1. Introduction
An enormous amount of trajectory data from moving objects is generated due to the development of location-acquisition devices, such as GPS, smartphones, and transportation monitoring systems. The variety and richness of location traces enable a better understanding of the movement behaviors of objects, which provides new applications, including smart transportation, urban development planning, and security surveillance. One of the crucial problems for the above applications is to detect the anomalous trajectories of objects. For taxi services, for example, abnormal trajectories are related to issues, such as traffic congestion, taxi driving fraud, and refusing to take passengers. Therefore, detecting anomalous taxi trajectories may improve the performance of this service [
1,
2,
3,
4]. Moreover, anomaly event detection plays a vital role in security surveillance in public spaces. These anomaly events, such as terrorism, violent attack, and fire, can be detected by analyzing the object trajectories in public places [
5,
6]. Moreover, to guarantee the safety and security of ships during a voyage, their location data are used to detect outlying trajectories and remind other ships to take the necessary avoidance actions [
7,
8]. Similarly, to ensure aircraft safety, data recorded from current flights are monitored and analyzed constantly. Once anomalous data patterns are detected, they are informed to the flight monitoring system to handle them instantly [
9,
10,
11,
12,
13]. On the other hand, those studies focused on detecting anomalous trajectories of objects in outdoor spaces.
In recent times, the location data of objects in buildings have been gathered because of the development of indoor navigation systems. This has attracted increasing attention from researchers in new fields. For example, customers’ shopping behavior can be identified by analyzing their historical trajectories in supermarkets. This allows managers to improve product placement and the layout of the supermarkets [
14]. Furthermore, human location prediction technologies in indoor spaces have been developed recently and are an important part of location-based services. Predicting where people will be in office buildings can help better understand their intentions and enhance their quality of life [
15,
16]. Nevertheless, there are few works on discovering anomalies in indoor human movement, which plays an important role in security surveillance and identifying emergencies. Therefore, this study develops a framework to detect anomalies in indoor human trajectories. In particular, two anomaly types are studied, i.e., rare location visit and route anomalies. A rare location is where humans rarely visit or are prohibited from visiting. Therefore, a person’s behavior may be considered abnormal if he/she accesses rare places. In addition, route anomalies can occur when people travel along unusual routes, such as detours or random routes. These anomaly types are illustrated in
Figure 1.
There are several challenges in anomaly detection in indoor human movement. First, detecting anomalies in urgent situations has a tight time constraint. This task requires anomaly detection as fast as possible to handle the occurring situations instantly. Hence, existing methods that detect anomalous trajectories with no time limits are unsuitable [
3,
17,
18,
19]. Second, the distance between trajectories in indoor spaces is different from outdoor spaces because indoor trajectories are limited by entities, such as rooms, corridors, and stairs. Therefore, anomaly detection methods using existing distance functions, including Euclidean distance, longest common sub-sequence (LCSS) [
20], dynamic time warping (DTW) [
21], and edit distance on real sequence (EDR) [
22], are ineffective for indoor trajectory data. In addition, indoor human movement behavior may be represented by location traces and the semantics of data points. For example, consider the behavior between two people. One stays in a meeting room, the other in a coffee room. Assume that these two rooms are next to each other. Their behavior is entirely different in this case, despite their close proximity. Therefore, semantic information should be considered when estimating the similarity between indoor trajectories. Finally, existing anomaly detection methods do not provide an effective way to choose algorithm parameters, which may degrade the detection performance. For example, the performances of distance-based and density-based methods are affected by the distance and density thresholds [
17,
23]. Clustering-based anomaly detection methods require input parameters for the clustering algorithm, such as the number of clusters in K-Means, spectral clustering, and hierarchical clustering. DBSCAN requires two input parameters: The minimum number of points to form a new cluster (MinPts) and the radius to find the neighbors (Eps). Choosing an appropriate value of Eps is essential for performing DBSCAN; most studies determined this value manually.
In this work, a DBSCAN-based anomaly detection method is developed, which addresses the above challenges. First, this study detects anomalies in a short time to satisfy time requirements. A time window is chosen to process trajectories. The window size is small enough to meet the time constraint. Next, a novel trajectory similarity metric called the longest common sub-sequence using indoor walking distance and a semantic label (LCSS_IS) is proposed. This metric uses indoor walking distance and semantic labels when calculating the similarity between trajectories. Finally, the proposed method detects human trajectory anomalies based on DBSCAN. The DBSCAN cluster validity index (DCVI) is proposed to determine the Eps value. Three elements were considered when designing this index: The inter-cluster distance, the intra-cluster distance, and the distance between outliers and clusters. DCVI estimates the clustering quality of DBSCAN based on the separation between clusters, the compactness within each cluster, and the separation between outliers and clusters. In summary, the main contributions of this work are presented as follows:
A novel two-phase anomaly detection framework is proposed to identify anomalous human trajectories in indoor spaces. Instead of estimating a trajectory over a long time, the trajectories in a short duration are considered, and an alarm is given when an anomaly is detected. This ensures timely anomaly detection in urgent situations.
A new similarity metric LCSS_IS is proposed using indoor walking distance and semantic labels to discover the similarity between trajectories in indoor spaces. In addition, a new cluster validity index for DBSCAN called DCVI is proposed to choose the Eps value. Eps is an important input parameter of DBSCAN, which directly affects the performance of the clustering algorithm.
The proposed anomaly detection method is evaluated using two real-world datasets. The results show that the proposed method outperforms the other anomalous trajectory detection methods over various anomalous trajectory types.
The paper is structured as follows.
Section 2 discusses related works and
Section 3 defines the anomaly detection problem. The methodology is described in
Section 4. Then, the algorithm performance is evaluated in
Section 5. Finally, the conclusion is reported in
Section 6.
2. Related Works
This section briefly reviews the related works in anomalous trajectory detection. The existing methods are divided into two categories: Methods that do not use similarity metrics and methods that do. The first category discovers the “few and different” characteristics of anomalies to detect them. Zhang et al. [
18] introduced the isolation-based anomalous trajectory (iBAT) method to exploit anomalies using the isolation forest (iForest) algorithm [
24]. They produced a random tree of trajectories and then adopted the iForest algorithm. The trajectories were split recursively until most were isolated. The trajectories following shorter paths are considered outliers because they were isolated faster than normal trajectories. The authors in [
25] designed a technique called maximal anomalous sub-trajectories (MANTRA) to detect temporally anomalous sub-trajectory patterns from an input trajectory. By analyzing the distinctive characteristics of anomalous sub-trajectories, they refined the search space into a disjoint set of anomalous sub-trajectory islands. The resulting set of maximal anomalous sub-trajectories is determined on the anomalous islands.
The second category has attracted more research attention. In particular, there have been various methods using similarity metrics for detecting trajectory anomalies, including the extensible Markov model (EMM)-based, distance-based, density-based, and clustering-based methods. The EMM combines a Markov chain with a clustering algorithm, which detects anomalous trajectories [
26]. Each node of EMM is a cluster of location points, which is represented by a cluster model. Depending on the distance between a new point and clusters, the point is grouped either into one of the existing nodes or forms a new node. A point is marked as an anomaly if it belongs to one of two situations: The point forms a new node, or the point belongs to a node whose occurrence probability or whose transition probability is lower than a given threshold. A trajectory is considered anomalous if it contains at least one abnormal point.
The distance-based anomalous trajectory detection method calculates the similarity between trajectories using a distance function. A similarity threshold is given to identify abnormal trajectories [
27,
28]. Zhu et al. introduced the time-dependent popular routes-based trajectory outlier detection (TPRO) method [
27]. In this study, the most popular routes on each timestamp were used to detect the temporal anomalies. The trajectory datasets were divided into groups using a partitioning strategy. A reference trajectory represents each group. The edit distance between the reference trajectory of each group and the popular routes in the given city was then calculated. The anomalous trajectory groups were detected if the distance between its reference trajectory and the popular routes was larger than a given distance threshold. Saleem et al. presented the road segment partitioning towards anomalous trajectory detection (RPAT) algorithm [
28]. The trajectories were divided into sub-trajectories based on the road segments. The speed, flow rate, and visited time were features used to calculate the score for each sub-trajectory. The score of each trajectory is the total of its sub-trajectory scores. Trajectory scores above a user-specified threshold are anomalies.
In the density-based anomalous trajectory detection method, the neighbor density of trajectories is estimated to detect anomalies. A previous study [
17] proposed the trajectory outlier detection (TRAOD) algorithm by investigating the partition and detection strategy in finding sub-trajectory outliers. A new distance function was proposed, which comprises three components: Perpendicular distance, parallel distance, and angle distance. The density of sub-trajectories was determined using a distance threshold. A sub-trajectory is anomalous if its density is smaller than a threshold. The study in [
23] also introduced a distance measure that uses intra-trajectory and inter-trajectory features. The distances between trajectories were first calculated to find the neighbor density of each trajectory. The anomalous trajectories were then detected based on the density threshold.
Clustering-based methods group trajectories into clusters using an appropriate clustering algorithm. Anomalies are detected if they do not belong to any clusters or belong to clusters that only have a few trajectories. Wang et al. [
3] proposed an anomalous trajectory detection method using a hierarchical clustering algorithm to derive anomalous trajectories from a taxi GPS dataset. First, the trajectories that travel between the same source and destination were all extracted. The hierarchical clustering algorithm is then adopted to derive the clusters of trajectories using the edit distance. The clusters that have only a trajectory are finally marked as anomalies. Unlike in [
3], the authors in [
29] developed a two-phase anomalous trajectory detection framework: Online phase and offline phase. The offline phase finds the clusters of trajectories. In this step, the distance between trajectories was calculated using LCSS, and a hierarchical clustering algorithm was also adopted to group trajectories. In the second phase, a trajectory was marked as an anomaly if it did not belong to any clusters.
The challenge of clustering-based anomaly detection methods is determining the input parameters of an algorithm. For example, the hierarchical clustering algorithm requires the number of clusters as an input parameter. Previous studies [
30,
31] proposed a few indices to find the number of clusters. These indices estimated the compactness of clusters and the separation between clusters for finding the number of clusters in datasets. DBSCAN requires two input parameters: Eps and MinPts; determining the Eps parameter is more difficult for DBSCAN. Many methods have been proposed to choose the Eps value. A combination of the elbow method and the
nearest neighbor is used to determine the Eps value for DBSCAN [
32]. They found
k nearest neighbors of all data points in the dataset and sorted them in descending order of
. An Eps value was chosen according to the cutoff point of the sorted
graph. On the other hand, the cutoff point cannot always be identified. A new method to choose the Eps value was proposed to overcome the disadvantage of the elbow method [
33]. They automatically found the greatest slope change instead of observing the graph. The Eps value was determined according to the point with the greatest slope. The performance of this method still depended on the shape of the
graph. A new approach was also proposed to determine the Eps value using empty circles [
34]. They started by finding all empty circles in the dataset. The radius of the circles was sorted in descending order. The elbow value of this sorted radius was chosen as the Eps value. Nevertheless, similar to the reported method [
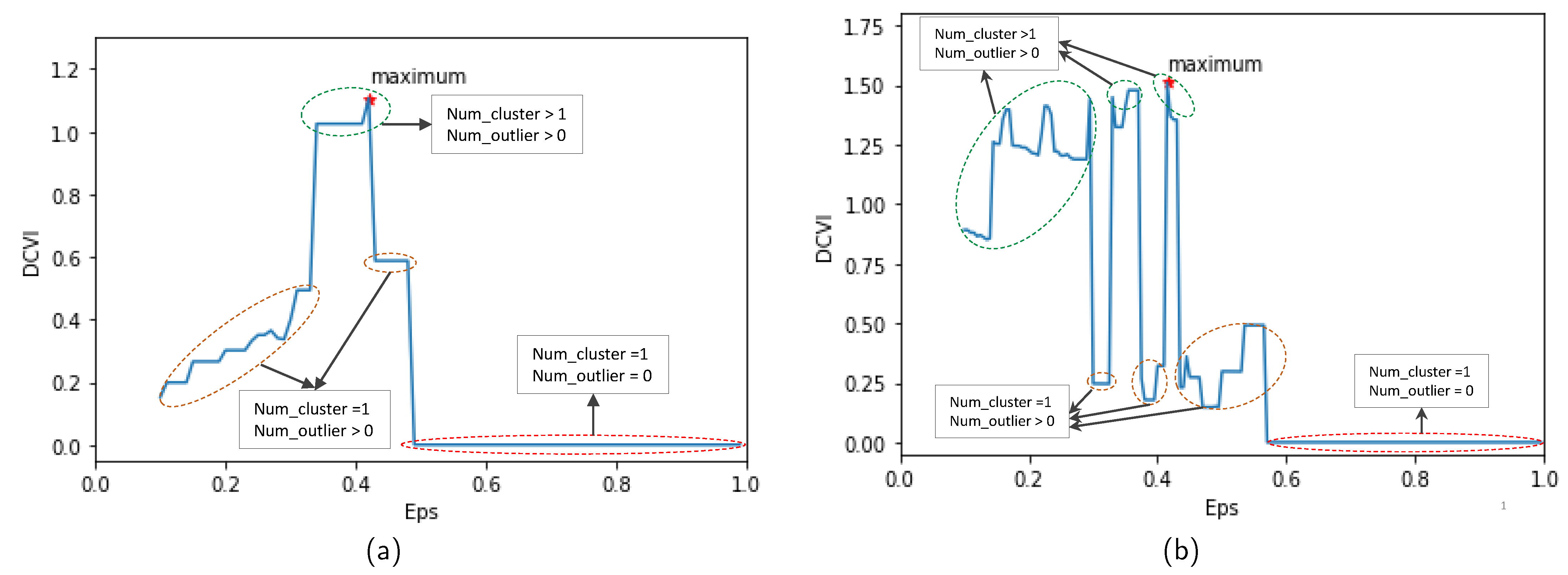
32], it was difficult to determine the appropriate elbow value if it was unclear. In contrast, in our work, the value of Eps is selected based on an evaluation of the clustering quality. Specifically, a novel DBSCAN clustering validity index called DCVI is proposed to choose the Eps value. DCVI measures the compactness of clusters, the separation between clusters, and the separation between clusters and outliers. The value of Eps is determined according to the maximum value of DCVI.
With anomalous trajectory detection methods, which use distance metrics for determining the similarity of the trajectories, choosing an appropriate distance metric plays a vital role. The most straightforward metric, the Euclidean distance, determines the total distance between all pairs of corresponding points on two trajectories. On the other hand, the Euclidean distance requires two trajectories of the same length, and it is sensitive to noises or equipment recording errors. Several distance measurements have been proposed to address these limitations. For example, LCSS can identify similar common sub-sequences between two trajectories of various lengths. This measurement is also noise-resistant because it provides the space and time thresholds to find similar points of two trajectories [
20]. DTW has been applied successfully to time series data and trajectories. DTW is based on defining a cost for aligning two data points and finding the minimum cost to align all points between two trajectories [
21]. EDR can also remove noise effects by quantizing the distance between a pair of elements to two values, 0 and 1. This measurement does not require the same lengths of two considering trajectories [
22]. With indoor spaces, however, the movement path between two points may not be a straight line segment because it is limited by indoor entities [
35]. Therefore, the above metrics are relatively ineffective for measuring the similarity of indoor trajectories.
Motivated by this, the authors in [
35] proposed an indoor semantic trajectory similarity measure (ISTSM) that was improved from the EDR. ISTSM integrated semantic labels and indoor walking distance to calculate the similarity of indoor semantic trajectories. On the other hand, the indoor walking distance was only considered if the two points were the same semantic. They directly assigned the penalty value of two different semantic points to a maximum value of 1. In other words, they ignored the space aspect between two points if they were different semantic labels. In contrast, this paper proposes a new distance function called LCSS_IS, which is extended from LCSS. The LCSS_IS uses the indoor walking distance in both situations of the same and different semantic labels for estimating the similarity of the indoor trajectories. Furthermore, the trade-off between space and semantic aspects in LCSS_IS is controlled by pre-defined user parameters.
3. Problem Definition
This work aims to detect indoor human movement anomalies in emergencies. When humans move, their location data are recorded, and trajectories may be achieved by connecting their location points. A location point p is defined as , where are the coordinates of p at timestamp t. A trajectory , which consists of n location points, is the collected location data during a time window W. Here n is the length of trajectory T. The trajectories may have different lengths because some data points may be lost during data collection.
Problem 1. Given a set of historical location data of N people who participated in collecting data over the same time duration. Assuming that a set of trajectories is extracted from the location dataset L using the time window W. M is the number of historical trajectories in D. With a new trajectory that comes during a time window W, the anomaly detection framework detects whether is an anomaly using the historical trajectory set D.
6. Concluding Remarks
This paper proposed a two-phase framework for detecting indoor human trajectory anomalies based on DBSCAN. This proposed method discovered trajectory clusters in the dataset. A newly coming trajectory is detected as an anomaly if it does not belong to any clusters of trajectories. A novel measure called LCSS_IS was proposed to determine the similarity of the trajectories, which was extended from the original LCSS for discovering the features of indoor human movement. In particular, the indoor walking distance and semantic information were combined to estimate the similarity of trajectories. Therefore, LCSS_IS measured the distance of trajectories in indoor spaces more precisely than existing distance metrics. Furthermore, a novel cluster validity index, DCVI, was proposed to choose the Eps parameter for DBSCAN. DCVI was designed to measure the separation between clusters, the separation between clusters and outliers, and the compactness within each cluster. An appropriate Eps value was determined corresponding to the maximum value of DCVI. The proposed method was evaluated on two real datasets: MIT Badge and sCREEN. The different anomalous trajectory types were also detected in this work. The proposed method showed impressive performance and outperformed the baselines.
In this work, there are a few limitations. First, several features of trajectory data, such as speed and moving direction, were not considered for calculating the distance between trajectories. Second, the proposed method was not evaluated on datasets with complex floor plans, such as buildings with many floors. We plan to extend this work to address the above limitations in a future study.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}