
Landslide Susceptibility Evaluation of Machine Learning Based on Information Volume and Frequency Ratio: A Case Study of Weixin County, China

Abstract
1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Data Sources
2.2.1. Landslide Cataloging Data
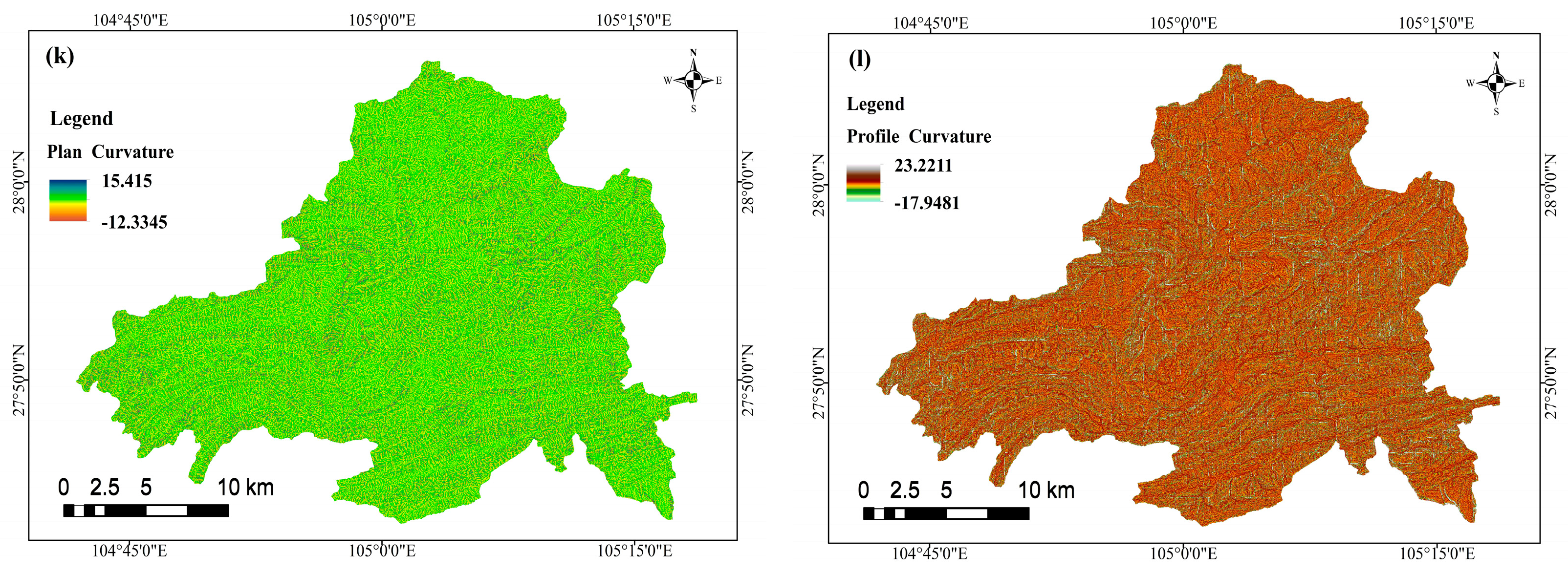
2.2.2. Data Description of Environmental Factors
3. Research Methodology
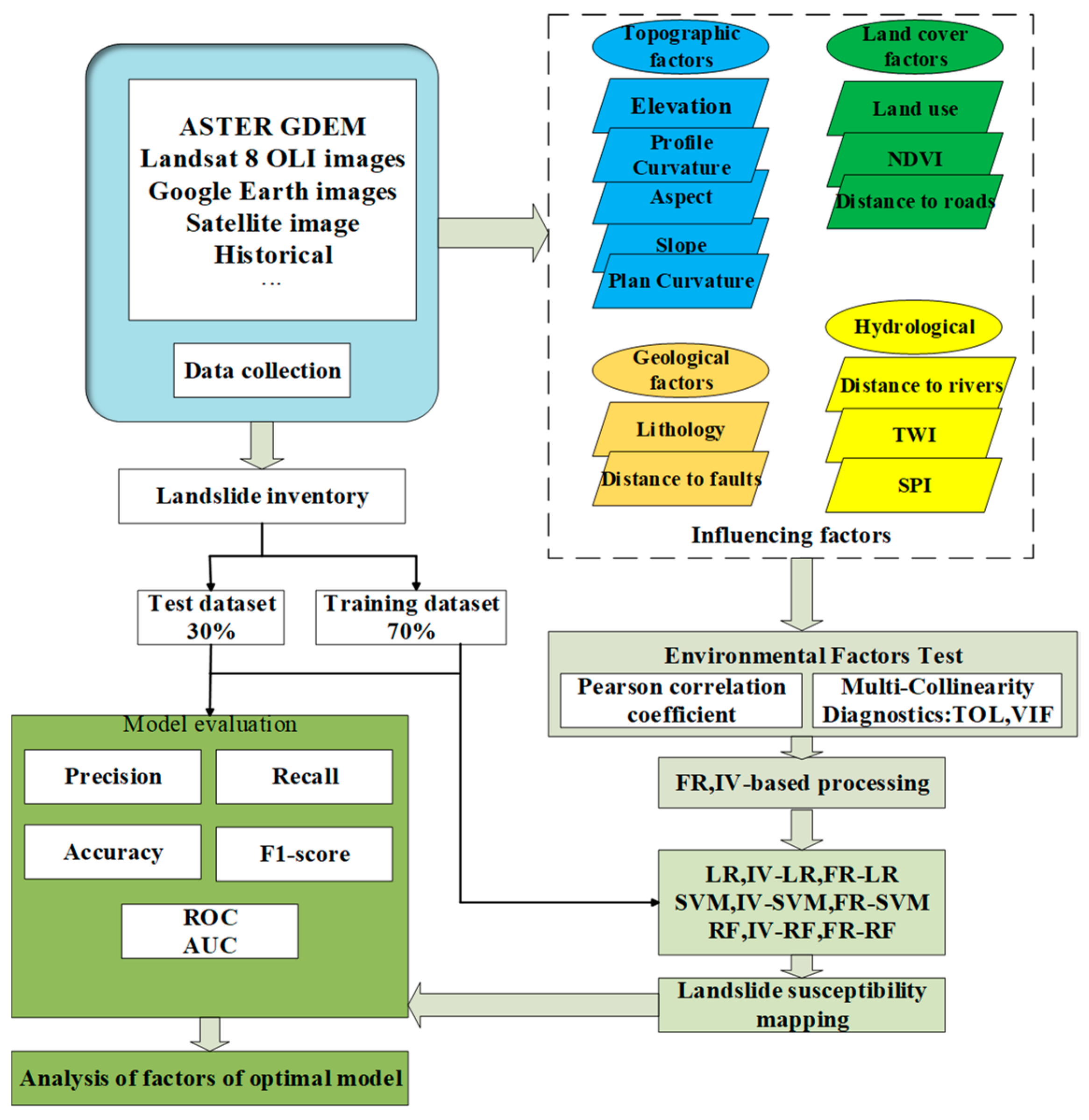
3.1. Research Technology Routes
3.2. Screening of Environmental Factors
3.2.1. Correlation Analysis of Factors
3.2.2. Multicollinearity Tests
3.3. Processing of Factors
3.3.1. Frequency Ratio (FR)
3.3.2. Information Volume (IV)
3.4. Machine Learning Models
3.4.1. Logistic Regression
3.4.2. Support Vector Machines
3.4.3. Random Forests
3.5. Performance Validation of the Model
3.5.1. Confusion Matrix
3.5.2. ROC Curves and AUC Values
4. Results
4.1. Independence Test of the Factors
4.1.1. Pearson’s Correlation Tests
4.1.2. Multicollinearity Tests
4.2. Classification of the Respective Attribute Interval of Environmental Factors and Calculation of Frequency Ratio and Information Value
4.3. Results of the Model
4.3.1. LR Regression and Coupling Model
4.3.2. Support Vector Machine (SVM) and Coupling Model
4.3.3. Random Forest and Coupling Models
4.4. Landslide Susceptibility Mapping
4.5. Accuracy Evaluation of the Model
4.5.1. Evaluation of Precision Parameters
4.5.2. Comparison of ROC Curve and AUC Values
4.6. Case Study
5. Discussions
5.1. Landslide Susceptibility Map Rationality
5.2. Evaluation Units
5.3. Significance of Environmental Factors
5.4. Uncertainty of the Coupling Models
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cruden, D.M. A simple definition of a landslide. Bull. Int. Assoc. Eng. Geol. 1991, 43, 27–29. [Google Scholar] [CrossRef]
- Ge, D.; Dai, K.; Guo, Z.; Li, Z. Early identification of serious geological hazards with integrated remote sensing technologies: Thoughts and recommendations. Geom. Inf. Sci. Wuhan Univ. 2019, 44, 949–956. [Google Scholar]
- Zhao, Z.; Zhang, F.; Zheng, J. Evaluation of landslide susceptibility by multiple adaptive regression spline method. Geom. Inf. Sci. Wuhan Univ. 2021, 46, 442–450. [Google Scholar]
- Wang, Y.; Fang, Z.; Niu, R.; Peng, L. Landslide susceptibility analysis based on deep learning. J. Geo-Inf. Sci. 2021, 23, 2244–2260. [Google Scholar]
- Guo, Z.Z.; Yin, K.L.; Fu, S.; Huang, F.; Gui, L.; Xia, H. Evaluation of landslide susceptibility based on GIS and WOE-BP model. Earth Sci. 2019, 44, 4299–4312. [Google Scholar]
- Sezer, E.A.; Pradhan, B.; Gokceoglu, C. Manifestation of an adaptive neuro-fuzzy model on landslide susceptibility mapping: Klang valley, Malaysia. Expert Syst. Appl. 2011, 38, 8208–8219. [Google Scholar] [CrossRef]
- Ulrich, K.; Benjamin, J.G.; Ghazanfar, A.K.; Lewis, A.O. GIS-based landslide susceptibility mapping for the 2005 Kashmir earthquake region. Geomorphology 2008, 101, 631–642. [Google Scholar]
- Huang, F.; Cao, Z.; Guo, J.; Jiang, S.; Li, S.; Guo, Z. Comparisons of heuristic, general statistical and machine learning models for landslide susceptibility prediction and mapping. Catena 2020, 191, 104580. [Google Scholar] [CrossRef]
- Panchal, S.; Shrivastava, A.K. Application of analytic hierarchy process in landslide susceptibility mapping at regional scale in GIS environment. J. Stat. Manag. Syst. 2020, 23, 199–206. [Google Scholar] [CrossRef]
- Zhu, A.; Miao, Y.; Wang, R.; Zhu, T.; Deng, Y.; Liu, J.; Yang, L.; Qin, C.; Hong, H. A comparative study of an expert knowledge-based model and two data-driven models for landslide susceptibility mapping. Catena 2018, 166, 317–327. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Pradhan, B.; Gokceoglu, C. Application of fuzzy logic and analytical hierarchy process (AHP) to landslide susceptibility mapping at Haraz Watershed, Iran. Nat. Hazards 2012, 63, 965–996. [Google Scholar] [CrossRef]
- Jaafari, A.; Zenner, E.K.; Panahi, M.; Shahabi, H. Hybrid artificial intelligence models based on a neuro-fuzzy system and metaheuristic optimization algorithms for spatial prediction of wildfire probability. Agric. For. Meteorol. 2019, 266–267, 198–207. [Google Scholar] [CrossRef]
- Gholami, M.; Ghachkanlu, E.N.; Khosravi, K.; Pirasteh, S. Landslide prediction capability by comparison of frequency ratio, fuzzy gamma and landslide index method. J. Earth Syst. Sci. 2019, 128, 42. [Google Scholar] [CrossRef]
- Costache, R.; Tien Bui, D. Spatial prediction of flood potential using new ensembles of bivariate statistics and artificial intelligence: A case study at the Putna river catchment of Romania. Sci. Total Environ. 2019, 691, 1098–1118. [Google Scholar] [CrossRef]
- Lima, P.; Steger, S.; Glade, T.; Murillo-García, F.G. Literature review and bibliometric analysis on data-driven assessment of landslide susceptibility. J. Mt. Sci. 2022, 19, 1670–1698. [Google Scholar] [CrossRef]
- Chanu, M.L.; Bakimchandra, O. A Comparative Study on Landslide Susceptibility Mapping Using AHP and Frequency Ratio Approach; Springer: Singapore, 2021; pp. 267–281. [Google Scholar]
- Wu, H.; Song, T. An evaluation of landslide susceptibility using probability statistic modeling and GIS’s spatial clustering analysis. Hum. Ecol. Risk Assess. Int. J. 2018, 24, 1952–1968. [Google Scholar] [CrossRef]
- Costache, R. Flash-Flood Potential assessment in the upper and middle sector of Prahova river catchment (Romania). A comparative approach between four hybrid models. Sci. Total Environ. 2019, 659, 1115–1134. [Google Scholar] [CrossRef] [PubMed]
- Li, A.A.; Garman, R.H.; Kaufmann, W.; Auer, R.N.; Bolon, B. Weight of evidence (WOE) and benchmark dose (BMD) analysis: Brain morphometry and startle behavior as examples. Neurotoxicol. Teratol. 2015, 100, 113. [Google Scholar] [CrossRef]
- Sifa, S.F.; Mahmud, T.; Tarin, M.A.; Haque, D.M.E. Event-based landslide susceptibility mapping using weights of evidence (WoE) and modified frequency ratio (MFR) model: A case study of Rangamati district in Bangladesh. Geol. Ecol. Landsc. 2019, 4, 222–235. [Google Scholar] [CrossRef]
- Wang, Q.; Li, W.; Chen, W.; Bai, H. GIS-based assessment of landslide susceptibility using certainty factor and index of entropy models for the Qianyang County of Baoji city, China. J. Earth Syst. Sci. 2015, 124, 1399–1415. [Google Scholar] [CrossRef]
- Zhao, Z.; Liu, Z.Y.; Xu, C. Slope Unit-Based Landslide Susceptibility Mapping Using Certainty Factor, Support Vector Machine, Random Forest, CF-SVM and CF-RF Models. Front. Earth Sci. 2021, 9, 589630. [Google Scholar] [CrossRef]
- Mandal, S.; Mondal, S. Weighted Overlay Analysis (WOA) Model, Certainty Factor (CF) Model and Analytical Hierarchy Process (AHP) Model in Landslide Susceptibility Studies; Springer International Publishing: Cham, Switzerland, 2018; pp. 135–162. [Google Scholar]
- Ozdemir, A. A Comparative Study of the Frequency Ratio, Analytical Hierarchy Process, Artificial Neural Networks and Fuzzy Logic Methods for Landslide Susceptibility Mapping: Taşkent (Konya), Turkey. Geotech. Geol. Eng. 2020, 38, 4129–4157. [Google Scholar] [CrossRef]
- Yilmaz, I. Landslide susceptibility mapping using frequency ratio, logistic regression, artificial neural networks and their comparison: A case study from Kat landslides (Tokat—Turkey). Comput. Geosci. 2009, 35, 1125–1138. [Google Scholar] [CrossRef]
- Xu, K.; Guo, Q.; Li, Z.W.; Xiao, J.; Qin, Y.S.; Chen, D.; Kong, C.F. Landslide susceptibility evaluation based on BPNN and GIS: A case of Guojiaba in the Three Gorges Reservoir Area. Int. J. Geogr. Inf. Sci. 2015, 29, 1111–1124. [Google Scholar] [CrossRef]
- Ali, S.; Parvin, F.; Pham, Q.B.; Khedher, K.M.; Dehbozorgi, M.; Rabby, Y.W.; Anh, D.T.; Nguyen, D.H. An ensemble random forest tree with SVM, ANN, NBT, and LMT for landslide susceptibility mapping in the Rangit River watershed, India. Nat. Hazards 2022, 113, 1601–1633. [Google Scholar] [CrossRef]
- Zhou, X.; Wen, H.; Zhang, Y.; Xu, J.; Zhang, W. Landslide susceptibility mapping using hybrid random forest with GeoDetector and RFE for factor optimization. Geosci. Front. 2021, 12, 101211. [Google Scholar] [CrossRef]
- Lee, S.; Lee, M.J.; Jung, H.S.; Lee, S. Landslide susceptibility mapping using Naïve Bayes and Bayesian network models in Umyeonsan, Korea. Geocarto Int. 2019, 35, 1665–1679. [Google Scholar] [CrossRef]
- Guo, Z.; Shi, Y.; Huang, F.; Fan, X.; Huang, J. Landslide susceptibility zonation method based on C5.0 decision tree and K-means cluster algorithms to improve the efficiency of risk management. Geosci. Front. 2021, 12, 249–267. [Google Scholar] [CrossRef]
- Yuan, X.; Liu, C.; Nie, R.; Yang, Z.; Li, W.; Dai, X.; Cheng, J.; Zhang, J.; Ma, L.; Fu, X.; et al. A Comparative Analysis of Certainty Factor-Based Machine Learning Methods for Collapse and Landslide Susceptibility Mapping in Wenchuan County, China. Remote Sens. 2022, 14, 3259. [Google Scholar] [CrossRef]
- Di Napoli, M.; Carotenuto, F.; Cevasco, A.; Confuorto, P.; Di Martire, D.; Firpo, M.; Pepe, G.; Raso, E.; Calcaterra, D. Machine learning ensemble modelling as a tool to improve landslide susceptibility mapping reliability. Landslides 2020, 17, 1897–1914. [Google Scholar] [CrossRef]
- Pradhan, B.; Seeni, M.I.; Kalantar, B. Performance Evaluation and Sensitivity Analysis of Expert-Based, Statistical, Machine Learning, and Hybrid Models for Producing Landslide Susceptibility Maps; Springer International Publishing: Cham, Switzerland, 2017; pp. 193–232. [Google Scholar]
- Nguyen, V.T.; Tran, T.H.; Ha, N.A.; Ngo, V.L.; Nadhir, A.A.; Tran, V.P.; Duy Nguyen, H.; Ma, M.; Amini, A.; Prakash, I.; et al. GIS Based Novel Hybrid Computational Intelligence Models for Mapping Landslide Susceptibility: A Case Study at Da Lat City, Vietnam. Sustainability 2019, 11, 7118. [Google Scholar] [CrossRef]
- Yang, L.; Wei, C. Landslide Susceptibility Evaluation Using Hybrid Integration of Evidential Belief Function and Machine Learning Techniques. Water 2019, 12, 113. [Google Scholar]
- Gu, T.; Li, J.; Wang, M.; Duan, P. Landslide susceptibility assessment in Zhenxiong County of China based on geographically weighted logistic regression model. Geocarto Int. 2021, 37, 4952–4973. [Google Scholar] [CrossRef]
- Xiao, B.; Zhao, J.; Li, D.; Zhao, Z.; Zhou, D.; Xi, W.; Li, Y. Combined SBAS-InSAR and PSO-RF Algorithm for Evaluating the Susceptibility Prediction of Landslide in Complex Mountainous Area: A Case Study of Ludian County, China. Sensors 2022, 22, 8041. [Google Scholar] [CrossRef]
- Mehdi, S.; Baharak, M.; Hasan, A.; Abolfazl, M. Assessing landslide susceptibility using machine learning models: A comparison between ANN, ANFIS, and ANFIS-ICA. Environ. Earth Sci. 2020, 79, 536. [Google Scholar]
- Zhou, C.; Yin, K.; Cao, Y.; Ahmed, B.; Li, Y.; Catani, F.; Pourghasemi, H.R. Landslide susceptibility modeling applying machine learning methods: A case study from Longju in the Three Gorges Reservoir area, China. Comput. Geosci. 2018, 112, 23–37. [Google Scholar] [CrossRef]
- Pham, B.T.; Pradhan, B.; Tien Bui, D.; Prakash, I.; Dholakia, M.B. A comparative study of different machine learning methods for landslide susceptibility assessment: A case study of Uttarakhand area (India). Environ. Model. Softw. 2016, 84, 240–250. [Google Scholar] [CrossRef]
- Xiong, K.; Adhikari, B.R.; Stamatopoulos, C.A.; Zhan, Y.; Wu, S.; Dong, Z.; Di, B. Comparison of Different Machine Learning Methods for Debris Flow Susceptibility Mapping: A Case Study in the Sichuan Province, China. Remote Sens. 2020, 12, 295. [Google Scholar] [CrossRef]
- Pham, B.T.; Shirzadi, A.; Shahabi, H.; Omidvar, E.; Singh, S.K.; Sahana, M.; Asl, D.T.; Ahmad, B.B.; Quoc, N.K.; Lee, S. Landslide Susceptibility Assessment by Novel Hybrid Machine Learning Algorithms. Sustainability 2019, 11, 4386. [Google Scholar] [CrossRef]
- Zhao, C.; Lu, Z. Remote Sensing of Landslides—A Review. Remote Sens. 2018, 10, 279. [Google Scholar] [CrossRef]
- Zhu, Z.; Gan, S.; Yuan, X.; Zhang, J. Landslide Susceptibility Mapping with Integrated SBAS-InSAR Technique: A Case Study of Dongchuan District, Yunnan (China). Sensors 2022, 22, 5587. [Google Scholar] [CrossRef] [PubMed]
- Cheng, J.Y.; Dai, X.A.; Wang, Z.K.; Li, J.Z.; Qu, G.; Li, W.L.; She, J.X.; Wang, Y.L. Landslide Susceptibility Assessment Model Construction Using Typical Machine Learning for the Three Gorges Reservoir Area in China. Remote Sens. 2022, 14, 2257. [Google Scholar] [CrossRef]
- Shahzad, N.; Ding, X.L.; Abbas, S. A Comparative Assessment of Machine Learning Models for Landslide Susceptibility Mapping in the Rugged Terrain of Northern Pakistan. Appl. Sci. 2022, 12, 2280. [Google Scholar] [CrossRef]
- Angillieri, M.Y.E. Debris flow susceptibility mapping using frequency ratio and seed cells, in a portion of a mountain international route, Dry Central Andes of Argentina. Catena 2020, 189, 104504. [Google Scholar] [CrossRef]
- Marjanović, M.; Kovačević, M.; Bajat, B.; Voženílek, V. Landslide susceptibility assessment using SVM machine learning algorithm. Eng. Geol. 2011, 123, 225–234. [Google Scholar] [CrossRef]
- Stumpf, A.; Kerle, N. Object-oriented mapping of landslides using Random Forests. Remote Sens. Environ. 2011, 115, 2564–2577. [Google Scholar] [CrossRef]
- Polat, A. An innovative, fast method for landslide susceptibility mapping using GIS-based LSAT toolbox. Environ. Earth Sci. 2021, 80, 217. [Google Scholar] [CrossRef]
- Youssef, A.M.; Pourghasemi, H.R. Landslide susceptibility mapping using machine learning algorithms and comparison of their performance at Abha Basin, Asir Region, Saudi Arabia. Geosci. Front. 2021, 12, 639–655. [Google Scholar] [CrossRef]
- Wu, R.Z.; Hu, X.D.; Mei, H.B.; He, J.Y.; Yang, J.Y. Spatial susceptibility assessment of landslides based on random forest: A case study from Hubei section in the three gorges reservoir area. Earth Sci. 2021, 46, 321–330. [Google Scholar]
- Zhang, J.; Yin, K.; Wang, J.; Liu, L.; Huang, F. Evaluation of landslide susceptibility for Wanzhou district of Three Gorges Reservoir. Chin. J. Rock Mech. Eng. 2016, 35, 284–296. [Google Scholar]
- Langping, L.I.; Hengxing, L.; Changbao, G.; Yongshuang, Z. Geohazard Susceptibility Assessment along the Sichuan Tibet Railway and Its Adjacent Area Using an Improved Frequency Ratio Method. Geoscience 2017, 31, 911. [Google Scholar]
- Zevenbergen, L.W.; Thorne, C.R. Quantitative analysis of land surface topography. Earth Surf. Process. Landf. 1987, 12, 47–56. [Google Scholar] [CrossRef]
- Camera, C.A.S.; Bajni, G.; Corno, I.; Raffa, M.; Stevenazzi, S.; Apuani, T. Introducing intense rainfall and snowmelt variables to implement a process-related non-stationary shallow landslide susceptibility analysis. Sci. Total Environ. 2021, 786, 147360. [Google Scholar] [CrossRef] [PubMed]
- Xi, W.; Li, G.; Moayedi, H.; Nguyen, H. A particle-based optimization of artificial neural network for earthquake-induced landslide assessment in Ludian county, China. Geomat. Nat. Hazards Risk 2019, 10, 1750–1771. [Google Scholar] [CrossRef]
- Hadmoko, D.S.; Lavigne, F.; Sartohadi, J.; Hadi, P. Landslide hazard and risk assessment and their application in risk management and landuse planning in eastern flank of Menoreh Mountains, Yogyakarta Province, Indonesia. Nat. Hazards 2010, 54, 623–642. [Google Scholar] [CrossRef]
- Deng, X.; Sun, G.; He, N.; Yu, Y. Landslide susceptibility mapping with the integration of information theory, fractal theory, and statistical analyses at a regional scale: A case study of Altay Prefecture, China. Environ. Earth Sci. 2022, 81, 346. [Google Scholar] [CrossRef]
- Faming, H.; Zhou, Y.E.; Chi, Y. Uncertainties of landslide susceptibility prediction: Different attribute interval divisions of environmental factors and different data-based models. Earth Sci. 2020, 45, 4535–4549. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Factors | Clusters | Sources |
|---|---|---|
| Elevation | Topographic | ASTER GDEM (spatial resolution of 30 m × 30 m) (http://www.gscloud.cn/, accessed on 13 May 2021) |
| Slope | ||
| Aspect | ||
| Plan curvature | ||
| Profile curvature | ||
| Distance to faults | Geological | Geological map of China (Scale of 1:20,000) |
| Lithology | ||
| Rainfall | Hydrological | Data Center of the Chinese Academy of Sciences (Spatial resolution 1 km × 1 km) (http://www.resdc.cn, accessed on 15 July 2021) |
| Distance to rivers | The thematic map of the river system in China from 91 satellite map assistant software (Scale of 1:50,000) | |
| NDVI | Land cover | The geospatial data cloud network (The Landsat 8 OLI image on http://www.gscloud.cn/ (accessed on 2 August 2021)) |
| Land use | The land use and land cover change database in China (http://www.resdc.cn, accessed on 10 September 2021) | |
| Distance to roads | Open street map data (https://www.openstreetmap.org, accessed on 3 August 2021) |
| Prediction Situation | Actual Situation | |
|---|---|---|
| Positive Sample | Negative Sample | |
| Landslide | True positive (TP) | False positive (FP) |
| Negative sample | False negative (FN) | True negative (TN) |
| Factors | TOL | VIF |
|---|---|---|
| Elevation | 0.513 | 1.951 |
| Slope | 0.844 | 1.185 |
| Aspect | 0.996 | 1.004 |
| Profile curvature | 0.713 | 1.403 |
| Plan curvature | 0.718 | 1.392 |
| Distance to rivers | 0.838 | 1.193 |
| Distance to roads | 0.853 | 1.172 |
| Distance to faults | 0.800 | 1.25 |
| Rainfall | 0.702 | 1.424 |
| NDVI | 0.603 | 1.659 |
| Lithology | 0.779 | 1.283 |
| Land use | 0.721 | 1.388 |
| Factors | Classes | FR | IV |
|---|---|---|---|
| Elevation/m | 478–800 | 1.66 | 0.51 |
| 801–900 | 0.68 | −0.38 | |
| 901–1000 | 0.97 | −0.03 | |
| 1001–1100 | 1.07 | 0.06 | |
| 1101–1200 | 0.97 | −0.03 | |
| 1201–1300 | 1.53 | 0.43 | |
| 1300–1500 | 0.9 | −0.1 | |
| >1500 | 0.33 | −1.12 | |
| Aspect | Flat (−1) | 0 | −9.94 |
| North (0–22.5, 337.5–360) | 0.88 | −0.25 | |
| Northeast (22.5–67.5) | 0.93 | −0.08 | |
| East (67.5–11.25) | 1.05 | 0.05 | |
| Southeast (112.5–157.5) | 0.98 | −0.02 | |
| South (157.5–202.5) | 1.25 | 0.23 | |
| Southwest (202.5–247.5) | 1.2 | 0.18 | |
| West (247.5–292.5) | 1.05 | 0.05 | |
| Northwest (292.5–337.5) | 0.83 | −0.19 | |
| NDVI | −0.71 | 15.03 | 2.71 |
| 0.16–0.34 | 4.59 | 1.52 | |
| 0.34–0.47 | 1.63 | 0.49 | |
| 0.47–0.77 | 1.36 | 0.31 | |
| 0.77–0.92 | 0.5 | −0.69 | |
| Distance to faults/m | 0–200 | 1.69 | 0.52 |
| 200–400 | 1.97 | 0.68 | |
| 400–600 | 1.69 | 0.53 | |
| 600–800 | 1.16 | 0.15 | |
| 800–1000 | 0.94 | −0.06 | |
| 1000–1200 | 1.22 | 0.2 | |
| >1200 | 0.87 | −0.14 | |
| Profile curvature | −17.95–−8.8 | 0 | −9.73 |
| −8.8–0.35 | 0.88 | −0.13 | |
| 0.35–4.92 | 1.24 | 0.21 | |
| 4.92–9.50 | 1.55 | 0.44 | |
| 9.50–23.23 | 0 | −10.79 | |
| Plan curvature | −12.33–−0.15 | 1.08 | 0.08 |
| −0.15–0.29 | 0.94 | −0.07 | |
| 0.29–1.49 | 0.96 | −0.05 | |
| 1.49–2.47 | 0.94 | −0.06 | |
| 2.47–15.42 | 1.06 | 0.06 | |
| Slope | 0–10 | 0.91 | −0.1 |
| 10–20 | 0.97 | −0.03 | |
| 20–25 | 1.02 | 0.02 | |
| 25–30 | 1.07 | 0.07 | |
| 30–40 | 1.09 | 0.08 | |
| 40–45 | 0.91 | −0.09 | |
| 45–76 | 0.8 | −0.23 | |
| Rainfall/mm | 1076.24–1080.39 | 0.86 | −0.16 |
| 1080.39–1082.46 | 0.42 | −0.91 | |
| 1082.46–1084.53 | 0.2 | −1.64 | |
| 1084.53–1088.97 | 1.43 | 0.42 | |
| 1088.97–1095.68 | 1.15 | 0.2 | |
| 1095.68–1099.62 | 1 | −0.01 | |
| 1099.62–1101.40 | 0.88 | −0.15 | |
| Distance to roads/m | 0–200 | 3.02 | 1.1 |
| 200–400 | 1 | 0 | |
| 400–600 | 0.73 | −0.32 | |
| 600–800 | 0.42 | −0.86 | |
| 800–1000 | 0.56 | −0.57 | |
| >1000 | 0.35 | −1.05 | |
| Distance to rivers/m | 0–200 | 1.44 | 0.36 |
| 200–400 | 1.01 | 0.01 | |
| 400–600 | 0.71 | −0.35 | |
| 600–800 | 1.12 | 0.11 | |
| 800–1000 | 0.56 | −0.58 | |
| >1000 | 0.91 | −0.09 | |
| Land use | Forestland | 0.78 | −0.25 |
| Farmland | 0.83 | −0.19 | |
| Residential areas | 4.65 | 1.54 | |
| Grassland | 1.68 | 0.52 | |
| Water | 2.62 | 0.96 | |
| Bareland | 9.73 | 2.28 | |
| Gardenland | 1.3 | 0.26 | |
| Lithology | Dolomite | 1.74 | 0.56 |
| Mudstone and limestone | 0.44 | −0.82 | |
| Shales | 1.4 | 0.34 | |
| Magmatic veins | 1.25 | 0.22 | |
| Metamorphic rock | 2.45 | 0.9 | |
| Granitic rocks | 0.74 | −0.3 |
| Figure | LR | IV–LR | FR–LR |
|---|---|---|---|
| Elevation | 0 | 0.28 | 0.36 |
| Slope | 0.02 | 2.21 | 2.1 |
| Aspect | 0 | 1.12 | 1.08 |
| Distance to rivers | 0 | −0.374 | −0.421 |
| Distance to roads | −0.001 | 0.761 | 0.598 |
| Distance to faults | 0 | 0.298 | 0.288 |
| Constant | 15.1 | −0.1 | −6.5 |
| Profile curvature | 1.072 | 1.802 | 1.182 |
| Plan curvature | 1.108 | 0.575 | 0.555 |
| Rainfall | −0.013 | 0.642 | 0.791 |
| NDVI | −3.38 | 0.667 | 0.237 |
| Lithology | 0.158 | 0.631 | 0.656 |
| Land use | 0.065 | 0.343 | 0.182 |
| Model | Geohazard Level | Number of Area Pixels | Area Pixels of Percentage (%) | Number of Landslide Pixels | Ratio of Landslides (%) | Frequency (FR) |
|---|---|---|---|---|---|---|
| LR | Very low | 274,712 | 17.74 | 290 | 3.96 | 0.22 |
| Low | 426,520 | 27.55 | 578 | 7.9 | 0.29 | |
| Moderate | 416,408 | 26.9 | 1424 | 19.46 | 0.72 | |
| High | 281,493 | 18.18 | 2203 | 30.1 | 1.66 | |
| Very high | 149,072 | 9.63 | 2824 | 38.58 | 4.01 | |
| IV–LR | Very low | 393,109 | 25.39 | 278 | 3.8 | 0.15 |
| Low | 479,922 | 31 | 550 | 7.51 | 0.24 | |
| Moderate | 339,148 | 21.91 | 1262 | 17.24 | 0.79 | |
| High | 212,188 | 13.71 | 2235 | 30.54 | 2.23 | |
| Very high | 133,835 | 8.64 | 2994 | 40.91 | 4.73 | |
| FR–LR | Very low | 397,363 | 25.67 | 280 | 3.83 | 0.15 |
| Low | 479,757 | 30.99 | 560 | 7.65 | 0.25 | |
| Moderate | 344,913 | 22.28 | 1266 | 17.3 | 0.78 | |
| High | 192,377 | 12.43 | 2275 | 31.08 | 2.5 | |
| Very high | 133,794 | 8.64 | 2938 | 40.14 | 4.65 | |
| SVM | Very low | 572,224 | 36.96 | 247 | 3.37 | 0.09 |
| Low | 373,936 | 24.15 | 702 | 9.59 | 0.4 | |
| Moderate | 218,640 | 14.12 | 908 | 12.41 | 0.88 | |
| High | 244,536 | 15.79 | 1318 | 18.01 | 1.14 | |
| Very high | 138,868 | 8.97 | 4144 | 56.62 | 6.31 | |
| IV–SVM | Very low | 677,668 | 43.77 | 263 | 8.84 | 0.2 |
| Low | 382,465 | 24.7 | 824 | 9.89 | 0.4 | |
| Moderate | 172,218 | 11.12 | 684 | 9.35 | 0.84 | |
| High | 180,610 | 11.67 | 1372 | 14.31 | 1.23 | |
| Very high | 135,244 | 8.74 | 4176 | 57.62 | 6.6 | |
| FR–SVM | Very low | 652,793 | 42.16 | 210 | 2.87 | 0.07 |
| Low | 374,546 | 24.19 | 820 | 11.2 | 0.46 | |
| Moderate | 173,883 | 11.23 | 686 | 9.37 | 0.83 | |
| High | 180,751 | 11.67 | 1423 | 19.44 | 1.67 | |
| Very high | 136,231 | 8.8 | 4180 | 57.11 | 6.49 | |
| RF | Very low | 272,850 | 17.62 | 48 | 0.66 | 0.01 |
| Low | 429,932 | 27.77 | 346 | 4.73 | 0.07 | |
| Moderate | 413,439 | 26.7 | 978 | 13.36 | 0.4 | |
| High | 306,267 | 19.78 | 1727 | 23.6 | 1.51 | |
| Very high | 125,717 | 8.12 | 4220 | 57.66 | 7.05 | |
| IV–RF | Very low | 368,515 | 23.8 | 37 | 0.51 | 0.02 |
| Low | 470,434 | 30.39 | 372 | 5.08 | 0.17 | |
| Moderate | 342,154 | 22.1 | 924 | 12.62 | 0.57 | |
| High | 238,676 | 15.42 | 1782 | 24.35 | 1.58 | |
| Very high | 128,419 | 8.29 | 4202 | 57.41 | 6.92 | |
| FR–RF | Very low | 385,216 | 24.88 | 36 | 0.49 | 0.02 |
| Low | 471,985 | 30.49 | 325 | 4.44 | 0.15 | |
| Moderate | 333,961 | 21.57 | 874 | 11.94 | 0.55 | |
| High | 230,193 | 14.87 | 1758 | 24.02 | 1.62 | |
| Very high | 126,850 | 8.19 | 4326 | 59.11 | 7.21 |
| LR | SVM | RF | IV–LR | IV–SVM | IV–RF | FR–LR | FR–SVM | FR–RF | |
|---|---|---|---|---|---|---|---|---|---|
| TP | 1611 | 1753 | 1874 | 1685 | 1768 | 1968 | 1752 | 1809 | 1979 |
| TN | 1438 | 1658 | 1779 | 1485 | 1621 | 1831 | 1424 | 1596 | 1868 |
| FP | 725 | 505 | 384 | 678 | 542 | 332 | 739 | 567 | 295 |
| FN | 618 | 476 | 355 | 544 | 461 | 261 | 477 | 420 | 250 |
| Precision (%) | 68.96 | 77.64 | 82.99 | 71.31 | 76.54 | 85.57 | 70.33 | 76.14 | 87.03 |
| Recall (%) | 72.27 | 78.65 | 84.07 | 75.59 | 79.32 | 88.29 | 78.60 | 81.16 | 88.78 |
| Accuracy (%) | 69.42 | 77.66 | 83.17 | 72.18 | 77.16 | 86.50 | 72.31 | 77.53 | 87.59 |
| F1 score (%) | 70.58 | 78.14 | 83.53 | 73.39 | 77.90 | 86.91 | 74.24 | 78.57 | 87.90 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, W.; Chen, G.; Zhao, J.; Lin, Y.; Qin, B.; Yao, W.; Cao, Q. Landslide Susceptibility Evaluation of Machine Learning Based on Information Volume and Frequency Ratio: A Case Study of Weixin County, China. Sensors 2023, 23, 2549. https://doi.org/10.3390/s23052549
He W, Chen G, Zhao J, Lin Y, Qin B, Yao W, Cao Q. Landslide Susceptibility Evaluation of Machine Learning Based on Information Volume and Frequency Ratio: A Case Study of Weixin County, China. Sensors. 2023; 23(5):2549. https://doi.org/10.3390/s23052549
Chicago/Turabian StyleHe, Wancai, Guoping Chen, Junsan Zhao, Yilin Lin, Bingui Qin, Wanlu Yao, and Qing Cao. 2023. "Landslide Susceptibility Evaluation of Machine Learning Based on Information Volume and Frequency Ratio: A Case Study of Weixin County, China" Sensors 23, no. 5: 2549. https://doi.org/10.3390/s23052549
APA StyleHe, W., Chen, G., Zhao, J., Lin, Y., Qin, B., Yao, W., & Cao, Q. (2023). Landslide Susceptibility Evaluation of Machine Learning Based on Information Volume and Frequency Ratio: A Case Study of Weixin County, China. Sensors, 23(5), 2549. https://doi.org/10.3390/s23052549