
Yolo-Pest: An Insect Pest Object Detection Algorithm via CAC3 Module


Abstract
:1. Introduction
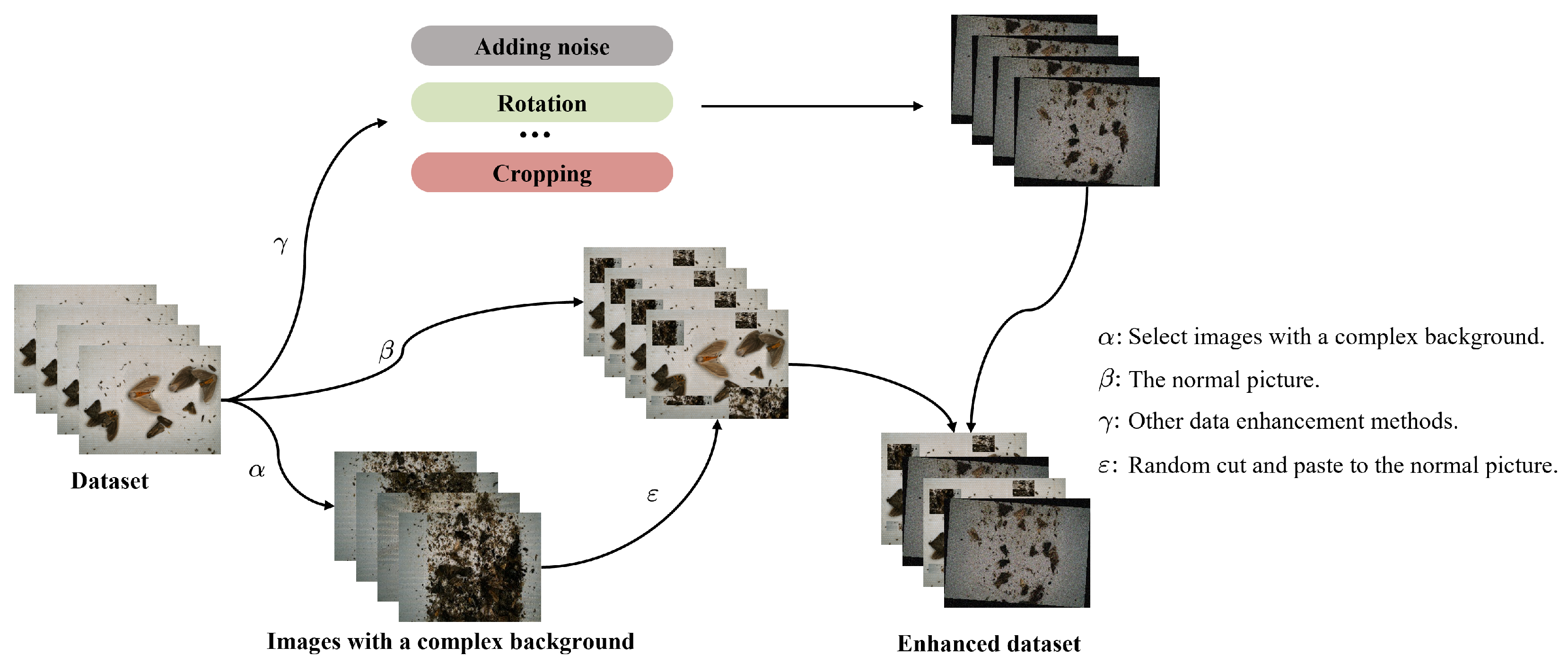
- This paper, in the Teddy Cup pest dataset, explores a data enhancement method based on a complex background. Random background enhancement is used, which improves the robustness, generalization ability, and sensitivity to the interference of the model to a certain extent;
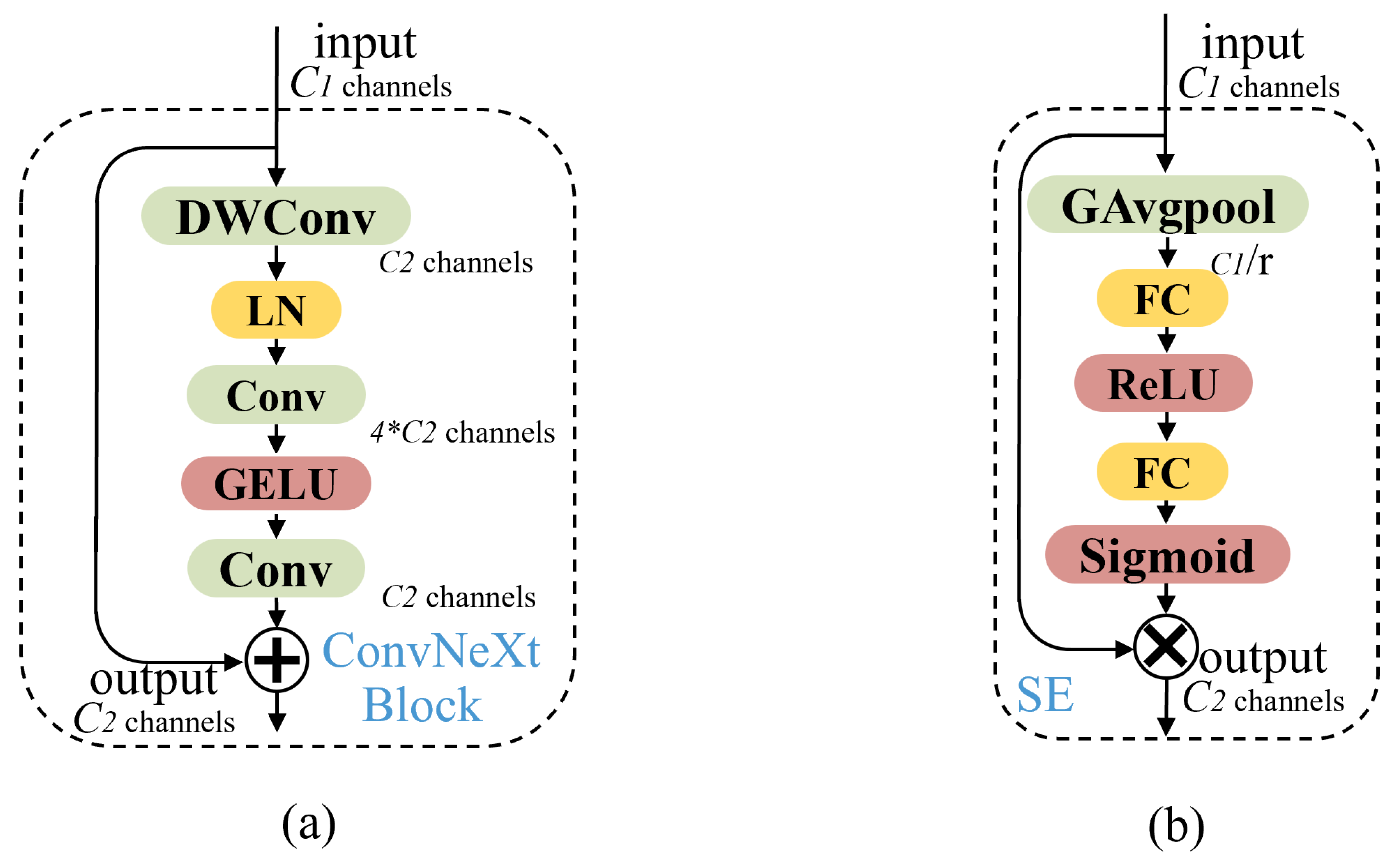
- This paper proposes the Yolo-Pest model for pest identification of various sizes and connects the ConvNext block [8] and SE [9] attention mechanism into the model. Large kernel sizes and other tricks are used to increase the receptive field to reduce the influence of the complex background and improve the overall model accuracy;
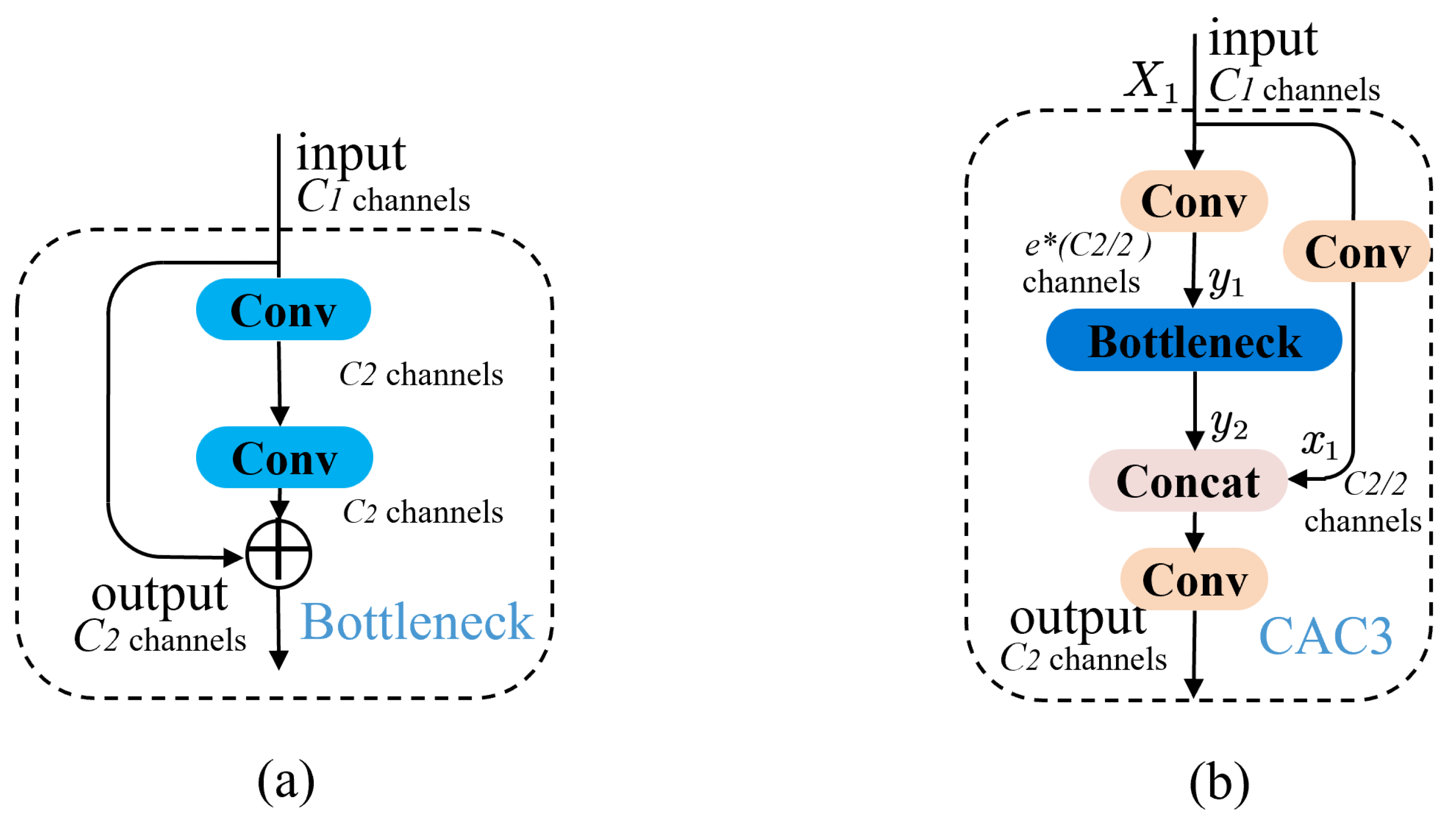
- This paper proposes a new module with the controllable channel residual feature extraction structure CAC3 (Convolution attention c3 module), which controls the stacking degree of residual blocks to solve the problem of feature loss or redundancy, explores the common improvement of object detection accuracy of different sizes in the model, and achieves an excellent balance between the accuracy of the model and the inference speed.
2. Related Work
2.1. Object Detection
2.2. Pest-Based Object Detection
3. Materials and Methods
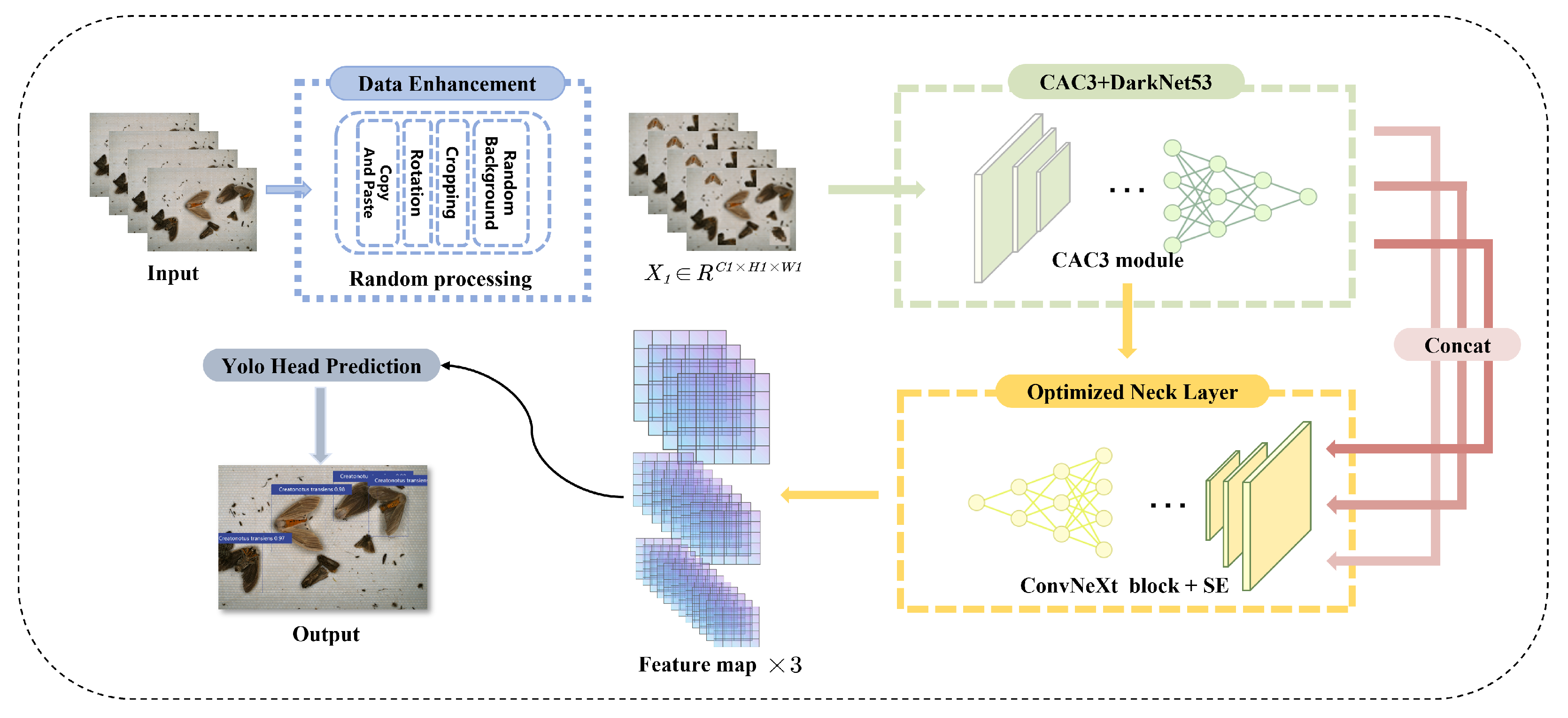
3.1. Yolo-Pest Structure
3.2. Data Augmentation
- Some data in the dataset have complex interference and a lot of noise;
- Interference is reasonable for most of the data and may be present in all of the data;
- There is no spatial irrationality in changing the background position randomly or in a certain dimension.
3.3. CAC3 Module
3.4. Optimized Neck Layer
4. Experiments
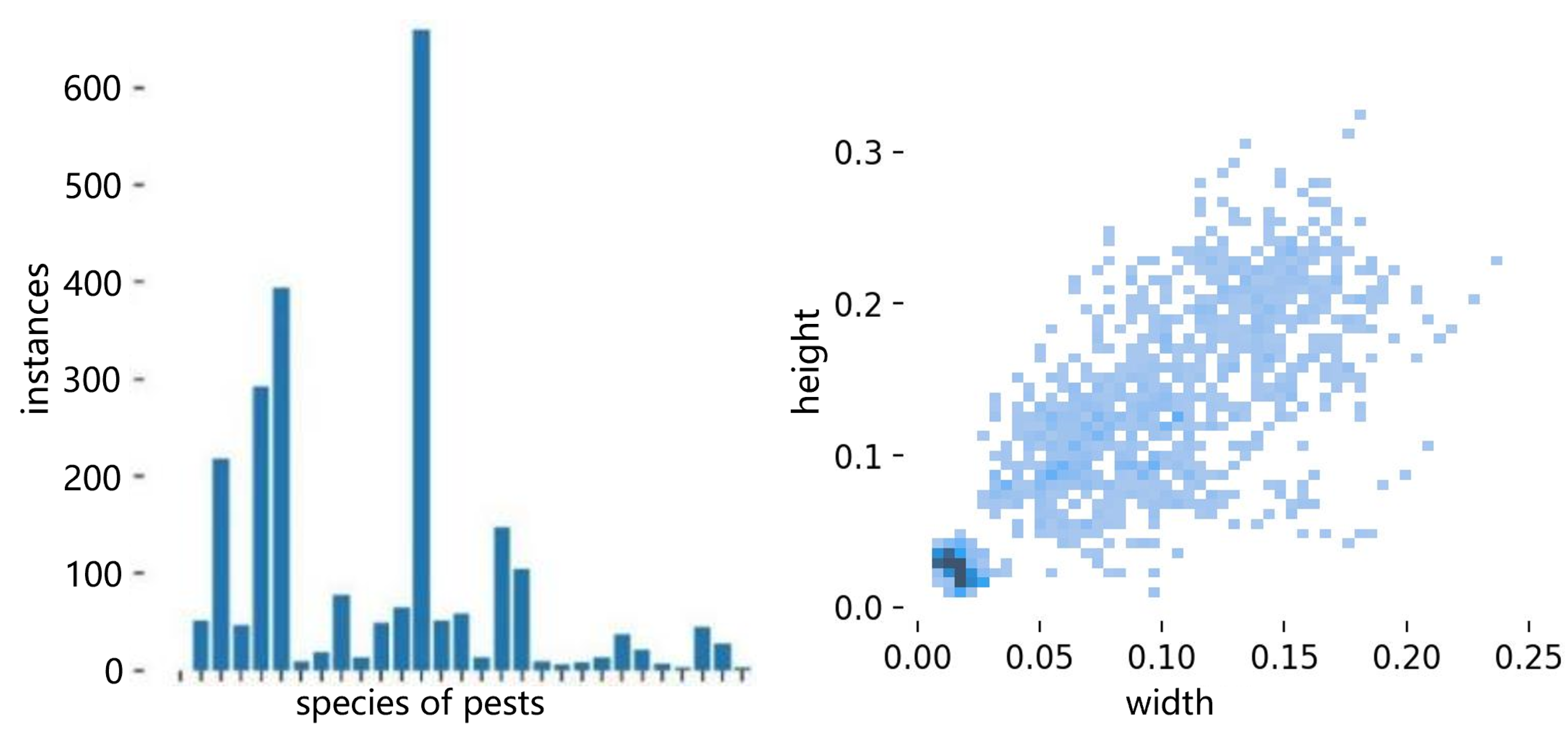
4.1. Datasets
- IP102
- The Teddy Cup pest dataset
4.2. Experimental Details Settings
4.3. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kandalkar, G.; Deorankar, A.; Chatur, P. Classification of agricultural pests using dwt and back propagation neural networks. Int. J. Comput. Sci. Inf. Technol. 2014, 5, 4034–4037. [Google Scholar]
- Deng, L.; Wang, Y.; Han, Z.; Yu, R. Research on insect pest image detection and recognition based on bio-inspired methods. Biosyst. Eng. 2018, 169, 139–148. [Google Scholar] [CrossRef]
- Wang, R.; Liu, L.; Xie, C.; Yang, P.; Li, R.; Zhou, M. AgriPest: A Large-Scale Domain-Specific Benchmark Dataset for Practical Agricultural Pest Detection in the Wild. Sensors 2021, 21, 1601. [Google Scholar] [CrossRef] [PubMed]
- Han, R.; He, Y.; Liu, F. Feasibility Study on a Portable Field Pest Classification System Design Based on DSP and 3G Wireless Communication Technology. Sensors 2012, 12, 3118–3130. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aladhadh, S.; Habib, S.; Islam, M.; Aloraini, M.; Aladhadh, M.; Al-Rawashdeh, H.S. An Efficient Pest Detection Framework with a Medium-Scale Benchmark to Increase the Agricultural Productivity. Sensors 2022, 22, 9749. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Zhen, T.; Li, Z. Image classification of pests with residual neural network based on transfer learning. Appl. Sci. 2022, 12, 4356. [Google Scholar] [CrossRef]
- Li, W.; Zhang, L.; Wu, C.; Cui, Z.; Niu, C. A new lightweight deep neural network for surface scratch detection. Int. J. Adv. Manuf. Technol. 2022, 123, 1–17. [Google Scholar] [CrossRef]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitat ion networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50× fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. Adv. Neural Inf. Process. Syst. 2016, 29, 1–9. [Google Scholar]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra r-cnn: Towards balanced learning for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 821–830. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Nagar, H.; Sharma, R. A comprehensive survey on pest detection techniques using image processing. In Proceedings of the 2020 4th International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 13–15 May 2020; pp. 43–48. [Google Scholar]
- Wen, C.; Guyer, D. Image-based orchard insect automated identification and classification method. Comput. Electron. Agric. 2012, 89, 110–115. [Google Scholar] [CrossRef]
- Hassan, S.N.; Rahman, N.S.; Win, Z.Z.H.S.L. Automatic classification of insects using color-based and shape-based descriptors. Int. J. Appl. Control. Electr. Electron. Eng. 2014, 2, 23–35. [Google Scholar]
- Huang, X.; Dong, J.; Zhu, Z.; Ma, D.; Ma, F.; Lang, L. TSD-Truncated Structurally Aware Distance for Small Pest Object Detection. Sensors 2022, 22, 8691. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Ghiasi, G.; Cui, Y.; Srinivas, A.; Qian, R.; Lin, T.Y.; Cubuk, E.D.; Le, Q.V.; Zoph, B. Simple copy-paste is a strong data augmentation method for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2918–2928. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Wu, X.; Zhan, C.; Lai, Y.K.; Cheng, M.M.; Yang, J. Ip102: A large-scale benchmark dataset for insect pest recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8787–8796. [Google Scholar]
- Rao, Y.; Zhao, W.; Tang, Y.; Zhou, J.; Lim, S.N.; Lu, J. Hornet: Efficient high-order spatial interactions with recursive gated convolutions. arXiv 2022, arXiv:2207.14284. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Radosavovic, I.; Kosaraju, R.P.; Girshick, R.; He, K.; Dollár, P. Designing network design spaces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10428–10436. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13733–13742. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Backbone | mAP0.5 | mAP0.95 | Param. | Complexity (FLOPs) |
|---|---|---|---|---|
| CAC3 + DarkNet53 (e = 0.25) | 86.4% | 71.4% | 5.9 M | 13.0 G |
| CAC3 + DarkNet53 (e = 1.0) | 81.2% | 72.0% | 9.5 M | 19.3 G |
| C3 + DarkNet53 | 83.7% | 71.5% | 7.1 M | 16.2 G |
| Hornet [38] + DarkNet53 | 85.7% | 71.2% | 9.3 M | 21.1 G |
| Mobilenet [39] | 86.1% | 70.8% | 2.2 M | 3.2 G |
| Regnet [40] | 76.1% | 59.6% | 5.0 M | 9.2 G |
| Moudle | mAP | mAP | Param. | Complexity (FLOPs) |
|---|---|---|---|---|
| C3 + Bottleneck | 83.7% | 71.5% | 7.1 M | 16.2 G |
| C3 + ConvNext block (ours) | 87.7% | 71.7% | 6.9 M | 15.8 G |
| C3 + Hornet block | 85.6% | 72.2% | 7.3 M | 16.7 G |
| ConvNeXt block | 82.8% | 70.4% | 10.7 M | 29.8 G |
| Hornet block | 82.0% | 71.1% | 9.5 M | 19.3 G |
| Attentions | Param. | P.&R. | mAP | mAP | Complexity (FLOPs) |
|---|---|---|---|---|---|
| SE | 7.13 M | 94.8% 76.8% | 85.5% | 73.6% | 16.2 G |
| CA | 7.12 M | 94.7% 75.9% | 84.4% | 72.0% | 16.2 G |
| CBAM | 7.13 M | 94.1% 76.2% | 83.6% | 72.1% | 16.2 G |
| SK [41] | 29.2 M | 95.0% 76.2% | 83.3% | 72.3% | 33.9 G |
| Models | Param. | mAP0.5 | mAP0.95 | Complexity (FLOPs) |
|---|---|---|---|---|
| Baseline (Yolov5s) | 7.1 M | 83.7% | 71.5% | 16.2 G |
| Baseline + CAC3 (e = 0.25) | 5.9 M | 86.4% | 71.4% | 13.0G |
| Baseline + ConvNeXt block | 6.9 M | 87.7% | 71.7% | 15.8 G |
| Baseline + ConvNeXt block + SE | 6.9 M | 90.4% | 75.0% | 15.9G |
| Baseline + CAC3 + ConvNeXtblock + SE (e = 0.25) | 5.8 M | 90.6% | 74.6% | 12.7 G |
| Baseline + CAC3 + ConvNeXtblock + SE (e = 0.275) | 5.9 M | 91.9% | 72.5% | 12.9G |
| Baseline + CAC3 + ConvNeXtblock + SE (e = 0.3) | 6.0 M | 91.0% | 74.3% | 13.1G |
| Detectors | Params (M) | FPS (img/s) | mAP |
|---|---|---|---|
| GhostNet [42] | 4.03 | 1768.49 | 39.68 |
| ShuffleNetV2 | 5.55 | 1686.72 | 43.63 |
| ResNet18 | 11.22 | 1577.33 | 46.85 |
| MobileNetV3-Large | 4.33 | 1612.18 | 47.44 |
| DenseNet121 [43] | 7.05 | 684.80 | 56.1 |
| Yolov5s | 7.1 | 158.70 | 57.0 |
| Yolo-Pest (ours) | 5.8 | 166.67 | 57.1 |
| Detectors | Params (M) | Complexity (FLOPs) | mAP |
|---|---|---|---|
| Yolov3-tiny | 8.7 | 13.0 G | 82.3 |
| Yolov4-mish | 9.2 | 21.0 G | 80.4 |
| Yolov5s | 7.1 | 16.2G | 83.7 |
| MobileNetV3-Small | 2.2 | 3.2 G | 87.9 |
| RepVGG-A0 [44] | 8.3 | 1.4 G | 84.1 |
| Yolo-Pest (ours) | 5.8 | 12.9 G | 91.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiang, Q.; Huang, X.; Huang, Z.; Chen, X.; Cheng, J.; Tang, X. Yolo-Pest: An Insect Pest Object Detection Algorithm via CAC3 Module. Sensors 2023, 23, 3221. https://doi.org/10.3390/s23063221
Xiang Q, Huang X, Huang Z, Chen X, Cheng J, Tang X. Yolo-Pest: An Insect Pest Object Detection Algorithm via CAC3 Module. Sensors. 2023; 23(6):3221. https://doi.org/10.3390/s23063221
Chicago/Turabian StyleXiang, Qiuchi, Xiaoning Huang, Zhouxu Huang, Xingming Chen, Jintao Cheng, and Xiaoyu Tang. 2023. "Yolo-Pest: An Insect Pest Object Detection Algorithm via CAC3 Module" Sensors 23, no. 6: 3221. https://doi.org/10.3390/s23063221
APA StyleXiang, Q., Huang, X., Huang, Z., Chen, X., Cheng, J., & Tang, X. (2023). Yolo-Pest: An Insect Pest Object Detection Algorithm via CAC3 Module. Sensors, 23(6), 3221. https://doi.org/10.3390/s23063221