



A Fault-Detection System Approach for the Optimization of Warship Equipment Replacement Parts Based on Operation Parameters
 , , , , , , and
, , , , , , and
Abstract
:1. Introduction
2. Related Work
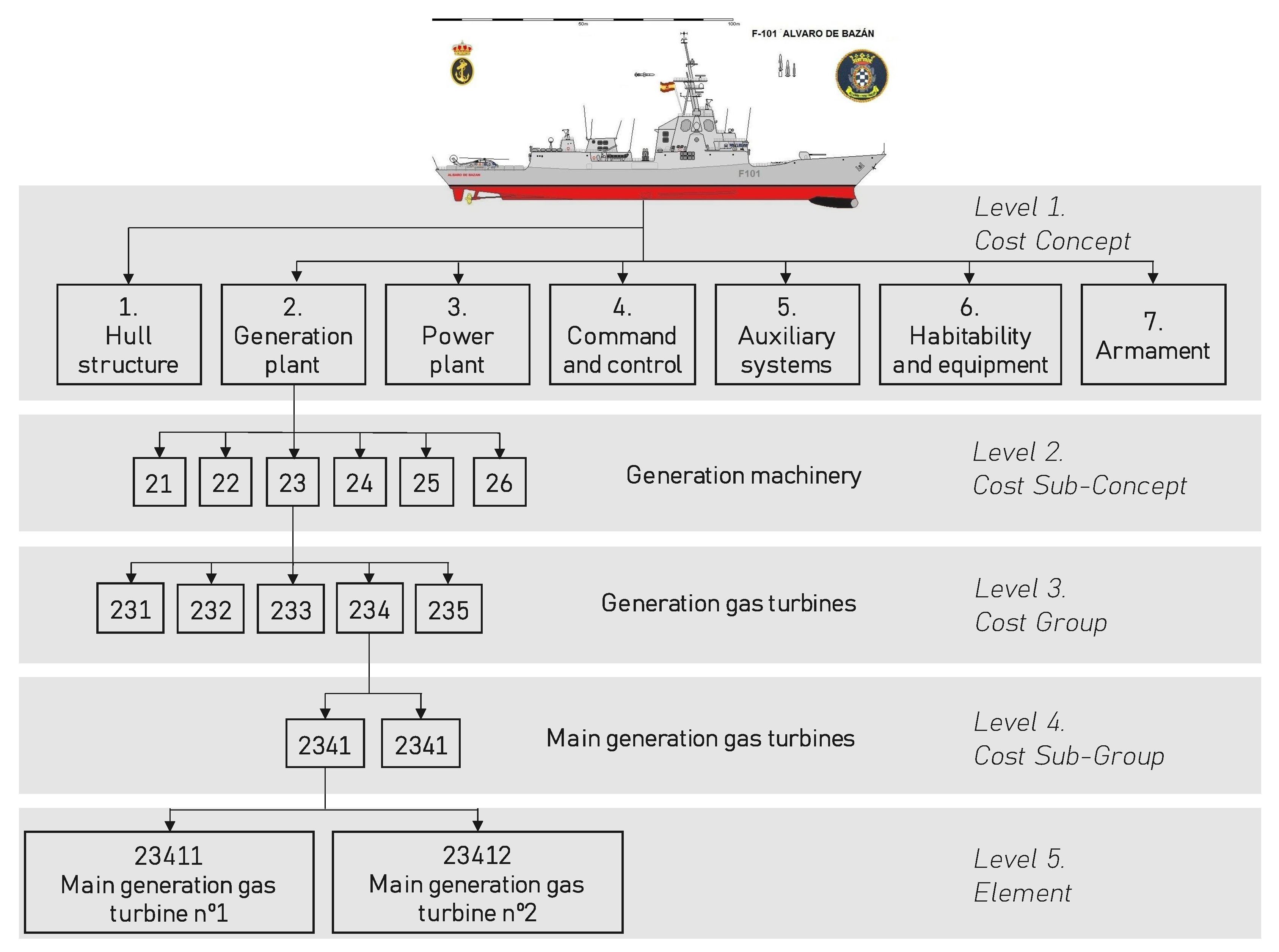
3. Case of Study
3.1. Equipment
3.2. Warship Information System Structure
4. Materials and Methods
4.1. Employed Methods
4.1.1. Statistical Models
Gaussian Model
- is the training set mean value;
- is the training set covariance matrix.
4.1.2. Geometric Boundaries
K-Means
- x represents a new input vector;
- denotes the centroid of the k cluster.
4.1.3. Dimensional Reduction
Autoencoder
- defines the output of the hidden layer;
- is the hidden layer activation function;
- corresponds to the weight matrix between input and hidden layer;
- is the input vector;
- denotes the bias vector.
- is the ANN output.
- denotes the activation function of the output layer.
- define the weight matrix between hidden and output layers.
- is the bias vector.
Principal Component Analysis
4.2. Dataset
- Dataset 1 contains two variables and a total of 902,796 samples, of which 219 correspond to anomalous data.
- Dataset 2 contains two variables and 897,191 samples, of which 101 correspond to anomalous data.
- Dataset 3 contains twenty-five variables and 887,294 samples, of which 233 correspond to anomalous data.
5. Experiments Description (Setup) and Results
5.1. Experimental Setup and Assessment
- Gaussian Model
- −
- Data normalization
- −
- Data regularization
- −
- Outlier factor
- K-means
- −
- Data normalization
- −
- Number of clusters
- −
- Outlier factor
- Autoencoder
- −
- Data normalization
- −
- Neurons in the hidden layer
- −
- Outlier factor
- Principal Component Analysis
- −
- Data normalization
- −
- Number of components considered
- −
- Outlier factor
5.2. Results
6. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Khastgir, S.; Birrell, S.; Dhadyalla, G.; Sivencrona, H.; Jennings, P. Towards increased reliability by objectification of Hazard Analysis and Risk Assessment (HARA) of automated automotive systems. Saf. Sci. 2017, 99, 166–177. [Google Scholar] [CrossRef]
- Wahidi, S.; Pribadi, S.; Pribadi, T.; Wardhana, N.; Arif, M. Fixed Manpower Reduction Analysis to Reduce Indirect Cost of Ship Production. In Proceedings of the 5th International Conference on Marine Technology (SENTA 2020), Surabaya, Indonesia, 8 December 2020; IOP Publishing: Bristol, UK, 2021; Volume 1052, p. 012048. [Google Scholar]
- Hannaford, E.; Hassel, E.V. Risks and Benefits of Crew Reduction and/or Removal with Increased Automation on the Ship Operator: A Licensed Deck Officer’s Perspective. Appl. Sci. 2021, 11, 3569. [Google Scholar] [CrossRef]
- Manis, K.; Madhavaram, S. AI-Enabled marketing capabilities and the hierarchy of capabilities: Conceptualization, proposition development, and research avenues. J. Bus. Res. 2023, 157, 113485. [Google Scholar] [CrossRef]
- Ang, J.H.; Goh, C.; Saldivar, A.A.F.; Li, Y. Energy-efficient through-life smart design, manufacturing and operation of ships in an industry 4.0 environment. Energies 2017, 10, 610. [Google Scholar] [CrossRef]
- Thompson, J.H. An Unpopular War: From Afkak to Bosbefok; Penguin Random House: Saxonwold, South Africa, 2011. [Google Scholar]
- La Monaca, U.; Bertagna, S.; Marinò, A.; Bucci, V. Integrated ship design: An innovative methodological approach enabled by new generation computer tools. Int. J. Interact. Des. Manuf. (IJIDeM) 2020, 14, 59–76. [Google Scholar] [CrossRef]
- Xing, T.; Song, B.; Ye, J.; Zhao, Z. General Analysis Method of Warship Service Life. In Proceedings of the 2010 Second WRI Global Congress on Intelligent Systems, Wuhan, China, 16–17 December 2010; IEEE: Piscataway, NJ, USA, 2010; Volume 3, pp. 223–228. [Google Scholar]
- Stanić, V.; Hadjina, M.; Fafandjel, N.; Matulja, T. Toward shipbuilding 4.0-an industry 4.0 changing the face of the shipbuilding industry. Brodogr. Teor. Praksa Brodogr. Pomor. Teh. 2018, 69, 111–128. [Google Scholar] [CrossRef]
- Fernández Jove, A.; Mackinlay, A.; Riola, J.M. Optimization of the Life Cycle in the Warships: Maintenance Plan and Monitoring for Costs Reduction. In Proceedings of the International Ship Design & Naval Engineering Congress, Pan American Congress of Naval Engineering, Maritime Transport and Port Engineering, Cartagena, Colombia, 13–15 March 2019; Springer: Berlin/Heidelberg, Germany, 2020; pp. 391–401. [Google Scholar]
- Jove, E.; Casteleiro-Roca, J.L.; Quintián, H.; Méndez-Pérez, J.A.; Calvo-Rolle, J.L. A new method for anomaly detection based on non-convex boundaries with random two-dimensional projections. Inf. Fusion 2021, 65, 50–57. [Google Scholar] [CrossRef]
- Jove, E.; Casteleiro-Roca, J.; Quintián, H.; Méndez-Pérez, J.; Calvo-Rolle, J. Anomaly detection based on intelligent techniques over a bicomponent production plant used on wind generator blades manufacturing. Rev. Iberoam. Autom. Inform. Ind. 2020, 17, 84–93. [Google Scholar]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. (CSUR) 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Ahmed, M.; Mahmood, A.N.; Hu, J. A survey of network anomaly detection techniques. J. Netw. Comp. Appl. 2016, 60, 19–31. [Google Scholar] [CrossRef]
- Casteleiro-Roca, J.L.; Jove, E.; Sánchez-Lasheras, F.; Méndez-Pérez, J.A.; Calvo-Rolle, J.L.; de Cos Juez, F.J. Power cell SOC modelling for intelligent virtual sensor implementation. J. Sens. 2017, 2017. [Google Scholar] [CrossRef]
- Kimera, D.; Nangolo, F.N. Maintenance practices and parameters for marine mechanical systems: A review. J. Qual. Maint. Eng. 2020, 26, 459–488. [Google Scholar] [CrossRef]
- Cullum, J.; Binns, J.; Lonsdale, M.; Ambassi, R.; Garaniya, V. Risk-Based Maintenance Scheduling with application to naval vessels and ships. Ocean Eng. 2018, 148, 476–485. [Google Scholar] [CrossRef]
- Zhang, P.; Gao, Z.; Cao, L.; Dong, F.; Zou, Y.; Wang, K.; Zhang, Y.; Sun, P. Marine Systems and Equipment Prognostics and Health Management: A Systematic Review from Health Condition Monitoring to Maintenance Strategy. Machines 2022, 10, 72. [Google Scholar] [CrossRef]
- Rao, X.; Sheng, C.; Guo, Z.; Yuan, C. A review of online condition monitoring and maintenance strategy for cylinder liner-piston rings of diesel engines. Mech. Syst. Signal Proc. 2022, 165, 108385. [Google Scholar] [CrossRef]
- Xie, T.; Wang, T.; He, Q.; Diallo, D.; Claramunt, C. A review of current issues of marine current turbine blade fault detection. Ocean Eng. 2020, 218, 108194. [Google Scholar] [CrossRef]
- Cipollini, F.; Oneto, L.; Coraddu, A.; Murphy, A.J. Condition-based maintenance of naval propulsion systems: Data analysis with minimal feedback. Reliab. Eng. Syst. Saf. 2018, 177, 12–23. [Google Scholar] [CrossRef]
- Karatug, C.; Arslanoglu, Y.; Guedes Soares, C. Trends in Maritime Technology and Engineering; Maintenance Strategies for Machinery Systems of Autonomous Ships; CRC Press: Boca Raton, FL, USA, 2022. [Google Scholar]
- Emovon, I.; Norman, R.A.; Murphy, A.J. Elements of maintenance system and tools for implementation within framework of Reliability Centred Maintenance- A review. Mech. Eng. Technol. 2016, 8, 1–34. [Google Scholar]
- Abbas, M.; Shafiee, M. An overview of maintenance management strategies for corroded steel structures in extreme marine environments. Marine Struct. 2020, 71, 102718. [Google Scholar] [CrossRef]
- Jimenez, V.J.; Bouhmala, N.; Gausdal, A.H. Developing a predictive maintenance model for vessel machinery. J. Ocean Eng. Sci. 2020, 5, 358–386. [Google Scholar] [CrossRef]
- Song, T.; Tan, T.; Han, G. Research on Preventive Maintenance Strategies and Systems for in-Service Ship Equipment. Polish Maritime Res. 2022, 29, 85–96. [Google Scholar] [CrossRef]
- Emovon, I.; Norman, R.A.; Murphy, A.J. Hybrid MCDM based methodology for selecting the optimum maintenance strategy for ship machinery systems. J. Intell. Manuf. 2018, 29, 519–531. [Google Scholar] [CrossRef]
- Michala, A.L.; Lazakis, I.; Theotokatos, G. Predictive maintenance decision support system for enhanced energy efficiency of ship machinery. In Proceedings of the International Conference on Shipping in Changing Climates, Glasgow, UK, 24–26 November 2015; pp. 195–205. [Google Scholar]
- Asuquo, M.P.; Wang, J.; Zhang, L.; Phylip-Jones, G. Application of a multiple attribute group decision making (MAGDM) model for selecting appropriate maintenance strategy for marine and offshore machinery operations. Ocean Eng. 2019, 179, 246–260. [Google Scholar] [CrossRef]
- Lazakis, I.; Turan, O.; Alkaner, S.; Olcer, A. Effective ship maintenance strategy using a risk and criticality based approach. In Proceedings of the 13th International Congress of the International Maritime Association of the Mediterranean (IMAM 2009), Genova, Italy, 13–16 September 2009. [Google Scholar]
- Diagkinis, I.; Nikitakos, N. Application of analytic hierarchy process and TOPSIS methodology on ships’ maintenance strategies. J. Pol. Saf. Reliab. Assoc. 2013, 4, 21–28. [Google Scholar]
- Emovon, I. Ship system maintenance strategy selection based on DELPHI-AHP-TOPSIS methodology. World J. Eng. Technol. 2016, 4, 252–260. [Google Scholar] [CrossRef]
- Zhao, J.; Yang, L. A bi-objective model for vessel emergency maintenance under a condition-based maintenance strategy. Simulation 2018, 94, 609–624. [Google Scholar] [CrossRef]
- Barrero, D.; Fontenla-Romero, O.; Lamas-López, F.; Novoa-Paradela, D.; R-Moreno, M.; Sanz, D. SOPRENE: Assessment of the Spanish Armada’s Predictive Maintenance Tool for Naval Assets. Appl. Sci. 2021, 11, 7322. [Google Scholar] [CrossRef]
- Samanta, B.; Al-Balushi, K.R. Artificial Neural Network based fault diagnostics of rolling element bearings using time-domain features. Mech. Syst. Signal Process. 2003, 17, 317–328. [Google Scholar] [CrossRef]
- Quinlan, J. Improved Use of Continuous Attributes in C4.5. Artif. Intell. Res. 1996, 4, 77–90. [Google Scholar] [CrossRef]
- Chen, Y.; He, Y.; Li, Z.; Chen, L.; Zhang, C. Remaining Useful Life Prediction and State of Health Diagnosis of Lithium-Ion Battery Based on Second-Order Central Difference Particle Filter. IEEE Access 2020, 8, 37305–37313. [Google Scholar] [CrossRef]
- Ratsch, G.; Mika, S.; Scholkopf, B.; Muller, K.R. Constructing boosting algorithms from SVMs: An application to one-class classification. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 1184–1199. [Google Scholar] [CrossRef]
- Susto, G.; Schirru, A.; Pampuri, S.; McLoone, S.; Beghi, A. Machine Learning for Predictive Maintenance: A Multiple Classifier Approach. IEEE Trans. Ind. Inf. 2015, 11, 812–820. [Google Scholar] [CrossRef]
- Ma, M.; Sun, C.; Chen, X. Deep Coupling Autoencoder for Fault Diagnosis with Multimodal Sensory Data. IEEE Trans. Ind. Inf. 2018, 14, 1137–1145. [Google Scholar] [CrossRef]
- Yuan, J.; Tian, Y. An Intelligent Fault Diagnosis Method Using GRU Neural Network towards Sequential Data in Dynamic Processes. Processes 2019, 7, 152. [Google Scholar] [CrossRef]
- Yang, R.; Huang, M.; Lu, Q.; Zhong, M. Rotating Machinery Fault Diagnosis Using Long-short-term Memory Recurrent Neural Network. IFAC-PapersOnLine 2018, 51, 228–232. [Google Scholar] [CrossRef]
- Zhu, R.; Peng, W.; Wang, D.; Huang, C.G. Bayesian transfer learning with active querying for intelligent cross-machine fault prognosis under limited data. Mech. Syst. Signal Process. 2023, 183, 109628. [Google Scholar] [CrossRef]
- Abid, A.; Khan, M.T.; Iqbal, J. A review on fault detection and diagnosis techniques: Basics and beyond. Artif. Intell. Rev. 2021, 54, 3639–3664. [Google Scholar] [CrossRef]
- Yamei, J.; Xin, T.; Hongjian, L.; Lifeng, M. Fault detection of networked dynamical systems: A survey of trends and techniques. Int. J. Syst. Sci. 2021, 52, 3390–3409. [Google Scholar]
- Xu, X.; Karney, B. Modeling and Monitoring of Pipelines and Networks: An Overview of Transient Fault Detection Techniques; ACM: New York, NY, USA, 2017; pp. 13–37. [Google Scholar]
- Madeti, S.R.; Singh, S.N. A comprehensive study on different types of faults and detection techniques for solar photovoltaic system. Solar Energy 2017, 158, 161–185. [Google Scholar] [CrossRef]
- Appiah, A.Y.; Zhang, X.; Ayawli, B.B.K.; Kyeremeh, F. Review and performance evaluation of photovoltaic array fault detection and diagnosis techniques. Int. J. Photoenergy 2019, 2019, 6953530. [Google Scholar] [CrossRef]
- Gangsar, P.; Tiwari, R. Signal based condition monitoring techniques for fault detection and diagnosis of induction motors: A state-of-the-art review. Mech. Syst. Signal Process. 2020, 144, 106908. [Google Scholar] [CrossRef]
- Mishra, D.P.; Ray, P. Fault detection, location and classification of a transmission line. Neural Comput. Appl. 2020, 30, 1377–1424. [Google Scholar] [CrossRef]
- Jove, E.; Casteleiro-Roca, J.L.; Quintián, H.; Méndez-Pérez, J.A.; Calvo-Rolle, J.L. A fault detection system based on unsupervised techniques for industrial control loops. Exp. Syst. 2019, 36, e12395. [Google Scholar] [CrossRef]
- Jove, E.; Casteleiro-Roca, J.L.; Quintián, H.; Simić, D.; Méndez-Pérez, J.A.; Calvo-Rolle, J.L. Anomaly detection based on one-class intelligent techniques over a control level plant. Logic J. IGPL 2020, 28, 502–518. [Google Scholar] [CrossRef]
- Reis, G.; Chang, J.; Vachharajani, N.; Mukherjee, S.S.; Rangan, R.; August, D.I. Design and evaluation of hybrid fault-detection systems. In Proceedings of the 32nd International Symposium on Computer Architecture (ISCA’05), Madison, WI, USA, 4–8 June 2005; pp. 148–159. [Google Scholar]
- NATO. Guidance on Integrated Logistics Support for Multinational Armament Programmes; ALP-10: Brussels, Belgium, 2017. [Google Scholar]
- Macías Gaya, J.M. El control de la configuración en la Armada del siglo XXI. Rev. Gen. Mar. 2019, 276, 77–89. [Google Scholar]
- NATO. Configuration management in system life cycle management. STANAG 4427 2014. [Google Scholar]
- Tax, D.M.J. One-Class Cassification: Concept-Learning in the Absence of Counter-Examples. Ph.D. Thesis, Delft University of Technology, Delft, The Nethlands, 2001. [Google Scholar]
- Casale, P.; Pujol, O.; Radeva, P. Approximate polytope ensemble for one-class classification. Pattern Recognit. 2014, 47, 854–864. [Google Scholar] [CrossRef]
- Jeon, B.; Landgrebe, D.A. Fast Parzen density estimation using clustering-based branch and bound. IEEE Trans. Pattern Anal. Mach. Intell. 1994, 16, 950–954. [Google Scholar] [CrossRef]
- Chiang, L.H.; Russell, E.L.; Braatz, R.D. Fault Detection and Diagnosis in Industrial Systems; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2000. [Google Scholar]
- Sakurada, M.; Yairi, T. Anomaly detection using autoencoders with nonlinear dimensionality reduction. In Proceedings of the MLSDA 2014 2nd Workshop on Machine Learning for Sensory Data Analysis, Gold Coast, QLD, Australia, 2 December 2014; p. 4. [Google Scholar]
- Wu, J.; Zhang, X. A PCA classifier and its application in vehicle detection. In Proceedings of the IJCNN’01, International Joint Conference on Neural Networks, (Cat. No. 01CH37222), Washington, DC, USA, 15–19 July 2001; IEEE: Piscataway, NJ, USA, 2001; Volume 1, pp. 600–604. [Google Scholar]
- Al Shalabi, L.; Shaaban, Z. Normalization as a preprocessing engine for data mining and the approach of preference matrix. In Proceedings of the 2006 International Conference on Dependability of Computer Systems, Szklarska Poreba, Poland, 25–27 May 2006; IEEE: Piscataway, NJ, USA, 2006; pp. 207–214. [Google Scholar]
- Jove, E.; Casteleiro-Roca, J.L.; Quintián, H.; Zayas-Gato, F.; Vercelli, G.; Calvo-Rolle, J.L. A one-class classifier based on a hybrid topology to detect faults in power cells. Logic J. IGPL 2022, 30, 679–694. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Evaluated Technique | Evaluated Configuration | Tested Values |
|---|---|---|
| Gaussian Model | Data normalization Data regularization Outlier factor (\%) | NoNorm, Norm, Zscore 0:0.003:0.009 0:5:15 |
| K-means | Data nomalization Number of clusters Outlier factor (\%) | NoNorm, Norm, Zscore 2:2:6 0:5:15 |
| Autoencoder | Data nomalization Neurons in the hidden layer Outlier factor (\%) | NoNorm, Norm, Zscore 1:1: 0:5:15 |
| PCA | Data nomalization Number of components Outlier factor (\%) | NoNorm, Norm, Zscore 1:1: 0:5:15 |
| Norm. | Regul. | Out. Factor (%) | Dataset 1 | Dataset 2 | Dataset 3 | |||
|---|---|---|---|---|---|---|---|---|
| AUC (%) | T. Time (s) | AUC (%) | T. Time (s) | AUC (%) | T. Time (s) | |||
| NoNorm | 0 | 0 | 50.000 | 0.094 | 50.000 | 0.112 | 50.000 | 0.863 |
| NoNorm | 0 | 5 | 81.317 | 0.082 | 97.501 | 0.089 | 48.365 | 0.937 |
| NoNorm | 0 | 10 | 81.260 | 0.082 | 95.136 | 0.090 | 56.761 | 0.784 |
| NoNorm | 0 | 15 | 82.460 | 0.072 | 92.507 | 0.086 | 64.647 | 0.921 |
| NoNorm | 0.003 | 0 | 50.000 | 0.077 | 50.000 | 0.087 | 50.000 | 0.874 |
| NoNorm | 0.003 | 5 | 89.071 | 0.077 | 97.537 | 0.091 | 55.218 | 0.936 |
| NoNorm | 0.003 | 10 | 93.209 | 0.079 | 95.019 | 0.090 | 72.345 | 1.056 |
| NoNorm | 0.003 | 15 | 92.529 | 0.076 | 92.565 | 0.092 | 85.718 | 0.773 |
| NoNorm | 0.006 | 0 | 50.000 | 0.079 | 50.000 | 0.082 | 50.000 | 0.965 |
| NoNorm | 0.006 | 5 | 93.676 | 0.073 | 97.584 | 0.079 | 55.942 | 0.748 |
| NoNorm | 0.006 | 10 | 95.048 | 0.074 | 95.065 | 0.082 | 74.366 | 0.967 |
| NoNorm | 0.006 | 15 | 92.528 | 0.076 | 92.562 | 0.082 | 86.222 | 0.946 |
| NoNorm | 0.009 | 0 | 50.000 | 0.077 | 50.000 | 0.075 | 50.000 | 0.796 |
| NoNorm | 0.009 | 5 | 95.797 | 0.076 | 97.592 | 0.074 | 56.158 | 1.059 |
| NoNorm | 0.009 | 10 | 95.045 | 0.075 | 95.021 | 0.086 | 76.098 | 0.814 |
| NoNorm | 0.009 | 15 | 92.516 | 0.075 | 92.583 | 0.095 | 86.222 | 0.739 |
| Norm | 0 | 0 | 50.000 | 0.074 | 50.000 | 0.083 | 50.000 | 1.085 |
| Norm | 0 | 5 | 81.384 | 0.078 | 97.501 | 0.093 | 48.366 | 0.920 |
| Norm | 0 | 10 | 81.254 | 0.076 | 95.136 | 0.101 | 56.688 | 0.928 |
| Norm | 0 | 15 | 82.453 | 0.078 | 92.507 | 0.095 | 64.648 | 0.770 |
| Norm | 0.003 | 0 | 50.076 | 0.078 | 50.000 | 0.076 | 50.000 | 0.925 |
| Norm | 0.003 | 5 | 81.313 | 0.074 | 97.501 | 0.089 | 48.150 | 0.819 |
| Norm | 0.003 | 10 | 81.243 | 0.072 | 95.088 | 0.084 | 53.658 | 0.741 |
| Norm | 0.003 | 15 | 82.469 | 0.085 | 92.511 | 0.100 | 62.551 | 0.839 |
| Norm | 0.006 | 0 | 50.000 | 0.073 | 50.000 | 0.077 | 50.000 | 0.852 |
| Norm | 0.006 | 5 | 81.376 | 0.074 | 97.504 | 0.077 | 48.150 | 1.051 |
| Norm | 0.006 | 10 | 81.183 | 0.074 | 95.046 | 0.082 | 54.234 | 0.928 |
| Norm | 0.006 | 15 | 82.473 | 0.072 | 92.504 | 0.087 | 62.771 | 0.839 |
| Norm | 0.009 | 0 | 50.000 | 0.078 | 50.000 | 0.089 | 50.000 | 0.883 |
| Norm | 0.009 | 5 | 81.307 | 0.078 | 97.515 | 0.086 | 48.149 | 0.883 |
| Norm | 0.009 | 10 | 81.112 | 0.079 | 95.074 | 0.089 | 54.667 | 0.950 |
| Norm | 0.009 | 15 | 82.488 | 0.078 | 92.501 | 0.094 | 64.002 | 0.822 |
| Zscore | 0 | 0 | 50.000 | 0.077 | 50.000 | 0.084 | 50.000 | 0.862 |
| Zscore | 0 | 5 | 81.388 | 0.079 | 97.501 | 0.089 | 48.365 | 0.852 |
| Zscore | 0 | 10 | 81.193 | 0.075 | 95.137 | 0.091 | 56.689 | 0.841 |
| Zscore | 0 | 15 | 82.467 | 0.074 | 92.506 | 0.091 | 64.649 | 0.951 |
| Zscore | 0.003 | 0 | 50.000 | 0.075 | 50.000 | 0.090 | 50.000 | 0.925 |
| Zscore | 0.003 | 5 | 81.386 | 0.077 | 97.501 | 0.083 | 48.149 | 0.753 |
| Zscore | 0.003 | 10 | 81.261 | 0.076 | 95.137 | 0.090 | 53.585 | 0.993 |
| Zscore | 0.003 | 15 | 82.477 | 0.080 | 92.531 | 0.090 | 62.556 | 0.946 |
| Zscore | 0.006 | 0 | 50.000 | 0.078 | 50.000 | 0.088 | 50.000 | 0.900 |
| Zscore | 0.006 | 5 | 81.534 | 0.074 | 97.504 | 0.088 | 48.148 | 0.820 |
| Zscore | 0.006 | 10 | 81.155 | 0.076 | 95.145 | 0.090 | 53.730 | 0.809 |
| Zscore | 0.006 | 15 | 82.478 | 0.077 | 92.514 | 0.094 | 62.340 | 0.958 |
| Zscore | 0.009 | 0 | 50.000 | 0.075 | 50.000 | 0.085 | 50.000 | 0.874 |
| Zscore | 0.009 | 5 | 81.532 | 0.076 | 97.503 | 0.099 | 48.148 | 0.872 |
| Zscore | 0.009 | 10 | 81.194 | 0.074 | 95.118 | 0.093 | 54.523 | 0.878 |
| Zscore | 0.009 | 15 | 82.470 | 0.078 | 92.517 | 0.082 | 62.267 | 0.865 |
| Norm. | N° of Clusters | Out. Factor (%) | Dataset 1 | Dataset 2 | Dataset 3 | |||
|---|---|---|---|---|---|---|---|---|
| AUC (%) | T. Time (s) | AUC (%) | T. Time (s) | AUC (%) | T. Time (s) | |||
| NoNorm | 2 | 0 | 50.228 | 0.263 | 50.000 | 0.271 | 50.000 | 4.756 |
| NoNorm | 2 | 5 | 88.435 | 0.229 | 97.509 | 0.273 | 47.716 | 4.473 |
| NoNorm | 2 | 10 | 91.251 | 0.280 | 95.045 | 0.241 | 61.300 | 4.746 |
| NoNorm | 2 | 15 | 88.648 | 0.304 | 92.559 | 0.278 | 86.572 | 4.692 |
| NoNorm | 4 | 0 | 50.000 | 0.642 | 50.000 | 0.413 | 50.000 | 6.553 |
| NoNorm | 4 | 5 | 91.340 | 0.529 | 97.520 | 0.398 | 48.004 | 6.977 |
| NoNorm | 4 | 10 | 89.028 | 0.663 | 95.052 | 0.361 | 73.487 | 5.410 |
| NoNorm | 4 | 15 | 86.670 | 0.593 | 92.540 | 0.514 | 56.844 | 7.174 |
| NoNorm | 6 | 0 | 50.076 | 0.625 | 50.000 | 0.492 | 50.000 | 7.230 |
| NoNorm | 6 | 5 | 90.155 | 0.650 | 94.489 | 0.670 | 58.692 | 7.526 |
| NoNorm | 6 | 10 | 84.190 | 0.473 | 95.015 | 0.586 | 45.210 | 7.120 |
| NoNorm | 6 | 15 | 88.033 | 0.910 | 92.515 | 0.630 | 42.706 | 8.634 |
| Norm | 2 | 0 | 50.000 | 0.271 | 50.000 | 0.300 | 50.000 | 7.109 |
| Norm | 2 | 5 | 84.373 | 0.353 | 97.524 | 0.314 | 62.796 | 9.290 |
| Norm | 2 | 10 | 85.206 | 0.326 | 95.040 | 0.340 | 89.068 | 8.206 |
| Norm | 2 | 15 | 86.559 | 0.334 | 92.559 | 0.328 | 89.902 | 6.341 |
| Norm | 4 | 0 | 50.000 | 0.569 | 50.000 | 1.018 | 50.000 | 12.225 |
| Norm | 4 | 5 | 89.866 | 0.540 | 89.801 | 0.937 | 78.969 | 10.016 |
| Norm | 4 | 10 | 90.562 | 0.843 | 90.328 | 0.600 | 76.912 | 9.586 |
| Norm | 4 | 15 | 89.376 | 0.599 | 92.522 | 0.637 | 86.655 | 14.039 |
| Norm | 6 | 0 | 50.000 | 0.802 | 50.000 | 1.123 | 50.000 | 11.278 |
| Norm | 6 | 5 | 93.246 | 1.094 | 97.544 | 1.223 | 53.423 | 18.574 |
| Norm | 6 | 10 | 91.043 | 1.130 | 94.989 | 1.107 | 66.796 | 9.461 |
| Norm | 6 | 15 | 88.726 | 1.232 | 92.517 | 0.770 | 62.852 | 15.000 |
| Zscore | 2 | 0 | 50.000 | 0.344 | 50.000 | 0.373 | 50.000 | 8.096 |
| Zscore | 2 | 5 | 85.232 | 0.269 | 97.503 | 0.358 | 78.669 | 14.072 |
| Zscore | 2 | 10 | 95.075 | 0.274 | 95.076 | 0.400 | 90.743 | 13.373 |
| Zscore | 2 | 15 | 92.559 | 0.281 | 92.553 | 0.330 | 89.685 | 12.033 |
| Zscore | 4 | 0 | 50.076 | 0.789 | 50.000 | 1.016 | 50.000 | 16.391 |
| Zscore | 4 | 5 | 95.003 | 0.641 | 97.527 | 0.634 | 90.428 | 17.606 |
| Zscore | 4 | 10 | 89.446 | 0.713 | 95.020 | 0.645 | 91.539 | 18.379 |
| Zscore | 4 | 15 | 90.092 | 1.038 | 92.509 | 1.104 | 89.689 | 15.503 |
| Zscore | 6 | 0 | 50.000 | 1.298 | 50.000 | 1.121 | 50.000 | 17.635 |
| Zscore | 6 | 5 | 94.997 | 1.076 | 97.530 | 1.268 | 62.290 | 18.634 |
| Zscore | 6 | 10 | 91.536 | 1.368 | 95.009 | 1.400 | 70.902 | 23.149 |
| Zscore | 6 | 15 | 90.209 | 1.306 | 92.529 | 1.493 | 74.332 | 20.021 |
| Norm. | Comp. | Out. Factor (%) | Dataset 1 | Dataset 2 | ||
|---|---|---|---|---|---|---|
| AUC (%) | T. Time (s) | AUC (%) | T. Time (s) | |||
| NoNorm | 1 | 0 | 50.000 | 0.484 | 50.000 | 0.488 |
| NoNorm | 1 | 5 | 59.834 | 0.518 | 48.026 | 0.459 |
| NoNorm | 1 | 10 | 58.336 | 0.486 | 46.032 | 0.439 |
| NoNorm | 1 | 15 | 55.814 | 0.470 | 44.536 | 0.441 |
| Norm | 1 | 0 | 50.000 | 0.457 | 50.000 | 0.461 |
| Norm | 1 | 5 | 85.668 | 0.523 | 97.027 | 0.438 |
| Norm | 1 | 10 | 86.524 | 0.565 | 95.021 | 0.451 |
| Norm | 1 | 15 | 88.009 | 0.484 | 92.552 | 0.478 |
| Zscore | 1 | 0 | 50.000 | 0.462 | 50.000 | 0.441 |
| Zscore | 1 | 5 | 70.969 | 0.458 | 69.237 | 0.440 |
| Zscore | 1 | 10 | 69.865 | 0.507 | 76.894 | 0.441 |
| Zscore | 1 | 15 | 68.618 | 0.484 | 80.425 | 0.460 |
| Norm. | Comp. | Out. Factor (%) | Dataset 3 | |
|---|---|---|---|---|
| AUC (%) | T. Time (s) | |||
| Norm | 1 | 5 | 90.357 | 2.603 |
| Norm | 2 | 5 | 90.717 | 3.353 |
| NoNorm | 3 | 15 | 72.586 | 3.045 |
| Norm | 4 | 15 | 53.828 | 3.138 |
| NoNorm | 5 | 15 | 70.494 | 3.497 |
| NoNorm | 6 | 15 | 75.689 | 3.229 |
| NoNorm | 7 | 15 | 59.308 | 2.679 |
| NoNorm | 8 | 0 | 50.000 | 3.126 |
| NoNorm | 9 | 15 | 50.148 | 2.608 |
| NoNorm | 10 | 0 | 50.000 | 3.182 |
| NoNorm | 11 | 15 | 51.809 | 3.233 |
| NoNorm | 12 | 15 | 57.290 | 2.819 |
| Norm | 13 | 15 | 52.603 | 3.083 |
| Norm | 14 | 15 | 58.655 | 3.468 |
| Zscore | 15 | 15 | 59.890 | 3.121 |
| Zscore | 16 | 15 | 63.352 | 2.979 |
| Zscore | 17 | 15 | 63.352 | 3.097 |
| NoNorm | 18 | 5 | 53.130 | 3.132 |
| Norm | 19 | 15 | 54.117 | 3.030 |
| Norm | 20 | 15 | 61.113 | 3.461 |
| Zscore | 21 | 15 | 63.493 | 2.766 |
| Norm | 22 | 15 | 66.233 | 3.058 |
| NoNorm | 23 | 15 | 54.984 | 3.177 |
| Zscore | 24 | 15 | 62.700 | 3.105 |
| Norm. | N° Neurons | Out. Factor (%) | Dataset 1 | Dataset 2 | ||
|---|---|---|---|---|---|---|
| AUC (%) | T. Time (s) | AUC (%) | T. Time (s) | |||
| NoNorm | 1 | 0 | 50.000 | 357.132 | 50.000 | 147.926 |
| NoNorm | 1 | 5 | 84.857 | 352.384 | 48.031 | 157.925 |
| NoNorm | 1 | 10 | 71.600 | 189.100 | 46.035 | 197.221 |
| NoNorm | 1 | 15 | 79.714 | 285.890 | 44.568 | 128.557 |
| Norm | 1 | 0 | 50.000 | 30.100 | 50.000 | 31.605 |
| Norm | 1 | 5 | 85.826 | 32.068 | 97.026 | 45.150 |
| Norm | 1 | 10 | 86.513 | 39.528 | 95.020 | 55.993 |
| Norm | 1 | 15 | 87.617 | 41.665 | 92.550 | 41.893 |
| Zscore | 1 | 0 | 50.000 | 34.112 | 50.000 | 21.486 |
| Zscore | 1 | 5 | 70.883 | 21.553 | 69.231 | 32.899 |
| Zscore | 1 | 10 | 70.133 | 13.587 | 76.874 | 50.331 |
| Zscore | 1 | 15 | 68.329 | 14.634 | 81.100 | 27.728 |
| Norm. | N° Neurons | Out. Factor (%) | Dataset 3 | |
|---|---|---|---|---|
| AUC (%) | T. Time (s) | |||
| Norm | 1 | 5 | 90.358 | 578.872 |
| Norm | 2 | 5 | 90.646 | 746.915 |
| Zscore | 3 | 15 | 71.300 | 699.515 |
| Zscore | 4 | 5 | 54.426 | 957.287 |
| Zscore | 5 | 15 | 52.447 | 1787.564 |
| Zscore | 6 | 0 | 50.000 | 1621.264 |
| Norm | 7 | 15 | 75.036 | 2483.040 |
| Zscore | 8 | 15 | 64.628 | 2248.230 |
| Zscore | 9 | 0 | 50.000 | 2473.127 |
| Zscore | 10 | 0 | 50.000 | 2539.572 |
| Zscore | 11 | 0 | 50.000 | 2636.626 |
| Zscore | 12 | 0 | 50.000 | 2682.045 |
| Norm | 13 | 15 | 57.131 | 3221.705 |
| Zscore | 14 | 15 | 57.675 | 2962.068 |
| Zscore | 15 | 15 | 56.630 | 3085.607 |
| Norm | 16 | 15 | 54.603 | 3490.254 |
| Norm | 17 | 15 | 56.859 | 3835.607 |
| Norm | 18 | 15 | 59.668 | 3910.105 |
| Zscore | 19 | 15 | 61.986 | 3670.120 |
| Zscore | 20 | 15 | 62.389 | 3764.557 |
| Zscore | 21 | 15 | 61.268 | 3992.231 |
| Norm | 22 | 15 | 64.799 | 3722.349 |
| Norm | 23 | 15 | 62.389 | 4018.956 |
| Norm | 24 | 15 | 60.247 | 4125.477 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Michelena, Á.; López, V.; López, F.L.; Arce, E.; Mendoza García, J.; Suárez-García, A.; García Espinosa, G.; Calvo-Rolle, J.-L.; Quintián, H. A Fault-Detection System Approach for the Optimization of Warship Equipment Replacement Parts Based on Operation Parameters. Sensors 2023, 23, 3389. https://doi.org/10.3390/s23073389
Michelena Á, López V, López FL, Arce E, Mendoza García J, Suárez-García A, García Espinosa G, Calvo-Rolle J-L, Quintián H. A Fault-Detection System Approach for the Optimization of Warship Equipment Replacement Parts Based on Operation Parameters. Sensors. 2023; 23(7):3389. https://doi.org/10.3390/s23073389
Chicago/Turabian StyleMichelena, Álvaro, Víctor López, Francisco Lamas López, Elena Arce, José Mendoza García, Andrés Suárez-García, Guillermo García Espinosa, José-Luis Calvo-Rolle, and Héctor Quintián. 2023. "A Fault-Detection System Approach for the Optimization of Warship Equipment Replacement Parts Based on Operation Parameters" Sensors 23, no. 7: 3389. https://doi.org/10.3390/s23073389