Abstract
A multi-modal 3D object-detection method, based on data from cameras and LiDAR, has become a subject of research interest. PointPainting proposes a method for improving point-cloud-based 3D object detectors using semantic information from RGB images. However, this method still needs to improve on the following two complications: first, there are faulty parts in the image semantic segmentation results, leading to false detections. Second, the commonly used anchor assigner only considers the intersection over union (IoU) between the anchors and ground truth boxes, meaning that some anchors contain few target LiDAR points assigned as positive anchors. In this paper, three improvements are suggested to address these complications. Specifically, a novel weighting strategy is proposed for each anchor in the classification loss. This enables the detector to pay more attention to anchors containing inaccurate semantic information. Then, SegIoU, which incorporates semantic information, instead of IoU, is proposed for the anchor assignment. SegIoU measures the similarity of the semantic information between each anchor and ground truth box, avoiding the defective anchor assignments mentioned above. In addition, a dual-attention module is introduced to enhance the voxelized point cloud. The experiments demonstrate that the proposed modules obtained significant improvements in various methods, consisting of single-stage PointPillars, two-stage SECOND-IoU, anchor-base SECOND, and an anchor-free CenterPoint on the KITTI dataset.
1. Introduction
In 3D object-detection scenarios, vehicles are generally equipped with LiDAR and cameras to acquire point cloud and RGB images. However, the task of handling complex scenarios is arduous using a single sensor. LiDAR-only methods find it arduous to detect objects that are far from the sensor, since the reflection points are too sparse. In contrast, image-only methods are vulnerable to occlusion and bad weather, such as fog and snow. Therefore, multi-modal approaches that use both sensors have become a popular research direction. Recently, many new multi-modal methods [1,2,3,4] have been proposed. However, LiDAR-only methods, such as SE-SSD [5] and PV-RCNN [6], outperform these in the KITTI [7] 3D object-detection benchmark. This anomaly indicates the importance of finding an effective fusion strategy to improve the 3D object-detector performance.
PointPainting [8] proposes a fusion strategy that attaches the semantic scores of the RGB image to the LiDAR points based on the transformation relationship between the image and the point cloud. This can be applied to various existing LiDAR-only methods and requires minimal changes to the network architecture. However, in some cases, the detection accuracy of PointPainting [8] drops compared with the original methods. Therefore, this paper proposes PointPainting++, including the following methods, to solve the problems in PointPainting [8].
This paper first proposes a novel anchor weight-assignment strategy to reduce the negative impact of inaccurate semantic information. Inaccurate semantic information is generated due to the following three points. Firstly, the semantic result of the image is imperfect due to the quality of the segmentation algorithm. In addition, there are errors in the calibration of cameras and LiDARs. Finally, rounding operations are needed during the transformation between the pixels and LiDAR points, which also introduces errors.
As shown in Figure 1, these inaccurate segmentations often correspond to many false detections, contrary to the intention of introducing semantic information. In this paper, we propose a strategy that uses the proportion of inaccurate points contained in the anchor to generate their weights in the loss function. In this way, anchors with more inaccurate points will play a more critical role, enhancing the detector’s ability to distinguish ambiguous objects.

Figure 1.
Semantic segmentation and 3D object-detection results of painted PointPillars [8] on the KITTI [7] dataset. The purple and yellow parts in the semantic segmentation results represent motorcycle and pedestrian categories, respectively. The inaccurate parts of the semantic segmentation results lead to false detections.
Furthermore, a dual-attention module based on the SEBlock [9] is introduced to the detection network. This module measures the importance of the channels and points in a voxelized point cloud and generates weights for each voxel in the channel and point dimensions. This module can suppress channels with inaccurate semantic information for each LiDAR point on the one hand, and suppress the features of LiDAR points carrying inaccurate semantic information on the other.
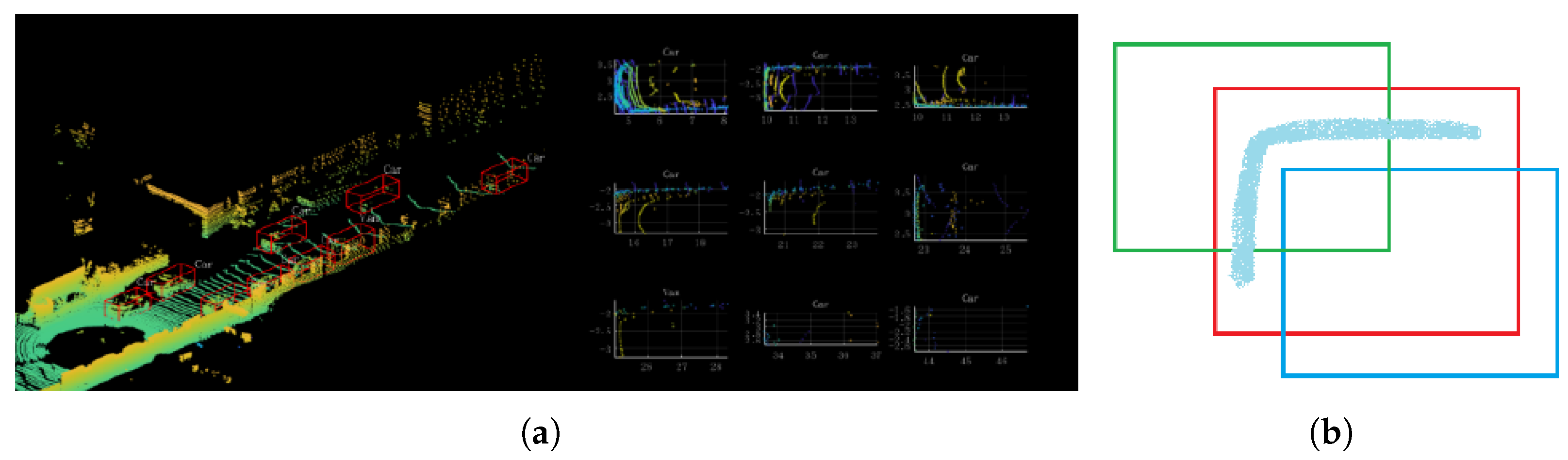
In addition, a SegIoU-based anchor assigner is used for more efficient anchor assignment. As shown in Figure 2a, the distribution of LiDAR points is often concentrated on the surface, since they are obtained by collecting the reflected laser. This phenomenon is more pronounced for objects of larger sizes, such as cars and trucks. Figure 2b shows that both boxes are assigned positive anchor tags when using the max-IoU assigner [10]. However, the blue box does not contain any target points, which makes classification difficult. This shows that the max-IoU assigner will introduce many controversial positive anchors with few points inside when processing “L”-shaped LiDAR points. We proposed a SegIoU-based anchor assigner to only assign positive tags to anchors that have a high degree of overlap and similar semantic information with ground-truth boxes. In this way, the inferior positive anchors containing few target points will be screened out due to different semantic information with ground-truth boxes.

Figure 2.
Figure (a) is a annotation sample from the KITTI [7] dataset, and Figure (b) is a typical case of anchor assignment. The red box in Figure (b) is the ground-truth box, and the green and blue boxes are anchors. A positive anchor tag will be assigned to the blue box by the max-IoU assigner. However, the blue box containing few target LiDAR points is not a high-quality positive anchor.
These three improvements are evaluated on the KITTI [7] 3D and bird’s-eye view (BEV) object-detection benchmarks. The results showed that PointPainting++ could better improve the performance of cars, pedestrians, and cyclists compared with PointPainting [8]. Experiments on the KITTI [7] valid set proved that our strategy is effective in multiple methods.
Contributions. PointPainting++ combines image and LiDAR point information more effectively based on PointPainting [8] and reduces detector interference caused by inaccurate semantic information. Our contributions are as follows:
- Anchor weight-assignment strategy. We propose a way to assign weights to anchors based on semantic information. The detector becomes more discriminative by paying more attention to the problematic anchors carrying more inaccurate semantic information.
- Dual-attention module. We adopt a dual-attention module to enhance the voxelized point cloud. This module suppresses the inaccurate semantic information in a voxelized point cloud.
- SegIoU-based anchor assigner. We use a SegIoU based anchor assigner to filter out abnormal positive anchors, to avoid confusion and improve detector performance.
2. Related Works
2.1. Multi-Modal 3D Object-Detection Methods
According to the level of data fusion, current multi-modal 3D object-detection methods using both point cloud and RGB images can be divided into three categories: raw data fusion, feature-level fusion, and decision-level fusion. A chronological overview of the multi-modal 3D object-detection approaches is shown in Figure 3.

Figure 3.
Chronological overview of the multi-modal 3D object-detection methods.
2.1.1. Raw Data Fusion
The raw data fusion-based method fuses RGB images and LiDAR points before they are fed into a detection pipeline. Such methods are generally built sequentially: 2D detection or segmentation networks are first employed to extract information from the RGB images, and then the extracted information is passed to the point cloud, and finally the enhanced point cloud is fed to the point-cloud-based detectors. Based on the fusion types, the raw data fusion-based methods can be divided into two categories: region-level fusion and point-level fusion.
Region-level fusion. Region-level fusion methods aim to utilize information from RGB images to constrain object candidate regions in the point cloud data. Specifically, an image is first passed through a 2D object detector to generate a 2D bounding box. Then, the bounding boxes are extruded into 3D viewing frustums. Finally, the LiDAR points within the frustums are sent to the point-cloud-based detector. F-PointNet [11] first proposes this fusion mechanism, and many new methods have been proposed to improve this fusion framework. Representative methods of this category include F-ConvNet [12], RoarNet [13], F-PointPillars [14], and General-Fusion [15].
Point-level fusion. Point-level fusion methods aim to enhance point cloud data with image information. The enhanced point cloud is then fed into a point-cloud-based detector for better detection results. PointPainting [8] is the pioneer of such methods. This fusion strategy has been followed by a lot of papers, including Fusion-Painting [16], Complexer-YOLO [17], and MVP [18].
2.1.2. Feature-Level Fusion
The feature-level fusion-based method builds fused features using the features extracted from the point cloud and images. This method is currently the most popular multi-modal method and many fusion methods fall into this category, since traditional CNN is not available on raw point clouds. The feature fusion methods can be divided into three categories based on the fusion stages [19].
Fusion in backbone. Such methods first correspond the LiDAR points to the pixels through a transformation between the camera coordinate system and the LiDAR coordinate system. After that, the features from a LiDAR backbone and the features from an image backbone using various fusion operators are fused according to this pixel-to-point correspondence. This fusion strategy can be performed in the middle layers of a voxel-based detection backbone. Representative methods included MMF [20], MVX-Net [21], DeepFusion [22], and CAT-Det [23]. In addition, this fusion strategy can also be conducted only at the feature maps of the voxel-based detection backbone. Representative methods include 3D-CVF [1], FUTR3D [24], BEVFusion [25], VF-Fusion [26], TransFusion [27], and PointAugmenting [28]. In addition to the fusion in voxel-based backbones, there also exist some papers incorporating image information into the point-based detection backbone, including PointFusion [29], EPNet [3], and PI-RCNN [2].
Fusion in proposal generation and RoI head. In such methods, 3D object proposals are first generated from a LiDAR detector, and then the 3D proposals are projected onto the image view and bird’s-eye view to crop features from the image and LiDAR backbone, respectively. Finally, the cropped image and LiDAR features are fused in an RoI head to predict parameters for each 3D object. MV3D [30] and AVOD [31] are pioneers using multi-view aggregation for multi-modal detection. FUTR3D [24] and TransFusion [27] employ the transformer [32] decoder as the RoI head for multi-modal feature fusion.
2.1.3. Decision-Level Fusion
Decision-level fusion merges the results of a LiDAR-based network and an image-based network at the decision level. It does not need to consider the interaction of the point cloud and RGB image at the information level, resulting in low complexity. The representative methods include CLOCs [4] and Fast-CLOCs [33].
2.2. PointPainting
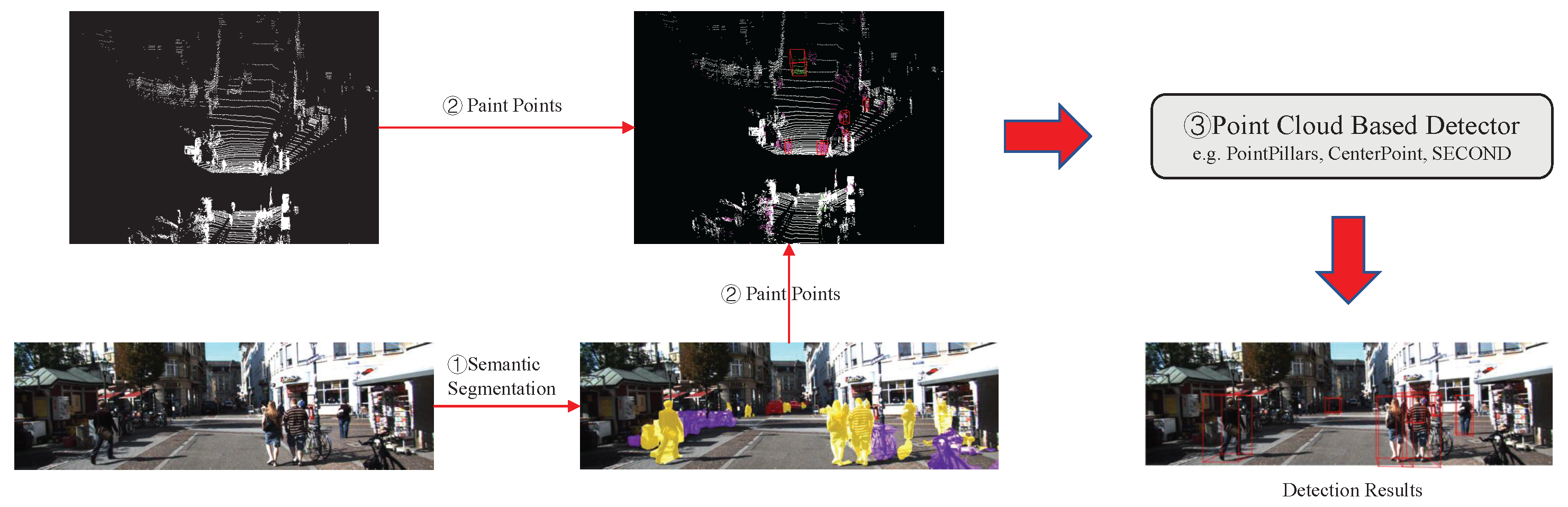
PointPainting [8] is one of the raw data-fusion methods and is the basis of the method proposed in this paper. As shown in Figure 4, the architecture of PointPainting [8] consists of three main stages: (1) semantic segmentation: an image-based semantic segmentation network that generates pixel-wise semantic scores; (2) point cloud painting: painting LiDAR points with the semantic scores; (3) point-cloud-based detector: a point-cloud-based 3D object-detection network with changed input channels. The three stages will be described in detail in the following sections.
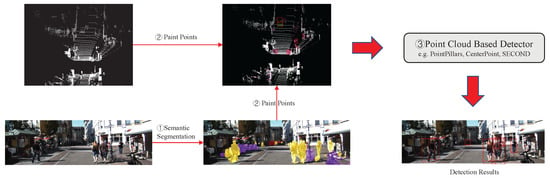
Figure 4.
Architecture of PointPainting [8]. This consists of three main stages: (1) image-based semantic segmentation, (2) point cloud painting, and (3) point-cloud-based detector.
2.2.1. Semantic Segmentation
The image-based semantic segmentation network takes an RGB image as input and outputs a matrix containing the predicted class scores that correspond to all pixels. These scores contain rich semantic information which can complement the point cloud. PointPainting [8] can use the existing semantic segmentation module to complete this step.
2.2.2. Point Cloud Painting
The data-fusion method of PointPainting [8] is shown in Algorithm 1. A LiDAR point can be projected onto an RGB image by an affine transformation. PointPainting [8] finds the corresponding pixel of the LiDAR point on the RGB image based on this transformation and then attaches the semantic scores of the pixel to the LiDAR point, forming new channels.
| Algorithm 1 Point Cloud Painting(). | |
| |
|
Take the KITTI [7] dataset as an example. The calibration file of the KITTI dataset gives the intrinsic matrix of camera i, the correction matrix of camera 0 , and the projection matrix between the LiDAR and camera coordinate system . A LiDAR point (homogeneous coordinates) can be projected onto the camera i image using the following formula:
where (homogeneous coordinates) represents the coordinates of the projected point in the camera coordinate system. The transformation in the above formula can be represented by a homogeneous transformation matrix . Thus, the above formula can also be expressed as:
Each LiDAR point in the KITTI [7] dataset is , where is the spatial location of each point and r is the reflectance of each point. The output of the semantic segmentation network is C class scores , where (car, pedestrian, cyclist, background). Once the LiDAR points are projected to the image, the semantic scores of the relevant pixel are appended to the LiDAR point to generate the painted LiDAR point .
2.2.3. Point-Cloud-Based Detector
The point-cloud-based detectors of different structures can be adapted to detect objects with painted points, simply by changing their input dimension. Better detection results can be achieved due to this additional semantic information.
3. PointPainting++
In this section, the details of PointPainting++ are introduced, followed by the efficient acceleration algorithm that this process uses.
3.1. PointPainting++ Architecture
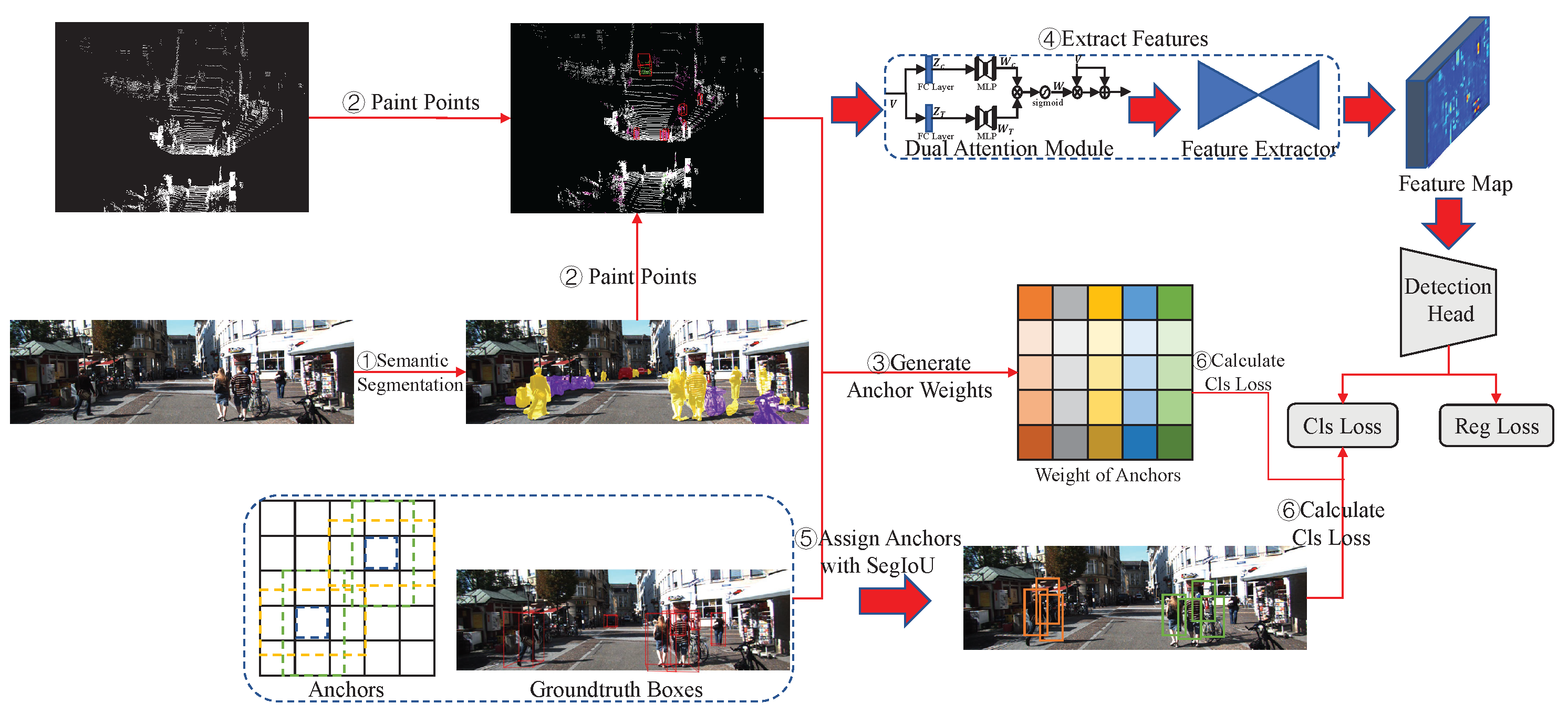
As shown in Figure 5, the main architecture of PointPainting++ consists of six steps. In the first and second steps, we follow PointPainting [8] to attach semantic information to the LiDAR points. In the third step, the weight of each anchor is generated by counting the proportion of inaccurate points and the total points inside each anchor. Then, the voxelized point cloud is weighted using the dual-attention module, followed by feature extraction using the backbone of the point-cloud-based method. After that, a SegIoU-based assigner is used to assign anchors. Finally, the classification loss is calculated by the anchor assignment result and the weight of each anchor.
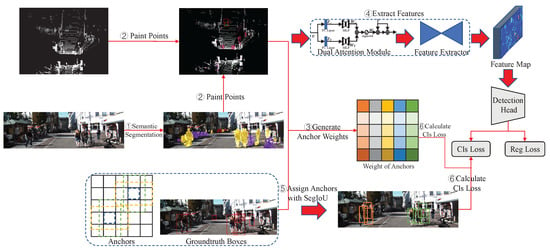
Figure 5.
Architecture of PointPainting++. It consists of six steps: (1) image-based semantic segmentation, (2) point cloud painting, (3) generation of anchor weights, (4) feature extraction, (5) SegIoU-based anchor assignment, (6) calculation of classification loss.
The following sections will detail our improvements to PointPainting [8].
3.1.1. Anchor Weight Assignment
In this paper, we propose a strategy for assigning weights to each anchor during the calculation of classification loss. Points containing inaccurate semantic information need to be labeled before weights are assigned. As shown in Algorithm 2, a LiDAR point will be considered to be an outlier if its semantic information does not match the ground truth. Different labels will be appended to the end of LiDAR points to distinguish them.
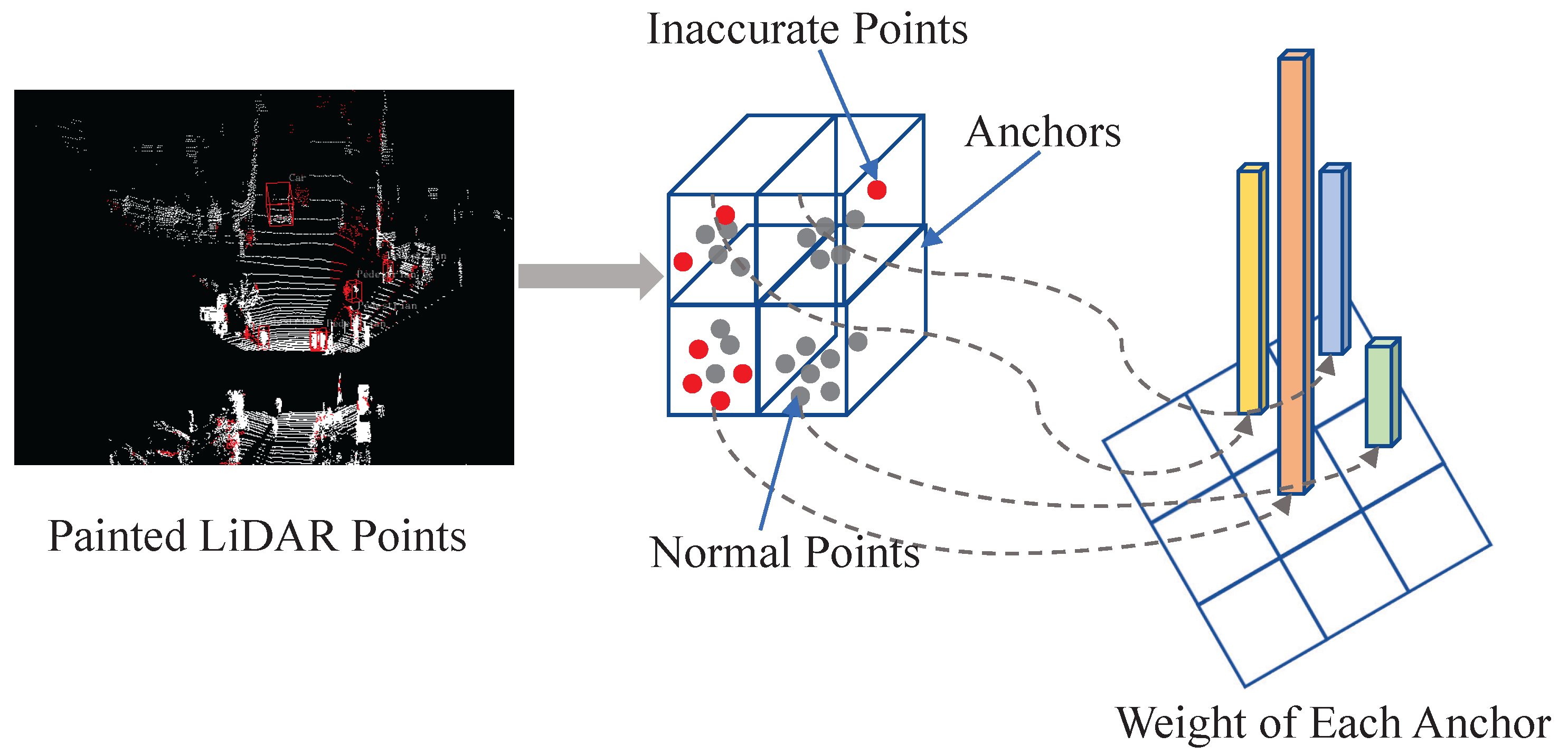
After labeling the inaccurate points, as shown in Figure 6, each anchor will be assigned a weight according to the proportion of inaccurate points in it. The more inaccurate points are contained within an anchor, the harder classification becomes. Therefore, the more inaccurate points an anchor contains, the higher weight it is assigned. The specific formula is as follows:
| Algorithm 2 Mark Points(). | |
| |
| |
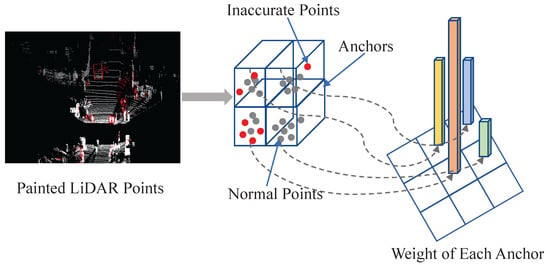
Figure 6.
Anchor weight-assignment strategy. The weight of each anchor is calculated according to the proportion of inaccurate points it contains.
In the above formula, is the base weight of each anchor, is the additional weight coefficient, is a small number preventing the denominator from being zero, and , represent the number of inaccurate points and the total number of points in the anchor, respectively. The weight assigned to each anchor ranges from to and linearly increases with the proportion of inaccurate points within the anchor. In this way, the difficult anchors that contain more inaccurate semantic information will play a more important role in the classification loss. The detector will also pay more attention to the anchors that are difficult to classify and obtain the ability to distinguish controversial samples, thereby showing better performance.
Such a weighting strategy is suitable for both anchor-based and center-based methods. Take the PointPillars [34] and CenterPoint [35] as examples.
The loss function of PointPillars [34] consists of the classification loss , the location regression loss , and the direction loss :
where is the number of positive anchors and are the weight coefficients of these three losses, respectively. The classification loss can be weighted according to the strategy in this section:
where is the weight of each anchor, generated as mentioned above.
Similarly, the loss function of CenterPoint [35] consists of the heatmap loss and the location regression loss :
where is the number of positive anchors and are the weight coefficients of these two losses. The detection head of CenterPoint [35] outputs a heatmap, which indicates the probability that there is a target center at this location. Each point on the heatmap corresponds to an area in the original space, and this area can be regarded as a pseudo-anchor when applying the weight-assignment strategy. Thus, the weights of this region can be calculated in the same the way as the anchor weights. The weighted can be expressed as follows:
where is the weight of each anchor, generated as mentioned above.
3.1.2. Dual-Attention Module
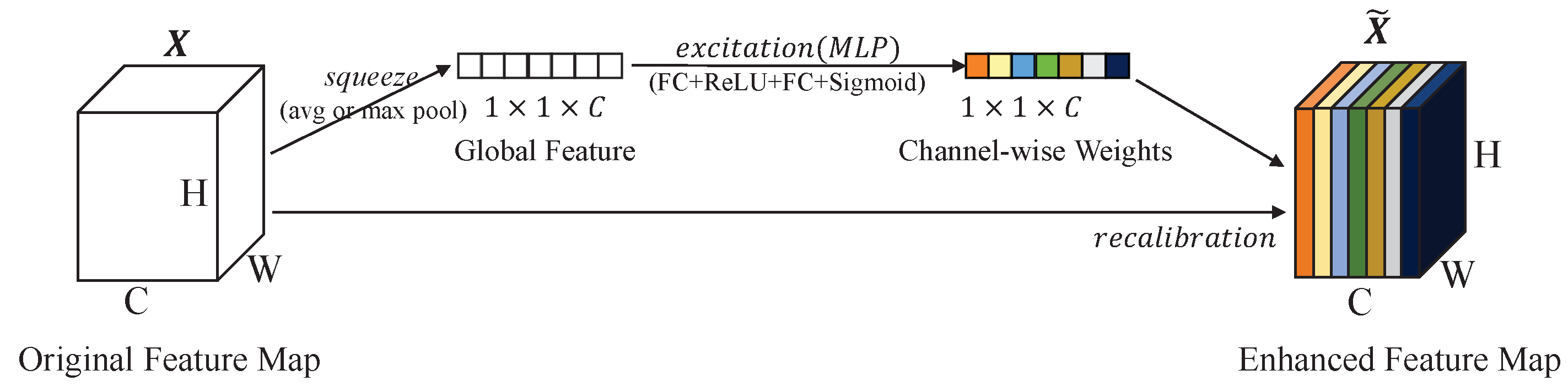
In addition to constraining inaccurate features from the perspective of the loss function, we further considered improving the network structure to suppress the inaccurate features. A structure based on SEBlock [9] is proposed to weigh the voxelized point cloud. This combines the channel dimension and point dimension to generate the weights of the voxelized point cloud. The structure of the SEBlock [9] is depicted in Figure 7. For any feature map , an SEBlock can be constructed to perform feature recalibration. The features are first put through a squeeze operation, which produces a channel descriptor by aggregating feature maps across their spatial dimensions . The aggregation is followed by an excitation operation, which takes a simple self-gating mechanism that takes the embedding as input and produces a collection of channel-wise weights. These weights are applied to the feature map to generate the output of the SEBlock [9], which can be directly fed into subsequent layers of the network.
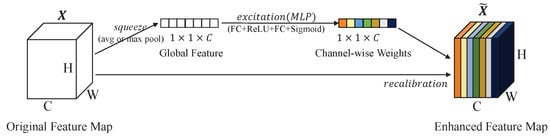
Figure 7.
The structure of SEBlock [9]. It first uses the squeeze operation to generate global features, and then uses the excitation operation to capture channel dependencies and generate channel-wise weights.
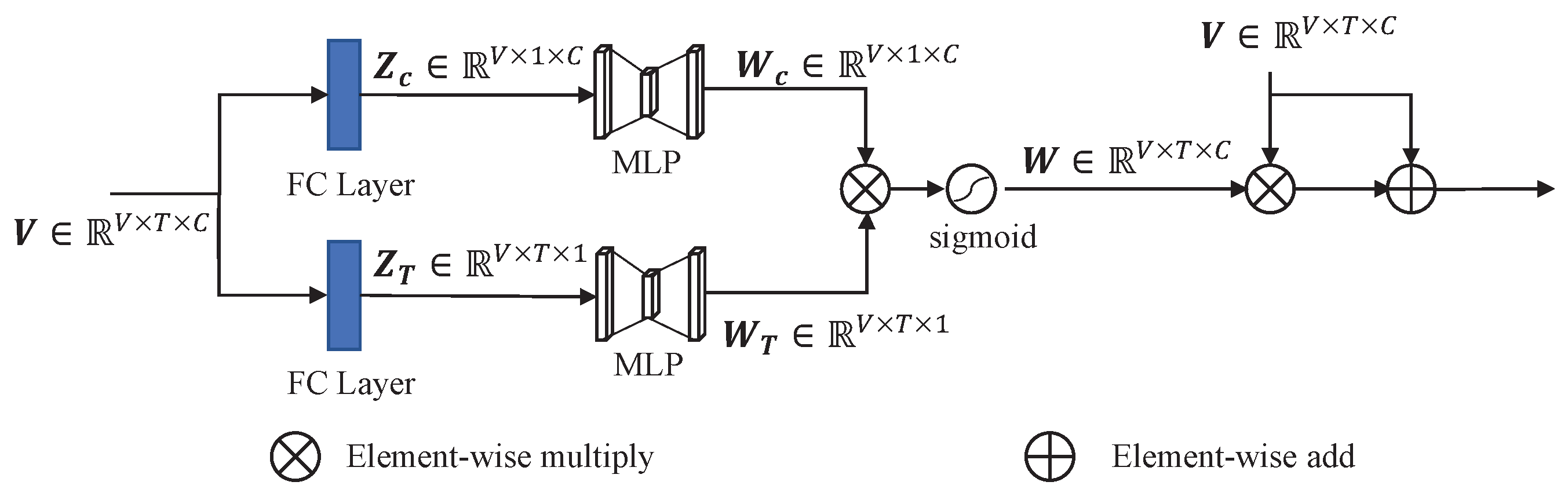
As shown in Figure 8, this module consists of two SEBlocks [9]. For any voxelized point cloud (V voxels, T points in each voxel, C features of each point), we use the fully connected layer to compress the channel dimension and point dimension, respectively, to extract global features. The global features then undergo a simple gating mechanism to generate weights for channel and point dimensions:
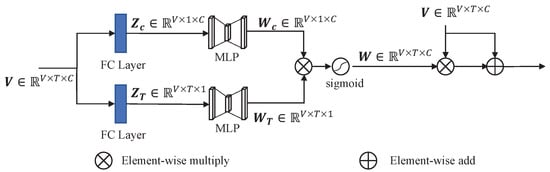
Figure 8.
The architecture of the dual attention module. This module has a symmetrical structure, and each part can be regarded as an SEBlock [9]. Fully connected layers are used to compress dimensions to extract global features.
refers to the ReLU function, and . We parameterize the gating mechanism to limit model complexity by forming a bottleneck with two fully connected (FC) layers. Subsequently, the element-wise multiply operation is used to comprehensively consider both channel and point dimensions and obtain the final weight through a sigmoid activation:
Finally, the original features and weighted features are combined through the element-wise add operation and fed into the subsequent network. The weight comprehensively considers the weight of each point in a voxel and the weight of each channel in a point. On the one hand, the weight of each point suppresses the features of points with inaccurate semantic information in the voxel. On the other hand, the weight of each channel suppresses the features of channel with wrong semantic information in each point. Therefore, the inaccurate semantic information is suppressed after the dual attention module, and the subsequent part of the detector can obtain more accurate features, thus showing performance improvement.
3.1.3. SegIoU-Based Anchor Assigner
As mentioned in Section 1, many anchors that contain few target points are assigned positive tags. In order to remove those controversial positive anchors, we propose the SegIoU-based anchor assigner.
We follow the anchor-assignment strategy of faster R-CNN [10] to assign a binary class tag (of being an object or not) to each anchor. Two kinds of anchors are assigned a positive tag: (1) the anchor/anchors with the highest IoU with a ground-truth box, (2) an anchor with an IoU that is higher than the positive threshold with any ground-truth box. Anchors with an IoU that is lower than the negative threshold to any ground-truth box are assigned a negative tag. Anchors that are neither positive nor negative do not contribute to classification loss.
On this basis, SegIoU is proposed instead of IoU for anchor assignment, which considers the degree of overlap between anchors and ground-truth boxes both in geometry and semantics:
where is a hyperparameter used to control the numerical size of the , and represent the semantic scores of points inside anchor and ground-truth box, respectively, and is the Hellinger distance used to quantify the similarity between the two probability distributions. and are obtained by averaging the semantic scores of the points within the anchor and ground-truth box. Most anchors do not contain any points inside due to the spareness of the point cloud. The semantic scores of such anchors are set to a uniform distribution.
After obtaining the probability distribution, the Hellinger distance can be computed as:
The semantic information of the ground-truth boxes usually has certain categories. Therefore, the probability distribution of the ground truth boxes will differ from those of the controversial positive anchors, making the semantic loss of controversial anchors more prominent. Thus, the SegIoU of the controversial anchors will be lower than that of the normal positive anchors. The controversial anchors can be filtered from positive anchors with a threshold that is set in advance.
The SegIoU-based anchor assigner has strict rules, which often result in a low number of positive anchors. We adopted an insurance mechanism to avoid the over-screening problem. Let be the number of positive anchors selected by the SegIoU-based assigner and be the number of positive anchors selected by the max-IoU assigner. We set the minimum value of the number of positive anchors to . The anchors will be sorted by SegIoU if , and the top ones will be selected as positive anchors.
3.2. An Efficient Acceleration Algorithm
Without exception, the methods mentioned in the previous section need to analyze the points in each anchor. For example, the number of inaccurate points and total points inside each anchor are needed when assigning weights to anchors. However, the anchors are generated according to the feature map, and each location on the feature map corresponds to anchors of different sizes, which means that the number of anchors is usually large. The number of anchors can be calculated by the following formula:
where W and H represent the size of the feature map, and C represents the number of anchor categories corresponding to each point on the feature map. Given a feature map, if there are three types of targets to be detected and each type has two orientations, then the total number of anchors will be = 960,000. Using the traversal and loop to handle such a massive number of anchors will consume a large amount of computational resources and severely slow down the training speed.
We propose utilizing 2D convolution to speed up this process. The size of anchors in the z-direction can be ignored because the anchor settings in the z-direction include all the parts in which points exist. A feature map with the same size as the voxelized point cloud can be constructed to record the information needed in each voxel after this simplification. Finally, after a 2D convolution of this feature map using the convolution kernel corresponding to the anchor, a tensor that records the information needed in each anchor can be obtained.
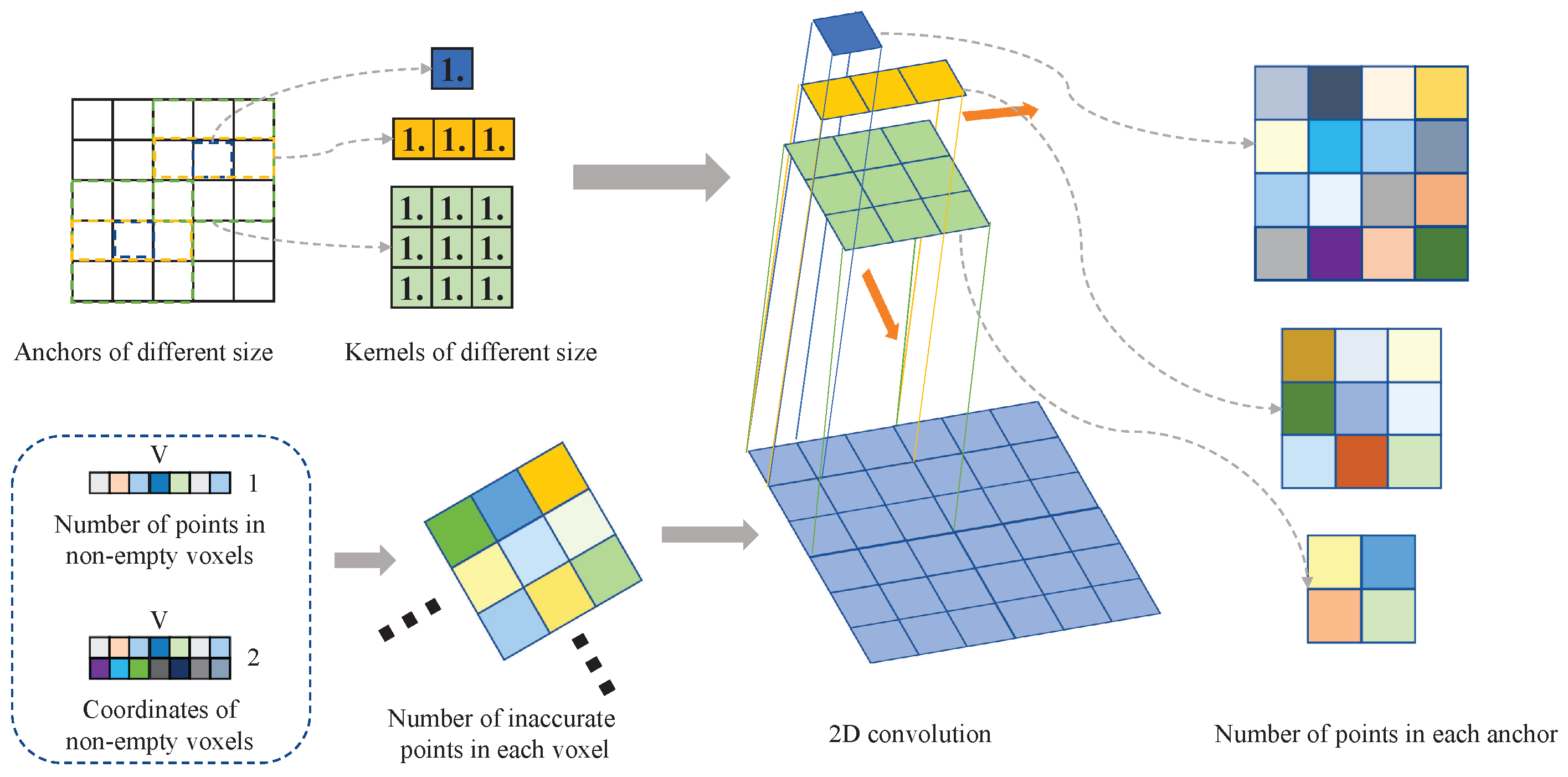
A case in point is the calculation of the number of points in each anchor. We illustrate this calculation process in Figure 9. This process can be divided into three steps. The first step is to voxelize the LiDAR points and obtain three tensors , , which represent the features after voxelization, the number of points in non-empty voxels, and the 2D coordinates of non-empty voxels. V represents the number of non-empty voxels, T represents the number of points collected within each voxel, and C represents the number of features of each point. The tensor that records the number of points inside each voxel can be obtained by filling according to into a tensor of the same size as the voxelized point cloud. The second step aims to determine the size of the convolution kernel by calculating the quotient of the anchor size and the voxel size. Finally, the convolution stride is determined by the scaling factor of the point cloud feature. The number of points in each anchor can be calculated by performing 2D convolution using the convolution kernel filled with 1.0 on the tensor that records the number of points in each voxel. Such convolution operations can be quickly accelerated by GPU, significantly improving the training speed compared with loop operations.
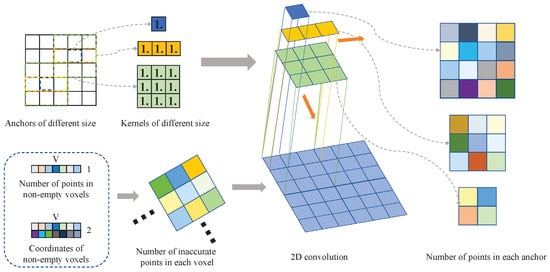
Figure 9.
The 2D convolution calculation process for the number of points in each anchor. The size of the convolution kernels is determined by the size of anchors. We generated a tensor that records the number of points in each voxel first, and then used different convolution kernels to perform 2D convolution on this tensor to obtain the number of points in each anchor.
4. Experimental Setup
In this section, we present the details of the dataset and the experimental setup for PointPainting++.
4.1. Dataset and Evaluation Metrics
We evaluated PointPainting++ on the KITTI [7] dataset. The data acquisition platform of the KITTI [7] dataset contained 2 grayscale cameras, 2 color cameras, 1 LiDAR, 4 optical lenses, and 1 GPS navigation system. Synchronized point cloud and images from the left and right color cameras in the KITTI [7] dataset were adopted. The dataset contained 7481 training samples and 7518 testing samples, with a total of 80,256 labeled objects. Three types of objects were detected, as required by the KITTI [7] object-detection benchmark: car, pedestrian, cyclist. We followed the guidance of [30,31] to further divide the training data into two groups, 3712 data and 3769 validation data, according to the partition file for experimental evaluation. We also followed the standard practice [30,36] to not use points projected outside the image range for training, since the ground-truth boxes are only annotated within the image range.
The results were evaluated using average precision (AP) as an indicator containing the IoU thresholds for three classes. The evaluation was conducted at three levels of difficulty—easy, moderate, and hard—according to the occlusion level, maximal truncation, and the height of the 2D box in the corresponding image.
4.2. Semantic Segmentation Network
We used DeepLabV3+ [37], implemented by mmsegmentation https://github.com/open-mmlab/mmsegmentation (accessed on 20 May 2021), for semantic segmentation. The module was trained on the CityScapes [38] dataset, which is similar to the KITTI [7] image data scene. We kept the semantic scores of cars and pedestrians, and followed PointPainting [8] to generate cyclists’ semantic scores. The semantic scores of the background category were obtained by adding the semantic scores of the other categories.
The image data collected by camera 2 and camera 3 were used for semantic segmentation. Any LiDAR point was discarded if its projection fell outside the perception range of camera 2 or 3. The semantic information of each LiDAR point contained the average value of the semantic scores of the images collected by the two cameras.
4.3. Point-Cloud-Based Network
We used the public code OpenPCDet https://github.com/open-mmlab/OpenPCDet (accessed on 17 January 2023) for PointPillars [34], SECOND [39], CenterPoint [35] and SECOND-IoU [39]. These existing methods cover the most common network structures: one-stage and two-stage, anchor-base and center-base, and voxel-feature and pillar-feature. Experiments show that PointPainting++ has good generality and improves the performance of networks of various architectures. Based on the original code, we implemented a new dataset—painted KITTI, instead of KITTI [7]—for experiments. The point cloud in painted KITTI contains expanded information, including the semantic scores of the four categories and accurate flag information. This changes the dimensions of point cloud from 4 to 9. The expanded point cloud is easily accepted by many existing LiDAR backbones after the input dimensions are changed. To compare this with PointPainting [8], the accurate flag information was not used in the training process. The SegIoU-based anchor assigner is only valid for anchor-based methods, including PointPillars [34], SECOND [39], and SECOND-IoU [39].
5. Experimental Results
This section describes the experimental results of PointPainting++ on the KITTI [7] dataset.
5.1. Quantitative Analysis
PointPainting++ was evaluated on various detection networks with different structures, including PointPillars [34], SECOND [39], CenterPoint [35] and SECOND-IoU [39]. We compared PointPainting++ with the original network and PointPainting methods in both 3D and BEV object-detection tasks. For the easy, moderate, and difficult samples, the IoU thresholds of the car category were 0.7, 0.5, and 0.5, respectively, and the IoU thresholds of the other categories were all 0.5. The mean average precision (mAP) over three kinds of different difficulty levels was used to represent the overall performance of the method. The fusion versions of each network that use PointPainting [8] will be referred to as being painted (e.g., Painted PointPillars), while the fusion versions that use PointPainting++ will be referred to as being painted++ (e.g., Painted PointPillars++).
As shown in Table 1, PointPainting++ showed a significant performance improvement for both 3D and BEV mAP compared to PointPainting [8] on detection networks with different structures. PointPainting [8] showed a performance degradation on some networks (e.g., SECOND-IoU [39]) due to the interference of inaccurate semantic information. Table 1 illustrates that the SECOND-IoU [39] after using PointPainting++ not only shows a performance improvement on the basis of PointPainting [8], but also achieves a better performance than the original network.

Table 1.
Comparison of experimental results on the KITTI [7] valid set.
As shown in Table 2, Table 3, Table 4 and Table 5, PointPainting++ showed a significant performance improvement in the detailed detection results for each category. As mentioned in PointPainting [8], for narrow vertical objects such as pedestrians, which are indistinguishable when using only LiDAR points, the introduction of semantic information leads to a more significant performance improvement. A further analysis of the experimental results is as follows:
Table 2.
Comparison of detailed experimental results for each category on the KITTI [7] valid set.
Table 3.
Comparison of detailed experimental results for each category on the KITTI [7] valid set.
Table 4.
Comparison of detailed experimental results for each category on the KITTI [7] valid set.
Table 5.
Comparison of detailed experimental results for each category on the KITTI [7] valid set.
Compared to PointPainting [8], after larger weights were assigned to anchors containing inaccurate semantic information, the network showed a significant performance improvement in the pedestrian category. In addition, PointPainting++ can also improve the performance degradation of certain categories mentioned in PointPainting [8]. Table 2, Table 3, Table 4 and Table 5 shows that PointPainting++ achieved a better performance than PointPainting [8] on all categories, and can achieve better results than the point-cloud-based network on certain structured detectors. This shows that our method can make more effective use of semantic information compared to PointPainting [8].
5.2. Ablation Study
We also incrementally added three improvements to the network. In the following discussion, we refer to the improved methods adopted by PointPainting++ as: I. anchor weight assignment with semantic information; II. dual-attention module; III. anchor-assignment strategy based on semantic information. PointPillars [34] was adopted as the benchmark method for this experiment. As shown in Table 6, the performance of the PointPillars [34] improved in the car and cyclist categories, a drop in performance was shown in the pedestrian category after I was applied. This is because the semantic results for pedestrians are usually more accurate, while those of cyclists contain errors. The detector will pay more attention to the cyclist category, which contains more inaccurate information under the guidance of weights. In addition, the performance of the PointPillars [34] in the pedestrian category was significantly improved after the addition of the dual-attention module, while also maintaining the improvements in the car and cyclist categories that were achieved in the previous step. Furthermore, the performance of the PointPillars [34] improved in all three categories after the SegIoU-based anchor assigner was introduced. The improved performance of the network demonstrates the effectiveness of PointPainting++.
Table 6.
Comparison of experimental results on different, improved methods of PointPainting++ on the KITTI [7] valid set.
5.3. Qualitative Analysis
Figure 10 shows the qualitative results of our PointPainting++, as applied to Painted PointPillars [34], CenterPoint [35], SECOND [39] and SECOND-IoU [39]. In Figure 10a, the original Painted PointPillars [8] wrongly detects cyclists in the bushes on the side of the road, while Figure 10e shows that our PointPainting++ eliminates these false detection results. In addition, as shown in Figure 10b, false detections remain, although PointPainting [8] helps in the detection of vertical narrow objects on the ground. However, as shown in Figure 10f, our PointPainting++ eliminated two such false detections. Figure 10c shows a scene with many overlapping targets. There are often numerous false detections in such scenarios, since many non-target points are projected to the target pixel positions. Figure 10g indicates that our PointPainting++ effectively reduces these false detections. Finally, as shown in Figure 10d, false detections may occur due to the inaccurate semantic results contained in single-target scenarios. In contrast, Figure 10h shows the performance improvement in our PointPainting++ in this scenario.

Figure 10.
Qualitative results of our PointPainting++ of PointPillars [34], CenterPoint [35], SECOND [39], and SECOND-IoU [39] on the KITTI [7] valid set. The upper part of each picture is the 3D detection projected to the image, and the lower part is the 3D detection in the LiDAR point cloud. The blue, green, and red boxes in the 2D detection results represent the car, cyclist, and pedestrian categories, respectively. The red boxes in the 3D result are the ground-truth boxes, and the rest of the boxes are the detection boxes. The results indicate that PointPainting++ improves the performance of detectors of various structures in multiple scenarios. (a) Painted PointPillars [34], (b) Painted CenterPoint [35], (c) Painted SECOND [39], (d) Painted SECOND-IoU [39], (e) Painted PointPillars++, (f) Painted CenterPoint++, (g) Painted SECOND++, (h) Painted SECOND-IoU++.
Figure 11 shows the qualitative results of our PointPainting++ when applied to Painted PointPillars [34]. The false detections in the multi-objective scene continued to decrease after improvement measures were applied to Painted PointPillars [34], which shows that the three improvement measures adopted in our PointPainting++ have a positive effect, reducing false detections and improving network performance.

Figure 11.
Qualitative results of our three improvements in the Painted PointPillars++. The experimental results of the Painted PointPillars [8] obtained with different improvement methods are shown from left to right. The blue, green, and red boxes in the 2D detection results represent the car, cyclist, and pedestrian categories, respectively. The red boxes in the 3D result are the ground-truth boxes, and the rest of the boxes are the detection boxes. False detections were significantly reduced as the improvements were introduced.
In sum, the qualitative analysis results show that PointPainting++ improves performance compared with existing methods in various network structures and various scenarios. The improvement methods all have a positive effect on reducing false detections and improving the performance of the object detector.
6. Discussions
Here, we performed ablation studies on the KITTI [7] valid dataset. All studies used the Painted PointPillars architecture and all parameters were kept constant except for the research objects.
6.1. The Influence of Anchor Weight
PointPainting++ reduces the confusion caused by inaccurate semantic information by assigning larger weights to anchors with more inaccurate LiDAR points. The effectiveness of this method strongly depends on the correct weight settings. The main reasons for this are as follows: most of the loss functions in the existing methods adopt the form of focal loss [40], which can pay more attention to difficult anchors. The network may pay too much attention to difficult anchors if the weights of difficult anchors are too large. In addition, we do not offer special treatment for empty anchors, which also have a strong confounding effect. Assigning too much weight to non-empty anchors may make it complex for the network to classify such anchors correctly.
To explore the impact of the anchor weights on network performance, we conducted ablation experiments with the following settings: in Equation (3) was set to the constant 1.0. Thus, the relative size of the weights of anchors with inaccurate semantic information can be adjusted by changing .
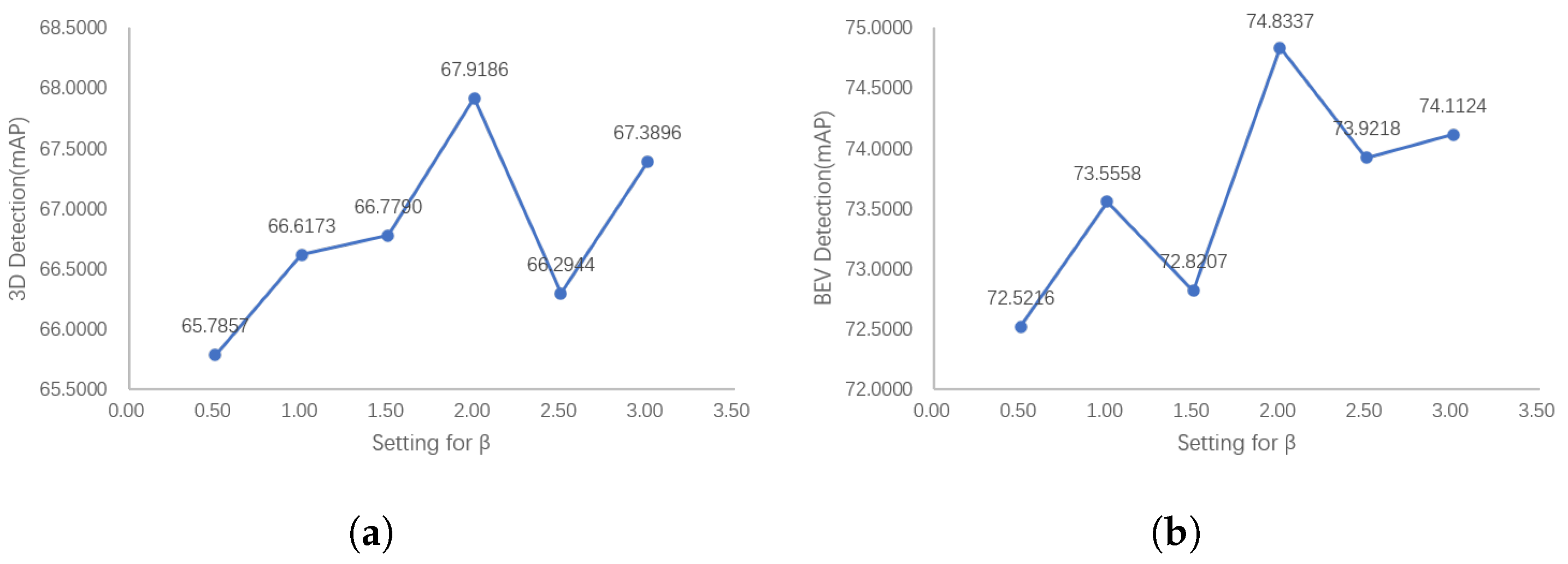
Figure 12 shows the results of our ablation experiments. Figure 12 indicates that the detection results of 3D and BEV show a similar trend; that is, with the increase in , the detector performance reaches a peak value, and then decreases with the increase in . This is because when is small, assigning larger weights to difficult anchors with inaccurate semantic information can cause the network to pay more attention to difficult anchors, but when is too large, this is counterproductive for the reasons mentioned above.
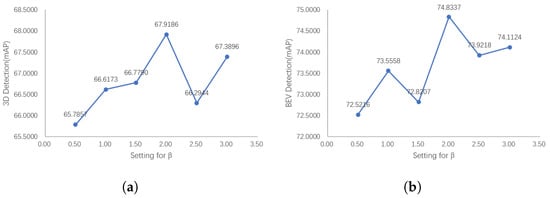
Figure 12.
The 3D and BEV detection results of our PointPainting++ with the relative weight coefficient . The detection performance first reaches the peak with the increase in , and then shows a downward trend. If weights are too large, the detector will focus too much on the difficult samples, while weights that are too small will not emphasize the difficult samples. (a) 3D detection results with (b) BEV Detection results with .
6.2. The Influence of Semantic Weight in SegIoU
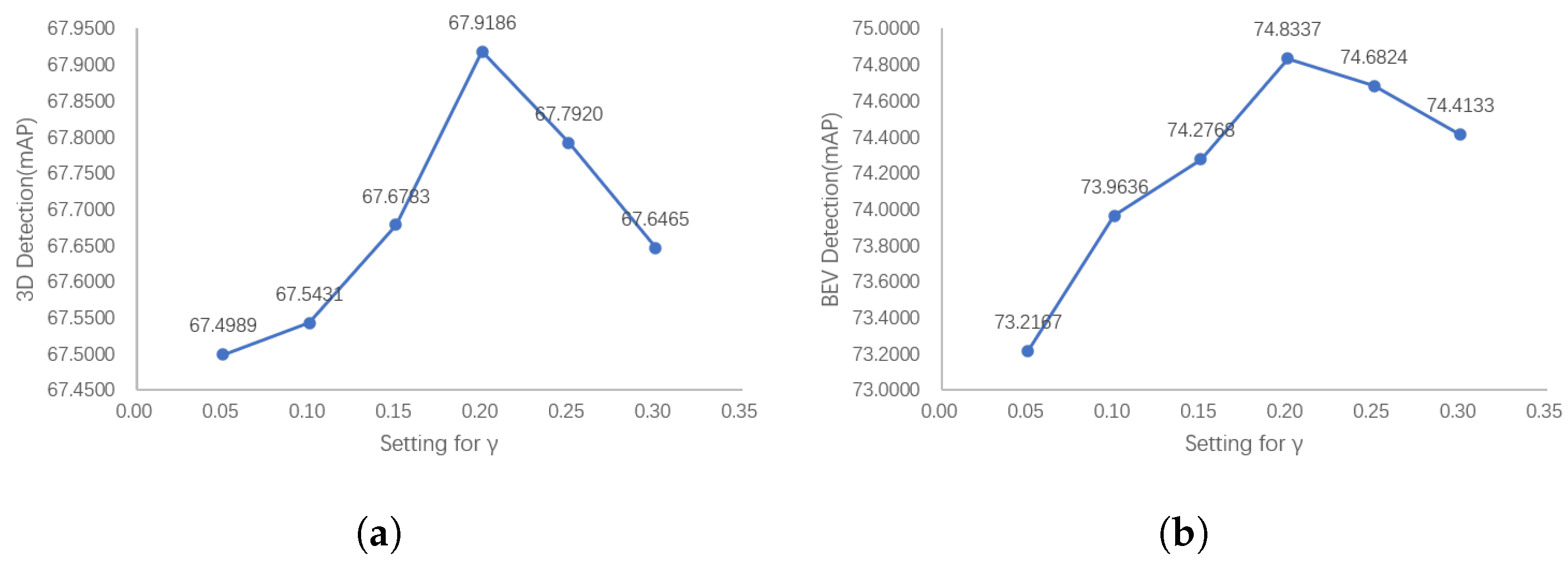
Our PointPainting++ further measures the degree of overlap between anchors and ground-truth boxes by adding semantic loss to the IoU and sifting out inferior positive anchors that contain only a few target LiDAR points. Therefore, it is particularly important to control the relative size of the loss of semantic information. On the one hand, it will be unable to filter out the inferior positive anchors if the semantic loss term is too small. On the other hand, if the semantic loss term is too large, there will be too few positive anchors, reducing the performance of the network. We tuned the relative size of the semantic loss term in SegIoU by changing the hyperparameter in Equation (10).
Figure 13 shows that the performance of the detector first shows an upward trend with the increase in the semantic loss weight in SegIoU, and then shows a downward trend after reaching the peak. This is consistent with the previously mentioned reasons, and also shows that the choice of an appropriate semantic loss size in the actual training process plays an important role in improving the detector performance.
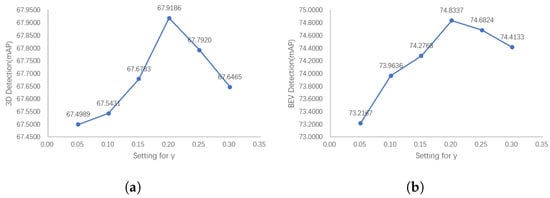
Figure 13.
The 3D and BEV detection results of our PointPainting++ with the semantic loss coefficient . The detector performance shows a trend of increasing and then decreasing as the semantic loss items increase. If the semantic loss terms are too large, there will be too few positive anchors, while semantic loss terms that are too small will not filter inferior positive anchors using semantic information. (a) 3D Detection results with (b) BEV detection results with .
6.3. The Influence of the Number of Positive Anchors
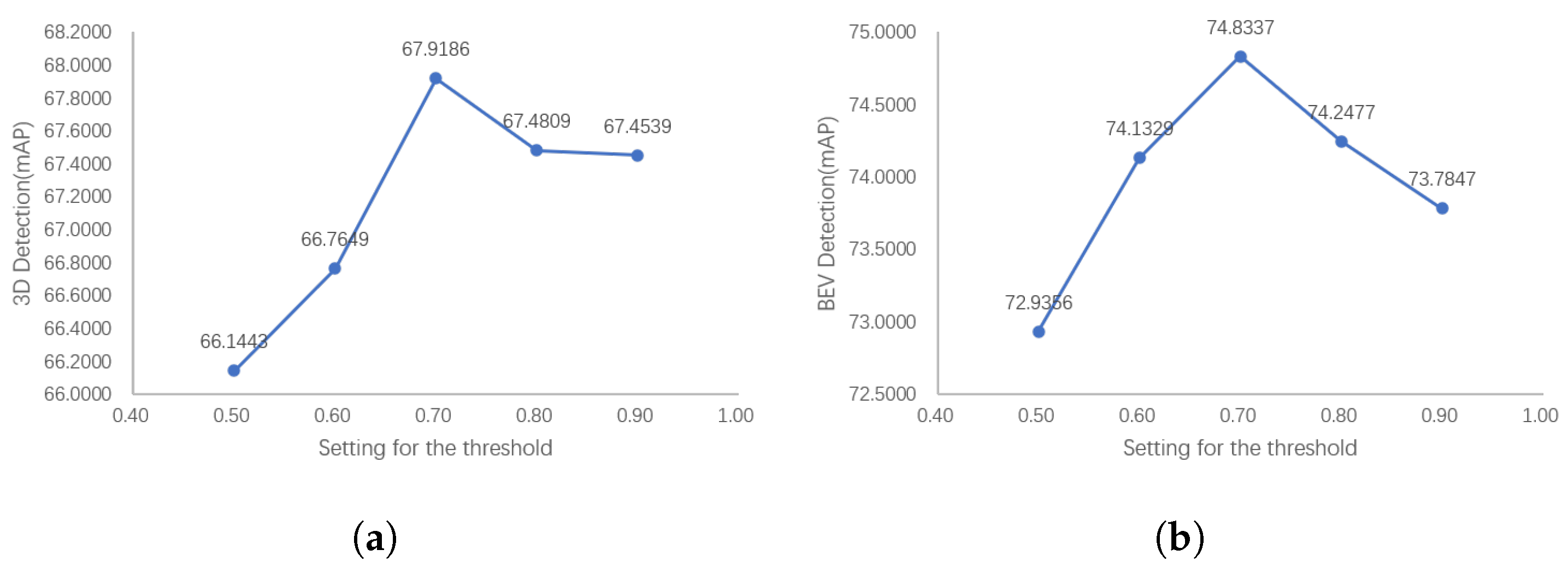
It is difficult to intuitively quantify the impact of the semantic loss term in the process of using SegIoU to filter out positive anchors, which often results in over-screening and a decrease in the detector performance. A moderate threshold is needed to limit the minimum number of positive anchors. On the one hand, the over-screening problem cannot be solved if the threshold is too small. On the other hand, the desired purpose of screening out inferior positive anchors will not be achieved if the threshold is too large. We changed this threshold and conducted ablation experiments to explore the effect of this threshold setting on the detector performance.
Figure 14 shows the results of our ablation experiments. The detection results show that the performance of the detector first shows an upward trend with the increase in threshold, and starts to decline after reaching the peak. This is consistent with our previous analysis, indicating that the selection of too large or small a threshold will affect the effectiveness of SegIoU and lead to performance degradation.
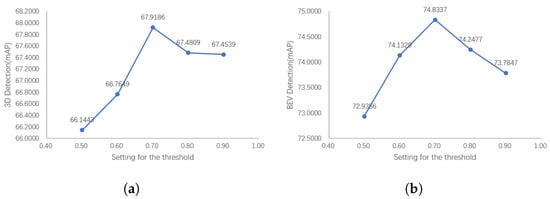
Figure 14.
The 3D and BEV detection results of our PointPainting++ with the number of positive anchors. The detection performance peaks after an appropriate number of positive anchors is selected. The excessive retention of the max-IoU assigner-based results may fail to remove inferior positive anchors, while having too few positive anchors will make it difficult for the detector to learn target features. (a) 3D detection results with the number of positive anchors. (b) BEV detection with the number of positive anchors.
7. Conclusions
In this paper, we propose a new 3D object-detection method based on PointPainting [8]. Three improvements were proposed to address the shortcomings of PointPainting [8]. Firstly, we proposed a weighting strategy for the loss function according to the accuracy of the semantic information, aiming to solve the problem of the point cloud containing inaccurate semantic information. Secondly, a dual-attention module was used to weigh the voxelized point cloud in the channel and point dimensions. Thirdly, we proposed a SegIoU-based anchor-assigner to filter these anchors, which effectively removes inferior positive anchors containing few target points. The experimental results show that our PointPainting++ shows significant performance improvements compared with PointPainting [8] in different network structures and various scenarios. Compared with PointPainting [8], our PointPainting++ does not introduce additional computation in the inference phase and adds very few parameters in the training phase, which means that the training time of the existing network is smaller.In summary, our PointPainting++ can improve the problems in PointPainting [8], and has a certain practical value.
Author Contributions
Conceptualization, Z.G. and Q.W.; methodology, Z.G. and Q.W.; software, Z.G.; validation, Z.G., Z.P., and Q.W.; formal analysis, Z.G. and H.L.; investigation, Z.G. and Q.W.; resources, Z.P.; writing—original draft preparation, Z.G.; writing—review and editing, Q.W. and Z.P.; visualization, Z.G. and Z.Z.; supervision, Z.P. and H.L.; project administration, Z.P.; funding acquisition, Z.P. All authors have read and agreed to the published version of the manuscript.
Funding
This study was supported by the Youth Innovation Promotion Association, CAS.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Restrictions apply to the availability of these data. KITTI is a project of Karlsruhe Institute of Technology and Toyota Technological Institute at Chicago. It is available at https://www.cvlibs.net/datasets/kitti/ (accessed on 25 February 2023) with the permission.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Yoo, J.H.; Kim, Y.; Kim, J.; Choi, J.W. 3d-cvf: Generating joint camera and LiDAR features using cross-view spatial feature fusion for 3d object detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 720–736. [Google Scholar]
- Xie, L.; Xiang, C.; Yu, Z.; Xu, G.; Yang, Z.; Cai, D.; He, X. PI-RCNN: An efficient multi-sensor 3D object detector with point-based attentive cont-conv fusion module. In Proceedings of the AAAI conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12460–12467. [Google Scholar]
- Huang, T.; Liu, Z.; Chen, X.; Bai, X. Epnet: Enhancing point features with image semantics for 3d object detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 35–52. [Google Scholar]
- Pang, S.; Morris, D.; Radha, H. CLOCs: Camera-LiDAR object candidates fusion for 3D object detection. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24–29 October 2020; pp. 10386–10393. [Google Scholar]
- Zheng, W.; Tang, W.; Jiang, L.; Fu, C.W. SE-SSD: Self-ensembling single-stage object detector from point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14494–14503. [Google Scholar]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. Pv-rcnn: Point-voxel feature set abstraction for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10529–10538. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Vora, S.; Lang, A.H.; Helou, B.; Beijbom, O. Pointpainting: Sequential fusion for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 4604–4612. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum pointnets for 3d object detection from rgb-d data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 918–927. [Google Scholar]
- Wang, Z.; Jia, K. Frustum convnet: Sliding frustums to aggregate local point-wise features for amodal 3d object detection. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 1742–1749. [Google Scholar]
- Shin, K.; Kwon, Y.P.; Tomizuka, M. Roarnet: A robust 3d object detection based on region approximation refinement. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 2510–2515. [Google Scholar]
- Paigwar, A.; Sierra-Gonzalez, D.; Erkent, Ö.; Laugier, C. Frustum-pointpillars: A multi-stage approach for 3d object detection using rgb camera and lidar. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 2926–2933. [Google Scholar]
- Du, X.; Ang, M.H.; Karaman, S.; Rus, D. A general pipeline for 3d detection of vehicles. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 3194–3200. [Google Scholar]
- Xu, S.; Zhou, D.; Fang, J.; Yin, J.; Bin, Z.; Zhang, L. Fusionpainting: Multimodal fusion with adaptive attention for 3d object detection. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; pp. 3047–3054. [Google Scholar]
- Simon, M.; Amende, K.; Kraus, A.; Honer, J.; Samann, T.; Kaulbersch, H.; Milz, S.; Michael Gross, H. Complexer-yolo: Real-time 3d object detection and tracking on semantic point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Yin, T.; Zhou, X.; Krähenbühl, P. Multimodal virtual point 3d detection. Adv. Neural Inf. Process. Syst. 2021, 34, 16494–16507. [Google Scholar]
- Mao, J.; Shi, S.; Wang, X.; Li, H. 3D object detection for autonomous driving: A review and new outlooks. arXiv 2022, arXiv:2206.09474. [Google Scholar]
- Liang, M.; Yang, B.; Chen, Y.; Hu, R.; Urtasun, R. Multi-task multi-sensor fusion for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7345–7353. [Google Scholar]
- Sindagi, V.A.; Zhou, Y.; Tuzel, O. MVX-Net: Multimodal VoxelNet for 3D Object Detection. In Proceedings of the International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019. [Google Scholar]
- Li, Y.; Yu, A.W.; Meng, T.; Caine, B.; Ngiam, J.; Peng, D.; Shen, J.; Lu, Y.; Zhou, D.; Le, Q.V.; et al. Deepfusion: Lidar-camera deep fusion for multi-modal 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17182–17191. [Google Scholar]
- Zhang, Y.; Chen, J.; Huang, D. Cat-det: Contrastively augmented transformer for multi-modal 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 908–917. [Google Scholar]
- Chen, X.; Zhang, T.; Wang, Y.; Wang, Y.; Zhao, H. Futr3d: A unified sensor fusion framework for 3d detection. arXiv 2022, arXiv:2203.10642. [Google Scholar]
- Liu, Z.; Tang, H.; Amini, A.; Yang, X.; Mao, H.; Rus, D.; Han, S. BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation. arXiv 2022, arXiv:2205.13542. [Google Scholar]
- Li, Y.; Qi, X.; Chen, Y.; Wang, L.; Li, Z.; Sun, J.; Jia, J. Voxel field fusion for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1120–1129. [Google Scholar]
- Bai, X.; Hu, Z.; Zhu, X.; Huang, Q.; Chen, Y.; Fu, H.; Tai, C.L. Transfusion: Robust lidar-camera fusion for 3d object detection with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1090–1099. [Google Scholar]
- Wang, C.; Ma, C.; Zhu, M.; Yang, X. Pointaugmenting: Cross-modal augmentation for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11794–11803. [Google Scholar]
- Xu, D.; Anguelov, D.; Jain, A. Pointfusion: Deep sensor fusion for 3d bounding box estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 244–253. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3d object detection network for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1907–1915. [Google Scholar]
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, S.L. Joint 3d proposal generation and object detection from view aggregation. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–8. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Pang, S.; Morris, D.; Radha, H. Fast-CLOCs: Fast camera-LiDAR object candidates fusion for 3D object detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 187–196. [Google Scholar]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12697–12705. [Google Scholar]
- Yin, T.; Zhou, X.; Krahenbuhl, P. Center-based 3d object detection and tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11784–11793. [Google Scholar]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 17–24 May 2018; pp. 801–818. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. Second: Sparsely embedded convolutional detection. Sensors 2018, 18, 3337. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).