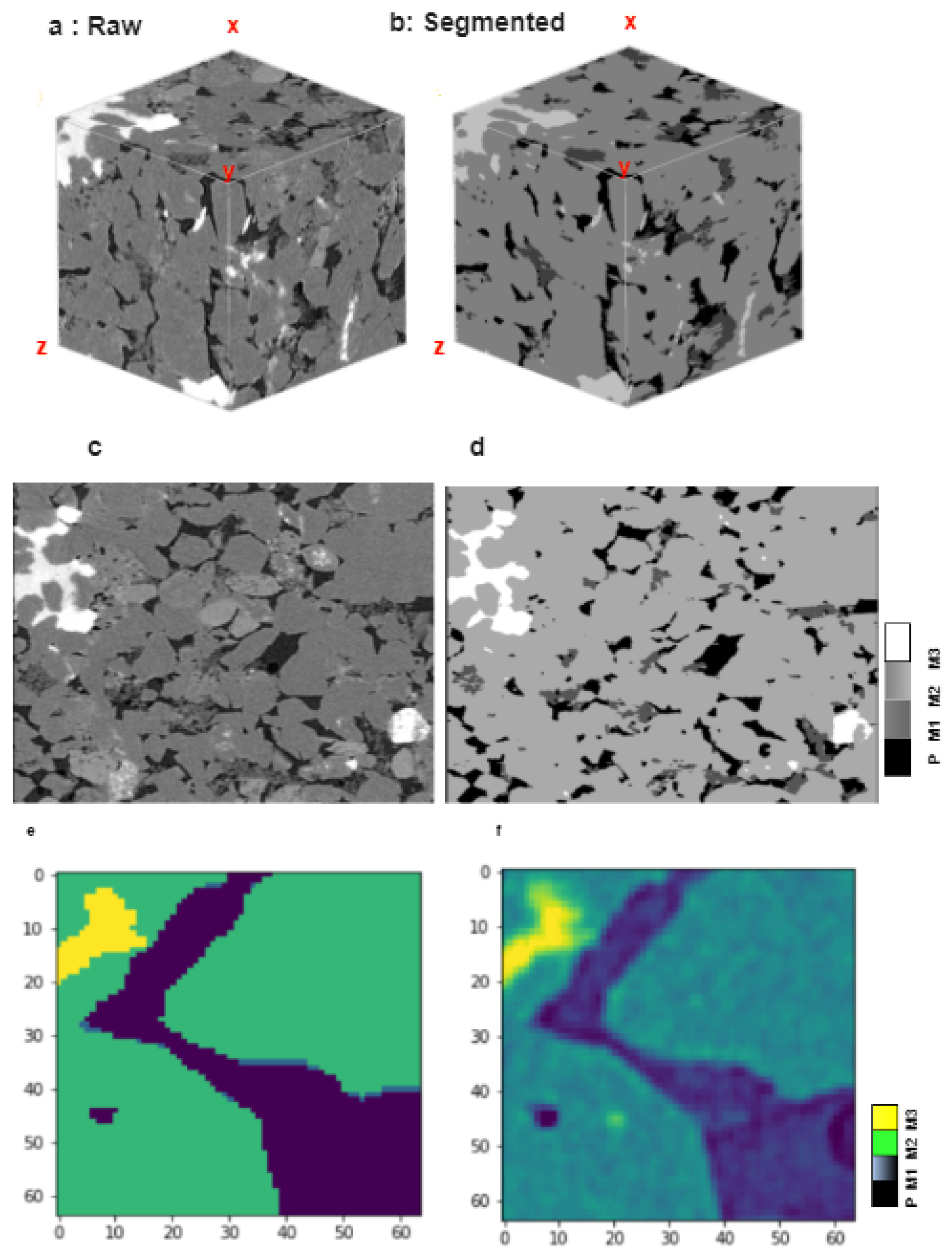
Because unusual reserves are inherently tight, it is essential to comprehend their microstructural characteristics, such as their mechanical properties, in order to effectively foresee how the formation will respond during the production and completion processes. Organic materials and petroleum both dwell in the micro- and nano-pores of unconventional reservoirs such as sandstones, shales, and coalbed methane formations. In order to quantify pore volume and explain pore structure, much recent research on these pores has relied on macroscopic, indirect measures [
16]. Macroscopic porosity and pore structure can be measured and characterized indirectly by techniques such as nuclear magnetic resonance (NMR) spectroscopy, mercury injection capillary pressure (MICP) and surface area analysis. While these techniques are great for defining the pore structure, they do not actually create an image of the pore structure in great detail. Two- and three-dimensional pictures of nanometer-sized pores can be obtained using conventional scanning electron microscopy (SEM) or focused ion beam scanning electron microscopy (FIB-SEM) [
17]. By firing an electron beam at a sample and then detecting the resulting signals, a two-dimensional image can be created using scanning electron microscopy (SEM). In FIB-SEM, an ion beam progressively mills away the surface as a series of sequential photos are captured to build a stack of images for a 3D representation, allowing for spot analysis in the mapping of elements across the surface. By combining these techniques, a 2D matrix representation of the sandstones’ minerals could be obtained. Reconstructing a 3D model of the matrix with FIB-SEM imaging allows us to see the microstructure and the connections between individual elements. There has been a lot of work based on CNN model object detection, image segmentation, etc. In order to quickly and accurately identify and classify various types of asphalt pavement cracks, Que et al. [
18] proposed a method of automatic classification of asphalt pavement cracks utilizing a novel integrated GANs and improved VGG model. The suggested method is a two-step approach. To augment the dataset in the first stage and enhance the performance of the classification model, a GAN is employed to produce synthetic crack images. In the second stage, an improved VGG model is trained using the generated images. The enhanced VGG model comprises more convolutional layers that assist in extracting more characteristics from the images, increasing classification precision. However, the work has potential limitations such as require extensive computational resources, lack of generalization to real-world scenarios, and less diverse datasets. Yang Yu et al. [
19] proposed a hybrid framework based on the CNN model and transfer learning to detect the cracks of various types of concrete. However, the crack detection system has a major disadvantage of considering whole patches as cracks, which could be resolved using a segmentation-based model. Noh et al. [
20] presented an early article on semantic segmentation based on deconvolution. The encoder uses convolutional layers from the VGG 16-layer network, and the deconvolutional network takes the classification model as input and generates a map of pixel-wise class probabilities. Deconvolution and unpooling layers detect pixel-wise class labels and forecast segmentation masks. In SegNet, another promising study, Badrinarayanan et al. [
21] suggested a convolutional encoder–decoder architecture for image segmentation. SegNet’s basic trainable segmentation mechanism comprises an encoder network that is topologically identical to the 13 convolutional layers of the VGG16 network, which is followed by a decoder network, and a pixel-wise classification layer. The decoder SegNet’s upsamples is unique. It uses max-pooling-step pooling indices for nonlinear upsampling of its lower-resolution input feature map(s). Upsampling is not required for learning. Using trainable filters to combine sparse upsampled maps and dense feature maps, SegNet has fewer trainable parameters than competing systems. Milletari et al. [
22] proposed the V-Net, another prominent FCN-based model, for 3D medical picture segmentation. They used a dice coefficient-based goal function during model training to handle the substantial difference between foreground and background voxels. The network was trained only on prostate MRI data and can currently predict volume segmentation. A novel visual crack width measurement method based on backbone double-scale features for enhanced detection automation proposed by Tang et al. [
23] is another significant contribution to the field of computer vision. The suggested method seeks to increase the precision and effectiveness of crack measurement and identification in diverse settings. The suggested method is computationally efficient in addition to having a high degree of accuracy because it only needs one forward pass of the backbone network to detect cracks and estimate their width. This qualifies it for real-time applications, including automatically spotting cracks in roads during inspections. It is crucial to note, though, that the proposed method has several drawbacks, such as limited crack patterns and generalization to real-world scenarios. A 2D CNN model with hyperparameter optimization performs well at predicting RC beams’ torsional strength [
24]. However, we believe, for this type of work especially where we have to see the insights of the structure, the 3D-based CNN model outperforms the traditional 2D model. Progressive Dense V-net (PDV-Net) for the rapid and automatic segmentation of pulmonary lobes from chest CT images and the 3D-CNN encoder for lesion segmentation [
25] are other notable medical image segmentation studies. Segmenting images from biological microscopy was made possible by U-Net, which was proposed by Ronneberger et al. [
15]. Training and tuning their network on sparsely annotated images requires data augmentation. The U-design net consists of a context-capturing contracting path and a localization-enabling symmetric expanding path. In order to extract features, the down-sampling or contracting section uses an FCN-like architecture with 3x3 convolutions. When up-sampling or expanding, up-convolution (or deconvolution) is used to reduce the number of feature maps while increasing their size. To prevent losing pattern information, the down-sampling portion of the network’s feature maps is replicated in the up-sampling portion. A segmentation map is created by applying an 11 convolution to the feature maps, which labels each pixel in the input image with a predetermined label. The original U-Net design has undergone various suggested alterations and extensions in recent years to enhance its functionality. Modifications to the algorithm include adding skip connections between the encoder and decoder, employing residual blocks in the encoder and decoder, and using attention techniques to prioritize the features in the encoder and decoder. The U-Net architecture that Chen et al. [
26] proposed may adaptively weight the feature maps based on their significance in the segmentation job. It has a channel and spatial attention mechanism. The use of U-Net in association with other deep learning models for image segmentation tasks has also been investigated by a number of experts. For instance, Li et al. [
27] introduced the MMF-Net, which is a multi-scale and multi-model fusion U-Net that merges multiple U-Net models of various scales to increase segmentation accuracy. The performance of U-Net in image segmentation tasks can be considerably enhanced using transfer learning, which is a potent deep learning technique. In order to segregate the nuclei in a dataset of histopathology photos, Kong et al. [
28] employed transfer learning to pre-train a U-Net on the ImageNet dataset. The capacity of the pre-trained model to learn high-level features that are essential for the segmentation task was cited by the authors as the reason why the pre-trained U-Net outperformed the U-Net trained from scratch.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}