
Overview of Spiking Neural Network Learning Approaches and Their Computational Complexities

Abstract
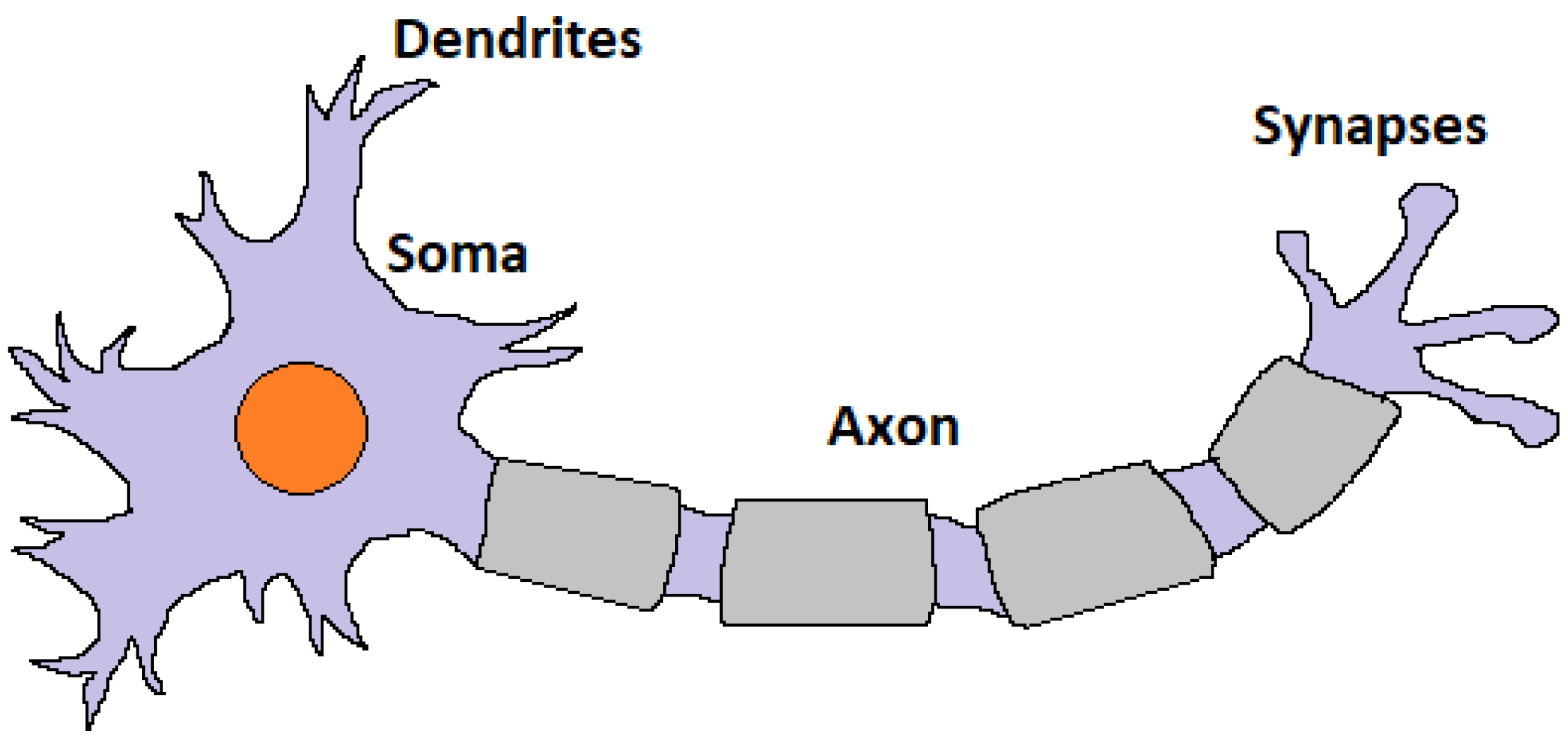
:1. Introduction
- IBM TrueNorth,
- Intel Loihi,
- Tianjic,
- SpiNNaker,
- BrainScaleS,
- NeuronFlow,
- DYNAP, and
- Akida.
- CPUs
- GPUs
- TPUs (Tensor Processing Units)
- FPGAs (Field Programmable Gate Arrays)
- VPUs (Vision Processing Units)
2. Spiking Neural Networks Fundamentals
2.1. Neuron Models
2.1.1. Integrate and Fire
2.1.2. Leaky Integrate and Fire
2.1.3. Izhikevich
2.1.4. Hodgkin–Huxley
2.2. Synapse Models
2.2.1. Current-Based Synapse Model
2.2.2. Conductance-Based Synapse Model
2.3. Encoding Types
2.3.1. Rate Encoding
2.3.2. Temporal Encoding
3. Types of Learning Approaches
3.1. STDP
3.2. Backpropagation
- (1)
- Membrane time constant is optimized during training and isn’t set as a hyperparameter.
- (2)
- Membrane time constant is shared within all neurons in the same layer.
- (3)
- Membrane time constants are distinct across all layers.
3.3. ANN–SNN Conversion
3.4. Comparison of Benchmarking Results
4. Computational Complexity Analysis
4.1. STDP
4.2. Backpropagation
4.3. ANN-SNN Conversion
4.4. Computational Complexity Comparison
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Variable Names
| C | number of classess | Equation (22) |
| membrane capacitance | Equations (1) and (2) | |
| V, v | previous membrane potential | Equations (1)–(5) and (7) |
| neuron’s potential after firing | Equation (27) | |
| u | recovery variable | Equations (3)–(5) |
| I | total current from synapses | Equations (1)–(3) and (9) |
| leak conductance | Equations (1) and (2) | |
| g | synapse conductance | Equations (8)–(10) and (17) |
| potassium reversal potentials | Equation (6) | |
| leak reversal potential | Equations (1), (2) and (6) | |
| sodium reversal potentials | Equation (6) | |
| equilibrium synapse potential | Equation (9) | |
| a, b, c, d | constants | Equations (3)–(5) |
| total current through the membrane | Equations (6) and (7) | |
| synaptic input current | Equation (7) | |
| potassium conductances per unit area | Equation (6) | |
| sodium conductances per unit area | Equation (6) | |
| leak conductance per unit area | Equation (6) | |
| m, h, n | constants | Equation (6) |
| n | number of output spikes | Equation (17) |
| membrane potential | Equations (6) and (16) | |
| spike voltage level | Equations (8) and (9) | |
| time constant of an excitatory postsynaptic potential | Equation (10) | |
| learning window | Equations (11) and (12) | |
| scaling factors for potentiation and depression | Equations (11) and (12) | |
| presynaptic and postsynaptic spike times | Equations (11) and (12) | |
| time constants of synapse potentiation and depression | Equations (11) and (12) | |
| potentiation and depression learning rates | Equation (13) | |
| w | weight value | Equation (13) |
| W | weight matrix | Equation (25) and (27) |
| E | mean squares error | Equations (14) and (17) |
| actual spike time | Equations (14) and (17) | |
| desired spike time | Equation (14) | |
| L | loss function | Equations (15), (20) and (22) |
| normalised smooth temporal convolution kernel | Equation (15) | |
| s | output spike train | Equation (15) |
| target spike train | Equation (15) | |
| sigmoid function | Equations (16), (23) and (24) | |
| T | expected firing time | Equations (17) and (22) |
| average firing time | Equation (17) | |
| spike response kernel | Equations (19) and (21) | |
| constant | Equation (19) | |
| o | output tensor | Equation (22) |
| output of layers | Equation (25) | |
| h | ReLU activation function | Equations (25) and (26) |
| avarage postsynaptic potential | Equation (27) |
Abbreviations
| ANN | Artificial Neural Network |
| BPTT | Back Propagation Through Time |
| CNN | Convolutional Neural Network |
| CPU | Central Processing Unit |
| DVS | Dynamic Vision Sensors |
| FPGA | Field Programmable Gate Arrays |
| GPU | Graphics Processing Unit |
| IF | Integrate and Fire |
| LIF | Leaky Integrate and Fire |
| NEF | Neural Engineering Framework |
| ReLU | Rectified Linear Unit |
| R-STDP | Reward Modulated Spike Timing Dependent Plasticity |
| SLAM | Simultaneous Localization and Mapping |
| SNN | Spiking Neural Network |
| SSTDP | Supervised Spike Timing Dependent Plasticity |
| STDP | Spike Timing-Dependent-Plasticity |
| TPU | Tensor Processing Unit |
| VPU | Vision Processing Units |
| VRAM | Video Random Access Memory |
| WTA | Winner Takes All |
References
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention (MICCAI); LNCS; Springer: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NJ, USA, 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Ha, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images. Available online: https://www.cs.toronto.edu/kriz/learning-features-2009-TR.pdf (accessed on 6 February 2023).
- Zhou, S.; Chen, Y.; Li, X.; Sanyal, A. Deep SCNN-Based Real-Time Object Detection for Self-Driving Vehicles Using LiDAR Temporal Data. IEEE Access 2020, 8, 76903–76912. [Google Scholar] [CrossRef]
- Patel, K.; Hunsberger, E.; Batir, S.; Eliasmith, C. A Spiking Neural Network for Image Segmentation. arXiv 2021, arXiv:2106.08921v1. [Google Scholar]
- Shalumov, A.; Halaly, R.; Tsur, E.E. LiDAR-driven spiking neural network for collision avoidance in autonomous driving. Bioinspiration Biomimetics 2021, 16, ac290c. [Google Scholar] [CrossRef] [PubMed]
- Baby, S.A.; Vinod, B.; Chinni, C.; Mitra, K. Dynamic vision sensors for human activity recognition. In Proceedings of the 2017 4th IAPR Asian Conference on Pattern Recognition (ACPR), Nanjing, China, 26–29 November 2017; IEEE: Nanjing, China, 2017; pp. 316–321. [Google Scholar]
- Orchard, G.; Jayawant, A.; Cohen, G.K.; Thakor, N. Converting Static Image Datasets to Spiking Neuromorphic Datasets Using Saccades. Front. Neurosci. 2015, 9, 437. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, H.; Liu, H.; Ji, X.; Li, G.; Shi, L. CIFAR10-DVS: An Event-Stream Dataset for Object Classification. Front. Neurosci. 2017, 11, 309. [Google Scholar] [CrossRef]
- Han, B.; Roy, K. Deep spiking neural network: Energy efficiency through time based coding. In Computer Vision—ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2020; Volume 12355. [Google Scholar]
- Makarov, V.A.; Lobov, S.A.; Shchanikov, S.; Mikhaylov, A.; Kazantsev, V.B. Toward Reflective Spiking Neural Networks Exploiting Memristive Devices. Front. Comput. Neurosci. 2022, 16, 859874. [Google Scholar] [CrossRef]
- Lobov, S.A.; Zharinov, A.I.; Makarov, V.A.; Kazantsev, V.B. Spatial Memory in a Spiking Neural Network with Robot Embodiment. Sensors 2021, 21, 2678. [Google Scholar] [CrossRef]
- Mo, L.; Wang, G.; Long, E.; Zhuo, M. ALSA: Associative Learning Based Supervised Learning Algorithm for SNN. Front. Neurosci. 2022, 16, 838832. [Google Scholar] [CrossRef]
- Tang, G.; Shah, A.; Michmizos, K.P. Spiking Neural Network on Neuromorphic Hardware for Energy-Efficient Unidimensional SLAM. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 4–8 November 2019; pp. 4176–4181. [Google Scholar]
- Juarez-Lora, A.; Ponce-Ponce, V.H.; Sossa, H.; Rubio-Espino, E. R-STDP Spiking Neural Network Architecture for Motion Control on a Changing Friction Joint Robotic Arm. Front. Neurorobot. 2022, 16, 904017. [Google Scholar] [CrossRef] [PubMed]
- Sandamirskaya, Y.; Kaboli, M.; Conradt, J.; Celikel, T. Neuromorphic computing hardware and neural architectures for robotics. Sci. Robot. 2022, 7, eabl8419. [Google Scholar] [CrossRef] [PubMed]
- DeWolf, T. Spiking neural networks take control. Sci. Robot. 2021, 6, eabk3268. [Google Scholar] [CrossRef]
- Furber, S.; Yan, Y.; Stewart, T.; Choo, X.; Vogginger, B.; Partzsch, J.; Hoeppner, S.; Kelber, F.; Eliasmith, C.; Mayr, C. Comparing Loihi with a SpiNNaker 2 prototype on low-latency keyword spotting and adaptive robotic control. Neuromorphic Comput. Eng. 2021, 1, 014002. [Google Scholar]
- DeWolf, T.; Stewart, T.C.; Slotine, J.J.; Eliasmith, C. A spiking neural model of adaptive arm control. Proc. Biol Sci. 2016, 283, 20162134. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Falanga, D.; Kleber, K.; Scaramuzza, D. Dynamic obstacle avoidance for quadrotors with event cameras. Sci. Robot. 2020, 5, eaaz9712. [Google Scholar] [CrossRef]
- DeWolf, T.; Jaworski, P.; Eliasmith, C. Nengo and Low-Power AI Hardware for Robust, Embedded Neurorobotics. Front. Neurorobot. 2020, 14, 568359. [Google Scholar] [CrossRef]
- Ivanov, D.; Chezhegov, A.; Grunin, A.; Kiselev, M.; Larionov, D. Neuromorphic Artificial Intelligence Systems. arXiv 2022, arXiv:2205.13037v1. [Google Scholar] [CrossRef]
- Quian Quiroga, R.; Kreiman, G. Measuring Sparseness in the Brain: Comment on Bowers (2009). Psychol. Rev. 2010, 117, 291–297. [Google Scholar] [CrossRef]
- Diehl, P.U.; Cook, M. Unsupervised Learning of Digit Recognition Using Spike-Timing-Dependent Plasticity. Front. Comput. Neurosci. 2015, 9, 99. [Google Scholar] [CrossRef] [Green Version]
- Rumelhart, D.; Hinton, G.; Williams, R. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Eliasmith, C.; Anderson, C.H. Neural Engineering: Computation, Representation, and Dynamics in Neurobiological Systems; MIT Press: Cambridge, MA, USA, 2003. [Google Scholar]
- Tsur, E.E. Neuromorphic Engineering: The Scientist’s, Algorithm Designer’s, and Computer Architect’s Perspectives on Brain-Inspired Computing; CRC Press: Boca Raton, FL, USA, 2021. [Google Scholar]
- Voelker, A.R.; Eliasmith, C. Programming neuromorphics using the neural engineering framework. In Handbook of Neuroengineering; Springer: Cham, Switzerland, 2020; pp. 1–43. [Google Scholar]
- Akopyan, F.; Sawada, J.; Cassidy, A.; Alvarez-Icaza, R.; Arthur, J.; Merolla, P.; Imam, N.; Nakamura, Y.; Datta, P.; Nam, G.-J.; et al. TrueNorth: Design and Tool Flow of a 65 MW 1 Million Neuron Programmable Neurosynaptic Chip. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2015, 34, 1537–1557. [Google Scholar] [CrossRef]
- Davies, M.; Srinivasa, N.; Lin, T.-H.; Chinya, G.; Cao, Y.; Choday, S.H.; Dimou, G.; Joshi, P.; Imam, N.; Jain, S.; et al. Loihi: A Neuromorphic Manycore Processor with On-Chip Learning. IEEE Micro 2018, 38, 82–99. [Google Scholar] [CrossRef]
- Höppner, S.; Yan, Y.; Dixius, A.; Scholze, S.; Partzsch, J.; Stolba, M.; Kelber, F.; Vogginger, B.; Neumärker, F.; Ellguth, G.; et al. The SpiNNaker 2 Processing Element Architecture for Hybrid Digital Neuromorphic Computing. arXiv 2022, arXiv:2103.08392. [Google Scholar]
- Moreira, O.; Yousefzadeh, A.; Chersi, F.; Kapoor, A.; Zwartenkot, R.-J.; Qiao, P.; Cinserin, G.; Khoei, M.A.; Lindwer, M.; Tapson, J. NeuronFlow: A Hybrid Neuromorphic—Dataflow Processor Architecture for AI Workloads. In Proceedings of the 2020 2nd IEEE International Conference on Artificial Intelligence Circuits and Systems (AICAS), Genova, Italy, 31 August–2 September 2020; IEEE: Genova, Italy, 2020; pp. 1–5. [Google Scholar]
- Yamazaki, K.; Vo-Ho, V.-K.; Bulsara, D.; Le, N. Spiking Neural Networks and Their Applications: A Review. Brain Sci. 2022, 12, 863. [Google Scholar] [CrossRef]
- Szczęsny, S.; Huderek, D.; Przyborowski, Ł. Spiking Neural Network with Linear Computational Complexity for Waveform Analysis in Amperometry. Sensors 2021, 21, 3276. [Google Scholar] [CrossRef]
- Szczęsny, S.; Kropidłowski, M.; Naumowicz, M. 0.50-V ultra-low-power ΣΔ modulator for sub-nA signal sensing in amperometry. IEEE Sens. J. 2020, 20, 5733–5740. [Google Scholar] [CrossRef]
- Szczęsny, S.; Huderek, D.; Przyborowski, Ł. Explainable spiking neural network for real time feature classification. J. Exp. Theor. Artif. Intell. 2023, 35, 77–92. [Google Scholar] [CrossRef]
- Van Pottelbergh, T.; Drion, G.; Sepulchre, R. Robust Modulation of Integrate-and-Fire Models. Neural Comput. 2018, 30, 987–1011. [Google Scholar] [CrossRef] [Green Version]
- Dutta, S.; Kumar, V.; Shukla, A.; Mohapatra, N.R.; Ganguly, U. Leaky Integrate and Fire Neuron by Charge-Discharge Dynamics in Floating-Body MOSFET. Sci. Rep. 2017, 7, 8257. [Google Scholar] [CrossRef] [Green Version]
- Izhikevich, E.M. Simple Model of Spiking Neurons. IEEE Trans. Neural Netw. 2003, 14, 1569–1572. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, F.; Zhao, W.; Chen, Y.; Wang, Z.; Yang, T.; Jiang, L. SSTDP: Supervised Spike Timing Dependent Plasticity for Efficient Spiking Neural Network Training. Front. Neurosci. 2021, 15, 756876. [Google Scholar] [CrossRef] [PubMed]
- Sengupta, A.; Ye, Y.; Wang, R.; Liu, C.; Roy, K. Going Deeper in Spiking Neural Networks: VGG and Residual Architectures. Front. Neurosci. 2019, 13, 95. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pfeiffer, M.; Pfeil, T. Deep Learning With Spiking Neurons: Opportunities and Challenges. Front. Neurosci. 2018, 12, 774. [Google Scholar] [CrossRef] [Green Version]
- Markram, H.; Gerstner, W.; Sjöström, P.J. Spike-Timing-Dependent Plasticity: A Comprehensive Overview. Front. Synaptic Neurosci. 2012, 4, 2. [Google Scholar] [CrossRef] [Green Version]
- Song, S.; Miller, K.; Abbott, L. Competitive Hebbian learning through spike-timing-dependent synaptic plasticity. Nat. Neurosci. 2000, 3, 919–926. [Google Scholar] [CrossRef]
- Izhikevich, E. Solving the Distal Reward Problem through Linkage of STDP and Dopamine Signaling. Cereb. Cortex 2007, 17, 2443–2452. [Google Scholar] [CrossRef] [Green Version]
- Burbank, K.S. Mirrored STDP Implements Autoencoder Learning in a Network of Spiking Neurons. PLoS Comput. Biol. 2015, 11, e1004566. [Google Scholar] [CrossRef] [Green Version]
- Masquelier, T.; Thorpe, S.J. Unsupervised Learning of Visual Features through Spike Timing Dependent Plasticity. PLoS Comput. Biol. 2007, 3, e31. [Google Scholar] [CrossRef] [Green Version]
- Vigneron, A.; Martinet, J. A Critical Survey of STDP in Spiking Neural Networks for Pattern Recognition. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; IEEE: Glasgow, UK, 2020; pp. 1–9. [Google Scholar]
- Zhong, X.; Pan, H. A Spike Neural Network Model for Lateral Suppression of Spike-Timing-Dependent Plasticity with Adaptive Threshold. Appl. Sci. 2022, 12, 5980. [Google Scholar] [CrossRef]
- Yousefzadeh, A.; Stromatias, E.; Soto, M.; Serrano-Gotarredona, T.; Linares-Barranco, B. On Practical Issues for Stochastic STDP Hardware With 1-Bit Synaptic Weights. Front. Neurosci. 2018, 12, 665. [Google Scholar] [CrossRef] [Green Version]
- Bohte, S.; Kok, J.; Poutré, J. SpikeProp: Backpropagation for Networks of Spiking Neurons. In Proceedings of the 8th European Symposium on Artificial Neural Networks, ESANN 2000, Bruges, Belgium, 26–28 April 2000; Volume 48, pp. 419–424. [Google Scholar]
- Zenke, F.; Ganguli, S. SuperSpike: Supervised Learning in Multi-Layer Spiking Neural Networks. Neural Comput. 2018, 30, 1514–1541. [Google Scholar] [CrossRef] [PubMed]
- O’Connor, P.; Welling, M. Deep Spiking Networks. arXiv 2016, arXiv:1602.08323. [Google Scholar]
- Shrestha, S.B.; Orchard, G. SLAYER: Spike Layer Error Reassignment in Time. In Advances in Neural Information Processing Systems; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; Volume 31. [Google Scholar]
- Fang, W.; Yu, Z.; Chen, Y.; Masquelier, T.; Huang, T.; Tian, Y. Incorporating Learnable Membrane Time Constant to Enhance Learning of Spiking Neural Networks. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; IEEE: Montreal, QC, Canada, 2021; pp. 2641–2651. [Google Scholar]
- Esser, S.K.; Appuswamy, R.; Merolla, P.; Arthur, J.V.; Modha, D.S. Backpropagation for Energy-Efficient Neuromorphic Computing; NIPS: Montreal, QC, Canada, 2015; pp. 1117–1125. [Google Scholar]
- Diehl, P.U.; Zarrella, G.; Cassidy, A.; Pedroni, B.U.; Neftci, E. Conversion of Artificial Recurrent Neural Networks to Spiking Neural Networks for Low-Power Neuromorphic Hardware. In Proceedings of the 2016 IEEE International Conference on Rebooting Computing (ICRC), San Diego, CA, USA, 17–19 October 2016; pp. 1–8. [Google Scholar]
- Stöckl, C.; Maass, W. Recognizing Images with at Most One Spike per Neuron. arXiv 2020, arXiv:2001.01682. [Google Scholar]
- Bu, T.; Fang, W.; Ding, J.; Dai, P.; Yu, Z.; Huang, T. Optimal Ann-Snn Conversion for High- Accuracy and Ultra-Low-Latency Spiking Neural Networks; ICLR: Vienna, Austria, 2022. [Google Scholar]
- Cao, Y.; Chen, Y.; Khosla, D. Spiking deep convolutional neural networks for energy-efficient object recognition. Int. J. Comput. Vis. 2015, 113, 54–66. [Google Scholar] [CrossRef]
- Rueckauer, B.; Lungu, I.-A.; Hu, Y.; Pfeiffer, M.; Liu, S.-C. Conversion of Continuous-Valued Deep Networks to Efficient Event-Driven Networks for Image Classification. Front. Neurosci. 2017, 11, 682. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mozafari, M.; Ganjtabesh, M.; Nowzari-Dalini, A.; Thorpe, S.J.; Masquelier, T. Bio-Inspired Digit Recognition Using Reward-Modulated Spike-Timing-Dependent Plasticity in Deep Convolutional Networks. Pattern Recognit. 2019, 94, 87–95. [Google Scholar] [CrossRef] [Green Version]
- Han, B.; Srinivasan, G.; Roy, K. RMP-SNN: Residual Membrane Potential Neuron for Enabling Deeper High-Accuracy and Low-Latency Spiking Neural Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13558–13567. [Google Scholar]
- Baydin, A.; Pearlmutter, B.; Radul, A.; Siskind, J. Automatic Differentiation in Machine Learning: A Survey. J. Mach. Learn. Res. 2018, 18, 43. [Google Scholar]
- Werbos, P.J. Backpropagation through time: What it does and how to do it. Proc. IEEE 1990, 78, 1550–1560. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MNiST | CIFAR-10 | |
|---|---|---|
| STDP | 97.20% [64] | - |
| Backpropagation | 99.72% [57] | 93.50% [57] |
| ANN-SNN conversion | 99.44% [57] | 93.63% [65] |
| Online STDP | Backpropagation | ANN-SNN Conversion | |
|---|---|---|---|
| SNN forward pass | √ | √ | - |
| ANN forwads pass | - | - | √ |
| trace-based weight update | √ | - | - |
| Backpropagation | - | √ | √ |
| param calculation | - | - | √ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pietrzak, P.; Szczęsny, S.; Huderek, D.; Przyborowski, Ł. Overview of Spiking Neural Network Learning Approaches and Their Computational Complexities. Sensors 2023, 23, 3037. https://doi.org/10.3390/s23063037
Pietrzak P, Szczęsny S, Huderek D, Przyborowski Ł. Overview of Spiking Neural Network Learning Approaches and Their Computational Complexities. Sensors. 2023; 23(6):3037. https://doi.org/10.3390/s23063037
Chicago/Turabian StylePietrzak, Paweł, Szymon Szczęsny, Damian Huderek, and Łukasz Przyborowski. 2023. "Overview of Spiking Neural Network Learning Approaches and Their Computational Complexities" Sensors 23, no. 6: 3037. https://doi.org/10.3390/s23063037