1. Introduction
In recent years, the rapid development of embedded systems and neural networks has made autonomous driving a popular field in computer vision, where panoramic traffic perception systems play a crucial role in autonomous driving. Research has shown that vehicle onboard camera image processing enables scene understanding, including road target detection, driveable area detection, and lane detection, which greatly reduces overhead compared to the traditional approach of using LIDAR and millimeter wave radar to establish the vehicle’s surroundings.
The traffic panorama perception system’s detection precision and decision-making speed significantly influence the vehicle’s judgment and decision-making and determine the safety of autonomous vehicles. However, actual vehicle driver assistance systems, such asthe Advanced Driver Assistance System, have limited computing power and are expensive. Therefore, achieving a good balance between detection accuracy and model complexity from a practical application perspective is a challenge for decision-makers.
Current target detection can be broadly divided into one-stage detection models and two-stage detection models. The two-stage detection approach usually starts by acquiring a candidate region and then performing a regression prediction from that candidate region to ensure the accuracy of the detection. However, this step-by-step detection approach is not friendly to embedded systems. The end-to-end, one-stage detection model has the advantage of fast inference speed and is gaining more attention in the field of detection.The use of direct regression bounding boxes in the SSD [
1] series, YOLO [
2] series, etc. is a milestone in the first stage of detection. FCN [
3] was the first to introduce fully convolutional networks to the task of semantic segmentation, although their performance was limited by resolution. PSPNet [
4] proposes pyramid pooling to extract multi-scale features to improve detection performance. Enet [
5] reduces the size of the feature map. SSN [
6] incorporates conditional random field units in the post-processing stage to improve segmentation performance. LaneNet [
7] proposes to use a single lane line as the object of instance segmentation. Layer-by-layer convolution is a technique used by spatial CNN [
8] that enables the transfer of feature information between ranks in a layer. Enet SAD [
9], on the other hand, uses a self-focused distillation method so that the feature maps can learn from each other.
Although the above algorithms are effective for their respective single-task detections, they can cause unnecessary network delays if they are used to achieve multi-task detection by acquiring the corresponding features through different task networks one by one. Multi-tasking networks, however, are better achieved by sharing information between multiple tasks. Mask R-CNN [
10] extends Faster R-CNN [
11] by mask branching to parallelize the detection task with the segmentation task. A similar approach is used by LSNet [
12] for tasks such astarget detection, instance segmentation, etc. An encoder–decoder structure is suggested by MultiNet [
13] to carry out the scene perception job concurrently.On the BDD100K dataset [
14], YOLOP [
15] is the first multi-tasking problem that implements panoramic driving perception, i.e., traffic target detection, driveable area segmentation, and lane detection, with high accuracy and speed at the same time with the help of embedded devices. YOLOP uses an efficient network structure and passes the feature information extracted from the images to the different decoders for their respective detection tasks. However, the use of separate segmentation heads for the driveable area and lane line segmentation tasks leaves room for multi-network optimization, i.e., these tasks can be fused into an overall segmentation task. HybridNets [
16] uses a lighter backbone network than YOLOP, and to achieve a higher level of feature fusion, the neck network uses a weighted bi-directional feature network that treats each top-down and bottom-up bi-directional path as a feature network layer. However, the anchor mechanism is used in the detection task to return vehicle position information, which requires pre-clustering of anchor boxes in order to better fit the target size and has cumbersome subsequent processing during the prediction process. In this paper, we propose a more efficient multi-tasking network after a thorough study of previous approaches and incorporating the idea of an anchor-free architecture.
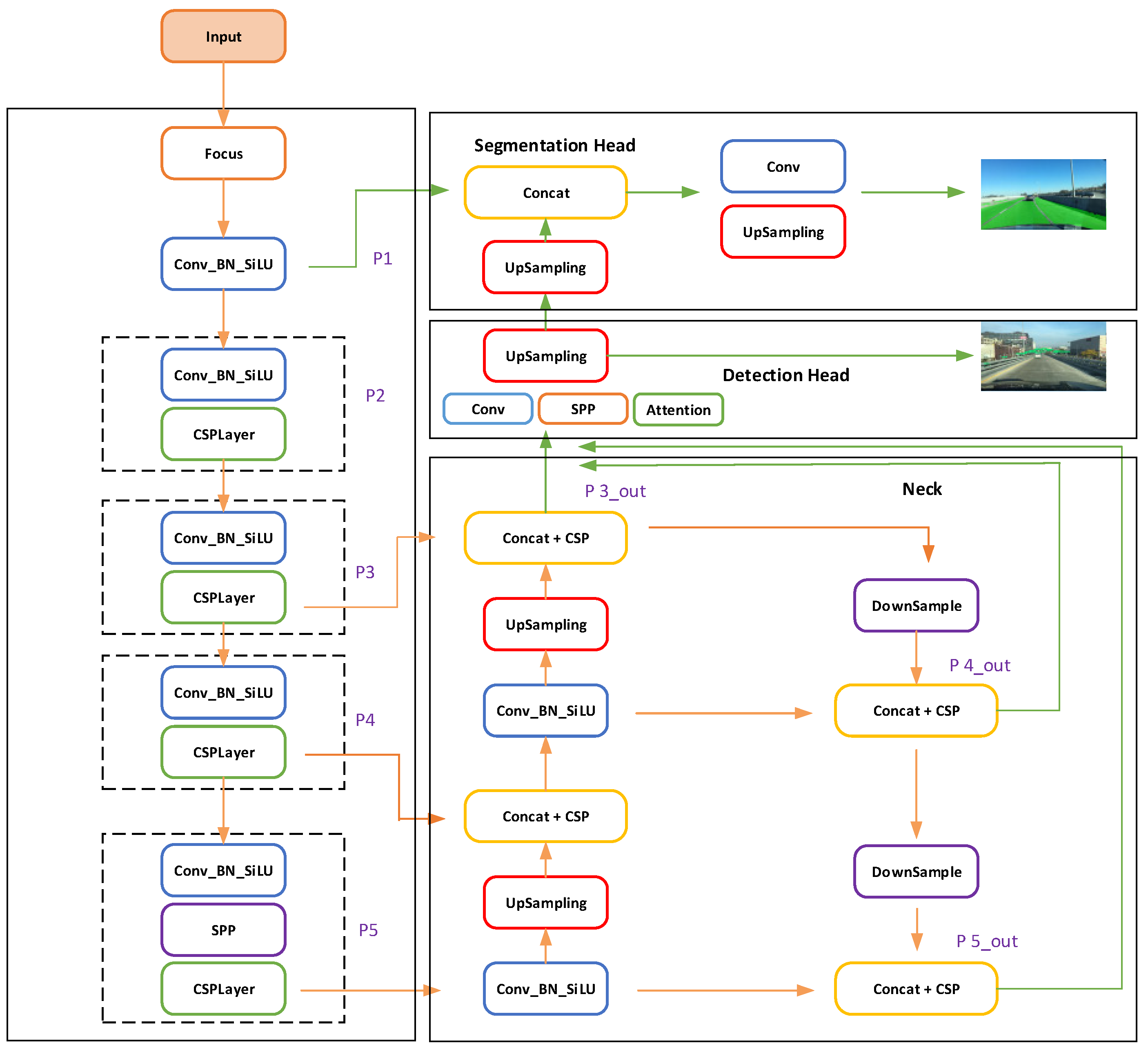
The CenterPNets backbone feature extraction network uses the CSPDarknet [
17] module pre-trained on ImageNet and fuses the path aggregation neck network to achieve a good balance between detection accuracy and computational overhead. The PANet [
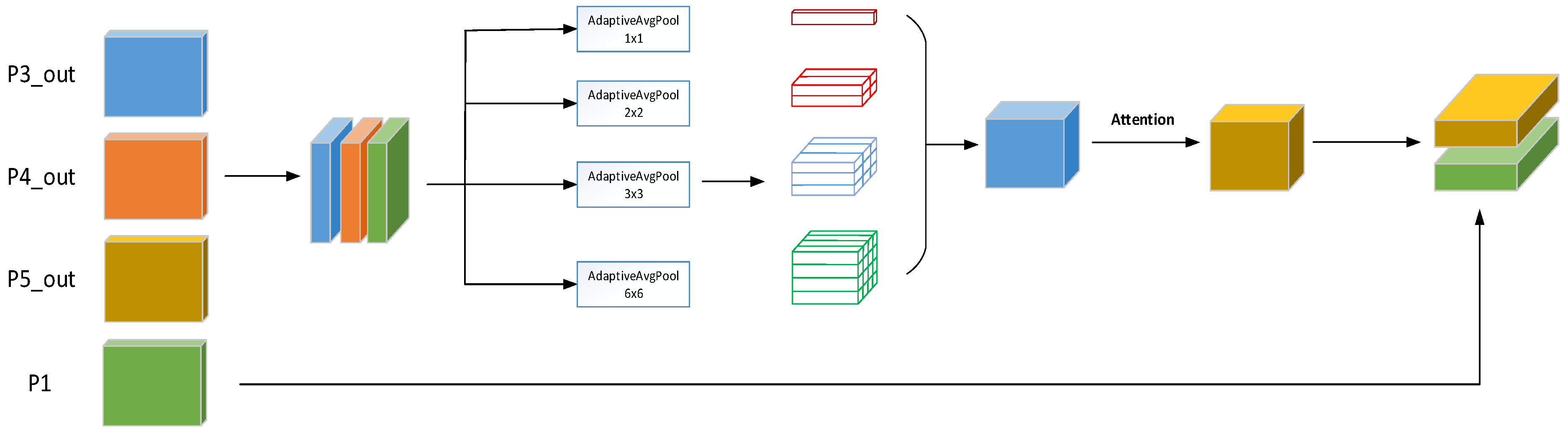
18] decoder uses multi-scale feature data for tasks such as segmentation and detection. For model optimization, CenterPNets employs a multi-task joint loss function. CenterPNets abandons the anchor mechanism with high recall in the detection head in favor of an anchor-free mechanism that returns the target center position information without the need for time-consuming anchor frame clustering and subsequent processing, such as NMS, thereby increasing the network’s overall inference speed. In the segmentation task, shallow features are rich in fine-grained information, which is essential for image segmentation. For this reason, we fuse multi-scale features with shallow features to retain the detailed information of the image and make the segmented edges smoother.
In this paper, in addition to using an end-to-end training strategy, we have also tried a frozen training approach. Using the freeze training strategy, this approach has been shown to be effective at preventing information interference from other non-relevant modules in the network and the completed training tasks are instructive for other tasks.
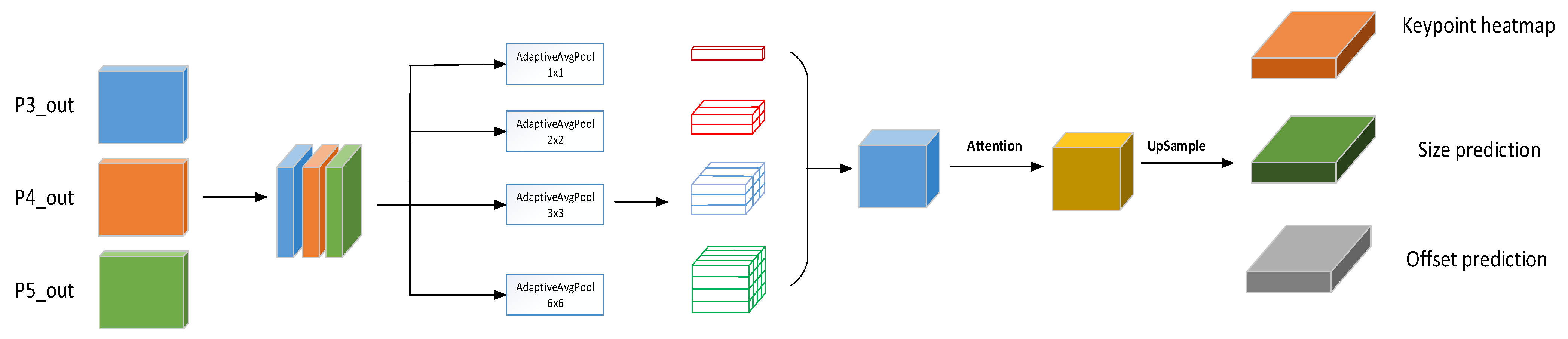
To sum up, the main contributions of this research are: (1) This paper proposes an effective end-to-end shared multi-task network structure that can jointly handle three important traffic sensing tasks: lane detection, driveable area segmentation, and road target detection. The network’s encoders and decoders are shared to fully exploit the correlation between each task’s semantic features, which can help the network reduce model redundancy. (2) The detection head adopts an anchor-free mechanism to directly return the target key point information, size, and offset, without the need for pre-clustering anchor box ratio and tedious subsequent processing, thus enhancing the overall inference speed of the network. (3) In the segmentation head section, similar features from the shared detection task are used and proposed to fuse multi-scale, deep semantic information with shallow features so that the feature information extracted from the segmentation task is rich in fine-grained information, thus enhancing the detail segmentation capability of the model.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}