
Adaptive Predefined-Time Sliding Mode Control for QUADROTOR Formation with Obstacle and Inter-Quadrotor Avoidance

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- (1)
- An artificial potential field method with virtual force is proposed to solve the local optimal problem encountered by using the artificial potential field method in the field of quadrotor formation, and the planned trajectory is input to the position controller of the quadrotor.
- (2)
- A predefined-time sliding mode control algorithm for controlling the position and attitude of the quadrotor is studied. Compared with the fixed-time sliding mode algorithm [14], the convergence time of this control algorithm can be expressed explicitly by a certain parameter.
- (3)
- On the basis of contribution (2), an adaptive predefined-time sliding mode control algorithm based on RBF neural networks is proposed so that the predefined-time sliding mode control algorithm can be applied to the occasions where there is interference in the environment or inaccurate modeling of the quadrotor model.
2. Necessary Preliminaries and Problem Formulation
2.1. Necessary Preliminaries
2.2. Quadrotor Dynamic Model
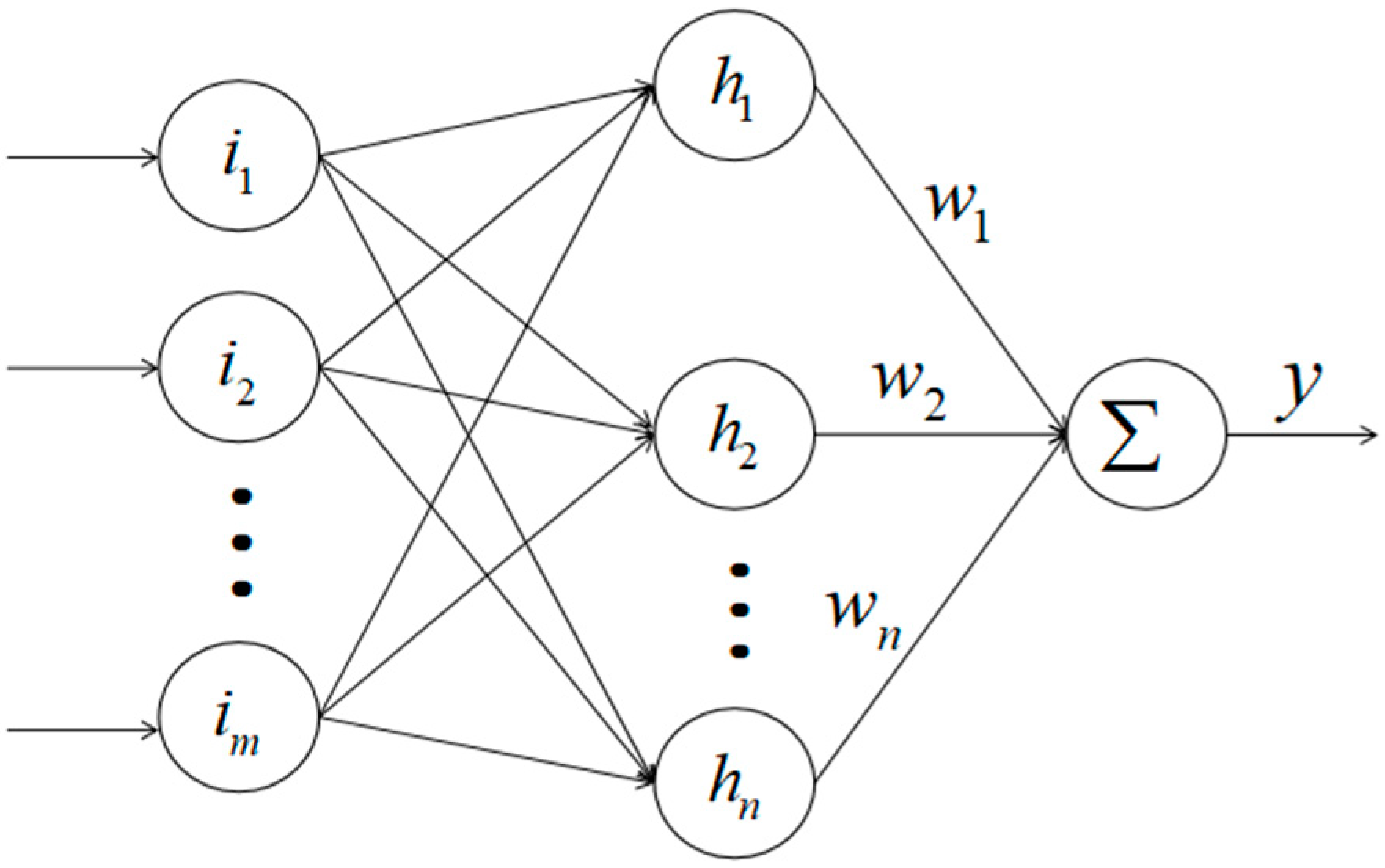
2.3. RBF Neural Network Estimation
3. Path Planning and Controller Design
3.1. The Path Planning of the Formation
3.2. Controller Design
3.2.1. Predefined-Time Sliding Mode Controller Design of the Position Loop
3.2.2. Predefined-Time Sliding Mode Controller Design of the Attitude Loop
4. Simulation Results and Analysis
4.1. Comparison of Predefined-Time Sliding Mode Control and Fixed-Time Sliding Mode Control
4.2. Comparison of Predefined-Time Sliding Mode Control and Adaptive Predefined-Time Sliding Mode Control Based on an RBF Neural Network
4.3. Simulation Results of the Obstacle Avoidance of the Quadrotor Formation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fax, J.A.; Murray, R.M. Information flow and cooperative control of vehicle formations. IEEE Trans. Autom. Control. 2004, 49, 1465–1476. [Google Scholar] [CrossRef] [Green Version]
- Olfati-Saber, R.; Murray, R.M. Consensus problems in networks of agents with switching topology and time-delays. IEEE Trans. Autom. Control. 2004, 49, 1520–1533. [Google Scholar] [CrossRef] [Green Version]
- Qu, Z. Cooperative Control of Dynamical Systems: Applications to Autonomous Vehicles. IEEE Trans. Autom. Control 2009, 53, 894–911. [Google Scholar] [CrossRef]
- Li, Y.; Yang, J.; Zhang, K. Distributed Finite-Time Cooperative Control for Quadrotor Formation. IEEE Access 2019, 7, 66753–66763. [Google Scholar] [CrossRef]
- Shang, W.; Jing, G.; Zhang, D.; Chen, T.; Liang, Q. Adaptive Fixed Time Nonsingular Terminal Sliding- Mode Control for Quadrotor Formation With Obstacle and Inter-Quadrotor Avoidance. IEEE Access 2021, 9, 60640–60657. [Google Scholar] [CrossRef]
- Cong, Y.; Du, H.; Jin, Q.; Zhu, W.; Lin, X. Formation control for multiquadrotor aircraft: Connectivity preserving and collision avoidance. Robust Nonlinear Control. 2020, 30, 2352–2366. [Google Scholar] [CrossRef]
- Yuan, W.; Chen, Q.; Hou, Z.; Li, Y. Multi-UAVs formation flight control based on leader-follower pattern. In Proceedings of the 2017 36th Chinese Control Conference (CCC), Dalian, China, 26–28 July 2017; pp. 276–1281. [Google Scholar]
- Li, Z.P.; Xian, B. Robust distributed formation control of multiple unmanned aerial vehicles based on virtual structure. Control. Theory Appl. 2020, 37, 2423–2431. (In Chinese) [Google Scholar]
- Kan, Y.X.; Zhao, F. Research on Autonomous Navigation Method of Quad Rotor Controller Based on Depth Deterministic Strategy Gradient Algorithm. Electromech. Eng. Technol. 2022, 51, 149–152. [Google Scholar]
- Li, C.; Chen, L.; Guo, Y.; Lyu, Y. Cooperative surrounding control with collision avoidance for networked lagrangian systems. J. Frankl. Inst. -Eng. Appl. Math. 2018, 355, 5182–5202. [Google Scholar] [CrossRef]
- Li, S.; Wang, X. Finite-time consensus and collision avoidance control algorithms for multiple AUVs. Automatica 2013, 49, 3359–3367. [Google Scholar] [CrossRef]
- Pan, H.; Sun, W. Nonlinear output feedback finite-time control for vehicle active suspension systems. IEEE Trans. Ind. Infor-Matics 2019, 15, 2073–2082. [Google Scholar] [CrossRef]
- Liu, H.; Ma, T.; Lewis, F.L.; Wan, Y. Robust formation control for multiple quadrotors with nonlinearities and disturbances. IEEE Trans. Cybern. 2020, 50, 1362–1371. [Google Scholar] [CrossRef] [PubMed]
- Mofid, O.; Mobayen, S. Adaptive sliding mode control for finite-time stability of quad-rotor UAVs with parametric uncertainties. ISA Transactions 2018, 72, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Tian, B.; Cui, J.; Lu, H.; Zuo, Z.; Zong, Q. Adaptive Finite-Time Attitude Tracking of Quadrotors With Experiments and Comparisons. IEEE Trans. Ind. Electron. 2019, 66, 9428–9438. [Google Scholar] [CrossRef]
- Wang, M.Y.; Chen, B.; Lin, C. Prescribed finite-time adaptive neural trajectory tracking control of quadrotor via output feedback. Neurocomputing 2021, 458, 364–375. [Google Scholar] [CrossRef]
- Wu, C.; Yan, J.; Shen, J.; Wu, X.; Xiao, B. Predefined- Time Attitude Stabilization of Receiver Aircraft in Aerial Refueling. IEEE Trans. Circuits Syst. II Express Briefs 2021, 68, 3321–3325. [Google Scholar] [CrossRef]
- Sun, Y.; Zhang, L. Fixed-time adaptive fuzzy control for uncertain strict feedback switched systems. Inf. Sci. 2021, 546, 742–752. [Google Scholar] [CrossRef]
- Chen, Q.; Xie, S.; He, X. Neural-network based adaptive singularity-free fixed-time attitude tracking control for spacecrafts. IEEE Trans. Cybern. 2021, 51, 5032–5045. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, L.Y. Implement of BP and RBF neural network and their performance comparison. Electron. Meas. Technol. 2007, 156, 77–80. [Google Scholar]
- Shou, Y.; Xu, B.; Lu, H.; Zhang, A.; Mei, T. Finite-time formation control and obstacle avoidance of multi-agent system with application. Int. J. Robust Nonlinear. Control. 2022, 32, 2883–2901. [Google Scholar] [CrossRef]
- Wang, J.; Ma, X.; Zhang, G.; Zhang, Y.; Miao, Q. Fixed-Time Terminal Sliding Mode Control for Quadrotor Aircraft. Identif. Control. 2020, 582, 413–421. [Google Scholar]












Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, H.; Tu, H.; Huang, S.; Zheng, X. Adaptive Predefined-Time Sliding Mode Control for QUADROTOR Formation with Obstacle and Inter-Quadrotor Avoidance. Sensors 2023, 23, 2392. https://doi.org/10.3390/s23052392
Liu H, Tu H, Huang S, Zheng X. Adaptive Predefined-Time Sliding Mode Control for QUADROTOR Formation with Obstacle and Inter-Quadrotor Avoidance. Sensors. 2023; 23(5):2392. https://doi.org/10.3390/s23052392
Chicago/Turabian StyleLiu, Hao, Haiyan Tu, Shan Huang, and Xiujuan Zheng. 2023. "Adaptive Predefined-Time Sliding Mode Control for QUADROTOR Formation with Obstacle and Inter-Quadrotor Avoidance" Sensors 23, no. 5: 2392. https://doi.org/10.3390/s23052392