1. Introduction
In recent years, the prevalence of indoor robotics has significantly increased. These robots are usually assigned to perform different indoor operations, including but not limited to transporting objects, offering navigation assistance, and handling emergencies. To accomplish these tasks effectively, the robot must be able to navigate autonomously from one location to another, making the path planning ability a critical factor in the autonomous behavior of the robot. Moreover, in real-world scenarios, dynamic obstacles, such as human beings or other robots, frequently arise, requiring the robot to also possess the ability to dynamically avoid these obstacles in order to achieve a higher level of autonomy. Therefore, a considerable amount of research has focused on studying path planning and dynamic navigation of robots in indoor environments [
1,
2,
3,
4].
Over the past few years, many algorithms have been developed to tackle the challenge of path planning. Among these approaches are the traditional methods, including the genetic algorithm, A* algorithm, D* algorithm, and Dijkstra algorithm, as documented by Gong et al. [
5] in their study on efficient path planning. These traditional approaches have demonstrated a degree of efficacy and success. However, some significant limitations have also been identified, such as being time-consuming, having a tendency to converge to local optima, failing to account for collision and risk factors, and so on. Consequently, these prior methods require improvement to meet the demands of more advanced path planning and increasingly complex environments.
Various advanced methods have been proposed in addition to the traditional path planning techniques to improve the path planning process. These include the method proposed by Haj et al. [
6], which utilizes machine learning to classify static and dynamic obstacles and applies different strategies accordingly. Bakdi et al. [
7] have proposed an optimal approach to path planning, while Zhang et al. [
8] have proposed a Spacetime-A* algorithm for indoor path planning. Palacz et al. [
9] have proposed BIM/IFC-based graph models for indoor robot navigation, and Sun et al. [
10] have employed semantic information for path planning. Additionally, Zhang et al. [
11] have proposed a deep learning-based method for classifying dynamic and static obstacles and adjusting the trajectory accordingly. Dai et al. [
12] have proposed a method that uses a novel whale optimization algorithm incorporating potential field factors to enhance mobile robots’ dynamic obstacle avoidance ability. Miao et al. [
13] have proposed an adaptive ant colony algorithm for faster and more stable path planning, and Zhong et al. [
14] have proposed a hybrid approach that combines the A* algorithm with the adaptive window approach for path planning in large-scale dynamic environments. Despite these advances, certain limitations still exist when applying these methods in real-life situations. For instance, Zhang et al.’s model relies on a waiting rule for dynamic obstacles, which may only be suitable for some types of dynamic obstacles. Furthermore, Miao et al.’s adaptive ant colony algorithm does not consider dynamic obstacles, making the model unsuitable for complex indoor environments.
The recent advancements in reinforcement learning have provided novel approaches [
15,
16,
17,
18] to address the path planning problem. The success demonstrated by Google DeepMind in various tasks, such as chess, highlights the potential of artificial intelligence in decision-making issues, including path planning. Implementing reinforcement learning in path planning enhances the autonomous capabilities of robots, resulting in safer, faster, and more rational obstacle avoidance. The convergence of the model is expected to provide more optimal solutions in the future. There have been numerous studies that propose reinforcement learning for path planning, such as the SAC model proposed by Chen et al. [
19] for real-time path planning and dynamic obstacle avoidance in robots, the DQN model proposed by Quan et al. [
20] for robot navigation, and the RMDDQN model proposed by Huang et al. [
21] for path planning in unknown dynamic environments.
The sequential linear path (SLP) algorithm was introduced by FAREH et al. [
22] in 2020. It is a path planning strategy that emphasizes the examination of critical regions, such as those surrounding obstacles and the goal point. It prioritizes the utilization of processing resources in these areas. As a global path planning approach, SLP generates a comprehensive path from the starting point to the goal while considering static obstacles, breaking down the dichotomy between path quality and speed. In our proposed path planning method, we incorporate the SLP algorithm to enhance the performance of DDPG.
This study presents three key contributions: (1) An enhanced reinforcement learning model for path planning is proposed, which enables the robot to modify its destination dynamically and provide real-time path planning solutions. (2) Both the convergence rate and path planning performance of DDPG are improved by incorporating the use of SLP to generate a global path to guide DDPG in large-scale environment path planning tasks. (3) To validate our approach, we conduct a comprehensive set of simulations and experiments that compare various path planning methods and provide evidence for the effectiveness of our proposed method.
The paper is structured as follows: In
Section 2, the problem and related algorithms are described.
Section 3 introduces the path planning pipeline of the proposed SLP improved DDPG algorithm, along with a detailed account of the reward function design.
Section 4 presents the simulation experiment and a detailed comparison and analysis of the experimental results. Finally,
Section 5 offers a comprehensive summary of the paper’s contents.
2. Related Work
2.1. Problem Definition
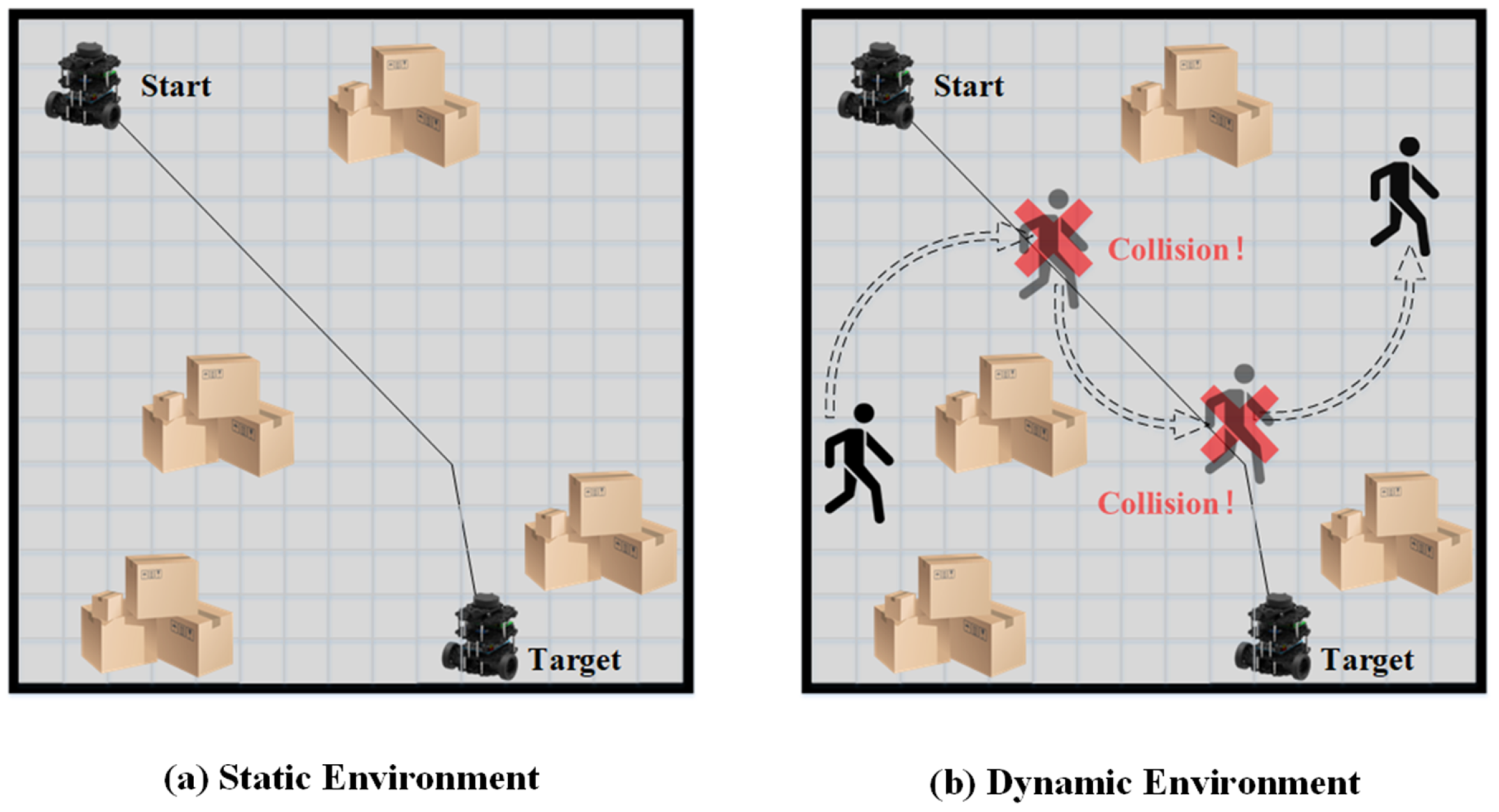
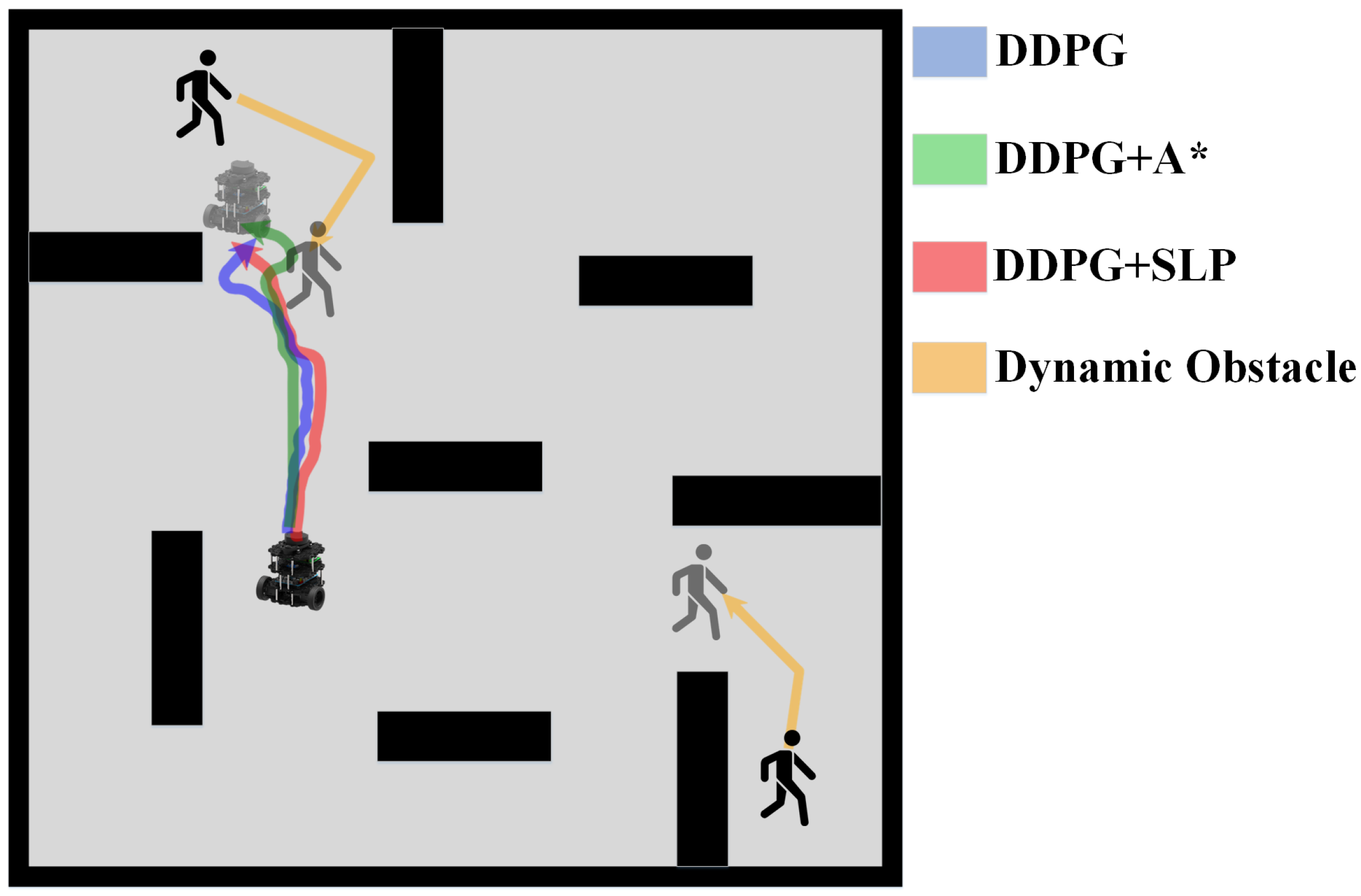
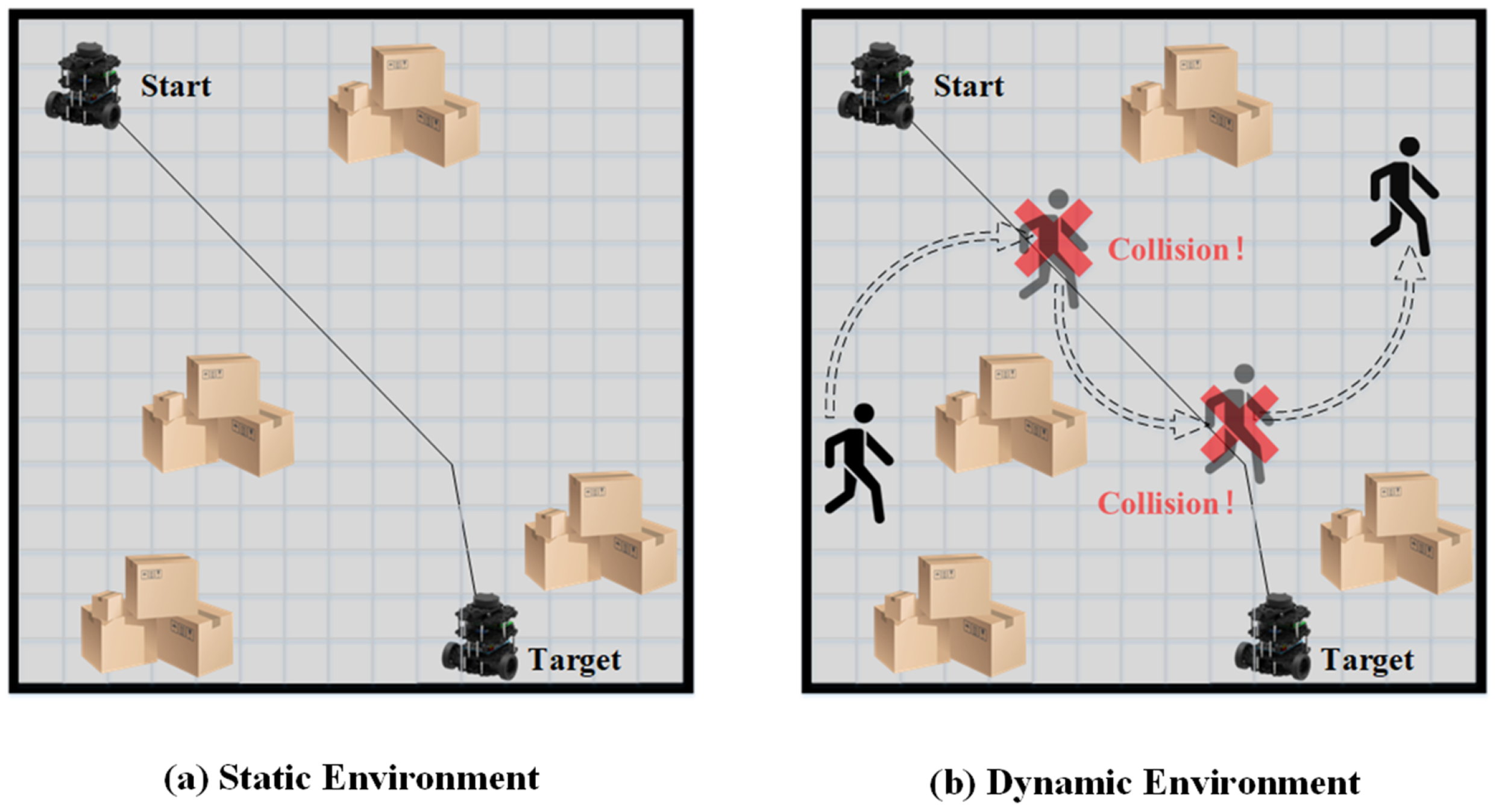
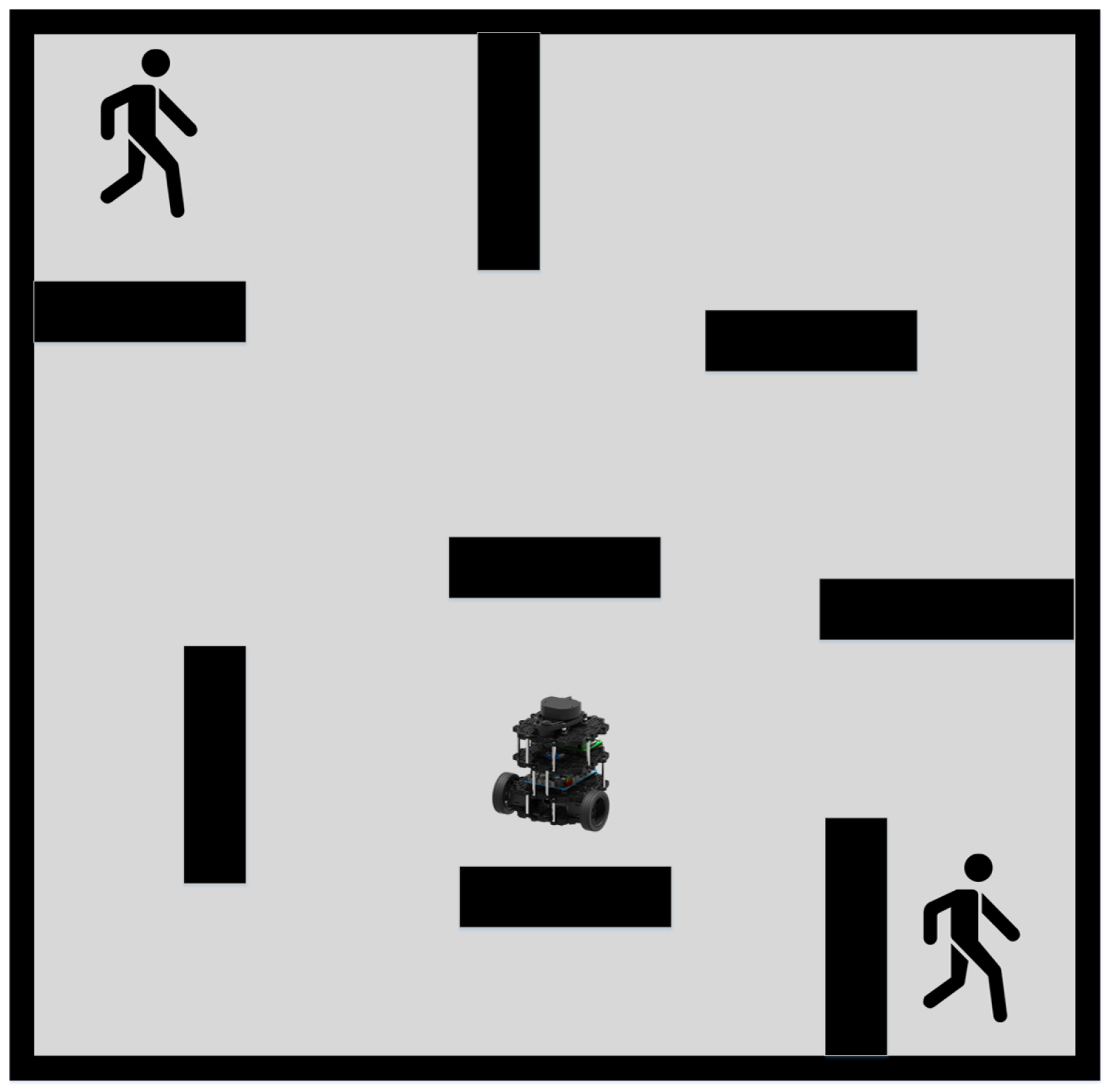
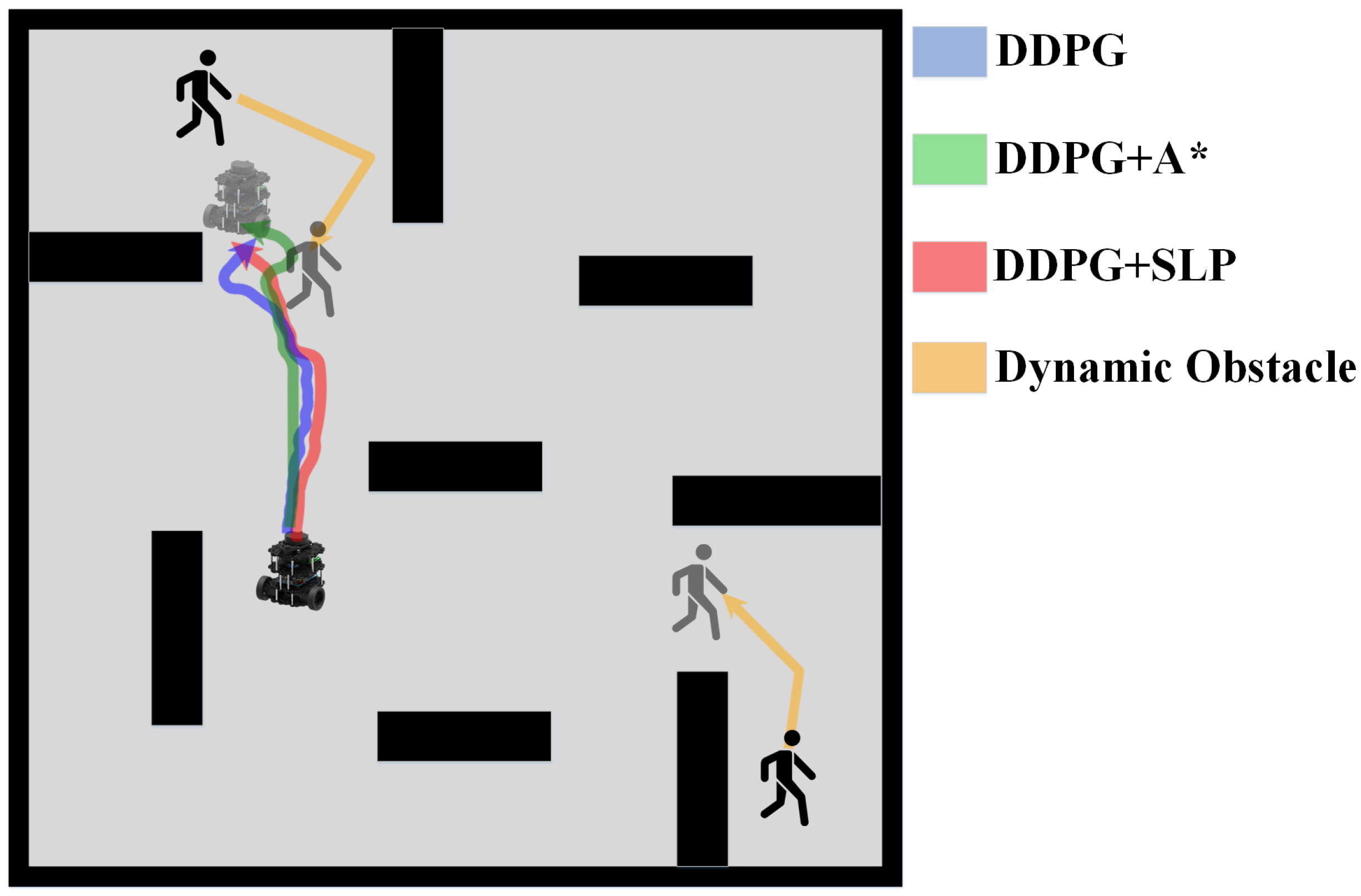
As discussed, previous researchers have developed robust and efficient global path planning algorithms. However, the assumption that the path planning environment is static is only valid in ideal scenarios. In reality, most environments for robot path planning, such as factories, warehouses, and restaurants, are dynamic. Thus, relying solely on global path planning will likely result in unsuccessful routing outcomes, as global planning cannot adapt to dynamic obstacles. Robots following a global path in dynamic environments are susceptible to collision with dynamic obstacles, as shown in
Figure 1.
2.2. Deep Deterministic Policy Gradient
The deep deterministic policy gradient (DDPG) reinforcement learning algorithm was introduced by the Google DeepMind group [
23]. It addresses the parameter relevance issue in the Actor–Critic algorithm and the inadequacy of continuous actions in the AQN algorithm. The DDPG algorithm can be considered an improved version of AQN that incorporates the overall structure of the Actor–Critic algorithm. Like the Actor–Critic algorithm, the DDPG algorithm consists of two primary networks: the Actor and Critic networks.
The output of the Actor network is a determined action, which is defined as . The estimation network that produces real-time actions is the , where we have indicating the parameters. It updates the parameter , outputs the action A according to the current state and interacts with the environment to generate the next state and reward . The Actor target network updates parameters in the Critic network and determines the following optimal action according to the next state sampled from the experience replay.
The Critic network aims to fit the value function . The Critic estimation network updates its parameters , calculates the current Q value and the target Q value . The Critic target network calculates the part of the target Q value. Here, is the discount factor that has the range .
The training process of the Critic network is to minimize the loss function L shown in Equation (
1).
where
is given by Equation (
2).
The Actor network is updated through a policy gradient shown in Equation (
3).
Target networks are updated through Equation (
4), with
.
Comparing DDPG with previous path planning and dynamic obstacle avoidance methods, such as ant colony, A* + adaptive window, roaming trail, etc., we may find DDPG has more potential for high complexity dynamic environment path planning and dynamic obstacle avoidance due to the following reasons:
- 1.
DDPG is a reinforcement learning method that improves through multiple iterations and gradually converges, which will likely provide optimal solutions for the current environment and state.
- 2.
Unlike traditional path planning methods that require previous knowledge of the environment map, DDPG does not require any map but can reach the goal using a pre-trained model. This makes the DDPG method more adaptive since, in dynamic environments, it is hardly possible to track the environment’s moving obstacles’ trajectory.
- 3.
Unlike traditional means of dynamic obstacle avoidance that produce simple actions when the robot encounters a dynamic obstacle, DDPG outputs a series of actions. The actions that DDPG produces to avoid obstacles are relatively reasonable and may have connections with previous actions. It is a real-time obstacle avoidance. The actions may be planned ahead of time instead of stopping the robot from adjusting the trajectory when a dynamic obstacle is detected.
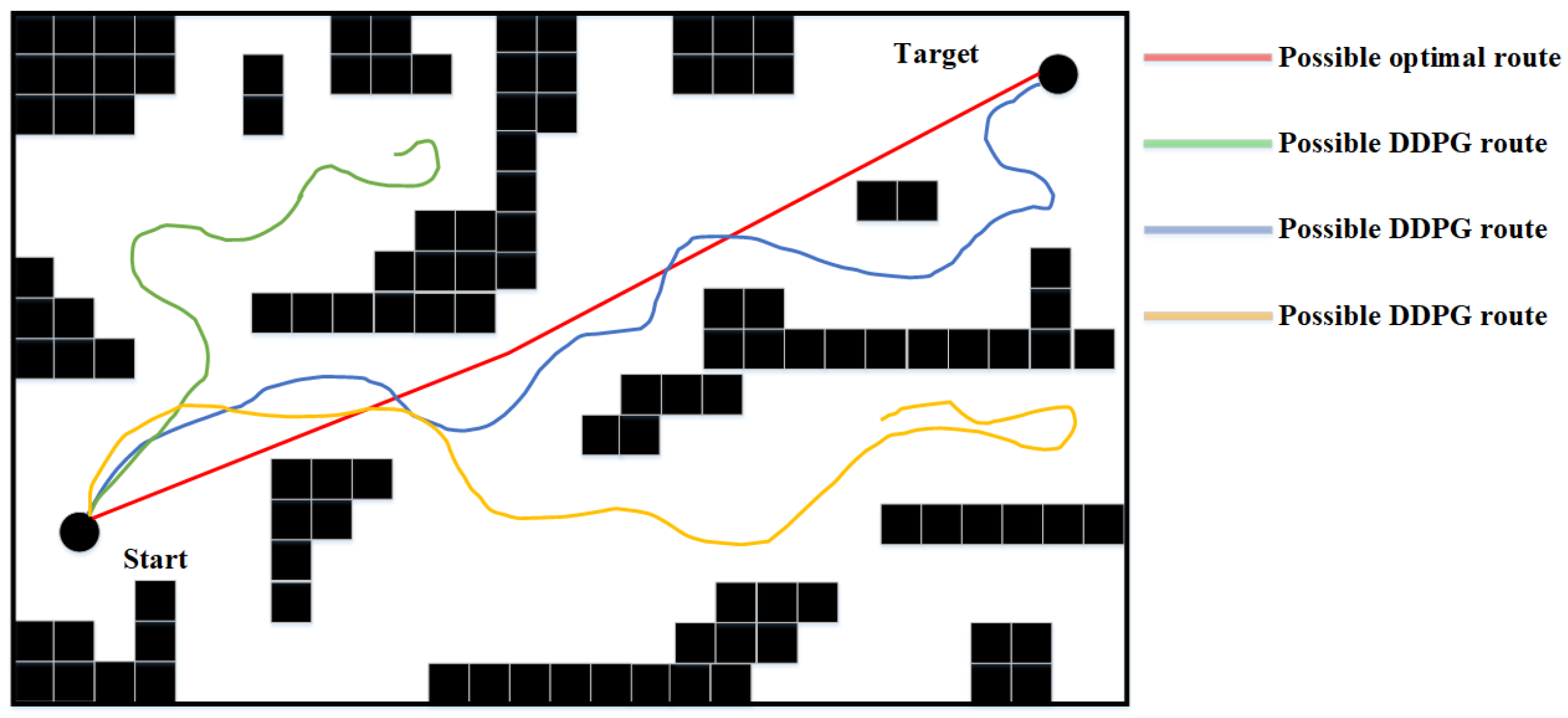
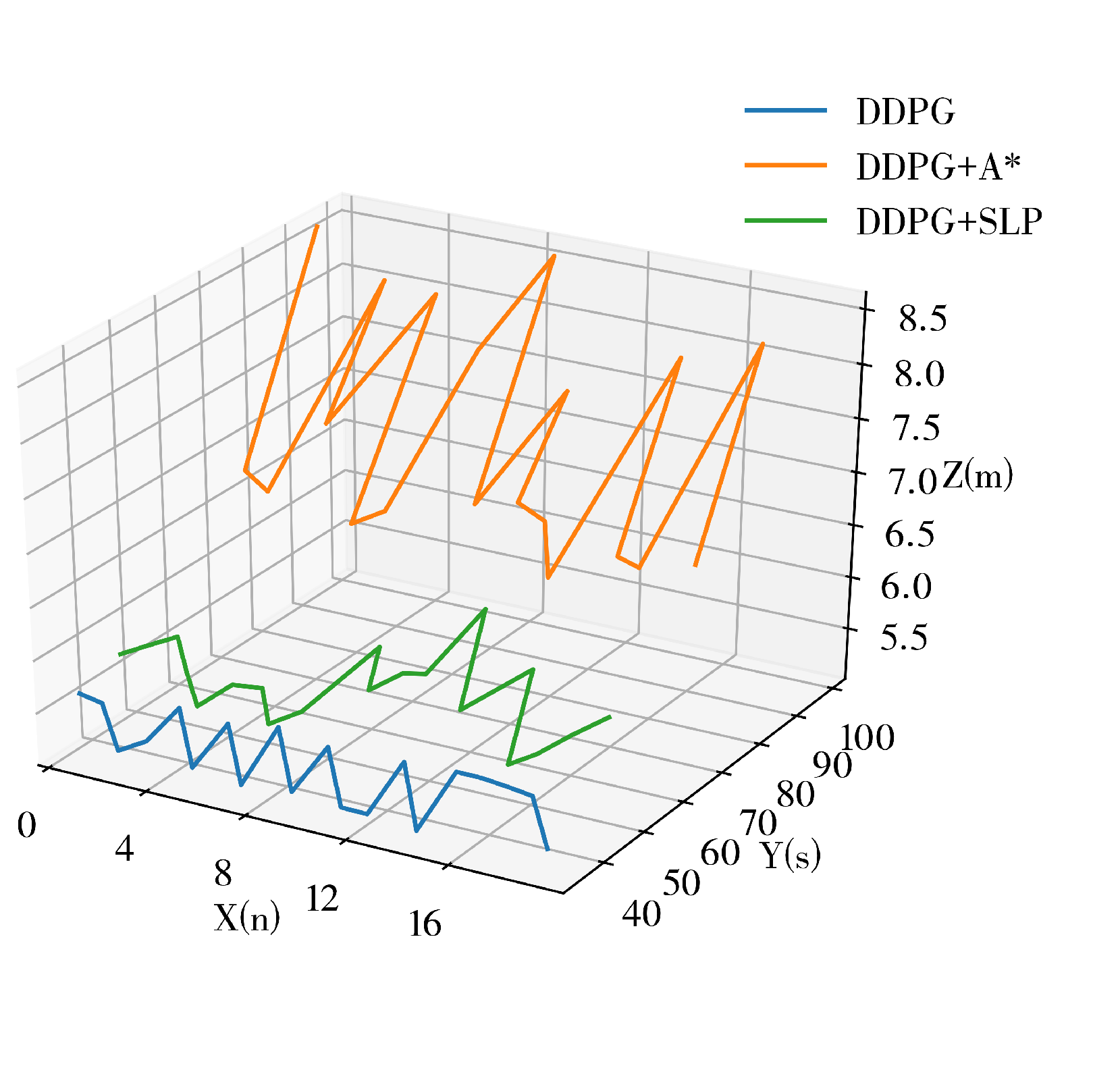
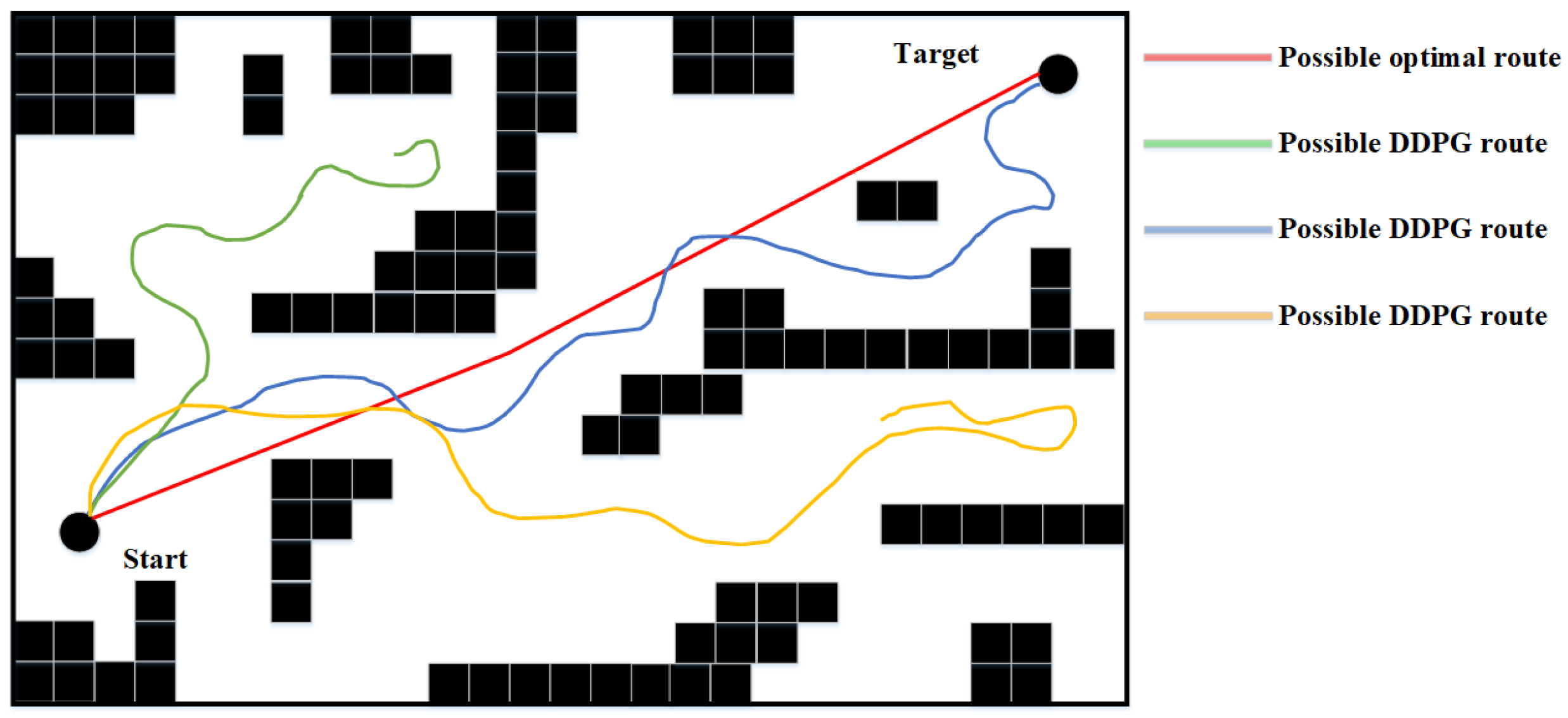
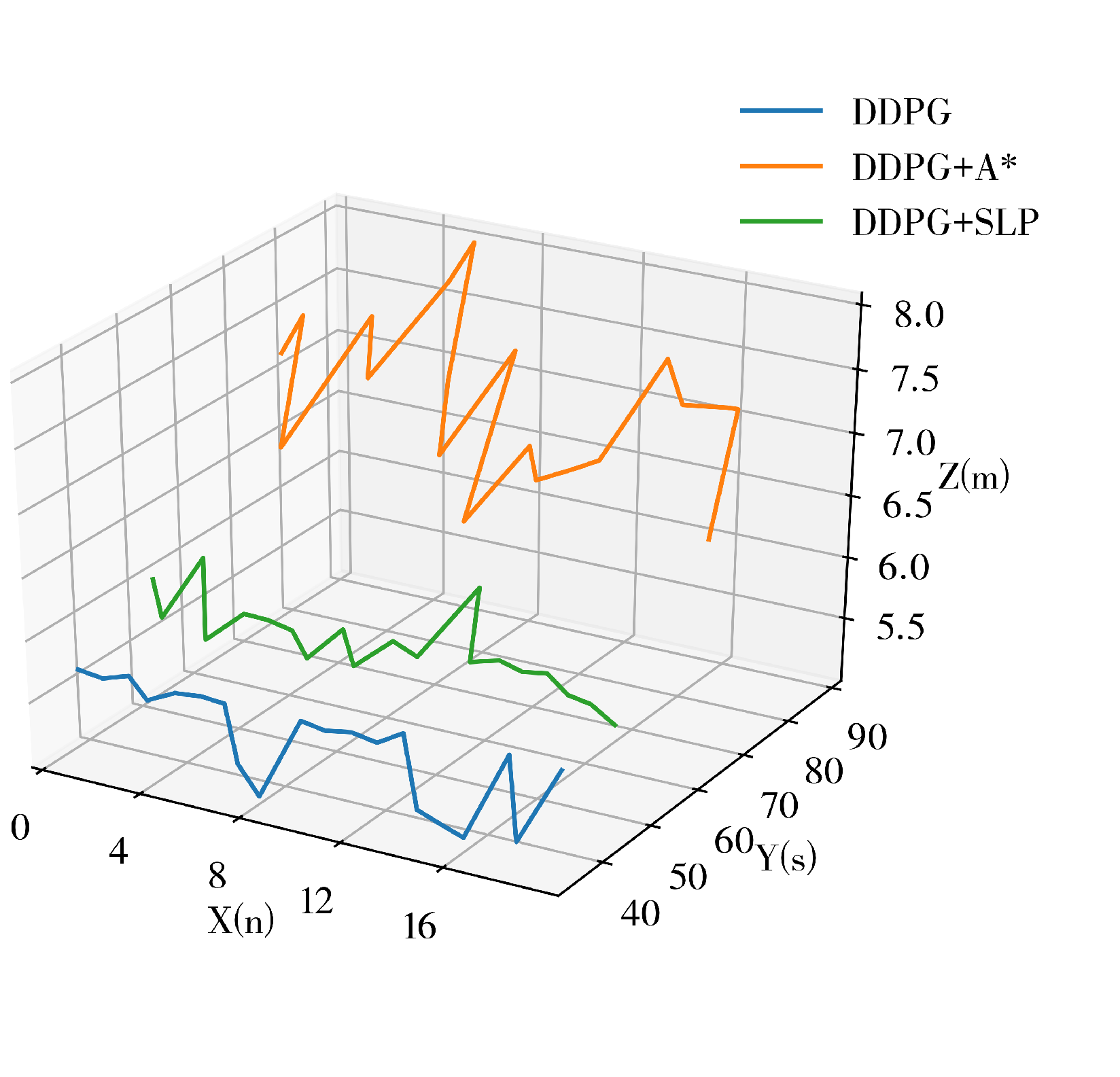
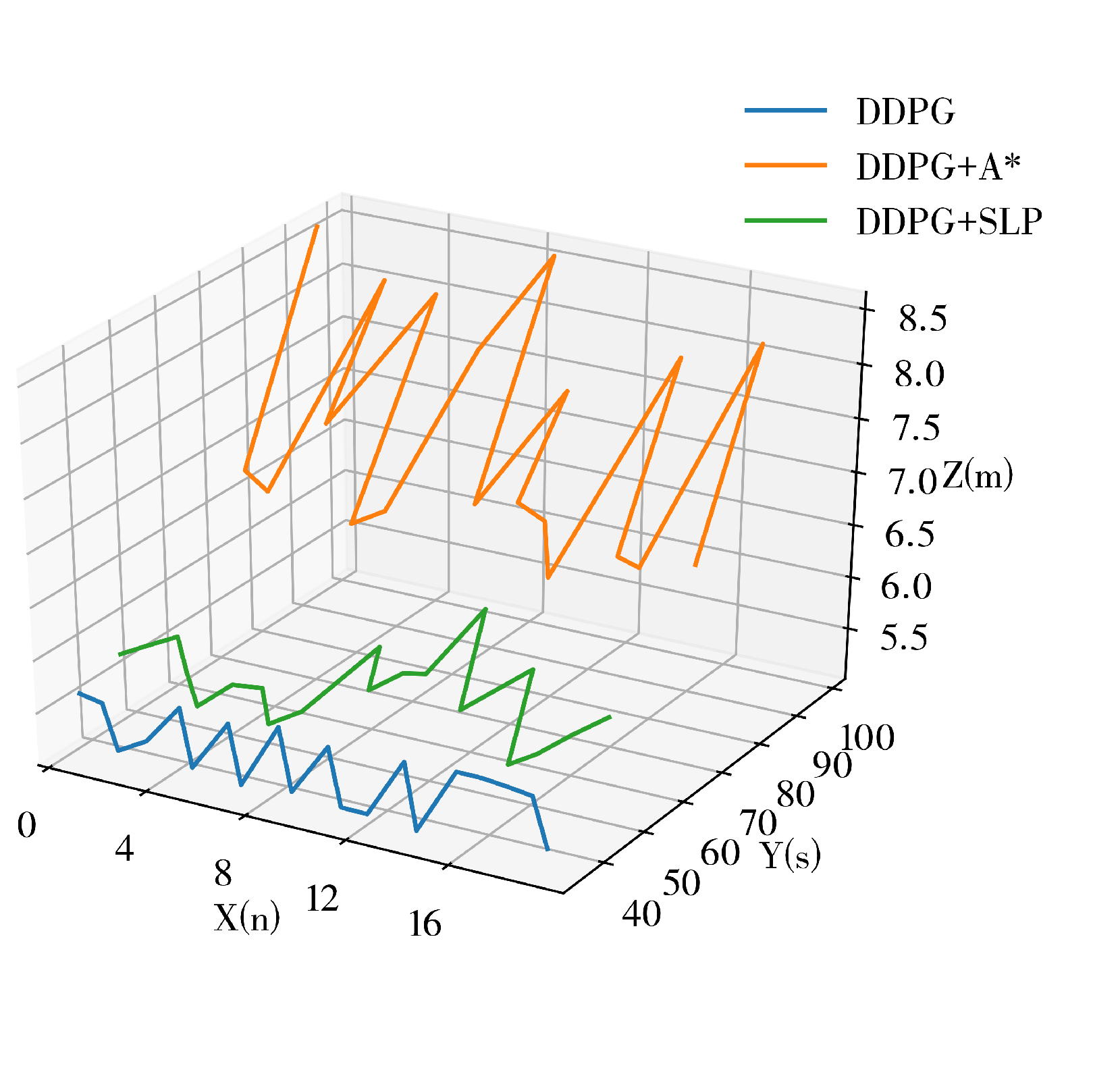
DDPG presents excellent potential in performing small-scale path planning. However, DDPG is a reinforcement learning method, which inevitably inherited the characteristics of randomness and uninterpretability of RL, thus causing the path planning results of DDPG to represent signs of randomness and unreasonableness. This is one of the defects of DDPG in path planning since it could cause inefficiency and is exaggerated as the scale of the environment increases. An example of DDPG path planning failing the path planning task or being unable to perform the task efficiently in a large-scale environment is shown in
Figure 2.
2.3. Sequential Linear Paths
The SLP (sequential linear paths) approach is a path planning method put forward by Fareh et al. in 2020 that has overcome the traditional trade-off between execution speed and path quality (also known as the swiftness-quality problem), enhancing both the path quality and swiftness.
The SLP path planning strategy focuses more on areas around static obstacles and areas around the goal point, defined as critical areas. SLP exhausts the processing power in critical areas to reduce computational resource waste and improve swiftness. It is interested in the obstacles that intersect with the direct linear line between the starting and goal points while ignoring unnecessary obstacles that do not lie alongside the route.
The SLP is a hybrid approach that implements traditional path planning, such as A*, D*, or the probabilistic roadmap (PRM), to find possible paths around obstacles that intersect with the linear line from the robot to the destination. The implemented procedure may reduce the computational efforts compared to applying the basis algorithm on the whole map. SLP enhances the path quality by finding any linear shortcuts between any two points in the path and modifying these shortcuts as the final global path.
The experimental results have proven that the SLP path planning strategy showed a superior advantage over other path planning techniques in both aspects, computational time (reached up to 97.05% improvement) and path quality (reached up to 16.21% improvement for path length and 98.50% for smoothness).
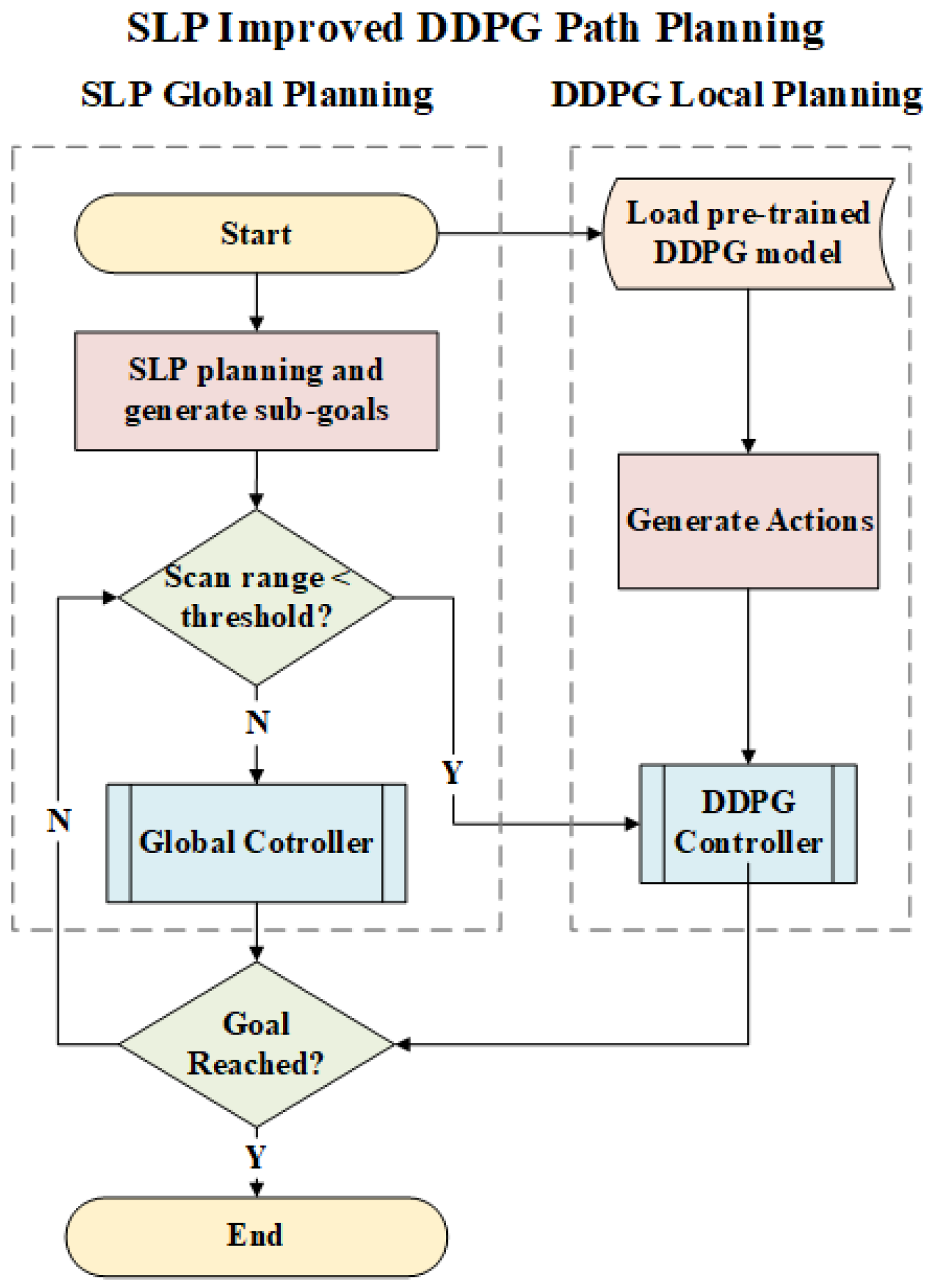
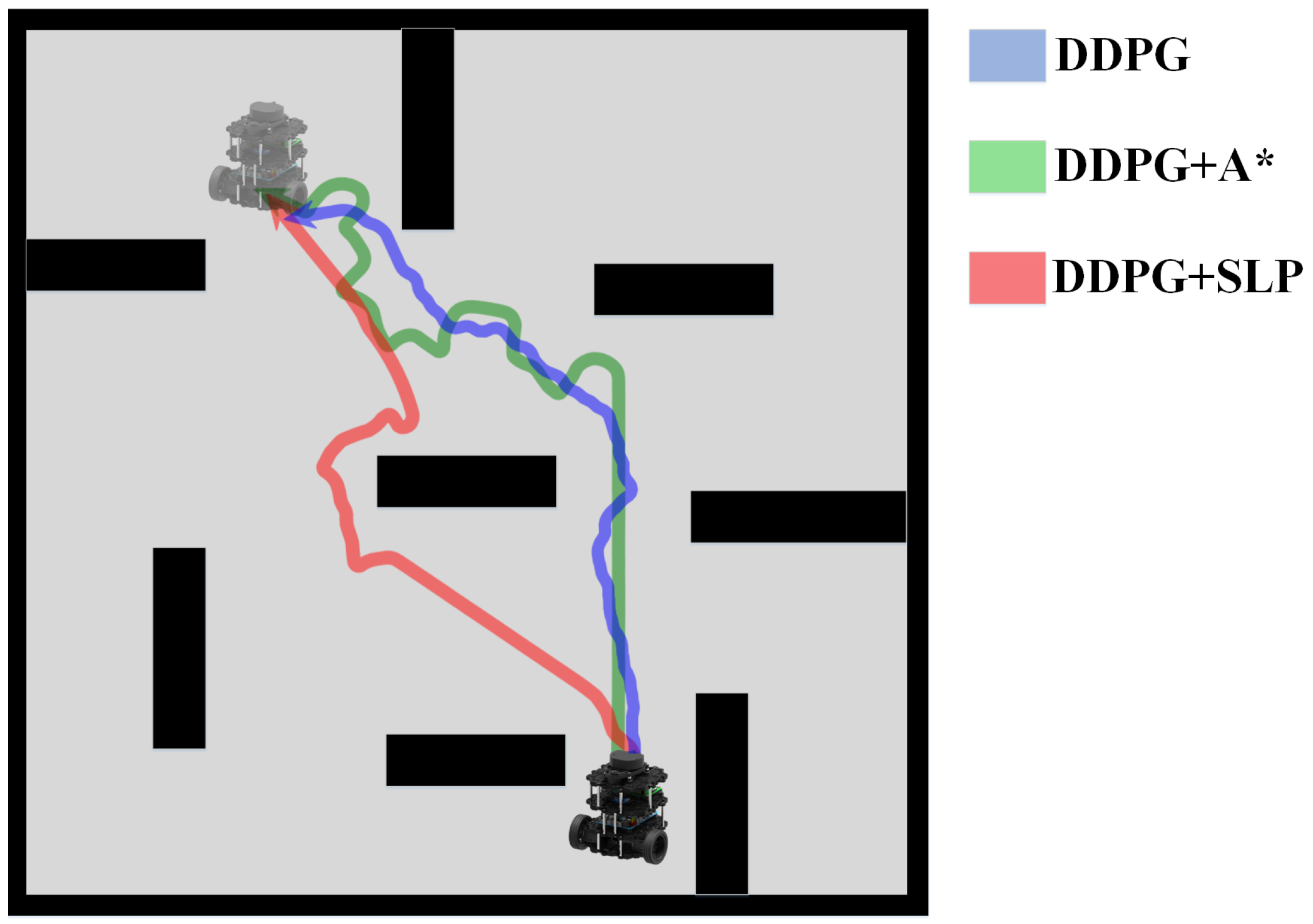
Our path planning method used SLP to calculate a prior global route to guide the DDPG to improve its performance in large-scale environments. The main idea is to perform global path planning using SLP and select sub-goal points to provide directional aid for the DDPG.
The sub-goals
between the starting point
S and goal point
G are directly generated using the SLP algorithm, and thus, the path can be denoted using points:










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}