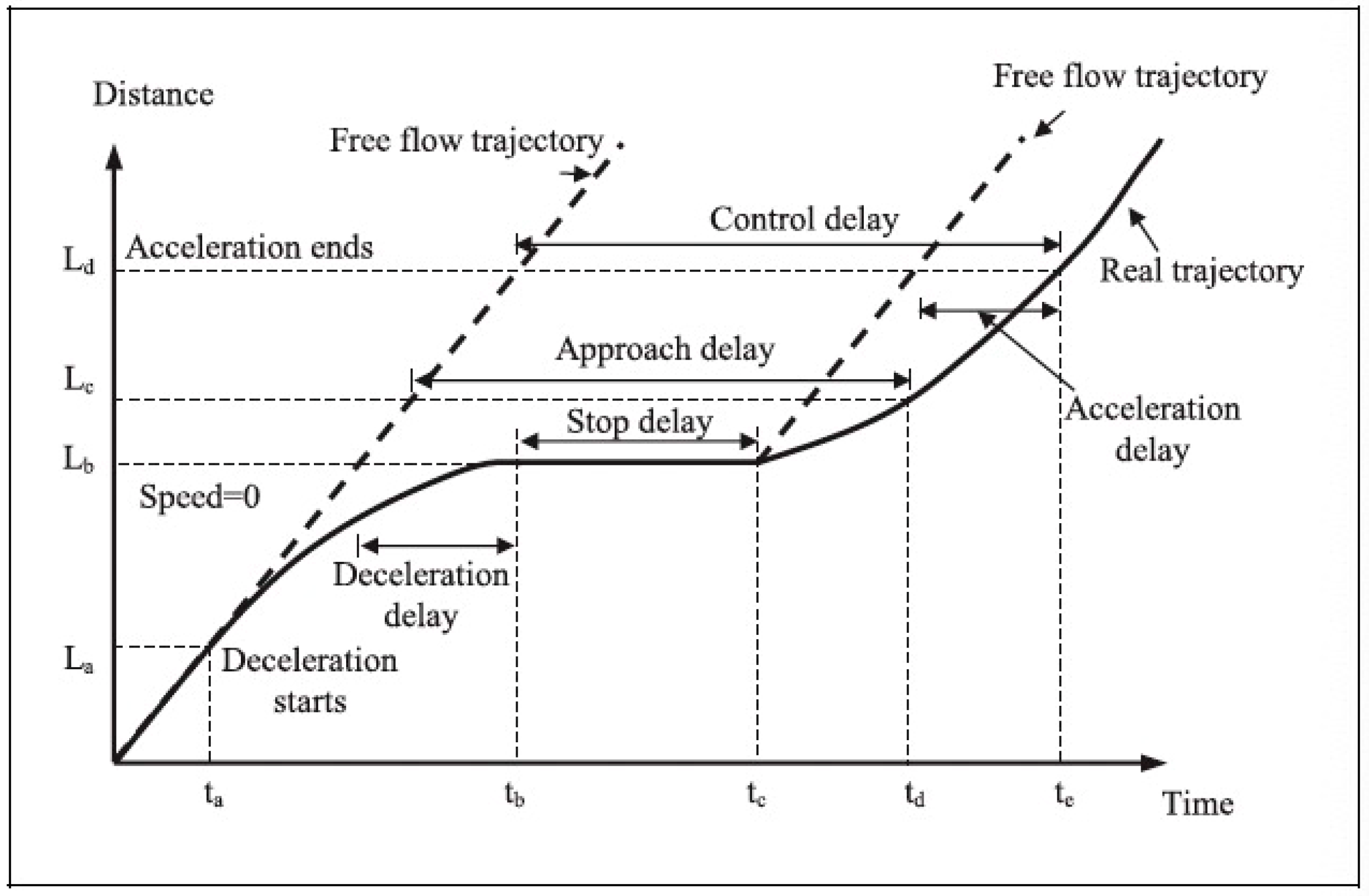
3.1. Related Work on Bicycle Delay Estimation
3.2. A Conceptual Framework for Determining Bike Delays at Signalized Intersections
3.3. Intersection Delay Estimation Approaches
4. Introduction to the Delay Estimation Case Study
4.1. Dataset
4.2. Delay Definition
4.3. Influential Variables in Delay Estimation Models
4.4. Hyperparameter Tuning and Estimation Model Setup
4.5. Performance Indicators
5. Results and Discussion
5.1. Exploratory Data Analysis
5.2. ML Model Training and Testing Results
5.3. Best Performance Model and Its Implications
5.4. Reflection on Relevant Insights
6. Conclusions and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Top 10 Countries with the Highest Bicycle Usage. Available online: https://rankingroyals.com/infographics/top-10-countries-with-the-highest-bicycle-usage/ (accessed on 1 July 2023).
- De Haas, M.; Hamersma, M. Cycling Facts: New Insights; Netherlands Institute for Transport Policy Analysis: Den Haag, The Netherlands, 2020. [Google Scholar]
- Thigpen, C. Rethinking Travel in the Era of COVID-19: Survey Findings and Implication for Urban Transportation, Support for Micromobility. Available online: https://www.li.me/blog/rethinking-travel-in-the-era-of-covid-19-new-report-shows-global-transportation-trends-support-for-micromobility (accessed on 1 July 2023).
- Duran Bernardes, S.; Ozbay, K. BSafe-360: An All-in-One Naturalistic Cycling Data Collection Tool. Sensors 2023, 23, 6471. [Google Scholar] [CrossRef]
- Gillis, D.; Gautama, S.; Van Gheluwe, C.; Semanjski, I.; Lopez, A.J.; Lauwers, D. Measuring Delays for Bicycles at Signalized Intersections Using Smartphone GPS Tracking Data. ISPRS Int. J. Geo-Inf. 2020, 9, 174. [Google Scholar] [CrossRef]
- New York City: Open Streets Program. Available online: https://portal.311.nyc.gov/article/?kanumber=KA-03327#:~:text=New%20York%20City’s%20Open%20Streets,enjoy%20cultural%20and%20community%20programs (accessed on 1 July 2023).
- Reid, C. Paris Mayor Anne Hidalgo to Make Good on Pledge to Remove Half of City’s Car Parking Spaces. Available online: https://www.forbes.com/sites/carltonreid/2020/10/20/paris-mayor-anne-hidalgo-to-make-good-on-pledge-to-remove-half-of-citys-car-parking-spaces/?sh=928dc2716ecf (accessed on 1 July 2023).
- Figg, H. Oslo—Promoting Active Transport Modes. Available online: https://www.eltis.org/resources/case-studies/oslo-promoting-active-transport-modes#:~:text=The%20initial%20intention%20of%20the,area%20of%20approximately%201.7%20km2 (accessed on 1 July 2023).
- Steps Ahead! The Future of Barcelona’s Superblock. Available online: https://www.polisnetwork.eu/news/steps-ahead-the-future-of-barcelonas-superblock/#:~:text=The%20superblock%20is%20a%20strategic,for%20interaction%2C%20play%20and%20recreation (accessed on 1 July 2023).
- Monitoring Cycling in the World’s Bicycle Capital. Available online: https://metrocount.com/monitoring-cycling-in-the-worlds-bicycle-capital/ (accessed on 1 July 2023).
- Nationaal Dataportaal Wegverkeer. Available online: https://www.ndw.nu/ (accessed on 1 July 2023).
- Mobiliteitspanel Nederland (MPN). Available online: https://www.mpndata.nl/ (accessed on 1 July 2023).
- Onderzoek Verplaatsingen in Nederland (OViN). Available online: https://www.cbs.nl/nl-nl/onze-diensten/methoden/onderzoeksomschrijvingen/korte-onderzoeksomschrijvingen/onderzoek-verplaatsingen-in-nederland--ovin-- (accessed on 1 July 2023).
- Lancering Nationale FietsTelWeek 2015. Available online: https://www.fietsersbond.nl/nieuws/lancering-nationale-fietstelweek-2015/ (accessed on 1 July 2023).
- Ring-Ring Initiative. Available online: https://ring-ring.nu/wat-is-ring-ring/ (accessed on 1 July 2023).
- Go Velo. Available online: https://govelo.nl/over-ons/ (accessed on 1 July 2023).
- Siemens en RingRing Verzamelen Fietsdata voor Talking Bikes. Available online: https://www.mobiliteitsplatform.nl/artikel/siemens-en-ringring-verzamelen-fietsdata-voor-talking-bikes (accessed on 1 July 2023).
- Tour de Force. Available online: https://fietsberaad.nl/Tour-de-Force-English/Home (accessed on 1 July 2023).
- Bagdatli, M.E.C.; Dokuz, A.S. Vehicle Delay Estimation at Signalized Intersections Using Machine Learning Algorithms. Transp. Res. Rec. 2021, 2675, 110–126. [Google Scholar] [CrossRef]
- Poliziani, C.; Rupi, F.; Schweizer, J.; Saracco, M.; Capuano, D. Cyclist’s Waiting Time Estimation at Intersections, a Case Study with GPS Traces from Bologna. Transp. Res. Procedia 2022, 62, 325–332. [Google Scholar] [CrossRef]
- Cheng, C.; Du, Y.; Sun, L.; Ji, Y. Review on Theoretical Delay Estimation Model for Signalized Intersections. Transp. Rev. 2016, 36, 479–499. [Google Scholar] [CrossRef]
- Murgano, E.; Caponetto, R.; Pappalardo, G.; Cafiso, S.D.; Severino, A. A Novel Acceleration Signal Processing Procedure for Cycling Safety Assessment. Sensors 2021, 21, 4183. [Google Scholar] [CrossRef] [PubMed]
- Xia, H.; Qiao, Y.; Jian, J.; Chang, Y. Using Smart Phone Sensors to Detect Transportation Modes. Sensors 2014, 14, 20843–20865. [Google Scholar] [CrossRef]
- Rijkswaterstaat. Handbook Sustainable Traffic Management—A Guide for Users; The Netherlands AVV Transport Research Centre: Rotterdam, The Netherlands, 2003. [Google Scholar]
- Nijholt, V.; Hoogendoorn, S.P.; Hoogendoorn-Lanser, S.; Yuan, Y. Understanding User Applications and Indicators for Smart Talking Bicycle Data: A Literature Review for the Application of RingRing and Tracefy Data. In Dispuut Verkeer Case Study; Delft University of Technology: Delft, The Netherlands, 2023. [Google Scholar]
- Velthuijsen, T. Calculating Cycling Delay at Signalized Intersections Using Smartphone Data. Bachelor’s Thesis, University of Twente, Enschede, The Netherlands, 2020. [Google Scholar]
- Rupi, F.; Poliziani, C.; Schweizer, J. Analysing the Dynamic Performances of a Bicycle Network with a Temporal Analysis of GPS Traces. Case Stud. Transp. Policy 2020, 8, 770–777. [Google Scholar] [CrossRef]
- Strauss, J.; Miranda-Moreno, L.F. Speed, Travel Time and Delay for Intersections and Road Segments in the Montreal Network Using Cyclist Smartphone GPS Data. Transp. Res. Part D Transp. Environ. 2017, 57, 155–171. [Google Scholar] [CrossRef]
- Kircher, K.; Ihlström, J.; Nygårdhs, S.; Ahlstrom, C. Cyclist Efficiency and Its Dependence on Infrastructure and Usual Speed. Transp. Res. Part F Traffic Psychol. Behav. 2018, 54, 148–158. [Google Scholar] [CrossRef]
- Yuan, Y.; Goñi-Ros, B.; Poppe, M.; Daamen, W.; Hoogendoorn, S.P. Analysis of Bicycle Headway Distribution, Saturation Flow and Capacity at a Signalized Intersection using Empirical Trajectory Data. Transp. Res. Rec. 2019, 2673, 10–21. [Google Scholar] [CrossRef]
- Reggiani, G.; Dabiri, A.; Daamen, W.; Hoogendoorn, S.P. Exploring the Potential of Neural Networks for Bicycle Travel Time Estimation. In Proceedings of the Traffic and Granular Flow 2019, Pamplona, Spain, 3–5 July 2019; pp. 487–493. [Google Scholar]
- Johansson, F. Estimating Interaction Delay in Bicycle Traffic from Point Measurements; Centre for Transport Studies: Stockholm, Sweden, 2018; p. 21. [Google Scholar]
- Flynn, B.S.; Dana, G.S.; Sears, J.; Aultman-Hall, L. Weather Factor Impacts on Commuting to Work by Bicycle. Prev. Med. 2012, 54, 122–124. [Google Scholar] [CrossRef]
- Schmiedeskamp, P.; Zhao, W. Estimating Daily Bicycle Counts in Seattle, Washington, from Seasonal and Weather Factors. Transp. Res. Rec. 2016, 2593, 94–102. [Google Scholar] [CrossRef]
- Lu, T.; Mondschein, A.; Buehler, R.; Hankey, S. Adding Temporal Information to Direct-demand Models: Hourly Estimation of Bicycle and Pedestrian Traffic in Blacksburg, VA. Transp. Res. Part D Transp. Environ. 2018, 63, 244–260. [Google Scholar] [CrossRef]
- Chang, Y.S.; Jo, S.J.; Lee, Y.-T.; Lee, Y. Population Density or Populations Size. Which Factor Determines Urban Traffic Congestion? Sustainability 2021, 13, 4280. [Google Scholar] [CrossRef]
- James, G.; Daniela, W.; Trevor, H.; Robert, T. An Introduction to Statistical Learning: With Applications in R; Springer: New York, NY, USA, 2013. [Google Scholar]
- Biau, G.; Scornet, E. A Random Forest Guided Tour. Test 2016, 25, 197–227. [Google Scholar] [CrossRef]
- Leif, P. K-Nearest Neighbor. Available online: http://www.scholarpedia.org/article/K-nearest_neighbor (accessed on 1 July 2023).
- Smola, A.J.; Schölkopf, B. A Tutorial on Support Vector Regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef]
- Chen, T.; Carlos, G. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, UK, 2016. [Google Scholar]
- Hoogendoorn, S.P. Unified Approach to Estimating Free Speed Distributions. Transp. Res. Part B Methodol. 2005, 39, 709–727. [Google Scholar] [CrossRef]
- Yuan, Y.; Daamen, W.; Duives, D.; Hoogendoorn, S. Comparison of Three Algorithms for Real-Time Pedestrian State Estimation—Supporting a Monitoring Dashboard for Large-Scale Events. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Washington, DC, USA, 1–4 November 2016; pp. 2601–2606. [Google Scholar]
- Balevski, E.I.; Lyubenov, D. A Study of Bicycle Travel Speed. Proc. Univ. Ruse 2018, 57, 154–158. [Google Scholar]
- Guo, N.; Jiang, R.; Wong, S.C.; Hao, Q.-Y.; Xue, S.-Q.; Hu, M.-B. Bicycle Flow Dynamics on Wide Roads: Experiments and Simulation. Transp. Res. Part C Emerg. Technol. 2021, 125, 103012. [Google Scholar] [CrossRef]
- Aurélien, G. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems; O’Reilly Media: Sebastopol, CA, USA, 2019. [Google Scholar]
- West, R.M. Best Practice in Statistics: The Use of Log Transformation. Ann. Clin. Biochem. 2021, 59, 162–165. [Google Scholar] [CrossRef] [PubMed]
- Overgoor, I. Priority at Traffic Lights for Cyclists: How Bicycle-Friendly Are the Traffic Lights in the Municipality of Arnhem; University of Twente: Enschede, The Netherlands, 2015. [Google Scholar]
- Boronat, P.; Pérez-Francisco, M.; Calafate, C.T.; Cano, J.-C. Towards a Sustainable City for Cyclists: Promoting Safety through a Mobile Sensing Application. Sensors 2021, 21, 2116. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predictors | Data Type | Details | Sample Record | |
|---|---|---|---|---|
| Intersection identifier | Intersection_ID | Integer | Intersection index | 1 |
| Weather conditions | Precipitation_Duration | Integer | Duration of precipitation in s over 10 min | 600 |
| Precipitation_Intensity | Decimal | Precipitation intensity over 10 min (mm/h) | 2.41 | |
| Temperature | Decimal | Average air temperature in °C over 10 min | 13.30 | |
| Wind_Average_Speed | Decimal | Average wind speed in m/s over 10 min | 8.47 | |
| Wind_Maximum_Speed | Decimal | Max. actual wind speed in m/s over 10 min | 12.43 | |
| Temporal features | Weekday_Number | Integer | Day of the week of the travel record (with 1 denoting Sunday, 2 denoting Monday, and so forth until 7 [Saturday]) | 1 |
| Hour | Integer | Hour of the day of the travel record | 13 | |
| Peak_Dummy | Dummy | Peak hour indicator (1: peak for the period between 7:00 and 19:00; 0: otherwise) | 1 | |
| Demographic feature | Population | Integer | Population of the region/city | 651,157 (Rotterdam in 2020) |
| Intersection characteristics | Intersection_Type | Integer | Intersection type (Four-armed: 1, three-armed: 2, or roundabout: 3) | 1 |
| Stream_No. | Integer | Standard index of bike flow movements at intersections | 2 | |
| Arms | Integer | Total No. of arms | 4 | |
| Car_Lanes | Integer | Total No. of car lanes | 15 | |
| Bike_Streams | Integer | Total No. of bike streams | 12 | |
| Tram_Dummy | Dummy | The presence of a tram line (1: presence) | 1 | |
| Bus_Dummy | Dummy | The presence of a bus lane (1: presence) | 0 |
| Int. ID | City | Int. Type | #Arms | #CarLanes | #Bike Streams | Tram Dummy | Bus Dummy | #Trip Records |
|---|---|---|---|---|---|---|---|---|
| 1 | Rotterdam | 1 | 4 | 15 | 12 | 1 | 0 | 542 |
| 2 | Rotterdam | 3 | 4 | 14 | 8 | 1 | 1 | 498 |
| 3 | Rotterdam | 1 | 4 | 4 | 12 | 1 | 1 | 898 |
| 4 | Delft | 3 | 4 | 12 | 8 | 1 | 1 | 225 |
| 5 | Delft | 1 | 4 | 12 | 12 | 1 | 1 | 253 |
| 6 | Delft | 2 | 3 | 4 | 6 | 0 | 0 | 168 |
| 7 | The Hague | 1 | 4 | 9 | 12 | 1 | 1 | 899 |
| 8 | The Hague | 1 | 4 | 6 | 12 | 1 | 1 | 588 |
| 9 | The Hague | 2 | 3 | 8 | 6 | 1 | 0 | 637 |
| 10 | Amsterdam | 1 | 4 | 5 | 12 | 1 | 1 | 3007 |
| 11 | Amsterdam | 1 | 4 | 8 | 12 | 1 | 0 | 3488 |
| 12 | Amsterdam | 2 | 3 | 6 | 6 | 1 | 0 | 2420 |
| 13 | Eindhoven | 1 | 4 | 4 | 12 | 0 | 1 | 995 |
| 14 | Eindhoven | 1 | 4 | 12 | 12 | 0 | 1 | 755 |
| 15 | Eindhoven | 1 | 4 | 13 | 12 | 0 | 1 | 242 |
| 16 | Utrecht | 1 | 4 | 4 | 12 | 1 | 1 | 1362 |
| 17 | Utrecht | 1 | 4 | 15 | 12 | 0 | 1 | 1650 |
| 18 | Utrecht | 2 | 3 | 6 | 6 | 0 | 0 | 779 |
| Training | Testing | ||||
|---|---|---|---|---|---|
| Estimation Models | R2 | RMSE (log) | R2 | RMSE (log) | RMSE (Median) |
| Linear regression | 0.045 | 1.141 | 0.040 | 1.126 | |
| Random forest (RF) | 0.347 | 0.944 | 0.097 | 1.092 | 3.62 (s) |
| Gradient boosting trees (XGBoost) | 0.211 | 1.038 | 0.091 | 1.096 | |
| Support vector regression (SVR) | 0.007 | 1.146 | 0.007 | 1.164 | |
| K-nearest neighbors (kNN) | 0.196 | 1.048 | 0.040 | 1.157 | |
| Neural networks (NN) | 0.095 | 1.111 | 0.060 | 1.115 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, Y.; Wang, K.; Duives, D.; Hoogendoorn, S.; Hoogendoorn-Lanser, S.; Lindeman, R. Bicycle Data-Driven Application Framework: A Dutch Case Study on Machine Learning-Based Bicycle Delay Estimation at Signalized Intersections Using Nationwide Sparse GPS Data. Sensors 2023, 23, 9664. https://doi.org/10.3390/s23249664
Yuan Y, Wang K, Duives D, Hoogendoorn S, Hoogendoorn-Lanser S, Lindeman R. Bicycle Data-Driven Application Framework: A Dutch Case Study on Machine Learning-Based Bicycle Delay Estimation at Signalized Intersections Using Nationwide Sparse GPS Data. Sensors. 2023; 23(24):9664. https://doi.org/10.3390/s23249664
Chicago/Turabian StyleYuan, Yufei, Kaiyi Wang, Dorine Duives, Serge Hoogendoorn, Sascha Hoogendoorn-Lanser, and Rick Lindeman. 2023. "Bicycle Data-Driven Application Framework: A Dutch Case Study on Machine Learning-Based Bicycle Delay Estimation at Signalized Intersections Using Nationwide Sparse GPS Data" Sensors 23, no. 24: 9664. https://doi.org/10.3390/s23249664