



Computation Offloading and Resource Allocation Based on P-DQN in LEO Satellite Edge Networks



Abstract
:1. Introduction
- To better simulate the real LEO network, the dynamic and changeable LEO satellite scenario is defined. The wireless channel with time-varying characteristics is modeled, the communication and computing models under three different offloading strategies are constructed, and the service latency model is obtained.
- The joint computing offloading and resource allocation problem in the LEO satellite edge network is built. Constraints on offloading decisions on processed tasks, on remaining available computing resources, and on power control on both LEO satellites and the cloud server are respectively inferred, followed by the optimization problem formulation.
- For the highly dynamic LEO satellite edge network and the discrete-continuous hybrid action space, an MDP model with parameterized actions is constructed to capture the dynamics in computing offloading, resource allocation, and power control, and the P-DQN RL method is used to maximize the number of accessed tasks.
2. Related Work
3. System Model and Problem Description
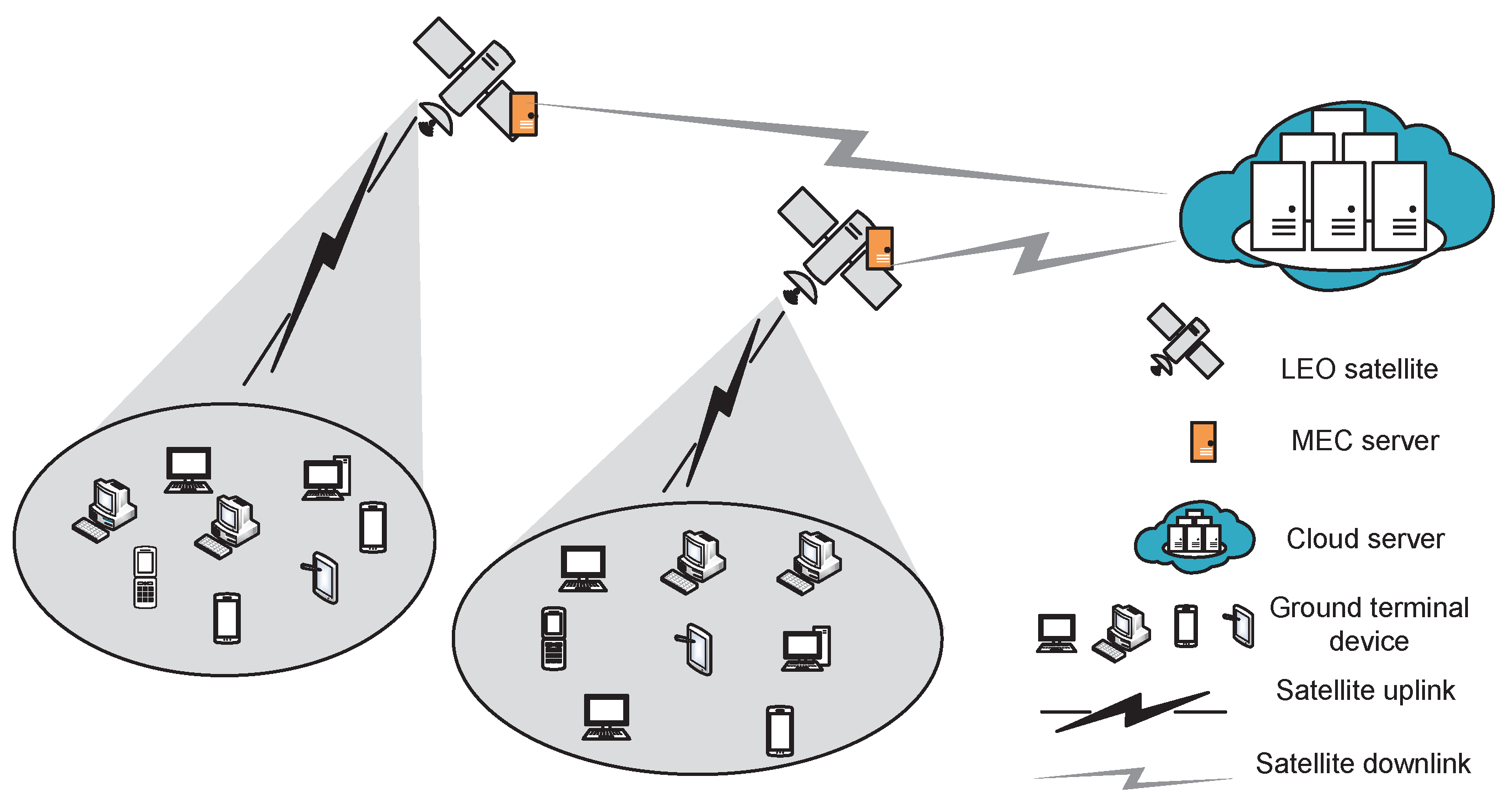
3.1. LEO Satellite Edge Network Model
3.2. Channel Model
3.3. Latency and Satisfied Task Model
| Algorithm 1 Judgment on satisfied conditions of task at slot t |
| Input: unfinished task Output: judgment result
|
3.4. Problem Formulation
4. P-DQN-Based Approach
4.1. MDP with Parameterized Action Space
- State space: For each , define , where and , respectively, represent the sets of new arrival tasks and being already processed ones.
- Parameterized action space: Define the parameterized action as , where . In particular, , , and are three types of offloading decisions. For , and the task is processed locally without parameters; for , the task is offloaded to the LEO satellite, the parameters are and ; and for , the task is offloaded to the cloud server, and the parameters become and .
- Transition probability: A model-free RL architecture is used since both state and action spaces are high-dimensional and we cannot give the precise state transfer.
- Reward function: To judge all tasks in per slot, the temporal reward function per task can be defined as . In particular, when the task is completed in the current slot, takes the large positive value; when the task is judged to be transmitted continuously, is temporarily set to be zero; and when the task fails, is finally set to be negative.
4.2. P-DQN Training
| Algorithm 2 Joint computation offloading and resource allocation with P-DQN |
Input: step sizes and , exploration rate and batch size U.
|
5. Simulations and Results Analysis
5.1. Parameter Settings
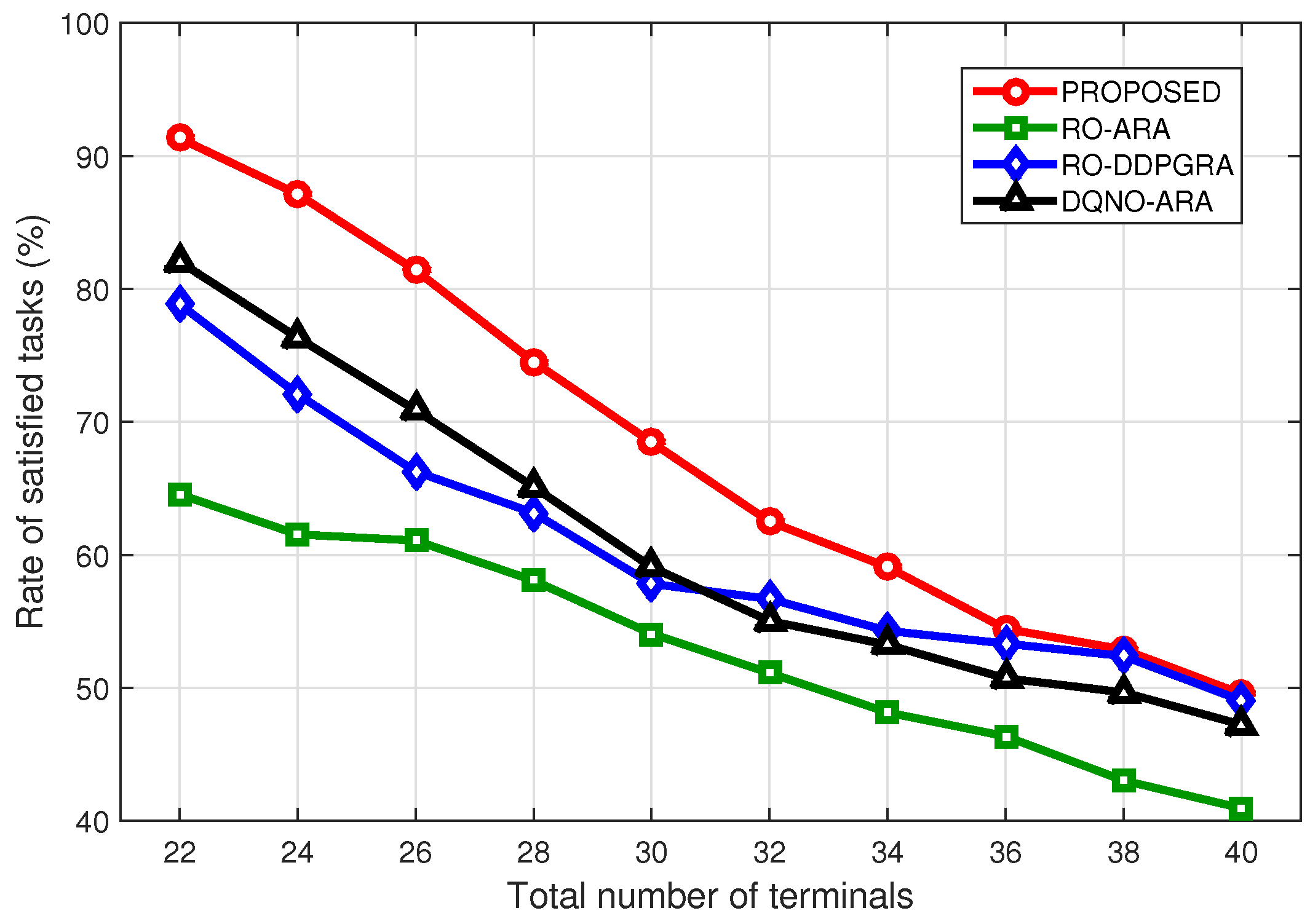
5.2. Performance Analysis
- (1)
- Random offloading (RO): Randomly offloading tasks locally, to LEO satellites and to the cloud server [52].
- (2)
- Average resource allocation (ARA): Computing resources on both LEO satellites and the cloud server are evenly shared among offloaded tasks [40].
- (3)
- DQN offloading (DQNO): The DQN is only used for the task offloading [52].
- (4)
- Deep deterministic policy gradient (DDPG) resource allocation (DDPGRA): The DDPG is used to allocate both computing and power resources for already offloaded tasks.
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Qu, Z.; Zhang, G.; Cao, H.; Xie, J. LEO satellite constellation for Internet of Things. IEEE Access 2017, 5, 18391–18401. [Google Scholar] [CrossRef]
- Chien, W.; Lai, C.; Hossain, M.; Muhammad, G. Heterogeneous space and terrestrial integrated networks for IoT: Architecture and challenges. IEEE Netw. 2019, 33, 15–21. [Google Scholar] [CrossRef]
- Chen, S.; Sun, S.; Kang, S. System integration of terrestrial mobile communication and satellite communication—The trends, challenges and key technologies in B5G and 6G. China Commun. 2020, 17, 156–171. [Google Scholar] [CrossRef]
- Chen, S.; Liang, Y.C.; Sun, S.; Kang, S.; Cheng, W.; Peng, M. Vision, requirements, and technology trend of 6G: How to tackle the challenges of system coverage, capacity, user data-rate and movement speed. IEEE Wirel. Commun. 2020, 27, 218–228. [Google Scholar] [CrossRef]
- Wang, G.; Zhou, S.; Zhang, S.; Niu, Z.; Shen, X. SFC-based service provisioning for reconfigurable space-air-ground integrated networks. IEEE J. Sel. Areas Commun. 2020, 38, 1478–1489. [Google Scholar] [CrossRef]
- Fu, S.; Gao, J.; Zhao, L. Integrated resource management for terrestrial-satellite systems. IEEE Trans. Veh. Technol. 2020, 69, 3256–3266. [Google Scholar] [CrossRef]
- Zhu, X.; Jiang, C.; Kuang, L.; Ge, N.; Guo, S.; Lu, J. Cooperative transmission in integrated terrestrial-satellite networks. IEEE Netw. 2019, 33, 204–210. [Google Scholar] [CrossRef]
- Kapovits, A.; Corici, M.I.; Gheorghe-Pop, I.D.; Gavras, A.; Burkhardt, F.; Schlichter, T.; Covaci, S. Satellite communications integration with terrestrial networks. China Commun. 2018, 15, 22–38. [Google Scholar] [CrossRef]
- Yang, Y.; Ma, M.; Wu, H.; Yu, Q.; Zhang, P.; You, X.; Wu, J.; Peng, C.; Yum, T.-S.P.; Shen, S.; et al. 6G network AI architecture for everyone-centric customized services. IEEE Netw. 2022, 1–10. [Google Scholar] [CrossRef]
- Zhang, S.; Liu, J.; Guo, H.; Qi, M.; Kato, N. Envisioning device-to-device communications in 6G. IEEE Netw. 2020, 34, 86–91. [Google Scholar] [CrossRef]
- Lakew, D.S.; Tran, A.T.; Masood, A.; Dao, N.N.; Cho, S. A Review on Satellite-Terrestrial Integrated Wireless Networks: Challenges and Open Research Issues. In Proceedings of the International Conference on Information Networking (ICOIN), Bangkok, Thailand, 11–14 January 2023; pp. 638–641. [Google Scholar]
- Sun, Y.; Peng, M.; Zhang, S.; Lin, G.; Zhang, P. Integrated satellite-terrestrial networks: Architectures, key techniques, and experimental progress. IEEE Netw. 2022, 36, 191–198. [Google Scholar] [CrossRef]
- Kumar, K.; Liu, J.; Lu, Y.H.; Bhargava, B. A survey of computation offloading for mobile systems. Mob. Netw. Appl. 2013, 18, 974–983. [Google Scholar] [CrossRef]
- Chen, X. Decentralized computation offloading game for mobile cloud computing. IEEE Trans. Parallel Distrib. Syst. 2014, 26, 129–140. [Google Scholar] [CrossRef]
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge computing: Vision and challenges. IEEE Internet Things J. 2016, 3, 637–646. [Google Scholar] [CrossRef]
- Du, J.; Zhao, L.; Feng, J.; Chu, X. Computation offloading and resource allocation in mixed fog/cloud computing systems with min-max fairness guarantee. IEEE Trans. Commun. 2017, 66, 1594–1608. [Google Scholar] [CrossRef]
- Wang, C.; Yu, F.R.; Liang, C.; Chen, Q.; Tang, L. Joint computation offloading and interference management in wireless cellular networks with mobile edge computing. IEEE Trans. Veh. Technol. 2017, 66, 7432–7445. [Google Scholar] [CrossRef]
- Chang, Z.; Zhou, Z.; Ristaniemi, T.; Niu, Z. Energy efficient optimization for computation offloading in fog computing system. In Proceedings of the IEEE Global Communications Conference (IEEE GLOBECOM), Singapore, 4–8 December 2017; pp. 1–6. [Google Scholar]
- Zhu, X.; Jiang, C. Integrated satellite-terrestrial networks toward 6G: Architectures, applications, and challenges. IEEE Internet Things J. 2021, 9, 437–461. [Google Scholar] [CrossRef]
- Brik, B.; Frangoudis, P.A.; Ksentini, A. Service-oriented MEC applications placement in a federated edge cloud architecture. In Proceedings of the IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar]
- Mehrabi, M.; You, D.; Latzko, V.; Salah, H.; Reisslein, M.; Fitzek, F.H.P. Device-enhanced MEC: Multi-access edge computing (MEC) aided by end device computation and caching: A survey. IEEE Access 2019, 7, 166079–166108. [Google Scholar] [CrossRef]
- Li, J.; Wang, R.; Wang, K. Service Function Chaining in Industrial Internet of Things With Edge Intelligence: A Natural Actor-Critic Approach. IEEE Trans. Ind. Inform. 2023, 19, 491–502. [Google Scholar] [CrossRef]
- Hao, Y.; Chen, M.; Hu, L.; Hossain, M.S.; Ghoneim, A. Energy efficient task caching and offloading for mobile edge computing. IEEE Access 2018, 6, 11365–11373. [Google Scholar] [CrossRef]
- Trakadas, P.; Masip-Bruin, X.; Facca, F.M.; Spantideas, S.T.; Giannopoulos, A.E.; Kapsalis, N.C.; Martins, R.; Bosani, E.; Ramon, J.; Prats, R.G.; et al. A reference architecture for cloud-edge meta-operating systems enabling cross-domain, data-intensive, ML-assisted applications: Architectural overview and key concepts. Sensors 2022, 22, 9003. [Google Scholar] [CrossRef] [PubMed]
- Militano, L.; Arteaga, A.; Toffetti, G.; Mitton, N. The cloud-to-edge-to-IoT continuum as an enabler for search and rescue operations. Future Internet 2023, 15, 55. [Google Scholar] [CrossRef]
- Yan, J.; Bi, S.; Zhang, Y.; Tao, M. Optimal task offloading and resource allocation in mobile-edge computing with inter-user task dependency. IEEE Trans. Wirel. Commun. 2019, 19, 235–250. [Google Scholar] [CrossRef]
- Zhang, G.; Zhang, S.; Zhang, W.; Shen, Z.; Wang, L. Joint service caching, computation offloading and resource allocation in mobile edge computing systems. IEEE Trans. Wirel. Commun. 2021, 20, 5288–5300. [Google Scholar] [CrossRef]
- Wu, F.; Leng, S.; Maharjan, S.; Huang, X.; Zhang, Y. Joint Power Control and Computation Offloading for Energy-Efficient Mobile Edge Networks. IEEE Trans. Wirel. Commun. 2021, 21, 4522–4534. [Google Scholar] [CrossRef]
- Tan, L.; Kuang, Z.; Zhao, L.; Liu, A. Energy-efficient joint task offloading and resource allocation in OFDMA-based collaborative edge computing. IEEE Trans. Wirel. Commun. 2021, 21, 1960–1972. [Google Scholar] [CrossRef]
- Ruan, Y.; Li, Y.; Wang, C.X.; Zhang, R.; Zhang, H. Energy efficient power allocation for delay constrained cognitive satellite terrestrial networks under interference constraints. IEEE Trans. Wirel. Commun. 2019, 18, 4957–4969. [Google Scholar] [CrossRef]
- Shi, S.; Li, G.; An, K.; Gao, B.; Zheng, G. Energy-efficient optimal power allocation in integrated wireless sensor and cognitive satellite terrestrial networks. Sensors 2017, 17, 2025. [Google Scholar] [CrossRef]
- Spantideas, S.T.; Giannopoulos, A.E.; Kapsalis, N.C.; Kalafatelis, A.; Capsalis, C.N.; Trakadas, P. Joint energy-efficient and throughput-sufficient transmissions in 5G cells with deep Q-learning. In Proceedings of the IEEE International Mediterranean Conference on Communications and Networking (MeditCom), Athens, Greece, 7–10 September 2021; pp. 265–270. [Google Scholar]
- Hsieh, C.K.; Chan, K.L.; Chien, F.T. Energy-efficient power allocation and user association in heterogeneous networks with deep reinforcement learning. Appl. Sci. 2021, 11, 4135. [Google Scholar] [CrossRef]
- Liu, C.H.; Chen, Z.; Tang, J.; Xu, J.; Piao, C. Energy-efficient UAV control for effective and fair communication coverage: A deep reinforcement learning approach. IEEE J. Sel. Areas Commun. 2018, 36, 2059–2070. [Google Scholar] [CrossRef]
- Li, B.; Liu, Y.; Tan, L.; Zhang, Y. Digital twin assisted task offloading for aerial edge computing and networks. IEEE Trans. Veh. Technol. 2022, 71, 10863–10877. [Google Scholar] [CrossRef]
- Liu, W.; Li, B.; Xie, W.; Fei, Z. Energy efficient computation offloading in aerial edge networks with multi-agent cooperation. IEEE Trans. Wirel. Commun. 2023, 22, 5725–5739. [Google Scholar] [CrossRef]
- Qiu, C.; Yao, H.; Yu, F.R.; Xu, F.; Zhao, C. Deep Q-learning aided networking, caching, and computing resources allocation in software-defined satellite-terrestrial networks. IEEE Trans. Veh. Technol. 2019, 68, 5871–5883. [Google Scholar] [CrossRef]
- Xu, F.; Yang, F.; Zhao, C.; Wu, S. Deep reinforcement learning based joint edge resource management in maritime network. China Commun. 2020, 17, 211–222. [Google Scholar] [CrossRef]
- Cheng, N.; Lyu, F.; Quan, W.; Zhou, C.; He, H.; Shi, W.; Shen, X. Space/aerial-assisted computing offloading for IoT applications: A learning-based approach. IEEE J. Sel. Areas Commun. 2019, 37, 1117–1129. [Google Scholar] [CrossRef]
- Cui, G.; Li, X.; Xu, L.; Wang, W. Latency and energy optimization for MEC enhanced SAT-IoT networks. IEEE Access 2020, 8, 55915–55926. [Google Scholar] [CrossRef]
- Wang, B.; Xie, J.; Huang, D.; Xie, X. A Computation Offloading Strategy for LEO Satellite Mobile Edge Computing System. In Proceedings of the International Conference on Communication Software and Networks (ICCSN), Chongqing, China, 10–12 June 2022; pp. 75–80. [Google Scholar]
- Lyu, Y.; Liu, Z.; Fan, R.; Zhan, C.; Hu, H.; An, J. Optimal Computation Offloading in Collaborative LEO-IoT Enabled MEC: A Multiagent Deep Reinforcement Learning Approach. IEEE Trans. Green Commun. Netw. 2023, 7, 996–1011. [Google Scholar] [CrossRef]
- Maattanen, H.L.; Hofstrom, B.; Euler, S.; Sedin, J.; Lin, X.; Liberg, O.; Masini, G.; Israelsson, M. 5G NR Communication over GEO or LEO Satellite Systems: 3GPP RAN Higher Layer Standardization Aspects. In Proceedings of the IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar]
- Zhou, D.; Sheng, M.; Wang, Y.; Li, J.; Han, Z. Machine learning-based resource allocation in satellite networks supporting internet of remote things. IEEE Trans. Wirel. Commun. 2021, 20, 6606–6621. [Google Scholar] [CrossRef]
- Yuan, Y.; Lei, L.; Vu, T.; Chang, Z.; Chatzinotas, S.; Sun, S. Adapting to dynamic LEO-B5G systems: Meta-critic learning based efficient resource scheduling. IEEE Trans. Wirel. Commun. 2022, 21, 9582–9595. [Google Scholar] [CrossRef]
- Dong, Y.; Wang, L.; Wang, J.; Hu, X.; Zhang, H.; Yu, F.R.; Leung, V.C.M. Accelerating Wireless Federated Learning via Nesterov’s Momentum and Distributed Principle Component Analysis. IEEE Trans. Wirel. Commun. 2023. [Google Scholar] [CrossRef]
- Dong, Y.; Zhang, H.; Li, J.; Yu, F.R.; Guo, S.; Leung, V.C. An online zero-forcing Precoder for weighted sum-rate maximization in green CoMP systems. IEEE Trans. Wirel. Commun. 2022, 21, 7566–7581. [Google Scholar] [CrossRef]
- Xiong, J.; Wang, Q.; Yang, Z.; Sun, P.; Han, L.; Zheng, Y.; Fu, H.; Zhang, T.; Liu, J.; Liu, H. Parametrized deep q-networks learning: Reinforcement learning with discrete-continuous hybrid action space. arXiv 2018, arXiv:1810.06394. [Google Scholar] [CrossRef]
- Masson, W.; Ranchod, P.; Konidaris, G. Reinforcement learning with parameterized actions. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), Phoenix, AZ, USA, 12–17 February 2016; pp. 1934–1940. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Zhang, J.; Zhang, X.; Wang, P.; Liu, L. A computation offloading strategy in satellite terrestrial networks with double edge computing. In Proceedings of the IEEE International Conference on Communication Systems (ICCS), Chengdu, China, 19–21 December 2018; pp. 450–455. [Google Scholar]
- Jiang, W.; Feng, D.; Sun, Y.; Feng, G.; Wang, Z.; Xia, X.G. Joint computation offloading and resource allocation for D2D-Assisted mobile edge computing. IEEE Trans. Serv. Comput. 2023, 16, 1949–1963. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| Length per time slot | 0.1 s |
| Slot number per episode | 100 |
| Task size | bits |
| Number of LEO satellites | 3 |
| LEO satellite orbit altitude | 900 Km |
| Maximum transmit power per LEO satellite | 100 w |
| Maximum transmission power per ground terminal | 20 w |
| Carrier frequency of Ka-Band | 30 GHz |
| Link bandwidth | 25 MHz |
| Number of terminals in region 1 | 14 |
| Number of terminals in region 2 | 12 |
| Number of terminals in region 3 | 8 |
| Noise power spectral density | −174 dBm/Hz |
| Computing resources per LEO satellite | cycle/s |
| Computing resources of cloud server | cycle/s |
| Maximum tolerance latency | 260 ms |
| Discounting factor | 0.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, X.; Fang, H.; Gao, Y.; Wang, X.; Wang, K.; Liu, Z. Computation Offloading and Resource Allocation Based on P-DQN in LEO Satellite Edge Networks. Sensors 2023, 23, 9885. https://doi.org/10.3390/s23249885
Yang X, Fang H, Gao Y, Wang X, Wang K, Liu Z. Computation Offloading and Resource Allocation Based on P-DQN in LEO Satellite Edge Networks. Sensors. 2023; 23(24):9885. https://doi.org/10.3390/s23249885
Chicago/Turabian StyleYang, Xu, Hai Fang, Yuan Gao, Xingjie Wang, Kan Wang, and Zheng Liu. 2023. "Computation Offloading and Resource Allocation Based on P-DQN in LEO Satellite Edge Networks" Sensors 23, no. 24: 9885. https://doi.org/10.3390/s23249885
APA StyleYang, X., Fang, H., Gao, Y., Wang, X., Wang, K., & Liu, Z. (2023). Computation Offloading and Resource Allocation Based on P-DQN in LEO Satellite Edge Networks. Sensors, 23(24), 9885. https://doi.org/10.3390/s23249885