1. Introduction and Related Works
In this aging society, the number of people with disabilities due to illness or accidents is increasing [
1]. For those with severe disabilities, who are unable to stand and walk, daily toilet care is a complex and heavy task for their caregivers [
2]. Particularly, the transfer task which is particularly important for toilet care is very burdensome and needs special body mechanics and the usage of proper techniques. Repeated lifting actions over a long period will harm the caregiver’s waist and reduce his or her work efficiency. Therefore, following appropriate techniques and utilizing excretion care robots (ECR) can make the transfer task more manageable and reduce the potential for injuries [
3]. In the author’s lab, we developed an excretion care robot in our previous study [
4]. To complete the transfer-assist task, the excretion care robot’s accurate recognition of transfer-assisted actions is crucial during its usage. Therefore, a highly reliable estimation of human posture and an accurate prediction of human movement is highly described.
Currently, research on predicting individualized movements for transferring and caring for the mobility-impaired is still in its early stages. However, various methods have been proposed for general motion prediction. Examples include methods based on vision, wearable sensors, and electromyography. However, specific scenarios like toilet care transfer also pose unique challenges. In addition to considering sensor applicability, predictive models must address issues of accuracy, real-time performance, and generalization capabilities in this context. The utilization of 3D human body models to capture motion characteristics is considered an effective approach, but existing models are computationally intensive and exhibit complexities in their expression, leading to a lag in reconstructing human motion. Furthermore, studies often focus solely on movements within the sagittal plane, with limited consideration for lateral swaying. Given that both predictive models and 3D human body model data are derived from sensors, ensuring high reliability, minimal error, and low drift in the data is crucial for this research.
Many methods exist for predicting human body movements. In terms of visual sensors [
5], human body movements can be predicted by modeling the spatial information of the body’s skeletal points. Common models used for predicting human actions include convolutional neural network (CNN) models [
6] and prediction models based on graph convolutional networks (GCN) [
7]. Study [
8] uses a multi-path convolutional network to learn the movement trajectory features of each joint in the human body. However, it is difficult for graph neural networks to fully model the correlations between one joint and other joints in the human body since they model the dynamic information of the human body based on nodes. In addition, during activities such as using the bathroom or getting on and off transportation, visual sensors may be affected by environmental factors such as lighting, as well as privacy concerns. In wearable sensor-based human action prediction [
9], conventional methods typically rely on Markov assumptions, smoothness, or low dimensionality to simulate real movements and provide predictions. A study [
10] proposed an ordered Markov chain to recognize and predict human action behaviors a few seconds earlier. However, the methods mentioned above are almost discrete, whereas human motion is continuous and nonlinear. Establishing a mapping model between joint angles and human movements based on wearable sensors is a feasible approach to addressing human motion prediction. This involves building a human model [
11] to obtain the trajectory of human motions. Study [
12] constructed an upper limb equivalent model based on the human anatomical structure and motion biomechanics model and evaluated and improved the trajectory planning of exoskeletons based on this model. However, current research in human modeling often simplifies computations by considering only movements in the sagittal plane [
13,
14]. Due to lower limb impairments, individuals with mobility difficulties may require assistance from others, causing their bodies to lean towards one side. In such cases, it is necessary to consider movements in the coronal plane when analyzing human motion trajectories. Furthermore, in three-dimensional modeling, there are challenges such as complex expressions and difficulties in reconstructing human motion [
15]. The complexity of the model and its expressions can result in a certain degree of lag in the model’s predictions. However, wearable sensors in practical applications are susceptible to various environmental factors. For example, accelerometers and gyroscopes are subject to measurement noise, biases, drift, and other influencing factors during their usage [
16]. The extended Kalman filter (EKF) [
17] is a suitable choice for handling nonlinear motion which has excellent noise-handling capabilities.
The transfer-assisted action of the human body during transferring is influenced by individual differences among caregivers, transfer times, and environmental variations. The differences in transfer actions often lead to variations in movement trajectories. This complexity makes it challenging to predict the movement trajectory of the hips during toileting for a caregiver. Many researchers have employed artificial neural networks (ANN) [
18], support vector machines (SVM) [
19], and Gaussian mixture prediction models [
20] for this purpose. However, these models often require high computational costs. Currently, the LSTM neural network has demonstrated outstanding advantages in its predictions compared to traditional prediction models. Its strength lies in its ability to learn long-term dependencies [
21]. It is an improved version of a recurrent neural network, effectively addressing the issues of gradient explosion and gradient vanishing. The LSTM algorithm has been widely applied in time series prediction problems [
22,
23]. In study [
24], LSTM was used to predict multiple time frames of gait, and the predicted results were highly correlated with the measured trajectories. As the application of LSTM deepens, various structural variants derived from it and algorithms that leverage the good performance of LSTM are still being explored. The well-known basic structure of LSTM is a unidirectional network, which only considers information from previous frames to learn future states, leading to inaccurate predictions. Another variant of LSTM called bidirectional long short-term memory (Bi-LSTM) [
25,
26,
27] can process input time series in both forward and backward directions. When making predictions, it considers both past and future information, capturing a more comprehensive context and resulting in coherent predictions that are closer to the true values. In reference [
28], a motion trajectory tracking system based on inertial measurement units (IMUs), residual neural networks, and Bi-LSTM is proposed. This system accurately predicts daily life activities. Besides considering the model’s prediction accuracy, we also need to evaluate the generalization performance of the model to ensure that it meets the requirements. To improve the generalization of the model and effectively learn time series features, many researchers have started to introduce attention mechanisms (AM) [
29] and their variant structures to enhance the model’s ability to generalize. During the process of assisting individuals in toileting and transferring, the movement trajectory of the individual’s hips is influenced by individual differences, temporal variations, and environmental factors. This necessitates the model to have a high level of generalization to accommodate these variabilities. In response to the aforementioned requirements and existing challenges, we present a novel continuous dynamic trajectory prediction approach based on the MHA Bi-LSTM neural network. The primary objective of this research is to address the issue of predicting motion trajectories characterized by distinctive properties. The MHA exhibits the capability of simultaneously considering multiple attention weights to extract crucial information from different dimensions. Moreover, it can automatically select and focus on the most relevant information. This ability enables the model to better capture important features within diverse motion patterns. The Bi-LSTM neural network combines the flow of information in both forward and backward directions, allowing for the effective utilization of past and future contextual information. This bidirectional modeling capability enables the model to better comprehend the temporal dependencies and dynamic variations within motion trajectories. In summary, the combination of the MHA and Bi-LSTM neural networks allows for the comprehensive utilization of critical information from different dimensions and the effective modeling of temporal dependencies and dynamic variations. This integration improves the accuracy and generalization of dynamic trajectory prediction.
The contribution of this paper is as follows:
- (1)
Develop a 3D model considering the lateral displacement in human motion. To address the issue of lateral displacement in individuals with lower limb weakness, establish the relationship between the angle of coronal plane displacement and lateral displacement using the cosine theorem. Based on geometric relationships, establish a 3D model for the lower limbs to obtain the continuous and dynamic trajectories of human transfer-assisted actions.
- (2)
To address the issue of differentiated transfer-assisted actions, a prediction method based on MHA Bi-LSTM is proposed. By incorporating MHA, key information related to differentiated actions can be extracted from different dimensions and given input weights. The Bi-LSTM network is utilized to effectively consider both past and future information, resulting in more accurate prediction outcomes. This model not only demonstrates strong generalization capabilities but also accurately forecasts multiple frames of motion.
The rest of this paper is presented as follows: in
Section 2, the hardware architecture of the system and the multi-sensor data acquisition system are presented;
Section 3 describes the methods used in this paper including the DEKF, the construction of a 3D model of human the human body, and the proposed MHA Bi-LSTM for transfer-assisted actions with differentiated characteristics;
Section 4 presents a discussion of the extensive experimental details of this paper; and
Section 5 gives our experimental conclusions.
4. Experiment
The experiments in this section are divided into two parts: a 3D human model experiment based on DEKF to acquire human lower limb motion trajectories, and a human hip motion trajectory prediction experiment based on MHA Bi-LSTM. The experiments were conducted in a laboratory setting with three subjects who provided informed consent and complied with ethical regulations. The average age, height, and weight of the three subjects were 23 years, 175 cm, and 62 kg, respectively. When doing the transfer maneuver for assisted toileting, we ask that it be the same caregiver assisting. To avoid a distortion of the caregiver-assisted movements, each movement will be separated by a period. Each subject was asked to perform three different maneuvers: sitting normally (meaning a small left–right shift), shifting to the left, and shifting to the right. The collected movement data were then constructed into a separate dataset to be used as a training model.
The experimental environment was as follows: CPU: 11th Gen Intel(R) Core (TM) i5-1135G7 2.42 GHz, Memory: 8GB, Development Environment: Win 11, Programming Language: Python, and Software Used: Visual Studio 2017.
4.1. Validation of the 3D Model
To verify the validity of the model, we assisted the human body to do transfer-assisted actions from standing to sitting, including a downward sitting movement with no offset, a downward sitting movement with a rightward offset, and a downward sitting movement with a leftward offset. The measurement equation and the initial covariance matrix
P0 of DEKF and the 3D model are given as shown in Equation (15).
The variance matrix of the system noise is Q0 = Diag (0.005, 0.005, 0.005), and the variance matrix of the measurement noise is Rk+1 = Diag (5, 5, 5). In addition, in the 3D model, we set the length of the thigh as l1 = 0.5 m, and the length of the calf as l2 = 0.4 m.
Figure 8a–c provides the experimental details of the three different sets of downward sitting motions, the trajectories of the hips during the downward sitting motions, and the positional changes of the hips in the
X,
Y, and
Z directions during the downward sitting motions.
As shown in
Figure 8, the path of the hip is given in the 3D path as a blue line, the path in the sagittal plane as a black line, and the offset in the
Y-axis as a red line. The offset in the
Y-axis direction can be derived from the XYZ position change diagram. A comparison of the three down-sit paths is shown in
Figure 9.
To validate the validity and accuracy of the 3D model constructed in this study, we used a multi-point calibration measurement method, which utilizes pre-calibrated seated positions and allows the person to sit down in the calibrated position, during which a total of five dynamic positions are measured at the ankle, knee, hip, calf center of mass, and thigh center of mass of the lower limb, and are then compared to the calibrated position to validate the validity and accuracy of the model. The height of the bench was 0.45 m. A1 and A2 were used to represent the knee, B1 and B2 the hip, C1 and C2 the center of mass of the lower leg, and D1 and D2 the center of mass of the thigh. The experimental details of the multi-point calibration validation method are given in
Figure 10, and
Table 1 gives the measured and calibrated data for a variety of standing-to-sit points.
As can be seen from
Table 1, we have calibrated five points in total, and as we have specified that there is no relative sliding between the foot and the ground in this study, only the four points of the knee, hip, calf center of mass, and thigh center of mass are considered for the accuracy of the model solution.
Table 2 shows that the
Z-axis for the knee, thigh center of mass, and hip are slightly higher than the calibrated values due to the influence of the measurement technique. The final error can be kept within ±4 cm.
4.2. Validation of Assist Action Prediction Model Considering Individual Differences
To construct the MHA Bi-LSTM prediction model, we used a grid search method to adjust the number of layers and nodes of the hidden layer of the Bi-LSTM network to find the optimal parameters. The best combination of parameters was found. The experimental parameters are set as follows: the learning rate is 0.0005, the number of nodes in the hidden layer is 128, the number of fully connected layers is 3, the number of neurons in the fully connected layer is 128, the number of training ephemera is 100, and the Batch size is 32. The discard rate of the discarded layer is 0.3. The number of parallel running attention mechanisms we set is 5, indicating that there are 5 heads. The CNN layer is used to extract the high dimensional features of the time series as inputs to the Bi-LSTM, whose optimal parameters are obtained using the grid search method. The CNN consists of a setup of a total of two layers, which are the convolutional layer and the maximum pooling layer. Where the convolutional layer’s filters = 64, kernel_size = (3, 3, 3), the activation = ‘relu’, padding = ‘same’, MaxPooling: pool_size = (2, 2, 2), strides = (2, 2, 2), and padding = ‘same’.
We have selected eight different individual shift multiplication action datasets, which include data from three individuals, and to reflect the variability of time, the dataset includes three different sampling times, because the shift multiplication time of different individuals in the real environment is also one of the key factors affecting the experiments. We also tested the prediction performance of the models on the test set for three different models with different shares of the test set and training set by comparing the prediction accuracy of the three algorithms with the MHA LSTM and MHA + CNN + Bi-LSTM.
The comparison of RMSE and MAE for three different algorithms on different datasets for
X,
Y, and
Z directions regarding the prediction results are given in
Figure 11a–c, respectively, and visualized in radar plots. The prediction results of the test set are depicted in line graphs. The MAE of MHA + BiLSTM for the
X-axis prediction is 0.155, which is smaller than the 0.182 MAE for MHA + CNN + BiLSTM and the 0.287 MAE for MHA + LSTM. The RMSE of MHA + BiLSTM for the
X-axis prediction is 0.155, which is smaller than the 0.182 RMSE for MHA + CNN + BiLSTM and the 0.287 RMSE for MHA + LSTM. For the
Y-axis analysis, the MAE predicted by MHA + BiLSTM for the
Y-axis is 0.153, which is smaller than the 0.157 MAE for MHA + LSTM and the 0.177 MAE for MHA + CNN + BiLSTM. The MAE predicted by MHA + BiLSTM for the
Y-axis is 0.153 less than the 0.157 MAE for MHA + LSTM and the 0.177 MAE for MHA + CNN + BiLSTM. In the
Z-axis analysis, the MAE predicted by MHA + BiLSTM for the
Z-axis is 0.2036 less than the 0.3621 MAE for MHA + LSTM and the 0.2384 MAE for MHA + CNN + BiLSTM. The MAE predicted by MHA + BiLSTM for the
Z-axis is 0.2036 less than the 0.3622 MAE for MHA + LSTM and the 0.2384 MAE for MHA + CNN + BiLSTM.
Figure 12 presents the prediction results of three algorithms on eight different datasets. Overall, the three algorithms perform well on Dataset 1 and Dataset 2, but MHA + CNN + BiLSTM exhibits the largest prediction error along the
X-axis for Dataset 2. When predicting Dataset 3, the precision of MHA + CNN + BiLSTM is the lowest for the
Z-axis, followed by MHA + LSTM. Due to the influence of temporal differences in Dataset 4, the average errors along the
Z-axis for MHA + CNN + BiLSTM and MHA + LSTM are 0.4 m and 0.2 m, respectively, both of which are greater than that of MHA + BiLSTM. On Dataset 5, all three algorithms exhibited suboptimal performance, with MHA + CNN + BiLSTM having the lowest precision and an average error of 0.18 m, while MHA + LSTM and MHA + BiLSTM had average errors of 0.05 m. For Dataset 6 and Dataset 8, influenced by individual differences, MHA + BiLSTM demonstrated the highest predictive accuracy. Datasets 6 and 8 are influenced by individual differences, with MHA + BiLSTM demonstrating the highest predictive accuracy. In Dataset 7, both MHA + BiLSTM and MHA + LSTM exhibit relatively high prediction accuracy, while MHA + CNN + BiLSTM has the largest prediction error. To verify the performance of the MHA Bi-LSTM method in the real-time prediction of differential trajectories, we predicted human hip sitting trajectories using MHA Bi-LSTM. We performed online predictions of 15 sample points for three different motion trajectories and quantitatively analyzed them using the mean error, RMSE, and MAE. The detailed analysis results are given in
Table 2.
The calculation equation is given in the following Equations (16) and (17):
where
n is the sample size,
ŷ the predicted value, and
y is the true value.
The following paper conducted experiments on the MHA Bi-LSTM neural network prediction model to make real-time online predictions. According to the results in
Table 2, the highest mean prediction error was 0.043 m, and the lowest was 0.010 m. Notably, the accuracy of predicting the position of Y was lower than the accuracy of predicting other types of motion in the down-sit to the left offset test set.
Table 2 analyzed these three types of motion using three evaluation models: mean error, RMSE, and MAE.
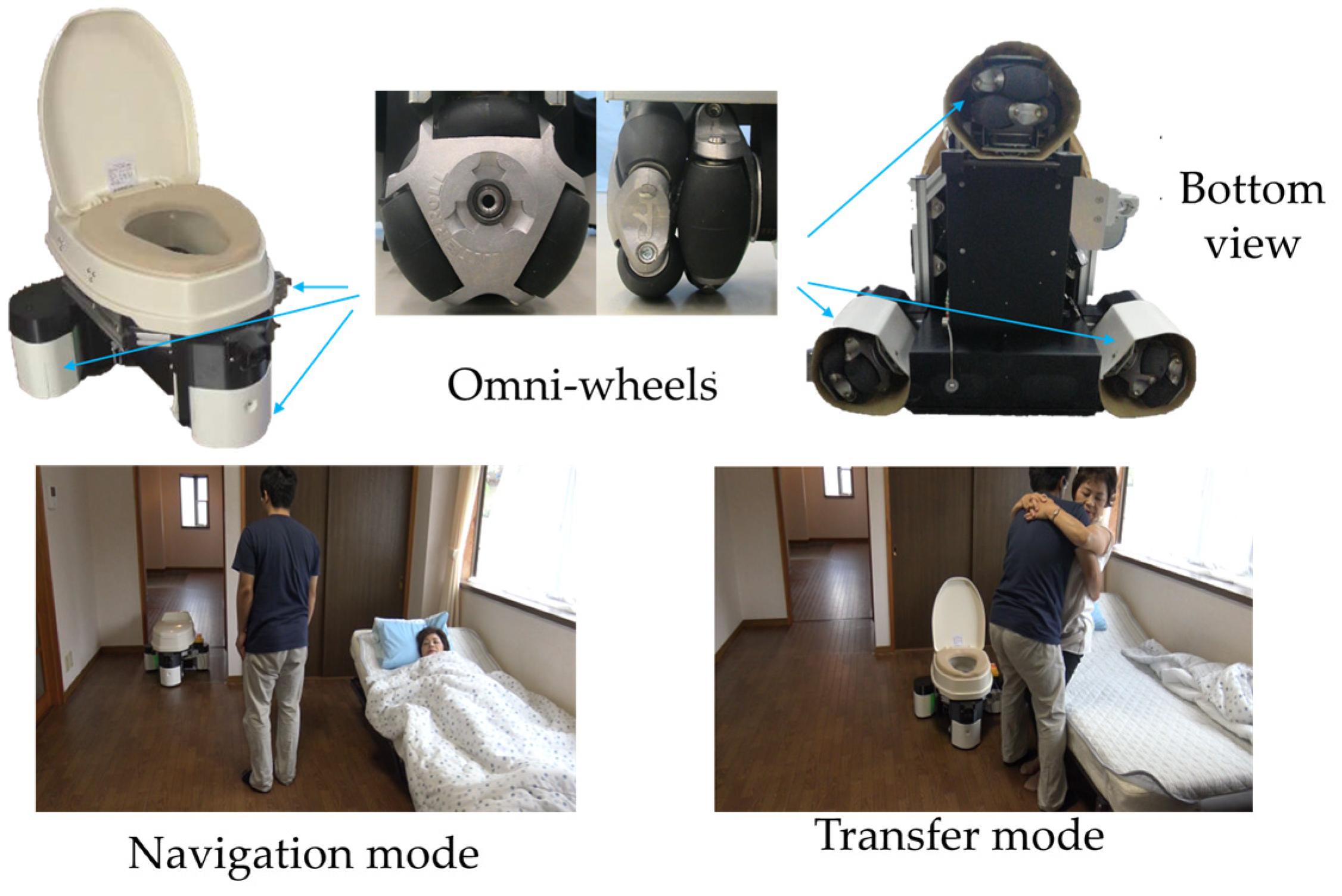
4.3. Validation of Transfer Assist Using the ECR
In the experiments, the ECR’s UWB tag was placed near the rear of the ECR, which is 60 cm from the very front of the ECR, the human body’s UWB tag was placed at the ankle, and the safe distance between the ECR and the human body was set at 5 cm to 10 cm for patient safety. When the robot obtains the human toilet point in advance, it first determines whether the posture is consistent, then the ECR moves towards the target point and finally fine-tunes the angle to provide better service. We judge the distance from the ECR to the buttocks during the ECR traveling process and then adjust the ECR to move along the
X-axis or
Y-axis until it reaches the toilet point. A UWB tag and a WSSS module are placed on the ECR and the right foot of the human body for localization and determination of the Yaw.
Figure 13a,b provides the details of the experimental setting and the location of the ECR with regard to the subjects.
The purposes of the experiments in this subsection are to validate the prediction performance of MHA Bi-LSTM in a real-time environment for different individuals and differences in sitting times with assistance.
The specific procedure for the first set of experiments was as follows, with the process and details of this set of experiments shown in
Figure 14a, and the traveling path of the UWB tracking ECR and the position of each point shown in
Figure 14b:
The first group of experiments is set up without deflection when the human body sits down. From
Figure 14a, we can see that the position of the right foot of the human body is measured by UWB as A1 (−0.130, 3.150), the position of the ECR is measured as C1 (0.540, 3.140), and the MHA Bi-LSTM predicts that the coordinates of the point where the human body sits down are B1 (0.350, −0.011), and the point B1 is translated into the world coordinate system as B11 (0.220, 3.161). From
Figure 14, it can be seen that the best down-sitting point is 30 cm from point C1, namely, D1 (0.240, 3.140). An analysis of points B1 and D1 shows an error of 0.020 m in the
X-axis direction and an error of 0.021 m in the
Y-axis direction, and the error in the
X-axis direction can be reduced by adjusting the safety distance. The error in the
Y-axis can be experimentally accepted.
The specific experimental procedure of the second group is as follows: The second participant was assisted to sit with their hips moving to the right.
Figure 15a presents the relevant details of the experiment, while
Figure 15b provides the UWB tracking and human positioning data related to the ECR movement path. The second participant was assisted to sit with their hips moving to the left, as shown in
Figure 15c, which presents the corresponding details of the experiment.
In the second set of experiments, the right foot position A2 (−0.160, 3.140) and the ECR position C2 (0.468, 3.304) were measured via UWB, and the MHA Bi-LSTM prediction was used to obtain the human body sitting down point B2 (−0.301, 0.125), which was converted to the world coordinate system B22 (0.141, 3.275), and the best sitting down point was D2 (0.168, 3.304). The analysis of B22 and D2 showed that there was an error of 0.027 m in the X direction and 0.029 m in the Y direction.
Figure 15c provides experimental details for Experiment 3. In experiment 3 we conducted the experiments with the same experimenters at different times, and
Figure 15c provides experimental data on the UWB tracking and human localization of ECR movement paths in this set of experiments. In the third group of experiments, the UWB prediction was used to obtain the sitting point A3 (−0.160, 3.140), the ECR position C3 (0.476, 3.011), the MHA Bi-LSTM prediction of the human sitting point B3 (−0.325, 0.153), the conversion of B3 to the world coordinate system B33 (0.165, 2.987), and the best toilet sitting point D3 (0.176, 3.011). By analyzing the B33 and D3 points, we can see that the error in the
X-axis direction is 0.01 m, and the error in the
Y-axis direction is 0.024 m.
In summary, the proposed prediction model of MHA Bi-LSTM demonstrates good predictive performance and robustness when applied to transfer actions involving individual differences and temporal variations.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}