
CenterPNets: A Multi-Task Shared Network for Traffic Perception

Abstract
:1. Introduction
2. Methods
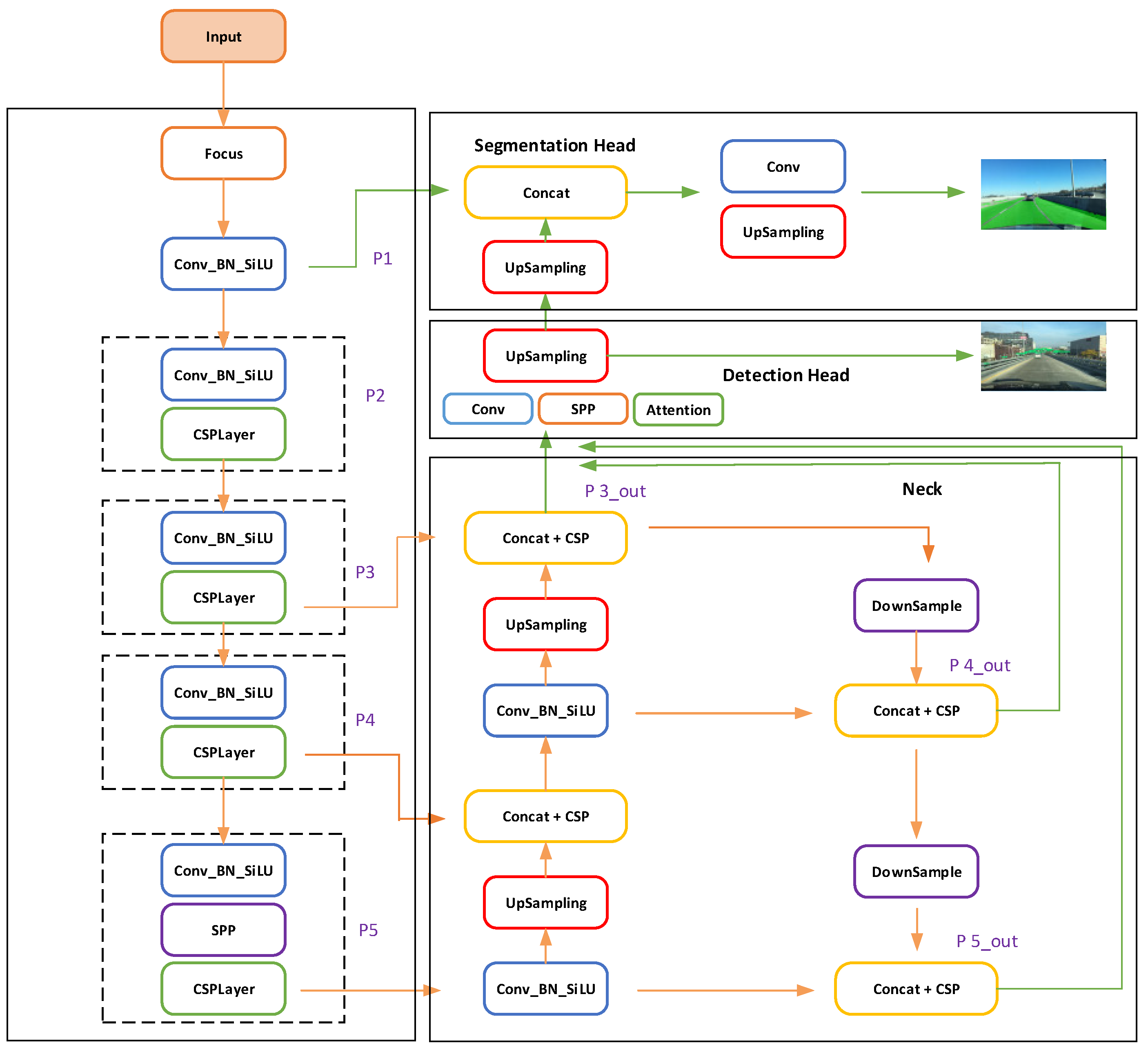
2.1. Network Architecture
- A.
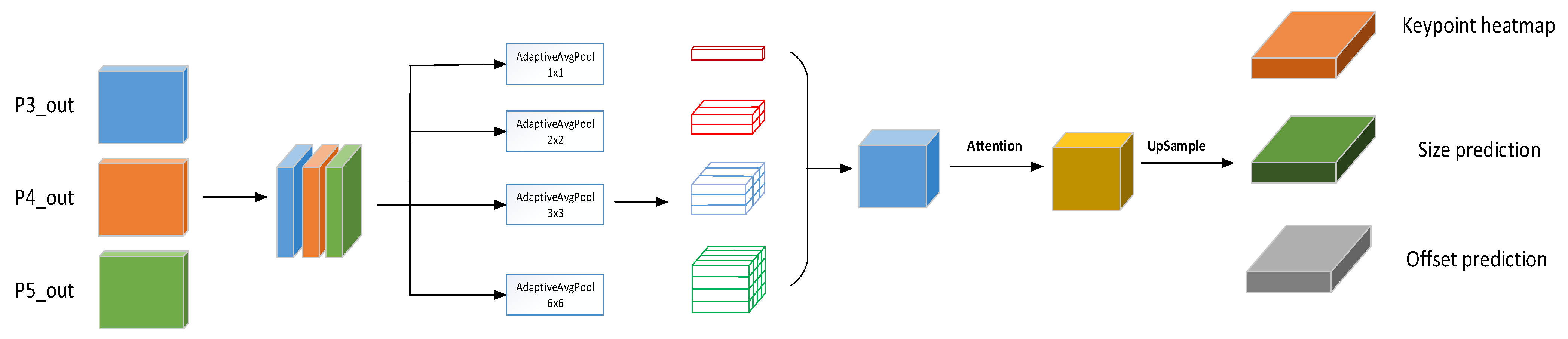
- Anchor-free detection head
- B.
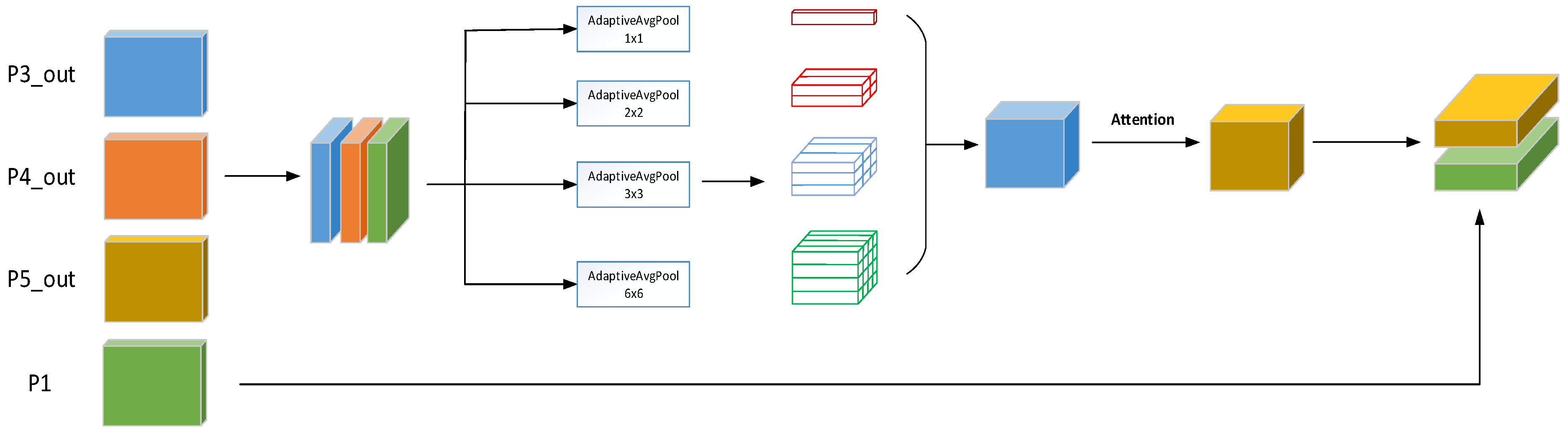
- Segmentation heads incorporating fine-grained features
2.2. Loss of Function for Joint Multi-Task Training
3. Results
3.1. Setting
3.1.1. Dataset Setting
3.1.2. Implementation Details
3.1.3. Evaluation Indicators
3.2. Experimental Analysis of Multi-Tasking Networks
3.2.1. Road Target Detection Tasks
3.2.2. Driveable Area and Lane Detection Tasks
- A.
- Travelable area segmentation tasks
- B.
- Lane area splitting task
- C.
- Split task ablation experiment
3.2.3. Training Method Comparison Experiment
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y. SSD: Single Shot MultiBox Detector. InComputer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. Enet: A deep neural network architec-ture for real-time semantic segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Ouyang, Y. Strong-Structural Convolution Neural Network for Semantic Segmentation. Pattern Recognit. Image Anal. 2019, 29, 716–729. [Google Scholar] [CrossRef]
- Wang, Z.; Ren, W.; Qiu, Q. LaneNet: Real-Time Lane Detection Networks for AutonomousDriving. arXiv 2018, arXiv:1807.01726. [Google Scholar]
- Pan, X.; Shi, J.; Luo, P.; Wang, X.; Tang, X. Spatial As Deep: Spatial CNN for Traffic SceneUndrstanding. arXiv 2017, arXiv:1712.06080. [Google Scholar]
- Hou, Y.; Ma, Z.; Liu, C.; Loy, C.C. Learning Lightweight Lane Detection CNNs by Self Attention Distillation. In Proceedings of the IEEE/CVFInternationalConference onComputer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1013–1021. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. PatternAnal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef] [PubMed]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with regionproposalnetworks. arXiv 2015, arXiv:1506.01497. [Google Scholar]
- Liu, B.; Chen, H.; Wang, Z. LSNet: Extremely Light-Weight Siamese Network For ChangeDetection in Remote Sensing Image. arXiv 2022, arXiv:2201.09156. [Google Scholar]
- Teichmann, M.; Weber, M.; Zöllner, M.; Cipolla, R.; Urtasun, R. MultiNet: Real-time JointSemantic Reasoning for Autonomous Driving. In Proceedings of the IEEE IntelligentVehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1013–1020. [Google Scholar] [CrossRef] [Green Version]
- Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F.; Madhavan, V.; Darrell, T. BDD100K: A Diverse Driving Dataset for Heterogeneous Multitask Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2633–2642. [Google Scholar] [CrossRef]
- Wu, D.; Liao, M.; Zhang, W.; Wang, X. YOLOP: You Only Look Once for Panoptic DrivingPerception. arXiv 2022, arXiv:2108.11250. [Google Scholar] [CrossRef]
- Vu, D.; Ngo, B.; Phan, H. HybridNets: End-to-End Perception Network. arXiv 2022, arXiv:2203.09035. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.Y.M. Scaled-yolov4: Scaling cross stage partialnetwork. arXiv 2020, arXiv:2011.08036. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR);IEEE: 2016. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks forvisual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Belongie, S. Feature pyramidnetworks for object detection. In Proceedings of the IEEEConference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:190407850. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.-E.; Sheikh, Y. Realtime multi-person 2d poseestimation using part affinity fields. In Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for denseobject detection. In Proceedings of the IEEE international Conference onComputer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Salehi, S.S.M.; Erdogmus, D.; Gholipour, A. Tversky Loss Function for Image SegmentationUsing 3D Fully Convolutional Deep Networks. In Machine Learning in Medical Imaging, MLMI 2017; Lecture Notes in Computer, Science; Wang, Q., Shi, Y., Suk, H.I., Suzuki, K., Eds.; Springer: Cham, Switzerland, 2017; Volume 10541. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense ObjectDetection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2019, arXiv:1711.05101. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Recall (%) | mAP50 (%) |
|---|---|---|
| MultiNet | 81.3 | 60.2 |
| Faster R-CNN | 77.2 | 55.6 |
| YOLOP | 89.2 | 76.5 |
| HybridNets | 92.8 | 77.3 |
| CenterPNets | 81.6 | 75.8 |
| Model | Image_infer(FPS) | Video_infer(S) | Param(M) |
|---|---|---|---|
| HybridNets | 5.719 | 90.632 | 12.83 |
| CenterPNets | 8.709 | 68.279 | 28.56 |
| Model | DriveablemIoU (%) |
|---|---|
| MultiNet | 71.6 |
| PSPNet | 89.6 |
| YOLOP | 91.5 |
| HybridNets | 90.5 |
| CenterPNets | 92.8 |
| Model | Accuracy (%) | Lane Line IoU (%) |
|---|---|---|
| ENet | 34.12 | 14.64 |
| SCNN | 35.79 | 15.84 |
| YOLOP | 70.50 | 26.20 |
| HybridNets | 85.40 | 31.60 |
| CenterPNets | 86.20 | 32.10 |
| Experimental Serial Number | MFI | SPP | Attention | SCI | Driveable | Lane Line | ||
|---|---|---|---|---|---|---|---|---|
| IoU (%) | Acc (%) | IoU (%) | Acc (%) | |||||
| 1 | --- | --- | --- | --- | 78.7 | 93.2 | 28.3 | 81.2 |
| 2 | √ | --- | --- | --- | 82.5 | 95.1 | 31.1 | 83.5 |
| 3 | √ | √ | --- | --- | 82.2 | 94.6 | 31.3 | 84.8 |
| 4 | √ | √ | √ | --- | 82.9 | 94.8 | 31.5 | 85.5 |
| 5 | √ | √ | √ | √ | 82.6 | 94.2 | 32.1 | 85.3 |
| Training Method | Detection | Driveable | Lane Line | |||
|---|---|---|---|---|---|---|
| Recall (%) | AP (%) | IoU (%) | Acc (%) | IoU (%) | Acc (%) | |
| Only(det) | 80.4 | 74.2 | -- | -- | -- | -- |
| Only(seg) | -- | -- | 82.6 | 94.2 | 32.1 | 85.3 |
| Multi-task | 81.6 | 75.8 | 82.5 | 93.2 | 32.1 | 86.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, G.; Wu, T.; Duan, J.; Hu, Q.; Huang, D.; Li, H. CenterPNets: A Multi-Task Shared Network for Traffic Perception. Sensors 2023, 23, 2467. https://doi.org/10.3390/s23052467
Chen G, Wu T, Duan J, Hu Q, Huang D, Li H. CenterPNets: A Multi-Task Shared Network for Traffic Perception. Sensors. 2023; 23(5):2467. https://doi.org/10.3390/s23052467
Chicago/Turabian StyleChen, Guangqiu, Tao Wu, Jin Duan, Qi Hu, Dandan Huang, and Hao Li. 2023. "CenterPNets: A Multi-Task Shared Network for Traffic Perception" Sensors 23, no. 5: 2467. https://doi.org/10.3390/s23052467
APA StyleChen, G., Wu, T., Duan, J., Hu, Q., Huang, D., & Li, H. (2023). CenterPNets: A Multi-Task Shared Network for Traffic Perception. Sensors, 23(5), 2467. https://doi.org/10.3390/s23052467