


A Sparse Representation Classification Scheme for the Recognition of Affective and Cognitive Brain Processes in Neuromarketing
 , , ,
, , ,  and
and 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- We explore the sparsity of brain signals in neuromarketing scenarios and we propose a novel SRC-based classification algorithm with applications to neuromarketing.
- We propose the use of a Sparse Bayesian Learning framework to find the weights of the linear combination, resulting in an iterative algorithm. More specifically, the current brain signals (i.e., a test signal) are represented as a sparse linear combination of brain signals existing in the training set (i.e., a dictionary of brain atoms).
- We propose the use of a graph-based sparseness generator prior, hence our algorithm is able to better use any prior knowledge and can improve classification performance in comparison with the state-of-the-art SRC algorithms. This prior knowledge contains structural information about the graph that describes our data.
- The proposed SRC classifier has been used as the basic part of a new EEG-based affective signal processing framework to discriminate affective processes during a neuromarketing experiment. Furthermore, the classifier is also used to discriminate between the cognitive processes that are evoked due to product viewing.
2. Methodology
2.1. Experimental Procedure and Dataset
2.2. EEG Features
2.3. Sparse Representation Classification Scheme
| Algorithm 1 Basic sparse representation classification scheme |
| Require:
Training samples, , with its corresponding labels, ℓ and one test sample, 1. Solve the minimization problem: 2. Calculate the residuals: , Ensure: |
| Algorithm 2 Proposed sparse representation classification scheme |
| Require: Training samples, , with its corresponding labels, ℓ, one test sample, , trade off parameter , and number of the nearest neighborhoods, k. 1. Construct graph Laplacian matrix, L. 2. Iterate over Equations (8), (9), (12) and (13) to find 3. Calculate the residuals: , Ensure: |
3. Results
- The kNN classifier [13];
- The typical Deep Learning Neural Network (DLNN) classifier [41]. The used DLNN consisted of three fully connected layers, where each one of the first two are followed by a batch normalization layer and a rectified layer. The third fully connected layer is followed by a softmax layer for classification purposes. For the DLNN optimization procedure, we have used the Adam optimizer and the learning rate has been set to 0.1. As an input to the network, we use the extracted features, while the first and second fully connected layers have 20 and 10 hidden units. Furthermore, the hidden units of the third layer are equal to number of corresponding classes.
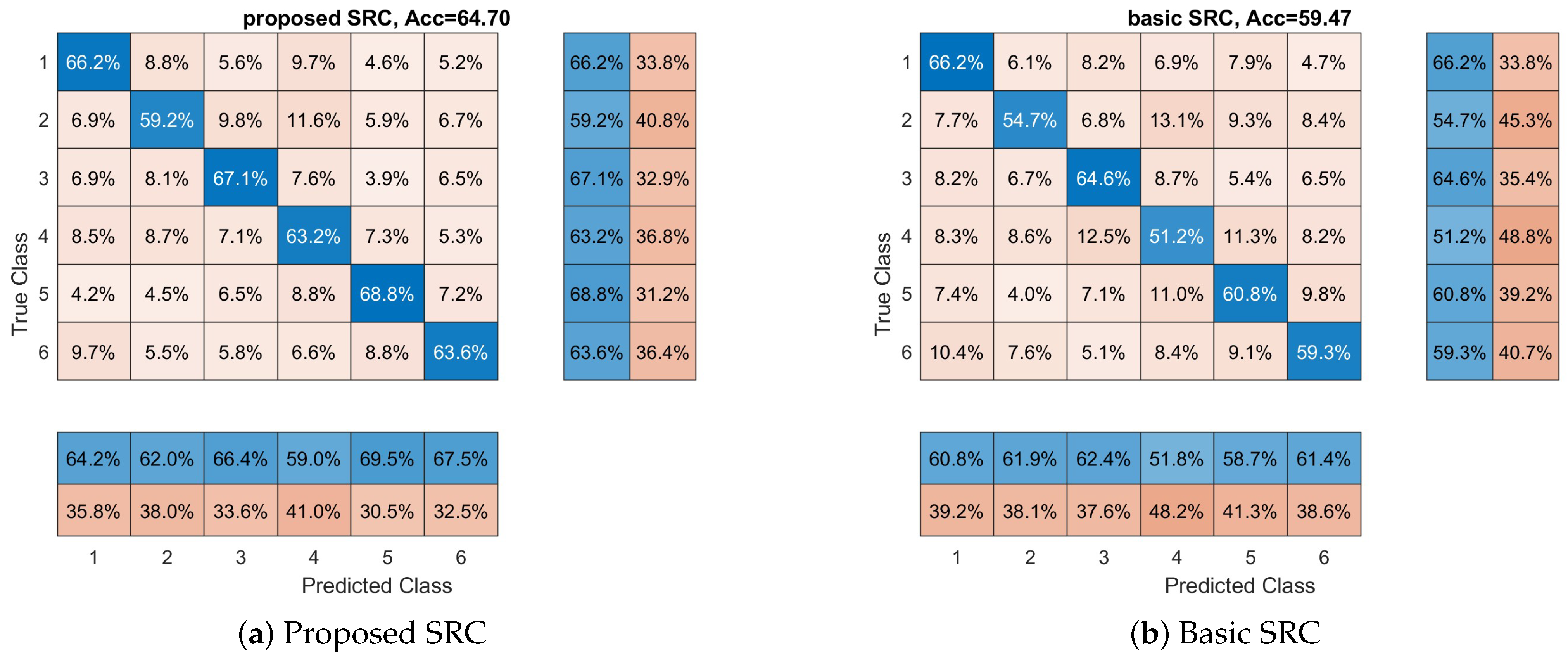
3.1. Affective States Recognition
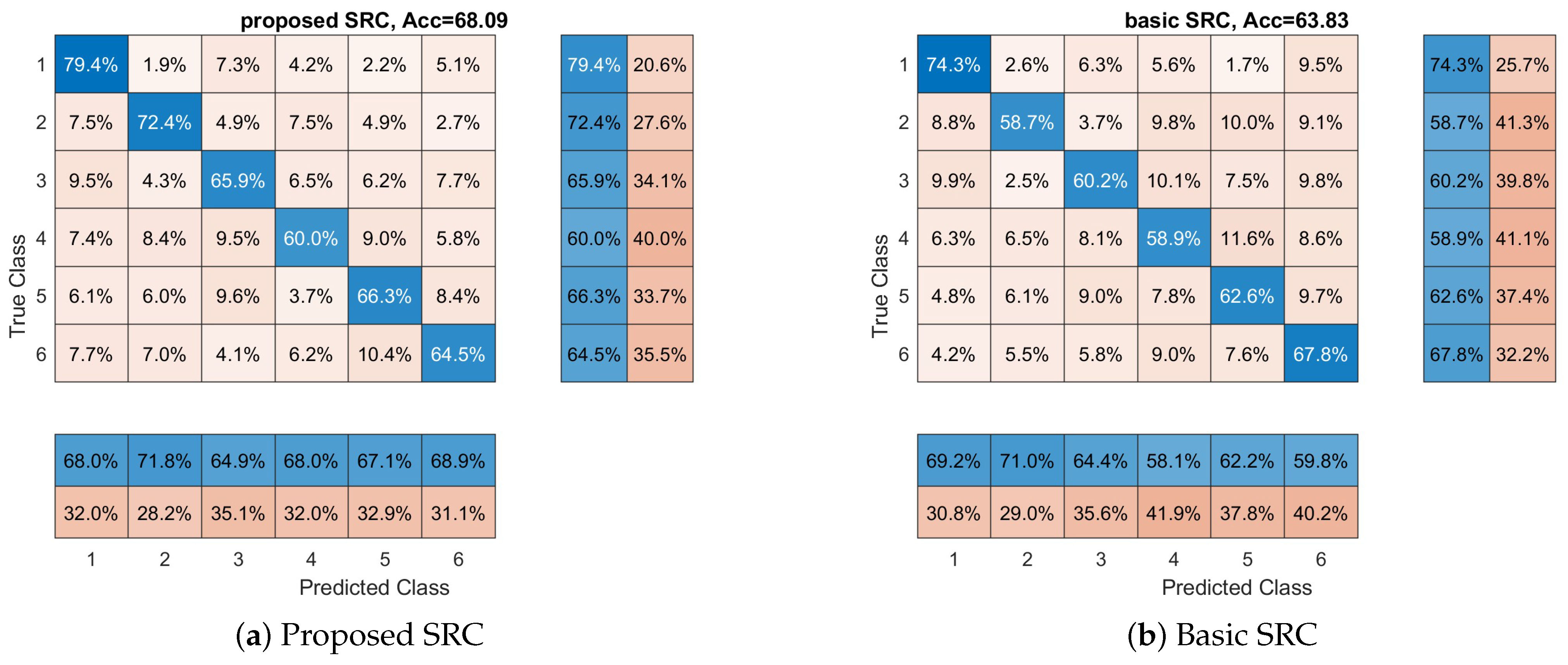
3.2. Cognitive States Recognition
3.3. Sensitivity to the Number of Training Samples
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lécuyer, A.; Lotte, F.; Reilly, R.; Leeb, R.; Hirose, M.; Slater, M. Brain-Computer Interfaces, Virtual Reality, and Videogames. Computer 2008, 41, 66–72. [Google Scholar] [CrossRef] [Green Version]
- Alimardani, M.; Hiraki, K. Passive Brain-Computer Interfaces for Enhanced Human-Robot Interaction. Front. Robot. AI 2020, 7, 125. [Google Scholar] [CrossRef] [PubMed]
- Gao, X.; Wang, Y.; Chen, X.; Gao, S. Interface, interaction, and intelligence in generalized brain–computer interfaces. Trends Cogn. Sci. 2021, 25, 671–684. [Google Scholar] [CrossRef]
- Ramadan, R.A.; Vasilakos, A.V. Brain computer interface: Control signals review. Neurocomputing 2017, 223, 26–44. [Google Scholar] [CrossRef]
- Zander, T.O.; Kothe, C. Towards passive brain–computer interfaces: Applying brain–computer interface technology to human–machine systems in general. J. Neural Eng. 2011, 8, 025005. [Google Scholar] [CrossRef] [PubMed]
- Kalaganis, F.P.; Georgiadis, K.; Oikonomou, V.P.; Laskaris, N.A.; Nikolopoulos, S.; Kompatsiaris, I. Unlocking the Subconscious Consumer Bias: A Survey on the Past, Present, and Future of Hybrid EEG Schemes in Neuromarketing. Front. Neuroergonomics 2021, 2, 11. [Google Scholar] [CrossRef]
- Yadava, M.; Kumar, P.; Saini, R.; Roy, P.P.; Dogra, D.P. Analysis of EEG signals and its application to neuromarketing. Multimed. Tools Appl. 2017, 76, 19087–19111. [Google Scholar] [CrossRef]
- Lin, M.H.; Cross, S.; Jones, W.; Childers, T. Applying EEG in consumer neuroscience. Eur. J. Mark. 2018, 52, 66–91. [Google Scholar] [CrossRef]
- Jiang, J.; Fares, A.; Zhong, S.H. A Context-Supported Deep Learning Framework for Multimodal Brain Imaging Classification. IEEE Trans. -Hum.-Mach. Syst. 2019, 49, 611–622. [Google Scholar] [CrossRef]
- Hakim, A.; Levy, D. A gateway to consumers’ minds: Achievements, caveats, and prospects of electroencephalography-based prediction in neuromarketing. WIREs Cogn. Sci. 2019, 10, e1485. [Google Scholar] [CrossRef]
- Braeutigam, S.; Rose, S.; Swithenby, S.; Ambler, T. The distributed neuronal systems supporting choice-making in real-life situations: Differences between men and women when choosing groceries detected using magnetoencephalography. Eur. J. Neurosci. 2004, 20, 293–302. [Google Scholar] [CrossRef] [PubMed]
- Khushaba, R.N.; Wise, C.; Kodagoda, S.; Louviere, J.; Kahn, B.E.; Townsend, C. Consumer neuroscience: Assessing the brain response to marketing stimuli using electroencephalogram (EEG) and eye tracking. Expert Syst. Appl. 2013, 40, 3803–3812. [Google Scholar] [CrossRef]
- Hakim, A.; Klorfeld, S.; Sela, T.; Friedman, D.; Shabat-Simon, M.; Levy, D.J. Machines learn neuromarketing: Improving preference prediction from self-reports using multiple EEG measures and machine learning. Int. J. Res. Mark. 2021, 38, 770–791. [Google Scholar] [CrossRef]
- Shah, S.M.A.; Usman, S.M.; Khalid, S.; Rehman, I.U.; Anwar, A.; Hussain, S.; Ullah, S.S.; Elmannai, H.; Algarni, A.D.; Manzoor, W. An Ensemble Model for Consumer Emotion Prediction Using EEG Signals for Neuromarketing Applications. Sensors 2022, 22, 9744. [Google Scholar] [CrossRef]
- Wei, Z.; Wu, C.; Wang, X.; Supratak, A.; Wang, P.; Guo, Y. Using Support Vector Machine on EEG for Advertisement Impact Assessment. Front. Neurosci. 2018, 12, 76. [Google Scholar] [CrossRef] [Green Version]
- Palmiero, M.; Piccardi, L. Frontal EEG asymmetry of mood: A mini-review. Front. Behav. Neurosci. 2017, 11, 8. [Google Scholar] [CrossRef] [Green Version]
- Ravaja, N.; Somervuori, O.; Salminen, M. Predicting Purchase Decision: The Role of Hemispheric Asymmetry over the Frontal Cortex. J. Neurosci. Psychol. Econ. 2013, 6, 1. [Google Scholar] [CrossRef]
- Ohme, R.; Reykowska, D.; Wiener, D.; Choromanska, A. Application of frontal EEG asymmetry to advertising research. J. Econ. Psychol. 2010, 31, 785–793. [Google Scholar] [CrossRef]
- Shestyuk, A.Y.; Kasinathan, K.; Karapoondinott, V.; Knight, R.; Gurumoorthy, R. Individual EEG measures of attention, memory, and motivation predict population level TV viewership and Twitter engagement. PLoS ONE 2019, 14, e0214507. [Google Scholar] [CrossRef]
- Vecchiato, G.; Toppi, J.; Astolfi, L.; Fallani, F.D.V.; Cincotti, F.; Mattia, D.; Bez, F.; Babiloni, F. Spectral EEG frontal asymmetries correlate with the experienced pleasantness of TV commercial advertisements. Med. Biol. Eng. Comput. 2011, 49, 579–583. [Google Scholar] [CrossRef]
- Barnett, S.; Cerf, M. A Ticket for Your Thoughts: Method for Predicting Content Recall and Sales Using Neural Similarity of Moviegoers. J. Consum. Res. 2017, 44, 160–181. [Google Scholar] [CrossRef]
- Wang, R.W.; Chang, Y.C.; Chuang, S.W. EEG Spectral Dynamics of Video Commercials: Impact of the Narrative on the Branding Product Preference. Sci. Rep. 2016, 6, 36487. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vecchiato, G.; Astolfi, L.; Vico, F.D.; Cincotti, F.; Mattia, D.; Salinari, S.; Soranzo, R.; Babiloni, F. Changes in Brain Activity During the Observation of TV Commercials by Using EEG, GSR and HR Measurements. Brain Topogr. 2010, 23, 165–179. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.; Xu, X.; Zhang, T. Emotion classification using deep neural networks and emotional patches. In Proceedings of the 2017 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Kansas City, MO, USA, 13–16 November 2017; pp. 958–962. [Google Scholar] [CrossRef]
- Xu, H.; Plataniotis, K.N. Affective states classification using EEG and semi-supervised deep learning approaches. In Proceedings of the 2016 IEEE 18th International Workshop on Multimedia Signal Processing (MMSP), Montreal, QC, Canada, 21–23 September 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Ieracitano, C.; Morabito, F.C.; Hussain, A.; Mammone, N. A Hybrid-Domain Deep Learning-Based BCI for Discriminating Hand Motion Planning from EEG Sources. Int. J. Neural Syst. 2021, 31, 2150038. [Google Scholar] [CrossRef] [PubMed]
- Gong, S.; Xing, K.; Cichocki, A.A.; Li, J. Deep Learning in EEG: Advance of the Last Ten-Year Critical Period. IEEE Trans. Cogn. Dev. Syst. 2022, 14, 348–365. [Google Scholar] [CrossRef]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Representation Learning on Graphs: Methods and Applications. arXiv 2017, arXiv:1709.05584. [Google Scholar]
- Wright, J.; Yang, A.Y.; Ganesh, A.; Sastry, S.S.; Ma, Y. Robust Face Recognition via Sparse Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 210–227. [Google Scholar] [CrossRef] [Green Version]
- Shen, C.; Chen, L.; Dong, Y.; Priebe, C. Sparse Representation Classification Beyond l1 Minimization and the Subspace Assumption. IEEE Trans. Inf. Theory 2020, 66, 5061–5071. [Google Scholar] [CrossRef]
- Oikonomou, V.P.; Nikolopoulos, S.; Kompatsiaris, I. Robust Motor Imagery Classification Using Sparse Representations and Grouping Structures. IEEE Access 2020, 8, 98572–98583. [Google Scholar] [CrossRef]
- Shu, T.; Zhang, B.; Tang, Y. Sparse Supervised Representation-Based Classifier for Uncontrolled and Imbalanced Classification. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 2847–2856. [Google Scholar] [CrossRef]
- Shin, Y.; Lee, S.; Lee, J.; Lee, H.N. Sparse representation-based classification scheme for motor imagery-based brain–computer interface systems. J. Neural Eng. 2012, 9, 056002. [Google Scholar] [CrossRef] [PubMed]
- Oikonomou, V.P.; Nikolopoulos, S.; Kompatsiaris, I. Sparse Graph-based Representations of SSVEP Responses Under the Variational Bayesian Framework. In Proceedings of the 2021 IEEE 21st International Conference on Bioinformatics and Bioengineering (BIBE), Kragujevac, Serbia, 25–27 October 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Badre, D.; Nee, D.E. Frontal Cortex and the Hierarchical Control of Behavior. Trends Cogn. Sci. 2018, 22, 170–188. [Google Scholar] [CrossRef]
- Davenport, M.A.; Duarte, M.F.; Eldar, Y.C.; Kutyniok, G. Introduction to compressed sensing. In Compressed Sensing: Theory and Applications; Eldar, Y.C., Kutyniok, G., Eds.; Cambridge University Press: Cambridge, UK, 2012; pp. 1–64. [Google Scholar] [CrossRef]
- Oikonomou, V.P.; Nikolopoulos, S.; Kompatsiaris, I. A Novel Compressive Sensing Scheme under the Variational Bayesian Framework. In Proceedings of the 27th European Signal Processing Conference (EUSIPCO 2019), Corunna, Spain, 2–6 September 2019; pp. 1–4. [Google Scholar]
- Tipping, M.E. Sparse Bayesian Learning and the Relevance Vector Machine. J. Mach. Learn. Res. 2001, 1, 211–244. [Google Scholar]
- Jiang, B.; Chen, H.; Yuan, B.; Yao, X. Scalable Graph-Based Semi-Supervised Learning through Sparse Bayesian Model. IEEE Trans. Knowl. Data Eng. 2017, 29, 2758–2771. [Google Scholar] [CrossRef]
- Alpaydin, E. Introduction to Machine Learning, 3rd ed.; The MIT Press: Cambridge, UK, 2014. [Google Scholar]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, UK, 2022. [Google Scholar]
- Georgiadis, K.; Kalaganis, F.P.; Oikonomou, V.P.; Nikolopoulos, S.; Laskaris, N.A.; Kompatsiaris, I. RNeuMark: A Riemannian EEG Analysis Framework for Neuromarketing. Brain Inform. 2022, 9, 22. [Google Scholar] [CrossRef] [PubMed]
- Rubinstein, R.; Bruckstein, A.M.; Elad, M. Dictionaries for Sparse Representation Modeling. Proc. IEEE 2010, 98, 1045–1057. [Google Scholar] [CrossRef]
- Fornito, A.; Bullmore, E.T. Connectomics: A new paradigm for understanding brain disease. Eur. Neuropsychopharmacol. 2015, 25, 733–748. [Google Scholar] [CrossRef]
- Lazarou, I.; Georgiadis, K.; Nikolopoulos, S.; Oikonomou, V.P.; Tsolaki, A.; Kompatsiaris, I.; Tsolaki, M.; Kugiumtzis, D. A Novel Connectome-based Electrophysiological Study of Subjective Cognitive Decline Related to Alzheimer’s Disease by Using Resting-state High-density EEG EGI GES 300. Brain Sci. 2020, 10, 392. [Google Scholar] [CrossRef] [PubMed]
- Hamedi, M.; Salleh, S.H.; Noor, A.M. Electroencephalographic Motor Imagery Brain Connectivity Analysis for BCI: A Review. Neural Comput. 2016, 28, 999–1041. [Google Scholar] [CrossRef]
- Fuster, J.M. The Prefrontal Cortex Makes the Brain a Preadaptive System. Proc. IEEE 2014, 102, 417–426. [Google Scholar] [CrossRef]
- Romanski, L.M.; Chafee, M.V. A View from the Top: Prefrontal Control of Object Recognition. Neuron 2021, 109, 6–8. [Google Scholar] [CrossRef] [PubMed]
- Kidmose, P.; Looney, D.; Ungstrup, M.; Rank, M.L.; Mandic, D.P. A Study of Evoked Potentials From Ear-EEG. IEEE Trans. Biomed. Eng. 2013, 60, 2824–2830. [Google Scholar] [CrossRef] [PubMed]
- Oikonomou, V.P. An Adaptive Task-Related Component Analysis Method for SSVEP Recognition. Sensors 2022, 22, 7715. [Google Scholar] [CrossRef] [PubMed]
- Spampinato, C.; Palazzo, S.; Kavasidis, I.; Giordano, D.; Souly, N.; Shah, M. Deep Learning Human Mind for Automated Visual Classification. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4503–4511. [Google Scholar] [CrossRef] [Green Version]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oikonomou, V.P.; Georgiadis, K.; Kalaganis, F.; Nikolopoulos, S.; Kompatsiaris, I. A Sparse Representation Classification Scheme for the Recognition of Affective and Cognitive Brain Processes in Neuromarketing. Sensors 2023, 23, 2480. https://doi.org/10.3390/s23052480
Oikonomou VP, Georgiadis K, Kalaganis F, Nikolopoulos S, Kompatsiaris I. A Sparse Representation Classification Scheme for the Recognition of Affective and Cognitive Brain Processes in Neuromarketing. Sensors. 2023; 23(5):2480. https://doi.org/10.3390/s23052480
Chicago/Turabian StyleOikonomou, Vangelis P., Kostas Georgiadis, Fotis Kalaganis, Spiros Nikolopoulos, and Ioannis Kompatsiaris. 2023. "A Sparse Representation Classification Scheme for the Recognition of Affective and Cognitive Brain Processes in Neuromarketing" Sensors 23, no. 5: 2480. https://doi.org/10.3390/s23052480
APA StyleOikonomou, V. P., Georgiadis, K., Kalaganis, F., Nikolopoulos, S., & Kompatsiaris, I. (2023). A Sparse Representation Classification Scheme for the Recognition of Affective and Cognitive Brain Processes in Neuromarketing. Sensors, 23(5), 2480. https://doi.org/10.3390/s23052480