
Working Mode Recognition of Non-Specific Radar Based on ResNet-SVM Learning Framework


Abstract
:1. Introduction
- A machine learning method, with radar knowledge embedded, is proposed. The framework creatively applies the radar principles to the dataset, and extracts the radar functional indicators from it, of which the input vector of classifier consists, along with pulse sequences and modulation types, and its feature vector is degraded by the histogram method. Because of the correlation between signal features, MSJR is more beneficial to extract features include the distribution features of data, making the model more extensible and able to identify unknown signals that meet this feature.
- We propose an MSJR learning framework, based on deep residual network and a support vector machine, for non-specific radar behavior pattern recognition. As an alternative to a single neural network or classifier, the framework optimizes two subnetworks, through model cascades, aiming at pattern recognition accuracy. This framework can better utilize the powerful data expression ability of deep learning, and make use of the classification ability of SVM. Moreover, it is more conducive to identifying patterns in complex environments with serious parameter overlap. Training the MSJR learning framework, can extract the information contained in the signal more efficiently than a single algorithm.
- The radar operating mode dataset is proposed, with reference to the actual radar, and the proposed method is evaluated on the four types of radar operating datasets commonly used by MFR, with its range and working mode covering most of the information displayed in the public. It also covers modes like target detection, ranging, tracking, speed detection, along with seven inter-pulse modulation types, e.g., constant, jitter, dwell and switch, stagger, slip, wobbulated, and hybrid modulation. In addition, a certain amount of noise, and 0–50% leaky pulses, are added in some cases, which brings more challenges to classification. The experimental results show that the proposed model can achieve more than 90% recognition accuracy under the condition of 10% measurement error and 35% leaky pulse, which is impossible to achieve with previous methods.
2. Related Work
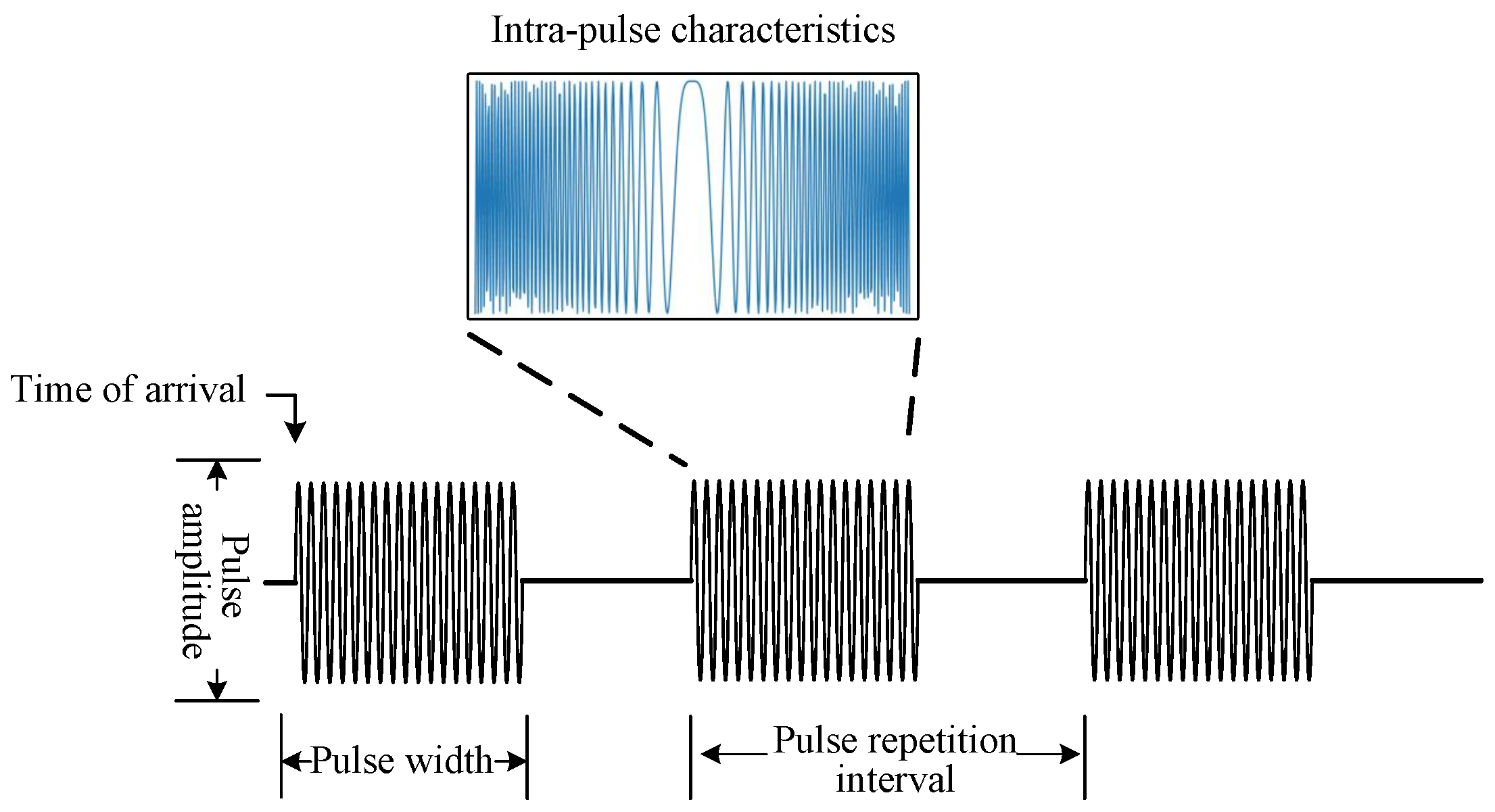
3. Problem Formulation
3.1. Radar Behavior Mode
3.1.1. Velocity Search (VS)
3.1.2. Range while Search (RWS)
3.1.3. Single Target Tracking (STT)
3.1.4. Trace and Search (TAS)
3.2. Pulse Modulation Mode
3.2.1. Constant
3.2.2. Stagger
3.2.3. Jitter
3.2.4. Dwell and Switch
3.2.5. Sliding
3.2.6. Wobbulated
3.3. Hierarchical Radar Pattern Recognition Task
4. Proposed MSJR Learning Framework
4.1. Residual Neural Network for Modulation Recognition
- The number of pulses in the sample is 8000∼16,000, so the model needs to have sufficient expression ability to extract signal patterns which are overlapped and seriously missing in long samples;
- The model structure should avoid being too large and complex, and the cost performance ratio should be considered;
- It can, not only have a strong representation ability, but also effectively avoid gradient problems caused by deep networks.
4.2. Joint Modeling Method
4.3. Fixed Distribution Normalization
4.4. Support Vector Machines for Mode Recognition
5. Experiments and Results
5.1. Dataset
5.2. Capability of Pulse Modulation Recognition Subnetwork
5.2.1. In-Training Views
5.2.2. In-Testing Views
5.3. The Performance of the Proposed MSJR Learning Framework
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ResNet | Residual Neural Network |
| SVM | Support Vector Machine |
| MSJR | Multi-Source Joint Recognition Framework |
| MFR | Multi Function Radar |
| PDW | Pulse Description Word |
| CNN | Convolutional Neural Network |
| DNN | Deep Neural Network |
| VS | Velocity Search |
| RWS | Range while Search |
| STT | Single Target Tracking |
| TAS | Trace and Search |
| HPRF | High Pulse Repetition Frequency |
| MPRF | Medium Pulse Repetition Frequency |
| D&S | Dwell and Switch |
| RF | Radio Frequency |
| PW | Pulse Width |
| PA | Pulse Amplitude |
| DOA | Direction of Arrival |
| TOA | Time of Arrival |
| PRI | Pulse Repetition Interval |
References
- De Martino, A. Introduction to Modern EW Systems, 2nd ed.; Electronic Warfare Library, Artech House: Boston, MA, USA, 2018. [Google Scholar]
- Wiley, R.G. ELINT: The Interception and Analysis of Radar Signals; Artech House Radar Library, Artech House: Boston, MA, USA, 2006. [Google Scholar]
- Weber, M.E.; Cho, J.Y.; Thomas, H.G. Command and Control for Multifunction Phased Array Radar. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5899–5912. [Google Scholar] [CrossRef]
- Mardia, H.K. New techniques for the deinterleaving of repetitive sequences. IEE Proc. F 1989, 136, 149–154. [Google Scholar]
- Jiang, Q. Network Radar Countermeasure Systems: Integrating Radar and Radar Countermeasures, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Rogers, J. ESM processor system for high pulse density radar environments. Proc. IEE Proc. Commun. Radar Signal Process. 1985, 132, 621–625. [Google Scholar] [CrossRef]
- Kauppi, J.P.; Martikainen, K.; Ruotsalainen, U. Hierarchical classification of dynamically varying radar pulse repetition interval modulation patterns. Neural Netw. 2010, 23, 1226–1237. [Google Scholar] [CrossRef]
- Lida, D.; Shilian, W.; Fanggang, W.; Wei, Z. Specific Emitter Identification via Convolutional Neural Networks. IEEE Commun. Lett. 2018, 22, 2591–2594. [Google Scholar]
- Nishiguchi, K.I.; Kobayashi, M. Improved algorithm for estimating pulse repetition intervals. IEEE Trans. Aerosp. Electron. Syst. 2000, 36, 407–421. [Google Scholar] [CrossRef]
- Han, L.; Gao, F.; Li, Z.; Dobre, O.A. Low Complexity Automatic Modulation Classification Based on Order-Statistics. IEEE Trans. Wirel. Commun. 2017, 16, 400–411. [Google Scholar] [CrossRef]
- Orlic, V.; Dukic, M. Multipath channel estimation algorithm for automatic modulation classification using sixth-order cumulants. Electron. Lett. 2010, 46, 1. [Google Scholar] [CrossRef] [Green Version]
- Lunden, J.; Koivunen, V. Automatic Radar Waveform Recognition. IEEE J. Sel. Top. Signal Process. 2007, 1, 124–136. [Google Scholar] [CrossRef]
- Shaokun, L.; Xiaopeng, Y.; Ping, L.; Xinhong, H.; Ke, W. Radar Emitter Recognition Based on SIFT Position and Scale Features. IEEE Trans. Circuits Syst. II Express Briefs 2018, 65, 2062–2066. [Google Scholar]
- Zhang, M.; Liu, L.; Diao, M. LPI Radar Waveform Recognition Based on Time-Frequency Distribution. Sensors 2016, 16, 1682. [Google Scholar] [CrossRef] [Green Version]
- Xu, C.; Zhang, J.; Zhou, Q.; Chen, S. Recognition of radar signals based on AF grids and geometric shape constraint. Signal Process. 2019, 157, 30–44. [Google Scholar] [CrossRef]
- Nikita, V. Syntactic Modeling of Multi-Function Radars. Ph.D. Thesis, McMaster University, Hamilton, ON, Canada, 2005. [Google Scholar]
- Visnevski, N.; Krishnamurthy, V.; Wang, A.; Haykin, S. Syntactic Modeling and Signal Processing of Multifunction Radars: A Stochastic Context-Free Grammar Approach. Proc. IEEE 2007, 95, 1000–1025. [Google Scholar] [CrossRef]
- Zhou, Y.; Yu, X.; Cui, M. Radar Target Recognition based on Multiple Features Fusion with Dempster-Shafer Theory. In Proceedings of the IEEE 2011 10th International Conference on Electronic Measurement & Instruments, Chengdu, China, 16–19 August 2019; pp. 262–266. [Google Scholar]
- Li, D.; Gu, L.; Zhu, L. Identification and parameter estimation algorithm of radar signal subtle features. Phys. Commun. 2020, 42, 101140. [Google Scholar] [CrossRef]
- Wu, Z.; Yang, Z.; Sun, H.; Yin, Z.; Nallanathan, A. Hybrid radar emitter recognition based on rough k-means classifier and SVM. EURASIP J. Adv. Signal Process. 2012, 2012, 198. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Huang, Z.; Wang, F.; Wang, X.; Liu, T. Toward Convolutional Neural Networks on Pulse Repetition Interval Modulation Recognition. IEEE Commun. Lett. 2018, 22, 2286–2289. [Google Scholar] [CrossRef]
- Li, X.; Liu, Z.M.; Huang, Z. Denoising of Radar Pulse Streams with Autoencoders. IEEE Commun. Lett. 2020, 24, 797–801. [Google Scholar] [CrossRef]
- Lutao, L.; Xinyu, L. Radar signal recognition based on triplet convolutional neural network. EURASIP J. Adv. Signal Process. 2021, 2021, 112. [Google Scholar]
- Han, J.W.; Park, C.H. A Unified Method for Deinterleaving and PRI Modulation Recognition of Radar Pulses Based on Deep Neural Networks. IEEE Access 2021, 9, 89360–89375. [Google Scholar] [CrossRef]
- Dadgarnia, A.; Sadeghi, M.T. Automatic recognition of pulse repetition interval modulation using temporal convolutional network. IET Signal Process. 2021, 15, 633–648. [Google Scholar] [CrossRef]
- Li, Y.; Zhu, M.; Ma, Y.; Yang, J. Work modes recognition and boundary identification of MFR pulse sequences with a hierarchical seq2seq LSTM. IET Radar Sonar Navig. 2020, 14, 1343–1353. [Google Scholar] [CrossRef]
- Yu, H.h.; Yan, X.p.; Liu, S.k.; Li, P.; Hao, X.h. Radar emitter multi-label recognition based on residual network. Def. Technol. 2022, 18, 410–417. [Google Scholar]
- Lutao, L.; Xinyu, L. Unknown radar waveform recognition system via triplet convolution network and support vector machine. Digit. Signal Process. 2022, 123, 103439. [Google Scholar]
- Tao, X.; Shuo, Y.; Zhangmeng, L.; Fucheng, G. Radar Emitter Recognition Based on Parameter Set Clustering and Classification. Remote Sens. 2022, 14, 4468. [Google Scholar]
- Yang, Y.; Bijan, S.; Maria, R.; Masoud, M.; Nguyen, N.T.; Guang, Z. Vision-based concrete crack detection using a hybrid framework considering noise effect. J. Build. Eng. 2022, 61, 105246. [Google Scholar]
- Han, L.; Donghang, C.; Xiaojun, S.; Feng, W. Radar emitter recognition based on CNN and LSTM. In Proceedings of the 2021 International Conference on Neural Networks, Qingdao, China, 27–29 August 2021; Volume 11933, p. 119331T. [Google Scholar]
- Jifei, P.; Shengli, Z.; Lingsi, X.; Long, T.; Linqing, G. Embedding Soft Thresholding Function into Deep Learning Models for Noisy Radar Emitter Signal Recognition. Electronics 2022, 11, 2142. [Google Scholar]
- Santos, G.S.d.; Luvizotto, L.G.J.; Mariani, V.C.; Coelho, L.d.S. Least squares support vector machines with tuning based on chaotic differential evolution approach applied to the identification of a thermal process. Expert Syst. Appl. 2011, 39, 4805–4812. [Google Scholar] [CrossRef]
- Huang, Q.; Wang, C.; Ye, Y.; Wang, L.; Xie, N. Recognition of EEG based on Improved Black Widow Algorithm optimized SVM. Biomed. Signal Process. Control 2023, 81, 104454. [Google Scholar] [CrossRef]
- Gizen, M.; İnan, A.Ç. SVM-SMO-SGD: A hybrid-parallel support vector machine algorithm using sequential minimal optimization with stochastic gradient descent. Parallel Comput. 2022, 113, 102955. [Google Scholar]
- Qihang, Z.; Yan, L.; Zilin, Z.; Yunjie, L.; Shafei, W. Adaptive feature extraction and fine-grained modulation recognition of multi-function radar under small sample conditions. IET Radar Sonar Navig. 2022, 16, 1460–1469. [Google Scholar]
- Skolnik, M.I. Radar Handbook, 3rd ed.; McGraw-Hill: New York, NY, USA, 2008. [Google Scholar]
- Weichao, X.; Huadong, L.; Jisheng, D.; Yanzhou, Z. Spectrum sensing for cognitive radio based on Kendall’s tau in the presence of non-Gaussian impulsive noise. Digit. Signal Process. 2022, 123, 103443. [Google Scholar]
- Kun, C.; Jihong, S.; Yan, L.; Liyan, W.; Sheng, W. A novel segmentation approach for work mode boundary detection in MFR pulse sequence. Digit. Signal Process. 2022, 126, 103462. [Google Scholar]
- Liao, Y.; Chen, X. Multi-attribute overlapping radar working pattern recognition based on K-NN and SVM-BP. J. Supercomput. 2021, 77, 9642–9657. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Alabaster, C. Pulse Doppler Radar: Principles, Technology, Applications; SciTech Publishing: Edison, NJ, USA, 2012; p. xiv. 411p. [Google Scholar]
- Wang, S.; Gao, C.; Zhang, Q.; Dakulagi, V.; Zeng, H.; Zheng, G.; Bai, J.; Song, Y.; Cai, J.; Zong, B. Research and Experiment of Radar Signal Support Vector Clustering Sorting Based on Feature Extraction and Feature Selection. IEEE Access 2020, 8, 9332–93334. [Google Scholar] [CrossRef]
- Xu, J.; He, M.; Han, J.; Chen, C. A Comprehensive Estimation Method for Kernel Function of Radar Signal Classifier. Chin. J. Electron. 2015, 24, 218–222. [Google Scholar] [CrossRef]
- Feng, H.C.; Tang, B.; Wan, T. Radar pulse repetition interval modulation recognition with combined net and domain-adaptive few-shot learning. Digit. Signal Process. 2022, 127, 103562. [Google Scholar] [CrossRef]
- Hui, L.; Dong, J.W.; Dong, L.H.; Wei, C.T. Work Mode Identification of Airborne Phased Array Radar Based on the Combination of Multi-Level Modeling and Deep Learning. In Proceedings of the the 35th China Command and Control Conference, Chengdu, China, 27–29 July 2016; pp. 273–278. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Output Shape | Parameter |
|---|---|---|
| Input | 8000 × 1 | - |
| Conv1D | 4000 × 4 | 16 |
| ResNet Unit1 | 2000 × 16 | 6160 |
| ResNet Unit2 | 1000 × 32 | 24,256 |
| ResNet Unit3 | 500 × 64 | 94,592 |
| Batch Normalization | 500 × 64 | 256 |
| GAP | 64 | - |
| Dense | 7 | 455 |
| Total parameters | 125,735 | |
| Trainable parameters | 123,935 | |
| Type | Parameter |
|---|---|
| Total | Number of pulses = 16,000 Scope of PRI = 3.3∼165 μs PRI perturbation <1% Sample size = 4000 |
| Constant | PRI value = PRImean |
| Stagger | Number of PRI levels = 2∼8 |
| Jittered | PRI deviation = 10∼30% |
| Dwell and Switch | Number of pulse groups = 2∼8 Length of pulse groups = 20∼1000 |
| Sliding | PRImax = (2∼6) PRImin Sliding variable cycle = 20∼1000 Direction: up or down |
| Wobbulated | Wobbulated amplitude = (0.9∼1.1) PRImean Cycle length = 20∼1000 |
| Hybrid | A mixture of any two of the above styles |
| Behavioral Model | Waveform | PRI Value | PW Value | Duty Ratio | Modulation |
|---|---|---|---|---|---|
| Total | Number of pulse = 16,000 Scope of RF = 8500∼10,000 MHz PA = PA/PAmax Measurement error < 10% Sample size = 6000 | ||||
| VS | HPRF | 3.3∼10 μs | 1∼3 μs | 10∼30% | Constant |
| RWS | HPRF | 3.3∼10 μs | 1∼3 μs | 10∼30% | Constant |
| MPRF | 50∼165 μs | 1∼20 μs | 1∼25% | Jittered, Dwell and Switch | |
| STT | HPRF and MPRF | 3.3∼125 μs | 0.1∼20 μs | 0.1∼25% | Constant, Stagger, Jittered, Sliding, Wobbulated |
| TAS | HPRF and MPRF | 3.3∼165 μs | 0.1∼20 μs | 0.1∼25% | Search waveform refer to RWS Tracking waveform refer to STT |
| Number of Layers | DNN | CNN | ResNet |
|---|---|---|---|
| 6-layer | 65.3% | 84.5% | 94.7% |
| 12-layer | 87.1% | 80.1% | 95.9% |
| 18-layer | 51.9% | 88.7% | 97.1% |
| 24-layer | 49.8% | 64.6% | 97.4% |
| Average | 58.3% | 79.5% | 96.3% |
| Model | Lost Pulse (%) | Process Time (s) | Model Capacity | |||||
|---|---|---|---|---|---|---|---|---|
| 0 | 10 | 20 | 30 | 40 | 50 | |||
| AlexNet | 0.407 | 0.551 | 0.807 | 0.561 | 0.317 | 0.283 | 2.42 | 520 K |
| ConvNet | 0.296 | 0.374 | 0.7525 | 0.546 | 0.397 | 0.412 | 11.46 | 954 K |
| LeNet | 0.416 | 0.459 | 0.738 | 0.481 | 0.354 | 0.252 | 4.16 | 285 K |
| ResNet | 0.890 | 0.883 | 0.870 | 0.847 | 0.799 | 0.666 | 10.93 | 1110 K |
| MSJR | 0.952 | 0.942 | 0.941 | 0.929 | 0.765 | 0.770 | 14.50 | 1220 K |
| VGGNet | 0.862 | 0.479 | 0.295 | 0.283 | 0.272 | 0.258 | 9.15 | 1680 K |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, J.; Xiong, J.; Zhuo, Y. Working Mode Recognition of Non-Specific Radar Based on ResNet-SVM Learning Framework. Sensors 2023, 23, 3123. https://doi.org/10.3390/s23063123
Pan J, Xiong J, Zhuo Y. Working Mode Recognition of Non-Specific Radar Based on ResNet-SVM Learning Framework. Sensors. 2023; 23(6):3123. https://doi.org/10.3390/s23063123
Chicago/Turabian StylePan, Jifei, Jingwei Xiong, and Yihong Zhuo. 2023. "Working Mode Recognition of Non-Specific Radar Based on ResNet-SVM Learning Framework" Sensors 23, no. 6: 3123. https://doi.org/10.3390/s23063123